안녕하세요, 스물 여덟 번째 x-review 입니다. 이번 논문은 2023년도 AAAI에 게재된 SPFormer: Superpoint Transformer for 3D Scene Instance Segmentation 입니다. 해당 논문은 3D Segmentation 논문으로 지난 주에 리뷰한 OneFormer3D의 베이스가 되는 구조 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
현재 3D instance segmentation은 크게 proposal / grouping 기반으로 나뉘어 연구가 진행되고 있습니다. proposal 기반은 top-down 방식으로 먼저 Figure1 (b)처럼 region proposal을 생성한 다음 해당 영역에 대한 instance mask를 예측하게 됩니다. 이러한 방식은 대표적으로 2D instance segmentation 영역에서 Mask-RCNN을 예시로 들 수 있습니다. 그러나 proposal 방법은 3D로 넘어오면 바운딩 박스의 차원이 더 커지기 때문에 fitting 하는데 2D에 비해 더 큰 어려움이 있습니다. 게다가 포인트는 보통 물체의 표면에 대해서만 제공되기 때문에 물체의 실제 기하학적인 중심에 대해서는 검출하지 못할 수 있습니다. 반면 grouping 기반은 bottom-up 방식으로 point 별로 semantic한 라벨과 instane 중심 offset을 학습하고 학습한 포인트의 offset과 semantic한 예측을 instance로 합치는데 사용합니다. 최근 연구에서는 grouping 기반의 방식이 해당 task에서 큰 성능 향상을 이루었지만 역시 몇 가지 한계점이 존재합니다. (1) semantic segmentation 결과에 의존적이어서 잘못된 semantic segmentation 예측에 따라 뒤따르는 과정의 성능에 많은 영향을 미칩니다. (2) aggregation 단계가 필요하기 때문에 학습 및 inference 시간이 길어지게 됩니다.
두 방식의 단점을 보완하면서 장점을 활용하기 위해 본 논문에서는 superpoint 트랜스포머 기반의 end-to-end 3D instance segmentation 방식인 SPFormer을 제안합니다. SPFormer는 bottom up으로 포인트 클라우드에서의 feature를 superpoint로 그룹화하고, top-down 파이프라인으로 쿼리 벡터별로 instance를 예측하게 됩니다.
bottom-up 그룹화 단계에서는 sparse U-Net 구조를 사용하여 bottom-up 포인트 별 feature을 추출합니다. potential 포인트 별 feature을 superpoint로 그룹화하기 위해 간단한 superpoint pooling 레이어를 제안합니다. superpoint는 포인트의 기하학적인 구조를 활용하여 동일한 instance를 가진 이웃 포인트를 나타낼 수 있습니다. supeproint를 3D scene에서 potential한 mid-level의 representation으로 정의하고, instance 라벨을 직접 사용하여 전체 네트워크를 학습합니다. top-down 단계에서는 트랜스포머가 포함된 새로운 쿼리 디코더를 제안하는데, learnable 쿼리 벡터를 활용하여 superpoint feature로부터 instance를 예측하는 것을 파이프라인으로 제안합니다. 여기서 learnable 쿼리 벡터는 cross attention을 통해 포인트의 instance 정보를 알 수 있고, Figure 1.(d)가 해당 과정을 의미합니다. 의자의 빨간색 부분이 많을수록 쿼리 벡터가 올바르게 attention 연산을 진행하고 있음을 의미합니다. 쿼리 벡터가 이러한 instance 정보와 superpoint feature을 전달하면 쿼리 디코더는 instance 클래스, score, 예측 마스크를 생성하게 되는 것 입니다. 마지막으로 superpoint 마스크를기반으로 bipartite 매칭을 통해 SPForemr는 시간이 많이 소요되는 추가적인 aggregation 단계 없이 end-to-end 학습이 가능합니다. 여기서 본 논문의 contribution을 정리하면 다음과 같습니다.
