안녕하세요. 4월이 밝았습니다. 이번 논문은 OWOD 태스크의 시초 논문 (CVPR 2021: Towards Open World Object Detection (ORE)) 이후의 논문으로, DETR을 어렵지 않은 방식으로 OWOD 태스크에 접목시킨 논문입니다. 본 논문은 ORE의 RPN을 탈피하여 DETR을 접목시킨 부분이 현 시점에서도 OWOD 태스크의 한 줄기 (transformer-based)를 이루고 있습니다. 방법이 어렵진 않으니 DETR을 잘 이해하고 있으시다면, 본 논문을 쉽게 이해하실 수 있습니다.
Introduction
OWOD 태스크 직후년도의 논문인만큼 현존 OD 모델이 open-world에서 학습하지 않은 객체를 탐지하지 못하는 문제를 일컫습니다. OWOD 파이프라인을 정리하는데, 이를 다시 짚고 넘어가보겠습니다. 각 학습 에피소드마다 모델은 아는 (known) 객체와 모르는 (unknown) 객체를 동시에 탐지하도록 학습됩니다. 이들 중 unknown 객체는 oracle (e.g. human annotator)에 던져져 정답을 받습니다. 새로운 정답 (new known)에 대해 모델은 스스로의 지식을 지속적으로 업데이트합니다 (incremental learning). 이 때, 이전 학습 단계의 아는 (previously known) 객체에 대해 처음부터 재학습 (retraining from scratch)하지 않는다는 점을 염두에 두어야 합니다. 이들의 반복된 학습 과정은 모델이 있는 한 지속됩니다.
저자는 현존 OD 모델이 OWOD 상황에서 잘 작동하지 않는 이유와 동시에 간략히 ORE의 파이프라인을 소개합니다. ORE는 Faster R-CNN 파이프라인을 따르며, unknown에 대한 학습을 위해 RPN의 objectness score를 토대로 (pseudo) auto-label을 생성합니다. 생성된 pseudo-unknown은 latent space 내 GT-known과 contrastive clustering을 진행합니다. 해당 clustering은 GT-known과 pseudo-unknown 간 구별력을 얻고자함으로, unknown 클래스에 대한 프로토타입을 생성 및 업데이트하며 클러스터링 시에는 이를 활용하여 학습합니다.
저자의 문제 정의는 다음으로 정리됩니다. (본 논문은 ORE 직후의 논문으로, ORE의 문제점을 정의합니다)
- ORE는 unknown에 대해 weak supervision을 가진 held-out validation set (energy-based classifier에 대해 unknown(novel)의 분포를 측정하기 위해 사용됨)에 의존하여 unknown을 분류합니다.
- ORE는 contrastive clustering을 위해 unknown을 하나의 프로토타입으로 투영하는데, 이는 모델이 클래스 내의 다양성을 모델링하기에 부족합니다. unknown은 보통 둘 이상의 클래스가 존재하기 때문입니다.
- convolution-based (CNN)의 일관된 문제점으로, long-range dependencies를 encoding하기 어렵습니다. unknown의 탐지 시, contextual 정보를 활용하면 도움이 됩니다.
위의 문제 정의에 대해 저자는 다음의 contribution을 언급합니다.
- Multi-scale context-aware detection framework, OW-DETR을 제안합니다. 자세히는 long-range dependencies를 encode하고자 transformer 기반 Deformable DETR을 활용하여 모델을 설계하였습니다.
- Attention-driven pseudo-labeling을 제안합니다. objectness score와 유사한 attention score를 가진 object query에 unknown 라벨을 부여합니다.
- Known으로부터 unknown에 대해 지식이 전달되게끔 하여 foreground (known과 pseudo-unknown)와 background를 구분하기 위한 objectness branch를 제안합니다. 자세한 내용은 뒤의 방법론에서 소개합니다.
Open-world Detection Transformer
Problem Formulation
OWOD 태스크의 정의와, 추후 사용될 노테이션에 대해 한번에 짚고 넘어가겠습니다. 특히나 요즘의 논문들이 최대한 많은 내용을 8페이지 (CVPR 기준) 내에 담고자하다보니, 노테이션을 정리 이후 해당 노테이션을 토대로 방법론을 설명하는 방향이 예전에 비해서 더욱 많아보입니다.
