제가 이번에 리뷰할 논문은 3D Object Pose Estimation 논문으로, rotation(3D)에 대한 정보를 추정하는 연구입니다. Unseen object에 대응하기 위해 6D Pose Estimation 분야에는 CAD모델을 이용하여 템플릿을 만들어두고, 실제 이미지와 비교하여 pose를 추정하는 방식을 주로 활용합니다. 본 논문도 동일한 방식을 이용하며, Unseen 6D Pose Estimation의 핵심 연구인 CNOS(자세한 내용은 양희진연구원님의 리뷰를 참고해주세요) 저자의 논문으로 해당 방법론을 열화상에 적용해보는 실험을 해보고 있어 리뷰하게 되었습니다.
Abstract
저자들은 새로운 객체의 일부분이 가려진 경우에도 객체의 3D pose(rotation)를 추정하기 위해 새로운 객체에 대해 real 이미지로 학습하지 않고 CAD모델만을 이용하는 방법론을 제안하였습니다. CAD 모델을 렌더링하여 구한 이미지들인 template(템플릿)과 RGB 이미지의 local한 영역을 매칭하는 방식으로, 학습한 객체와 새로운 객체가 크게 달라도 적용 가능하며 LINEMOD와 Occlusion-LINEMOD 데이터에 대해 처음으로 일반화를 보였습니다. 기존의 template 기반 방식의 실패를 분석하여 local feature의 장점을 검증하였으며, LINEMOD, Occlusion-LINEMOD, T-LESS 데이터에서 SOTA를 달성하였다고 합니다.
Introduction
먼저 Object Pose Estimation의 중요성을 언급하며, 딥러닝 연구를 통해 occlusion에 강인해지고 실제 데이터의 필요성을 완화하였지만 산업에 적용하기 위해서는 임의의 Unseen 객체에 대응이 가능해야 하므로 여전히 산업 환경에 적용하기에는 어려움이 있음을 주장합니다. (CAD 모델에는 접근 가능) 기존 연구들은 unseen 객체에 대한 대응을 위해 1. 새로운 객체의 카테고리에 대해 이미 알고 있거나 2. 학습 과정에 비슷한 객체를 이용하였거나 3. 두드러지는 특성이 있다는 추가적인 전제가 필요하였습니다.
기존의 template 기반의 방법론은 CAD모델로 생성한 template과의 매칭을 위해 이미지의 임베딩을 학슴함으로써 임의의 객체에 대해 일반화 가능성을 보였으나 이는 명확한 입증이 되지 않았습니다. 저자들은 실험을 통해 template 기반의 방식이 occlusion과 같이 복잡한 장면에 대해서는 어려움이 있음을 보였으며, CAD 모델로 template을 만들어 global representation과 비교하는 방식은 1. 새로운 객체가 clutter한 배경에 있을 경우 일반화가 잘 되지 않으며 단조로운 배경에서도 성능이 떨어지고, 2. occlusion에 대응이 어렵다는 한계를 확인합니다.
이러한 관찰을 통해 이미지의 2D 구조를 유지하도록 template 기반의 방식을 설계하고자 하였고, 소량의 데이터로 local feature를 학습하여 합성 템플릿과 실제 이미지를 매칭하는 방식을 제안하였습니다. 저자들은 local feature를 이용하므로써 배경에 의한 한계(1번)를 해결할 수 있었고, local feature를 사용하면 pooling과정과 같이 데이터가 손실되는 작업을 사용하지 않을 수 있어 정확도를 높일 수 있었다고 합니다. 또한, template의 마스크와 쿼리 이미지의 occlusion을 명시적으로 고려하여 유사도를 평가하는 방식을 도입하여 occlusion에 강인하게 작동할 수 있도록 하였다고 합니다. 이러한 장점을 LINEMOD와 Occlusion-LINEMOD, T-LESS 데이터에 대해 실험을 통해 입증하였으며 본 논문의 contribution을 정리하면 다음과 같습니다.
