이번에 소개드릴 논문은 DINOv2라는 논문입니다. Self-supervised Learning에서 매우 잘 알려진 Facebook AI Research의 DINOv1의 후속작으로 해당 논문도 마찬가지로 페이스북에서 공개한 논문입니다.
본 논문과 21년도 논문이었던 DINOv1의 가장 큰 차이점은, 해당 논문이 작성된 23년도 기준으로 공개된 최신 자기지도학습 방식을 잘 활용하여 더 큰 모델과 데이터 규모에서 잘 동작하는 자기지도학습 방식을 제안하는 것입니다. 그래서 약간 논문이 약간 순수 연구쪽이라기 보다는 개발쪽 성향을 더 짙게 띄고 있는 것 같습니다.
특히 저자들이 사용한 ViT-G 모델 기준 11억개의 파라미터를 1억 4천만개가 넘는 데이터로 학습시키다보니 모델 학습에 상당히 많은 시간과 비용이 들어갈 수 밖에 없는데, 이러한 부분들을 해결하기 위한 개발 구현 관점에서의 기술 스택들이 한 섹션을 장식하고 있습니다. 상당히 매력적이긴 하지만 리뷰에 제가 잘 정리해서 소개드리기까지는 그쪽 분야 지식이 좀 얕아서 궁금하신 분들은 실제 논문을 참고해주시면 좋겠습니다(대충 웃으며 눈물을 흘리는 얼굴 이모티콘)
그럼 리뷰 시작하겠습니다.
Intro
Transformer의 등장 이후 NLP에서는 GPT, BERT와 같이 테스크에 상관없이 좋은 특징을 추출하여 다운스트림 테스크의 성능을 크게 개선시킨 방법론들이 꾸준히 제안되어왔습니다. 이러한 모델들의 성공은 몇십억이 되는 파라미터 수를 지닌 모델과 이를 학습시킬 수 있는 수천~수억개의 방대한 양의 데이터 덕분이죠.
물론 이렇게 많은 데이터를 학습시키는데 있어 사람이 수작업으로 모델 학습에 필요한 레이블을 어노테이션한다는 것은 비용과 시간적 측면에서 불가능하기 때문에, 모델 스스로 입력 데이터로부터 레이블을 생성하는 자기지도학습 방식의 기술 발전도 LLM의 성공에 상당히 중요한 몫을 했습니다.
이러한 NLP 쪽 분야에서의 성공을 부러워하였는지, 비전쪽 일부 연구자들은 영상과 텍스트를 함께 활용하여 이미지 특징을 학습하는 방식을 제안하였습니다. 하지만 캡션 기반 학습 방식은 영상의 풍부한 정보를 대략적으로 근사화하였기에 복잡한 픽셀 레벨의 정보는 해당 캡션들로부터 드러나지 않아 결국 모델이 영상에 내재된 정보를 포착하는데 한계가 나타났습니다.
이러한 텍스트 가이드 방식에 대안책으로 영상 데이터만을 자기지도학습을 하는 방식들이 꾸준히 연구되었습니다. 이들은 비전 도메인에서의 Self-supervised Learning(SSL)을 공부하신 분들이라면 잘 아실법한 SIMCLR, MOCO, DINO, MAE 등등이 존재합니다.
하지만 이러한 비전쪽 SSL 연구는 아쉽게도 작은 규모의 정제 데이터 셋(ImageNet 1K)에서만 이루어진다는 단점이 존재합니다. 불과 10년전만에도 이미지넷은 상당히 방대한 크기의 데이터셋으로 알려져있지만, 딥러닝 기술 발전 (특히 SSL 분야 기술) 덕분에 백만장 수준의 데이터 규모는 거뜬히 학습시킬 수 있게 되었습니다.
그리고 물론 백만 단위에 데이터가 어떠한 목적을 수행하는데 있어 결코 적은 것은 아닙니다만, 결국 어떠한 상황에서도 정확한 추론을 수행하는 AGI에 도달하기에는 백만장이라는 데이터의 규모가 터무니없이 부족한 것도 사실입니다. 이러한 관점에서 몇몇 논문들이 이미지넷을 넘어서 SSL 연구들의 규모를 키우기 위한 시도를 했지만, 이들은 정제되지 않은 데이터 셋에서의 학습을 집중하였기 때문에 특징의 퀄리티가 상당히 떨어졌다는 문제점이 발생했습니다. 즉 좋은 특징을 생성하기 위해서는 데이터의 품질과 다양성에 대한 통제가 필수적이라는 것.
DINOv2는 이러한 연구 흐름 속에서 더 방대한 규모의 데이터와 모델을 학습시키기 위한 SSL 방법론을 제안합니다. 저자들은 기존 연구들의 문제점을 바로 잡기 위해 대용량 데이터를 수집하는 방식부터 특징 표현을 향상시키기 위해 어떻게 수집된 데이터를 효율적으로 정제할 것인지에 집중합니다.
보다 구체적으로, 저자들은 전체 영상과 패치 레벨 모두에서 특징을 학습하는 SSL 방법론인 iBOT을 기반으로 보다 더 방대한 데이터셋 관점에서 모델 설계를 재고려하였다고 합니다. 특히 데이터와 모델의 사이즈를 키울 때 SSL의 안전성과 가속성에 대하여 맞춤화된 방법론을 제안합니다. 결과적으로 제안하는 방법은 기존의 SSL 연구들과 비교해 2배 더 빠르고 3배 더 적은 메모리를 활용함으로써, 더 많은 배치 사이즈와 긴 학습을 활용할 수 있도록 한다고 하네요.
리뷰 시작 부분에서 말씀드렸다시피 본 리뷰에서는 데이터셋을 수집하고 이를 정제하는 방식, 그리고 모델을 SSL 하는 방법에 대해서만 다룰 것이며, 더 빠른 학습과 적은 메모리를 사용할 수 있었던 개발 기술 스택에 대해서는 다루지 않을 예정이니 참고부탁드립니다.
