안녕하세요, 서른한 번째 X-Review입니다. 이번 논문은 2021년도 arXiv에 올라온 Probabilistic two-stage detection입니다. 본 논문은 지지난 주 리뷰한 CenterNet의 후속작인 CenterNet2라고 해서 읽어봤는데요 ,, centernet을 이은 논문이라기 보다는… 2-stage detector에 대한 새로운 학습 기법을 제시하는 논문이었고 그 중 centernet을 사용한 것이 가장 성능이 높아 centernet2라고 이름 지은 것이엇습니다 …… 바로 시작하도록 하겠습니다. ?
1. Introduction
Object detection은 영상 내에 있는 모든 객체를 찾고, 그 객체의 location 및 어떤 class에 속할지의 확률을 파악하는 것을 목표로 합니다. 1-stage detector는 location과 class 예측에 대한 확률을 동시에 추론합니다. 이 1-stage 검출기들은 어노테이션된 gt를 기반으로 object를 정확하게 식별하는 log-likelihood를 최대화하도록 학습한 후 추론 시에 적절한 likelihood score를 예측합니다.
반면 2-stage detector는 먼저 객체가 존재할 법한 위치를 검출한 다음 (2단계에서) 이를 분류합니다. 이 2-stage 검출기에서 첫 번째 단계는 recall을 최대화하도록 설계되었는데, 이는 객체가 아닌 배경을 찾는다고 하더라도 놓치는 객체 없이 가능한 많은 객체를 찾는것에 우선순위를 두기 때문에 Recall 값을 최대화하는 것을 목적함수로 삼습니다. 그렇다면 RPN의 주요 목표는 proposal된 영역에 실제로 객체가 있는지 여부를 정확히 판단하는 것은 아니라는 것이 되겠죠. 두 번째 단계에서는 앞 단계에서 식별된 객체를 분류하는데, 여기서는 각 객체의 class를 정확하게 식별하는데 목표를 두었습니다. . 이 두 번째 단계에서는 class에 대한 확률이 나오게 되지만, 1단계와 2단계를 아우르는 전체 process에 대한 직접적인 확률이 나오지는 않습니다.
본 논문에서는 2-stage detector의 확률적 해석을 다루고 있으며, 두 단계 모두를 포함한 공동의 확률적 loss 함수를 설계하여 기존 2-stage detetor를 학습하는 새로운 방식을 제안합니다. 본 논문에서 제시된 확률적 해석을 구체적으로 말해보자면, 첫 단계에서는 보정된 object likelihood를 추론해야 한다고 합니다. 여기서 보정된.. 이라는 의미는 RPN의 output으로 나오는 score는 proposal된 영역에 객체가 실제로 존재할 가능성을 정확히 반영하지 않을 수 있기 때문에 이를 신뢰할 수 있는 score가 나오도록 해야 한다는 의미입니다. 저자가 말하기를 2021년 당시의 2 stage detector에서 사용되던 RPN(Region proposal network)은 recall을 최대화하도록 설계되었기 떄문에 정확한 likelihood를 생성해내지 못한다고 하며, 1-stage detector는 가능하다고 합니다.
그렇기에 본 논문에서는 RPN단계에서 proposal된 영역에 object가 존재할 가능성을 정확하게 추정하기 위해 sota 1-stage detector를 기반으로 확률적 2-stage detector를 설계하고자 하였습니다. 첫 단계에서 모델이 region-level의 특징을 추출하고 분류하며, 두 번째 단계에서 faster r-cnn의 classifier, 혹은 cascade classifier를 사용하였습니다. 이 모델을 사용해서 첫 단계에서 검출한 object를 다시 분류하여 정확도를 높이고자 한 것인데, 즉 이 두 단계를 함께 학습하여서 gt object에 대한 log-likelihood를 최대화하도록 한 것이죠. 추론 시에는 이 최종 log-likelihood를 detection score로 사용하였습니다. 이런 방식은 기존 1-stage detector의 장점을 활용해 빠른 속도를 유지하면서 두 번째 단계를 통해 정확도를 향상시킨 방식입니다.
