이번에 소개드릴 논문은 ZoeDepth라는 논문입니다. 비록 아카이브에만 머물고 있는 논문이지만, 인텔과 KAUST에서 공개한 논문이기도 하고, github star도 1.9K라는 점에서 상당한 저력이 있는 논문이라고 생각합니다.
먼저 해당 논문은 Monocular Depth Estimation의 일반화 성능을 크게 향상시키기 위한 foundation model을 제안하는 것을 목표로 합니다. Depth Foundation model에 대하여 가장 시초가 되는 논문은 TPAMI2020에 게재된 Midas라는 논문이며, 해당 논문을 시작으로 DPT, ZoeDepth 그리고 24년도 기준 DepthAnything이라는 논문이 제안되어왔습니다.
Depth Anything은 지난번에 리뷰를 했었는데, 지금 리뷰하는 ZoeDepth라는 논문이 DepthAnything의 이전 연구격 논문이라고 생각하셔도 무방할 것 같습니다. 그럼 리뷰 시작하겠습니다.
Intro
Monocular Depth Estimation은 말 그대로 이미지 한장에 대하여 영상 내 환경에 대한 거리를 측정하는 분야입니다. 이러한 단안 영상 깊이 추정은 크게 Metric Depth Estimation(MDE)와 Relative Depth Estimation(RDE)로 크게 나눌 수 있습니다.
먼저 MDE는 카메라와 객체 사이에 거리를 절대적인 물리적 단위, 즉 meter 단위로 측정하는 것을 의미합니다. 어찌보면 MDE는 깊이 추정이라는 단어를 딱 들었을 때 누구나 당연하게 생각할 법한 방식입니다. 카메라와 객체 사이에 정확한 거리는 자율주행, 영상 편집, 무인로봇, AR 등 상당히 많은 분야에서 활용이 됩니다.
근데 metric depth 추정 모델이 다중 데이터셋에 대해서는 종종 성능이 손상되는데, 특히 indoor와 outdoor와 같은 depth scale의 편차가 클 때 이러한 문제가 크게 발생합니다. 이는 모델이 Metric Depth를 학습할 때 사용하는 학습 데이터의 Depth scale이 환경마다 상이하기 때문입니다.
예를 들어, 실내 환경에서는 촬영되는 장소 및 환경적 요소들이 카메라와의 거리가 멀어봐야 10미터 이내 정도로 한정이 됩니다. 반면에 Outdoor 상황에서는 카메라로부터 거리가 한없이 멀거나 보통 Lidar의 유효 거리 (80m~200m) 정도를 최대 거리로 잡을 수 있습니다.
따라서 모델이 indoor 환경과 outdoor 환경을 같이 학습을 하게 될 경우 모델이 학습해야하는 depth scale의 편차가 너무 심하다보니 학습이 잘 진행되지 않는 경우가 자주 발생합니다. 그래서 일반적으로는 하나의 뎁스 모델이 하나의 환경에 과적합시키는 방식으로 진행이 되죠.
반면 Relative Depth Estimation(RDE)은 스케일이라는 요인을 제거함으로써 여러 환경 내 큰 깊이 스케일 변화를 다룰 수 있습니다. 즉 RDE 방식은 카메라와 객체 사이에 거리를 측정한다기보다는 객체와 객체 사이에 상대적인 거리를 측정하는 방식을 이용합니다. 가령 사과와 바나나가 함께 촬영되었을 때 사과와 바나나가 카메라로부터 정확히 얼마나 멀어져있는지는 모르지만, 사과가 바나나보다 카메라에 더 가까이 있다라는 느낌으로 학습이 되는 것이죠.
이러한 RDE 방식은 다양한 장면과 데이터셋 심지어 3D 영화 데이터셋으로도 모델을 학습시킬 수 있다는 장점이 있지만, metric 정보를 가지고 있지 않기에 활용도 측면에서는 크게 제한이 되긴 합니다. (카메라와 객체 사이에 정확한 거리를 알려주지는 않으니..)
보통 Generalization Performance를 향상시키기 위한 목적으로 Depth foundation model을 만드는 논문들은 이 RDE를 학습하는 방식으로 진행합니다. 다양한 데이터 셋을 섞어서 학습을 수행하다보니 MDE로 학습을 하게 되면 모델의 학습이 불안정할 수 밖에 없는 것은 당연하고, 데이터셋의 스케일을 확장하기에도 어렵기 때문에 어쩔 수 없이 RDE 방식으로 학습을 하는 것이지만, 저자들은 결국 MDE가 활용성 측면에서 더 중요하기 때문에 MDE를 잘하는 model을 만들어야한다고 주장하는 것이죠.
따라서 저자들은 RDE와 MDE의 학습을 2-stage 방식으로 나눠서 진행하여 model의 generalization performance는 유지한체로 MDE도 보다 잘 수행할 수 있는 foundation model을 제안합니다.
먼저 첫번째 학습 단계에서는 일반적인 encoder-decoder 구조의 depth network가 relative depth 추정을 수행하도록 학습을 시키는데, 이때 Midas에서 제안한 학습 방식 활용을 온전히 활용합니다. 이러한 RDE 학습은 방대한 양의 데이터로 학습을 진행할 수 있기에 모델의 일반화 성능을 키우는데 중요합니다.
