안녕하세요.
오늘 리뷰할 논문은 CVPR 2024에 accept된 따끈따끈한 논문입니다.
Thermal Object Detection을 수행하는데에 있어서 RGB의 정보를 함께 사용해 UDA를 수행하는 논문이며, 제가 현재 진행중인 task와 매우 유사도가 큰 주제입니다.
위 논문은 아주대학교 황원준 교수님 연구실과 현대자동차와의 산학 과제를 통해 작성된 논문이며, 그렇기 때문에 저자들 중 아주 익숙하고 반가운 분이 계십니다 ㅎㅎ.
각설하고, 리뷰 시작하도록 하겠습니다.
1. Introduction
아무래도 CVPR에서 thermal 센서가 그다지 친숙하지 않을 수 있기 때문에 본 논문의 Intro 첫 문단의 상당 부분을 thermal 센서 도입의 필요성 및 정당성에 대해 서술하고 있습니다. 해당 내용은 저희가 잘 아는 그런 내용들이기 때문에 생략하겠습니다.
(조명, smoke, nighttime 등 환경에서의 robustness를 위해 thermal 도입~~~)
본 논문에서는 RGB에 비해 강인한 센서인 thermal 센서를 사용해서 Object Detection을 수행하고자 합니다. 하지만 labeled thermal dataset이 매우 부족하기 때문에 여러 한계들이 존재하고, 이를 해결하기 위해 큰 규모의 labeled RGB dataset로 부터 학습된 모델을 사용하고자 합니다. 그리고 이 과정에서 RGB->Th UDA가 수행되는데, 이것이 본 논문에서 수행하고자 하는 핵심적인 task이죠.
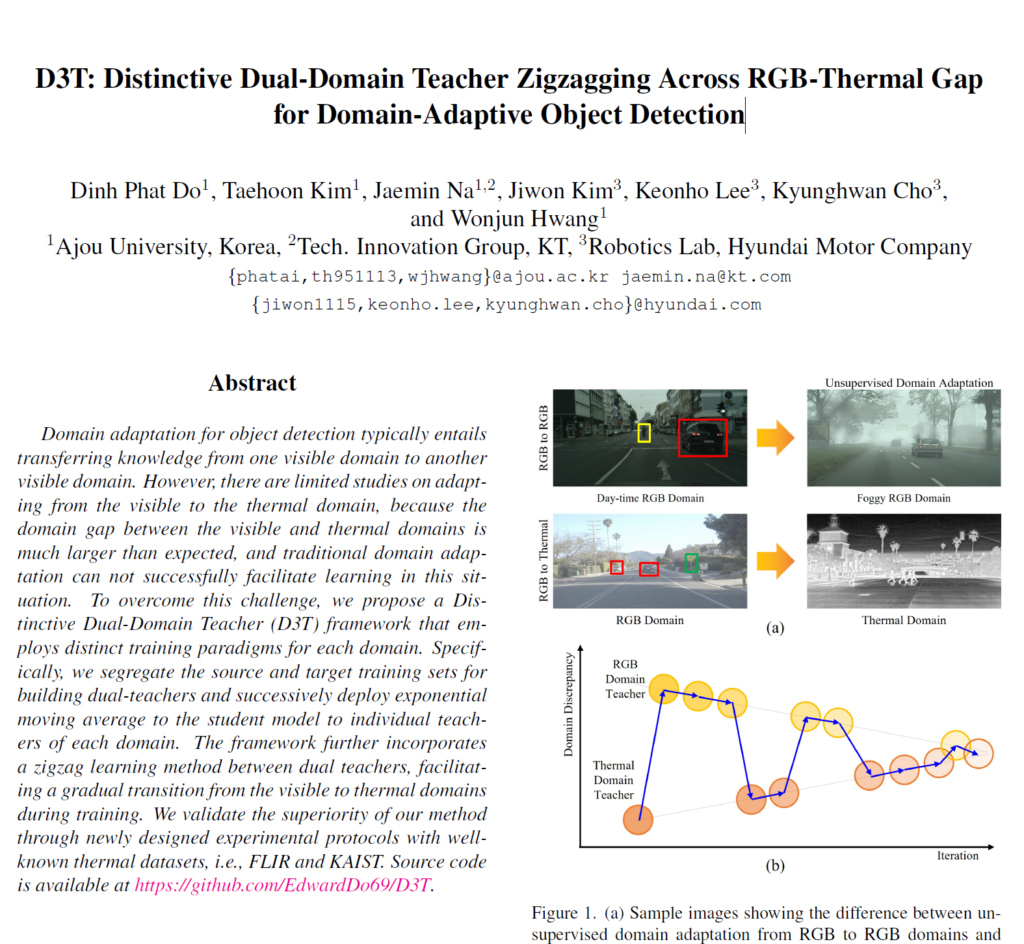
UDA 연구는 여러 task (detection, segmentation,,) 등에서 매우 활발하게 이루어 지고 있습니다. Object Detection (OD) 분야에서도 매우 활발하게 이루어지고 있죠. 하지만 OD 내 대부분의 UDA 연구들은 source를 일반적인 RGB scene, target을 foggy 등의 열악한 RGB scene으로 설정하여 adaptation을 수행하고 있습니다. 아래 그림의 위쪽 (1st row) 처럼 말이죠.