확률적 2-stage detector는 1-stage 및 2-stage detector보다 더 빠르게 동작하며 더 정확하다고 합니다. 기존 2-stage anchor 기반 detector인 Cascade r-cnn과 비교했을 때 객체가 존재할 영역을 제안하는 1단계에서 더 높은 정확도를 달성하였고, RoI head에서 사용하는 proposal 개수를 줄일 수 있게 되어 (256개 vs 1000개) 전체적인 detection 속도도 향상하였습니다. 또한 1단계(RPN)에서 더 단순한 head 구조를 사용하며, output class를 하나로 줄이게 되어 속도가 빨라져 2 stage detector의 단점인 느린 속도를 보완할 수 있었다고 합니다.
아래 본문에서 저자가 제안한 확률적 2-stage detector에 대해 자세히 살펴보도록 하겠습니다.
2. Preliminaries
Object detector는 사전에 정의된 class C set에 대한 모든 객체 i의 location인 b_i ∈ R^4와 class-specific한 likelihood score s_i ∈ R^{|C|}를 예측하는 것을 목표로 합니다. 객체의 location b_i는 대부분 bbox의 좌상단 우하단 두 모서리 좌표로 나타내지거나, 중심 좌표 + 크기로 표현하기도 합니다. object detector간의 주요 차이점은 class likelihood를 표현하는 것에 있습니다.
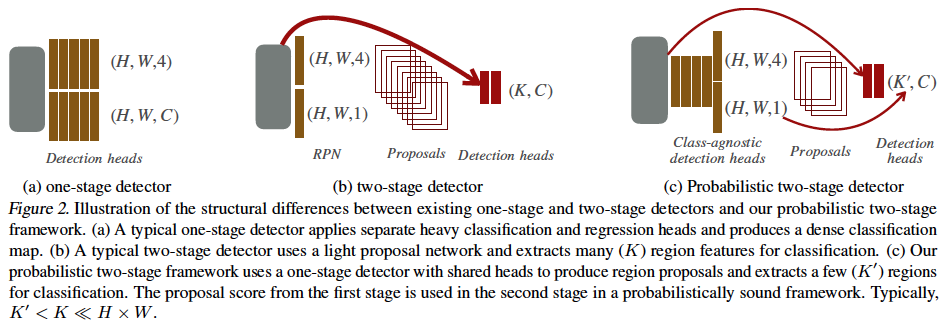
One-stage detectors
YOLOv3나 CenterNet같은 1-stage detector는 single network에서 객체의 위치와 likelihood score를 동시에 예측합니다. L_{i,c}=1는 object i, class c에 대한 positive detection을 의미하고 L_{i,c}=0은 배경을 나타낸다고 해봅시다. CenterNet을 포함한 대부분의 1 stage detector는 class별 weight(w_c)와 백본으로부터 추출된 feature f_i ∈ R^c를 사용하여 class likelihood를 베르누이 분포로 파라미터와 하는데요, , 식으로 나타내면 아래와 같습니다.
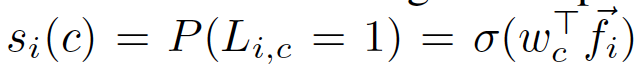
학습 과정에서 이런 확률적인 해석을 통해 1-stage detector는 gt 정보의 log-likelihood log(P(L_{i,c}를 최대화하도록 학습됩니다. 이 1-stage detector는 positive sample(\hat{L_{i,c}}=1)과 negative sample(\hat{L_{i,c}}=0)의 정의 방식에서 차이가 존재하는데요, 몇 1-stage detector는 anchor overlap 정도를 기준으로, 몇은 location 정보만을 사용해서 positive와 negative를 판단합니다. 그러나, 모든 1-stage detector는 log likelihood 함수를 최적화하며 class probability를 사용해 box의 score를 매겨 직접적으로 bbox 좌표를 regression합니다.
Two-stage detectors
2-stage 검출기인 Faster rcnn과 cascade rcnn은 먼저 objectness measure P(O_i)를 사용하여 object proposal이라고 불리는 잠재적인 객체의 위치를 추출하는 과정을 수행합니다. 그 다음 각 잠재적인 객체에 대한 feature를 추출하고 C class 또는 background로 분류한 다음 object의 location을 refine하게 됩니다. 이 각각의 단계는 dependent하게 학습됩니다.
