
안녕하세요. 허재연입니다. 이번에 다룰 논문은 Self-Supervised Learning 논문이며, 그 중에서도 Contrastive Learning에 속합니다. 요즘 pedestrian detection에 SSL을 어떻게 적용해볼 수 있을까 고민하고 있는데, 관련해서 찾아보다 읽어보게 된 논문입니다. 기존의 contrastive learning에 관련된 논문을 읽을 때는 사전학습 방법론 자체에 집중해서 읽었으며, 대부분 평가가 classification에서 이루어졌습니다. 하지만 object detection, 그것도 이미지의 국소적인 부분에 대한 좋은 feature가 필요한 pedestrian detection의 경우 contrastive learning이 잘 동작할까에 대한 의문을 항상 가지고 있었습니다. contrastive learning은 본질적으로 data instance 전체에 대해 수행되기 때문에, 이미지 데이터의 local feature를 잘 학습할 수 있을지에 대한 확신을 가질 수 없었습니다. 관련하여 찾아보니 역시 이에 대한 문제 제기를 한 연구들이 있었고, 이 논문 또한 semantic segmentation이나 object detection 같은 (논문에서는 dense prediction task라고 지칭합니다) task에 알맞은 사전학습 방법을 제안합니다. 리뷰 시작하겠습니다.
Abstract
현재까지 대부분의 기존 Self-Supervised Learning 기법들은 이미지 분류 기법에 맞춰 설계되었지만, 이런 사전 학습 모델은 image-level prediction과 pixel-level prediction 간 불일치로 인해 dense prediction task에 접합하지 않을 수 있습니다. 이러한 격차를 메우기 위해 저자들은 pixel 수준(혹은 local feature 수준)에서 직접 동작하는 효과적인 self-supervised learning기법을 설계하는 것을 목표로 하며, image instance 및 local feature에 대한contrastive learning을 수행하는 dense contrastive learning(DenseCL)을 제안합니다. 해당 방법론은 기존의 MoCo-v2에 비해서 연산량이 크게 늘어나지 않지만 (1%보다 작은 수준의 지연 시간만 늘어난다고 합니다) object detection, segmentation과 같은 dense prediction task에서 기존보다 일관되게 우수한 성능을 보여준다고 합니다.
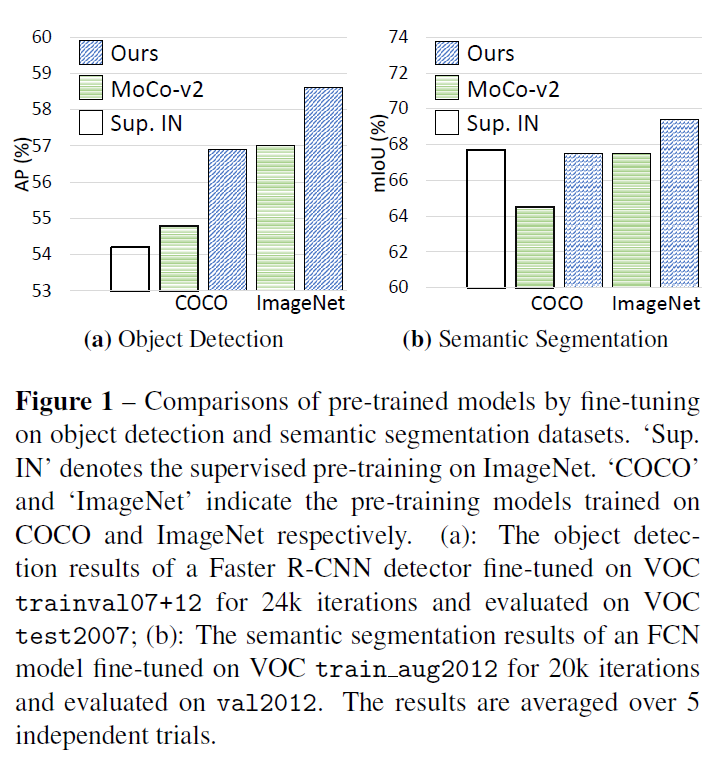
Fig 1은 dense prediction task인 Object Detection과 Semantic Segmentation에서의 성능 비교를 보여주는데, 저자들이 제안한 방법은 ImageNet 사전학습 가중치와 MoCo-v2보다 좋은 성능을 보여주는것을 확인할 수 있습니다.
