안녕하세요, 스물아홉 번째 X-Review입니다. 이번 논문은 2019년도 arXiv에 올라온 Objects as Points입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
2019년 당시 object detection은 각 object를 표현할 때 축으로 정렬된(axis-aligned) bounding box를 사용하였습니다. 그 다음, 분류를 통해 많은 수의 검출된 object bbox들을 줄이게 되죠. 각 bbox에 대해서 분류기가 특정 객체인지 혹은 배경인지 결정하게 됩니다. 이 때 같은 instance에 대해 bbox IoU를 계산함으로써 중복된 detection을 제거하는 후처리 과정인 nms가 필요합니다. 하지만 이 nms는 미분하기 어려우며, 당연히 그럼 학습하기에도 어렵겠죠.
이전까지 많은 좋은 방법론들이 나왔지만, 특히 sliding window 기반의 객체 검출기는 꽤 비효율적인데, 당연하게도 많은 수의 anchor가 필요하기 때문입니다. 그래서 본 논문에서는 훨씬 간단하고 더 효율적인 검출기를 제안하고자 합니다.
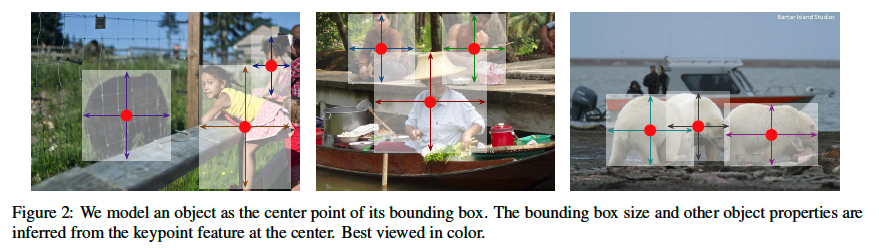
바로 위 그림과 같이 object를 bbox의 센터 한 점으로 나타내는 방식을 제안하였습니다. 객체의 크기나, 차원, 3D extent, orientation이나 pose같은 것들은 (od뿐만 아니라 3d detection, pose estimation 가능) 영상 feature의 center 위치에서 바로 regression 하도록 하였습니다. 이렇게 한다면 object detection은 일반적인 keypoint estimation 문제로 해결한다고 볼 수 있습니다. (center point가 어딘지 추정하는 문제이므로) 무튼, 저자들은 입력 영상을 fully convolutional network에 태워서 heatmap을 생성해내도록 하였습니다. 그 다음 이 heatmap의 peak 점을 object의 center 점으로 보았으며, 각 peak마다 feature에서 bbox의 heigh, width를 예측하도록 하였습니다. 이렇게 설계함으로써 모델은 nms 후처리 없이 추론 할 수 있게 됩니다.
본 방법론은 object detection 외의 다른 task로 확장이 가능한데, 논문에서는 3D object detection과 multi-person human pose estimation으로 확장한 실험을 보였습니다. 간단하게 언급하자면, 3D bbox를 추정하기 위해서 depth와 3d bbox dimension그리고 객체의 orientation을 regression하도록 하였습니다.