그 다음 metric depth estimation 수행을 위해 metric depth dataset에 대하여 fine-tuning을 수행해주는데, 이때 light-weight metric head를 각 도메인 별 (즉 indoor인지 outdoor인지 구분)로 하나씩 추가하여 학습을 진행합니다. 참고로 metric head의 크기는 전체 모델의 파라미터 중 1% 미만 이라고 하네요.
학습 단계에서 각 도메인 별로 헤드를 나누었기 때문에 추론 단계에서는 encoder의 특징을 토대로 적절한 head를 사용하는 것을 자동적으로 찾아주는 분류기 헤드를 따로 설계하였다고 합니다.
Method
그럼 방법론에 대해서 자세히 살펴보겠습니다.
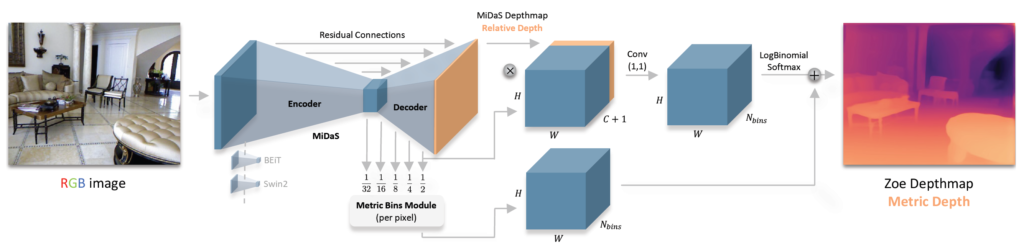
일단 크게 Encoder-Decoder 구조로 이루어진 Depth Network가 존재하며, 그 다음 저자들이 제안하는 Metric Bins Module 과정이 뒤에 존재하게 됩니다.
보통 Depth Foundation model들은 Midas가 제안하는 데이터셋 mixing 방식과 scale-shift invariance loss를 사용하게 됩니다. 따라서 Depth Network의 모델 구조는 취향껏 사용하게 되는데 가장 대표적으로는 DPT라고 하는 ViT 기반의 Depth Network를 많이들 활용합니다.
저자들 역시 DPT의 Decoder는 그대로 활용하게 되고 Encoder의 경우 ViT가 아닌 BeiT를 사용하였다고 합니다. 취향에 따라서 Encoder를 Swin Transformer와 같이 다른 Transformer 구조를 사용해도 됩니다.
LocalBins Review
이 논문에서 가장 핵심은 metric depth estimation을 수행하는 bin module입니다. 저자들은 ECCV2022에 게재된 LocalBins라는 방법론에 많은 영감을 얻었다고 합니다. Local Bins는 Depth Network의 multi-scale feature를 입력으로 하여 각 픽셀별로 빈의 중심을 추론하는 모듈을 제안한 논문입니다.
이때 최종 depth는 빈 센터들에 대하여 그에 대응되는 예측된 확률 분포를 통한 가중합 방식으로 결정됩니다. 이러한 bin 기반의 깊이 추정 방식에 대해 익숙치 않으신 분들은 아래 그림을 참고하시면 좋을 것 같습니다.
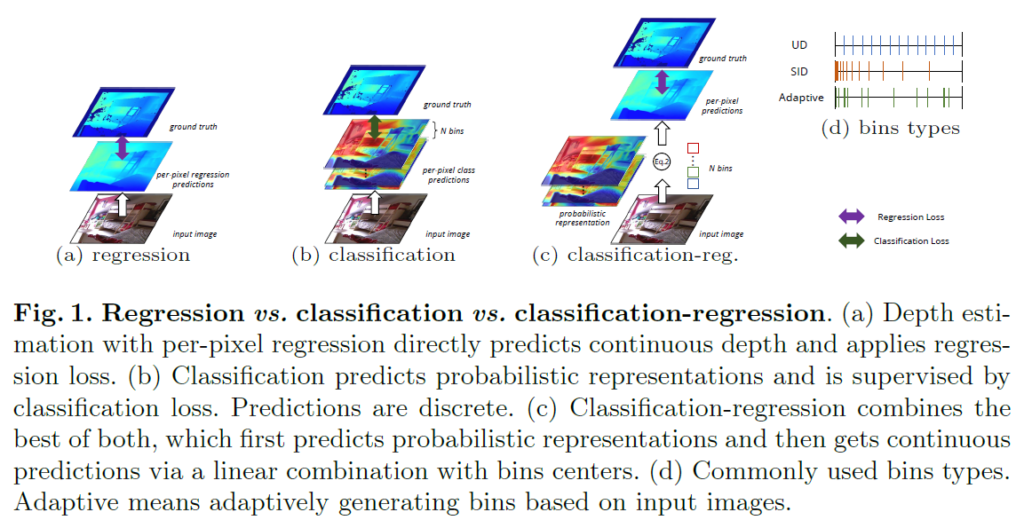
위에 그림은 깊이 추정을 수행하는 방식에 대해 크게 3가지를 나타낸 것인데, 가장 많이 활용되는 방식은 regression 방식으로 깊이라는 값이 연속적인 값이기 때문에 픽셀 레벨에서의 regression을 하는 것을 의미합니다. 그리고 최근 MDE 연구들에서는 regression 대신에 일정한 거리감을 나타내는 depth interval bin을 구성하고, 해당 bin들에 대하여 확률 분포를 계산해 어떠한 빈들의 조합으로 깊이를 추정할 것인지를 결정하는 것이죠.