- \mathcal{K}^t = \left\{ 1,2, \cdots, \mathcal{C} \right\}은 t 시간대의 known 클래스에 대한 집합입니다.
- \mathcal{D}^t = \left\{ \mathcal{I}^{t}, \mathcal{Y}^{t} \right\}는 N 개의 이미지: \mathcal{I}^{t} = \left\{ I_1, \cdots, I_N \right\} 와 매칭되는 라벨 \mathcal{Y}^{t} = \left\{y_1, \cdots, y_N \right\} 입니다.
- 다시 보통 이미지의 수와 라벨의 수가 동일하지 않음 (웬만해선 하나의 이미지 내 인스턴스는 하나 이상 등장함)을 염두에 두고, i번째 이미지에 대한 라벨인 Y_i = \left\{y_1, \cdots, y_K \right\} 는 K개의 인스턴스에 대한 집합입니다. 이 때, y_k 는 클래스 라벨 l_k와 바운딩 박스 x_k, y_k, w_k, h_k 의 합집합: [l_k, x_k, y_k, w_k, h_k] 입니다. 이 때 l_k 는 당연히도 known 클래스에 대한 집합 \mathcal{K}^{t} 에 속합니다.
- 테스트에 마주할 unknown 클래스에 대해서는 \mathcal{U} = \left\{C+1, \dots \right\} 로 정의합니다.
- OWOD 세팅에서, t 시간대의 모델 \mathcal{M}^{t} 는 이전에 마주한 known 클래스 C 의 seen 인스턴스와 동시에 unknown 클래스에 속한 unseen 인스턴스를 탐지하도록 학습됩니다.
- \mathcal{M}^{t} 에서 탐지한 unknown 인스턴스의 집합 U^{t} \subset \mathcal{U} 를 oracle (e.g. human annotator)에 전달하면, 관심 클래스에 라벨을 지정한 이후, 그에 해당하는 학습 데이터를 제공받습니다. (이 때 명심해야할 점으로, 관심 클래스를 지정함은 “모든 객체 후보에 라벨을 부여하긴 어려움”과 “OWOD는 특정 태스크에 대한 라벨링을 전제로 함”이 전제되어 있습니다)
- 점진적으로 다음 학습 단계 (t+1)에선 새로 부여된 클래스와 이미 학습한 클래스를 합한 \mathcal{K}^{t+1} = \mathcal{K}^{t} + \left\{C + 1, \cdots, C + n \right\} 이 구성됩니다.
- 이 때, ORE에서 언급한 바에 따라 이전 t 시간대의 학습 시의 클래스에 대한 데이터는 몇몇만 전달됩니다 (처음부터 (scratch) 학습하지 않으며 동시에 catastrophic forgetting을 방지하고자 함입니다 catastrophic forgetting이란 모델이 학습함에 따라 이전의 정보를 잃어버리는 현상으로, 예를 들어 t 시간대 학습 시의 known 클래스 “기린”에 대한 예제를 t+1 시간대에 한 번도 보지 않는다면, “기린” 클래스에 대해 잘 분류하지 못하는 현상을 말합니다. 해당 주제 역시 하나의 키워드로 논문이 쓰일 정도인 꽤나 유명한 주제입니다).
- 이제, 이전 t 시간대의 모델 \mathcal{M}^{t} 은 incremental learning을 통해 t+1 시간대의 \mathcal{M}^{t+1} 로 업데이트됩니다. 해당 업데이트된 모델은 이제 다시, \mathcal{K}^{t+1} = \mathcal{K}^{t} + \left\{C + 1, \cdots, C + n \right\} 에 대해 탐지함을 학습함과 동시에 해당 시간대의 unseen 인스턴스를 탐지하는 것을 목표로 합니다.
- 위의 과정을 줄이자면 “각 episode마다 모델은 지식을 업데이트하며 새로운 unknown 클래스를 탐지함을 목표로 하며, 동시에 이전에 학습한 클래스에 대한 정보를 잊지 않음도 목표로 한다”로 볼 수 있습니다. 이 과정은 계속 지속됩니다.
