안녕하세요, 이번에도 Zero-shot 기반의 object pose estimation 논문을 가져왔습니다.
foundation model을 사용함에도 불구하고 기존의 방법론들에 비해 매우 빠른 속도를 보여주고 있어 흥미를 가지고 읽게 된 논문입니다.
바로 리뷰 시작하겠습니다.
Introduction
물체에 대한 pose 추정은 최근까지도 크게 개선이 되었습니다. 하지만 supervision을 통한 딥러닝 학습 방법은 높은 정확도에도 불구하고 산업 환경에 적용하기에는 여전히 어려움이 있는데요. 실제로 novel object에 대해 새롭게 수집된 데이터를 사용하여 pose 추정 모델을 재학습 해야하는 어려움도 있겠네요. 재학습을 시키는 것은 시간적으로도 비용이 많이 들어 이러한 경우에는 실제 산업 환경에 적용하는 것은 비현실적으로 보입니다. 최근 novel object에 대한 다양한 방법론들이 제안되고 있는데요. 이번 GigaPose의 핵심 아이디어는 novel object에 대한 pose를 추정하는 것에 대한 유용한 것으로 선행 연구를 통해 입증된 템플릿에 대한 사용으로 인해 더 정확한 pose 추정으로 이어지도록 patch들 간의 correspondence를 어떻게 잘 만들어볼지에 대한 아이디어라고 합니다. 템플릿을 사용하여 azimuth(방위각)과 elevation(고도)에 대한 2가지의 자유도를 추정하는 것을 제안하게 되는데요.
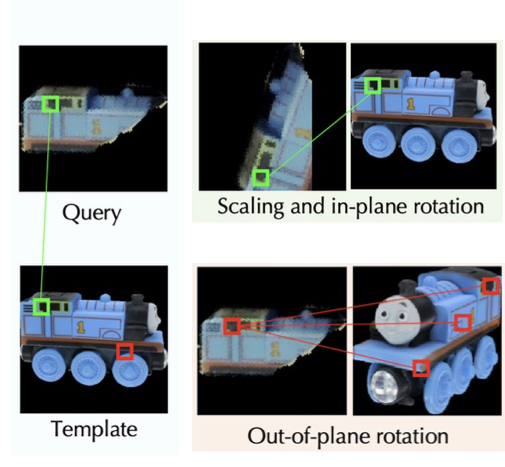
그리고 해당 논문에서 자주 나오는 단어인 in-plane rotation, out-of-plane rotation에 대해 부연 설명을 하자면 in-plane의 경우 중심(특정 평면 기준)을 두고 rotation을 하는 것을 의미하며 out-of-plane의 경우 중심에 대한 여러 방면으로 회전한 경우를 의미합니다. 위 그림은 논문의 그림에서 짜집기하여 이해하기 쉽게 만든 그림인데요. in-plane의 경우 쿼리 이미지에 대해 특정 축에 대한 각도에서만 rotation만 한 결과이며, 아래의 out-of-plane의 경우 템플릿에 대한 다양한 축에 대한 rotation을 수행한 것을 확인할 수 있습니다. GigaPose에서는 이러한 correspondence를 생성하기 위해 feature extractor 모델 1개와 coase pose estimation을 위한 Feature extractor + MLP로 구성된 모델 1개 각각에 대한 학습을 진행하게 됩니다.
이러한 GigaPose는 기존의 방법론들에 비해 훨씬 빠르면서 정확한 pose 추정을 하는 결과를 보였습니다.
각각에 대해 어떻게 수행하였는지 구체적으로 알아보도록 하겠습니다.
Method
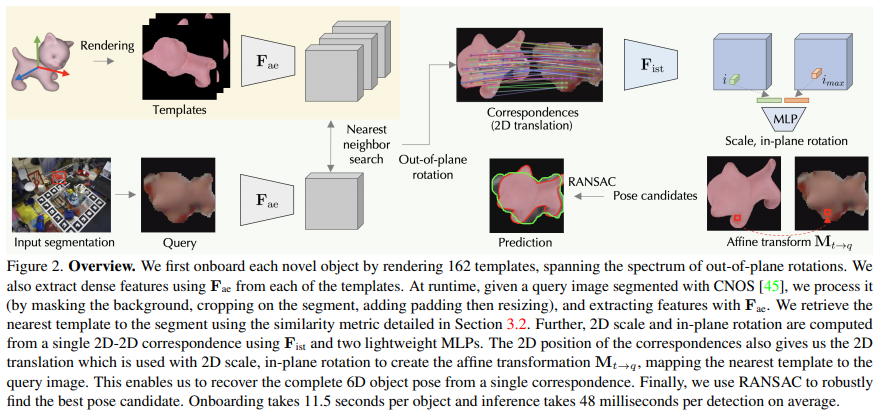
Generating Templates
이번 GigaPose에서는 162개의 템플릿을 이용하였다고 합니다. 이는 icosphere으로 정의된 뷰포인트의 개수이며 다양한 뷰포인트가 잘 분포하도록 하는 선행 연구로 나온 결과로 보시면 되겠습니다.
