안녕하세요, 서른 번째 X-Review입니다. 이번 논문은 2024년도 EAAI에 게재된 A fast, lightweight deep learning vision pipeline for autonomous UAV landing support with added robustness입니다. 본 논문은 UAV의 자율적인 착륙을 위해 landing pad를 감지하고 포즈를 추정하는 파이프라인을 제안하는 논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
자율적인 착륙은 무인 항공기(UAV)가 수행하는 테스크 중에 가장 위험한 것들 중 하나로 간주된다고 합니다. 공중에 있는 항공 로봇 등의 주변 환경에 해를 끼치지 않고 안전하게 착륙하는 것은 광범위하게 UAV를 사용하기 위해서는 필수적인 요건이라고 볼 수 있습니다. 착륙을 성공적으로 하기 위해서는 무엇이 필요할까요 ? 착륙 지점을 검출하고 포즈를 추정하고, 목표 지점을 향한 궤적을 계산하고 이를 실행하는 제어 메커니즘이 필요합니다. 이때 정확도도 중요하겠지만 실시간으로 검출하고 실행을 가능하게 하는 빠른 업데이트 속도도 필요하겠죠.
본 논문에서는 UAV 착륙을 위한 비전 기반의 파이프라인을 제안합니다. 이 파이프라인은 UAV가 먼저 착륙 대상 근처에 대략적으로 위치하여 착륙 패드가 온보드 카메라 FoV에 들어온다는 가정하에 동작합니다. 이 가정은 약 3m 오차의 정확도를 제공하는 GNSS(글로벌 항법 위성 시스템)을 사용한다면 쉽게 확인할 수 있다고 합니다. 본 파이프라인은 착륙 패드를 인식하여 착륙 패드 위에 착륙하고, 그 근방에 사람이 없는지 인식하여 사람에 대한 위험성을 미리 방지합니다. 착륙해도 안전하다고 판단이 되면 착륙 패드의 키포인트를 검출하고 이 키포인트의 coordinate를 사용하여 착륙 패드에 대한 상대적인 position을 계산합니다. 또한 실시간으로 동작할 것을 고려하여 모델들은 lightweight하며 착륙 패드가 가려져 있거나, 착륙 패드 영상이 불완전하거나, 모션 블러, 기상 환경 등과 같은 것들을 고려하였다고 합니다. 간단하게 설명드리자면 단순히 ‘go’나 ‘no-go’ 사인을 보내는 것이 아니라 좀 더 착륙을 신중하게 하는 피드백 정보를 생성하도록 하였다고 하네요. 자세한 건 아래 method에서 다루도록 하겠습니다.
2. Methodology and models
2.1. Visual algorithm for UAV precise landing
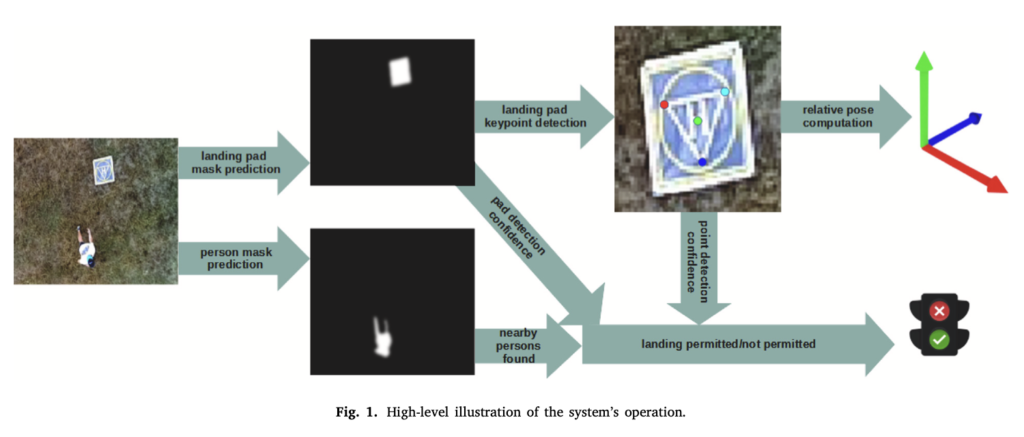
vision 알고리즘에 대한 동작 과정은 위 그림 1에서 확인할 수 있습니다. 처음에 입력 이미지가 들어온다면 segmentation network가 사람의 존재 여부와 landing pad의 존재 여부에 대한 두 개의 probability map을 output으로 내뱉게 됩니다. 이후 미리 사전에 정의한 threshold를 두 확률 맵에 적용합니다. 그 다음에 두 마스크에서 윤곽을 추출해내어 각각 blob을 검출해낸다고 하는데 blob이 뭔지는 잘 모르겠습니다 ㅠ. 찾아보니까 윤곽이 흐릿한 것, 얼룩을 blob이라고 한다고는 하네요 . . .