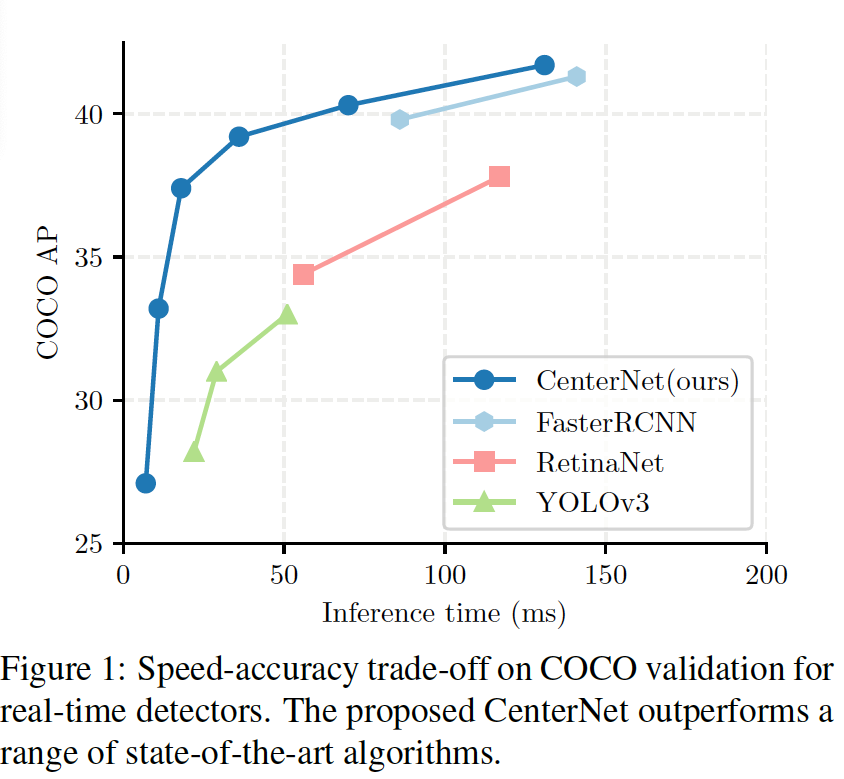
간단히 본 방법론 성능을 살펴보자면, 위 그림에서 파란색 라인이 CenterNet에 해당합니다. 보시면 inference time이 가장 빠른것을 확인할 수 있습니다.
2. Related work
Object detection with implicit anchors.
Faster RCNN은 region proposal과정이 있는데, anchor라고 하는 고정된 크기의 bbox들을 선별한 다음 배경인지 전경인지 분류하는 과정을 거치게 됩니다. anchor들은 gt object와 IoU를 계산했을 때 0.7 초과인 경우 전경으로 판단되고, 0.3 미만인 경우 배경으로 라벨링됩니다. 이런 배경인지 전경인지 분류하던 분류기를 multi-class classification 형식으로 바꾼 것이 1 stage detector들입니다. 본 방법론 같은 경우 이런 yolo나 ssd와 같은 anchor 기반의 1 stage detector들과 굉장히 가깝습니다.
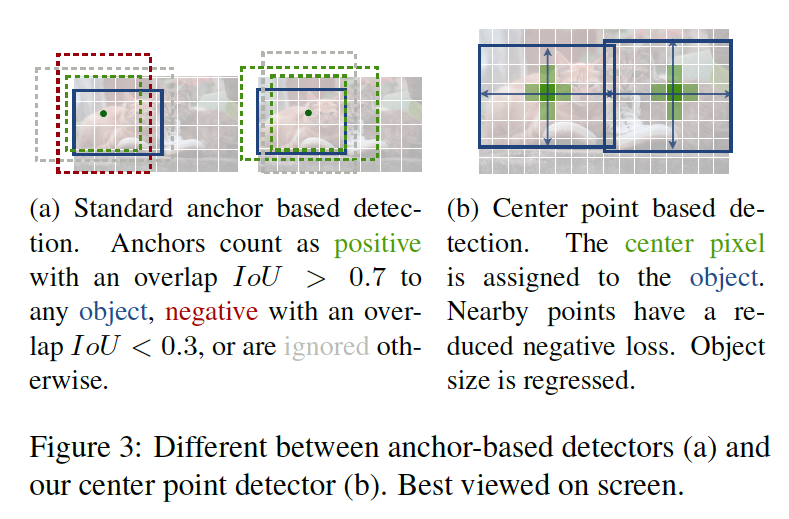
위 그림을 보시면 기존 anchor 기반의 detector들과(a), 본 방법론(b)의 차이를 보실 수 있습니다. center point는 shape-agnostic한 anchor로 볼 수 있겠으나, 기존 detector들과 몇가지 중요한 차이점이 존재합니다. 먼저, 본 CenterNet은 box overlab을 기준으로 삼는게 아니라 오직 위치만을 기반으로 anchor를 할당하게 됩니다. 즉, 전경 배경을 분류하는데 threshold를 사용하지 않습니다.두 번째로 object 당 오직 한 개의 positive anchor가 나오기 때문에 nms 과정이 필요하지 않습니다. 단순히 keypoint heamap에서 peak를 object의 center로 보기 때문입니다. 마지막으로, CenterNet은 기존 방법론보다 큰 output 해상도를 갖습니다. 기존 전통적인 od 방법론은 output stride가 16인 것에 비해 centernet은 4라고 합니다. 여기서 output stride는 input 영상 대비 output 영상의 해상도의 비율입니다.