Predicting Azimuth and Elevation
Training the feature extractor \mathbf {F_{ae}}
GigaPose의 전체적인 overview를 나타내고 있는 그림(2)를 보시면 \mathbf {F_{ae}}는 dense feature를 뽑기 위한 ViT를 모델을 의미하는데요. 입력 이미지가 들어왔을 때 detector 역할을 CNOS로 하게 됩니다. 여기서 \mathbf {F_{ae}}를 이용하여 입력 이미지와 템플릿으로부터 추출된 dense feature는 각각 독립적인 관계인데요. 즉 onboarding 노란색 영역은 온보딩 과정이므로 사전에 novel object에 대한 정보를 추출하는 단계라고 볼 수 있겠습니다.
그럼 이번 문단의 제목인 \mathbf {F_{ae}}는 어떻게 학습이 진행되는 것인지 알아보도록 하겠습니다.
먼저 앞서 추출된 template과 입력 이미지(쿼리)에 대한 각각의 feature를 비교해야 하는데요. 비교를 한다는 것은 유사도를 측정하는 과정으로 이해하시면 되겠습니다. 추출된 feature는 out-of-plane에 대한 rotation 정도는 다르지만 scale, in-plane에 대한 rotation/translation이 고정되어 있는 template과 쿼리에 대한 매칭을 목표로 하게 되는데요. 이러한 feature는 scale, in-plane rotation/translation에는 invariant 해야 하고, out-of-plane rotation에는 크게 반응해야 합니다.
저자는 위와 같은 효과를 주도록 feature extractor인 \mathbf {F_{ae}}를 학습하도록 유도하는데요. 이때 contrastive learning을 사용하게 됩니다. 메인으로 어려운 부분은 positive와 negative pair를 어떻게 정의할 것인가? 인데요.
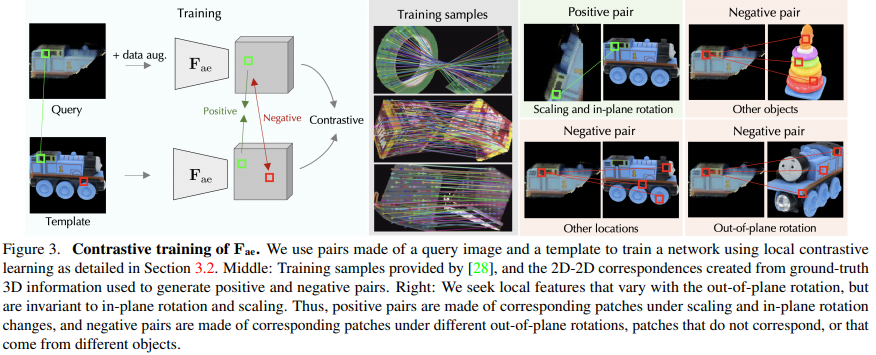
위 그림(3)은 학습 파이프라인을 나타내는 그림입니다. 입력으로 받는 쿼리(\mathcal Q_{k})는 어떤 특정 pose에 대한 이미지로부터 얻은 렌더링 결과(occlusion이 된 것을 보아)이고, 템플릿(\mathcal T_{k})은 앞서 얻은 3D 모델로부터 얻은 렌더링 결과입니다. out-of-plane rotation은 동일하지만 in-plane rotation/translation, scale에 대해 서로 매칭이 되도록 (\mathcal Q_{k}, \mathcal T_{k}) 쌍으로 batch를 구성합니다. 저희는 3D 모델에 대한 접근이 가능하므로 GT 2D-2D correspondence를 계산하여 positive 및 negative에 대한 pair를 만들었다고 합니다. 또한 저자는 실제 이미지와 합성 렌더링 된 이미지 간의 domain gap이 발생하게 되어 이를 줄이는 것을 목표를 하였는데요. 입력에 대한 pair를 random crop, augmentation을 적용하여 contrastive learning을 수행합니다. 이때 학습을 위해 사용된 데이터셋은 MegaPose에서 제공한 GSO(Google Scanned Objects), SN(ShapeNet)의 이미지와 CAD 모델을 사용하였다고 합니다. 