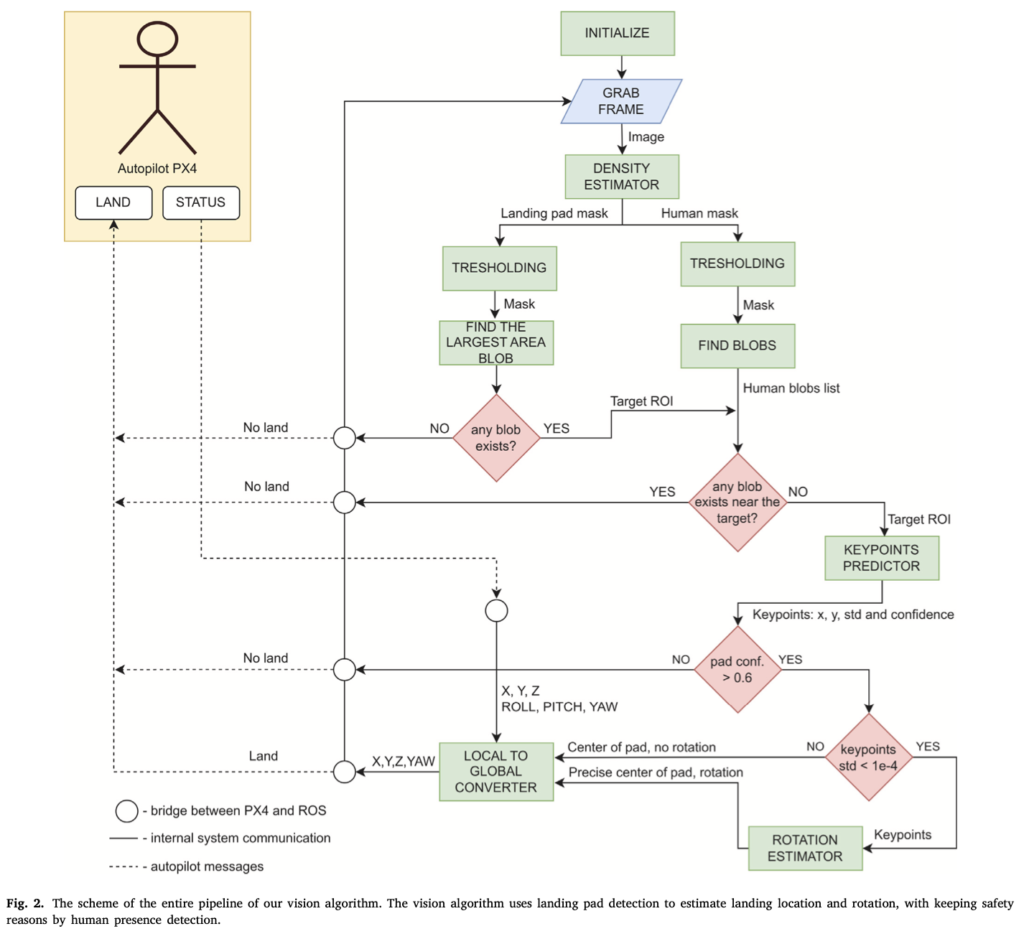
무튼 사람을 인식한 경우, threshold 영역보다 더 큰 blob은 凸남겨둬서 패드에 착륙하는 것이 얼마나 안전한지에 대한 정보를 얻습니다. blob이 존재하고 사전에 pad와의 거리가 미리 설정한 threhold 미만인 경우 착륙 패드 근처에서 한 명 이상의 사람이 관찰된다는 것을 의미하며 착륙 process가 일시 중단됩니다. landing pad blob이 존재하는 경우 표면적이 가장 큰 blob이 keypoint를 검출하는 모델에서 입력으로 들어가도록 RoI로 선택이 되구요. 이 keypoint detector같은 경우 keypoint의 위치와, coordinate variance, keypoint 존재 신뢰도를 output으로 뱉습니다. confidence같은 경우는 이 RoI가 landing pad의 필요한 여역을 커버하는데 사용되며, keypoint의 coordinate variance가 threshold보다 작으면 related pose estimmation 알고리즘으로 추정된 위치가 전달됩니다. 포즈 추정 알고리즘으로는 landing pad의 실제 3D model과 PnP 알고리즘을 사용하여 camera와 target사이의 transformation을 계산하며, 마지막으로는 얻어낸 coordinate랑 yaw rotation을 global 좌표계로 변환합니다. 전체적인 플로우는 그림 2에서 확인할 수 있습니다.
2.2. Human and landing pad mask estimation