아무튼 저자들은 정제되지 않은 방대한 영상 데이터를 정제하고 균형을 새로 맞춘 데이터셋을 생성하는 자동 파이프라인을 추가로 설계하였습니다. 이는 사람의 어노테이션과 외부 메타데이터 없이 데이터 유사도 기반으로 데이터를 정제하는 NLP 분야 기술을 응용하였다고 하네요. 또한 해당 기술 구현 과정에서 정제되지 않은 데이터에 대하여 균형을 맞추기 위해 일반적인 군집화 기법을 적절히 활용하였다고 합니다. 이러한 기술적 디테일은 밑에서 설명드리도록 하겠습니다.
결과적으로 저자들이 제안하는 데이터 수집 및 정제 방식은 총 1억4천2백만개(142M)의 정제된 영상 데이터를 모을 수 있게 하였으며, 이러한 데이터로 사전학습한 모델을 평가하는데 있어 영상 분류, Segmentation, Depth Estimation, Retrieval, Video Understanding 등 다양한 Downstream task에서 철정한 검증을 보여줍니다.
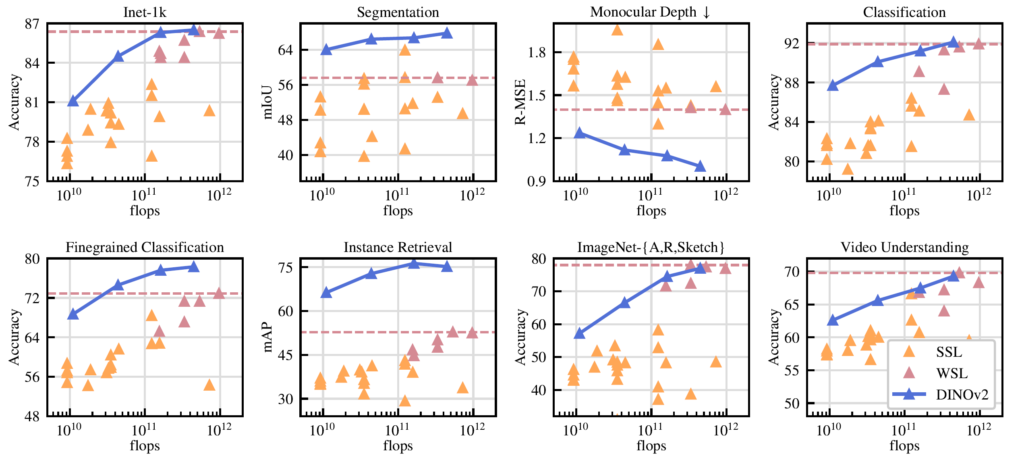
실제로 그림 1을 살펴보시면 기존의 SSL 연구들(주황색)과 Weakly-supervised 방법론들(짙은 핑크색?)과 비교하여 저자들이 제안한 DINOv2가 다양한 테스크에서 더 우수한 성능을 보여줌을 나타냅니다. 물론 모델의 규모나 학습 데이터 크기 차이로 인해 그런 것이지만 Large Vision Model을 만들기 위한 관점에서 상당한 의의가 있지 않은가 싶습니다.
Method – Processing
그러면 본격적으로 DINOv2의 방법론에 대해서 살펴보겠습니다.
먼저 학습에 사용하기 위핸 대용량 데이터를 취득하는 과정에 대해서 설명드리겠습니다. 저자들이 대용량 데이터를 취득한 방식은 크게 2단계로 구성되며 먼저 중복되는 데이터를 제거하는 단계와 정제된 데이터 샘플링 단계로 이루어져있습니다.
Data sources
우선 저자들이 SSL을 수행하는데 있어 제안한 142M 수준의 데이터 구성은 아래 표와 같습니다.
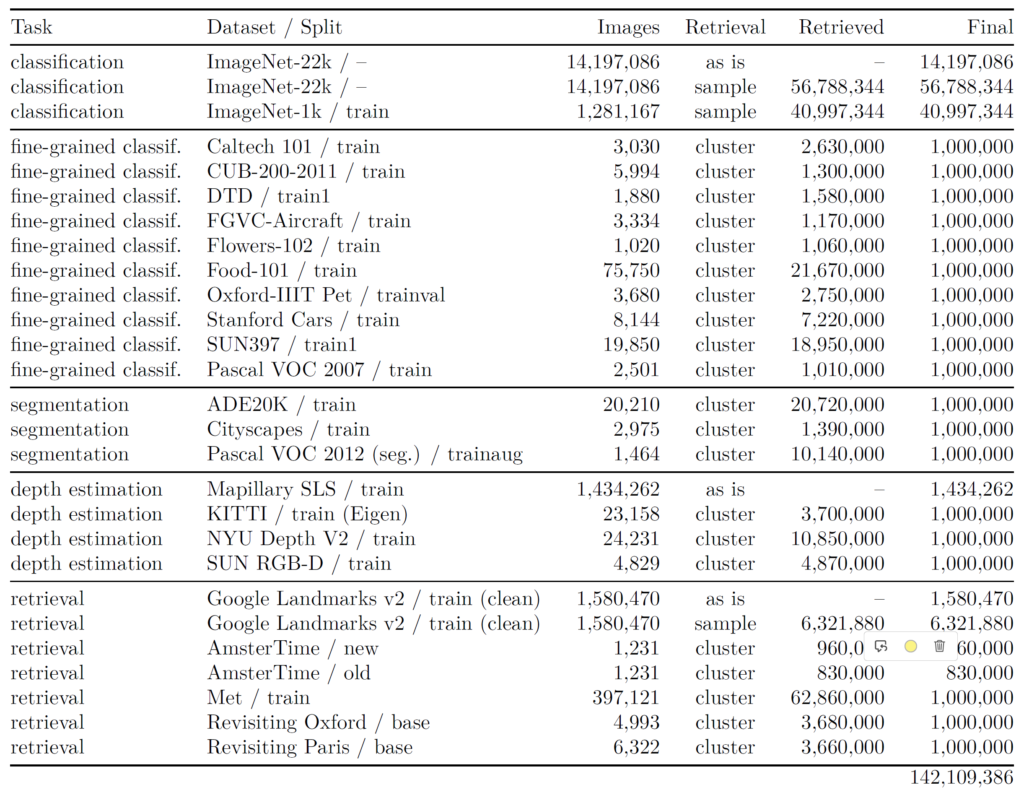
여기서 Dataset/Split 열을 살펴보시면 데이터셋의 이름이 나와있는데 상당히 낯이 익은 이름들이 존재합니다. ImageNet부터 ADE20K, Cityscape, KITTI, Google Landmarks 데이터 셋 등등 말이죠. 이들의 역할에 대해서는 데이터 정제 과정에 대해서 보다 자세하게 설명드리겠습니다. 일단은 지금 표에 있는 데이터셋들은 모두 연구를 위해 공개된 데이터셋으로 정제된 상태라고 이해주시면 됩니다.