- 물체 검출 결과나 semantic segmentation 결과에 의존하지 않는 superpoint 기반의 새로운 end-to-end 모델 제안
- superpoint cross attention을 통해 instance 정보를 사용할 수 있는 learnable 쿼리 벡터 설계
- superpoint 마스크 기반 bipartite matching을 통해 aggretation 단계를 생략하여 비교적 빠른 학습 및 inference
2. Method
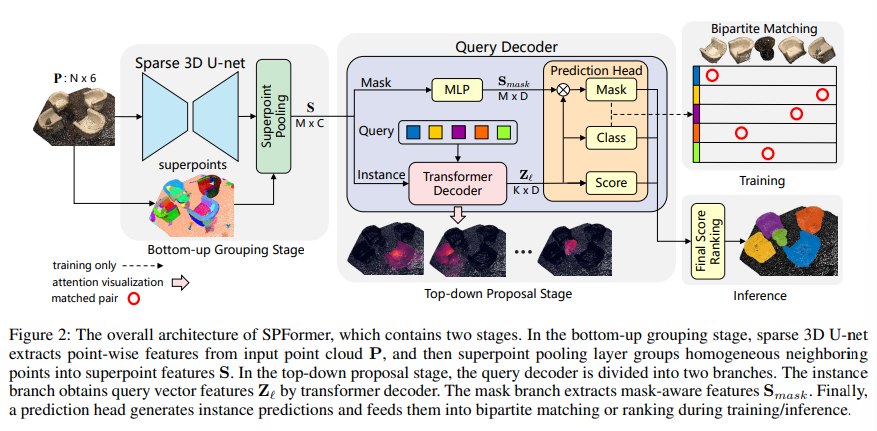
2.1. Backbone and Superpoints
먼저 입력으로 N개의 포인트 클라우드 P \in \mathbb{R}^{N \times 6}가 들어오면 복셀 형태로 변환 후 U-Net 구조의 sparse 백본 네트워크를 통과하여 포인트 feature P’ \in \mathbb{R}^{N \times C}을 추출합니다. 이전의 grouping 기반 방법론과 다르게 추가적인 semantic, offset 브랜치는 추가하지 않았다고 합니다. 이렇게 추출한 feature을 end-to-end 학습이 가능하도록 직접적으로 미리 계산된 superpoint 기반의 superpoint pooling 레이어를 통과하도록 설계하였습니다. superpoint pooling 레이어는 간단하게 superpoint 내부의 포인트 별 average pooling을 통해 superpoint feature S \in \mathbb{R}^{M \times C}을 구하는 것 입니다. 일반화를 위해 원래 입력으로 들어오는 포인트 클라우드에서 이미 superpoint로 계산된 포인트 M개가 존재한다고 가정합니다. superpoint pooling 레이어는 입력 포인트 클라우드를 수백개의 superpoint로 다운샘플링하여 그 다음 과정들에서 계산 오버헤드를 줄일 수 있고 superpoint를 사용함으로써 전체 네트워크의 representation을 최적화할 수 있습니다.
2.2. Query Decoder
쿼리 디코더는 크게 instance와 mask 브랜치로 구성됩니다. mask 브랜치에서 간단하게 MLP 구조로 mask-aware feature S_{mask} \in \mathbb{R}^{M \times D}를 추출합니다. instance 브랜치는 여러개의 트랜스포머 디코더 레이어로 구성되어 suprperpoint cross attention을 통해 learnabel 쿼리 벡터에 대한 연산을 진행합니다. 만약에 K개라는 learnable 쿼리 벡터가 있다고 가정하면 각 트랜스포머 디코더 레이어로부터 나오는 쿼리 벡터의 feature을 Z_l \in \mathbb{R}^{K \times D}로 정의합니다. 여기서 D는 임베딩 차원이고 l은 레이어 인덱스를 의미합니다.