Object detection by keypoint estimation
본 방법론이 object detection에서 keypoint estimation을 사용한 첫번째 방법론은 아닙니다. CornetNet이 시초인데, 이 CornerNet은 2개의 bbox 코너를 keypoint로 검출하게 되며, 이후 등장한 ExtremeNet은 각 object에 대해 top, left, bottom, right 점과 center point를 검출하게 됩니다. 이 두 방법론도 본 CenterNet과 마찬가지로 keypoint estimation network를 기반으로 하는 방법론이지만, 이 둘은 combinatorial grouping이라고 하는 작업이 필요했습니다. 이 combinatorial grouping이란, bbox의 두 corner점을 검출하는 CornerNet을 예시로 들자면, 영상 속에 여러 객체가 존재할 때 이 객체 수 만큼의 좌상단 우하단 코너점들이 검출되게 되는데, 이 코너점들 중 같은 bbox의 코너쌍끼리 매칭해주는 과정을 의미합니다. 하지만, CenterNet같은 경우 object 당 한 개의 center point만 추출되니 이런 후처리 과정도 필요하지 않습니다.
3. Preliminary
너비 W, 높이 H를 갖는 입력 영상을 I ∈ R^{W \times H \times 3}라고 할 때, 목표는 keypoint heatmap \hat{Y} ∈ [0, 1]^{W/R \times H/W \times C}을 생성하는 것입니다. 여기서 R은 output stride(입력 영상 해상도와 출력 영상 해상도 비율)로 4로 설정하였으며, C는 keypoint type의 수로 쉽게 말해 coco 데이터셋에서 object detection을 한다고 하면 C=80이 되며, human pose estimation에서는 human joint 개수로 C=17이 됩니다. \hat{Y}_{x,y,c}=1로 예측을 하게 됐다면 이는 c class에 대해서 x, y위치에 keypoint를 검출했다는 의미가 됩니다. 그럼 \hat{Y}_{x,y,c}=0인 것들은 배경을 의미하게 되겠죠.
본 논문에서는 몇 fully-convolutional 인코더-디코더 네트워크를 사용하여 \hat{Y}를 예측하도록 하였습니다. FCN으로는 stacked hourglass 네트워크, ResNet, DLA(Deep layer aggregation)을 사용하였다고 합니다.
이 keypoint prediction 네트워크를 학습하는 방법은 CornerNet 논문의 방식을 그대로 따랐다고 합니다. 각 class에 대한 gt keypoint p ∈ R^2가 있을 때 먼저, 저해상도의 gt를 계산해 냅니다. (\tilde{p} = [p/R]) 이건 네트워크의 output이 input image/R 크기이기 때문에 gt도 R로 나눈 만큼의 크기로 맞춰주는 것입니다. heatmap은 centerpoint 유무를 식별하는 용도로 사용되는 0과 1로 center 위치만을 표시한 binary mask라고 생각하시면 됩ㄴㅣ다.
무튼 downsampling한 이후 가우시안 커널을 씌우는데, 이는 gt에 blur를 적용하여 prediction에 대한 허용 오차를 갖도록 하기 위함입니다. 즉 다시 말해 gt를 blur하게 하여 어느 정도 gt에 근접한 centerpoint들은 맞게 예측했다고 가정하여 loss를 계산하겠다는 의미힙낟. 이 keypoint 예측에 대한 loss로는 아래 식 1의 focal loss를 사용하였습니다.