그리고 저자들은 SSL 학습을 위해 데이터셋의 규모를 상당량 키우기 위해서 웹 상에서 공개된 데이터를 크롤링하여 정제되지 않은 데이터셋을 수집합니다. 이렇게 수직된 데이터의 양만 총 12억개라고 하네요.
Deduplication
12억장의 데이터들이 모두 특별하고 고유한 정보만을 가지고 있으면 좋겠으나, 당연하게도 12억장의 이미지들 안에는 상당량의 영상들이 서로 중복되거나 겹치는 경우가 많이 존재할 것입니다. 그래서 저자들은 22년도에 공개된 copy detection 파이프라인을 적용하여 정제되지 않거나 혹은 유사하게 중복된 영상들을 지우고 다양성을 확보합니다.
Self-supervised image retrieval
중복되는 영상들을 제거했으니 이제는 모델 학습에 사용할 데이터를 선별하는 작업을 진행해야 합니다. 저자들은 Image retrieval 방식으로 데이터 선별 작업을 수행했다고 하네요. 그렇다면 선별 작업을 통해 취득한 “좋은” 데이터의 기준은 무엇일까요? 일단 좋은 데이터의 가장 큰 기준은 해당 데이터를 SSL에 사용시 모델이 좋은 특징 표현력을 학습할 수 있도록 하는 것입니다.
인트로에서도 간단하게 소개드렸지만, ImageNet보다 더 큰 스케일의 데이터로 모델을 학습시키려는 연구들은 몇몇 있었습니다. 하지만 해당 연구들이 대용량 데이터로 학습했음에도 불구하고 좋은 성능을 달성하지 못한 이유에 대해 저자들은 정제되지 않은 데이터를 곧바로 학습에 사용했기 때문이라고 주장합니다.
따라서 저자들은 억대에 달하는 수집된 데이터에 대하여 상당수는 모델 학습을 방해하는 노이즈 데이터로 구성되어있을테니, 모델 학습에 정말로 도움을 줄 수 있을만한 데이터들을 선별하기를 원한 것이죠.
그렇다면 좋은 데이터에 대한 대략적인 기준은 알아보았는데 이를 어떻게 더 구체화해서 판별할 수 있을까요? 그것은 바로 기존에 연구 목적으로 활용되는 공공 데이터들을 잘 정제된 데이터로 판단하고 이들 데이터와 (정제되지 않은) 수집된 데이터들 간에 유사도를 기반으로 샘플링을 하는 방식을 채택합니다.
이러한 선별 과정은 크게 2가지 케이스로 나뉘게 됩니다.
- K-Nearest Neighbors Search 기반 샘플링
- K-means Clustering 기반 샘플링
첫번째 방식은 아주 단순합니다. 잘 정제된 공공 데이터셋을 Query Set이라고 하였을 때 Query Set과 대규모 미정제 데이터셋들간의 유사도를 다 계산하여 Query set과 가까운 이웃 K개를 선별하는 것입니다. 기계학습에서 KNN으로 대상을 분류하는 문제들을 한번씩은 풀어보셨을텐데 이때는 Query data 기준 주변 이웃 K개의 데이터들의 class 비율에 따라서 Query class를 지정하는 방식이라면, 지금 DINOv2의 방식은 반대로 Query 데이터를 기준으로 주변 이웃 K개가 모두 Query와 유사한 특징으로써 채택된다고 보시면 되겠습니다. (만약 분류 문제였다면 이웃 K개의 영상들이 Query와 동일한 Class로 배정된다는 의미.)
두번째 K-means Clustering 기반 샘플링 방식도 매우 단순한데, 정제되지 않은 대규모 데이터셋에 대하여 K-means Clustering을 수행한 뒤 해당 군집들과 Query set간의 유사도를 계산합니다. 그래서 만약 Query data가 어떠한 군집에 속하게 된다면 해당 군집 안에 있는 샘플들 M개를 임의로 샘플링하는 방식으로 데이터를 수집합니다.
이러한 첫번째 (KNN) 방식과 두번째 (K-means Clustering) 방식은 잘 정제된 Query 데이터셋의 규모에 따라서 결정이 되는데, 만약 Query Set이 ImageNet, Google Landmark처럼 100만장 이상의 대용량 데이터셋일 경우에는 KNN 방식으로 미정제 데이터에 대하여 선별 과정을 거치게 되며, KITTI, CITYScape와 같이 몇만~몇십만장 수준의 데이터의 경우에는 K-means Clustering 방식을 통해서 보다 충분한 양의 데이터를 선별한다고 합니다.
