제가 이번에 리뷰할 논문도 Object Pose Estimation에서의 Novel object 에 대한 연구입니다. 지난번에 리뷰한 Template Pose 논문의 저자가 CVPR 2024에 발표한 논문으로, CAD 모델을 사용하지 않고, 단일 reference 이미지만을 이용해 3D pose(rotation 예측)를 추정할 수 있다는 것에 contribution이 인정된 것으로 보입니다.
Abstract
객체의 pose estimation 본 논방법론들은 새로운 객체에 대한 사전 지식과 학습이 필요하다는 한계로 인해 실용적인 한계가 있었고, 최근 이를 해결하기 위한 연구가 진행중입니다. 해당 논문에서는 새로운 3D 모델에 대한 사전 지식이나 재학습 없이 단일 이미지만을 입력으로 사용하여 새로운 객체에 대한 상대적 pose(reference와의 Pose 차이를 예측하기 때문에 상대적 pose입니다)를 예측합니다. 이를 위해 저자들은 객체의 주변 viewpoint에 대해 discriminative한 embedding을 예측하도록 모델을 학습하였으며, SOTA 방법론과 비교하여 정확성과 견고성 측면에서 더 우수함을 실험적으로 보입니다.
Introduction
객체의 pose 추정은 해당 분야의 연구를 통해 성능과 occlusion등에 대한 강인성이 상당히 개선되었습니다. 또한, Domain Randomization이나 Self-supervised 방식에 대한 연구 등을 통해 label 정보가 있는 실제 데이터에 대한 의존도 상당히 완화되었습니다. 그러나 기존의 객체의 pose 추정을 위해 3D 모델이 필요하며, 학습을 위한 sequence나 다양한 view에서 촬영된 이미지가 필요하며 학습이 요구된다는 점에서 실제로 응용에 한계가 있습니다. 기존의 새로운 객체(novel object,학습을 하지 않은 처음 보는 객체)에 대응하기 위한 연구들은 학습 시 유사한 특징을 가진 객체가 포함되거나, 눈에 띄는 특징이 있다는 가정을 통해 재학습 과정 없이도 pose를 추정하는 연구를 수행하였습니다.
본 논문에서는 Novel Object Pose Estimation(NOPE)라는 새로운 방식을 제안하여, 새로운 객체에 대한 단일 이미지만을 이용하여 새로운 객체에 대한 재학습 과정 없이 상대적인 pose를 추정하고자 하였습니다. 이러한 방식은 기존의 multi-view와의 비교를 통해 pose를 추정하는 연구보다 더 어려운 세팅입니다. NOPE는 새로운 view에서의 영상을 합성하는 연구를 기반으로 하지만 두가지 차이점이 존재합니다. 먼저, 이미지를 예측하는 대신 view의 차이에 대한 embedding을 예측한다는 차이점이 있습니다. 이러한 embedding은 U-Net 구조의 네트워크에서 attention과 새로운 view에 대해 원하는 pose로 조건화되어 추출됩니다.
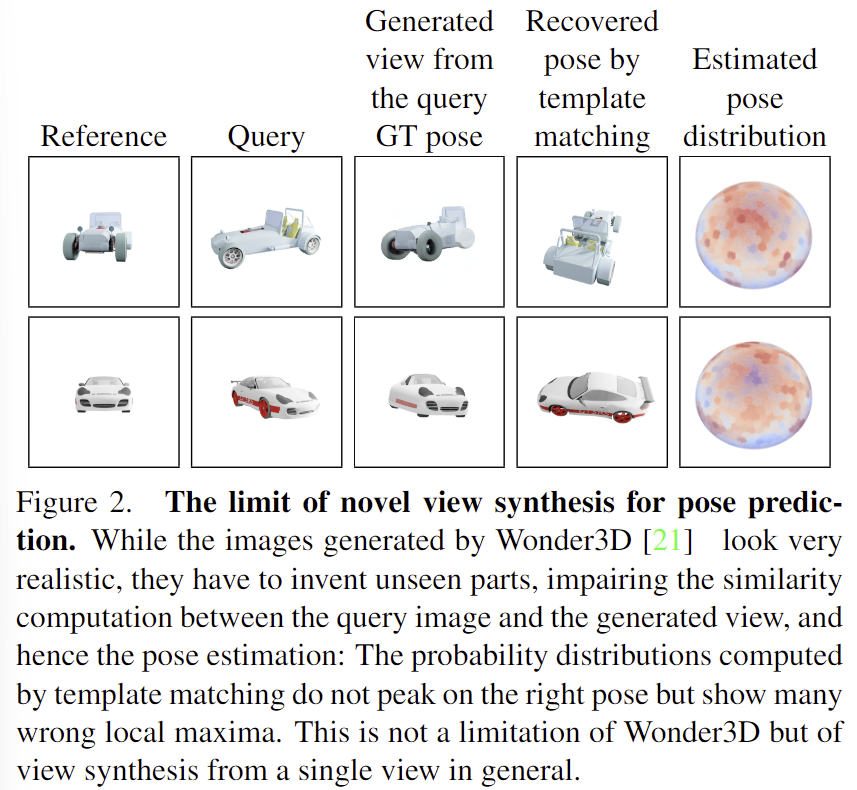