Introduction
저자들은 앞쪽에서 사전학습 및 self-supervised learning에 대한 자세한 소개를 하며 시작합니다. Pre-training 패러다임은 컴퓨터 비전 task에서 그 패러다임이 잘 성립되어 있으며, 일반적으로는 대규모 데이터 세트에 대해 사전 훈련한 다음 목표로 하는 작업에 대한 더 작은 데이터셋으로 fine-tuning을 하게 됨니다. 특히 대규모 데이터셋인 ImageNet으로 사전학습된 가중치를 사용하는 것이 일반적이었다고 합니다. 이와는 달리, 주어진 GT label이 없는 데이터를 활용해서도 사전학습을 할 수 있습니다. Self-Supervised Learning(SSL)은 일반적으로 unlabeled data를 이용하여 data 그 자체에서 supervision을 얻어 학습하게 됩니다. 이렇게 사전학습을 마친 모델들은 각 downstream task에 알맞게 fine-tuning하여 활용할 수 있습니다. SSL 방법에는 여러 방법이 있는데, 오늘 다룰 논문은 contrastive learning에 속하는 방법론입니다.
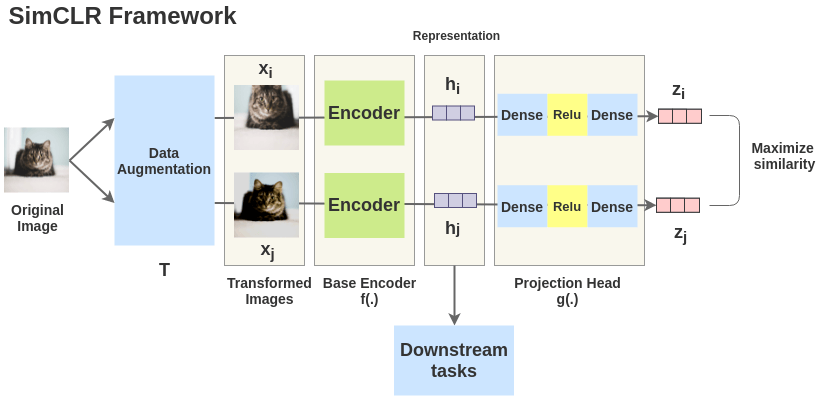
contrastive learning은 positive pair와 negative pair를 구성해 positive pair끼리는 거리가 가까워지도록, negative pair끼리는 거리가 멀어지도록 학습하는 방법입니다. 이 과정을 반복하며 encoder(ResNet과 같은 backbone)와 prejection head 를 거진 벡터가 잘 임베딩 될 수 있게 하는데, 이렇게 사전학습을 한 모델은 데이터에 대한 좋은 표현력을 갖추게 됩니다. 위 그림은 SimCLR라는 방법론에 대해 나타낸 것인데, 하나의 image data를 positive pair로 묶어 서로 다르게 augmentation 해서 encoder와 prejection head를 거치게 하여 similarity가 높아지게 하는(negative pair끼리는 similarity가 낮아지게 하는) 작업을 반복합니다.