Overall Architecture
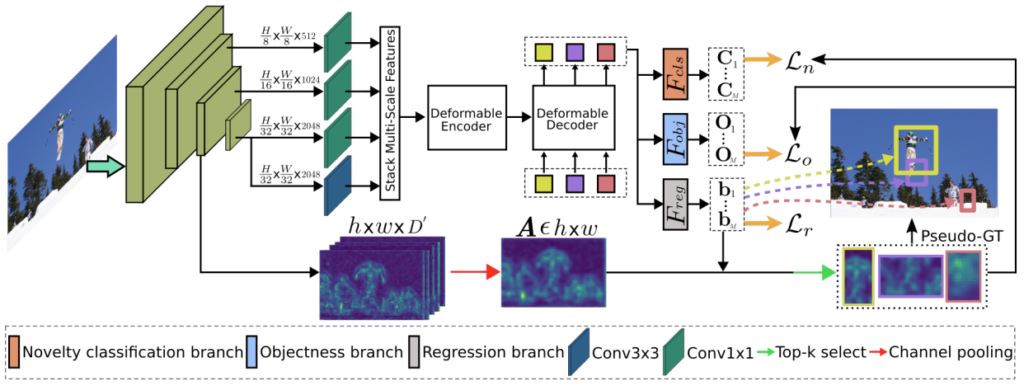
이제 OW-DETR의 구조와 함께 제안한 각 방법을 차근히 살펴봅니다. 위에서 10단계의 구성을 통해 OWOD의 파이프라인을 자세히 살펴보았는데, 해당 파이프라인을 충분히 이해하였다면 OWOD를 안다고 해도 무방합니다. OW-DETR의 DETR은 Deformable DETR (DDETR)을 받아들여 설계하였습니다. OW-DETR에서 Y 개의 인스턴스 집합을 포함한 H \times W 의 I 는 self-supervised 방식으로 사전 학습한 백본 네트워크에 입력됩니다. 당연한 과정을 언급한 이유가 있는데, 저자는 Implementation Details에서 아래와 같이 언급하였습니다.
“Multi-scale feature maps are extracted from a ResNet-50, pretrained on ImageNet in a self-supervised manner. Such a pretraining mitigates a possible open-world setting violation, which could occur in fully-supervised pretraining (with class lables) due to possible overlap with the novel classes”
번역하자면 SSL 방식이 아닌 fully-supervised로 학습된 ImageNet 가중치는 novel (unknown) 클래스에 대해 마주했을 수 있어 OWOD의 세팅을 침해할 수 있다고 합니다. ORE와 이후 RandBox와 같은 몇몇 논문의 코드를 확인했을 때는 단순히 ImageNet 가중치를 사용하는데, 이 점에서 아직 OWOD의 태스크에 대한 침해 여부등이 확립되지 않았나 싶기도 합니다. 태스크를 처음 제안한 ORE의 저자에게 이슈를 남겨놓았지만… 답장이 올지는 잘 모르겠습니다.
다시 넘어와 백본 네트워크 (feature extractor)로부터 나오는 D차원의 multi-scale feature map을 쌓아 transformer 기반의 deformable encoder 및 decoder에 입력합니다. self-attention과 cross-attention으로 구성된 decoder의 출력 결과, 입력 토큰은 M 개의 학습 가능한 object query로 변환되며 각 object query q_e \in \mathbb{R}^{D} 는 영상 내 잠재적인 객체 인스턴스를 인코딩합니다.
다음, 그림에 나타난 바와 같이 q_e 는 세 브랜치로 입력됩니다 – 1. bounding box regression ( F_{reg}), 2. novelty classification ( F_{cls} ), 3. novelty objectness ( F_{cls} ). DETR에 사용되는 bipartite matching loss는 GT-known과 가장 잘 매칭되는 query와 일대일 매칭을 위해 사용됩니다. 이후 남은 query들이 이제 unknown이 될 수 있는 후보군입니다.
Figure 1의 하단 부를 보면 attention map ( h \times w \times D^{'})을 합친 A \in h \times w를 볼 수 있는데, 이 attention map을 활용하여 query q_e에 대한 objectness score s_o 를 계산하여, Top-5개의 객체를 pseudo-unknown(GT)으로 지정합니다. 이 때, s_o 는 attention map의 activation magnitude를 통해 계산되는데, 이 과정은 굉장히 간단하며, 추후 아래에서 다시 다루겠습니다.