- 새로운 객체에 template 기반의 방법론을 적용하였을 때 failure-case 분석
- 새로운 객체에 대한 학습 혹은 학습된 데이터와 유사하도록 제한하지 않고 CAD모델을 이용하여 새로운 객체의 pose 추정하는 방식 제안
- 새로운 객체의 occlusion이나 challenging한 시나리오에 강인한 방법론 제안
Method
저자들은 color 이미지에서 새로운 객체를 인식하고 해당 객체의 3D Pose를 예측하는 것을 목표로 합니다. 이를 위해 3D 모델을 렌더링한 template과 쿼리 이미지를 매칭시키는 방식을 이용하며 template에는 객체의 id와 pose 정보를 포함하고 있어 쿼리 이미지와 가장 유사한 템플릿의 id와 pose를 반환하여 pose를 추정하게 됩니다. 이미지와 template 사이의 유사도를 측정하는 것이 중요한 문제가 되며, 이때 새로운 객체는 학습 과정에 미리 볼 수 없고, 일부가 가려지거나 실제 환경의 조명 조건이 다르고 배경이 복잡하더라도 안정적으로 pose 정보를 추정해야 합니다.
해당 논문은 global representation에 비해 local representation이 occlusion에 대해 더 안정적으로 작동한다는 것을 기반으로 딥러닝 모델을 통해 추출된 local feature를 활용하여 이미지와 template 사이의 유사성을 측정하는 방식을 이용합니다. 소량의 real 학습 데이터와 templates 쌍을 이용하여 모델을 학습하고 학습한 객체와 형태가 크게 다른 새로운 객체에 대해서도 동작하는 object pose estimation 방법론을 제안합니다.
1. Motivation and Analysis
해당 파트는 unseen 객체에 대한 template matching 과정에 global representation을 이용할 경우의 한계를 분석하는 실험을 수행합니다.
Cluttered Background
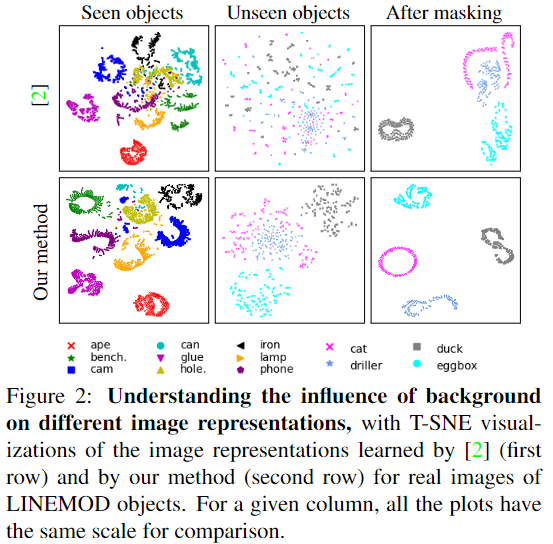
먼저 저자들은 global represenstation을 이용할 경우 clutter한 배경에서 객체에 대한 표현력이 떨어진다는 것을 보입니다. 위의 [그림 1]은 기존의 global representation을 이용하는 template 기반 pose 추정 방식**과 local representation을 이용하는 본 논문의 방법론을 LINEMOD 객체에 적용하였을 때 representation의 T-SNE를 시각화 한 것입니다. 1열은 학습된 객체에 대한 T-SNE이로 clutter한 배경임에도 두 representation 모두 잘 군집화되어있는 것을 확인할 수 있습니다. 2열은 Unseen 객체에 대한 T-SNE로 global representation에 대해서는 객체를 구분하기 어렵지만 local feature를 이용하는 저자들의 방식은 어느정도 모여있는 경향을 보인다는 것을 확인할 수 있습니다. 마지막으로 3열은 객체 영역에 대한 masking을 추가한 것으로 unseen 객체에 대하여 global representation을 이용할 경우 배경이 영향을 준다는 것을 입증하며 저자들의 방식은 객체별 구분이 확실해짐을 통해 clutter한 배경에 더 잘 작동한다는 것을 보였습니다.