이러한 bin 기반의 깊이 추정 방식은 그냥 영상 전체에 대해 depth min~depth max까지의 간격을 나타내는 global bin을 설정합니다. 하지만 LocalBins이라는 방법론은 각 local마다 적절한 bin의 구간이 있을 것이기 때문에 픽셀 별로 맞춤형 bin을 추론하자고 주장하였습니다.
그래서 LocalBins 방법론의 경우 초기에 서로 다른 seed bin이 각 픽셀 별로 존재하게 되는데, 이 빈들은 모든 디코더 레이어마다 MLP 레이어를 통과하여 2개로 분리된다고 합니다. 결과적으로 N개의 디코더 레이어를 다 통과하고 나면 각 픽셀들은 2^n개의 시드 빈들이 생성되는 것이죠.
이러한 시드 빈 생성과 동시에 디코더 특징들로부터 softmax를 취하여 2^{n} 개의 시드 빈 센터들 c에 대하여 대응되는 확률 분포 p를 계산하며 최종 depth 값은 수식1처럼 계산이 됩니다.
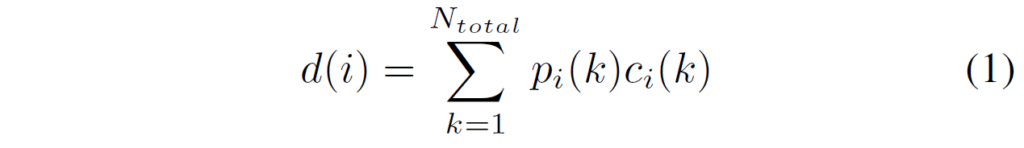
Metric bins module
저자들은 기존의 LocalBins 방법론이 했던 것처럼 bottleneck laery에서 적은 수의 bin으로 시작해 점차 늘려나가는 것 대신에, 처음부터 모든 빈 센터들을 추론한다음 디코더를 통과하면서 보정하는 방식으로 변경하였다고 합니다.
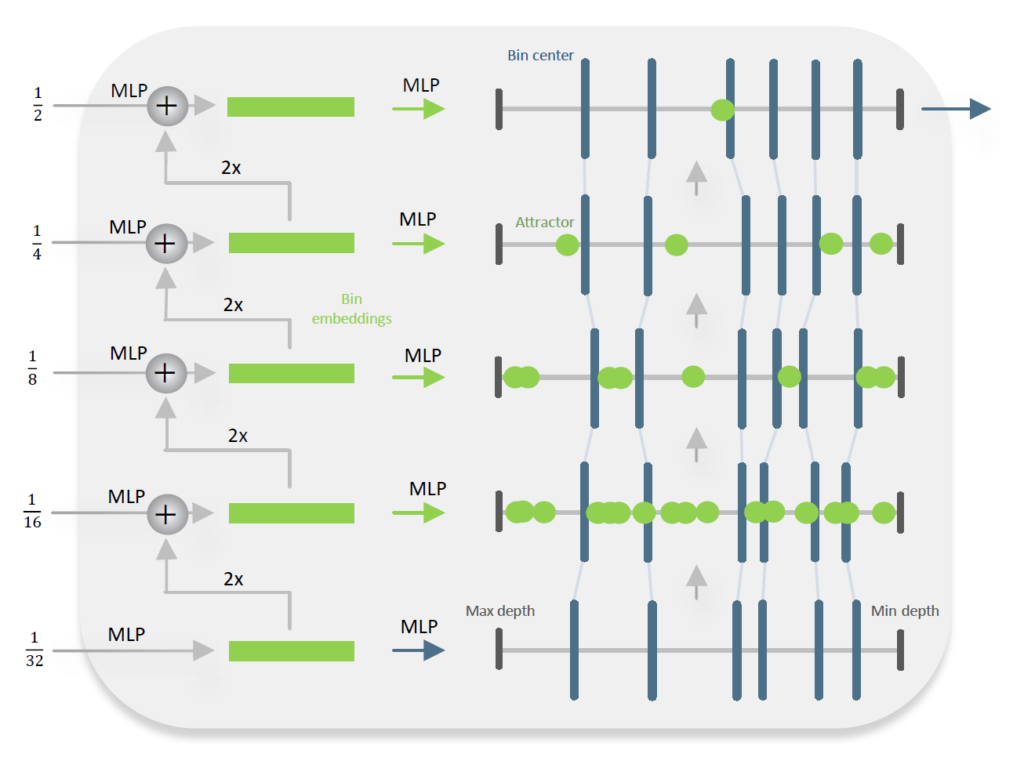
그림 2는 저자들이 제안한 Metric Bins Module의 구조를 나타낸 것인데, 제일 작은 해상도 (i.e., 1/32)에서부터 최고해상도 (i.e., 1/2)까지 그림의 예시 기준 모두 6개의 빈으로 개수가 통일되어 있으며, 해상도가 올라갈 때 마다 bin을 보정하는 과정을 통해 빈의 위치가 적응적으로 변경되는 것을 확인하실 수 있습니다.