Multi-scale Context Encoding
OWOD의 중요한 요소 중 하나는 unknown이 정의되어 있지 않으므로, 이미지/feature map 상에서 그들의 context 정보를 encode하는 일입니다. 그러기 위해선 이미지의 여러 스케일에서 큰 receptive field에 대한 long-term dependencies를 포착해야합니다 (쉽게 말하자면, 익히 알고 있듯이 feature encoding에 transformer 구조가 효과적입니다). 또한 저자는 transformer의 inductive bias가 적은 특성이, 오히려 unknown에 대한 가정이 적어 탐지 시에는 더욱 효과적이라고 합니다. CNN과 transformer를 비교 시 transformer는 상대적으로 inductive bias (특히 locality에 대해)가 적은데, 이는 known에 대한 supervised 방식의 학습 시에는 CNN 방식이 도움될지 몰라도 (물론 실험 결과 상 학습을 마친 이후에는 transformer가 대체적으로 더 좋은 성능을 보입니다만), unknown에 대해 탐지 시에는 inductive bias가 적은 것이 더 도움이 된다고 합니다. 저자는 이를 위해 Deformable DETR (DDETR) 구조를 도입하였으며, 기존의 DDETR의 학습 방식만으로는 unknown 인스턴스를 탐지하기엔 적합하지 않지만, 이를 해결하고자 attention 기반의 pseudo-labeling을 도입하여 추후 소개하는 novelty classification과 novelty objectness branch에서 unknown을 탐지하도록 합니다.
Attention-driven Pseudo-labeling
OWOD는 unknown에 대한 GT가 존재하지 않는다는 가정이므로, unknown을 탐지하기 위해선 특정 과정을 통한 pseudo-labeling을 하는 것이 지배적입니다. 이전 논문인 ORE에서는 GT와 겹치지 않는 Top-1의 objectness score를 pseudo-unknown으로 지정하였습니다. 이처럼 해당 태스크의 논문에서는 pseudo-unknown을 위한 auto-labeling 기술을 제안하는 부분도 꽤나 중요한데, 본 논문의 저자는 ORE의 objectness score를 사용함은 RoI feature를 추출해내는 RPN이 known 클래스에 편향된다고 설명합니다. 이는 RPN의 학습 시 known 인스턴스가 classification loss에 관여하기 때문으로 보이는데, 이에 대한 자세한 설명이 없어 아쉽습니다.
저자는 DDETR을 도입하였으므로 결국 RPN이 없어, 새로운 pseudo-labeling 방식을 제안해야합니다. 이에 대해 저자는 위 Figure 1에 대해 설명 시 언급한 내용과 같이, 백본 네트워크에서 추출한 D‘차원의 attention map을 하나의 차원으로 합친 이후 특정 bbox 내의 attention map score, 다시 말해 feature map의 값 (magnitude of the feature activation)을 평균내는 방식으로 objectness score s_o(b) 를 정합니다. 수식으로 본다면 DDETR의 decoder를 타고 나온 object query q_e 에 대해, bipartite matching을 통해 GT로 판명나지 않은 unknown 후보군들의 bbox 정보 b = [x_b, y_b, w_b, h_b] (center (x,y)와 넓이 및 높이 (w, h))를 기반으로 아래의 수식 (결국 평균낸다는 의미)을 통해 objectness score를 계산하고, Top-k (학습 시에는 5개, 추론 시에는 50개)개의 unknown 후보군을 선정합니다. 수식과 그림을 통해 다시 복기해보시죠.
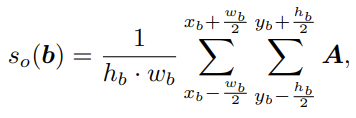
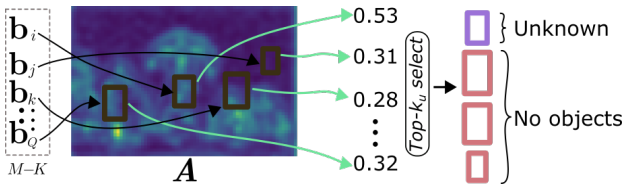
Novelty Classification
Introduction에 설명한 바와 같이, ORE는 energy-based unknown identifier가 known과 unknown 클래스를 분류하는 역할을 진행하며, 이 때 held-out validation set을 활용하여 energy 분포에 대한 weak unknown supervision을 줍니다. energy-based unknown identifier는 쉽게 설명하면 각 proposal에 대해 분포를 토대로 known과 unknown을 분류합니다. 본 논문의 저자는 held-out validation set에 의존하여 unknown에 대한 (weak) supervision을 주는 것이 문제라고 하네요. 저자는 OW-DETR이 unknown에 대한 supervision을 필요로 하지 않고, 오직 pseudo-unknown에 의존적으로 동작하고자 classification branch를 손봅니다.
