안녕하세요. 교정기를 빼고 교정 유지기를 차고 오니 발음장애가 생겼습니다. 다행히 글 작성엔 무리가 없습니다. 논문 제목과 동시에 구조도를 보았을 때 제가 실험하려고 하는 바와 유사한 방식으로 보였으며 실제로 본 논문의 방향성만큼은 괜찮아보여 읽게 되었습니다. 다만, 중간 수식이 몇몇 등장하는데 이 수식을 굳이 이해해야하나 싶을 정도로 난해하고 어려웠습니다. 이번 논문은 핵심 내용만을 작성해보려 합니다.
Introduction
OWOD는 Real-World에서 맞닥뜨릴 수 있는 문제를 해결하는, 더욱 어려운 문제로 주목받고 있습니다. Joseph의 ORE (Towards Open World Object Detection)와 Gupta의 OW-DETR (Open World Detection Transformer)은 각각 Faster R-CNN과 DETR을 기반으로 하여 OWOD의 (1) 학습 이외의 (Unseen) 객체를 unknown으로 인지 (2) 해당 unknown에 대해 레이블이 주어지면 다음의 학습 (episode)에서 이들을 known의 한 범주로 인지하는 OWOD의 문제를 풀어보고자 했습니다.
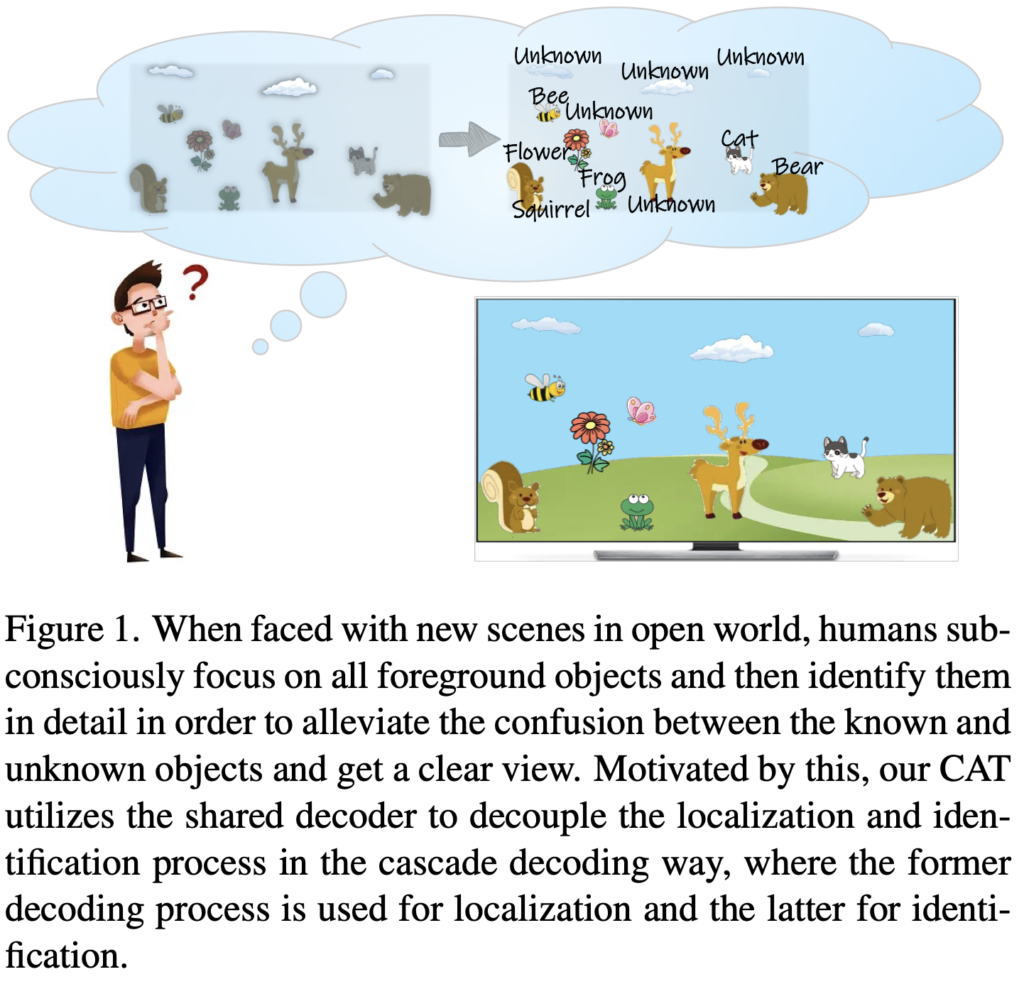
본 논문의 저자는 이들이 모두 PLM, Pseudo Label Mechanism이 필요합니다. RPN (Faster R-CNN)의 objectness score, DETR의 attention map으로부터 구하는 attention score를 통해 특정 객체에 대해 “unknown”으로 레이블링해주는 과정입니다. 하지만 이들의 과정이 결국 모델 연산 과정 중의 feature map에 대해 구한 pseudo-label이므로 텍스쳐, 조도 등의 입력의 사전 정보등이 충분히 활용되지 않았다고 보고 있습니다 (모델도 이들의 정보로부터 시작되었다고 생각드는데 저자는 그보다 이미지 자체에서 생성되지 않아 아쉽다고 생각하나봅니다). 또한, PLM의 고정된 선택 방법 (Top-k)이 unknown에 대한 좋은 pseudo-label을 생성하기 어렵다고 보고 있습니다. 맨 위의 Figure 1도 사람이 foreground의 object들에 대해 localization을 수행한 이후 순차적으로 그들의 자세한 정보를 인지한다고 봅니다.