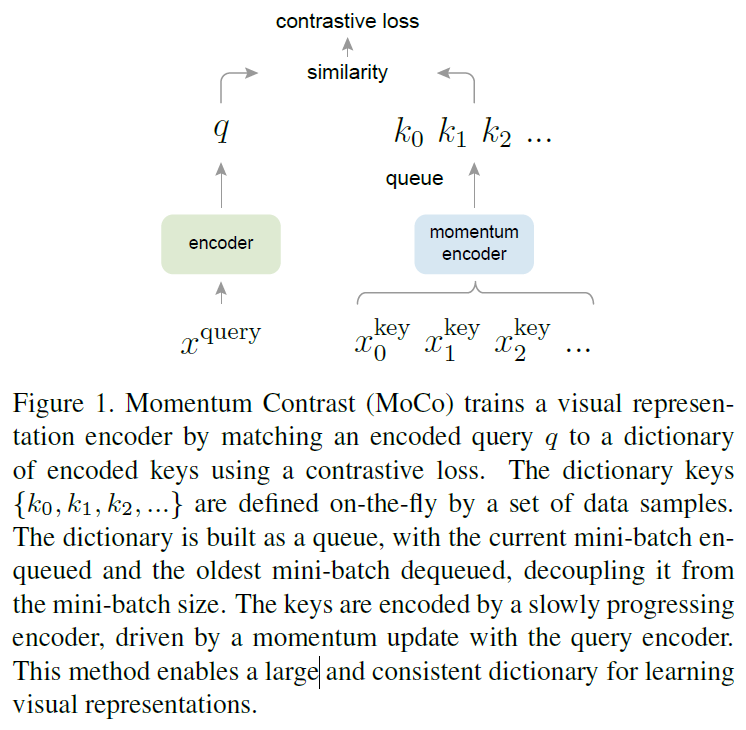
본 논문에서 baseline으로 삼는 MoCo 또한 SimCLR와 비슷한 방식으로 학습하는 방법인데, negative sample들을 관리하는 것과 encoder를 업데이트 하는 방법에서 약간의 차이가 있습니다. 일반적으로 contrastive learning은 negative pair의 수가 많아질수록 학습할 대상이 많아져 성능이 좋아지는데, 기존에는 batch 내에 있는 다른 데이터들을 negative pair로 정의했으므로 batch size가 너무 커지는 문제점이 있었습니다. MoCo의 경우 queue 형태로 관리되는 dictionary를 정의해서 image data에 대한 key값들을 관리하는 방법으로 배치 사이즈를 작게 유지할 수 있게 만들었습니다. 위 그림에서 encoded query와 encoded key가 positive/negative pair로 묶인다고 생각하시면 됩니다.
하지만 기존의 이런 contrastive learning 방법은 global feature를 사용한 image-level prediction을 하기에 dense prediction task를 수행하기에는 최적화되지 않는 부분이 있었습니다. 기존 contrastive learning의 훈련 과정에서는 입력 이미지 단위로 분류를 하게 되는데 반해 detection/segmentation과 같은 task들은 국소적인 부분에 대해 밀도 높은 분류/회귀 작업을 수행해야 하기 때문입니다. 따라서 저자들은 이런 이미지 데이터의 local한 요소들도 고려한 사전학습 방법이 필요하다는 문제를 제기하며 dense feature를 고려한 DenseCL을 제안합니다. DenseCL은 global image classification이 아닌 dense pairwise contrastive learning을 이용합니다. 우선 backbone network에서 feature를 입력받아 dense feature vector 만들어내는 dense projection head를 도입합니다. 이렇게 만들어낸 dense feature vector는 기존의 global projection head보다 공간적 정보를 잘 보존하고 있습니다. 그리고 positive pair에서 얻어낸 두 local feature vector를 positive pair로 묶어 contrastive learning을 진행합니다. dense contrative learning은 기존의 InfoNCE라는 contrative loss를 dense feature vector에 알맞게 변형시킨 dense contrative loss로 진행하게 되며, global feature의 contrastive learning과 동시에 진행됩니다.
저자들이 주장하는 contribution은 다음과 같습니다 :
- 우리는 픽셀 수준(local feature)에서 동작하는 dense contrastive learning이라는 새로운 contrastive learning 패러다임을 제안한다.