저자는 기존의 object detection 알고리즘 같은 경우는 복잡하고 시간이 오래 걸리는 후처리가 있음을 고려할 때 edge AI device에서 동작하면서 사람과 landing pad를 잘 검출할 수 있지 못할 것이라고 생각하였습니다. 이 때문에 segmentation task를 선택하였으며, segmentation 어노테이션 과정에서 서로 다른 어노테이터들 간에 의견이 일치하지 않는 부분이 대부분 object의 boundary 즉, 객체 경계 부근에서 발생하는 것을 알게 되었습니다. 따라서 학습의 안정성을 높이기 위해 kernel의 표준 편차를 1로 설정한 가우시안 필터를 사용해서 segmentation mask를 흐리게 처리한 다음 loss 함수로 cross entropy를 사용하여 학습하였습니다. output으로 나온 각 pixel에는 사람이나 landing pad에 속할 확률이 스케일링 되어있으며, 실험 부분에서는 F1 score과 예측된 마스크와 gt mask 간의 precision 및 recall을 평가 지표로 삼았습니다.
segmentation 모델로는 일반적으로 사용되는 DeepLabv3plus와 UNet과 같은 fcn이 사용되었습니다. 두 모델 모두 encoder-decoder 구조를 갖고 있으며 feature를 추출하는 encoder같은 경우 resnet이나 mobileNetV3, LCNet, MNASNet으로 변경하여 실험 결과를 리포팅하였습니다.
2.3. Regression of landing pad’s keypoints
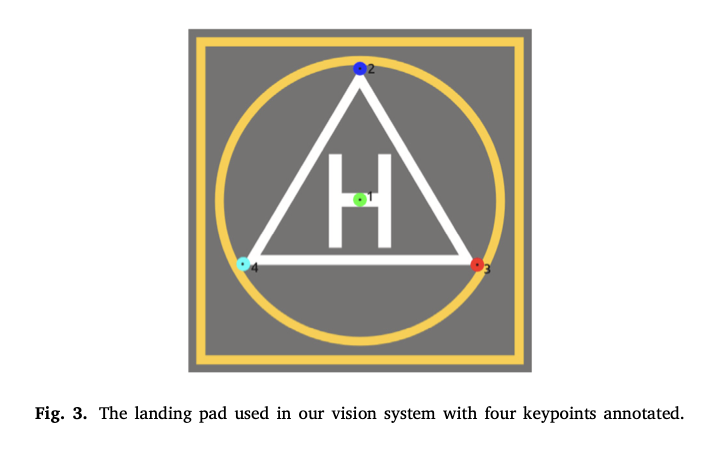
landing pad의 keypoint를 검출하는 신경망 같은 경우, landing pad가 포함 될 것이라고 예상되는 scene에서 128 x 128로 crop해냅니다. 본 논문에서는 아래 그림 3과 같이 총 4개의 서로 다른 keypoint를 정의했는데, 모든 keypoint에 대해 모델은 선택한 RoI에서 point가 표시될 확률과 RoI의 위치 좌표, coordinate의 분산 값을 출력해냅니다.
