안녕하세요 정의철 연구원입니다. 이번에 제가 리뷰할 논문은 ‘DetCo: Unsupervised Contrastive Learning for Object Detection’이란 논문입니다. 이 논문을 읽게된 계기는 이번에 진행할 연구로 Multispetral pedestrian detection에 self supervised learning(SSL)을 적용시켜볼 계획인데 이 연구 주제와 관련된 서베이를 진행하던 중 도움이 될만한 논문을 찾게 되어 리뷰하게 되었습니다. 기존 SSL 방법론들은 Object Detection task에 transfer 시켰을 때 괜찮은 성능을 보여왔지만 Classification task에 적용시켰을때는 성능이 감소하는 경향을 보여왔습니다. 그래서 Detco는 이러한 문제를 분석하고 2가지 task에서 모두 성능을 높이기 위해 연구한 방법론입니다. 그럼 이제 자세히 리뷰를 해보겠습니다.
Abstract
DetCo는 Object Detection을 위한 간단하면서도 효과적인 self supervised learning(SSL) 방법론입니다. 최근에는 Object Detection을 위해 다양한 Unsupervised pre-training methods 개발되었지만, 이들은 일반적으로 이미지 분류에 대한 부족함이 있어 왔습니다. DetCo는 이와 달리, downstream instance-level dense prediction tasks에서 잘 transfer되며 동시에 이미지 분류에서도 높은 정확도를 유지합니다. 이점은 다음과 같은 두 가지 디자인 요소에서 비롯됩니다: (1) multi-level supervision to inter- mediate representations, (2) contrastive learning between global image and local patches. 이 두 가지 디자인은 각 feature pyramid에서 global하고 local한 표현을 학습할 수 있기에 Detection 및 Classification의 성능을 개선합니다.
1. Introduction
Visual Representation의 자기 지도 학습은 컴퓨터 비전에서 중요한 문제로, 이미지 분류, 객체 검출 및 semantic segmentation와 같은 여러 downstream task에 적용이 됩니다. 이는 대규모 언라벨된 데이터에서 사전 훈련된 모델을 downstream task에 적용시키는 것을 목표로 합니다. 이전 방법들은 다양한 pretext tasks 설계하는 데 연구가 되어왔습니다. 그 중 가장 유명한 방법 중 하나는 contrastive learning입니다. contrastive learning 은 한 이미지를 여러 뷰로 변환하고, 동일한 이미지에서 뷰 간 거리를 최소화하고, 다른 이미지에서 뷰 간 거리를 최대화하는 방식으로 작동합니다. 그동안 contrastive learning 과 온라인 클러스터링을 기반으로 한 몇 가지 방법(MoCo v1/v2, BYOL 및 SwAV 등)이 이미지 분류에서 fully-supervised method과의 격차를 줄이는데 큰 역할을 했습니다. 그러나 이러한 방법들은 object detection에서의 transfer 성능은 만족할만한 결과를 보여주지는 않았습니다. 당시 저자의 연구와 동시에 DenseCL, InsLoc 및 PatchReID도 contrastive learning을 적용시켜 객체 검출에 잘 맞는 pretext task를 설계했습니다. 그러나 이러한 방법들은 객체 검출에서는 잘 전이되지만 이미지 분류의 성능은 감소하는 경향이 있습니다. 이처럼 이미지 분류와 객체 검출에서 모두 좋은 성능을 보일 수 있는 pretext task를 설계하는 것은 어려운 일입니다. 저자가 말하길 이미지 분류와 객체 탐지 사이에 메울 수 없는 gap은 없다고 말합니다. 직관적으로, 이미지 분류는 a single high-level feature map,에서 global instance를 인식하는 반면, 객체 검출은 multi-level feature pyramids에서 local instance를 인식합니다.