즉 저자들은 빈들의 multi-scale refinement를 수행하는데 있어 각 스케일 마다 bin들을 분리시키는 것이 아닌 보정하는 방식을 취한 것인데, 이 보정이라는 개념은 depth interval 위에 존재하는 bin들을 왼쪽 혹은 오른쪽으로 위치를 조정하는 것을 의미합니다.
조정하는 방식에 대해 설명드리면, 디코더 feature에 대해 mlp를 태워서 특정 픽셀 위치에 대하여 n개의 attractor point n_{a} 들을 예측하는데, 이 attractor point들은 빈의 중심 위치를 변화시키기 위한 변화량 값을 계산하는데 활용됩니다. (수식2 참고)
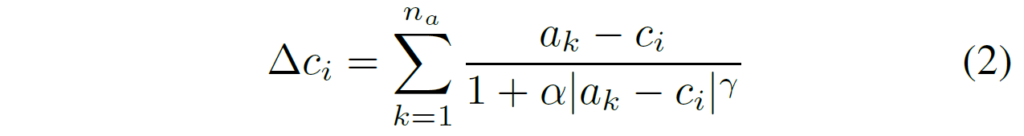
수식2에서 알파와 감마 값은 각각 attractor의 강도를 조절하는 하이퍼파라미터라고 합니다. 결과적으로 \triangle c_{i} 는 bin center를 의미하는 c의 위치를 조정하는 변화량 값으로 갱신된 bin 중심은 c'_{i} = c_{i} + \triangle c_{i} 로 표현할 수 있습니다.
Log-binomial instead of softmax
bin 기반의 깊이를 추론하는 방식은 수식1에서 설명했다시피 depth interval을 의미하는 bin들과 그에 대응되는 확률 분포 p에 대한 가중합 방식으로 계산이 된다고 했습니다. 이는 모델이 bin을 잘 생성하는 것 뿐만 아니라 확률 분포 p 역시도 올바르게 추정을 해야하는 것이죠.
이전의 adaptive bins 방법론들은 빈 중심에 대한 확률 분포를 예측하기 위해 단순히 softmax를 사용했습니다. 확률 분포를 계산한다는 관점에서 classification과 같은 이산적인 분류 방식을 그대로 차용한 것이죠.
분류와 같이 순서가 상관이 없는 분야 (즉 2번째 클래스와 3번째 클래스는 서로 아무 관련이 없음)에서는 softmax가 잘 동작하는 것은 맞지만 bin 같은 경우에는 순서가 중요한 개념이다보니 순서에 따른 확률 예측을 하는 것이 타당하다고 저자들은 주장합니다.
실제로 아래 그림은 얼굴 사진을 보고 나이를 맞추는 분류기인데, 모델이 예측한 3가지의 서로 다른 분포가 Cross-entropy로 error를 계산할 시 모두 동일한 값을 가진다고 합니다. 하지만 똑같은 CE error 값이라 할지라도, 분포 A와 B보다는 C라고 예측하는 것이 나이를 예측하는 관점에서는 더 정확하다고 볼 수 있습니다. 딱 봐도 어른인데 senior나 teen이 아닌 baby가 높은 분포로 예측이 되면 학습이 잘 못 되었다고 볼 수 있는 것이겠죠?
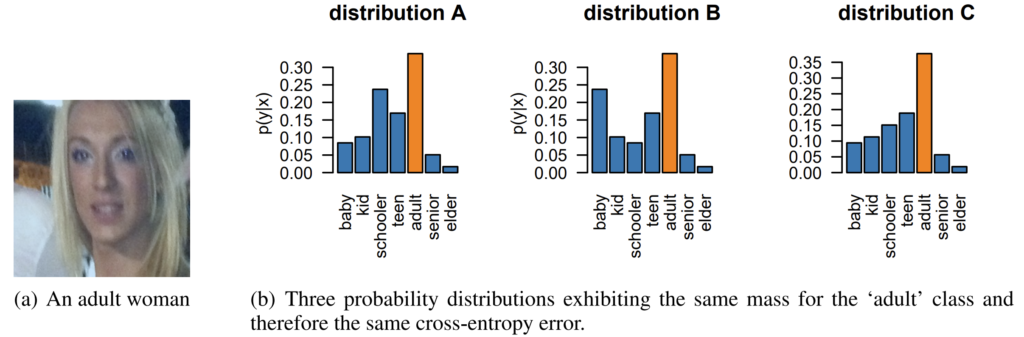
아무튼 저자들은 이렇게 순서가 어떤 분포에 있어서 중요한 개념인 task에서 자주 활용이 되는 binomial distribution이라는 것을 활용해 모델을 학습시켰다고 합니다.