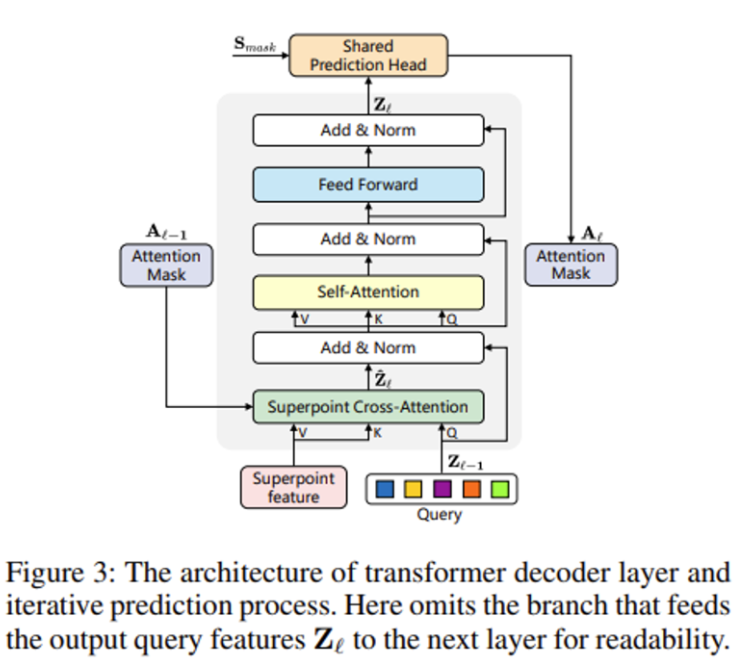
순서가 정해져 있지 않고 들어오는 입력 개수가 계속해서 변하는 포인트의 특성을 고려하여 변하는 입력 데이터의 길이를 처리하기 위한 트랜스포머 구조를 설계하였습니다. superpoint의 potential feature와 learnable 쿼리 벡터를 디코더의 입력으로 사용하는데, 쿼리 벡터는 학습 전에 랜덤하게 초기화되며 각 포인트 클라우드의 인스턴스 정보는 superpoint cross attention을 통해서만 얻을 수 있기 때문에 디코더 층에서는 일반적인 트랜스포머 디코더 구조와 다르게 self attention과 cross attention 순서를 바꾸게 됩니다. 쿼리 벡터 외에 potential feature 역시 입력으로 들어오기 때문에 position 임베딩은 실험적으로 제거하였다고 합니다. 디코더 내에서 이전 레이어인 Z_{l - 1}의 쿼리 벡터는 cross attention 연산을 통해 컨텍스트한 정보를 얻을 수 있습니다.
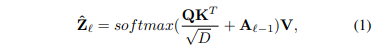
- \hat{Z} : \hat{Z} \in \mathbb{R}^{K \times D}, superpoint cross attention 출력값
- Q : \psi_Q(Z_{l - 1}) \in \mathbb{R}^{K \times D}, 입력 쿼리 벡터 Z_{l - 1}과 K, V의 linear projection
- A_{l - 1} : A_{l - 1} \in \mathbb{R}^{K \times M}, superpoint attention 마스크
앞선 예측 헤드에서 예측한 superpoint 마스크 M_{l - 1}이 주어지면, superpoint attention 마스크 A_{l - 1}은 특정 임계값 \boldsymbol{\tau}를 기준으로 아래의 식(2)와 같이 superpoint를 필터링하게 됩니다. 여기서 임계값은 실험적으로 0.5로 설정하였다고 합니다.

- A_{l - 1}(i, j) : M_{l - 1}(i, j)가 \boldsymbol{\tau}보다 높은 j번째 superpoint에 해당하는 i번째 쿼리 벡터
인스턴스 브랜치에서의 쿼리 벡터 Z를 두 개의 독립적인 MLP를 사용해서 classification \{p_i \in \mathbb{R}^{N_{class} + 1}을 예측합니다. 그리고 IoU-aware score \{s_i \in [0, 1]\}^K_{i = 1}을 통해 각각의 예측 proposal의 정확도를 평가하비다. 여기서 특히나 bipartite 매칭을 통해 propoasl에 GT를 할당하고 다른 proposal은 negative 예측으로 처리하기 위해 기존에 존재하는 N_{class} 이외에 “no instance”, 즉 인스턴스 정보가 없을 확률을 가진 예측 라벨을 추가합니다. 또한 proposal이 instance segmentation 결과에 큰 영향을 미친다는 사실은 맞지만, 실제로 bipartite 매칭으로 인해서 대부분의 proposal이 배경으로 간주되어 proposal 정확도를 평가한 결과가 잘못 정렬될 수 있다는 문제점이 존재합니다. 이러한 잘못된 정렬 문제를 해결하기 위해 예측된 superpoint 마스크와 GT 마스크의 IoU를 추정하는 score 브랜치를 추가적으로 설계하게 됩니다. 또한 마스크 브랜치에서 mask-aware feature S_{mask} \in \mathbb{R}^{M \times D}가 주어지면, 직접 쿼리 벡터 Z_l에 시그모이드 함수를 곱하여 superpoint 예측 마스크인 M_l \in [0, 1]^{K \times M}을 생성합니다.