standard DDETR에서 classification branch F_{cls} 는 known / background를 분류하였습니다. 이는 당연히도 unknown을 탐지하는데 문제가 있기에 저자는 pseudo-unknown에 “novel class” 라벨을 부여한 이후, pseudo-unknown은 novel class로 분류하도록 합니다. known과 background를 known과 unknown으로 바꾼, 사실 이는 자명히도 당연한 수순입니다.
Foreground Objectness
앞선 F_{cls} 가 query embedding q_e 를 class-specific하게 C개의 known과 1개의 unknown으로 분류하지만, 이 방식으로 known에 대한 지식이 unknown에 전달되진 않습니다 (저자는 known과 unknown 간 유사성이 있다고 생각하며 그러므로 지식 전달이 중요하다고 합니다). 또한 제안한 attention-driven pseudo-unknown이 결국 pseudo이기 때문에 (supervision이 없으므로), 많은 query들이 결국 background로 예측될 수 있다는 점도 언급합니다. 이를 극복하고자 저자는 classification branch 외에도 objectness branch F_{obj} 를 설계하여, 이번에는 known과 unknown이 아닌 foreground (known + unknown)과 background를 분류하도록 합니다. 이처럼 class-agnostic한 분류는 known 클래스로부터 unknown 클래스로의 지식 전달이 가능하게 하며 (known과 unknown이 동일한 분류로 묶이게 되니), 동시에 background를 잘 분류하는데 도움이 됩니다.
Training and Inference
Training
위의 제안한 F_{cls}, F_{obj} 와 기존의 bounding box branch F_{reg} 을 end-to-end로 학습하는 loss는 다음과 같습니다.
- \mathcal{L} = \mathcal{L}_n + \mathcal{L}_r + \alpha \mathcal{L}
차례대로, \mathcal{L}_n + \mathcal{L}_r + \alpha \mathcal{L} 는 각각 novelty classification, bounding box regression, novelty objectness scoring에 관한 loss로, classification과 objectness scoring에 focal loss가 사용되며, regression loss에는 l1 loss가 사용됩니다. 저자는 각 task (episode) 마다, 학습 시 이전 task에 학습한 클래스에 대한 catastrophic forgetting을 방지하고자 ORE에 사용한 exampler replay (이전 task의 학습 데이터 일부분을 토대로 finetuning을 진행하는 방식)를 동일하게 활용합니다.
Inference
추론 시 M개의 object query q_e 는 테스트 이미지 내 인스턴스들에 대해 예측합니다. 이 때, 위에서 언급한 바와 같이 t 시간대의 known 클래스 C^t 와 하나의 unknown 클래스에 대해 ( C^t = \left| \mathcal{K}^t \right| + 1 ) high class score를 unknown으로 선택하여 평가에 활용합니다.
Experiments
전체적인 실험 세팅은 ORE의 Pascal VOC (Task1) / MS-COCO (Task2, Task3, Task4)를 따릅니다. 아래 보이는 Table 1은 실험 세팅 설명을 위해 ORE의 벤치마킹을 가져왔습니다. 구체적으로 아래에서 살펴보겠습니다.
- 우선 설명의 간편함을 위해 A-OSE는 “Unknown으로 분류되어야 하는데 Known 클래스 중 하나로 예측된 개수”를 의미합니다. 즉, A-OSE가 사용되었음은 다른 말로 Unknown에 대해 다루고 있다고 여길 수 있습니다.