이러한 binomial distribution에서 가장 중요한 파라미터는 최빈값의 위치를 결정하는 q라는 인자입니다. 저자들은 디코더 특징과 relative depth map을 concatenation한 뒤 2채널의 출력 (q-mode, t-temperature)을 예측합니다.
이렇게 예측된 q와 t값들은 아래 수식을 통해 확률 분포 p로 계산이 됩니다.
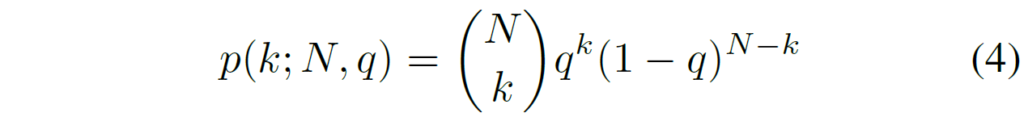
여기서 N은 bin의 최대 개수를 의미합니다. 저자들은 참고로 N의 값이 64로 크기 때문에 수치적 안정성을 위하여 Stirling’s approximation이라는 기법을 적용했다고 합니다.
사실 Stirling 근사화 방식이 정확히 무엇인지 논문에서 따로 설명이 없지만 수식4를 통해 계산한 확률 값에다가 아래 수식을 적용해주는 것이라고 합니다.
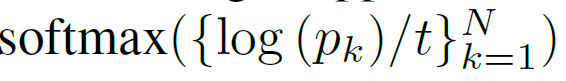
여기서 방금 softmax가 순서의 개념을 못살리지 않아서 안쓴다고 하지 않았나? 라고 생각하실 수 있는데, 이미 수식4를 통해 확률을 계산한 상황에서 취하는 softmax는 값을 정규화하는 함수의 역할로써 쓰이기 때문에 unimodality의 성질을 그대로 유지한다고 합니다.
아무튼 이렇게 확률분포를 계산하게 되면 계산된 bin과의 수식1 과정을 통해 최종적인 깊이를 추론할 수 있게 됩니다.
Routing to metric heads
다음은 메트릭 헤드를 어떻게 선별할 것인지에 대한 방식입니다. 인트로에서도 잠깐 소개를 드렸었는데, 특정 상황 (indoor, outdoor)별로 적절한 bin을 생성하기 위해 multiple head 구조를 채택하였기 때문에 입력에 맞는 적절한 head를 찾는 router가 필요합니다.
이러한 routing 방식으로 크게 3가지 방식을 골랐는데, 첫번째 방식은 그냥 학습과 추론 단계에서 모두 지금 입력이 어떠한 상황인지를 알려주는 label 제공 방식이며, 두번째 방식은 입력에 대하여 상황을 판단할 수 있는 분류기를 학습시키는 방식 (때문에 학습 때는 입력 상황에 대한 label이 필요로 하지만, 추론 단계에서는 필요가 없음.), 마지막으로 두번째 방식과 동일하게 학습 가능한 분류기가 따로 존재하지만, 학습 시에도 환경에 대한 레이블이 없는 경우라고 합니다. 근데 마지막 autor Router 같은 경우에는 도대체 어떻게 학습을 시켰는지 모르겠네요? 그냥 depth estimation 학습에 사용되는 loss를 분류기에도 적용한 거 같기도 하구요.
Experiments
Depth Foundation model에 학습에 사용한 데이터 셋은
학습에 사용한 데이터 셋은 HRWSI, BlendedMVS, ReDWeb, DIML-Indoor, 3D Movies, MegaDepth, WSVD, TartanAir, ApolloScape and IRS 그리고 KITTI와 NYU v2로 총 12가지입니다. 평가에는 위에 12개의 데이터 셋 외에 다양한 데이터 셋에서 zero-shot performance를 평가하게 되구요.
테이블에서 모델 이름이 ZoeD-{RDPT}-{MFT} 꼴로 표기가 되어있을텐데, 앞에 ZoeD는 자신들의 방법론 이름인 ZoeDepth의 약자이며, RDPT는 relative depth estimation 사전학습을 하였는지 안하였는지를 의미합니다. 그래서 X이면 사전학습을 안한 것이고, M12면 12개의 Mixed dataset으로 사전학습을 수행했다는 것이죠. 마지막으로 MFT는 metric depth estimation 학습을 위한 데이터 셋 이름으로 각각 N(YUv2), K(ITTI)로 구분이 됩니다.
그럼 정량적 결과부터 하나씩 살펴보겠습니다.