2.3 Bipartite Matching and Loss Function
만약 proposal의 수가 고정되어 있따면, GT 라벨 할당을 최적의 할당 방식으로 정의할수 있습니다. i번째 proposal과 k번째 GT의 유사도를 평가하기 위해서 proposal과 GT 쌍에 대한 매칭 cost인 C_{ik}를 사용합니다.
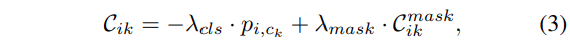
- p_{i, c_k} : i번째 proposal의 클래스 c_k에 대한 확률
- \lambda_{cls}, \lambda_{mask} : 항의 계수로 실험적으로 각각 0.5, 1로 설정
C_{ik}는 위의 식(3)에서 정의한 것과 같이 classification 확률과 superpoint 마스크 매칭 코스트 C^{mask}_{ik}에 따라 결정됩니다.
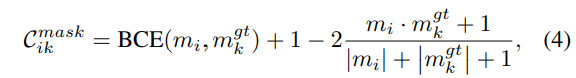
- m_i, m^{gt}_k : proposal과 GT superoint 마스크
식(3)에서 C^{mask}{ik}에 대해 더 얘기해보면 식(4)와 같이 BCE와 라플라스 smoothing을 사용한 dice loss로 구성됩니다. dice loss는 저의 바로 이전 리뷰에서도 이야기한 것처럼 segmentation task에서 널리 사용되는 loss 입니다. superpoint 내 포인트 절반이상이 instance에 속하는지의 여부에 따라서 각superpoint에 hard instance라는 라벨을 할당합니다. 매칭 cost C{ik}로 헝가리안 알고리즘을 사용하여 proposal과 GT 사이의 최적의 매칭을 찾아 할당한 후에 GT가 할당되지 않은 proposal은 아까 추가적으로 생성한 “no instance” 클래스로 처리하게 되고, 전체 proposal에 대해서 Cross Entropy Loss L_{cls}를 계산합니다. 그 다음, 각 propsoal-GT 쌍에 대해서 Binary Cross Entropy Loss L_{bce}와 dice loss L_{dice}로 구성된 superpoint mask loss를 계산하게 됩니다. 추가적으로 score branch를 설계하였으니, 이에 대한 식(5)와 같은 L2 loss L_s를 정의합니다.
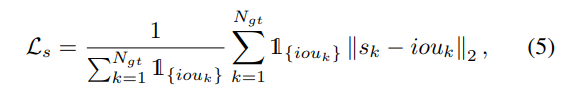
- {s_k}^{N_{gt}}{k=1} : GT N{gt}에 할당된 score 예측 결과의 집
- \mathbb{1}_{\{iou_k\}} : proposal 예측 마스크와 해당 마스크에 할당된 GT 사이의 IoU가 0.5 이상인지에 대한 여부
그래서 결국 최종적으로 사용하는 전체 loss를 정리하면 아래의 식(6)과 같습니다.
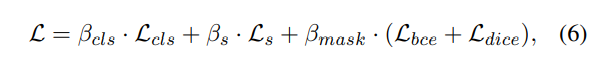
3. Experiments
실험은 indoor 데이터셋인 ScanNetv2와 S3DIS에서 진행하였습니다.