이러한 관점에서 (1) feature pyramid의 각 level에서 분별력있고 (2) global 이미지와 로컬 패치에 대해 일관된 표현을 구축하는 것이 해결 방안이 될 수 있습니다. 그러나 기존의 unsupervised methods은 이 두 가지 측면을 간과합니다. 따라서 검출과 분류가 서로 상호 개선되지 못합니다. 본 연구에서는 DetCo를 제시하는데 DetCo에는 (1) 백본 네트워크의 multi-level supervision on features from different stages (2) 전역 이미지와 지역 패치 간의 contrastive learning이 포함됩니다.
2. Related Work
기존의 representation 학습을 위한 비지도 학습 방법은 일반적으로 generative 방법과 discriminative 방법으로 나눌 수 있습니다. generative 방법은 일반적으로 이미지의 auto-encoding 또는 adversarial learning에 의존하며, 주로 픽셀 공간에서 작동합니다. 따라서 대부분의 generative 방법은 계산 비용이 많이 들며, 이미지 생성을 위해 필요한 픽셀 수준의 세부 사항은 고수준 representation 학습에는 필요하지 않을 수 있습니다. discriminative 방법 중에서는 generative 방법과 달리, contrastive learning 은 같은 이미지 뷰의 representation (즉, 양성 쌍)을 가깝게 끌어당기고 다른 이미지의 뷰의 representation (즉, 음성 쌍)을 멀리 밀어냄으로써 computation-consuming generation step를 줄입니다. 시각적 representation의 대조 학습을 위한 간단한 프레임워크로는 SimCLR가 있습니다. 이는 데이터 증강의 조합 후 이미지를 대조하여 특징을 학습합니다. 그 후 MoCo와 MoCo v2를 제안하여 memory bank에서 뽑힌 음성 쌍의 일관된 representation을 유지하기 위해 모멘텀 인코더를 사용합니다. SwAV는 contrastive learning에 온라인 클러스터링을 도입하여 pairwise comparisons를 계산하지 않고도 작업합니다. BYOL은 반복적으로 네트워크의 출력을 bootstrapping함으로써negative pairs의 사용을 피했습니다. 이러한 방법론들은 시각적 representation 학습을 위해 Relative patch pre- diction, colorizing gray-scale images , image inpainting , image jigsaw puzzle , image super- resolution , geometric transformation와 같은 pretext 작업에 의존했습니다. 그러나 대부분의 위 방법들은 주로 이미지 분류를 위해 설계되었으며 객체 검출은 고려하지 않았습니다. 물론 저자의 방법론과 같이 DenseCL, InsLoc ,PatchReID처럼 객체 검출을 위해 pretext task 설계한 논문도 있지만 이들의 transferring performance은 이미지 분류에서 좋지 않습니다. 저자의 방법론은 detection에 좋은 성능을 유지하면서 이미지 분류에 representation을 유지하는 더 나은 pretext task를 설계하는 데 초점을 맞추고 있습니다.
3. Methods
3.1. DetCo Framework