먼저 첫번째 단계인 RPN(Region Proposal Network)에서는 어노테이션 된 object b_i를 전경으로, 그 외의 다른 box들을 배경으로 분류하는 방법을 학습합니다. 이건 일반적으로 log-likelihood 목적 함수를 통해 학습되죠. 하지만 RPN은 배경 영역을 아주 보수적? 으로 정의하는데,,,,,, 어노테이션 된 object와 IoU가 30%이상 겹치는 모든 예측된 box들은 foreground로 간주될 수 있습니다. 이렇게 라벨링하는 방식은 precision이나 정확한 likelihood를 추정하기보다는 높은 recall이 나오기만을 바란 것이죠.
두 번째 단계에서는 softmax classifier가 각 proposal들을 foreground class 또는 background 중 하나로 분류하는 방식을 학습합니다. 이 classifier는 log-likelihood 목적함수를 사용하며, foreground label은 어노테이션된 object로 구성되고 background label은 1단계에서 proposal된 bbox에서 가져오게 됩니다. 학습 중에 이 categorical distribution은 앞선 1단계의 positive한 proposal에 대해서만 학습되고 평가되기 때문에 암시적으로 1단계의 positive한 검출에 대해서 조건이 부여되게 됩니다. 이 1단계와 2단계 모두 확률론적인 해석을 가지며, positive와 negative 정의에 따라 각각 object 또는 class의 log-likelihood를 추정하게 됩니다. 하지만 전체적인 검출기는 그렇지 못하죠. 이 전체적인 검출기는.. 여러 heuristic과 sampling 전략을 결합해서 1단계와 2단계를 독립적으로 학습하게 되는데 최종적인 output은 오직 2단계의 classification score를 갖는 bbox로만 구성되게 됩니다.
아래에서, 저자가 소개한 single class-likelihood를 추정하는 2-stage detector에 대한 간단한 확률적 해석을 설명하겠습니다.
3. A probabilistic interpretation of two-stage detection
목표는 각 영상에 대해 class distribution과 연관된 K개의 bbox를 검출하는 것입니다. 다시 말해 객체가 특정 클래스에 속할 확률에 기반한 bbox를 검출하는 2-stage detector입니다. . 여기서 bbox regression 부분을 변경하지 않고 class distribution에만 초점을 맞췄습니다. 2-stage detector는 이 분포를 두 부분으로 분해하는데, class-agnostic한 object likelihood P(O_k)가 첫 번째 부분이고, conditional categorical classification P(C_k | O_k )가 두번째 부분입니다. 여기서 O_k=1은 첫 번째 단계에서의 검출이 positive인 경우를 나타내며 O_k=0은 배경에 해당합니다.(negative) . 첫 번째 단계의 검출이 negative면 O_k는 bacground C_k = bg classification으ㅗㄹ 이어지게 됩니다. 즉, P(C_k=bg | O_k = 0) multi-stage detector인 cascade rcnn의 경우 여러 단계의 앙상블을 통해 classification이 수행되는 반면, faster rcnn의 경우 single classifier를 사용합니다. 그럼 2-stage model의 공통 class distribution은 다음과 같습니다.
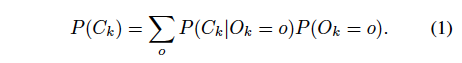
최종 class distribution은 1단계 판별 결과가 o인 경우 즉, 객체가 있다고 판단되는 경우에 객체 k가 class c에 속할 확률과, 그냥 1단계 판별 결과가 o인 경우를 고려하고 있음을 확인할 수 있습니다.
4. Results
실험은 COCO, LVIS, Objects365 데이터셋에서 진행되었으며 평가 지표는 mAP입니다.
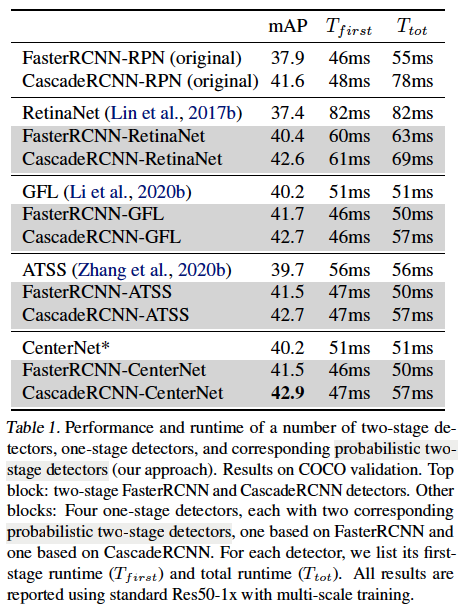
위 table1은 1-stage, 2-stage detector를 본 논문의 확륙 2-stage detector와 성능을 비교한 표입니다.