또한, 기존의 새로운 view에 대한 영상 합성은 일반적으로 하나의 이미지를 생성하고자 하지만 일부 보이지 않는 부분에 대해서는 영상을 만들어내야 하므로 생성된 영역으로 인해 잘못된 pose를 예측하게 된다는 문제가 있습니다. 위의 [Figure 2]에서 확인할 수 있듯이, 그럴듯한 이미지가 생성되지만(3열), query와는 차이가 있어 정확한 pose 추정이 어렵습니다. (5열은 예측되는 pose에 분포로, 예측된 pose의 분포가 적절한 곳에 밀집되어있지 않다는 것을 의미합니다.) 이러한 모호성을 해결하고자 NOPE는 가능한 모든 형태의 평균을 예측한 뒤 예측의 평균을 template으로 취급합니다. 이를 통해 새로운 view에 대한 모호성을 처리하고, template matching을 통해 빠르고 occlusion에도 강인하게 pose이 가능하다고 합니다. 또한, 3D 모델을 이용하지 않고, 단일 view만을 이용하여도 대칭에 의한 모호성에 대응이 가능하다고 합니다. 아래의 [Figure 1]은 이에 대한 예시로, pose를 보다 명확하게 예측하며, 대칭인 객체에 대해서도 대응이 가능하다는 것을 보여줍니다.

contribution을 정리하면, 단일 view 이미지만을 reference로 이용하여 새로운 view에서 학습하지 않은 객체에 대한 상대적 pose를 효율적이고 안정적으로 구할 수 있으며, 이는 단일 view만을 이용하여 대칭이나 occlusion에 의한 모호성을 예측하는 최초의 방법론이라고 저자들은 주장합니다.
Method
1. Formalizatin
대상 물체에 대에 reference 이미지 I_r와 query 이미지 I_q가 주어졌을 때, I_r과 I_q 사이의 상대적 pose \Delta R일 확률 p(\Delta R | I_r, I_q)을 구하는 것이 목표입니다. 이러한 확률이 임베딩 공간에서 정규분포를 따른다고 가정하며 아래의 식(1)로 정의합니다.
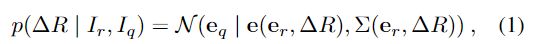
- \mathbb{e}_q, \mathbb{e}_r: query이미지와 reference 이미지의 embedding을 의미
- \mathbb{e}(\mathbb{e}_r,\Delta R): 정규분포의 평균
- \Sigma (\mathbb{e}_r, \Delta R): 정규분포의 공분산
이처럼 확률로 처리함으로써 이미지가 주어졌을 때 시점 \Delta R에서 다양한 모습을 고려할 수 있도록 하였다고 합니다.
대상 물체의 \Delta R에서 가능한 3D 형태의 평균 embedding을 \mathbb{e}(\mathbb{e}_r,\Delta R)로 사용하며 아래의 식(2)로 정의합니다.
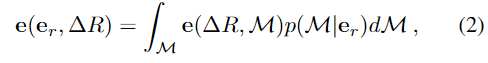
- \mathcal{M}: 대상 객체의 3D model
- \mathbb{e}(\Delta R, \mathcal{M}): 동일 객체의 \Delta R pose에서의 이미지의 embedding
이렇게 구한 평균 embedding은 L2 loss를 이용하여 간단하게 네트워크를 학습할 수 있으며 아래의 식(3)으로 정의됩니다.