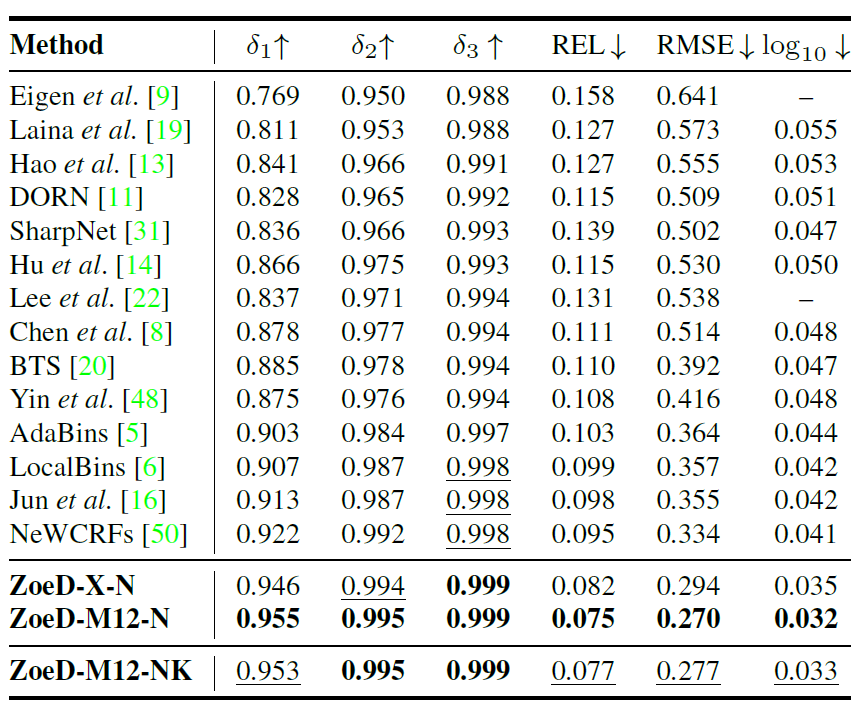
위에 표는 NYUv2 Indoor dataset에서의 정량적 비교 결과입니다. 보시면 저자들이 제안하는 방법론이 가장 좋은 성능을 보여주는 것을 확인할 수 있는데, 한가지 재밌는 점은 대용량의 데이터셋으로 사전학습을 진행하지 않은 경우에도 다른 방법론들보다 더 좋은 성능을 보여주는 것을 확인할 수 있습니다.
물론 Mix12 데이터셋으로 사전학습을 하게 되면 전반적으로 더 정확한 성능을 보여주기도 합니다만, 저자들이 주장하는 바로는 이러한 대용량 데이터 셋 없이도 자신들이 제안하는 모델 구조(빈 모듈)에 대한 장점 덕분에 다른 SOTA 방법론들보다 더 좋았다고 주장합니다.
근데 저자들이 BeiT 백본을 사용하는 것은 알고 있는데 거기서 Tiny, Small, Base, Large 중 어떤 모델을 사용했는지를 잘 모르겠네요. 만약 BeiT large 모델을 사용한 것이라면 다른 방법론들과의 모델 파라미터 수 차이로 인하여 성능이 더 높게 나오는 것일지도 모르겠습니다.
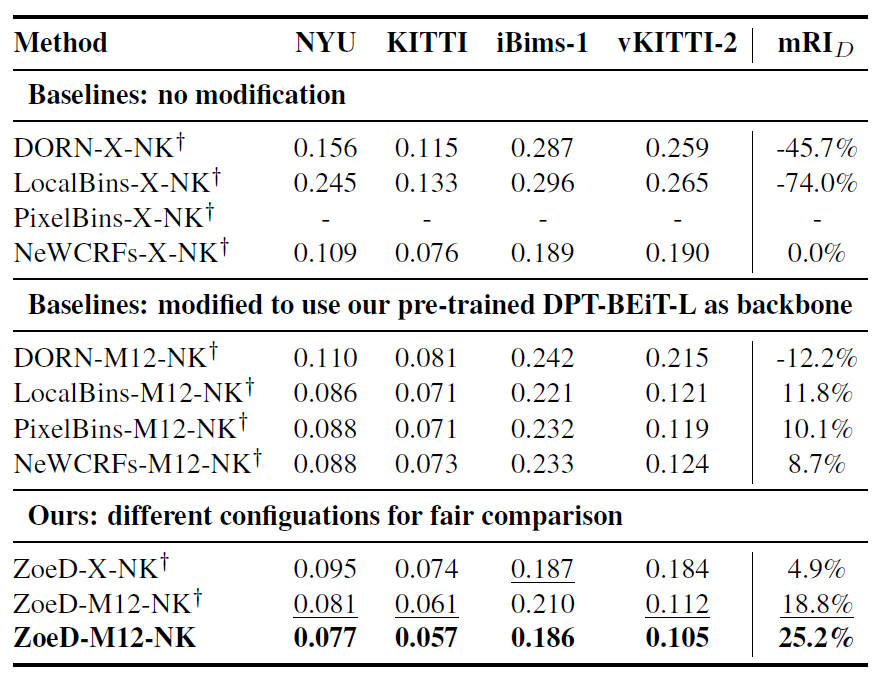
다음 실험결과는 다른 SOTA 방법론들과 자신들의 방법론간에 더 정확한 비교 및 검증을 위해서 백본 모델 변경과 multi-head 실험 유무에 대한 실험 결과를 보여줍니다.
공통적인 실험 과정은 Metric Depth Estimation을 할 때 indoor 데이터셋인 NYUv2와 outdoor 데이터셋인 KITTI 데이터셋을 동시에 사용한다는 점인데, 이 경우 indoor와 outdoor 사이에 depth scale 차이로 인하여 모델 학습이 상당히 어렵게 됩니다.