그림(3)의 중간에 학습을 위한 샘플이 나와있네요. 이렇게 각 이미지 \mathcal Q_{k}와 템플릿 \mathcal T_{k}를 \mathbf {F_{ae}}에 독립적으로 전달해주는 역할을 하여 dense feature인 \mathbf q_{k}, \mathbf t_{k}를 추출하게 됩니다. ViT의 downsampling 과정으로 인해 feature에 대한 각 위치를 의미하는 i는 14×14 크기를 갖는 patch에 해당하게 됩니다. 여기서 사용되는 feature map에서 (\mathcal Q_{k}, \mathcal T_{k})에서 물체의 foreground에 해당하는 각각의 segmentation mask인 \mathbf m_{\mathcal Q_{k}}, \mathbf m_{\mathcal T_{k}}가 존재합니다. 쿼리에 대한 feature map \mathbf q_{k}에 대한 특정 위치 i에 대해 템플릿 feature map에서의 i에 대응하는 해당 위치를 i^{*}로 나타냅니다. 즉, 쿼리에 대한 patch \mathbf q_{k}^{i^{*}}와 여기에 대응하는 템플릿에 대한 patch \mathbf t_{k}^{i^{}}를 주대각 원소에는 positive pair가 포함되도록, 다른 이외의 항목들은 negative pair가 포함되도록 정방행렬의 형태로 만들어줍니다.
효율적인 contrastive learning을 하기 위헤서는 쿼리 이미지의 \mathcal Q_{k}와 템플릿 \mathcal T_{k^{\prime}}의 negative pair를 추가적으로 사용하게 되는데요. 이때, k와 k^{\prime}은 서로 다른 것입니다. \mathbf {F_{ae}}를 학습시켜 positive pair에 대한 representation을 만들어주게 되고 negative pair에 대해서는 아래의 식(1)과 같은 InfoNCE loss를 사용하여 분리하도록 설계합니다.
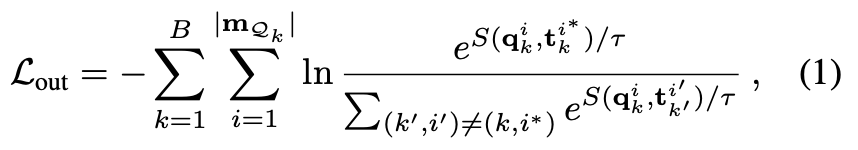
위 식에 사용되는 S(., .)는 쿼리와 템플릿 간의 코사인 유사도를 측정한 값에 \tau(temperature parameter)로 나누어 연산을 진행하게 됩니다. 논문에서는 해당 \tau를 0.1로 설정하였다고 합니다.
positive pair는 서로 다른 scale과 in-plane에 대한 rotation을 가지게 되는데요. \mathbf {F_{ae}}는 해당 두 가지 요소에 invariant하도록 학습하는 방식이라고 보시면 되겠습니다. 이때 사용되는 \mathbf {F_{ae}}는 사전학습된 DINOv2의 가중치를 가져와 사용하였다고 합니다.
Azimuth and elevation prediction
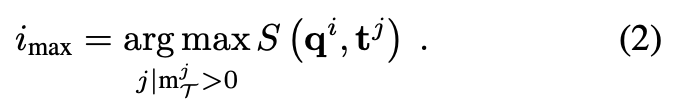
각 쿼리-템플릿 간의 pairwise한 유사도 메트릭을 정의합니다. 해당 메트릭을 통해 위치 i의 패치에 해당하는 로컬 쿼리 feature {\mathbf q_{i}}에 대해 템플릿 feature \mathbf t에서 Nearest neighbor를 위 식(2)과 같이 템플릿에 대한 i_{\max}로 값을 계산하게 되는데요.