- Task 1은 Pascal VOC의 20개의 클래스로 학습합니다. 모든 평가는 Task1, Task2, Task3, Task4 모두 동일하게 Pascal VOC와 COCO의 평가 데이터를 합친 데이터 셋을 사용합니다 (굉장히 중요한 부분입니다). Task 1에 대해 평가 시, 이전에 알고 있던 클래스는 없으므로 해당하는 20개의 클래스에 한정하여 mAP를 측정합니다. 이 때, A-OSE를 살펴보면 8234개임을 알 수 있는데, 이는 곧 20개의 클래스 이외의 Unknown으로 분류되어야하는 객체들이 20개의 클래스 중 하나로 분류되었음을 의미합니다.
- 사실, A-OSE 지표는 하나의 함정이 숨어져 있습니다. 이는 A-OSE의 측정 방식의 전제가 “Known으로 분류된 객체”이므로, Unknown으로 분류되지 않고 BG로, 즉 예측에 실패했더라도 카운팅되지 않습니다. 물론 A-OSE는 “Unknown을 얼마나 Unknown으로 잘 분류하는지”에 의의가 있다고 할 때 큰 문제가 되진 않습니다. – 본 논문의 저자는 이를 변경하고자 “U-Recall” 평가 측도를 제안합니다.
- 다시 돌아와, Task 2에서는 t2 시간대로 나뉜 데이터에 대해 탐지하여, Unknown으로 분류된 객체 중 Task 2에 해당한다면 어노테이션을 제공됩니다. 이전 Task 1의 평가에서 Task 2에 해당하는 클래스들은 Unknown이였지만, Incremental learning을 통해 어노테이션을 제공받아 특정 클래스로 분류할 수 있습니다. 이 과정은 Task 3, Task 4에 이어집니다.
- Task 1 이후의 각 Task마다, Exampler replay 방식을 통해 catastrophic forgetting을 방지하기 위해 이전 Task의 약 10개정도의 샘플이 학습에 추가됩니다. 예를 들어, Task 2 학습 시 Task 1의 데이터가 10장 정도만 학습하여, 이전 Task의 객체들을 잊어버리는 현상을 최대한 방지하기 위함입니다.

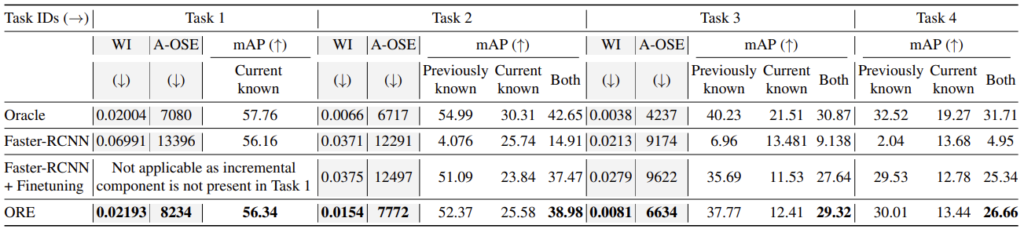
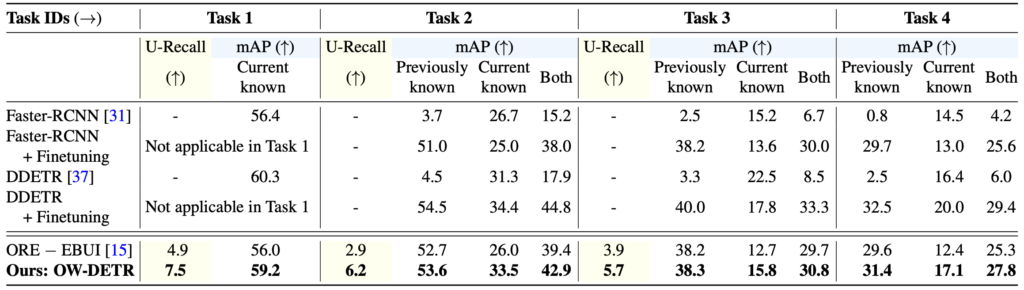
ORE와 동일한 세팅에서의 벤치마킹입니다. ORE의 논문을 살펴보면, held-out validation dataset을 통해 데이터의 energy를 측정한 후 known과 unknown을 분류하는데, 저자는 pair comparison을 위해 이 (EBUI)를 제거한 후 비교하였습니다. U-Recall을 보면 알 수 있듯, 여전히 owod의 방법론들이 Unknown에 대한 탐지 성능 자체가 많이 높지 않음은 알 수 있습니다. 또한 Previously Known에 대한 성능이 Task가 지남에 따라 낮아짐을 알 수 있는데, 이것을 incremental learning에서 해결하고자 하는 catastrophic forgetting에 대헤 이야기하고 싶습니다. 새 학습 데이터만 보게 되어 대해 이전의 학습 데이터에 대해 잊어버린다는 것이죠.