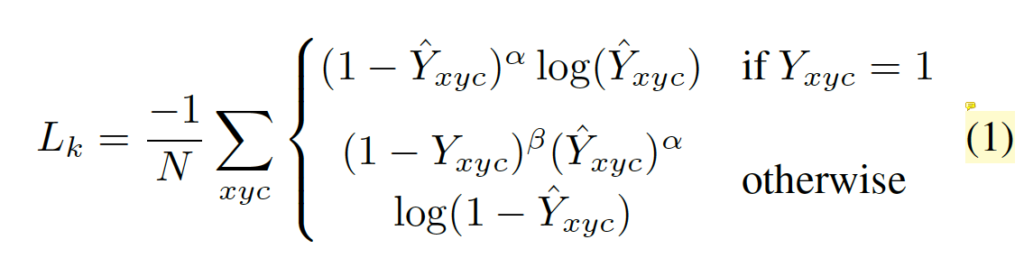
- α, β : focal loss의 하이퍼파라미터 (각각 2, 4로 설정)
- N : 이미지 I 내의 keypoint 개수
Center point를 예측한 후 이 예측한 center point를 입력 영상 해상도에 맞춰 매핑해주어야 하는데, 이 때 정확성이 떨어질 수 있기 때문에 추가적으로 local offset \hat{O} ∈ R^{W/R \times H/W \times C}을 예측하도록 하였습니다. x축에 대한 offset, y축에 대한 offset 2개가 나오게 되는 것이겠죠. 이 offset에 대한 loss function으로는 L1 loss를 사용하였습니다.
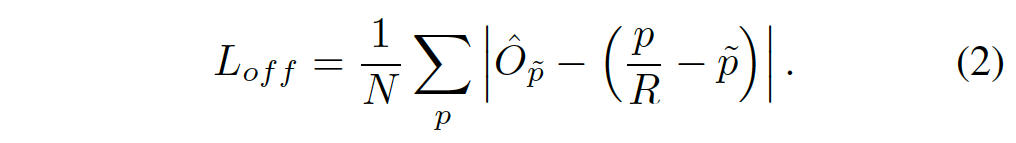
4. Objects as Points
category c에서 k번째 object의 bbox를 (x_1^{(k)}, y_1^{(k)}, x_2^{(k)}, y_2^{(k)})라고 할 때 이 bbox의 센터 점은 ((x1 + x2)/2, (y1+y2)/2)로 나타낼 수 있겠죠. 저자는 keypoint, offset을 예측하는 것에 추가로 object의 size도 regression하도록 하였습니다. size prediction \hat{S}∈ R^{W/R \times H/R \times 2}은 아래 식3과 같은 L1 loss로 학습하도록 하였습니다.
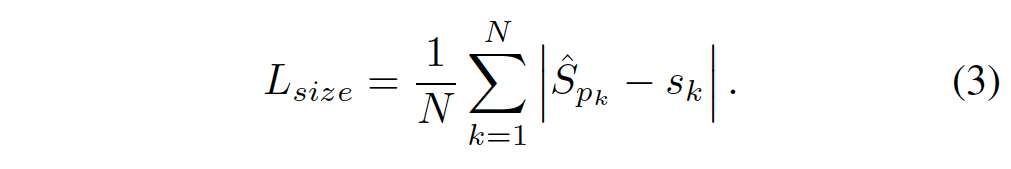
최종 loss는 아래와 같습니다.
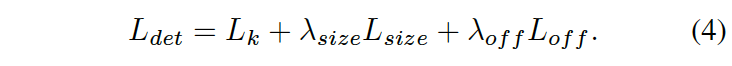
정리하자면 CenterNet은 keypoint \hat{Y}, offset \hat{O}, size \hat{S}를 예측하게 됩니다. 그렇다면 prediction은 총 C+4의 output이 나오게 되겠죠. (keypoint C + offset 2 + size 2)
모든 output들은 동일한 fully convolutional 백본 네트워크를 공유하게 됩니다. 각 모달리티에 대해 백본에서 추출된 feature에다가 3×3 conv, 1×1 conv를 태우게 됩니다.