** Brachmann, Eric, et al. “Learning 6d object pose estimation using 3d object coordinates.” ECCV 2014
Pose Discrimination
두 번째로 저자들은 global representation을 이용할 경우 unseen 객체에 대한 real 이미지를 3D 모델로 렌더링하여 구한 template과 매칭시킬 때 객체의 ID를 알고있고, 배경이 단조로울 경우에도 낮은 신뢰도를 갖는 다는 것을 주장합니다. global representation을 구하기 위해서는 pooling과 같이 정보가 손실되는 과정이 포함되며, 학습된 객체는 나머지 네트워크를 통해 해당 정보를 보완할 수 있으나, unseen 객체는 이를 보완할 수 없어 일반화가 되지 않는다고 설명합니다.
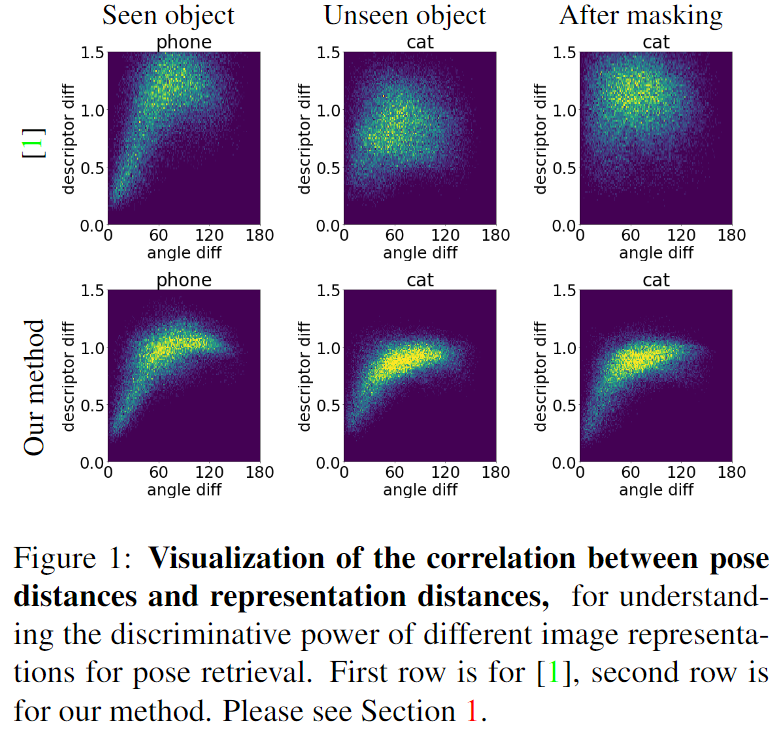
위의 [그림 2]는 이에 대한 시각화 결과로 pose distance와 representation distance에 대한 상관 관계를 그래프로 표현한 것입니다.(해당 이미지는 supplementary에 따로 작성되어 있어서 이미지상 Figure와 reference 순서가 다르지만, 그림1과 동일한 방법론에 대한 실험 결과입니다!!) 매칭이 잘 이뤄지기 위해서 (0,0)에 모여있는 것이 이상적이며, representation을 기반으로 매칭을 수행하므로 representation이 달라질수록 pose 오차가 커질 것이기 때문 대각선의 패턴을 통해 pose와 represenation 사이의 강한 상관 관계를 확인할 수 있습니다. 1열을 통해 학습된 객체에서 representation과 pose distance 사이에 강한 상관 관계가 있음을 확인할 수 있으며, 2열을 통해 unseen 객체에 대해 기존 global feature를 이용하는 방식은 상관 관계가 손실되지만 저자들의 방식은 여전히 비슷한 경향을 보인다는 것을 확인할 수 있습니다. 마지막으로 3열은 배경에 대한 정보를 제거하는 masking을 사용하더라도 global representation을 이용하는 방식은 상관 관계가 회복되지 않는다는 것을 보여주며, 저자들은 이를 pooling layer가 객체에 대한 중요한 정보를 제거하였기 때문이며 학습한 객체는 네트워크의 다른 부분에서 이러한 정보 손실을 보완할 수 있으나 unseen 객체에 대해서는 정보 보완이 불가능하기 때문이라고 설명합니다.