실제로 LocalBins와 PixelBins라는 방법론들은 모두 높은 REL 에러 값을 가지게 되는데, 이는 두 데이터셋의 서로 다른 depth scale에 대하여 모델이 적절한 bin을 학습하기 어려워서 발생한 문제라고 합니다.
표의 가운데 행에 대한 실험은 기존의 SOTA 방법론들의 백본을 저자들이 Mix12 데이터셋으로 사전학습한 모델 백본으로 변경하였을 때의 성능인데, 이 경우에는 DORN을 제외한 3가지 방법론들이 비슷한 수준의 좋은 성능을 보여주고 있습니다. 이는 Relative Depth Estimation을 사전학습 하는 것이 MDE를 학습하는데 상당한 도움을 준다는 것을 보여주는 결과이기도 합니다.
그리고 마지막으로, 저자들이 제안하는 ZoeD의 경우 사전학습을 하지 않았을 때에도 SOTA 방법론들 대비 좋은 성능을 보여주고 있으며, 여기서 십자가 표기가 없는 경우 (즉 indoor, outdoor에 따라 depth head가 다중으로 구분되는 경우)에 가장 좋은 성능을 보여줍니다. 저자들은 해당 결과를 통해 상황에 맞추어 depth head를 따로 두는 것이 파라미터 효율적이면서도 성능을 크게 개선시켜줄 수 있다고 합니다.
다음은 학습 때 전혀 보지 않은 Unseen dataset에 대한 zero-shot 평가 결과입니다.
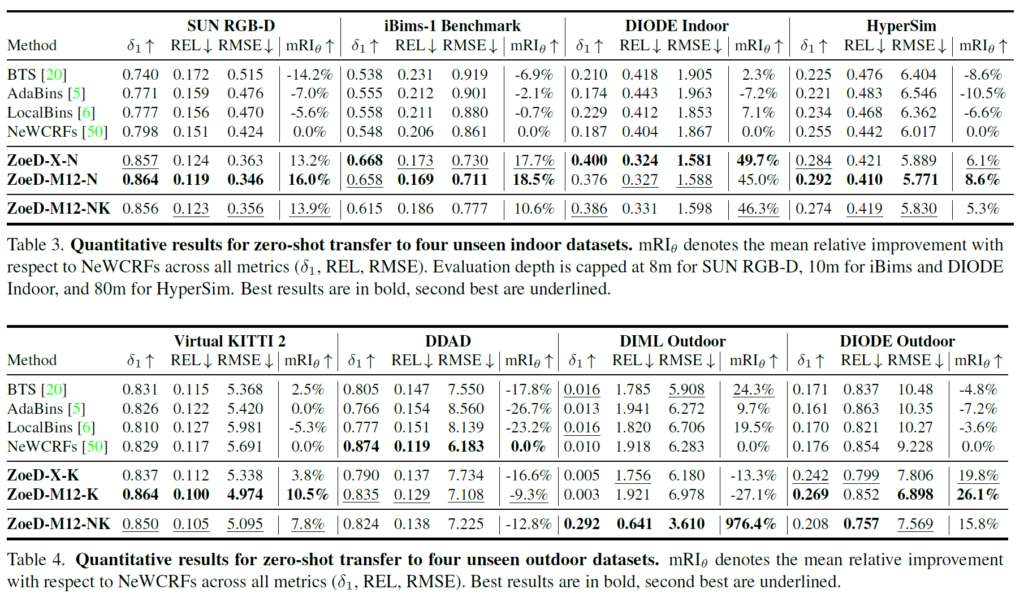
첫번째 표는 Indoor에 대한 결과를, 2번째 표는 outdoor 데이터셋에 대한 결과를 나타낸 것인데, 확실히 MDE fine-tuning을 할 때 indoor 셋만으로 학습한 것이 indoor 셋들 평가할 때 대부분 좋은 성능을 보여주고, outdoor 셋 평가를 할 때 outdoor 셋으로만 학습한 것이 가자아 좋은 성능을 보여주긴 합니다. 데이터셋의 종류가 많기에 경향성이 항상 일정한 것은 아니지만, 대략적인 성능 향상 폭을 봐주시면 좋을 것 같습니다.
Ablation Study
다음은 ablation study입니다.