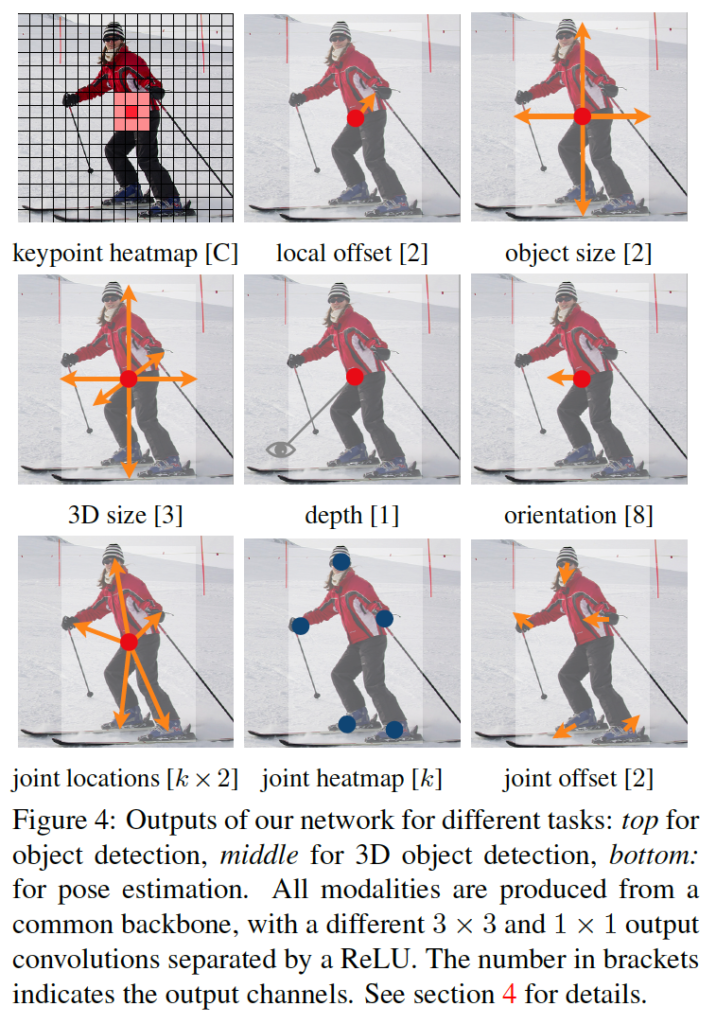
위 그림이 본 centernet의 output을 보여줍니다. 맨 위 행이 object detection에 대한 output이며, 가운데 행이 3d object detection에 대한 output, 마지막 행이 pose estimation에 대한 output입니다.
From points to bounding boxes
추론 시에는, 먼저 각 category에 대한 heatmap들의 peak들을 추출합니다.
우선, heapmap에서 주위 8개 pixel보다 값이 크거나 같은 값들을 모두 저장을 해두고 저장해둔 값들 중 값이 큰 100개의 peak들을 남겨둡니다. 각 keypoint 위치는 정수 좌표 (x, y)로 주어지기 때문에 최종 bbox location은 아래와 같이 나타낼 수 있겠습니다.
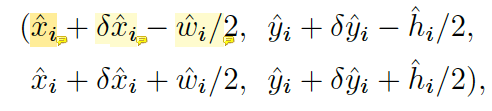
- \hat{x}_i : 예측된 center점 x좌표
- δ\hat{x}_i : 예측된 x축 offset 값
- \hat{w}_i : 예측된 x축 size
모든 output들은 keypoint estimation으로부터 바로 추출되기 때문에, IoU 기반의 NMS과정이 없으며 다른 어떠한 후처리 과정이 존재하지 않습니다.
5. Experminets
Object detection 성능은 MS COCO 데이터셋에서 수행되었으며, 평가지표는 IoU threshold가 0.5일때와 0.75 그리고 all일 때인 AP_{50}, AP_{75}, AP 입니다.