이외에도 unknown을 찾고자하는 노력이 오히려 known을 검출하는데 방해가 된다 (즉, known과 unknown 사이의 구별력이 약하다)며, 사람이 물체를 검출하는 과정이 localization과 classification (indentification)이 병렬적으로 분리된다는 연구를 통해 검출 시 regression과 classification을 분리하고자 노력 (추후 다시 언급하겠지만, 디코더를 따로 둡니다)합니다.
Proposed method
t-시간의 known과 unknown, 이외의 incremental learning 등의 과정을 담은 problem formulation에 대해선 이전 논문 리뷰(OW-DETR)에서 상세히 다루었으므로, 바로 architecture로 넘어가서 살펴보겠습니다.
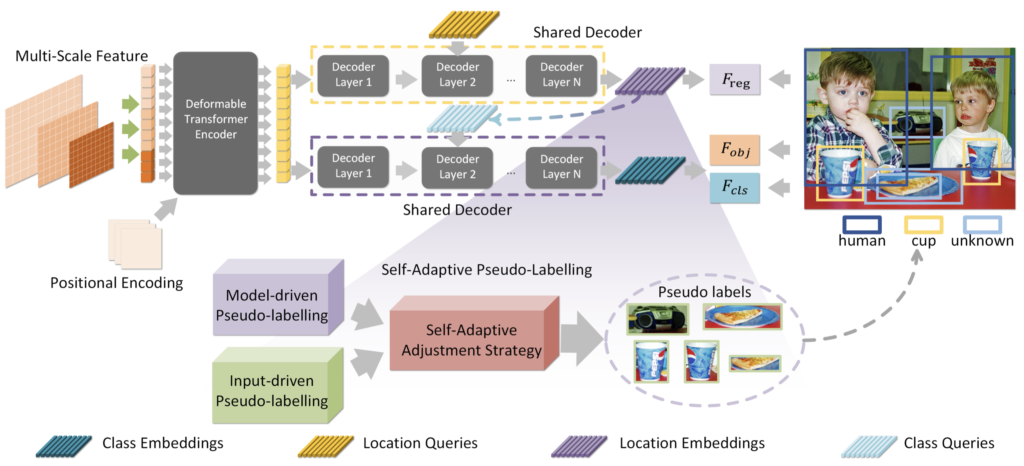
중간의 거대한, 너무 이해하기 어려운 수식이 하나 있지만, 이는 크게 다루지 않고 핵심을 위주로 살펴보겠습니다. 위 architecture을 살펴보면 OW-DETR을 따라 Deformable DETR을 기반으로 설계하였습니다. 입력 이미지 \mathcal{J} \in \mathbb{R}^{H \times W \times 3} 에 대해 백본 네트워크로부터 multi-scale feature ( Z_{i} \in \mathbb{R}^{\frac{H}{4 \times i^{2}} \times \frac{W}{4 \times 2^{i}} \times 2^{i}C_{s}}, i = 1, 2, 3 )를 추출합니다. 추출한 세 feature map은 1×1 convolution을 통해 C_{d} 차원으로 projection 시킨 다음, 이들을 concat하여 N_{s} 의 벡터를 생성합니다. 해당 벡터를 DETR의 encoder와 decoder에 통과시키는데, decoder를 살펴보면 위 브랜치와 아래 브랜치로 나뉩니다.