- 제안된 dense contrastive learning으로 우리는 dense prediction task에 알맞게 맞춘 간단하고 효과적인 self-supervised learning 방법인 DenseCL을 고안했다. 이는 기존의 self-supervised 사전학습 방법과 dense predictino task 간 격차를 메울 수 있다.
- DenseCL방법은 sota 방법론인 MoCo-v2를 object detection(+2.0% AP), instance segmantation(+0.9% AP), semantic segmentation (+3.0% mIoU)에서 크게 능가하는 결과를 보였다.
Method
Method 부분에서는 기존에 제안되었던 Contrastive Self-supervised learning 방법들(MoCo, SimCLR)과 그 pipe라인에 대해 자세히 설명하고 denseCL에 대한 소개를 합니다. 전체적인 파이프라인은 introduction에서 다루었으니 생략하고, 바로 DenseCL을 살펴보겠습니다.
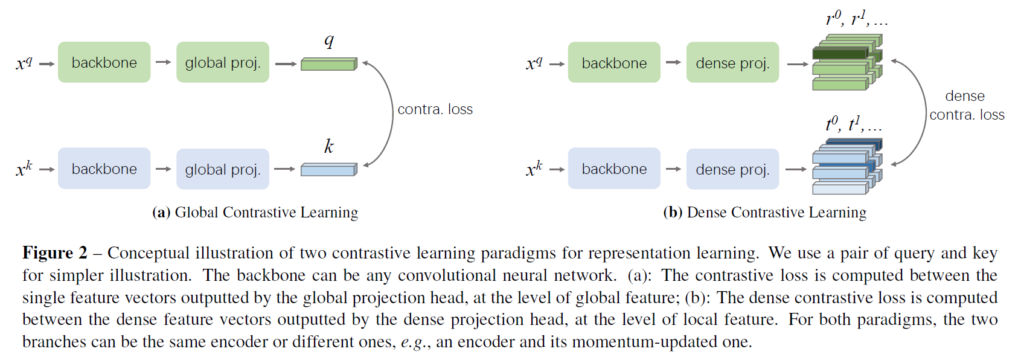
요약하자면 denseCL은
1. global projection head를 거쳐 나온 global feature(single feature vector)는 global contrastive learning을 수행하고, 2. dense projection head를 거쳐 나온 dense feature vector(local feature)들은 가장 유사도가 높은 vector를 매칭하여 positive pair로 묶어 dense contrastive learning을 진행해서 3. 두 contrastive loss를 가중합 한 최종 loss를 이용해 학습한다.
라고 할 수 있을 것 같습니다. 기존의 global projection head를 dense projection head로 교체해 dense feature를 얻게 되는데, 구체적으로는 global pooling layer를 제거하고 기존의 MLP를 1×1 conv로 교체한 것을 dense projection head로 사용합니다. backbone network는 global projection head와 dense projection head 2개를 병렬적으로 사용해 global feature, dense feature를 뽑게 되고 이들을 병렬적으로 contrastive learning을 진행시키게 됩니다. dense contrastive learning에서 positive pair는 대응하는 view의 feature들과 일일히 유사도 매칭을 수행해 가장 유사도가 높은 vector를 positive pair로 묶게 되며, negative pair는 대응에 대한 의미가 떨어지므로 구현상의 편의를 위해 global pooling을 사용해 만들었다고 합니다(애초에 다른 이미지에서 온 벡터이므로 구분하는 역할만 하도록 한 것 같습니다. negative pair도 벡터 간 매칭 방법을 이용할 수 있다고 언급은 있습니다).
결론적으로는 2개의 loss를 가중합 한 형태의 최종 loss함수로 학습을 진행하게 됩니다.