그리고 실제 구현 단계에서 저자들은 KNN의 경우 4의 값을 활용했으며 K-means Clustering에서의 K는 10만, 그리고 군집 내 M개의 데이터 샘플링 시에는 1만장으로 지정했다고 합니다. 또한 정제된 영상과 비정제된 영상들은 모두 ImageNet22K데이터를 자기지도 방식으로 학습한 VIT-H 모델을 통해 추출한 feature vector를 활용하였으며, 거리 추정 계산은 Cosine Similarity를 사용했다고 합니다.
결과적으로 저자들의 데이터 수집 및 선별 과정을 정리하면 아래 그림과 같겠네요.
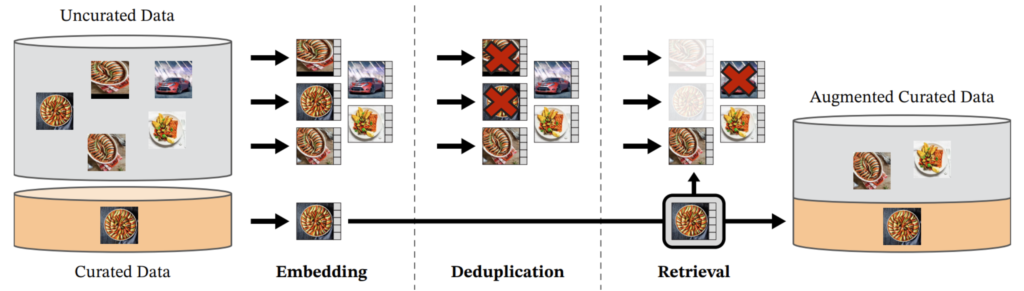
영상 데이터들을 특징 공간으로 임베딩하고, copy detection으로 중복을 제거하며, (정제된 쿼리 데이터셋의 규모에 따라 KNN or K-means 기반) Retrieval 과정을 통해 모델 학습에 도움을 줄법한 데이터만을 선정하는 것입니다.
Discriminative Self-supervised Pretraining
이렇게 데이터 선별 과정이 모두 마무리 되었으니, 이제 모델을 학습하는 방식에 대해서 간략하게 다뤄보겠습니다. 저자들은 우선 iBOT이라고 하는 논문을 베이스라인으로 삼았습니다. iBOT은 또 DINOv1과 Beit라는 논문의 컨셉을 결합하여 개선한 논문인데, 일단 Beit에 대해서 먼저 간단하게 설명드리겠습니다.
Beit는 BERT 방식으로 Image backbone을 사전학습하는 방식을 의미합니다. 사실 비전 도메인에서는 He 교수님이 22년도에 제안하신 Masekd Auto Encoder(MAE)를 더 잘 아실 수도 있겠습니다만, MAE 이전에 BERT와 유사한 pretext task를 설정하여 비전 쪽 사전학습을 연구한 연구로 BeiT가 존재합니다.
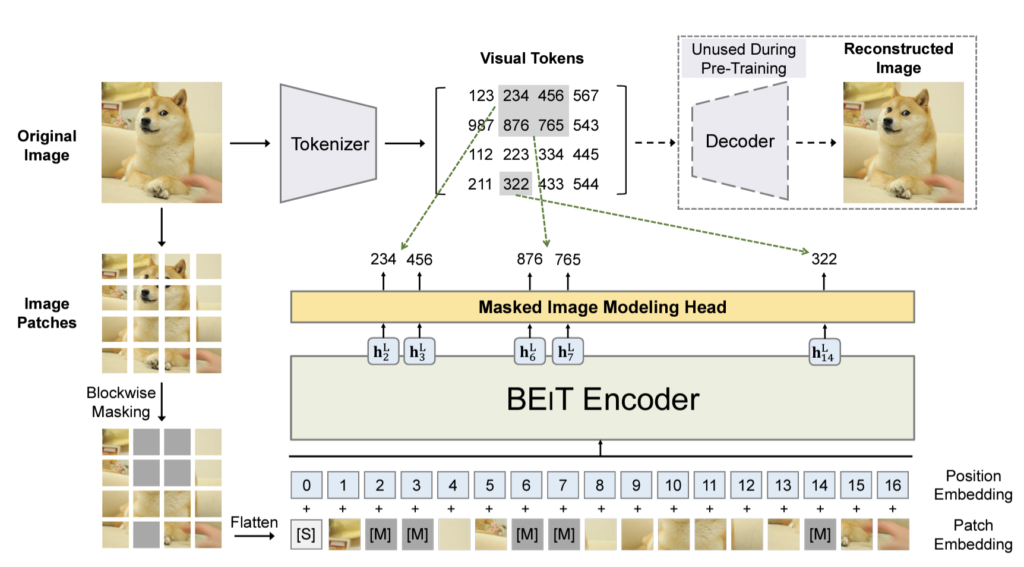
Beit는 BERT의 컨셉을 비전 도메인에 그대로 옮기는 것이기 때문에 상당히 직관적입니다. 영상에 대하여 패치로 쪼개고, 해당 패치에 마스킹을 덧씌운 뒤, Vision Transformer 인코더에 태워서 특징을 추출한 뒤, Masked Image Modeling head를 통해 마스킹된 패치를 복원하면 되는 것입니다.
여기서 흔히 잘 알려진 MAE 연구의 경우 AutoEncoder에서 그랬듯이 입력으로 RGB 영상을 넣고 복원 과정도 입력에 사용된 RGB 영상을 추론하는 것이라면, Beit는 사전학습된 DALLE의 Tokenizer를 통하여 token 값을 복원하는 방식을 적용했습니다. 이러한 방식은 즉 BeiT 인코더가 DALLE의 Knowledge를 Distillation 하고 있다고 봐도 무방합니다.
IBOT이라는 논문은 이러한 Beit 방식이 결국 DALLE와 같이 사전 학습된 Tokenizer가 필요하다는 것을 문제로 지적합니다. 결국 저희가 원하는 것은 Label 없이 잘 사전학습된 백본을 하나 만드는 것인데, 해당 모델을 만들기 위해서 또 Tokenizer를 사전학습해야하는 상황을 문제로 삼은 것이죠. 즉 IBot 저자들은 End-to-End 방식으로 한번의 모델을 학습시키고자 하였으며 이를 위해 DINOv1의 학습 방식을 참고합니다.