DetCo의 전체 아키텍처는 위의 그림과 같습니다.DetCo는 MoCo v2를 기반으로 한 파이프라인으로 설계되었습니다. DetCo는 백본 네트워크, MLP 헤드, 메모리 뱅크로 구성됩니다. MLP 헤드 및 메모리 뱅크의 셋팅은 MoCo v2와 동일합니다.
구체적으로, DetCo는 MoCo v2와 다른 점 (1) multi-level supervision은 여러 단계에서 피쳐를 구별하기 위해 사용됩니다. (2) global and local contrastive learning은 전역 및 로컬 피쳐 표현을 모두 향상시키기 위해 사용됩니다. 이러한 두 가지 다른 설계는 DetCo가 MoCo v2의 이미지 분류에 대한 장점을 이어가면서 검출 작업에서 훨씬 좋은 전이 성능을 보이게 합니다.
DetCo의 손실 함수는 다음과 같이 정의됩니다

여기서 I는 global 이미지를 나타내고 P는 로컬 패치 세트를 나타냅니다. 식 (1)은 multi-stage contrastive loss입니다. 각 단계에서는 세 가지 교차 로컬 및 전역 contrastive loss가 있습니다.
3.2. Multi-level Supervision
객체 검출기는 RetinaNet 및 Faster R-CNN FPN과 같이 다양한 피쳐 level에서 객체를 예측합니다. 각 level에서 피쳐가 좋은 구별력을 유지해야 하는데 위 요구 사항을 충족하기 위해 저자는 원래의 MoCo 베이스라인에 간단한 수정을 추가했습니다. 구체적으로, 하나의 이미지를 백본 ResNet-50에 인풋으로 넣으면 Res2, Res3, Res4, Res5라는 다양한 단계에서 피쳐가 출력됩니다. MoCo는 Res5만 사용하는 반면, 저자는 모든 수준의 피쳐를 활용하여 contrastive loss를 계산하여 백본의 각 단계가 구별력 있는 표현을 생성하도록 만들었습니다.
이미지 I ∈ R(H×W ×3)가 주어지면 먼저 global view의 transformations set인 Tg에서 무작위로 선택된 두 가지 변형에 따라 이미지 Iq 및 Ik의 두 가지 뷰로 변환합니다. 동일한 구조를 가진 인코더q와 인코더k를 함께 학습하고, 인코더k는 momentum 업데이트을 사용하여 가중치를 업데이트합니다.
인코더q에는 백본과 네 개의 global MLP 헤드가 포함되어 있습니다. 저자는 Iq를 백본 bθq (·)에 인풋으로 넣어 피쳐 {f2, f3, f4, f5} = bθq (Iq)를 추출합니다. 여기서 fi는 i번째 단계의 피쳐를 의미합니다.
multi level features를 얻은 후에는 가중치가 공유되지 않는 네 개의 글로벌 MLP 헤드 {mlp2q (·), mlp3q (·), mlp4q (·), mlp5q (·)}를 추가합니다. 결과적으로 네 개의 global representations {qg2, qg3, qg4, qg5} = encoder_q(Iq)를 얻습니다. 마찬가지로 {kg2, kg3, kg4, kg5} = encoder_k(Ik)를 쉽게 얻을 수 있습니다. MoCo는 InfoNCE를 사용하여 손실을 계산하며 다음과 같이 정의됩니다:

저자는 이를 multi level features에 대한 multi level contrastive loss로 확장하여 다음과 같이 정의합니다:

여기서 w는 손실 가중치이고 i는 현재 단계를 나타냅니다. 손실 가중치는 PSPNet에서 영감을 받아 shallow한 레이어의 손실 가중치를 deep한 레이어보다 작게 설정합니다. 또한 각 레이어에 대해 개별 메모리 뱅크 queuei를 구축합니다.
3.3. Global and Local Contrastive Learning
객체 탐지기는 로컬 영역에서 분류기를 재사용하여 감지를 수행합니다. 따라서 각 로컬 영역은 인스턴스 분류에 대해 구분력이 있어야 합니다. 위 요구 사항을 충족시키기 위해 저자는 global 및 local contrastive learning을 개발하여 패치 세트와 전체 이미지에서 일관된 인스턴스 representation을 유지합니다. 이 전략은 이미지 level representation을 활용하여 인스턴스 level representation을 향상시키는데 구체적으로는 입력 이미지를 9개의 로컬 패치로 변환하는 jigsaw augmentation을 사용합니다. 이러한 패치는 인코더를 통과하여 9개의 로컬 특징 representation을 얻을 수 있습니다. 그런 다음 이러한 특징을 MLP 헤드로 결합하여 하나의 특징 representation을 생성하고, global 및 local contrastive learning을 구축합니다. 이미지 I ∈ R(H×W ×3)가 주어지면, 먼저 두 개의 로컬 패치 세트 Pq와 Pk로 변환됩니다. 이는 local transformation set Tl에서 선택된 두 transformation에 의해 수행됩니다. 각 로컬 패치 세트에는 {p1, p2, …, p9}와 같이 9개의 패치가 있습니다. 로컬 패치 세트를 백본에 입력하여 각 단계에서 9개의 특징 Fp = {fp1, fp2, …, fp9}를 얻습니다. 한 단계를 예로 들어, 로컬 패치를 위한 MLP 헤드인 mlplocal(·)을 구축하게 됩니다. 그런 다음 Fp는 로컬 패치 MLP 헤드에 output을 입력으로 주어 최종 representation ql을 얻습니다. 마찬가지로 kl을 얻는 데도 동일한 접근 방식을 사용할 수 있습니다. contrastive cross loss에는 global↔local contrastive loss와 local↔local contrastive loss 두 부분이 있습니다. global↔local loss는 다음과 같습니다:

마찬가지로, local↔local loss는 다음과 같이 정의할 수 있습니다:

4. Experiments
다음은 실험 부분입니다. 저자는 PASCAL VOC, COCO , instance segmentation, 2D pose estimation, DensePose 및 Cityscapes instance와 semantic segmentation과 같은 2D 및 3D dense prediction task에서 DetCo의 성능을 평가합니다. 이 실험을 통해 DetCo가 기존의self-supervised 와 supervised 보다 좋은 성능을 보임을 확인할 수 있습니다
4.1 Object Detection
Experimental Setup: 저자는 세 가지 대표적인 detectors를 선택합니다: Faster R-CNN, Mask R-CNN, RetinaNet 및 Sparse R-CNN. Mask R-CNN은 two-stage detectors이고, RetinaNet은 stage detectors입니다. Sparse R-CNN은 NMS 없이 엔드 투 엔드 detectors이며, COCO에서 높은 mAP를 가집니다. 실험 설정은 MoCo와 동일합니다.


PASCAL VOC: Table 9와 Figure 3에 표시된 바와 같이 MoCo v2는 이미 VOC detection에서 다른 self supervised learning 방법을 앞지르기 때문에 저자는 이를 baseline으로 설정합니다. 그러나 DetCo는 200 epoch 및 800 epoch에서 MoCo v2 보다 성능이 좋으며, 100 epoch 사전 학습만으로도 MoCo v2-800ep(800 epoch 사전 학습)과 거의 동일한 성능을 달성합니다. 또한 DetCo-800ep는 mAP에서 58.2 , AP75에서 65.0의 성능으로 sota를 달성합니다. 이는supervised learning 대비 AP 및 AP75에서 각각 4.7 및 6.2 향상된 결과입니다.
COCO with 1× and 2× Schedule.
Table 3에서는 R50-C4 및 R50-FPN 백본에 대한 Mask RCNN 결과를 나타냅니다. DetCo는 R50-C4 및 R50-FPN 백본에 대해 MoCo v2 기준으로 0.9 및 1.2 AP를 앞지르며, supervised learning 대비 1.6 및 1.2 AP를 달성합니다.