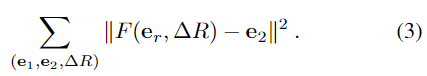
- F: 네트워크
- \mathbb{e}_1, \mathbb{e}_2: 각각 학습 view에 대한 embedding과 동일 객체의 \Delta R pose에서의 view에 대한 embedding
학습을 통해 F(\mathbb{e}_r, \Delta R)은 \mathbb{e}(\mathbb{e}_r,\Delta R)에 수렴하게 됩니다.
2. Framework
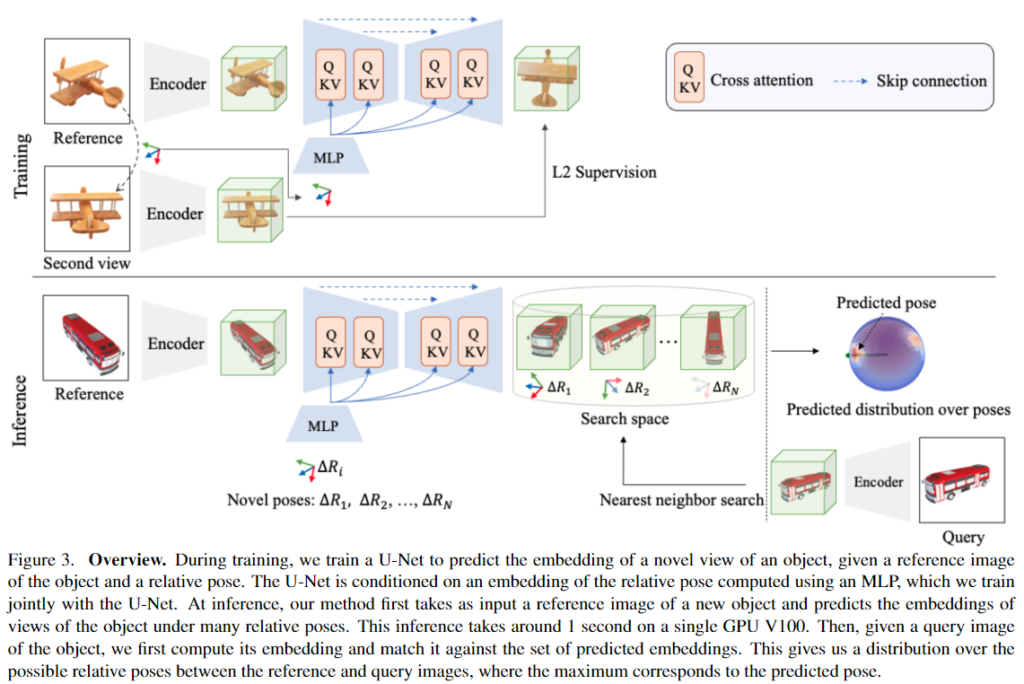
위의 [Figure 3]은 해당 방법론의 개요로, 첫번째 object 카테고리의 데이터 셋에서 객체 이미지 쌍과 해당 pose 변화를 사용하여 객체의 새로운 view에서의 평균 embedding을 예측하는 네트워크를 학습시킵니다. 이때 기존 연구를 통해 template matching에서 강인하게 작동하는 것으로 알려진 VAE 사전학습모델**을 이용하여 embedding을 계산하였다고 합니다. 먼저 MLP를 통해 reference view의 embeding을 \Delta R pose의 embedding으로 변환합니다. 그 다음 cross-attention을 이용한 U-Net 구조를 통해 \Delta R pose의 embedding을 feature map에 제공합니다.
** Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj´orn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. In CVPR, 2022
매 iteration마다 N쌍의 reference 이미지와 상대적 pose를 알고 있는 동일 객체에 대한 또 다른 이미지(query로 사용)로 배치를 구축하고, U-Net은 reference 이미지의 embedding을 입력으로, 상대 pose의 embedding을 condition으로 사용하여 두번째 이미지의 embedding을 예측합니다. 이렇게 예측된 embedding과 query 이미지의 embedding 사이의 유클리드 distnace가 최소화 되도록 U-Net 구조와 MLP를 함께 학습합니다. 이때 VAE 네트워크의 사전학습된 파라미터를 이용하는 encoder는 freeze한다고 합니다.