하지만 위 그림의 아래쪽 (2nd row) 에서 보시는 것과 같이 RGB->Th 사이의 adaptation을 수행하고자 하는 본 논문의 관점에서, RGB와 Th 사이에는 상당히 큰 gap이 존재하기 때문에 일반적인 RGB->foggy RGB 에서 사용되는 기법을 그대로 적용하게 되면 한계점이 존재하게 된다고 주장합니다.
Contribution 1: D3T framework
RGB->Th로의 UDA 수행을 위해 본 논문에서는 Semi-Supervised 및 UDA에서 자주 사용되는 Mean Teacher 개념을 도입하여 Distinctive Dual-Domain Teacher (D3T) 라고 하는 새로운 기법을 설계하게 됩니다. 이것이 첫번째 contribution 입니다.
이름에서도 알 수 있다시피 RGB와 Thermal 각 domain 별로 개별적인 mean teacher를 구성하여 자기 자신에 대한 domain-specific 정보를 학습하도록 합니다.
RGB mean teacher는 RGB specific 정보를, Th mean teacher에서는 Thermal specific 정보를 말이죠.
Contribution 2: Zigzag Learning Method
본 논문에서는 Thermal Object Detection을 수행하기 위해 큰 규모의 RGB dataset을 source로, 그리고 Thermal dataset을 target으로 설정합니다.
그리고 일반적인 Mean Teacher 방식과는 달리, 본 논문에서는 RGB & Thermal Mean Teacher를 따로 구성하게 됩니다. (cont 1)
그렇다면 이렇게 설계한 domain별 mean teacher를 사용해서 어떻게 adaptation을 수행하게 될까요? 이와 관련된 learning 기법이 2번째 contribution 입니다.
저자들은 Zigzag Learning 이라고 하는 학습 기법을 설계하게 됩니다.
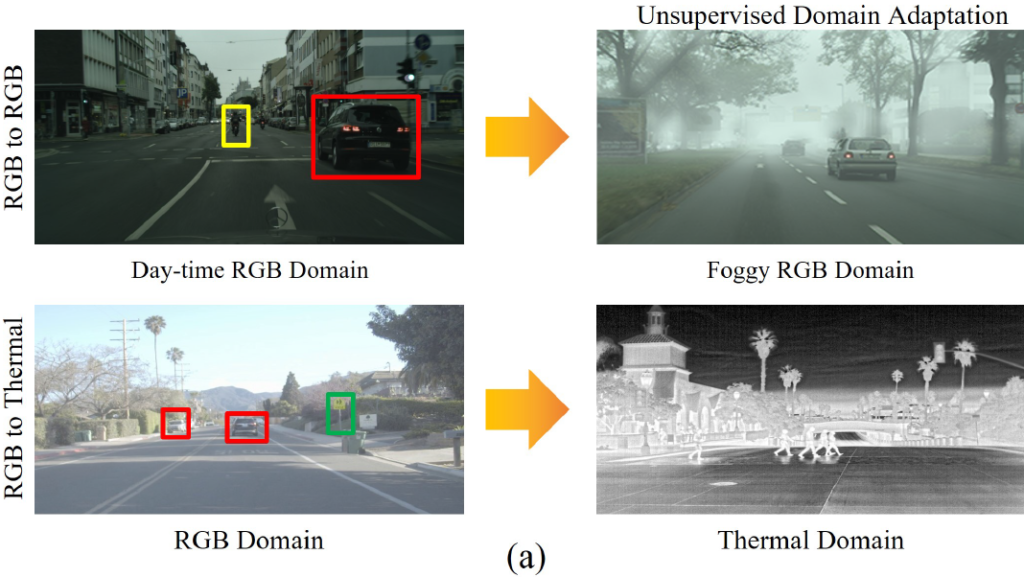
Zigzag(지그재그) 라는 이름에서 아실 수 있다시피, RGB와 Thermal mean teacher 둘 중 하나를 번갈아가면서 선택해서 adaptation 과정을 수행합니다.