2. Framework
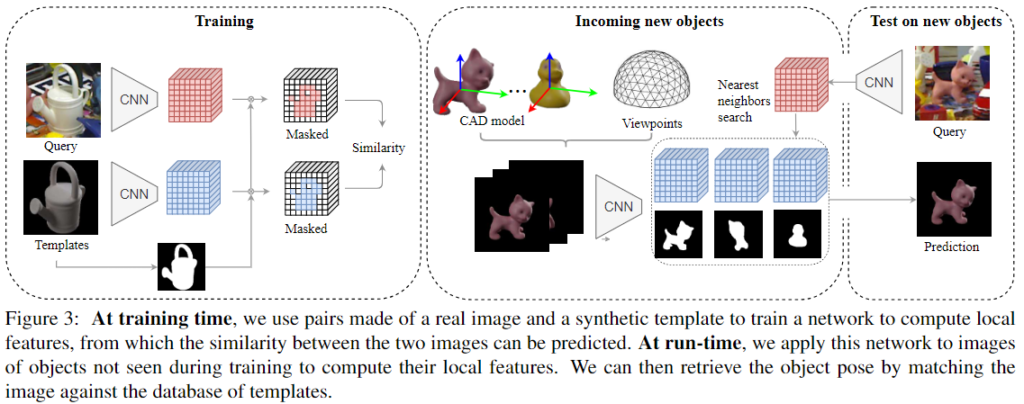
이제 본 논문에서 제안하는 프레임워크에 대한 설명입니다. 먼저 N개의 positive 쌍을 샘플링합니다. 이때 i번째 쌍은 real 이미지 \mathbf{q}_i와 이미지의 pose 정보와 5 degree 이하의 차이가 나는 합성 template \mathbf{t}_i로 구성되며 real이미지와 다른 객체나 5 degree 이상의 차이가 나는 모든 쌍은 negative 쌍으로 정의됩니다. 저자들은 기존의 pose estimation 방법론**에서 제안한 loss \mathcal{L}=\mathcal{L}_{triplet}+\mathcal{L}_{pair}를 활용하여 positive 쌍의 representation은 가까워지고 negative 쌍은 멀어지도록 학습하는 것을 목표로 합니다. (아래의 실험 파트에서 Loss_[38]에 해당하는 loss입니다)
**Paul Wohlhart and Vincent Lepetit. Learning Descriptors for Object Recognition and 3D Pose Estimation. In Conference on Computer Vision and Pattern Recognition (CVPR), 2015
- \mathcal{L}_{triplet}
- 학습된 embedding space에서 positive 쌍 \Delta^{(i)}_{+}의 거리는 negative 쌍\Delta^{(i)}_{-}의 거리보다 일정한 마진 m 이내의 거리보다 가까워지도록 하는 triplet loss로 식은 아래와 같이 정의됩니다.
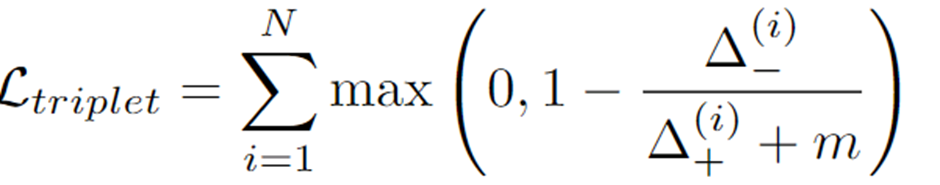
- \mathcal{L}_{pair}
- positive 쌍에 대한 항으로, 배경이나 조명 변화가 있어도 객체에 대한 representation이 동일하도록 하기 위해 도입한 pairwise loss로 아래의 식으로 정의됩니다.