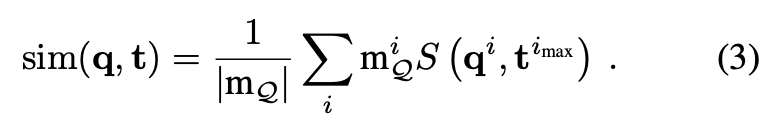
그리고 식(3)과 같이 Nearest neighbor search를 수행하기 위해 i ↔ i_{\max}에 대한 서로 간의 correspondence 리스트를 계산하게 됩니다. 이때 이상치에 대한 threshold로 유사도가 0.5 이상인 correspondence만을 유지하도록 하며 최종 유사도 결과는 유사도 값에 대한 평균을 취해 얻게 됩니다.
모든 템플릿 \mathcal T_{k}에 대한 해당 점수를 계산하여 가장 유사한 out-of-plane rotation을 생성하는 top K로부터 후보를 찾고 Nearest neighbor search를 진행하는 방식으로 동작하게 됩니다.
Predicting the Remaining DoFs
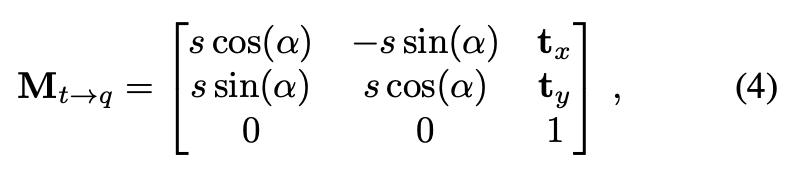
앞선 같은 과정을 통해 템플릿에 대한 후보를 찾았으니 이제 pose를 알아내는 과정인데요. 나머지 4개의 자유도를 의미하는 rotation, scale, translation(x, y)에 대한 추정을 통해 각 템플릿에 대한 후보 \mathcal T를 입력 이미지 \mathcal Q만큼 변환시켜주는 affine transformation인 M_{t \rightarrow q}를 구합니다.
Training the feature extractor \mathbf {F_{ist}} and the MLP
두 번째 feature extractor인 \mathbf {F_{ist}}는 어떻게 학습을 했는지 살펴보겠습니다.
이전 섹션에서는 \mathbf {F_{ae}}의 feature로 부터 2D-2D correspondence를 만들어 (i, i_{\max})의 리스트를 얻었습니다. 해당 correspondence는 고유한 patch의 위치 i와 i_{\max}를 통해 2D translation인 [t_{x}, t_{y}]를 얻을 수 있겠네요. 나머지 2개의 자유도를 가지고 있는 scale s와 rotation에 대한 \alpha값에 대한 찾기 위해 단일 2D-2D correspondence로부터 해당 값들을 직접 regression 하도록 모델을 설계합니다. 하지만 \mathbf {F_{ae}}는 rotation 및 scale에 대한 invariance이므로 해당 특징을 사용하여 regression을 할 수 없으므로
추가적인 extractor가 필요하다는 말을 의미하는데요. 이말을 좀 더 풀어보면, 두 이미지가 같은 물체에 대해 다른 각도로 회전 시켰을 때, 해당 물체에 대한 feature는 회전에 대해 그대로 변하지 않을 것이라는 의미가 됩니다. 이러한 경우는 저희가 유도하는 경우가 아니겠죠. 따라서 \mathbf {F_{ist}}라는 추가적인 모델을 학습하게 됩니다. (\mathcal Q, \mathcal T)의 쌍으로부터 2D-2D 매칭한 결과를 \mathbf {F_{ist}} 통과한 feature가 주어졌을 때, 각 feature에 존재하는 \{i, i_{\max}\}를 MLP에 태워 \alpha, s를 regression을 하도록 합니다.
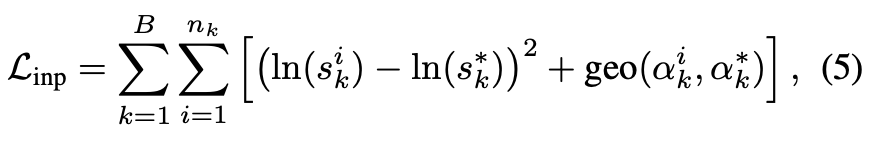
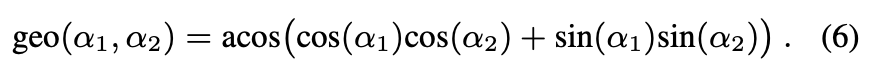
식(5)와 같은 loss function을 통해 \mathbf {F_{ae}}와 동일한 데이터 샘플에 대해 \mathbf {F_{ist}}와 MLP를 같이 학습합니다. s_{k}^{*}, \alpha_{k}^{*}는 GT scale, rotation을 나타내며, geo(\cdot, \cdot)는 식(6)과 같이 rotation에 대한 geometric loss를 의미합니다.