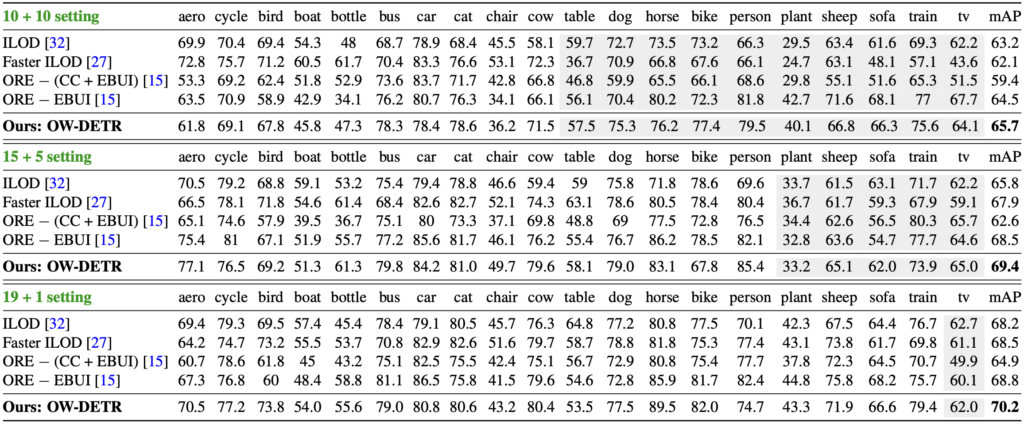
Incremental Object Detection (iOD)를 평가하기 위한 벤치마킹 표도 존재합니다. 10(Known) + 10(Unknown), 15+5, 19+1의 설정에서 incremental 방식으로 학습을 진행 시, 새로운 데이터에 대해 얼마나 잘 찾는지, 그래서 이전의 데이터는 얼마나 잘 잊어버리지 않고 전체 mAP를 높게 내는지에 대한 성능을 보시면 됩니다. 사실 owod의 철학과 방법론에 집중하며, 성능면에서는 현재까진 다소 낮아보임과 동시에,해당 태스크가 나온지 얼마되지 않아 각 논문들마다 본인들이 유리한 방식의 평가 지표등을 만들어내며 리포팅하는 시기라, 성능은 표 정도를 살펴보고 넘어가면 좋을듯 합니다.
이외의 Appendix를 참고하시면 다양한 정성적 결과를 비교하여 확인하실 수 있습니다 (이 이상의 이미지는 용량으로 인해 업로드가 안된다고 하네요..허허). 다음에는 owod의 최신 방법론을 살펴볼텐데, 그 때는 현재의 성능과 비교하여 단 1-2년 사이 성능이 얼마나 오른지에 주목하여 살펴봐주시면 좋을것 같습니다. 감사합니다.
안녕하세요. 지난번 세미나 때 한번 발표해주셔서 내용을 이해하는데 무리는 없었지만 다시 읽다보니 궁금한게 하나 생겨서요.
feature map의 값을 평균내서 pseudo-labeling을 수행하는 부분에 대하여 리뷰 글을 읽어보니 ” Top-k (학습 시에는 5개, 추론 시에는 50개)개의 unknown 후보군을 선정합니다.”라는 글이 있더군요.
근데 pseudo-labeling이라 함은 모델 학습을 수행하는데 있어, 즉 loss를 계산하는데 있어 사용하는 것이다보니 학습 시에 진행하는 과정이라고만 이해했는데 추론 시에 50개의 후보군을 선정한다는 것은 무슨 의미인가요? 학습된 모델은 추론 단계에서 곧바로 known인지 unknown인지 구분하는 줄 알았는데, 혹시 추론 단계에서도 labeling을 과정을 거쳐야만 unknown이라는 class를 구분할 수 있는 것인가요?