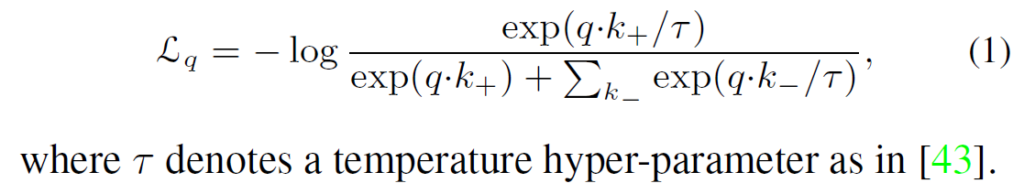
global contrastive learning은 기존 방법론들과 동일한 InfoNCE loss를 사용하게 됩니다. 식에서 q는 쿼리, k+는 positive pair(key), k-는 negative pair(key)입니다. exp() 내부의 연산은 키와 쿼리 간 내적을 이용해 cosine similarity를 구한 후 이 유사도를 temperature parameter인 τ로 나눈 것이라고 생각하시면 됩니다. τ는 contrastive learning의 강도를 조절하는 파라미터인데, 논문에서는 0.2로 설정했습니다.
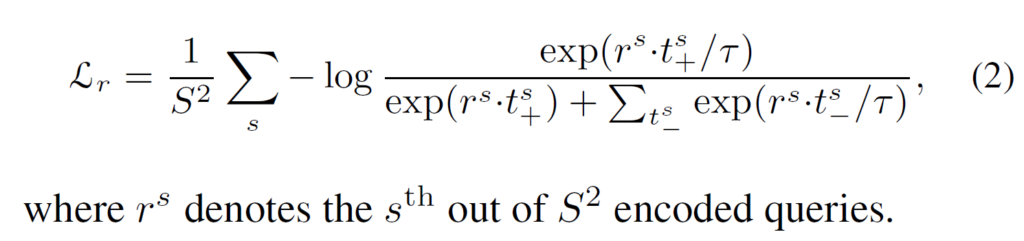
dense contrastive loss는 식(2)와 같이 정의하게 됩니다. 해당 식에서 r과 t는 dense feature vector입니다. dense projection head를 타고 나온 최종 feature map의 width와 height를 Sh, Sw로 표기했는데, 논문에서는 편의상 Sh=Sw=S로 표기하기에 식 앞에 1/S^2는 평균을 위해 나눠준 것이라 생각하시면 됩니다. 따라서 이 둘을 가중합한 최종 loss는 다음과 같습니다.
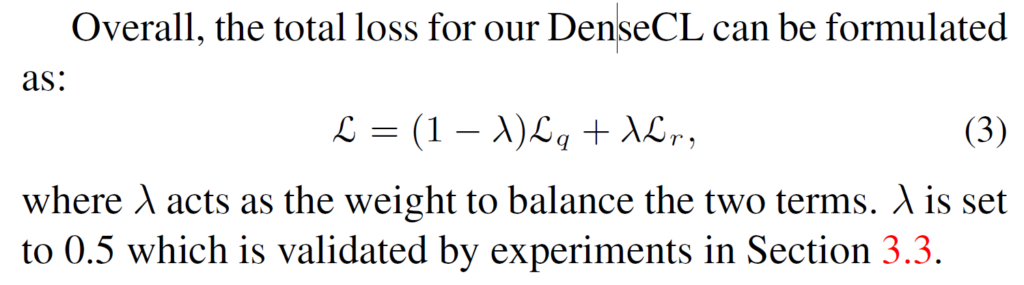