또한 adaptation과정 수행 전 모델의 pre-trained에 사용되는 dataset이 RGB 이미지로 구성되어있다 보니, 초기 예측의 정확도는 Thermal mean teacher보다 RGB mean teacher의 정확도가 상대적으로 정확합니다. 그리고 점차적으로 학습이 진행될 수록 thermal teacher의 성능이 더 향상되게 되구요. (RGB->Th adaptation이기 때문에)
그래서 Zigzag Learning 과정 속 두 domain의 mean teacher중 하나를 선택할 때 단순히 번갈아가면서 선택하는 것이 아닌, 횟수에 대한 가중치를 조금 다르게 줍니다. 학습 초반에는 RGB mean teacher를 더 많이 선택하고, 후반부로 갈 수록 Thermal mean teacher를 더 많이 선택하는 방식으로 말이죠. 이를 잘 나타내주는 그림은 아래와 같습니다.
Method 부분에서 한번 더 설명드릴 예정이니 가볍게 보고 지나가셔도 됩니다.
2. Method
2.1. Preliminary – Mean Teacher
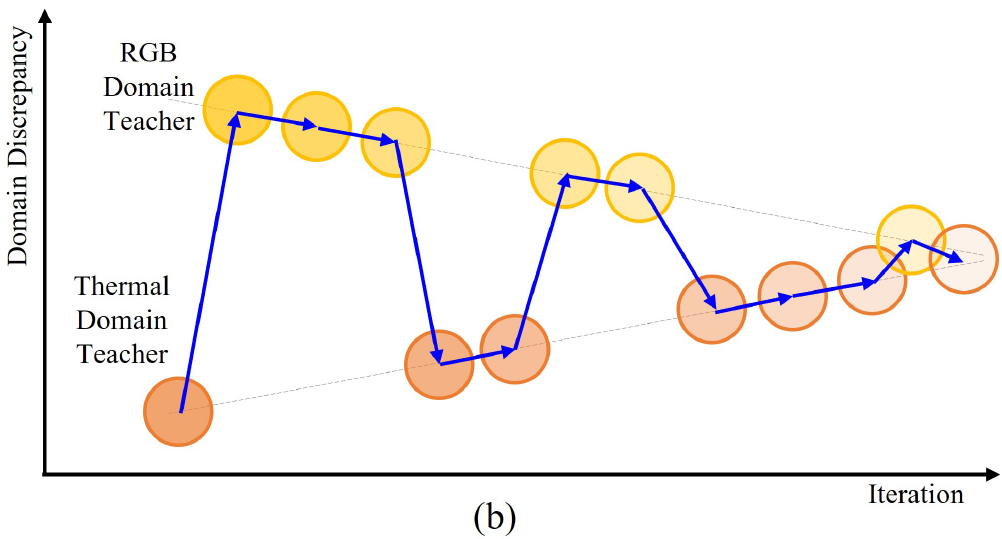
Mean Teacher가 적용된 framework는 크게 teacher 모델과 student 모델로 구성됩니다.
이 중 teacher 모델은 우선 labeled source dataset으로 pre-trained을 시키는 과정을 거치게 됩니다.
그리고 teacher가 생성해 내는 target domain을 위한 pseudo label을 사용해서 student 모델의 optimizing과 함께 parameter update가 수행되게 됩니다.
이때 teacher 모델에 mean teacher 방식이 도입되는데, mean teacher의 parameter는 optimizing을 통해 학습이 되는 것이 아니라, 매번 time steps에 대한 sutdent 모델의 parameter 를 누적하여 EMA update 하는 방식으로 구성됩니다. 즉 학습이 진행되는 과정 속 student 모델들의 앙상블 결과라고 보시면 됩니다.
이를 학습과정 시 data의 흐름 관점에서 다시 살펴보겠습니다.