다양한 object에 대하여 학습을 진행하고, 이를 통해 네트워크는 특정 object에 한정되지 않고 새로운 object에도 적용 가능하도록 일반화됩니다. 이때 저자들은 대칭과 관련하여 별다른 정보를 제공하지 않지만, test 과정에서 대칭에 의해 발생하는 pose의 모호성을 고려할 수 있었다고 합니다. (관련 내용은 다음 파트인 3. pose prediction에서 더 설명합니다.)
3. Pose prediction
[Template matching]
앞선 과정을 통해 새로운 view에 대한 embedding을 생성할 수 있습니다. I_r과 N개의 상대적 pose를 가지는 viewpoint \mathcal{P}=(\Delta R_1, \Delta R_2, ... , \Delta R_N)이 주어졌을 때 각각에 대응되는 예측 embeddings (\mathbb{e}_1, \mathbb{e}_2, ..., \mathbb{e}_N)을 생성하게 됩니다. 이때 viewpionts는 정이십면체에서 각 삼각형을 4개의 작은 삼각형으로 세분화하는 과정을 2번 반복하여 총 342개의 viewpoints를 생성하였다고 합니다. 마지막으로 N개의 embedding에 대한 Nearest Neighbor search를 이용하여 가장 가까운 embedding을 찾는 방식으로 template matching을 수행합니다.
[Detecting Pose ambiguities]
유의미한 부분에 occlusion이 발생하거나 대칭에 의해 pose에 대한 모호성이 발생하는 경우 query 이미지의 embedding과 생성된 embedding 사이의 distance를 통해 단일 pose를 예측할 수 있을 뿐만 아니라 reference view와 query view에 대한 가능한 모든 pose를 인식할 수 있습니다. 이는 앞서 문제 정의에서 설명한 대로 확률 분포를 사용하기 때문으로, 아래의 [Figure 4]를 이용하여 설명합니다.
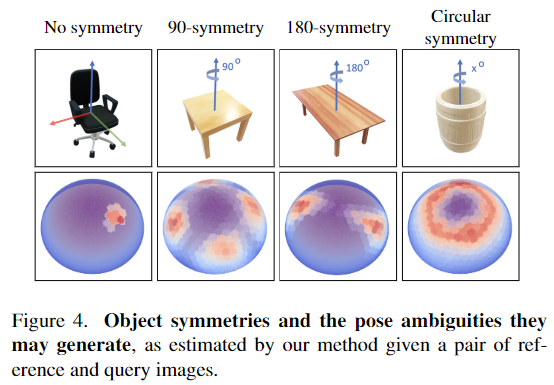
[Figure 4]는 서로 다른 3가지 대칭적인 형태를 가지는 객체에 대하여 reference 와 본 적 없는 query view에 대한 pose 분포를 시각화 한 것으로, 유사성 점수가 높은 영역의 개수가 object의 대칭으로 인해 발생하는 모호한 부분의 수와 일치하는 것을 볼 수 있습니다. 대칭이 아닌 객체는 한 영역에 집중되는 예측이 가능함을 확인할 수 있으며, 90°와 180°, 축에 대해 모두 대칭인 경우 각각 대칭되는 영역에 대응되는 view에 유사도 점수가 높은 것을 확인할 수 있습니다. (높은 확률을 가지는 pose가 대칭을 모델링할 수 있다는 점이 굉장히 인상깊었습니다 ㅎㅎ)
Experiments
1. Experimental Setup
저자들에 따르면 학습 과정에 보지 않은 카테고리의 object에 대하여 단일 이미지로 pose를 추정하는 첫번째 연구라고 하며, 평가 방식에 대하여 새롭게 정의합니다.
Synthetic dataset
FORGE**라는 기존의 합성 데이터 생성 방식을 이용하여 합성 데이터를 생성합니다. ShapeNet을 이용하여 합성 데이터 셋을 생성합니다. 학습을 위해 13개 카테고리(airplane, bench, cabinet, car, chair, display, lamp, loudspeaker, rifle, sofa, table, telephone, vessel)에서 각각 무작위로 1,000개의 인스턴스를 선택하여 총 13,000개의 인스턴스를 선택합니다. 이후 평가를 위해 두가지의 test set을 구축합니다. 첫 번째 test set은 학습 카테고리에 대한 50개의 새로운 인스턴스를 이용하여 “novel instances” set을 구성합니다. 두 번째 test set은 학습에 사용하지 않은 10개의 unseen 카테고리(bus, guitar, clock, bottle, train, mug, washer, skateboard, dishwasher, and pistol)에 대하여 각각 100개의 인스턴스를 이용하여 “novel category” set을 구성합니다. 각 3D 모델에 대해 카메라 pose를 무작위로 선택하여 5개의 reference 이미지와 5개의 query 이미지를 생성합니다.
