제가 이번에 리뷰할 논문은 dehazing논문입니다. 에어로졸로 인해 영상 품질이 저하된 상황에서 6D Pose Estimation을 수행하기 위한 연구를 고려하고 있는 상황에서 균일하지 않은 fog 상황에 대한 dehazing 연구를 발견하여 리뷰하게 되었습니다.
Abstract
non-homogeneous한 haze는 불균일한 분포의 안개상황으로, 기존의 homogeneous dehazing 방식을 적용하는 데에 한계가 있었습니다. non-homogeneous dehazing의 가장 중요한 문제는 효과적으로 불균일한 분포의 feature를 추출하고 안개로 가려진 영역의 디테일한 정보를 복원하는 것입니다. 본 논문에서는 새로운 self-paced semi-curricular attention network(SCANet)를 제안하여 안개로 가려진 영역에 집중하여 non-homogeneous한 이미지의 dehazing 연구를 수행하였습니다. 저자들이 제안한 방식은 attention generator 네트워크와 scene reconstruction 네트워크로 구성되며 luminance 차이를 통해 attention map을 제한하고 학습 초기 단계에서 학습 모호성을 줄이고자 self-paced semi-curricular learning 방식을 제안하였습니다. 다양한 실험을 통해 SOTA보다 강인하게 작동함을 보였다고 합니다.

Introduction
기존의 많은 dehazing 연구들은 균일한 분포(homogeneousg)의 안개로 가정하고 안개로 인해 영상의 품질 저하를 아래의 식(1)과 같이 물리적 사전 지식을 통하여 모델링하였습니다.
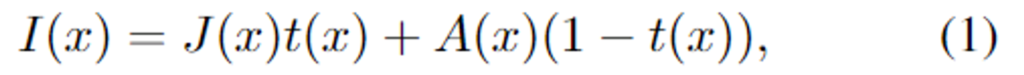
(↳ x: 픽셀 index, I: haze 이미지, J: clear image, t: transmission, A: global atmospheric light)
식(1)로부터 t와 A를 추정하는 것이 dehazing에서 중요하였으며, 복잡한 hazy scene에서는 t와 A의 추정이 부정확하여 성능 저하가 발생할 수 있습니다. dehazing 성능을 높이고자 다양한 딥러닝 기반의 연구가 진행되었으나, 실제 환경에서 안개는 가변적이며 균일하지 않을 수 있으므로 homogeneous한 dehazing이 잘 작동하지 않습니다.
따라서 최근 non-homogeneous한 상황에 대한 dehazing연구가 진행되었으나 안개와 영상 사이의 복잡한 상호작용을 모델링하는 것은 여전히 어려운 문제라고 합니다. 저자들은 안개 분포를 인식하고 안개가 짙은 영역에 대한 texture 정보를 복원하는 것이 핵심 과제로 보고 새로운 self-paced semi-curricular attention network(SCANet)을 제안하였습니다. luminance변화가 큰 영역의 잘 복원하기 위해 학습 방식(self-paced semi-curricular learning, 쉬운 것부터 어려운 것까지 네트워크를 점차 학습시키는 방법이라합니다)을 설계하였으며, 실험을 통해 PSNR이 SOTA 방법론들과 비교하여 경쟁력 있는 성능을 보여줌을 입증하였다고 합니다.
본 논문의 cotribution을 정리하면
- non-homogeneous한 이미지의 dehazing을 위해 비균일한 안개와 영상 사이의 복잡한 상호작용을 학습하는 네트워크를 제안하였으며, 네트워크는 attention generation과 scene reconstruction으로 구성됨.
- luminance 변화가 큰 영역에서 dehazing 능력을 높이기 위해 self-paced semi-curricular learning 기반의 학습 방식을 제안하여 모델의 성능을 향상시키고 학습의 모호성을 줄임.
- 실험을 통해 제안된 SCANet이 SOTA 방법론 대비 우수한 성능을 보이는 것을 확인하였으며, ablation study를 통해 각 요소의 효과를 입증함.