우선 source dataset으로 teacher 모델을 pre-trained 시키고, 학습된 parameter를 동일하게 student에 복사합니다. 이후 학습 수행 시 source data와 target data가 모두 학습에 사용되는데 각각에 대해 나눠보자면,,
i) source domain data
source data에 strong & weak augmentation 중 하나를 부여해서 student 모델에 대해 supervised 학습을 수행합니다. source data의 경우 x 와 y가 모두 존재하기 때문에 가능한 것이겠죠.
즉, source domain data는 student 모델로만 forward 연산이 수행됩니다.
ii) target domain data
target data는 student와 teacher 모델 모두에 대해 forward 과정이 수행됩니다.
다만 이때 pseudo label을 생성하는 teacher 모델에는 생성하게 될 pseudo label의 안정성을 위해 weak augmentation을 적용한 이미지가 입력으로 들어가게 되고,
student 모델은 조금 더 다양한 표현력을 학습하기 위해 strong augmentation을 적용한 이미지가 입력으로 들어가게 됩니다.
위 i, ii에 대해 loss를 계산하면 아래와 같습니다.
L_{src}는 source data에 대한 supervised loss이며, L_{tgt} loss는 teacher의 예측, 즉 pseudo label과 student 예측 사이의 loss 입니다.
구체적으로 어떠한 loss가 사용되는지는 task와 달라지며, 전체적인 구조는 아래로 보시면 될 듯 합니다.
(아래 그림은 본 논문의 그림이 아닌 구글링으로 가져온 그림이므로, 간단히 참고용으로만 보세요)
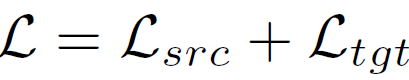
위에서도 언급드렸다시피 loss function을 통해 최적화가 진행되는 모델은 student 모델입니다.
Mean Teacher는 학습이 되는 모델이 아니며, 아래 수식을 통해 student parameter를 EMA 계산하여 update가 수행되게 됩니다.
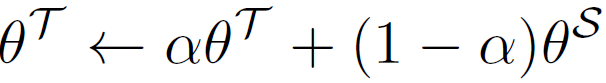
통상적으로 parameter \alpha 는 0.9 이상의 값을 사용하며, 본 논문에서는 0.9996의 값을 사용했다고 하네요.
2.2. Distinctive Dual-Domain Teacher (D3T)
Object Detection 분야에서 UDA를 수행하는 앞선 연구들은 대부분 RGB->Foggy RGB 로의 adaptation을 수행하도록 모델을 설계했습니다. 그렇기 때문에 Mean Teacher를 하나만 사용하였죠.
하지만 본 논문에서는 RGB와 Thermal 사이의 domain gap이 꽤나 상이하기 때문에 공통된 mean teacher를 하나만 사용하게 되면 꽤나 모델 학습에 부정적인 영향을 끼칠수 있다고 주장합니다.
그리하여 본 논문에서는 Distinctive Dual-Domain Teacher (D3T), 즉 각 domain별로 Mean Teacher를 개별적으로 구성합니다. 제안하는 D3T의 전체 구조는 아래와 같습니다.
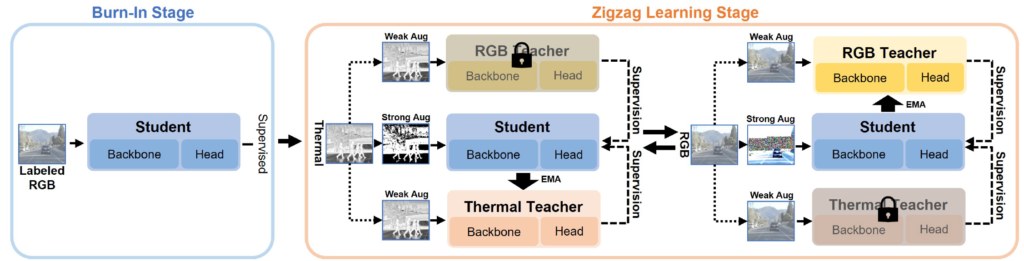
Separate Teachers
해당 방법의 핵심은 RGB mean teacher 그리고 Thermal mean teacher를 개별적으로 구성하는 것입니다. 그리고 각각의 mean teacher들은 자신 domain의 이미지가 forward될 때 student에 의해 paramter update가 수행되게 됩니다.