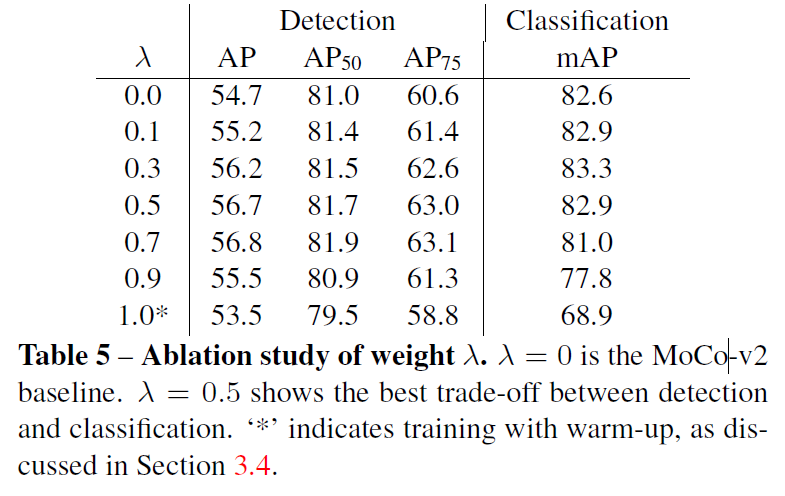
Alation study에서는 λ값을 변화시키며 실험을 수행해 보았을 때, λ=0.5일때 가장 성능이 좋았다고 합니다. 저자는 이런 경향을 global feature와 local feature가 잘 상호작용해서 좋은 표현력을 얻을 수 있었을 것이라 설명합니다.
Experiment
당시 기존의 강력한 baseline이었던 MoCo-v2를 baseline으로 설정해서 다양한 task에 대한 실험이 수행되었습니다. 대부분의 세팅은 MoCo-v2를 그대로 따랐다고 합니다. 표를 하나씩 보겠습니다.
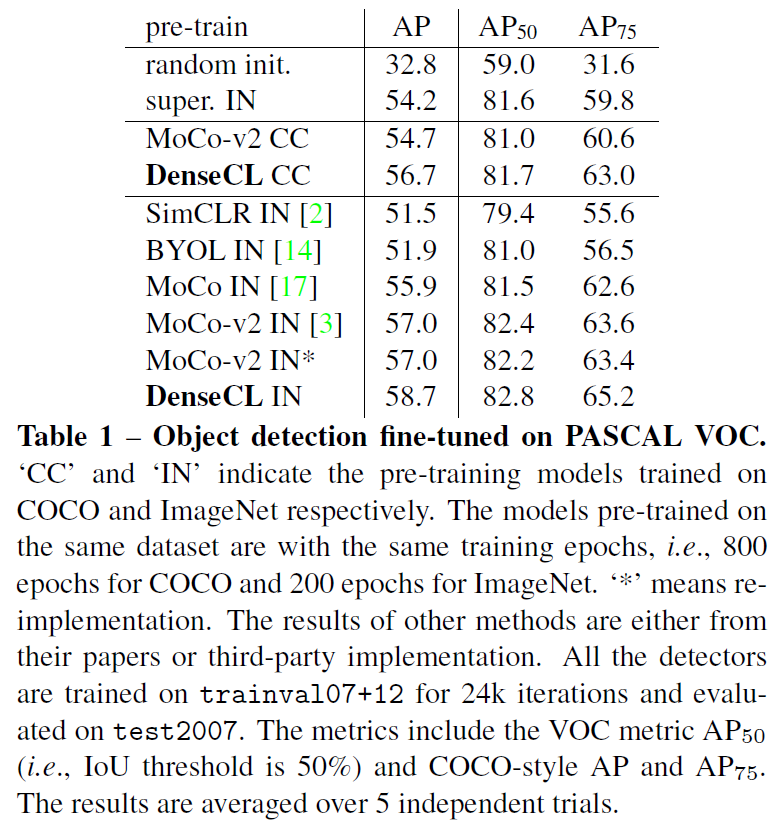
Table1은 다양한 데이터셋을 ImagNet, COCO dataset으로 사전학습 시키고 PASCAL VOC object detection에 fine-tuning한 실험입니다. super.IN은 이미지넷 데이터에 대해 supervised learning한 가중치를 이용한 것이며, SSL 방법론 옆의 CC는 COCO 데이터셋을, IN은 이미지넷 데이터셋을 사용해 SSL을 수행한 결과합니다. 보는바와 같이 COCO, ImageNet 모두 DenseCL을 사용해 사전학습 했을 때 성능이 가장 뛰어난 것을 확인할 수 있습니다.