Method
1. Network Architecture
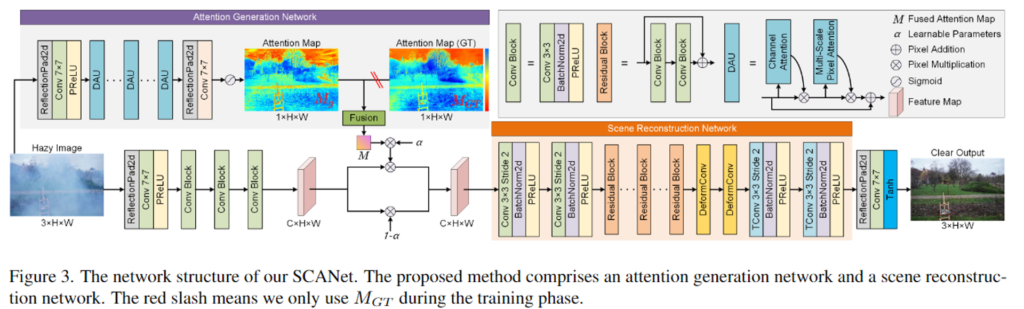
위의 [Figure 3]에서 확인할 수 있듯 SCANet은 attention generation network(AGN)와 scene reconstruction network(SRN)이라는 2개의 네트워크로 구성됩니다. AGN은 attention feature map을 생성하고 SRN은 haze가 없는 영상을 만들기 위해 encdoer-decoder 구조로 이루어집니다.
Attention Generator Network(AGN)
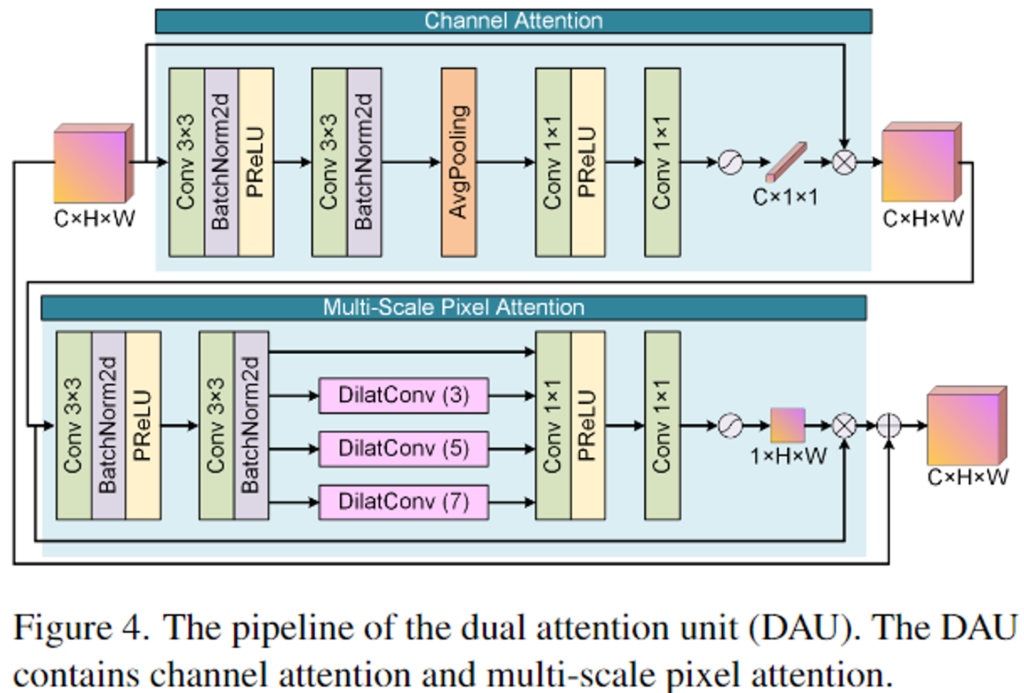
AGN는 attention feature map을 생성하기 위해 고안된 네트워크로 여러 dual-attention units(DAUs)로 구성됩니다. DAU는 위의 [Figure 4]를 통해 구조를 확인하실 수 있으며, 입력된 feature map이 순차적으로 Channel Attention(CA)과 multi-scale pixel attention(MSAP)을 통과하여 output feature를 얻습니다. CA로 구한 feature의 각 채널에 대한 가중치는 input feature와 곱해져 MSPA로 들어갑니다. MSPA에서는 안개의 공간적 분포에 대한 인지 능력을 높이기 위해, dilated convolution을 사용하여 다양한 receptive field의 feature를 얻게됩니다. MASP로 구한 feature와 input feature를 더해 attention map M_g을 구합니다.