Table 7의 2-3 열을 보면 detectors RetinaNet의 결과를 보여주는데 여기서 DetCo 사전 학습은 supervised learning 방법과 MoCo v2보다 1.0 및 1.2 AP가 우수하며, AP50에서 MoCo v2보다 1.3 높습니다.
COCO with Few Training Iterations: COCO는 PASCAL VOC보다 훨씬 큰 데이터 규모를 갖고 있기에 Scratch의 학습을 통해서도 좋은 결과를 얻을 수 있습니다. 때문에 저자는 unsupervised pre-training의 효과를 확인하기 위해 적은 Iterations으로만 모델을 학습시키고 성능을 비교하는 실험을 수행합니다. 이 실험에서 저자는 12k Iterations으로만 detectors를 학습합니다. 12k Iterations은 detectors를 under-trained 상태로 만들며 수렴하기에는 부족합니다. 이 셋팅에서 Mask RCNN-C4, DetCo는 APbb50에서 MoCo v2를 3.8 AP로 앞지르며, 모든 지표에서 supervised learning 방법을 능가합니다.
COCO with Semi-Supervised Learning: Self-supervised learning으로 학습된 피쳐를 Transferring 시킬 때 작은 데이터셋으로 Transfer 시켜 좋은 성능을 얻는것이 Self-supervised learning 가치 중 하나 일 것입니다. 이 실험에서는 작은 규모의 데이터셋에서 self supervised learning의 효과를 확인하기 위한 실험입니다. 실험 셋팅으로는 RetinaNet을 fine_tune하는데 1%, 2%, 5%, 10% 데이터를 임의로 샘플링합니다. 이 셋팅에서는 데이터의 규모가 작기 때문에 오버피팅을 피하고자 12k Iterations으로 detectors를 fine_tune합니다.

결과는 Table 8에 나와있습니다. 10% 데이터 사용 시 DetCo는 supervised learning 방법과 MoCo v2를 각각 2.3 AP 및 1.9 AP로 앞지르는 것을 확인할 수 있습니다. 이러한 결과는 DetCo 사전 학습 모델이 Semi-Supervised object detection에도 유용하다는 것을 보여줍니다.

DetCo vs. Concurrent SSL Methods: InsLoc, DenseCL 및 PatchReID는 object detection을 위해 설계된 Pretraining 기법입니다. 이들은 object detection의 성능을 향상시켰지만 이미지 분류의 성능은 크게 감소하는 단점이 있습니다. Table 1에 표시된 바와 같이, DetCo는 이미지넷 분류에서 InsLoc, DenseCL 및 PatchReID에 비해 +6.9%, +5.0% , +4.8% 높은 성능을 보여주고 COCO detection에서도 DetCo가 이러한 방법들보다 좋은 성능을 보임을 확인할 수 있습니다.
Discussions: 위의 실험 결과를 토대로 DetCo가 가진 이점들을 살펴보면 다음과 같습니다. 먼저, DetCo는 작은 데이터셋(예: PASCAL VOC)에서 supervised learning 방법의 성능을 크게 향상시킵니다. 둘째, DetCo는 COCO 12k Iterations에서도 좋은 성능을 보여줍니다.이는 DetCo가 다른 self-supervised learning 및 supervised learning 방법과 비교하여 훈련 수렴을 빠르게 만들 수 있음을 나타냅니다. 마지막으로 충분한 데이터가 있는 경우(COCO 등), Detco는 다른 self-supervised learning 및 supervised learning 대비 성능을 크게 향상시킵니다.
4.2. Image Classification

저자는 Image Classification에 대한 실험도 진행합니다. 선형 분류기로는 ImageNet 선형 분류와 VOC SVM 분류를 따릅니다. Table 10을 확인해보면 DetCo는 Top-1 정확도에서 MoCo v2보다 +1.1% 높은 성능을 보입니다. 또한 저자는 VOC SVM 분류 정확도에서도 sota 모델과 비교했을때 어느정도 경쟁력을 갖추고 있다고 말하고 있습니다. 이 실험에서 저자가 말하고 싶은 부분은 DetCo는 object detection을 위해 설계되었지만 분류 정확도에서도 경쟁력을 갖추고 있기에 classification-detection trade off 관계에서 좋은 결과를 보여준다고 말하고 있습니다.
4.4. Visualization Results

Figure 4는 DetCo와 MoCo v2의 attention 맵을 시각화합니다. 이미지에 두 개 이상의 객체가 있는 경우, DetCo는 모든 객체를 성공적으로 찾아내지만 MoCo v2는 일부 객체를 활성화하지 못합니다. 또한 마지막 열에서 DetCo의 attention 맵은 MoCo v2보다 정확한 모습을 볼 수 있고 DetCo의 localization 능력은 MoCo v2보다 좋기에 object detection에 더 유리하다고 볼 수 있겠습니다.
4.5. Ablation Study