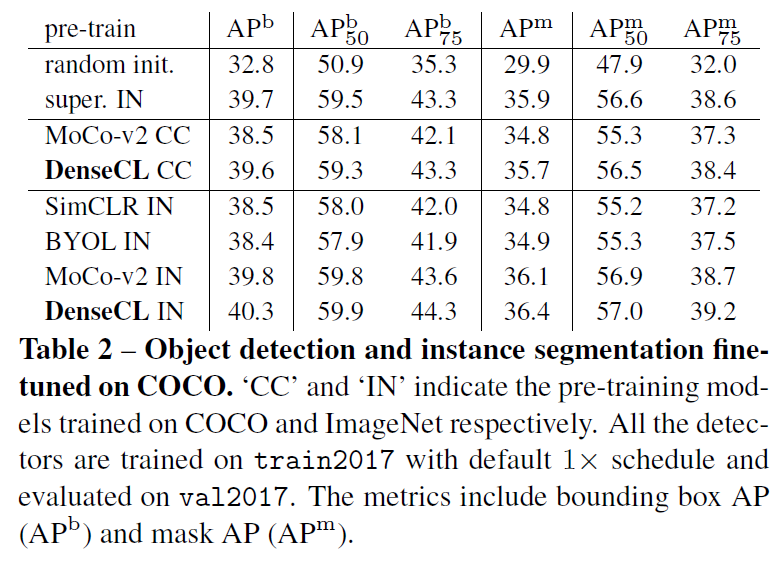
다음은 COCO 데이터셋으로 fine-tuning한 결과입니다. 다양한 방법으론 사전학습을 시켰지만 object detectio과 instance segmentation에서 DenseCL로 사전학습 시킨게 가장 좋은 성능을 보였습니다.
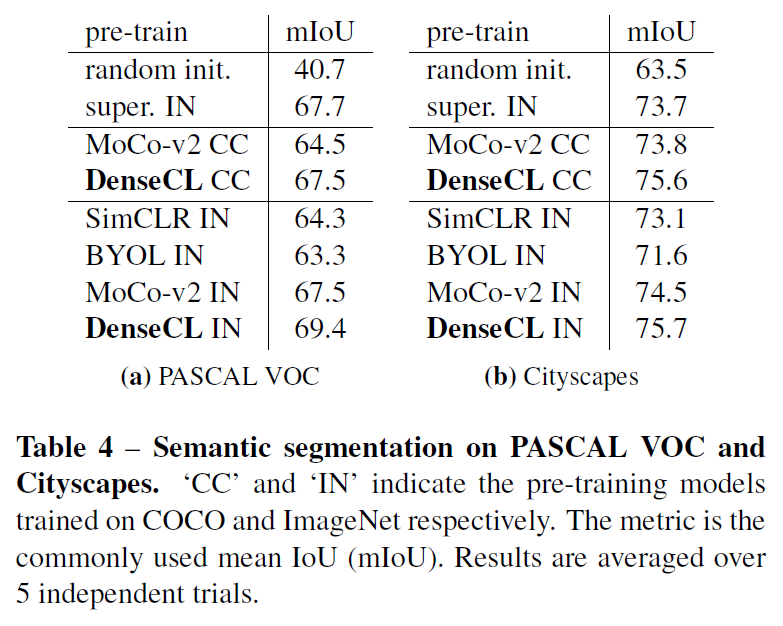
object detection과 instance segmentation 다음은 segmantic segmentation입니다. PASCAL VOC과 Cityscapes로 fine-tuning되었으며, MoCo-v2보다 상당히(2~3%정도) 개선된 성능을 기록했습니다.