Scene Reconstruction Network(SRN)
SRN은 haze가 없는 영상을 복원하는 네트워크로, encoder-decoder 구조를 사용합니다. 자세한 구조는 [Figure 3]을 통해 확인할 수 있으며, downsapled feature를 추출하기 위해 다중 conv layer를 통과하고 여러 residual block과 offset을 이용하여 관심 영역에 집중할 수 있도록 커널의 모양을 조정할 수 있는 2개의 deformable conv layers를 이용하여 low-resolution의 feature representation을 학습합니다. 이후 2개의 transposed conv layers를 이용하여 원본 해상도로 복원한 뒤 reflection padding-7×7 conv-tanh 함수를 거쳐 haze가 없는 영상을 복원합니다.
2. Self-Paced Semi-Curricular Attention
먼저 저자들은 attention 메커니즘으로 학습해야하는 이유에 대하여 설명합니다. non-homogeneous한 haze는 haze가 심한 부분에 집중해야하므로 attention 메커니즘을 통해 네트워크가 haze features에 집중할 수 있도록 해야한다고 주장합니다. 그러나 attention map은 비지도학습 방식으로 구해지므로 중요도가 높은 영역에 집중하지 못하는 경우가 발생할 수 있습니다.

위의 [Figure 5]의 (b)와 (e)는 AGN으로 구한 attention map과 SRN으로 생성한 haze free 영상입니다. haze가 하늘 영역에만 집중되어있다는 것(attention 높을수록 밝음)을 확인할 수 있으며, 그 결과 생성된 영상에 아티팩트가 발생한다는 것을 파란 박스 영역을 통해 확인할 수 있습니다. 저자들은 non-homogeneous한 안개는 안개가 짙은 영역의 luminance를 크게 증가시키는 경향이 있음을 관찰하였고, 이를 바탕으로 luminance 변화가 큰 영역에 집중하여 reconsturction을 수행할 경우 성능이 향상될 수 있다고 주장합니다. 따라서 이미지를 YCbCr color space로 변환하고 Y 채널 기반의 luminance 편차를 GT attention map M_{GT}으로 이용합니다.
Self-Paced Semi-Curicular Learning
다음은 저자들이 제안한 학습 전략에 대한 설명입니다. 서로 다른 목적을 가진 AGN과 SRN을 학습하는 것은 학습 모호성을 증가시키는 경향이 있다는 것을 언급하며, 모델이 더 잘 수렴할 수 있도록 self-paced semi-curricular learning[1]을 채택하여 쉬운 것부터 학습하여 점차 어려운 것을 학습하도록 하는 학습 전략을 제안하였다고 합니다. 학습 과정에는 AGN으로 생성한 attention map M_g과 GT M_{GT}이 합쳐져 최종 attention map M을 구하며, 이는 아래의 식(2)로 표현 가능합니다.
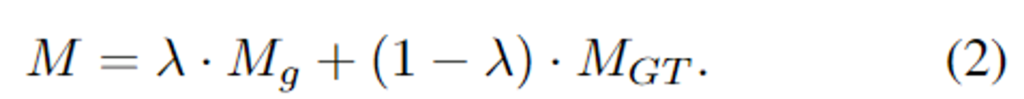
이때, \lambda는 두 attention map의 가중치로 L1 loss \mathcal{L}^a_{sl1}를 이용하여 동적으로 조정되도록 설정하였습니다.
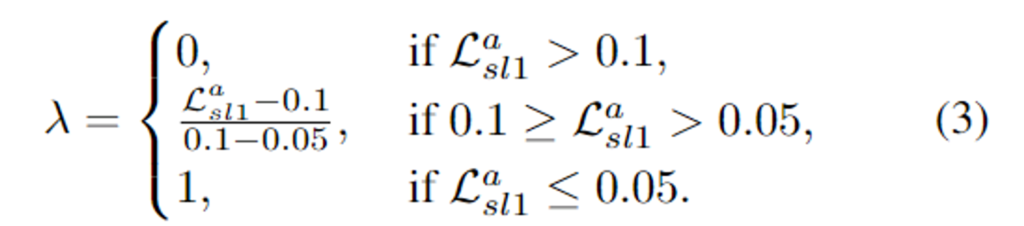
위의 식(3)은 M_{g}와 M_{GT}의 비중을 조절하는 데 사용되며, \mathcal{L}^a_{sl1}가 큰 학습 초기에는 학습 모호성을 낮추기 위해 주로 M_{GT}에 높은 비중을 주고, 학습이 진행됨에 따라 \mathcal{L}^a_{sl1}가 감소할 경우 생성된 attention map M_g의 비율이 점차 증가하다 \mathcal{L}^a_{sl1}가 0.05보다 작을 경우는 M_g만으로 이루어진 attention map을 이용하도록 하였다고 합니다. 이때 과도하게 M_{GT}에 의존하지 않도록 하기 위해 전체 epoch 중 초반 25%에만 semi-curricular learning을 적용하였다고 합니다.
attention map M을 구한 뒤, 학습 가능한 파라미터 \alpha를 통해 attention map에 적응적으로 가중치를 주어 output feature를 구합니다.