RGB 이미지가 입력으로 들어오게 된다면 이를 통해 학습된 student 모델이 RGB mean teacher를 update 시키고, 반대로 Thermal 이미지가 입력으로 들어오게 된다면 학습된 student 모델이 Thermal mean teacher를 update 시키는 그런 방식이죠.
Learning knowledge from Dual-Teachers
학습이 진행될 때 RGB 영상과 Thermal 영상을 모두 사용하게 됩니다.
이들은 함께 forwarding 되는 것이 아니라 개별적으로 연산이 수행되기 때문에 loss function 또한 개별적으로 설계되어야 합니다. 아래에서 설명드릴 loss function을 통해 student 모델의 학습이 이루어지는 것입니다.
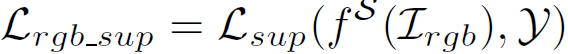
- I_{rgb}: 입력 rgb 영상
- f^S: student 모델
- y: gt 정보
RGB 영상, 즉 source data가 입력으로 들어가는 경우는 간단합니다. 그냥 ground truth와의 supervised loss를 계산하면 되는 것이죠.
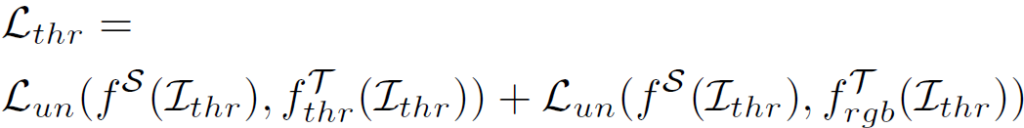
- I_{thr): 입력 thermal 영상
- f^T_(thr): Thermal teacher 모델
- f^T_(rgb): RGB teacher 모델
다음은 thermal 영상, 즉 target data 입니다.
thermal 영상은 대응되는 gt가 없기 때문에 pseudo label을 생성해서 loss를 계산하게 됩니다. 그리고 이 pseudo label은 teacher 모델로부터 구해지게 되죠.
음,, 다만 여기서 제가 아직 이해가 덜 된 부분은 위 loss fuction 내 2개의 term 중 뒤쪽 term에 대한 부분입니다. thermal 영상이 입력으로 들어갔을 때 student의 예측과, rgb teacher의 예측 사이의 unsupervised loss를 계산하는 부분인데요,, 아직 정확하게 rgb teacher를 왜 사용했는지에 대해서는 이해를 하지 못한 상황입니다.
2.3. Zigzag Learning Method
다른 일반적인 UDA 연구들에서는 보통 source 와 target domain에 대해 학습을 동시에 수행하게 됩니다. 이 말이 뭐냐함은, 두 domain의 영상을 동시에 각 모델로 forward 시켜서 loss를 계산한다는 뜻입니다.
하지만 본 논문에서는 RGB와 Thermal 사이의 domain gap 때문에 동시에 학습하지 않고 새로운 방식을 제안하게 됩니다. zigzag로 말이죠.
Distinctive Training
Zigzag learning 기법에서는 각 doamin의 개별적이고 specific한 지식 학습을 위해 RGB와 Thermal 에 대해 개별적으로 학습(forward 과정) 을 수행하게 됩니다.
RGB 영상이 입력으로 들어오게 되면 thermal은 고정한 채 RGB mean teacher에 대한 parameter 만 EMA update를 수행하고, thermal 영상이 입력으로 들어오면 그 반대로 thermal mean teacher만 update 되는 것이죠.
Progressive Training Transition
Zigzag, 이름에서 느껴지는 것은 RGB와 Thermal를 번갈아가면서 학습하나보다~ 라고 느껴지실 겁니다. 맞긴 합니다만 본 task의 목적을 다시 살펴볼 필요가 있습니다. 바로 UDA, RGB source에서 Thermal target으로의 adaptation을 수행하는 것입니다. 그 말은 즉슨 모델이 초기 pre-trained된 dataset은 RGB dataset이고, 학습 초반부에는 thermal 대비 rgb의 예측이 훨씬 더 정확도가 높다는 것이죠.
그리고 성공적으로 adaptation이 수행된다면, 후반부로 갈 수록 thermal 의 performance가 오르기를 기대할것입니다.