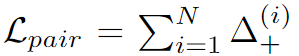
여기에 InfoNCE loss 방식도 적용하였다고 합니다.
real 이미지 \mathbf{q}_i에 대하여 negative 합성 template \mathbf{t}_k을 만들어 현재 배치에 대하여 N-1개의 negative 쌍을 생성합니다. 즉, 각 배치에 대하여 N개의 positive 쌍과 (N-1)XN개의 negative 쌍을 만들어 아래의 식을 최소화하면서 positive 쌍의 representation 사이의 일치를 최대화 하도록 학습하며 아래의 식으로 정의됩니다.(아래의 실험 파트에서 Loss_Eq. (2)에 해당하는 loss입니다)
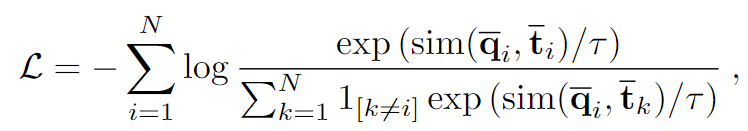
- sim(\bar{\mathbf{q}}, \bar{\mathbf{t}}): 각각 real 이미지 \mathbf{q}와 template \mathbf{t}의 local feature \bar{\mathbf{q}}와 \bar{\mathbf{t}} 사이의 유사도
- \tau: 하이퍼파라미터로 0.1로 설정
Local feature similarity
기존의 contrastive learning은 주로 classification에 중점을 두고 두 이미지의 global representation을 이용하여 similarity를 정의하였지만, 위의 실험을 통해 객체의 pose를 추정하기 위해서는 local representation이 중요함을 보였으며 복잡한 배경을 효과적으로 처리하기 위해 local feature \bar{\mathbf{q}}, \bar{\mathbf{t}}에 대해 pairwise로 유사도를 계산하며 이는 아래의 식으로 정의됩니다.
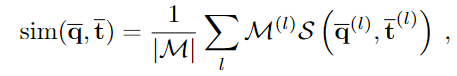
- \mathcal{S}: local similarity metric
- \mathcal{M}: template \mathbf{t}에 대한 이진 마스크
- \bar{\mathbf{q}}^{(l)}, \bar{\mathbf{t}}^{(l)}: 2D 그리드 위치
template의 마스크를 이용하여 real 이미지의 배경 영역을 버릴 수 있으며 cosine similarity를 이용하여 유사도를 측정합니다.
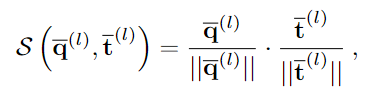
Run-time and Robustness to Occlusions
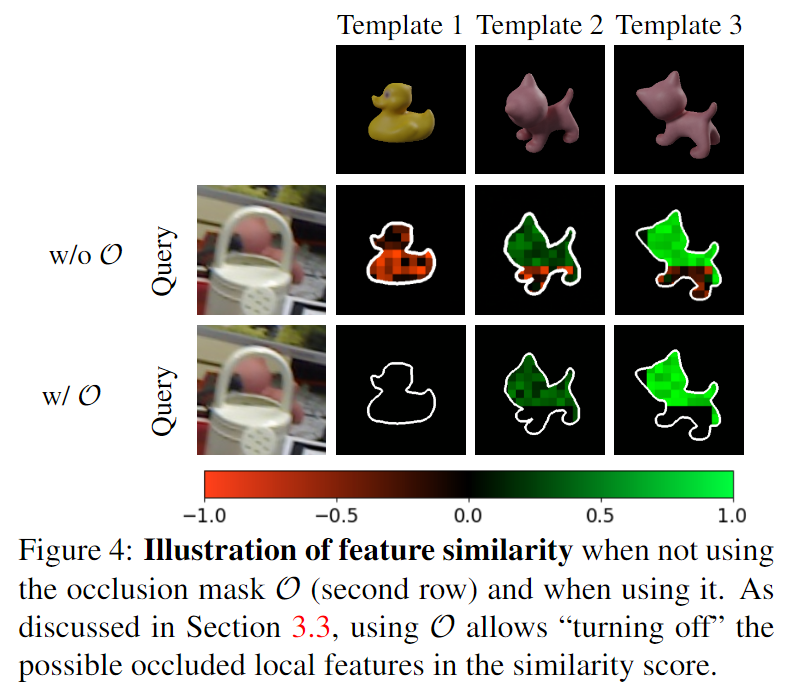
앞서 배경 영역에 대한 영향을 줄이고자 template의 이진마스크를 이용하였지만, template의 마스크는 real 이미지의 occlusion을 반영하지 못한다는 한계가 있습니다. 따라서 occlusion에도 강인하게 작동하도록 하기 위해 similarity를 아래의 식으로 조정하는 것을 제안합니다.