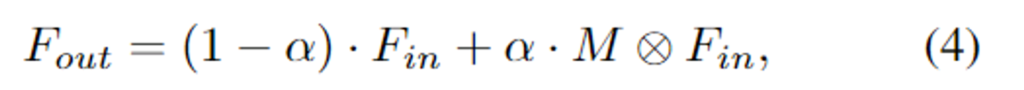
- F_{in} / F_{out}: input feature map/ output feature map
- ⊗: pixel-wise 곱 연산
3. Loss function
SCANet의 결합 loss \mathcal{L}_{joint}는 아래의 식(5)로 구성되며 이때 \gamma는 각 loss의 가중치로 각각 1, 0.3, 0.01, 0.5, 0.0005로 설정하였다고 합니다.
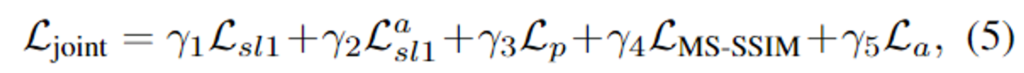
- Smooth L1 loss
- 기존 연구[2]를 통해 image reconstruction에는 L2보다 L1이 더 효과가 있음이 입증되었다고 합니다. 따라서 최종 결과물 \hat{J}와 attention map M_g를 학습하기 위해 L1 loss를 사용하였으며 각각은 아래의 식으로 정의됩니다.
- 이때, \mathcal{L}_{sl1}은 haze가 없는 이미지와 생성한 영상에 대한 loss이며, \mathcal{L}_{sl1}^a은 attention map에 대한 loss 입니다.
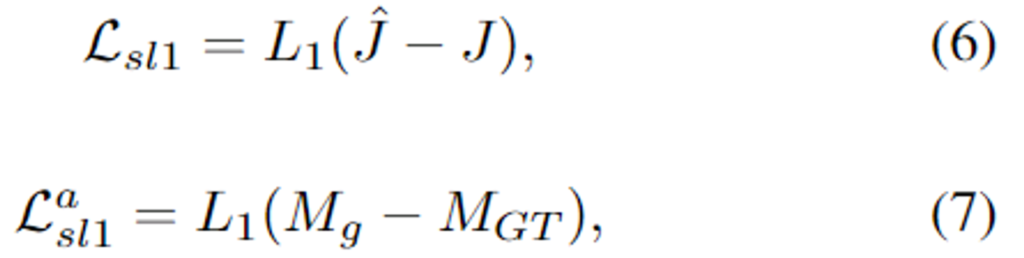
- Perceptual Loss
- 생성한 영상과 GT 영상이 비슷할수록 특정 레이어의 feature가 유사할 것이라는 아이디어로부터 사용하는 loss로 feature space의 출력과 GT사이의 유사성을 고려하기 위한 것입니다.
- 이때, \phi^v_{k}(.)는 VGG16의 k번째 layer의 feature를 의미합니다.
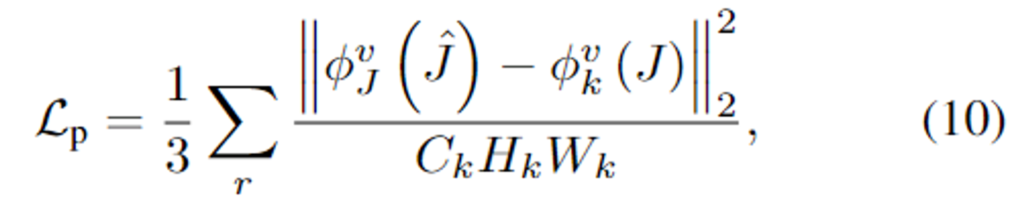
- MS-SSIM Loss
- 고주파수 영역의 대비를 향상시키기 위해 사용하는 loss로 다음과 같이 정의됩니다.
- 이때, L_{MS-SSIM}는 multi-scale 구조 유사성으로 SSIM 값을 이용합니다.