그렇기 때문에 각 domain별 teacher update 횟수를 변경해 나가면서 RGB에서 thermal로의 adaptation을 수행하게 됩니다. 단번에 바뀌는 것이 아니라 횟수가 천천히 점차적으로 변경되기 때문에 smooth domain adaptation이라는 용어도 사용하네요. 아무튼 아래 그림을 참고하시면 됩니다.
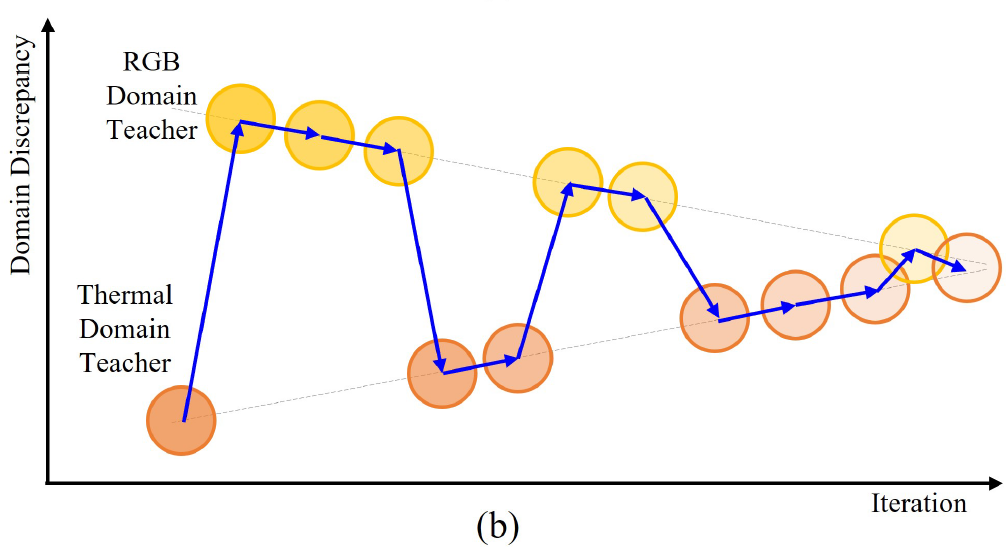
위 그림을 보시면 RGB domain teacher의 선택 횟수는 3->2->1 순으로 줄어드는것을, 반대로 thermal domain teacher의 선택 횟수는 1->2->3 순으로 늘어나는 것을 알 수 있습니다.
위 과정을 통해 점차적으로 thermal domain (mean) teacher의 선택 및 update 빈도를 높이면서 RGB->Th의 smooth DA가 가능해지게 됩니다.
2.4. Incorporating Knowledge from Teacher Models
2.2절에서 설명드리길, 입력 RGB 영상에 대해서는 ground truth와의 supervised loss를 계산한다고 하였습니다. 아래 식을 통해서 말이죠.
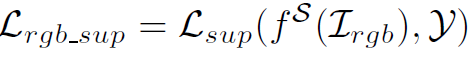
리뷰 앞쪽에서 설명 드렸다시피 Mean Teacher의 학습 컨셉 상 student의 입력으로는 strong aug 이미지가 들어가서 예측을 수행하게 됩니다. 여기서 단순 이 예측값을 ground truth y 하고만 비교하게 되면 ground truth label의 복잡성 때문에 student 모델이 효과적으로 학습될 수 없다고 저자는 언급합니다.
(사실 잘 와닿지 않았습니다..)
그래서 rgb에 대한 학습 수행 시 ground truth y 뿐만 아니라 mean teacher의 예측인 pseudo label과의 loss도 추가적으로 계산한다고 합니다.
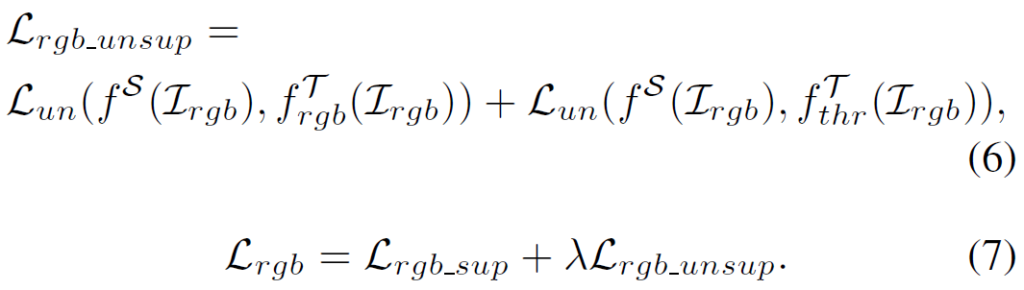
L_{rgb_unsup} 이 mean teacher의 예측을 pseudo label삼아 loss를 계산하는 부분이고, 이는 2.2절에서 설명드린 thermal를 학습시키는 L_{th}와 형태가 유사합니다.