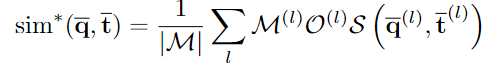
- \mathcal{O}^{(l)}=1_{\mathcal{S}(\bar{\mathbf{q}}^{(l)},\bar{\mathbf{t}}^{(l)})>\delta}: occlusion의 영향을 줄이기 위해 cosine similarity가 임계치 이상일 경우만 1이 되도록 하며, 이때 실험적으로 임계치를 \delta=0.2로 설정함.(위의 [그림 4]에 표현되어있으며, 유사도가 낮은 영역은 고려하지 않도록 함)
마지막으로, 보다 효율적인 계산을 위해 위의 식을 element-wise 곱 ⊙로 정리합니다.
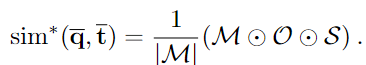
4. Template Creation
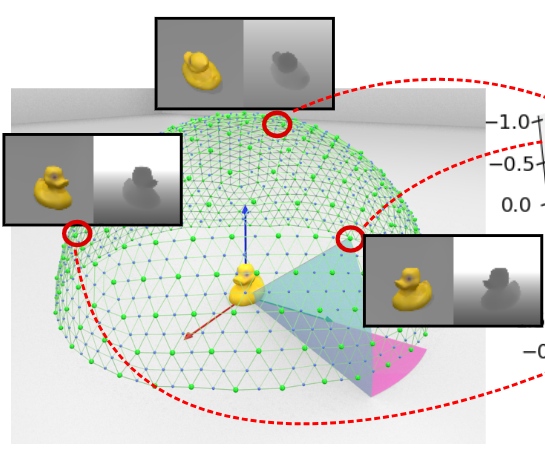
LINEMOD와 Occlusion-LINEMOD 데이터에 대하여 기존 연구의 프로토콜을 따라 템플릿을 샘플링하였다고 합니다. 아래의 그림이 샘플링된 view point를 나타내며 정 20면체에서 시작해서 각 삼각형의 내부를 4개의 삼각형으로 세분화하는 과정을 재귀적으로 2번 반복하고 위의 반구에 해당하는 viewpoint로 객체를 렌더링하여 객체당 301개의 template을 생성합니다.
T-LESS도 기존 연구의 프로토콜을 따라 각 이미지에 대해 2,536개의 균일한 view-point와 36개의 in-plane rotation을 적용한 각 객체마다 92,232개의 렌더링 이미지를 생성합니다. 또한 조금 더 coarse하게 602개의 view point에 36개의 in-plane rotation을 적용해 객체별로 21,672개의 template을 생성하였다고 합니다.
Experiments
Experimental Setup
먼저 실험 세팅에 대해 설명을 드리겠습니다. LINEMOD와 Occlusion-LINEMOD에 대하여 unseen 객체에 대한 평가를 위한 표준이 없으므로 ID순서에 따라 3가지로 split하여 평가를 수행하는 것을 제안합니다. 아래와 같이 class별로 split을 3가지로 나누었으며 아래에서 bold 표시된 것은 Occlusion-LINEMOD 데이터의 occlusion이 발생하는 경우가 많이 포함된 것입니다.