** Hanwen Jiang, Zhenyu Jiang, Kristen Grauman, and Yuke Zhu. Few-View Object Reconstruction with Unknown Cate- gories and Camera Poses. In 3DV, 2022

Real-world dataset
기존 연구의 평가 프로토콜을 따라 T-LESS 데이터를 이용합니다. 1-18번 class를 이용하여 학습하고 전체 카테고리에 대한 평가를 진행합니다. inference 과정에서 occlusion이 발생하지 않는 모든 view나 정면 view(-45°~45°)로 reference 이미지를 무작위로 샘플링합니다.
Metrics
- 합성 데이터(ShapeNet)에 대한 평가를 위해 상대 pose의 오차를 기반으로 2가지 평가지표를 이용합니다. 먼저 Acc30은 pose 오차가 30° 이하일 경우 올바른 pose 예측으로 판단하여 accuracy를 측정하며, 예측된 pose중 distance가 가까운 상위 3개나 5개에 대한 결과를 리포팅합니다.
- real 데이터(T-LESS)에 대한 평가를 위해 10% 이상의 영역이 보이고 20 mm 이내의 오차를 가지는 Visible Surface Discrepancy(VSD error)에 대한 recall 평가지표를 이용합니다.
Baselines
저자들은 단일 view에서 pose를 예측하는 이전 방법론들과 비교를 수행합니다.
- PIZZA: 상대 pose에 대해 직접적으로 regression을 수행하는 방식
- SSVE/ViewNet: semi/self-supervised 방식으로 viewpoint 추정 뿐만 아니라 conditional하게 해당 뷰에 대한 이미지를 생성하는 방식
- 3DiM: pixel수준의 합성 view를 생성하는 diffusion기반의 최신 방법론.(해당 방법론은 view에 대한 영상을 생성하는 것으로 pose를 추정하는 방법론이 아니므로 template을 생성하여 nearest neighbor search를 이용하여 pose를 구하는 과정을 추가)
2. Comparison with SOTA
Results on ShapeNet(Synthetic data)
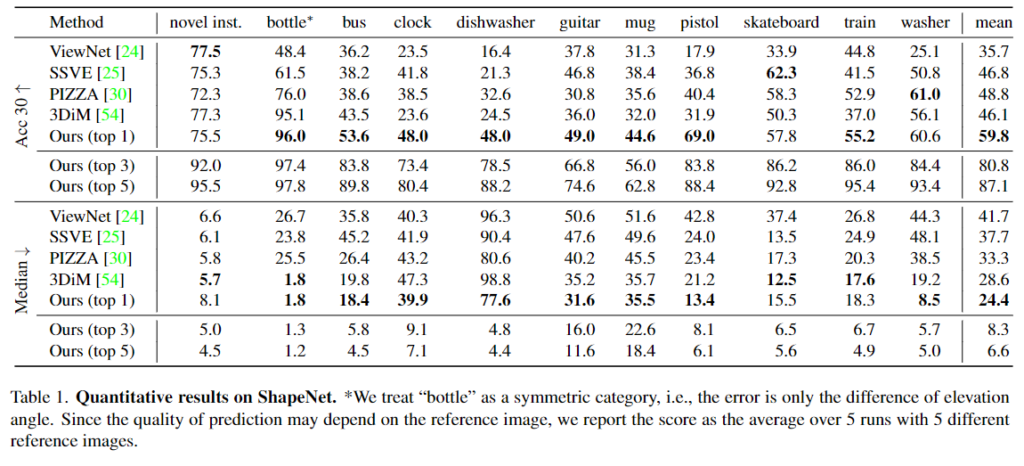
- Table1은 베이스라인과의 성능을 비교한 것으로 평균적으로 Acc30에서 10% 이상, Median에서 10° 이상 성능이 개선되는 것을 확인할 수 있습니다.
- 특히 unseen category에 대한 실험 결과(10개의 class에 대한 결과)를 통해 일반화 성능이 크게 개선되었음을 확인할 수 있습니다.