이 키포인트 검출 모델에 대한 손실 함수는 아래 식1과 같습니다.
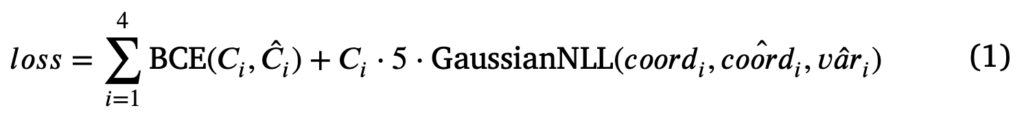
regression을 위한 gaussian negative log-likelihood loss와 confidence를 위해 binary cross entropy로스를 사용하였습니다. 식에서 C_i, \hat{C}_i는 각각 gt keypoint 여부와 예측된 키포인트 존재 여부를 나타냅니다.
2.4. Dataset overview
본 논문에서는 UAV view 영상에서 segmentation을 하려고 했기 때문에 사용할 수 있는 데이터셋이 없었다고 합니다. 그래서 자체적으로 데이터셋을 수집해야 했다고 하며, 딥러닝 모델을 돌리기 위해 많은 양의 데이터가 필요하기 때문에 수집 뿐만이 아니라 어노테이션하는 것이 부담이었다고 합니다. 이런 문제를 극복하기 위해 사전학습 시에는 합성 데이터셋을 사용하기로 하였습니다. 합성 데이터셋은 Unity3D 게임 엔진을 사용하였습니다.

위 그림 4 (a)에서 생성된 합성 이미지를 확인할 수 있으며, (b)는 real-world image입니다. 이는 fine-tuning에서 사용됩니다. Real image같은 경우는 다양한 시간대와 기상 조건에서 668장의 영상을 촬영하였습니다.
3. Evaluation
실험에서는 segmentation 모델과 keypoint detection 모델에 대한 평가 지표를 각각 설정하였습니다. segmentation 같은 경우는 F1 score와 Dice Coefficient를 사용하였는데 둘 다 높을수록 좋은 성능을 의미합니다. 이때 background pixel은 성능 계산에서 제외하였습니다. 또 Keypoint detection 같은 경우 예측된 point와 gt point 사이의 MAE를 측정하였습니다. 추가로 두 모델 각각에 대해서 FPS도 측정하여 실제 UAV에서 사용할 수 있는 신경망 모델인지 확인하였습니다.
먼저 사람과 landing pad에 대한 segmentation 네트워크 실험 결과부터 살펴보도록 하겠습니다.
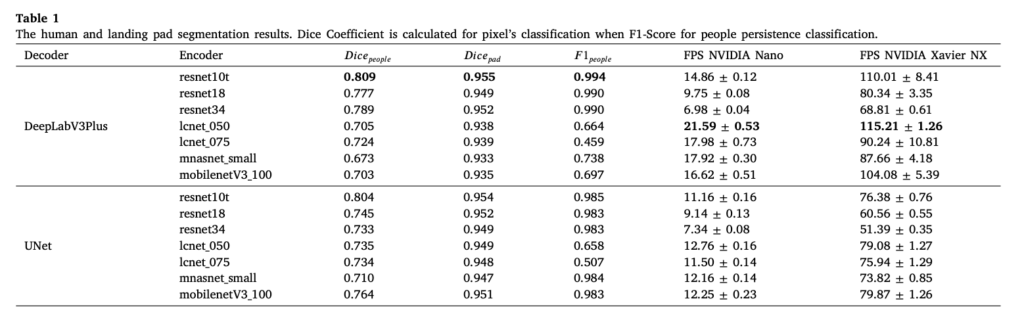
표 1을 보면 F1 score와 Dice coefficient에서 가장 높은 성능을 보인 모델은 ResNet10t 인코더를 탑재한 DeepLabV3Plus입니다. 하지만 일반적으로 DeepLabV3 모델은 임베디드 GPU에서 UNet 아키텍처보다 더 높은 연산량을 필요로 했다고 합니다. 또 LCNet encoder를 사용하는 경우에는 landing pad 근처 사람이 있는 경우 이를 판단하는 능력이 다른 모델보다 떨어진다고 하네요.