저자들은 unseen 객체 뿐만 아니라 학습에 사용한 객체에 대한 평가도 진행하였으며, 이를 위해 학습에 사용되는 객체의 real 이미지 중 10%를 평가에 사용하였다고 합니다. 아래의 Table 1은 분할에 대한 추가 정보입니다.
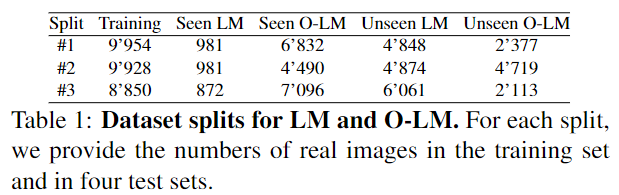
T-LESS는 SUN397 데이터로 랜덤하게 배경을 적용하여 학습하였으며, 이때 1~18번 객체에 대해서만 학습을 수행하고 전체 test set에 대한 평가를 수행하였다고 합니다.
Evaluation metrics
예측 pose와 GT pose의 각도의 오차를 측정합니다. 이때 symmetric한 객체(Eggbox/Glue)에 대해서는 z축을 중심으로 대칭을 처리합니다. 또한 기존 연구는 rotation 오차만을 측정하였다면, 해당 논문은 다른 object로부터 pose를 추정할 수 있으므로 class를 바르게 예측하였는 지 평가를 함께 수행합니다.따라서 pose 오류가 15 degree 미만이고 클래스가 올바른지를 평가하는 Acc15 metric을 이용할 것을 제안합니다.
T-LESS는 기존 연구를 따라 10% 이상의 영역이 보이고 20 mm 이내의 오차를 가지는 Visible Surface Discrepancy(err_{vsd})에 대한 recall 평가지표 err_{vsd}<0.3를 이용합니다.
Comparision with SOTA
- LINEMOD and Occlusion-LINEMOD
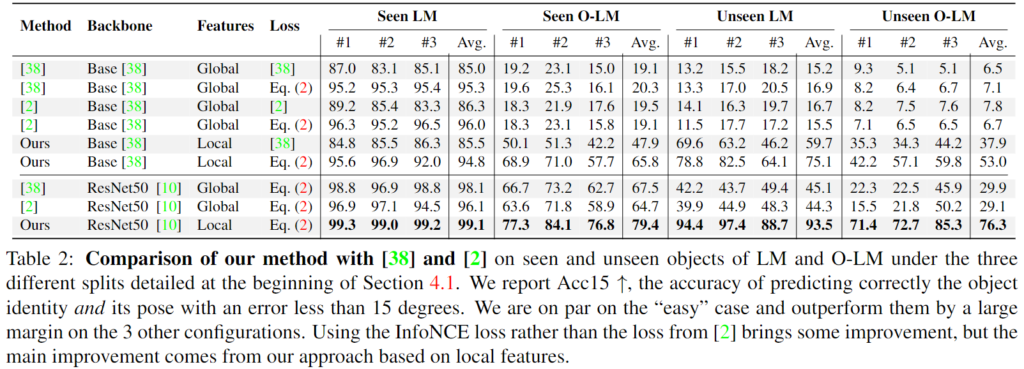
기존 연구와의 비교를 나타내며, local feature를 이용하는 저자들의 방식이 Base와 ResNet50 백본에서 모두 좋은 성능을 보이는 것을 확인하였습니다. 또한 모든 방법론에서 InfoNCE loss를 활용할 경우 모두 성능이 개선되는 것을 확인하였습니다. 또한, 학습한 객체에 oclcusion이 발생할 경우(Seen O-LM) 기존 방법론들은 성능이 크게 저하되었지만, 해당 논문에서 제안한 방법론은 상대적으로 높은 정확도를 보이는 것을 확인하였습니다. 이를 통해 local feature를 이용하므로써 occlusion에 강인할 수 있었다는 것을 실험적으로 보였습니다. 또한, Unseen 객체에 대한 실험 결과는 occlusion 여부에 관계 없이 모두 성능이 크게 개선되는 것을 확인할 수 있습니다. 이를 통해 local feature를 이용한 매칭 방식은 unseen에서도 잘 일반화되며 occlusion이 발생해도 강인하게 작동한다는 것을 보였습니다.