Dense correspondence visualization
저자들은 사전학습이 완료된 MoCo-v2와 DenseCL 및 DenseCL의 학습 과정에서 dense correspondence를 시각화했습니다. DenseCL은 baseline보다 더 많은 high-similarity 매칭에 성공한것을 확인할 수 있으며, 저자들은 동일한 이미지에서 유사한 2개 view에서 local feature를 잘 추출하는 능력 덕분이라고 설명합니다.

Conclusion
본 논문에서 저자들은 기존의 MoCo를 발전시켜 dense prediction task에 잘 작동할 수 있는 간단하고 효과적인 Self-Supervised Learning 방법인 DenseCL을 제안했고, segmentation, detection task에서 기존보다 좋은 성능을 달성할 수 있었습니다.
기존 contrastive learning 방법론들은 classification에만 치중되어 있었는데, 이후 application을 위해서는 본 논문과 같이 dense/local feature를 고려하는 사전학습 방법들도 살펴봐야 할 것 같습니다. 추가적으로, 기존에는 너무 classification 논문만 읽었는데, 이제는 다른 task에 대한 논문도 봐야 할 것 같습니다. 시야가 너무 좁아지는 느낌이네요.. 우선 detection과 segmentation부터 차근차근 볼 생각입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
loss의 λ값을 변화시키며 실험한 ablation study 표5를 보면 detection 성능은 0.5보다 0.7이 높은 것 같고 classification에서는 0.3이 0.5보다 성능이 더 높은 것 같은데 둘을 고려하여 0.5로 선정한 것으로 보면 될까요 ?
또, coco 데이터셋으로 fine-tuning한 실험 테이블에서 AP^b와 AP^m은 각각 무엇인지 궁금합니다.
감사합니다.
안녕하세요, 정윤서 연구원님. 말씀해 주신 대로 loss term 간 가중치 λ같은 경우에는 classification과 detection 간 trade-off를 고려하여 0.5로 설정하였다고 합니다. classification과 detection에서 λ값에 대한 성능 차이가 있다 보니 절충안으로 0.5값을 선택한 듯 합니다.
COCO dataset에 대한 table2에서는 Object detection과 instance segmentation에 대한 성능을 같이 나타내었는데, AP^ b는 bounding box AP를, AP^ m은 mask AP를 뜻합니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Method 부분에서 global projection head를 거쳐 나온 global feature와 다르게 dense projection head를 거쳐 나온 dense feature vector들은 여러 개가 나오는 것을 확인할 수 있는데 dense projection head가 구체적으로 어떻게 구현되었는지가 궁금합니다.
또한 dense contrastive learning에서 negative pair는 구현상의 편의를 위해 global pooling을 사용해 만들었다고 하셨는데 어느 부분에서 global pooling을 적용시킨건가요?
감사합니다.
안녕하세요, 정의철 연구원님.
dense projection head는 global projection head에서 global pooling layer를 제거하고 기존의 MLP를 1×1 conv로 교체한 것을 사용합니다. backbone network는 global projection head와 dense projection head 2개를 병렬적으로 사용해 global feature, dense feature를 뽑게 되고 이들을 병렬적으로 contrastive learning을 진행시키게 됩니다.
또한 Figure 2는 positive pair에 대한 그림임을 알 수 있는데, negative pair에서는 dense feature를 사용하지 않고 contrastive learning representation을 만들 때 global feature를 사용합니다(dense projection head는 global pooling layer가 적용되지 않았기에 global feature가 아닌 dense feature를 얻을 수 있었죠). negative pair를 구성할 때 사실 dense feature를 사용해도 된다는 언급 정도가 있는데, 더 자세한 설명은 없네요.. 관련 ablation study도 있었으면 좋았을텐데 아쉽습니다.
감사합니다.