DINOv1은 매우 그 방식이 단순합니다. DINOv1은 영상 레벨 (즉 Global feature)에 대하여 학습하는 방식으로 학생 모델과 선생 모델 각각이 추론한 ViT의 class token 간에 Cross-entropy loss를 계산하는 방식으로 학습이 되죠. 이때 선생 모델은 학생 모델의 가중치를 EMA 방식으로 재갱신한 모델입니다. 아까 BeiT의 Teacher model이 사전학습된 Tokenizer였다면, IBOT에서는 이러한 DINOv1의 EMA teacher 방식에 영감을 받아 Tokenizer를 EMA beiT Encoder로 대체한 것이죠.
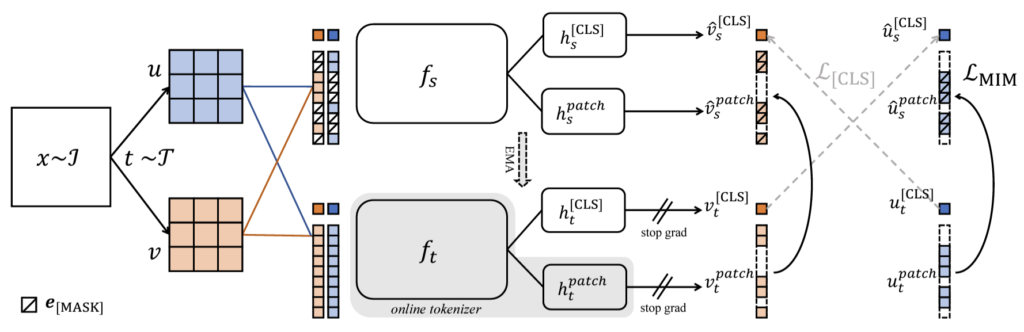
BeiT는 마스킹된 패치를 복원하는 방식이다보니 패치 단위(local feature)의 표현력을 학습시키는 방식이며, DINOv1은 Global feature를 학습시키는 방식이다보니 IBot은 이 둘을 모두 한번에 학습하는 방식을 채택했습니다. 즉 VIT의 Token들 중 CLS token은 DINOv1 처럼 CE loss로 학습시키고, 마스킹된 영역에 대해서도 Teacher model의 output과 비교하는 방식으로 학습하는 것이죠.
이러한 IBOT 방법론을 DINOv2에서는 베이스라인으로 사용합니다. 그래서 loss 함수도 크게 2가지로 Global feature를 학습하는 Image Level 쪽 loss와 Local feature를 학습하는 patch level에 대한 목적 함수가 구분되어 있습니다.
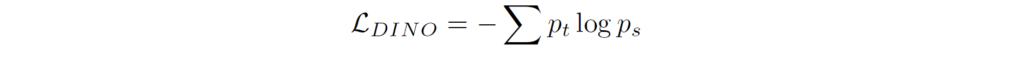
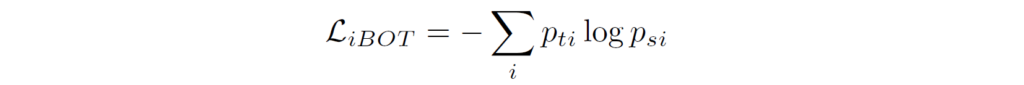
여기서 Dino loss는 global feautre에 대하여 softmax를 취한다음에 CE loss를 계산한 것이고, iBOT loss는 teacher model과 student model의 i번째 token에 대한 CE loss를 계산한 것입니다. 즉 패치 별로 CE loss를 계산한 것이죠.
Untying head weights between both objectives
그리고 그림4를 보시면 아시겠지만, Encoder에서 나온 feature에 대하여 곧바로 loss 계산을 하는 것이 아닌 MLP로 구성된 head를 태워 loss 계산을 위한 최종적인 특징들을 재가공하는 것이 SSL 연구들의 기본적인 형식입니다. iBot에서는 Dino head (cls token)와 iBOT head (masked modeling)를 수행하는 MLP를 파라미터 공유하면 더 좋은 성능을 낸다고 리포팅하였는데, DINOv2 저자들은 데이터의 스케일이 더 커지니 이 둘을 구분 짓는 것이 더 좋다라는 것을 실험적으로 확인하였다고 합니다.
KoLeo regularizer
저자들은 모델 학습 시 규제화도 하나 추가하였다고 합니다.
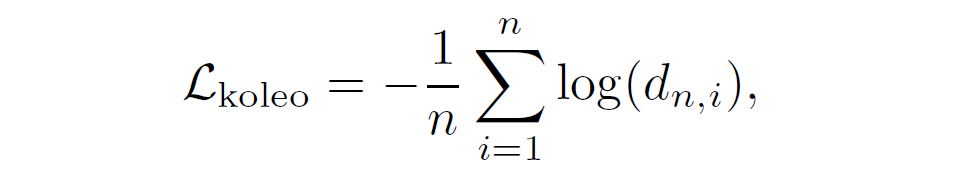
일단 loss 함수는 위와 같습니다. 여기서 d_{n, i} = min_{j != i} || x_{i} - x_{j} || 로, 요약하면 n 길이의 미니 배치 속 데이터 샘플들 간의 유사도를 측정 후 i번째 샘플과 가장 유사한 값에 대하여 log 값을 취하는 것입니다. 이는 곧 i번째 샘플과 가장 유사한 샘플은 1의 값을 가질수록 좋다는 것인데.. 이러한 규제화는 제 추측이지만 log(0)이 될 경우 무한대의 값을 가지게 되는데, 이때 0의 값이 나온다는 것은 두 특징이 완전 같다라는 의미로, dimensional collapse 현상을 막기 위함이 아닐까라는 생각이 드네요. 아니면 완전히 같지는 않으면서도 최대한 특징들이 유사할수록 군집을 이루도록 하고 싶은 것일수도 있고… 논문에서 해당 규제화를 사용하는 의도를 설명하지는 않아서 정확한 의도를 설명드리기는 힘들겠네요.