RANSAC-based M_{t \rightarrow q} estimation
각 템플릿에 대한 각 correspondence가 존재할텐데 correspondence를 생성하는 과정에서 outlier가 생성될 수 있습니다. 보통 이러한 outlier들을 제거하기 위해 RANSAC을 사용하게 되는데요. 해당 과정에서도 RANSAC을 적용하여 특정 threshold \delta에 못미치는 경우 없애고 남은 correspondence를 이용하여 유효성을 검증하는 과정을 거치게 됩니다. 해당 과정에서 \delta는 패치 크기(14)로 설정하였습니다. M_{t \rightarrow q}에 대한 최종적인 예측은 가장 많은 수의 inlier를 가지는 경우에 결정되게 됩니다.
참고로 DINOv2는 scale, rotation에 대해 매우 invariant한 모델이기 때문에 해당 \mathbf {F_{ist}}에서는 DINOv2를 사용하지 않고 ResNet18의 수정된 형태를 가지고 가중치를 초기화했다고 합니다.
Experiments
Experimental Setup
Evaluation datasets
Core BOP dataset :
LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HomebrewedDB(HB), YCB- Video(YCB-V)
총 132개의 물체, 19048장의 테스트 이미지
Evaluation metrics
Visible Surface Discrepancy (VSD),
Maximum Symmetry-Aware Surface Distance (MSSD)
Maximum Symmetry-Aware Projection Distance (MSPD).
AR=\frac {AR_{VSD} + AR_{MSSD} + AR_{MSPD}}{3}Pose estimation wit a 3D model predicted from single image
Wonder3D라는 생성 모델을 이용하여 단일 이미지에서 3D 모델을 예측하고, 데이터셋에서 제공하는 3D CAD 모델 대신 reconstruction 된 모델을 사용하여 MegaPose와 제안한 GigaPose에 대한 성능을 평가하였습니다.
Comparison with the State of the Art
Accuracy
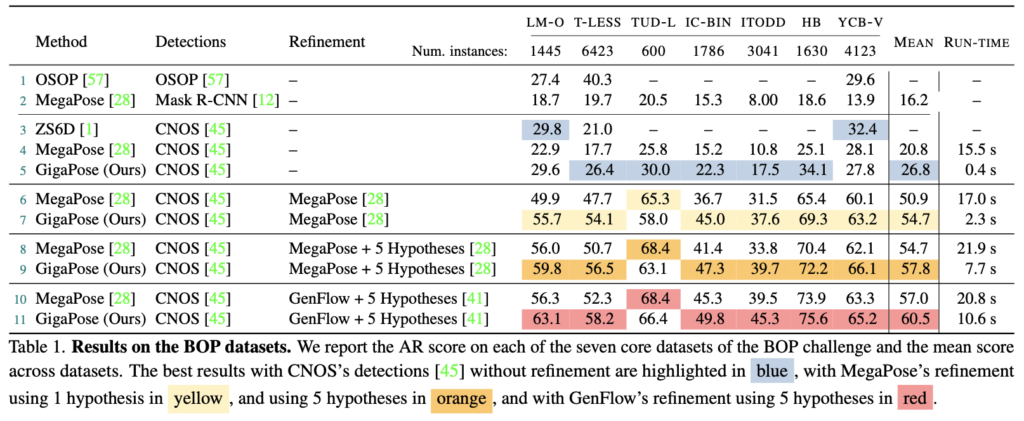
표(1)은 베이스라인(OSOP, ZS6D, MegaPose)과 비교한 결과를 나타내고 있는데요. refinement 과정의 여부에 관계 없이 모든 세팅에서 GigaPose의 속도가 가장 빠른 것을 볼 수 있습니다. refinement를 거치지 않은 coarse pose로 예측한 결과는 MegaPose에 비해 6%가량 성능이 우세한 것을 확인할 수 있네요. refinement를 거치는 경우에도 우세한 결과를 보여주고 있습니다.