다만 L_{rgb} 는 이에 더해 gt와의 loss인 L_{rgb_sup}을 함께 고려해서 최종 loss를 계산하게 되죠. 이 둘은 \lambda 의 비율로 결합됩니다.

사실 실험섹션에서 설명드려야할 부분이긴 한데,,, 미리 가지고 왔습니다.
\lambda = 0, 즉 오로지 ground truth y와의 loss만 고려할 때 68.46의 성능을 보입니다.
그리고 \lambda = 1, 각 domain별 mean teacher의 예측을 pseudo label 삼아 계산한 loss를 동일 비율로 섞으니 성능의 하락이 매우 크네요.
다만 학습이 진행되면서 \lambda 값을 0->1로 향상시키니 69.30, 기존 대비 약 1의 성능향상이 있었다고 합니다. 이는 학습이 진행되면서 RGB-Thermal 사이의 domain gap을 점차적으로 완화했기 때문이라고 합니다.

전체적인 알고리즘 입니다.
iteration이 돌면서 만약 thermal teacher가 선택이 되었다면 L_{th} 를 계산해서 student 모델을 학습시킨 후, thermal teacher 모델을 EMA update 해 줍니다.
그리고 만약 RGB teacher가 선택이 되었다면 반대로 L_{rgb}를 계산해서 student 모델을 학습시킨 후, RGB teacher 모델을 EMA update 해 줍니다.
여기서 thermal teacher를 선택할 지 RGB teacher 를 선택할 지의 여부는,
초기에는 RGB의 선택을 더 많이 하고 학습이 진행됨에 따라 Thermal의 선택 횟수를 늘려나갑니다.
3. Experiment
실험에서는 FLIR Dataset 및 KAIST Dataset을 사용하였습니다.
본 논문에서 수행하는 task가 RGB->Thermal UDA 이기 때문에
i) RGB→Thermal FLIR evaluation
ii) RGB→Thermal KAIST evaluation
이렇게 개별적으로 학습 및 평가를 진행합니다.
실험 세팅에서 흥미로운 부분이 있는데, FLIR와 KAIST와 같은 RGB-Th pair dataset을 그대로 pairwise하게 사용하게 되면 모델이 overfitting이 될 수 있어서 UDA의 성능 체크에 방해가 될 수 있다, 부정확하다 라고 언급하게 됩니다.
그래서 저자들은 효과적인 UDA 향상 폭 체크를 위해 일부러 RGB, Th를 pair하지 않게, disjointed images로 사용했다고 합니다.
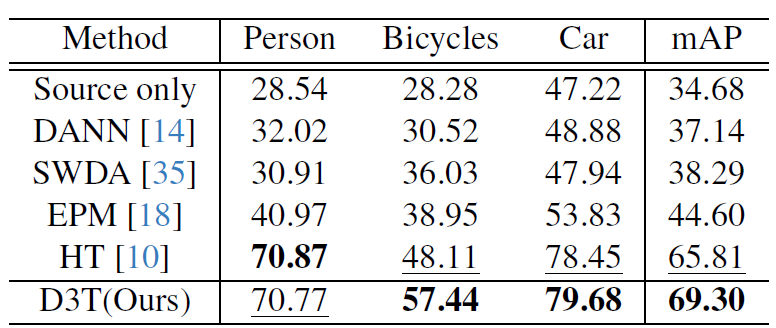
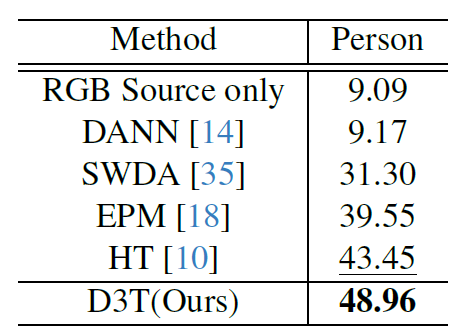
위 실험들은 순서대로 FLIR, KAIST Dataset에서의 실험 결과입니다.