표의 첫 block 같은 경우 기존 2-stage detector인 fasterRCNN과 CascadeRCNN 성능을 리포팅 해 놓은 것이고요, 다음 block은 네 개의 1-stage detector의 성능과 해당 확률적 2-stage detector의 성능을 보여주고 있스빈다. 결과를 확인해보면, 모든 확률적 2-stage detector가 1-stage detector보다 성능이 높은 것을 확인할 수 있습니다. 각각의 확률적 2-stage faster r-cnn 모델은 해당 1-stage model모다 mAP가 1~2가량 향상되고 있으며, 흥미로운 점은 여기서 각 2-stage probabilistic model들은 head를 더 light하게 설계해서 1-stage detector보다 더 빠르게동작한다는 점입니다. 가장 높은 성능을 보였던 건 Cascade R-CNN-CenterNet인데요,,, 그래서 저자는 이 구조를 채택하여 CenterNet2라고 하였다고 합니다 .. . . . .
Real-time models
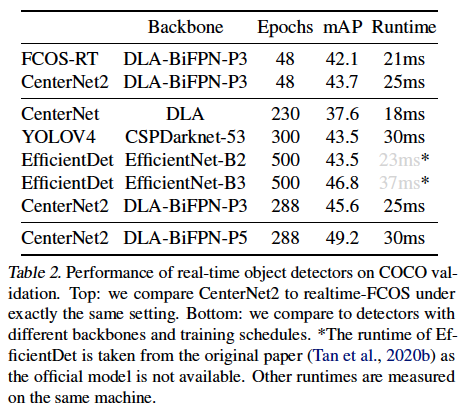
이제 기존 실시간으로 동작하는 detector와 본 논문의 모델을 비교해보도록 하겠습니다. table2를 보시면 CenterNet2는 동일한 백본을 사용하고, 동일한 에포크로 학습을 하였을 때 FCOS(1-stage detector)보다 1.6mAP 더 높은 성능을 보이며 단 4ms만 느린 것을 확인할 수있습니다. YOLOv4과 비교해보았을 때도 2021 당시 대부분의 실시간으로 동작하는 detector는 1-stage model이었지만, 여기서는 2-stage detector인 centernet2가 더 높은 정확도를 보이면서 1-stage model만큼 빠르게 동작할 수 있음을 보여줍니다.
State-of-the-art comparison
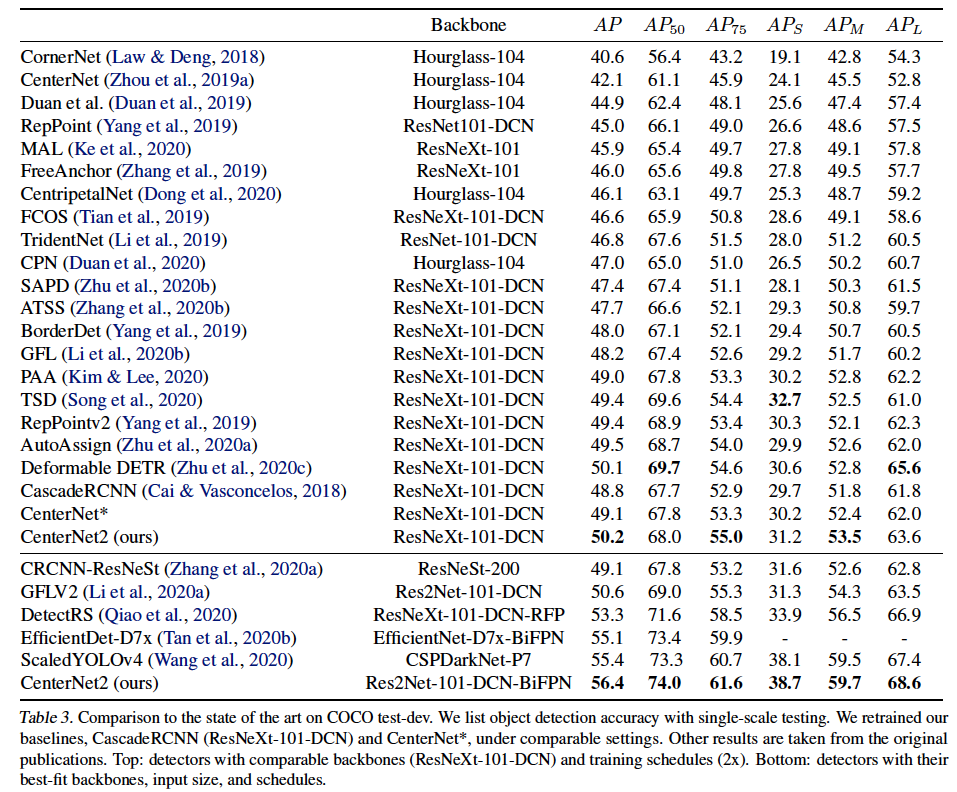
위 표3에서는 COCO test-dev 데이터셋에서 본 CenterNet2를 다른 sota 모델들과 비교한 table입니다. . 타 모델들이 주로 사용하는 ResNeXt-101-DCN 백본을 사용한 CenterNet2는 동일한 백본을 사용한 기존 모든 모델의 성능을 능가하는 50.2mAP를 달성하였습니다. 여기서 최종 모델로 Res2Net-101-DCN-BiFPN을 사용하였을 때 56.4mAP으로 SOTA네용