나뉘는 브랜치는 각각 regression (localization)과 identification (objectness + classification, objectness는 objectness score를 추출하는 부분으로, classification에 합친 개념으로 소개하겠습니다)에 대한 브랜치로, 동일한 encoder로부터 semantic한 정보를 추출해냄은 동일하나, 각 브랜치를 통해 다른 역할을 수행합니다. 이 때, detection 태스크에서 classification은 regression과 전혀 다르게 수행할 수는 없는데 (어떤 bounding box에 대한 클래스를 분류하므로), 그러므로 regression branch의 deocder query가 identification branch에 더해져 분류를 위한 객체의 공간 상 정보를 주고 있음을 알 수 있습니다. 저자는 이 과정을 “Cascade Decouple Decoding Way”로 명합니다. 수식은 아래와 같이 설계됩니다.
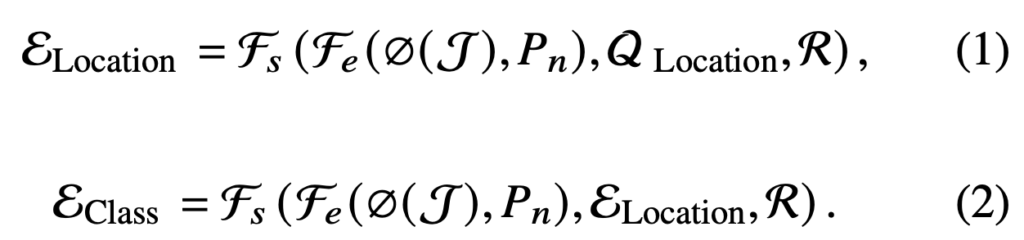
\varepsilon_{Location} 에 대해 \mathcal{F}_{s} 는 decoder, \mathcal{F}_{e} 는 encoder, \emptyset 은 backbone, P_{n} 은 positional encoding, \mathcal{R} 은 Deformable convolution의 reference point에 해당합니다.
다음은 Self-adaptive Pseudo-labeling Mechanism입니다. 문제의 수식 부분인데, 그 보다 제가 중요하게 여긴 점은 기존의 방법이 model-driven pseudo-labeling으로 마쳤다면, 저자는 input-driven pseudo-labeling 즉 입력 이미지로부터 selective search를 통해 pseudo-unknown을 생성한 이후 (물론 model-driven pseudo-unknown도 생성합니다), 이 둘 간의 IoU를 통해 교집합을 pseudo-unknown으로 생성합니다. 저자는 이 과정을 통해 더 신뢰성 있으며 동시에 입력 이미지의 특성을 고려할 수 있음을 언급합니다. 제가 아쉬운 점은 그러면 합집합으로 쓰지, 왜 교집합을 택하였는지 아쉽습니다.
이후 pseudo-unknown에 대한 confidence score를 소개하여 이 과정이 adaptive하게 변하는 weight으로 소개하는데, 이 과정에서 수 많은 수식이 사용됩니다. 한번 논문을 보셔도 좋겠지만, 제가 그 수식을 이해하지 못했음에도 본 논문의 리뷰를 쓴 점은 문제 정의를 통해 input-driven pseudo-unknown을 제안하는 부분때문입니다. 저 또한 RGB 영상 외의 다른 정보를 추가한 pseudo-unknown을 생성하려 하는데 본 논문의 문제 정의를 빌릴 수 있지 않을까도 싶습니다.
Experiments

OW-DETR과 비교한 정성적 비교입니다. 결국 저자의 주장은 “input-driven pseudo-unknown을 생성한 후, model-driven pseudo-unknown과 교집합하여 더 품질 높은 unknown 후보군을 생성하겠다”로 보이네요. 제가 위에서 언급한 “왜 합집합이 아닌 교집합을 사용했을까”에 대한 의문이 이렇게되면 조금 해소됩니다.