Experiment Settings: 저자는 Ablation study도 진행하는데 Table 11과 12에서 “MLS”(Multi-Level Supervision), “GLC”(Global and Local Contrastive learning)의 유무에 대한 실험을 진행합니다.
Effectiveness of Multi-level Supervision: Table 11(a) 및 (b)에 표시된 바와 같이 MoCo v2에Multi-Level Supervision을 추가하는 경우, 분류 정확도가 감소하지만 검출 성능이 향상됩니다. 이는 이미지 분류에서 각 레이어가 구별되어야 하는 필요가 없으며, 최종 레이어 피쳐만 구별되어야 하기 때문에 나온 결과라고 해석할 수 있습니다.
Effectiveness of Global and Local Contrastive Learning: Table 11(a) 및 (c)에 표시된 바와 같이 Global and Local Contrastive learning만 추가하는 경우, 분류 및 검출 성능이 향상되어 MoCo v2의 성능을 능가합니다. 또한 Table 11(d)에 표시된 바와 같이 GLC는 검출 및 분류 정확도를 더욱 향상시킵니다. Table 12(a), (c) 및 (d)에서 GLC는 서로 다른 스테이지의 구별 능력도 향상시킬 수 있다는 것을 보여줍니다.
4.6. Segmentation and Pose Estimation
Multi-Person Pose Estimation : Table 7의 마지막 열은 Mask RCNN을 사용한 COCO 키포인트 검출 결과를 보여줍니다. 보시는 것처럼 DetCo는 모든 메트릭에서 다른 방법들을 능가합니다. 또한 supervised에 비해 1.4 APkp 및 1.5 APkp 75가 더 높게 나타나는 것을 확인할 수 있습니다.
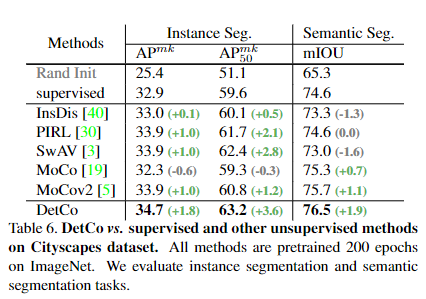
Segmentation on Cityscapes: 저자는 MoCo를 따라 Mask RCNN을 사용하여 instance segmentation에 대한 성능도 평가합니다. 결과는 Table 6에 나와있습니. DetCo 사전 훈련은 COCO와는 완전히 다른 도메인임에도 불구하고 transfer performance가 높게 나오는 것을 확인할 수 있습니다.
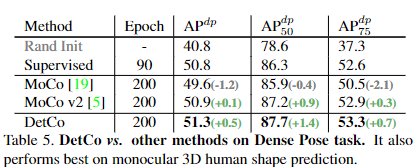
DensePose : 저자는 DetCo를 통해 DensePose task에서도 평가를 진행합니다. DetCo가 이 작업에도 잘 transfer되는 것을 발견했고 Table 5에 표시된 것처럼, DetCo는 모든 메트릭에서 ImageNet 감독 방법과 MoCo v2보다 큰 성능을 보여줍니다.
5. Conclusion and Future work
DetCo는 large-scale unlabeled data를 활용하여 다양한 downstream task에 pretrain model을 제공할 수 있고 MoCo v2 기본 성능의 장점을 유지하면서 (1) multi-level supervision (2) global and local contrastive learning을 추가함으로써 MoCo v2를 뛰어넘습니다. Detco는 이 두 가지 디자인을 통해 각 feature pyramid에서 global하고 local한 표현을 학습 Detection 및 Classification의 성능을 개선합니다.
안녕하세요 .좋은 리뷰 감사합니다.
실험 부분에서 detection외에 segmentation, pose estimation 등의 task에서 DetCo의 성능을 평가하였다구 언급되어 있는데, table에는 object detection 및 classification에 대한 실험테이블만 있는 것 같아서요 . . .