5.1. Ablation studies
Trade-off in the number of proposals
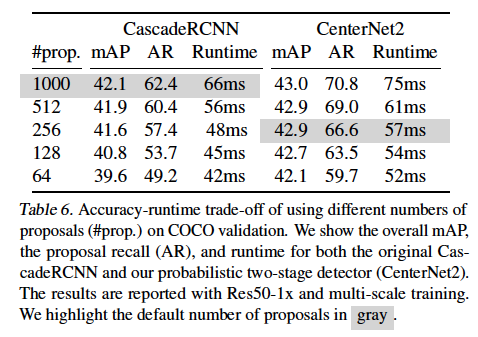
표6은 기존 RPN 기반 Cascade R-CNN과 CenterNet2에 대해 proposal number를 다르게 했을 때의 mAP와 average recall(AR), Runtime을 비교한 표입니다. Cascade RCNN과 CenterNet2 둘 다 당연하게도 proposal 개수가 적을 수록 더 빠르게 동작합니다. 하지만, proposal number가 줄어들수록 정확도 측면에서 차이가 발생하는데 구체적으로, Cascade R_CNN의 경우 proposal num을 1000개에서 128개로 줄이면 mAp가 1.3 떨어지지만 본 논문의 centernet2는 상대적으로 적은 proposal 개수를 사용하더라도 좋은 성능을 유지하는 것을 확인할 수 있네요 !

마지막으로 CascadeRNN과 본 논문의 centernet이 proposal한 region을 시각화한 그림입니다. 보시면 확연히 기존 cascade RCNN이 훨씬 region proposal을 많이 하고 있음을 확인할 수 있네욤.
안녕하세요 ! 좋은 리뷰 감사합니다.
Preliminaries의 two-stage detector 두번째 단계 설명에서 background label에 대해 1단계에서 propoasl된 bbox를 가져온다고 했는데, 여기서 proposal된 bbox라고 함은 RPN 과정 중에서도 배경으로 분류된 proposal을 의미하는것이 맞는 것이죠 ?? foreground label에서는 그렇다면 RPN에서 forground로 분류한 proposal box를 사용하지는 않는건가요 ?
그리고 실험 부분에서 가장 높은 성능을 보인 것이 CenterNet을 적용하였을 때라고 말씀해주셨는데, anchor free 방식의 CenterNet을 기존 2-stage detctor 기반의 방법론에 어떻게 적용하였는지 더 구체적으로 설명해주실 수 있나요 ??
감사합니다.