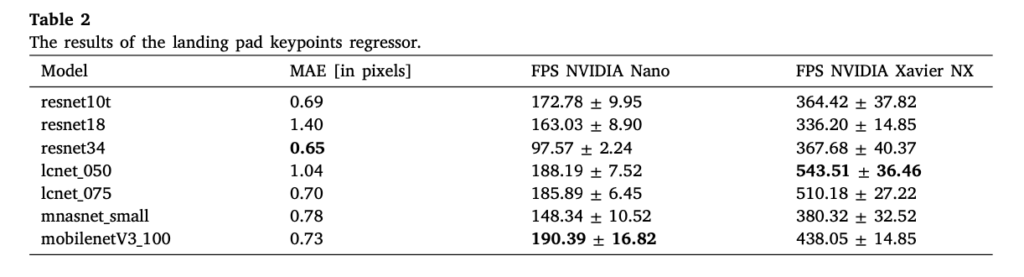
이제 keypoint regression 아키텍처에 대한 성능을 살펴보도록 하겠습니다. 표2를 보면 가장 높은 성능은 resnet34에서 0.65 MAE입니다. 하지만 엔비디아 젯슨 나노에서 FPS는 mobilenetv3_100 모델을 ㅅㅏ용한 경우가 190정도로 가장 높습니다. 이런 결과는 모델이 실시간으로 동작할 수 있음을 시사한다고 볼 수 있겠네요.

마지막으로 정성적 결과 보여드리고 리뷰 마무리하도록 하겠습니다. … 위 그림 7은 키포인트 검출에 대한 정성적 결과인데, 그림자가 있거나 조명이 너무밝은 경우 혹은 노이즈가 있는 경우에도 키포인트를 잘 검출하고 있음을 확인할 수 있습니다. 이런 결과는 본 알고리즘이 빛반사나, 대비 변화, blur 및 그림자 등 실제 환경에서 발생할 수 있는 다양한 환경 조건을 잘 처리할 수 있음을 보여줍니다만, 복잡한 지형이나 악천후 상황같은 경우에는 정확도가 많이 떨어지거나 작동이 불가능할 수 있다는 한계점이 존재합니다.
안녕하세요. 좋은 리뷰 감사합니다.
새로운 분야의 리뷰라 흥미롭게 읽은 것 같습니다. 이 task에 대해서 잘 몰라 질문 수준이 깊지는 않은데, 본 논문의 저자의 경우, object detection 알고리즘이 segmentation task보다 복잡하고 시간이 오래 걸린다고 하는데, object detection 알고리즘의 경우 빠른 알고리즘도 이제는 충분히 많을 것이라 생각하는데 굳이 segmentation으로 방법론을 수행한 이유가 궁금합니다. 아니면 통상적으로 object detection 알고리즘 보다 segmentation 알고리즘이 더 속도가 빠른가요?
감사합니다.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
fast, lightweight 라는 키워드를 보고 읽어보게 되었습니다.
본문의 UAV landing이라는 단어는 처음 접해보았는데 결국 UAV의 안전한 착륙을 위해 주변에 사람이 있는지 찾고, 착륙 지점의 pose를 추청하는 것으로 이해하였습니다.
본문에서 효율적으로 landing pad를 감지하기 위해 semantic segmentation을 사용하고 검출된 roi를 keypoint detection 모델에 입력한다고 하였는데, detection과 segmentation 모델간의 시간이나 연산량을 직접적으로 비교한 실험은 없었는지 궁금합니다.