논문에 segmentation이나 pose estimation 실험 table이 없는걸까요 ?!?!? 잇다면 이에 대해 간단히 설명부탁드립니다.
감사합니다.
안녕하세요 윤서님 좋은 질문 감사합니다.
segmentation, pose estimation 실험 부분이 누락되어있어서 수정했습니다.
이 실험을 통해 저자가 제안한 Detco가 다른 도메인, task에 transfer 시켜도 performance가 높게 나오는 것을 확인할 수 있습니다.
감사합니다.
안녕하세요 정의철 연구원님 좋은 리뷰 감사합니다.
우선 리뷰 제목에 말머리로 해당 논문의 출처 (학회 연도) 를 적어주시면 좋을 것 같습니다!
가장 먼저, 문제정의에서부터 의문점이 하나 생겼는데..
SSL로 학습한 뒤, detection과 classification 둘 다 성능 향상을 가져온 것이 없다는 것이 문제인 것 같습니다.
그런데 다른 downstream 끼리의 비교는 없을까요? classification에서 성능 드랍이 발생하는게 큰 문제인가 라는 의문점이 들어서요.. 만일 detection&Seg 도 떨어지고, 또 다른 조합에서도 성능 드랍이 일어난다면, 궁극의 파라미터를 찾자 라는 SSL 목표에서 멀어지는 거라 이해가 되는데.. 단순히 detection & classification 조합의 성능 드랍이 문제라는 것이 이해가 안가네요.. 혹시 detection에서는 성능이 좋은데 classfication에서는 성능이 안좋은게 추후 어떤 영향까지 발생할까요?
두번째로 4.5. Ablation Study에서 Table11, 12의 평가지표인 Top1, Top5, 그리고 Res1… 는 무엇을 의미하나요? 그리고 MLS만 추가햇을 때, 데이터셋마다 다소 성능이 떨어지는 결과를 보이는것 같은데, 이에 대해 저자는 무엇이라고 언급하는게 있나요? 없다면 의철님은 왜 때문이라고 생각하시나요?
안녕하세요 주영님 좋은 질문 감사합니다.
1. 본 논문에서 detection와 classification을 계속 엮어서 문제 정의를 하고 전개를 해 나아가는데 이 둘의 조합으로 성능을 따지는 이유는 detection을 위해서 classification과 localization를 모두 고려해서 진행되기 때문인 것 같습니다. pretext task를 통해서 학습시킨 모델을 detection이나 classification에 적용시켰을때 둘 중 하나에서만 좋은 성능을 보인다면 이는 classification은 잘되지만 localization이 잘 안되거나 그 반대로 인한 결과라고 생각이됩니다.
주영님이 말씀하신 것처럼 SSL 목표를 생각해 봤을 때 detection에서 성능이 좋다면 classification에 대한 성능도 좋아야 classification과 localization을 모두 고려한 representation이 학습된걸로 해석할 수 있지않을까 싶습니다.
2. Top-1 Accuracy는 모델이 예측한 가장 높은 확률을 가진 클래스가 실제로 정확한 클래스인 경우를
Top-5 Accuracy는 모델이 예측한 상위 5개의 확률을 가진 클래스 중에 실제 정확한 클래스가 포함되어 있는 경우를 의미합니다 res1…은 backbone ResNet-50에서 stage 별로 나온 Feature를 의미합니다.
Multi-Level Supervision을 추가하는 경우, 분류 정확도가 감소하는데 이는 이미지 분류에서 각 레이어가 구별되어야 하는 필요가 없으며, 최종 레이어 피쳐만 구별되어야 하기 때문에 나온 결과라고 저자는 말하고 있습니다.
감사합니다.