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
음, 제가 본 질문을 읽고 어? 이상하다 하며 다시 논문의 그 부분을 읽어보았는데,
추론 시에는 object query 중 top-50개를 unknown으로 선정하는 듯 합니다.
음,, 사실 그래도 논문의 한 줄 쓰인 부분으로 제가 추론해서 글을 쓸 때 확신이 없어지네요. 다음주에 해당 논문의 코드로 베이스라인을 잡을 때 코드를 자세히 확인해본 이후 추가 댓글달도록 하겠습니다.
뭔가 놓친 부분인것 같네요. 짚어주셔서 감사합니다.
안녕하세요, 이상인 연구원님. 좋은 리뷰 감사합니다. 기본적일 수도 있겠지만 제가 해당 task가 낯설어서.. 질문 몇개 남기도록 하겠습니다.
1. Self-Supervised Learning이 아닌 ImageNet pretrained 가중치를 사용하는 논문들이 있다고 하는데, 그럼 다른 OWOD 논문에서는 ImaegNet pretrained 가중치를 사용하는 것에 문제가 있다고 생각하지 않는 것인가요?
2. unknown의 objectness는 어떻게 구하나요? ojbectness branch에서 known+unknown과 background를 분류하는데, 여기서 known만을 제외해서 구하게 되는 건가요?
3. OWOD 적용 과정을 보면 objectness unknown class들을 oracale에게 쿼리하고 새로운 클래스를 추가하는 것이 반복되는 것 같은데, 그럼 이 사이클이 반복되는 것인가요?
4. task 1,2,3,4는 뒤로 갈수록 unknown class가 추가되는 것인가요?
5. OWOD의 평가 지표가 U-Recall인것으로 보이는데, 이는 어떻게 측정되는 성능인가요?
안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. 음, ImageNet Pretrained Weight에 대해 누구는 “당연히 상관없지 않느냐”, 또 저와 같은 누구는 “문제가 될 수 있다”는 주장인데요, 은연 중 사용되는 바로 보입니다. 상관없지 않느냐는 입장에선 단순히 ImageNet Pretrained Weight는 백본에서 좋은 Feature 추출에 사용되지, 그 이상의 Detector에 관여하곤 있지 않기 때문으로 보기 때문으로 보입니다.
2. Unknown의 objectness는 각 방법론에 따라 정의하기 다릅니다. Faster R-CNN 기반의 프레임워크에서는 RPN의 objectness score를, 본 논문에서는 위에 언급된 바와 같이 윈도우 내의 Magnitude의 평균으로 정합니다.
3. 네. 해당 사이클이 계속 반복되는게 이상적인 owod 태스크입니다.
4. 위에 평가 데이터 셋 양식이 있는데, MS-COCO에서 Pascal VOC와 겹치지 않는 60개의 클래스를 Task1, Task2, Task3로 나누어 Unknown으로 지정하므로, 뒤로 갈 수록 unknown class가 추가됩니다.
5. U-Recall은 단순히 Unknown에 대한 Recall으로, 모델이 얼마나 Unknown에 대한 예측을 잘 하는지에 따라 달립니다. BG를 Unknown으로 예측하지 않는다면 올라간다고 생각해도 되겠습니다.
리뷰 잘 읽었습니다.
리뷰 초,중반부 >>>> transformer의 inductive bias가 적은 특성이, 오히려 unknown에 대한 가정이 적어 탐지 시에는 더욱 효과적<<<< 해당 부분에서 궁금한 점이 있는데,,, unknown 탐지 시 locality와 관련된 inductive bias가 적은것이 더 도움이 된다라는 게 뭔가 느낌은 알 거 같은데 잘 와닿지가 않아서요,, 저자는 그냥 가정? 혹은 추측으로 말한건가요, 아니면 뭔가 더 추가적인 언급이 있었나요?? 감사합니다!
안녕하세요. 리뷰 읽어주셔서 감사합니다.
음, 제 생각에도 그렇습니다. 저자의 추가적인 언급은 없었지만, Trasformer 자체가 결국 Inductive bias가 CNN에 비해 약하고, 이는 오히려 추가적인 가정이 없기 때문에 더 많은 표현력을 보이지 않을까 즉, 한 객체에 대해 Unknown이라는 objectness로 인식될 수 있지 않을까 생각합니다.