(평가지표는 Detection mAP 입니다)
위에서 D3T(Ours)를 제외한 타 방법론들은 원래 RGB->Foggy RGB를 수행하던 연구들인데, 저자들이 re-implementation을 한 결과입니다.
저자들이 위 table을 통해 보여주고자 한 바는,
‘RGB와 Thermal 사이에는 생각보다 domain gap이 크기 때문에 mean teacher를 하나로 구성하면 안되고, 우리처럼 개별적으로 구성해서 learning 을 해야해~’
입니다.

그리고 위 작은 table은 supplementary에 있는 실험이긴 한데,
Ours 방법론을 기존 RGB->Foggy RGB 세팅에 적용했을 때의 성능입니다.
기존 SOTA였던 AT 라는 방법론을 뛰어 넘네요..
해당 table을 통해 저자들이 설계한 방식이 기존 실험 방식에서도 강건하게 동작한다는 것을 보여주고 있습니다.

위 시각화 결과는 mean teacher들이 예측하는 pseudo label 결과를 시각화한 것입니다. 각각,
(a): 학습 초반부 – RGB teacher
(b): 학습 초반부 – Thermal teacher
(c): 학습 후반부 – RGB teacher
(d): 학습 후반부 – Thermal teacher
의 예측입니다.
학습 초반, (a)와 (b)를 살펴보면 각 domain 별로 조금은 상이하고 부정확한 pseudo label을 뽑아내는 것을 볼 수 있습니다. 그러다가 학습 후반부 (c)와 (d)를 살펴보면 각 domain별로 매우 유사한 pseudo label 예측을 하는것을 볼 수 있습니다. 이는 저자들이 설계한 D3T 알고리즘이 domain gap을 잘 줄여나갔다는 것을 보여줍니다.

그리고 위 table은 zigzag learning 방식에서, 학습이 진행됨에 따라 Thermal mean teacher의 선택을 점차적으로 늘려나가는 방식에 대한 실험 결과입니다. 그리고 Fix 50은 RGB mean teacher 50번 Thermal 50번 이렇게 번갈아가면서 고정적인 횟수로 선택한 것이죠.
위 실험을 통해 점차적으로 Thermal의 비율을 늘려나가는 것이 UDA적 측면에서 꽤나 효과가 있음을 보여주고 있습니다.
네, 오늘은 Detection 분야에서의 RGB->Th UDA 논문에 대해 읽어봤습니다.
mean teacher를 각 domain별로 2개 구성했다는 점은 꽤나 흥미롭고 novelty가 있다고 느껴졌습니다. 그리고 zigzag 방식도 꽤나 직관적이면서도 효과가 좋았습니다.
사실 방법론이 그렇게 복잡하지 않고 매우 직관적인데 CVPR에 붙은걸 보니, 복잡하고 어려운것만이 정답이 아니라 정말직관적이고 깔끔한게 좋은가봅니다.
리뷰 마치겠습니다 감사합니다.
석준님 안녕하세요!
좋은 리뷰 감사합니다!
UDA라는 생소한 분야에 대해서, 기초부터 상세히 설명해주셔서 감사합니다.
첫번째는 2.2. Distinctive Dual-Domain Teacher (D3T)의 Learning knowledge from Dual-Teachers 파트에서 RGB 영상이 입력으로 들어가는 경우에서 GT값이 augmentation이 적용되지 않은 원본 RGB영상인 것 인가요? 아니면 RGB 이미지에 싱크가 맞춰진 Thermal이미지인 것인가요?
두번째는 target domain teacher모델이 생성하는 pseudo label이라는 것이 무엇인지와 이것이 왜 Thermal의 GT로써 이용될 수 있는 지 궁금합니다.
세번째는 2.3. Zigzag Learning Method의 Progressive Training Transition파트에서 학습을 거듭할 수록 RGB와 Thermal간의 domain gap이 줄어드는 것을 시각화한 그림이 있습니다.
해당 이미지에서 Domain Discrepancy가 줄어들면서 gap이 좁아지는 모습인데요. 여기서 Domain Discrepancy라는 것이 어떻게 보면 조금은 추상적인 것이라고 생각되는데, 어떻게 이것 어떻게 정의되고 측정되는 것인지 궁금합니다!
감사합니다!