Adapting the resolution
일반적으로 고해상도의 데이터를 통해 모델을 학습시키면 모델이 더 좋은 성능을 보여줍니다. 이는 작아서 안보이는 객체가 고해상도에서는 뚜렷하게 나타나기 때문에 모델이 인식하는 측면에서 더 좋기 때문입니다. 하지만 고해상도 영상으로 학습을 처음부터 해버리면 너무 많은 시간과 메모리를 잡아먹으니, 저자들은 사전학습이 거의 끝나가는 시점에서 짧은 기간에만 고해상도로 사전학습을 수행하였다고 합니다.
Experiments
그럼 실험 섹션에 대해서 다루고 리뷰 마무리 짓도록 하겠습니다.
Ablation study
우선 ablation study 관련입니다. 아래 표는 ImageNet-22K 데이터셋에 대하여 VIT-large 모델에 대한 실험 결과입니다.
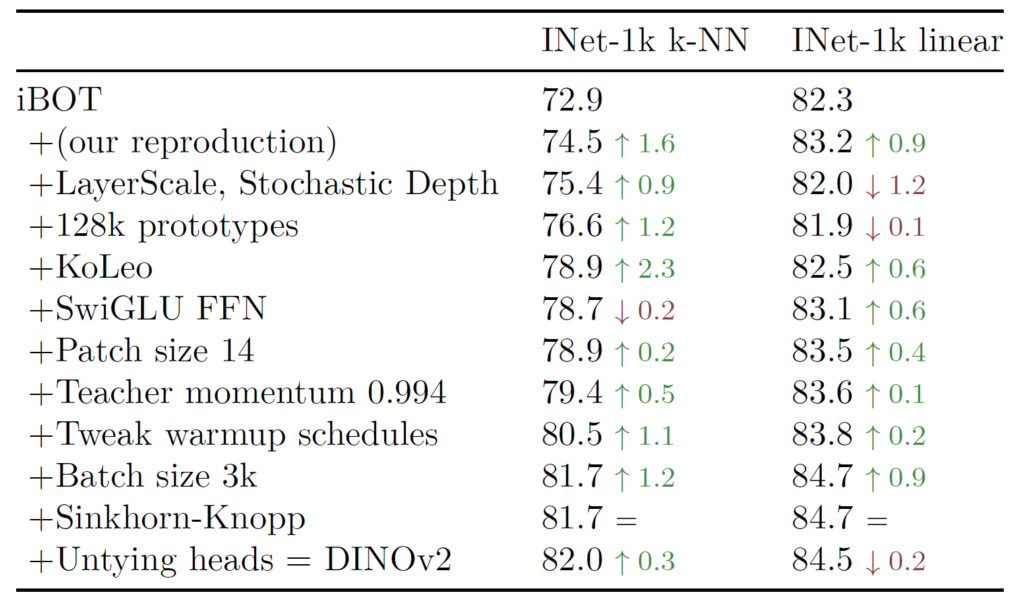
iBOT을 baseline으로 삼았을 때 저자들이 적용한 개선사항들 하나하나들에 따라서 점진적인 성능 개선이 꾸준히 일어나는 것을 확인할 수 있습니다. 물론 제가 리뷰에서 소개드리지 않은 행들도 종종 보이는데, 사실 해당 표에서는 논문에서 막 새롭게 제안한 개념들이 들어가있다기 보다는, 하이퍼파라미터 세팅이나 기존 연구들에서 좋다고 알려진 기법들을 적용한 것들이 대부분인지라, 그냥 각각의 요소들이 모델 성능에 어떠한 향상을 보이는구나 정도로 경향 파악에 초점을 두시면 좋겠습니다.

위에 표는 SSL 사전 학습을 진행할 때의 학습 데이터에 따른 downstream task의 성능을 나타낸 것입니다. 일단 위에 표에서 가장 중요한 것은, ImageNet과 같이 기존 연구들이 사용하는 정제된 데이터 셋으로 SSL 한 것이 정제되지 않은 대용량 데이터셋으로 SSL 한 것보다 대부분의 task에서 더 좋은 성능을 보여준다는 점입니다.
직관적으로 보았을 때, SSL의 가장 큰 이점은 Label이 없어도 영상만으로 모델을 학습시킬 수 있으니 데이터만 충분히 모을 수 있다면 언제든지 학습을 시킬 수 있다! 라고 생각을 하였는데 무작정 데이터만 많이 수집한다 하여도 잘 정제된 소규모 데이터셋으로 SSL 한 것보다 더 나쁜 성능을 달성할 수 있다라는 나름 의미있는 결과를 확인할 수 있습니다.
그래서 저자들이 제안한 데이터 정제 방식을 통해 새롭게 재구성한 LVD-142M 데이터셋으로 SSL을 할 경우 ImageNet-1K를 제외하고 모든 데이터셋에서 더 우수한 성능을 보여준 것을 확인할 수 있습니다. 여기서 저자들은 데이터 정제의 필요성을 더 강조하네요.
근데 조금 우려스러운 점은 사실 저자들이 데이터 정제를 수행하는데 있어 위에 Training Data 속에 표기된 데이터 셋들 중 Inet-1K, ADE-20K, Oxford-M의 경우 데이터 선별 과정에서 사용한 데이터셋이긴 합니다. 즉 평가에 사용한 데이터셋들과 유사한 데이터들을 선별해서 모델 사전학습에 사용했기 때문에 특히 더 유리한 성능을 보인 것이 아닐까..? 라는 생각이 들긴 합니다만.. 그 외에 나머지 데이터셋은 데이터 선별 과정에서 사용하지 않기도 했음에도 성능이 더 좋은 것으로 미루어보아 효과가 모델의 특징 표현을 향상시키는 관점에서 효과가 없지는 않겠구나 라는 생각도 들긴 합니다.