5.1. Object detection
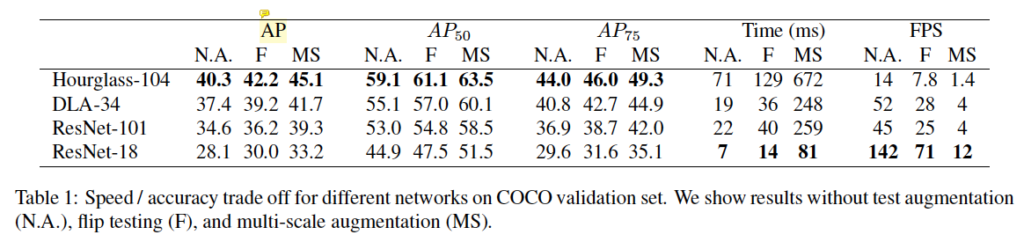
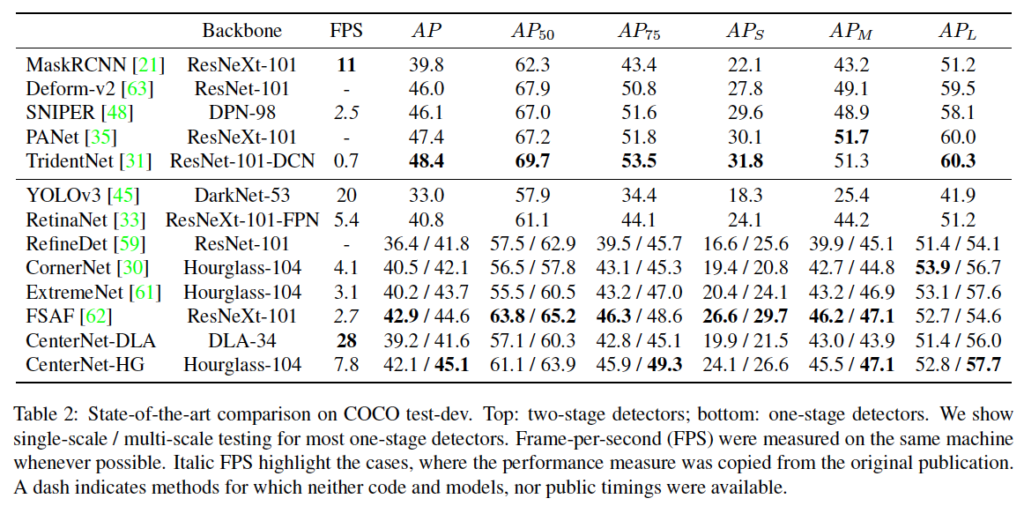
먼저 object detection에 대한 성능 결과입니다. 실험은 hourglass network, dla, resnet101, 18 네 백본에 대해 수행되었습니다. 표 1을 보시면 hourglass 104의 경우 42.2%의 AP로 네 백본 중 가장 높은 정확도를 달성하였습니다. 표2에 나와있듯이 이는 CornerNet과 ExtremeNet보다 속도도 빠르고 정확도 측면에서도 더 우수한 성능을 보입니다. 저자는 이에 대해 CornerNet과 ExtremeNet에 비해 output head 수가 더 적으며, 더 단순한 box decoding 방식(combinatorial grouping X)으로 인한 것과 동시에 center point가 corner점이나 extreme point (극점)보다 더 쉽게 검출되기 때문이라고 언급하고 있습니다.
이외에 ResNet18을 사용한 경우 COCO에서 28.1%의 AP 성능을 보이며 FPS는 142이며, DLA34를 사용한 경우 속도와 정확도 trade-off를 최적으로 고려한 네트워크라고 할 수 있겠습니다. 표 2를 보시면 최종적으로 hourglass-104를 사용한 CenterNet이 2019년 당시의 기존 1 stage object의 성능을 전부 능가하고 있습니다.
5.2. Additional Experiments

다음은 추가적인 실험에 대한 부분입니다. 운이 안좋은 경우 두 서로 다른 객체가 동일한 center를 가질 수 있겠죠. 이런 상황에서 CenterNet은 그 중 하나만 검출하게 될 것이구요. 저자들은 실제로 이런 상황이 얼마나 자주 발생하는지에 관한 실험을 진행하였습니다.
Center point collision
COCO train dataset에서는 output stride를 4로 하였을 때 동일한 center점을 갖는 충동하는 객체 쌍이 614개가 있다고 합니다. COCO train dataset의 총 object 수는 860,001개이기 때문에 비율로 따져보면 0.1%에 해당하는 셈이죠. 저자들은 이에 대해 Fast RCNN의 불완전한 region proposals과정에서 누락된 검출이 약 2%인에, 이보다 훨씬 적다고 하여 크게 문제될 만한 부분은 아니라고 합니다.