Results on T-LESS(Real-world data)
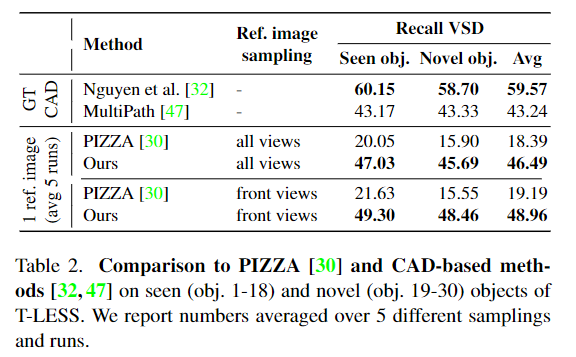
- Table 2는 T-LESS 데이터에 대한 실험 결과로, CAD 모델을 이용하는 두가지 방법론과의 비교도 함께 리포팅 되어있습니다.
- 베이스라인 방법론과의 성능 비교 결과 상당한 개선이 이루어졌지만, 여전히 CAD 모델을 이용하는 방식에 비해 성능이 떨어지는 것을 확인할 수 있습니다.
3. Robustness to Occlusion
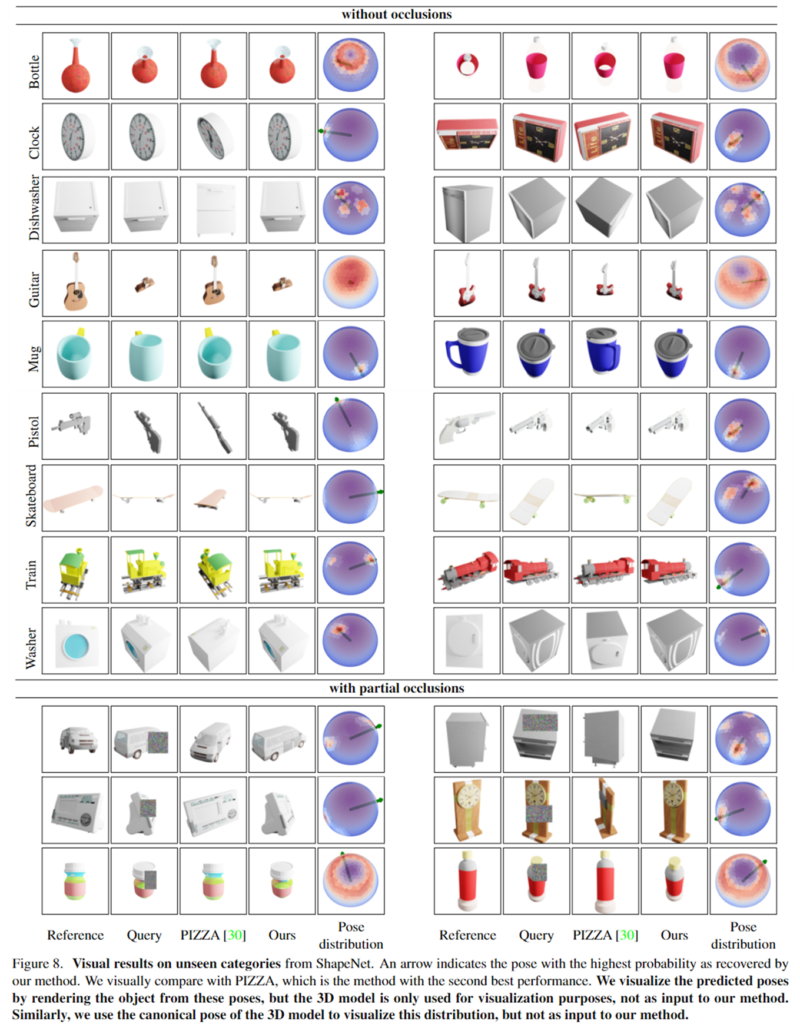
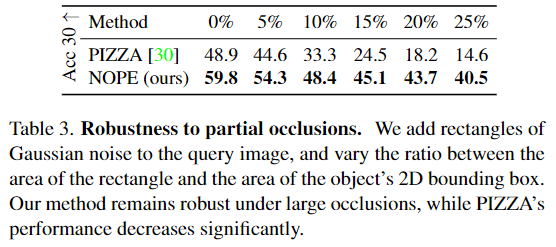
- occlusion에 대한 강인성을 평가하기 위해 객체에 대한 bounding box의 0~25%가 가려지도록 Random Erasing을 적용하여 이미지의 일부를 가우시안 노이즈로 변경하였습니다. [Figure 1]의 mug와 [Figure 8]의 아래 결과를 통해 정성적 결과를 확인할 수 있습니다.