3.1. Benchmark Results
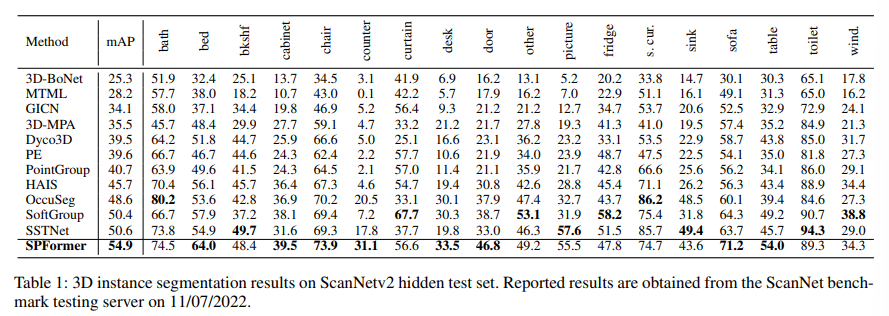
먼저 Table1은 SOTA 방법론과 SPFormer를 ScanNetV2의 test set에서 비교한 실험 입니다. SPFormer는 54.9%의 mAP를 달성하면서 이전 SOTA 대비 큰 폭의 성능 향상을 보이고 있습니다. 특정 18개 클래스 중에 8개에 대해 높은 AP를 달성하였는데, 특히 기존 방식에서는 매우 낮은 성능을 보이던 counter 클래스에서 눈에 띄는 성능 향상을 이루면서 훨씬 더 instance 정보를 잘 활용하고 있다는 것을 증명하고 있습니다.
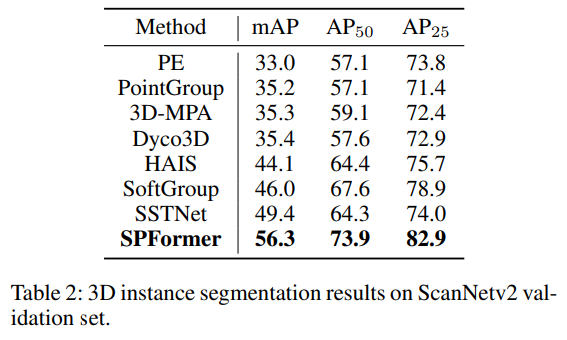
그리고 Table2와 같이 ScanNetV2에서 추가적으로 validation set에 대한 평가도 진행하였는데, 역시나 마찬가지로 가장 높은 mAP를 달성하였습니다.
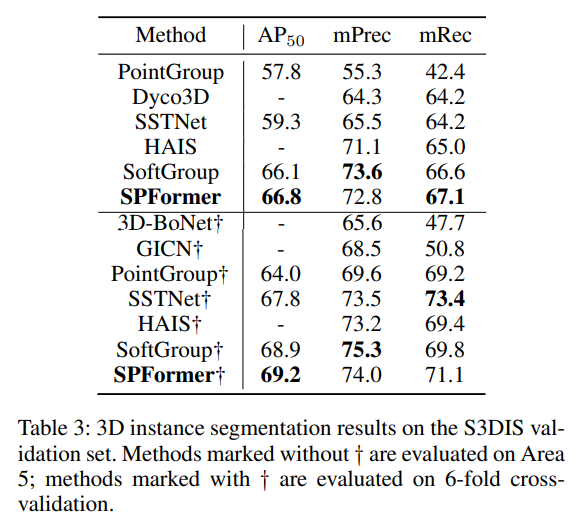
Table 3은 evluation에서 일반적인 세팅인 Area5와 6-fold 교차 검증을 사용하여 S3DIS에서 평가한 결과 입니다. 이전방식에서 사용된 평가 프로토콜을 그대로 따라서 mPrec와 mRec을 추가적으로 평가한 결과, SPForemr는 모든 평가 지표에서 SOTA는 아니더라도 우수한 결과를 얻을 수 있었다고 합니다. 이러한 모든 평가 지표에서 고루 좋은 성능을 보이는 결과를 통해서 SPFormer의 일반화 성능을 확인할 수 있습니다.