NMS
CenterNet에서는 IoU 기반의 NMS가 필요하지 않은지 확인하기 위해 실제로 NMS 후처리를 했을 경우와 하지 않았을 경우에 대한 실험을 진행하였습니다. NMS를 적용한 경우 DLA34백본을 사용하였을 경우 AP가 39.2%에서 39.7%로 0.5% 향상하였고, Hourglass104 백본을 사용한 경우 AP가 42.2%로 동일했다고 합니다. 그래서 최종적으로 성능이 미미한 향상이거나 동일한 점으로 보아 NMS를 사용하지 않았다고 하네요.
Training and Testing resolution
다음으로 학습 및 평가에서 입력 영상의 resolution에 대한 실험입니다. 학습 도중에는 입력 영상 해상도를 512 x 512로 고정하였지만, 평가할 때는 CornerNet의 방식을 따라 원본 영상 해상도로 진행하였다고 합니다. 표 3-(a)를 보면 Original로 test하는 것이 약간의 성능 향상을 보였기에 이를 따랏다고 합니다.
Regression loss & Bounding box size weight
이어서 L1 loss와 smooth l1 loss에 대한 실험도 진행한 결과 표 3-(c)와 같이 L1이 더 높았다고 하며, 표 3-(b)에 bbox size loss에 대한 weight를 0.2, 0.1, 0.02에 대해 실험한 결과 0.1이 가장 좋은 성능을 보였다고 합니다.

마지막으로 정성적 결과입니다. 맨 위 행이 object detection에 대한 결과이며, 2, 3번째 행이 pose estimation, 4, 5번째 행이 3D object detection에 대한 결과입니다.
안녕하세요. 좋은 리뷰 감사합니다.
gt keypoint map을 생성할 때 가우시안 커널을 씌워서 prediction에 대한 허용 오차를 갖도록 한다고 하셨는데, 먼저 이런 과정이 왜 필요한지 궁금합니다.
또 가우시안 커널을 적용하였을 때 블러되는 영역, 즉 허용 오차 범위기 어느정도 인지 알 수 있을까요 ? 이 허용 오차 범위에 따라 성능이 달라질 것 같은데 이에 대한 ablation study는 없었는지 궁금합니다.
감사합니다.
안녕하세요 윤서님, 좋은 리뷰 감사합니다.
입력영상을 fully convolutional network에 태워서 heatmap을 생성하고 그 다음 이 heatmap의 peak 점을 object의 center로 간주했다고 하셨는데,
heatmap의 peak가 bbox의 center point로 대표되는 이유는 무엇인가요?
리뷰 잘 읽었습니다.
읽다보니 궁금한 점이 있는데요,,
Related Work 에서 >>>>’두 번째로 object 당 오직 한 개의 positive anchor가 나오기 때문에 nms 과정이 필요하지 않습니다’ <<<< 라고 언급하신 부분에서 궁금한 점이 있습니다. 학습 때는 gt bounding box 정보가 있기 때문에 이 bounding box를 기준으로 해서 내부 point 중 가장 peak가 되는 부분을 keypoint로 예측해서 오직 하나의 poistive anchor가 나온다고 이해하면 되는건가요?? 그렇다면 평가 단계에서는 gt정보가 없을텐데,,, 이때는 무엇을 기준으로 peak를 계산하게 되는지 궁금합니다. (제가 이해를 잘못해서 엉뚱한 질문을 하는걸수도 있습니다) 감사합니다.
윤서님 안녕하세요!
좋은 리뷰 감사합니다!
detection을 공부하면서, 당연시 생각하던 nms, predefined anchor등을 생략한 방법론이 굉장히 신기했습니다.
먼저 해당 방법론은 초기에 heatmap을 얼마나 잘 뽑느냐에 따라 성능차이가 발생할 것 같다고 생각합니다.
저자가 해당 부분에 대한 언급은 없었는지 궁금합니다.
또한 해당 논문 자체가 기존과 다른 방식으로의 localization을 하는 것에 중점되어있다는 것은 잘 알고 있습니다.
그렇다면, classification에 대한 접근은 기존의 one-stage detector들과 동일한 지 궁금합니다.
감사합니다!