- Table 3는 앞선 실험을 통해 베이스라인 중 좋은 성능을 보인 PIZZA와 occlusion에서의 성능을 비교한 것입니다.
- 정량적 결과를 통해 베이스라인 방법론보다 embedding 값에 대한 예측 시 occlusion 영역이 증가하더라도 더 강인하게 작동할 수 있음을 확인하였으며, [Figure 8]의 결과를 통해 occlusion상황에서 올바른 영역에서 pose의 확률이 높은 것을 확인할 수 있으며, 대칭에도 잘 작동함을 확인합니다.
4. Runtime analysis

- 앞서 빠른 추론이 가능하다고 언급한 것에 대한 실험적 결과입니다. diffusion 방법론과 다르게 새로운 view에 대한 embedding을 한번에 예측하는 방식을 통해 훨씬 빠르게 동작하였다고 합니다.(그런데 PIZZA 방식이나 다른 방법론에 대한 평가 결과가 누락되어있어서 .. 아쉽습니다.)
5. Failure cases
- Table 1에 대한 오차에 대한 Median 성능을 보면 clock, dishwasher, guitar, mug에서 높은 오차가 발생하며, 이에 대한 정성적 결과를 [Figure 7]에서 확인할 경우 guitar를 제외한 나머지 객체들이 대칭적인 형태임을 확인할 수 있습니다.
- 이에 대해 top-3나 top-5에 대한 예측을 이용할 경우 90°나 180° 대칭인 객체들은 오류가 크게 개선되는 것을 확인할 수 있으며, 한 축을 기준으로 대칭인 mug에 대해서는 개선이 잘 이루어지지 않았다고 합니다.
- 또한, guitar의 경우 특정 view에서 너무 얇게 보여 pose를 추정하기 어려웠다고 합니다.
와 pose를 확률 분포로 표현 가능하도록 프레임워크를 구축한 논문이라… 역시 잘하는 사람은 따라 잡을 수 없는 것 같아요…
어려운 논문이라 제가 이해를 못한 부분이 있어 질문 남깁니다.
1. 가장 핵심적인 부분을 이해를 못한 것 같아요. ‘NOPE는 가능한 모든 형태의 평균을 예측한 뒤 예측의 평균을 template으로 취급’에서 예측의 평균이 latent feature 같은데 342개의 viewpoint를 뽑아서 평균을 내는 것일까요?
2. fig 3에서 triaining 쪽의 sencond view와 reference의 아웃풋의 pose가 달라보이는데 L2 supervision을 어떻게 수행하는 것인가요?
3. NN을 통해 가장 유사한 feature를 뽑고 fine하게 처리하는 부분은 따로 언급이 없었나요?
질문 감사합니다.
저도 굉장히 심플한 프레임워크 같은데 방법론의 강점(대칭에 대하여 반영이 가능함)을 잘 입증하여 인상적이였습니다…. 질문에 대해 답변드리겠습니다.
1. 이해하신 바가 맞는 것 같습니다. 코드를 살펴보았을 때 배치에 대한 sum을 수행하는 것으로 보아 하나의 reference 이미지와 그에 대응되는 N개(342개)의 template으로 해당 과정을 수행하는 것으로 보입니다.
2. 또한, 해당 이미지는 임베딩 값을 보기 좋게 어떤 pose의 embedding 인지 표현한 것으로 보입니다. 따라서 second view의 pose에 해당하는 embedding 형태가 되도록 학습하는 것으로 이해하시면 됩니다.
3. 넵. 해당 pose를 구한 뒤 refinement를 수행하는 것에 대한 언급은 따로 없었습니다. 코드상으로도 없는 것으로 확인됩니다.
안녕하세요, 좋은 리뷰 감사합니다.
다양한 template-based 방법론들이 제안되고 있네요. pose distribution이라는 걸 이용하는 게 흥미롭네요.
1. 식(3) l2 loss에서는 왜 e2만 고려하는 건가요? e1은 계산에서 사용하지 않는 이유가 있는지 궁금합니다.