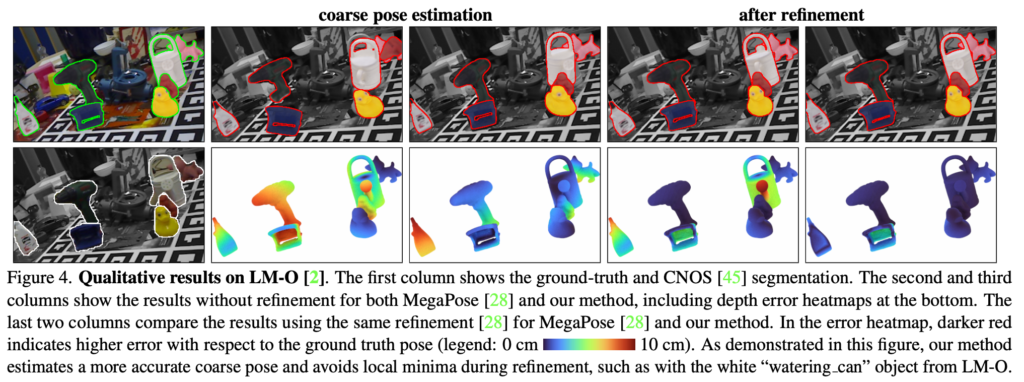
그림(4)는 coarse pose와 refinement를 거치고나서의 pose에 대한 정성적 결과를 보여주고 있습니다.
Accuracy when using predicted 3D models
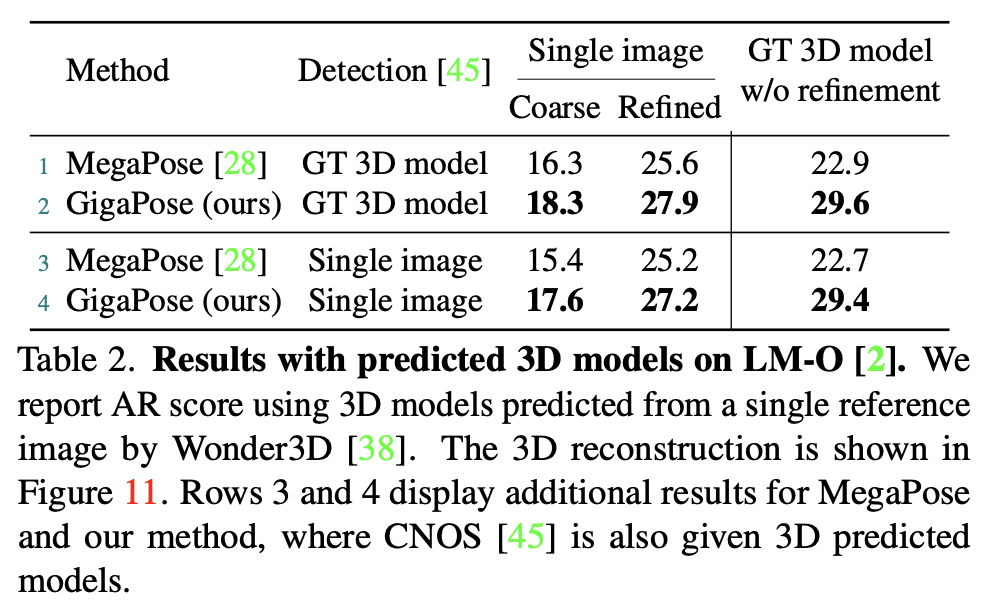
이번 GigaPose에서는 재밌는 실험 결과를 리포팅 하였는데요. 앞서 언급했던 Wonder3D를 통해 얻은 3D 모델을 가지고 비교한 결과를 나타내고 있습니다. GT 3D 모델을 사용하거나 Wonder3D로 얻은 3D 모델을 예측하든 모든 우세한 결과를 보여줌으로써 3D 모델이 바뀌어도 모델에 대한 성능이 기존의 방법론보다 우세하다는 것을 보여주고 있습니다.