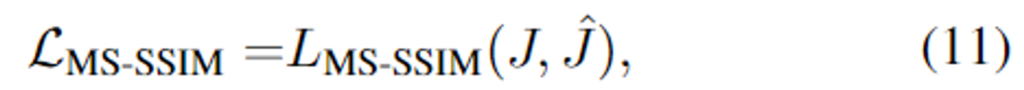
- Adversarial Loss
- 네트워크의 일반화 성능을 높이기 위해 adversarial loss를 추가하였다고 합니다.
- D(.)는 discriminator, S는 학습 데이터 수를 나타냅니다.
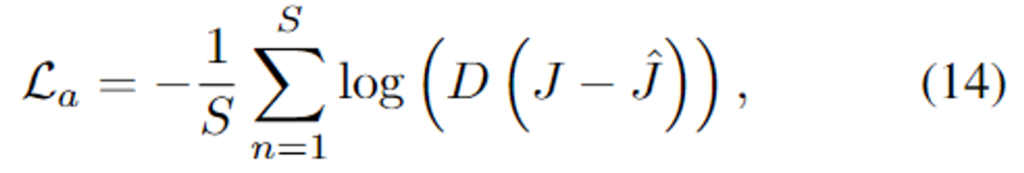
Experiments
Dataset & Evaluation Metrics
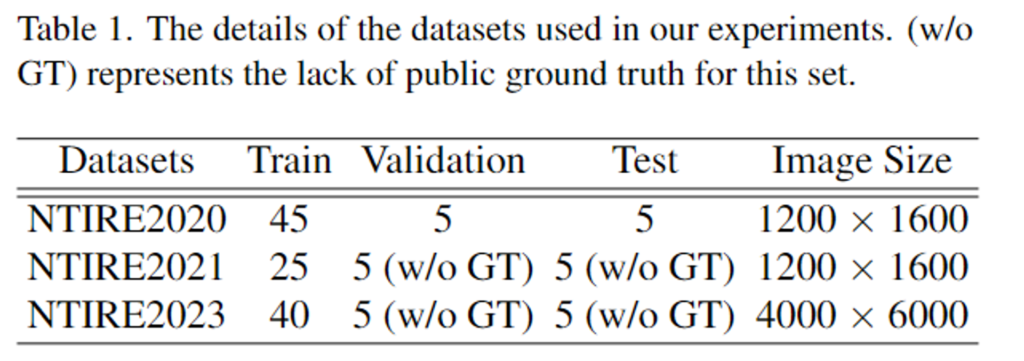
챌린지인 NTIRE2020, NTIRE2021, NTIRE2023의 데이터 셋을 SCANet의 학습과 평가에 이용하였다고 합니다. 3개의 데이터 셋 모두 non-homogeneous한 분포로 이루어지며 NTIRE2020은 학습/검증/평가 데이터가 각각 45/5/5쌍의 이미지로 구성되어있으며(NH-Haze), NTIRE2021은 25/5/5쌍(NH-Haze2), NTIRE2023은 40/5/5쌍으로 이루어져있습니다. 평가지표로는 PSNR과 SSIM을 이용합니다.
Comparisons with SOTA
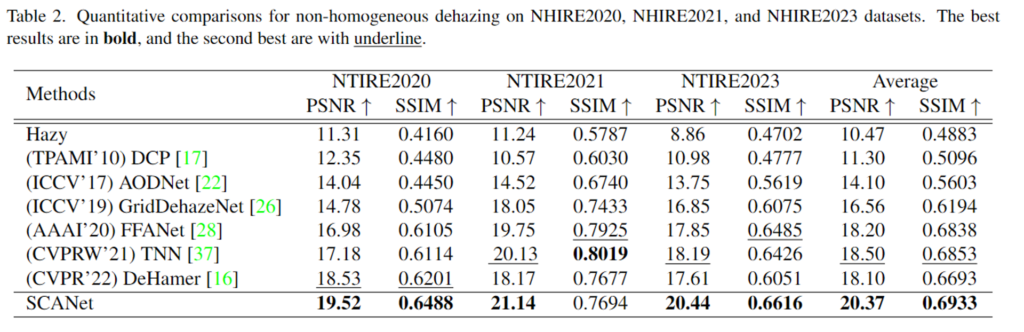
위의 Table 2가 SOTA 방법론들에 대한 성능을 리포팅한 것으로, 사전지식을 기반으로 하는 DCP는 non-homogeneous에서 성능이 안 좋은 것을 확인할 수 있으며, 학습기반의 방법론들은 dehazing이 더 잘 작동하는 것을 확인할 수 있으며, SCANet이 대부분의 항목에서 가장 좋은 성능임을 보였습니다.