Model Size and Data
다음은 모델의 크기와 데이터 규모에 따른 성능 개선 정도입니다.

위에 그림을 살펴보시면 각각 ViT-Large, Huge, Giant 순으로 나열이 되어 있는데, 핵심만을 설명드리면 데이터의 사이즈가 충분하지 않으면(i.e., INet-22K) 모델의 사이즈가 아무리 커진다고 하더라도 성능 개선에 그리 도움이 되지는 않는 반면, 데이터의 용량만 충분하면 모델의 크기가 커질수록 선형적으로 성능이 개선한다는 점입니다.
Impact of Knowledge Distillation
다음 실험은 조금 재밌는 실험인데 상대적으로 사이즈가 작은 백본 모델에 대하여 스크래치로 SSL 학습을 시키는 것이 더 좋을지 아니면 이미 SSL을 한 매우 큰 모델이 있을 때 해당 모델의 지식을 Distillation하는 것이 좋은지에 대한 실험입니다.
저자들은 VIT-L 모델을 스크래치부터 학습하는 것과, ViT-G 모델로 Distillation하였을 때의 downstream task에 대한 성능 벤치마크를 아래 표를 통해 보여줍니다.
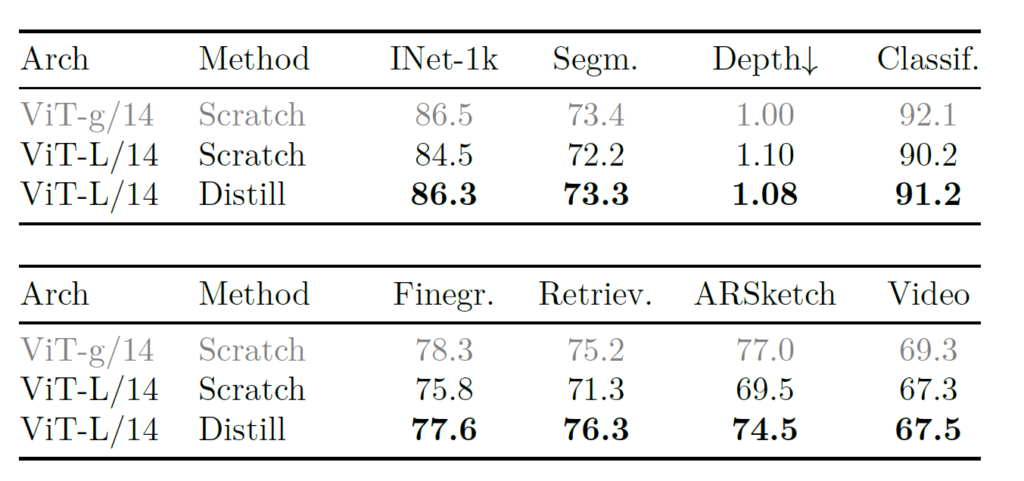
재밌는 점은 상대적으로 사이즈가 작은 모델의 경우 스크래치로 SSL 하는 것 보다 그냥 대용량 모델의 지식을 전이받는 방식이 모든 downstream task에서 더 좋은 성능을 달성하는 것을 볼 수 있습니다. 게다가 Retrieval 같은 경우에는 Teacher model인 ViT-G의 성능을 능가하기도 했네요.
결과적으로 저자들은 대용량 데이터와 대용량 파라미터로 학습한 라지 모델을 통해 상대적으로 작은 모델들을 Distillation하는 것이 더 효과적임을 실험적으로 검증합니다.
Impact of Resolution
마지막으로 Resolution에 따른 사전학습의 유의미성을 알아보는 실험입니다. 방법론에서도 간단하게 소개드렸다시피 모델이 사전학습을 224×224로 진행하다가 거의 학습 끝날 무렵에 고해상도로 SSL을 수행한다고 했었는데요, 실험 결과는 아래와 같습니다.
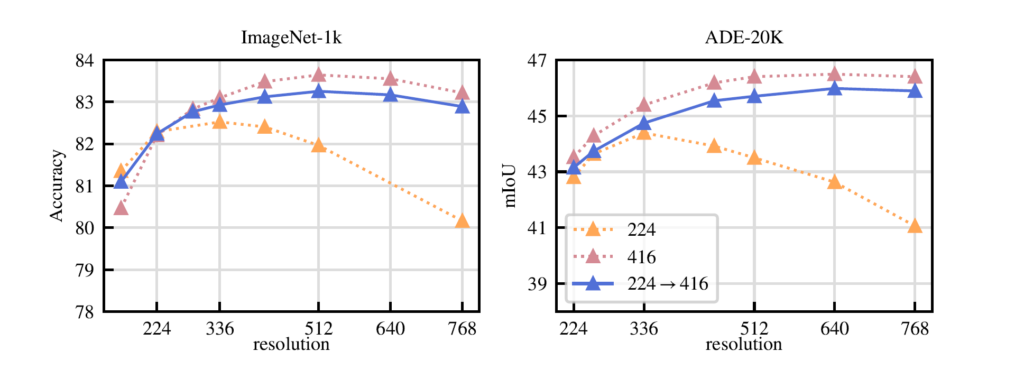
보시면 처음부터 끝까지 고해상도 (416)으로 학습한 모델이 분류와 세그멘테이션에서 대부분의 해상도로 추론하더라도 더 좋은 성능을 보여주게 되었습니다. 특히 저해상도로 사전학습한 모델의 경우에는 고해상도 입력에 대한 추론을 진행할시에 성능이 크게 감소하는 것을 볼 수 있네요.