Ablation study
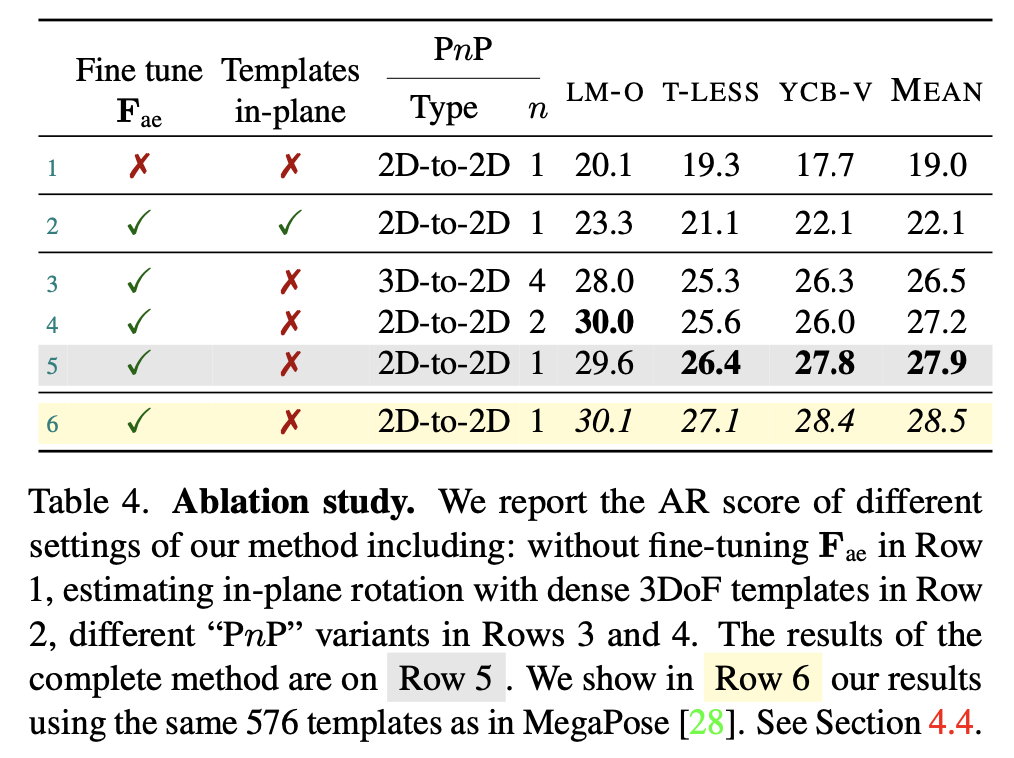
Fine-tune \mathbf {F_{ae}}
표(4)의 1행은 DINOv2 기반의 Feature extractor인 \mathbf {F_{ae}}를 추가적인 fine-tuning 없이 사용한 결과를 보여주며 이외의 아래 행들은 fine-tuning을 한 결과를 나타내고 있습니다. GigaPose에서 사용한 2D-2D matching을 통해 얻은 결과가 가장 성능이 좋은 것을 5행을 통해 알 수 있습니다.
Estimating in-plane rotation with templates
표(4)의 2행은 in-plane에 대한 rotation 정도를 10도씩 36개의 구간으로 나누어 물체 당 5832개의 템플릿을 생성하여 얻은 결과입니다. 5행과 비교했을 때 적은 template을 가지고도 좋은 성능을 보여준 것을 확인할 수 있습니다.
2D-to-2D vs 3D-to-2D correspondences
2D-3D correspondence 는 렌더링을 통해 얻은 depth 정보를 이용하면 3D 위치로 대체할 수 있습니다. 해당 결과보다는 2차원 상의 매칭을 하는 것이 좀 더 좋은 결과를 보여주고 있습니다.
Number of templates
6행의 경우 MegaPose와 동일하게 템플릿을 576개 사용한 결과인데요. 적은 수(162개)의 템플릿을 사용한 5행의 성능 보다 더 향상되긴 하였지만, 0.6%정도의 오차면 정확도를 크게 해치지 않은 것으로 저자는 분석합니다. 즉, 많은 수의 템플릿을 사용하는 것보다 적은 수를 사용함으로써 이를 통해 메모리 사용량을 줄일 수 있는 효과가 있는 것으로 볼 수 있겠네요.
Conclusion
이번에는 novel object에 대한 6D coarse pose estimation인 GigaPose에 대해 살펴보았습니다.