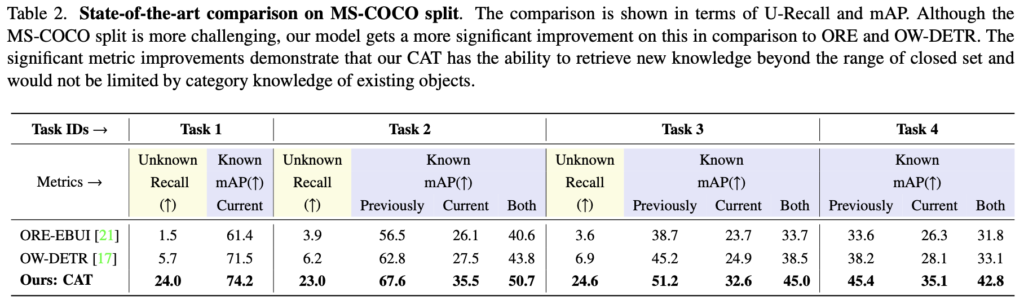
OWOD의 핵심 성능 표 (Pascal VOC와 MS-COCO를 활용한)입니다. 더 많은 모델들이 존재하지만, 이렇게 시초의 논문들과 비교하니 성능이 무려 24배, 5배가 더 좋아진 것처럼 보이는 효과도 있네요 허허. 주목할 점은 Unknown Recall입니다. 저자가 제안하는 pseudo-labeling이 unknown에 대한 탐지를 굉장히 효과적으로 만들었다고 보여집니다.
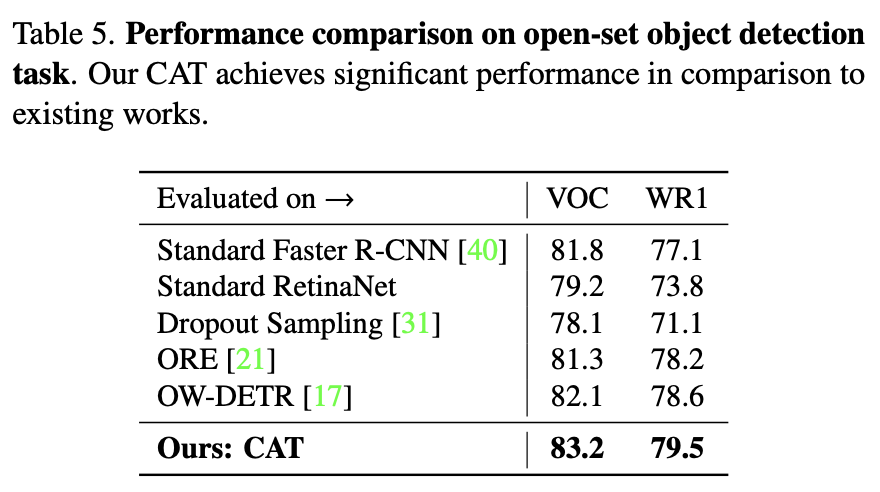
마지막으로 open-set object detection에 대한 성능입니다. 가끔 몇몇 논문에서 OWOD 외에 open-set object detection에서도 성능을 보이는데 음, 개인적으로 실험을 얼마나 잘 하는지도 굉장히 중요해보이네요. 이번 논문은 위의 input-driven pseudo-labeling을 주요하게 살펴보고자 한, 그리고 제가 예전에 생각한 “localization과 classification을 분리해야함”이 보여진 논문이여서 꽤나 심각하게 (제 컨셉과 겹치나 싶어) 읽어보았습니다. 다만, 물론 저자가 adaptive한 weight을 소개하긴 하는데 이 개념이 수학적으로 굉장히 어려워 제게는 다소.. 막 와닿진 않았던 것 같습니다. 리뷰 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
사람이 물체를 검출하는 과정이 localization과 classification이 병렬적으로 분리된다는 연구를 통해서 이를 분리하고자 노력했다고 하셨는데, 이 사람이 물체를 검출할 때 localization과 classification이 병렬적으로 분리한다는 연구에 대해 좀 더 자세히 말씀해주실 수 있을까요 !??! 본문에서는 detection task에서 classification은 regression과 전혀 다르게 수행할 수 없다고 했는데 사람은 이를 전혀 다르게 수행하는 건가요 ?
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
OWOD task에 대한 설명을 보니 제가 이제야 보기 시작한 OVOD와는 완전히 다른 task라는 것이 느껴지네요.
기존 방법론이 사용한 pseudo label 기반의 unknown 박스 탐지 과정에 대한 질문이 있습니다.
Faster RCNN의 objectness score나 DETR의 attention score로부터 해당 박스를 unknown으로 지정하는 기준이 무엇인가요?
또한 unknown이 오히려 known의 구별력을 방해한다는 것이 모델이 쉽게 known 중 특정 클래스로 분류할 수 있었는데 기존의 unknown 검출 방식에 따라 unknown으로 빠져버릴 수 있다는 의미인가요?