2. 템플릿의 뷰포인트 개수가 342개나 사용하는데, 제가 최근에 돌려본 SAM6D에서는 42개만 사용하더라구요. 혹시 이와 관련한 내용이 있거나 뷰포인트에 따른 ablation study는 없나요?
감사합니다.
질문 감사합니다!
1. 해당 식에서 e_r이 e_1에 대응되는 것으로 보입니다. (논문에서 e_1에 대해 the embedding for a view of a training object로, e_2에 대해 the embedding for the view of the same object after pose change ΔR라고 표현합니다.)
2. 우선 저자들은 342 개수에 대하여 자신들의 이전 논문인 Template 3D(2022)를 언급하며 비슷하게 342개를 쓴다고 합니다. CAD모델을 이용하지 않기 때문에 다양한 view를 고려하기 위한 것으로 보입니다. 또한 viewpoint 개수에 대한 ablation study는 없었고, Supplementary Material도 없어서 일단은 없다고 보입니다.
안녕하십니까, 좋은 리뷰 감사합니다.
학습 때 한 번도 보지 못한 물체에 대해서도 instance-level로 추가적인 depth나 3D 정보 없이 자세를 추정하는 방법론 두 가지를 소개해주신 것으로 이해하였습니다.
1. 결국에는 단일 이미지만을 사용할 때 NOPE이 성능을 개선할 수 있었던 이유는 객체 주변의 viewpoint에 대한 embedding을 함께 고려했기 때문으로 이해하였는데, 여기서 주변의 viewpoint라는 것이 무엇을 의미하나요?
2. 또한 수식 (1)에서 가우시안 분포일 것으로 가정하는 것이 특정 이미지의 다양한 view를 고려하게 되는 것과 어떤 관련이 있는지 궁금합니다.
3. 마지막으로 NOPE의 Framework를 보니 Inference 과정에선 N개의 고정된 view 중 하나로만 예측하는 것으로 이해하였는데, 이 N이 무수히 많은 숫자인 것인가요? 굉장히 detail하게 회귀 방식으로 자세 parameter들을 추정해야 할 것 같은데 이 N이 어느정도의 범위를 갖는 것인지 궁금합니다.
4. 3번 질문과 이어져 모델의 출력이 어떤 형태인지와 평가는 어떻게 진행되는지 궁금합니다. 평가지표에 Acc이 있던데, annotation이 애초에 30도, 60도, 90도 이런 식으로 정해져있고 분류를 하는 task인 것인가요?
질문 감사합니다.
1. 혼선을 드린 것 같아 표현을 정정하자면, 주변 view라기 보다도 전체적인 view를 고려할 수 있다고 표현하는 것이 좋을 것 같습니다. 조금 더 자세한 정보는 Template matching 과정에 대한 설명으로, viewpionts는 정이십면체에서 각 삼각형을 4개의 작은 삼각형으로 세분화하는 과정을 2번 반복하여 총 342개의 viewpoints에서 embedding을 고려하게 되고, 네트워크가 N개의 view에 대한 각각의 확률을 예측하는 방식이므로 다양한 viewpoint 정보가 함께 고려되게 됩니다.
2. 여러 view에서의 pose의 확률을 예측하도록 하였으므로 다양한 pose 정보를 고려할 수 있게 된 것이고, 이를 위한 확률을 정규분포 형태로 정의한 것으로 이해하시면 좋을 것 같습니다.
3. 1번에서 설명드린대로, 객체를 중심에 두고 정이십면체를 만든 뒤, 삼각형을 세분화하여 만든 342개의 viewpoint에 대한 예측을 수행합니다.
4. 먼저, training 과정에서는 reference를 상대 pose만큼 변화시켰을 때의 embedding값을 출력하게되며, inference 과정의 모델의 출력은 N개(해당 논문은 342개)의 view중 query와 가장 유사한 view를 찾고 그에 대한 상대 pose 정보를 이용하여 평가를 수행하게 됩니다.
또한, 두 view 사이의 상대적 pose 정보가 GT이며, reference를 기준으로 query 이미지에 대한 상대 pose 정보를 추정하여 예측된 상대 pose와 GT 상대 pose 사이의 오차를 구하는 것 입니다. 이 오차가 30° 이하일 경우 정답으로 판단하는 것 입니다.