- T-LESS
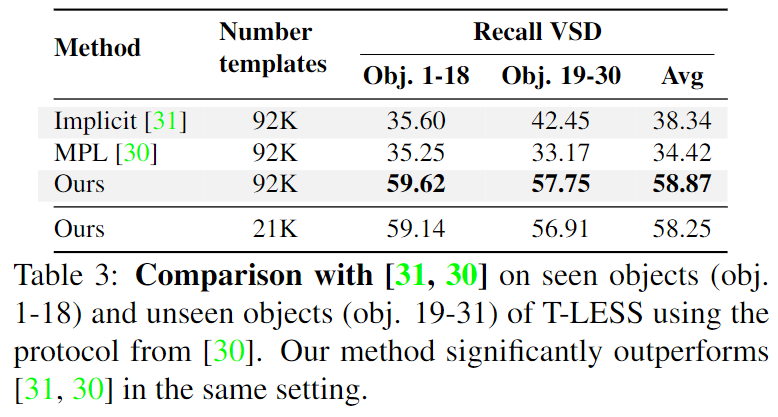
위의 Table 3이 T-LESS 데이터에 대한 실험 결과로, 학습한 객체(Obj. 1-18)뿐만 아니라 unseen 객체(Obj. 19-30)서도 가장 좋은 성능을 보였습니다.
Ablation Study
- Effectiveness of masking
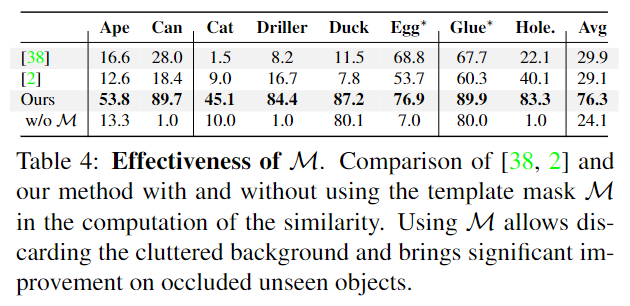
위의 Table 4는 template의 마스크을 이용할 경우의 효과를 보이기 위한 실험으로, 마스크를 사용하지 않을 경우의 성능 저하를 통해 배경을 제거하는 것의 중요성을 보였습니다.
- Influence of the threshold δ
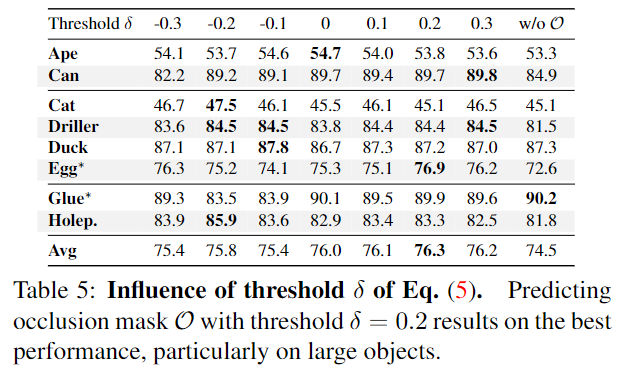
위의 Table 5는 occlusion이 존재하는 객체들에 대해 occlusion 영역을 제외하기 위해 사용하는 cosine similarity의 임계치 변화에 따른 성능 변화입니다. 저자들은 객체의 크기가 큰 Can, Driller, Egg에 대해서는 occlusion mask \mathcal{O}를 사용할 경우 성능이 개선되었지만, 작은 객체에서 효과가 미미한 이유로 아래의 예시와 같이 occlusion이 너무 많은 비율을 차지하기 때문이라고 설하였습니다.

- Run-time

위의 Table 6은 실행시간을 나타낸 것입니다. 속도는 굉장히 느리다는 것을 확인할 수 있습니다…