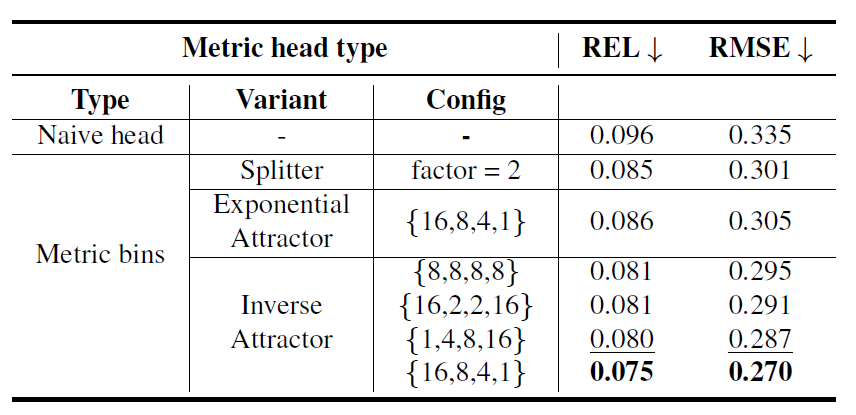
위에 표는 depth head에 대한 ablation study인데, 가장 첫번째 naive head는 regression 방식으로 깊이 추론을 한 것을 의미합니다. 그리고 bin 기반의 가중합 방식으로 깊이를 추론하는 것을 Metric bins 방식이라고 하는데, 여기서 splitter는 bin의 개수가 2배씩 증가하는 것을 의미합니다. 즉 ECCV2022의 LocalBins 방식이라고 보시면 됩니다.
그리고 Attractor 방식은 Split 방식이 아니라 매 decoder stage마다 bin을 조정하는 역할이라고 했는데, 여기서 Inverse Attractor가 위 방법론 소개 중 수식2의 방식입니다. 저자들은 Inverse attractor를 16, 8, 4, 1 꼴로 설정하였을 때 가장 좋은 성능을 보여주었다고 합니다.
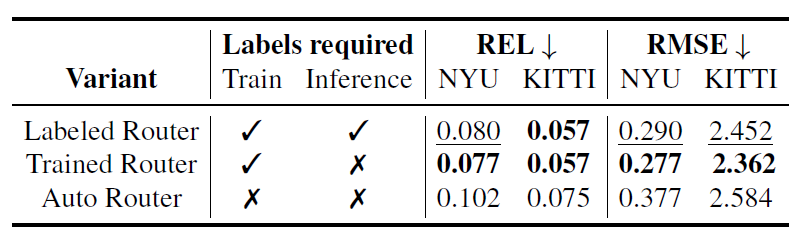
다음은 Router에 대한 결과입니다. Rotuer의 경우 3가지 방식이 있다고 소개드렸는데, 가장 좋은 성능을 보여준 것은 학습 때만 indoor인지 outdoor인지 하는 환경정보를 레이블로 제공해 학습시키고 평가때는 분류기의 추론값을 기반으로 head를 설정하는 Trained Router 방식이 가장 좋은 성능을 보여주었다고 합니다.
사실 Labeled Router가 추론때도 label을 제공해주니 더 좋은 성능을 보여주지 않을까라는 생각도 들긴 했는데, 모델 학습 단계에서 분류기를 통한 loss가 모델 전체에 반영이 되기 때문에 환경에 맞추어 더 좋은 feature representation을 지녔기 때문이 아닐까 라는 추측을 합니다.
결론
이전 연구들의 흐름을 많이 활용했기 때문에 막 엄청 참신하다 그런 느낌을 받지는 못했지만, foundation model을 학습시키는데 있어 많은 컴퓨팅 자원이 필요로 하는 관점에서 저자들이 보여준 다양한 실험 및 그 결과에 대한 경향성이 관련 연구를 수행하는 연구자들에게 도움이 되지 않았는가 합니다. 그리고 Foundation model들이 Metric Depth를 수행하는데 있어 ZoeDepth의 framework을 종종 활용하는 관점에서도 어찌보면 큰 기여를 하는 것일지도 모르겠네요.
안녕하세요 정민님, 좋은 리뷰 감사드립니다.
우선 처음보는 개념이 많아서 이해하는 데 어려웠습니다. 그래서 이해가 부족한 부분에 있어 확인받고자 질문드립니다.
1. 일정한 거리감을 나타내는 depth interval bin에 대한 설명에서
이게 일반적으로 히스토그램에서 말하는 제가 아는 bin의 개념과 똑같은 것인가요?
그렇다면 어떤 빈들의 조합으로 깊이를 추정할 것인지라는 뜻은, 결국에 수식 1에서 설명하시는 것처럼 특정 depth interval을 뜻하는 서로 다른 bin과 그것들에 대응되는 확률 분포p에 의해 가중합 방식이 된다는 뜻인 건가요?
그리고 이 LocalBins 방식이 결국엔 regression개념과 classification 개념을 모두 사용한 것으로 이해해도 될까요?
2. 수식 1에서 변수 k가 의미하는게 디코더 레이어의 개수라면 pi(k)는 k번째 디코더 특징들의 확률분포, ci(k)는 bin center들 인 것으로 이해했는데, 그렇다면 i변수는 무엇인가요?
3. routing to metric heads에서
첫번째 방식은 학습과 추론 단계에서 상황에 대한 단순 라벨 입력으로,
두번째 방식은 지도학습 같이, 상황에 대해 학습의 느낌으로 이해했습니다.
그런데 저 또한 역시 세번째 방식의 언급이 잘 이해가 되지 않았습니다!
학습 가능한 분류기가 존재하지만, 학습 시에 환경에 대한 레이블이 없으면,
해당 방식이 비지도 학습인 가능성도 있을 수 있는 것인가요?