기존 방법론들에 비해 speed, robustness, accuracy 측면에서 월등히 뛰어난 결과를 보여주었으며 이를 통해 저자는 향후 실시간으로 정확한 pose 추정이 가능하도록 기대하고 있습니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
query와 template 사이의 feature 매칭에서의 기준은 “out-of-plane에 대한 rotation 정도는 다르지만 scale, in-plane에 대한 rotation/translation이 고정되어 있는 template과 쿼리에 대한 매칭을 목표”로 한다고 말씀해주셨는데, 막상 학습 파이프라인에서는 “out-of-plane rotation은 동일하지만 in-plane rotation/translation, scale에 대해 서로 매칭이 되도록”이라고 표현이 되어 있어서 .. positive pair로 분류된 예시를 보니 out-of-plane 정도가 다른 쌍이 positive pair로 정의된 것 같은데 매칭되는 기준에 대해서 명확하게 한번 더 설명해주시면 감사하겠습니다.
실험 결과에서 2D-to-2D 대응 관계가 3D-to-2D 보다 더 좋은 결과를 보여주고 있다고 리포팅 되어 있는데, 대응 관계를 찾는 이유가 결국은 query와 가장 유사한 template을 찾아서 rendering에 쓰인 3D cad 모델에 접근하기 위함이라고 이해했는데 그런 관점에서 depth 정보를 이용한 3D 위치가 더 많은 정보를 줄 수 있을 거라는 생각이 듭니다. 혹시 이러한 결과에 대해서 2D-to-2D가 더 좋은 성능을 보일 수 있었던 분석이나 이유에 대한 서술이 있었는지, 혹은 희진님의 고찰이 궁금합니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 그림(3)의 positive pair에는 확대하고 회전만 한 상태로, scaling을 적용한 후 in-plane rotation이 맞습니다. 매칭되는 기준은 in-plane에 대한 rotation/translation(scale) invariant해야 하므로 반응이 적어야 하며, out-of-plane에 대한 rotation은 variant하므로 반응이 크도록 합니다.
2. 저도 해당 과정에 대해 흥미로웠는데요, 먼저 PnP 알고리즘을 2D-3D 간 적용하기 위해 4개의 포인트를 사용하였음에도 불구하고 오히려 더 좋지 않은 성능을 보이고 있습니다. 이를 통해 단순히 2차원 RGB 영상들의 매칭으로도 coarse pose estimation을 용이하게 할 수 있다는 가능성을 보여주고 있습니다. 하지만, 건화님의 말씀대로 depth를 고려해야 refinement 과정에 좀 더 의미있지 않나 라는 생각에는 동감합니다.
감사합니다.
좋은 리뷰 감사합니다.
쿼리가 이미지로부터 얻은 렌더링 결과라고 하셨는데, CNOS를 통해 얻은 segmentation 결과로 이해하면 될까요??
‘patch [latex]q_k^i[/latex] 와 여기에 대응하는 템플릿에 대한 patch [latex]t_k^{i}[/latex] ‘에 오타가 있습니다.([latex]t_k^{i*}[/latex])
Training the feature extractor [latex]?_{ist}[/latex] and the MLP 파트에서 i와 i_max를 통해 2D translation을 구할 수 있다고 하셨는데, crop된 이미지와 템플릿을 통해 x,y에 대한 rotation도 예측할 수 있지 않나요..? z축에 대한 정보가 부족하여 translation만을 구하는 것일까요??
그리고 최근 제가 templat matching 방식을 수행하는 방법론을 보고있어서 그런지, 전체 파이프라인에서 F_ae는 coarse한 pose를 구하고 F_ist를 통해 refinement를 수행하는 것으로 볼 수 있지 않을까 하는 생각이 듭니다. 이에 대한 희진님의 생각은 어떠신가요?? 해당 논문에서 이야기하는 refinement는 ICP와 같이 하나의 특정 알고리즘을 의미하는 것인지 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 오타 부분 정정하였습니다. 감사합니다.
2. 2차원 상의 좌표값만을 고려하기 때문에 Z축에 대한 정보는 고려하지 않습니다. 아핀 변환에 따른 파라미터 값을 고려하는 것 자체가 4자유도에 대한 값들을 구하는 것이므로 2차원 이동 변환을 나타내는 x, y 좌표 값은 단순히 구할 수 있지만 rotation, scale은 식(4)와 같이 translation과는 관련이 없습니다. 따라서 분리되어 고려해야 되는 대상이 되므로 추가적인 extractor를 설계하였다고 보시면 되겠습니다.
3. 승현님 말씀대로 그렇게 저도 이해하고 있습니다. refinement 과정 자체가 F_ist를 통해 얻은 아핀 변환 파라미터 값을 알아냄으로써 pose를 refinement를 한다고 보면 될 것 같습니다.
감사합니다.