이러한 관점에서 SSL을 고해상도로 진행하는 것이 상당히 중요하겠으나 문제는 시간과 비용 문제입니다. 가뜩이나 억에 달하는 데이터로 학습을 해야하는 마당에 해상도를 그렇게 높인다는 것은 엄청난 메모리와 학습 시간을 불러일으킵니다.
그래서 대부분의 학습을 저해상도(224)로 진행하다가 학습 마무리 시점에 고해상도로 높여서 학습을 하는 경우 물론 항상 고해상도로 학습한 결과보다 좋지는 않지만 대부분의 해상도에서 항상 고해상도로 학습한 모델의 성능과 유사한 경향성을 띄는 것을 확인할 수 있습니다. 이를 통해 비용과 정확도의 trade-off 관계에서 학습 마지막 단계에 고해상도 학습을 하는 방식이 상당히 유의미하다고 볼 수 있겠습니다.
결론
논문에서 다루고 있는 실험이 너무 많아서 이번 리뷰에 다 담기에는 어려울 듯 합니다. 최대한 논문의 핵심이 되는 부분들을 위주로 담았으며, 그 외에 기존 SOTA LLA 방법론들과의 비교 테이블은 담지 않았습니다. 이는 DINOv2가 당연히 학습에서 더 많은 (정제된) 데이터를 사용하여 다른 downstream task에서 기존 SSL 연구들 대비 성능이 좋을 수 밖에 없기 때문에.. 관련 실험들을 소개드리지 않았습니다. 하지만 성능의 격차가 얼만큼 차이나는지 궁금하신 분들은 직접 논문 실험 섹션을 참고하시면 좋을 것 같습니다.
논문이 개발쪽 성향이 짙다보니 이해를 하는데 어려움이 있기도 하였으나, Large Vision Model로써 상징성이 깊지 않을까라는 생각이 드네요. 이래서 최근 연구들이 DINOv2의 사전학습 가중치를 사용했나 싶기도 합니다. 그리고 SSL이 나아가야할 방향은 단순히 영상 데이터만 있으면 뭐든지 학습할 수 있어!가 아니라 어떻게하면 SSL을 하더라도 모델 학습에 도움이 되는 데이터를 잘 선별할 수 있을까?가 앞으로의 SSL의 방향성이 아닐까 싶습니다. (결국 Active Learning을 잘 해야겠네요^^)
안녕하세요, 신정민 연구원님. 좋은 리뷰 감사합니다.
SSL 쪽 리뷰라서 관심을 가지고 읽어보게 되었습니다. 기존 논문들을 읽을 때는 어떻게 image data의 좋은 representation을 학습할 수 있을지에만 집중했었는데.. 학습 데이터셋 자체의 규모와 품질을 관리한다는 관점이 저에게는 새롭네요. 읽고 보니 매우 중요하고 당연히 고려해야 하는 부분이고 생각됩니다.
특히, 기존 논문들 보면 Classification, Object detection, (instance, semantic, panoptic) segmentation 정도의 task에 대해서만 report되었는데, depth estimation, retrieval, video 쪽에 대한 성능 검증도 있다는 것이 눈에 띄었습니다. 데이터 정제 과정부터 시작해서 학습 자원이 상당할 것 같은데, 메타라서 가능한 것이가 하는 생각이 드네요.
질문 하나 남기겠습니다.
손실함수에서 L_DINO와 L_iBOT term을 사용한 이유는 결국 global feature와 local feature를 모두 학습하기 위해서라고 생각하면 될까요? 그럼 사전학습에 있어 최종 loss는 이 둘의 가중합으로 생각하면 되는건가요?
안녕하세요.
최종 목적 함수는 말씀해주신대로 Dino loss와 ibot loss를 가중합하는 방식으로 학습합니다.
거기에 추가적으로 Regularization term도 들어간다고 보시면 될 것 같네요.
안녕하세요 정민님!
좋은 리뷰 감사드립니다.
글을 읽던 중 궁금한 점이 있어서 댓글답니다.
SSL을 위한 대규모데이터셋을 구축함에 있어서 크롤링한 이미지중에 학습을 위한 좋은 이미지를 골라내는 과정을 거치게 되고, 그러는 과정에서 기존에 존재하는 데이터셋을 기준으로 유사한 분포를 갖는 이미지들을 선정한다고 이해하였습니다.
그런데 대용량데이터셋을 통한 학습을 통해서 우리가 얻고자 하는 것은 일반화된 특징을 학습하는 것인데, 해당 기준을 통해서 구축한 데이터셋이 기존의 데이터셋과 유사하여 일반화성능이 떨어질 것 같다는 생각을 해보았습니다. 해당 부분에 대하여 정민님은 어떻게 생각되시는 지 궁금합니다.
감사합니다.
안녕하세요.
상당히 좋은 질문입니다. 결국 일반화 성능을 향상시키기 위해서는 말씀해주신대로 학습 데이터의 다양성이 확보되어야 하는데, 이때 기존의 학습 데이터 분포와 유사한 데이터를 수집할 경우 이러한 다양성이 부족하다는 문제가 발생할 수도 있습니다.
다만 해당 논문에서 다루는 데이터의 스케일은 1억~10억 단위의 데이터이기 때문에 기존 데이터 셋과 유사한 군집들 내에서 선정할지라도 말씀해주시는 문제가 발생하지 않는 것 같습니다. 즉 데이터 다양성이 부족하여 성능이 훼손되는 것보다 오히려 노이즈 데이터로 인한 모델의 학습 방해가 성능에 더 큰 영향을 준다고 볼 수 있겠네요.
게다가 데이터 셋의 규모가 작은 경우에는 10억개 이상의 unlabeled set을 10만개로 군집화하여 해당 군집 내 1만개의 데이터를 랜덤하게 샘플링하는 방식을 사용하기 때문에 데이터의 다양성이 걱정하신 것과 달리 충분히 확보될 수 있다고 생각합니다.
감사합니다.