3.2. Ablation Study
Component Analysis

Table5는 모델 구조에서 여러 구성을 생략하면서 각 구성이 모델 성능에 어떤 영향을 주는지 평가한 결과 입니다. 우선 백본 네트워크의 출력을 쿼리 디코더로 바로 주게 되면, 즉 superpoint pooling을 적용하지 않으면 큰 성능 저하가 발생하는 것을 확인할 수 있습니다. 쿼리 벡터는 cross attention의 소프트맥스 과정 때문에 수십만개의 raw한 포인트 feature을 처리하기 어렵습니다. superpoint를 이용하여 다운샘플링 및 백본과 쿼리 디코더 사이에 연결 고리를 형성하면서 큰 성능 향상을 이룰 수 있었다고 합니다. 다음으로는 추가적인 score branch를 도입하여 proposal의 퀄리티에 대한 평가에서 발생하는 잘못된정렬 문제를 완화함으로써 성능 향상에 도움이 되는 것을 알 수 있습니다.
Number of Queries and Layers
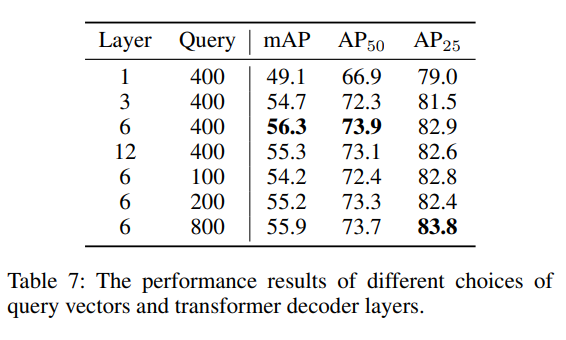
다음은 쿼리 벡터와 트랜스포머 디코더의 레이어 수에 따른 성능 변화로, 결과적으로 레이어가 너무 적거나 많은 경우 모두 성능이 저하되는 것을 볼 수 있습니다. 그런데 쿼리 벡터가 100/200개인데 비해 400개를 사용할 때 약간의 성능 향상이 발생하지만 800개가 되면 성능이 거의 saturation 되고 있습니다. 이러한 결과는 3D scene에서 instance의 수가 일반적으로 2D 데이터셋에 비해 instance 수가 많기 때문일 수 있다고 저자는 분석하고 있습니다.
The Selection of Mask Loss
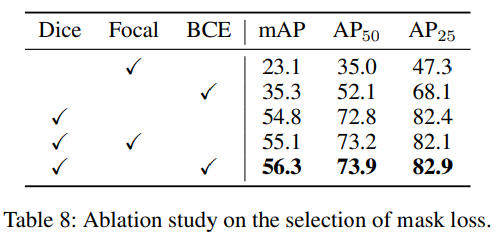
마지막으로 mask loss의 구성에 따른 ablation study 입니다. BCE loss 혹은 Focal loss만을 사용하면 성능이 눈에 띄게 낮아지고 있는 결과를 통해, mask loss에서 dice loss는 무조건적으로 필요한 구성 요소임을 확인할 수 있습니다. dice loss를 기반으로 BCE loss나 Focal loss를 추가했을 때 전체적으로 성능이 향상되며 그 중에서도 논문의 세팅인 dice loss와 BCE loss를 함께 사용할 때 가장 좋은 결과를 얻을 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
3D segmentation에 대한 논문은 이전 세미나를 통해 처음 보게되었는데요, 실험을 진행하는 데이터셋은 scannetv2에서 실험을 진행하는 것 같은데 해당 논문은 3d detection task에서만 사용되는 게 아니라 3d segmentation 수행할 수 있는 gt 라벨링이 되어있는 건가요?
수 많은 포인트 클라우드 중 proposal을 만드는 것도 쉽지 않을 것 같은데 superpoint만으로도 매칭이 된다는 게 신기하네요. 쿼리 디코더를 타고 나오면 소위 말하는 RoI를 생성한다고 보면 될까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. ScanNetV2는 detection task로만 쓰이는 데이터셋은 아니고, 원래 segmentation 마스크에 대한 라벨링까지 제공하고 있기 때문에 segmentation task에도 사용할 수 있습니다.
2. 단순 RoI라기 보다는 쿼리 디코더를 타고 나온 예측값은 GT와 직접적으로 매칭이 가능한 클래스와 예측 proposal을 의미하게 됩니다. 즉 예측 라벨링이 포함된 최종 마스크 후보들이라고 말하는 것이 더 맞을 것 같네요.
감사합니다.