위의 [Figure 6]은 정성적 결과로, DCP로 생성된 결과는 색상이 왜곡되는 문제가 있으며, 기타 학습기반 방법론들도 안개를 완전히 제거하지 못하는 것을 확인할 수 있습니다.
Compexity Analysis
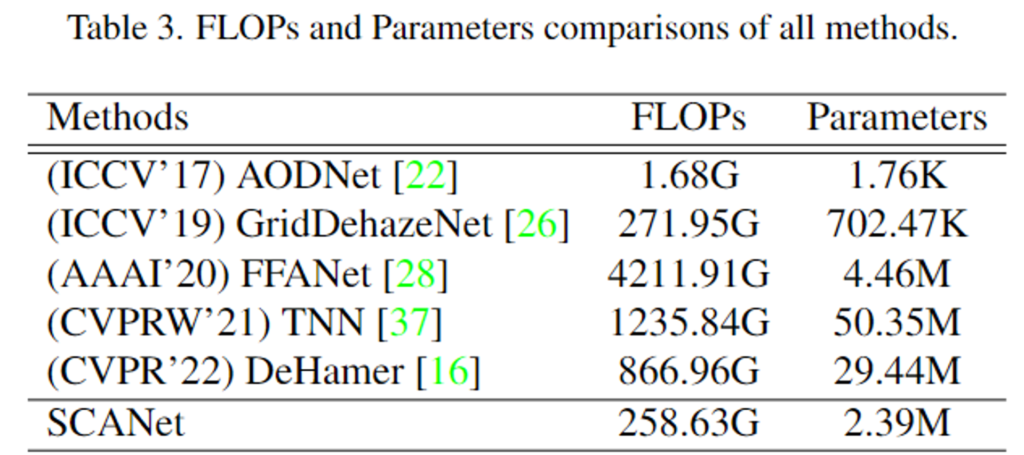
위의 Table 3은 1200×1600 해상도의 이미지에 대한 파라미터 수와 FLOPs를 비교한 것으로, SCANet이 FLOPs도 낮고 매개변수도 적다는 것을 확인할 수 있습니다.
Ablation Analysis
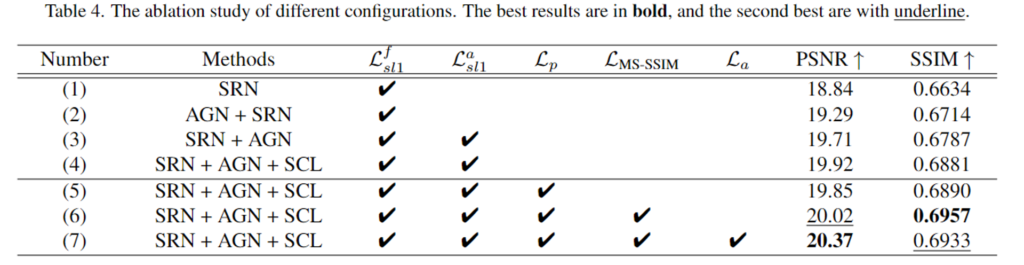
위의 Table 4는 AGN과 SRN, self-paced semi-curicular learning방식(SCL)과 각 loss에 대한 ablation study 결과입니다.
(1)과 (2)를 통해 SRN 앞에 AGN을 추가할 경우 성능 개선이 가능함을 확인하였으며, 이를 통해 non-homogeneous dehazing을 위해서는 안개가 짙은 영역에 집중해야 함을 보입니다. (2)와 (3) 비교를 통해 \mathcal{L}^a_{sl1}을 통해 attention map을 지도학습할 경우 PSNR과 SSIM 모두 개선이 이루어짐을 보였습니다. 또한 (3)과 (4)를 통해 학습 과정에 SCL을 도입함으로써 네트워크의 수렴 난이도를 낮추고 성능 향상이 가능함으로 보였습니다.
<Reference>
[1] Du, Yong, et al. “DSDNet: Toward single image deraining with self-paced curricular dual stimulations.” Computer Vision and Image Understanding 230 (2023): 103657.
[2] Zhao, Hang, et al. “Loss functions for image restoration with neural networks.” IEEE Transactions on computational imaging 3.1 (2016): 47-57.
안녕하세요 ! 좋은 리뷰 감사합니다.
식(1)에서 I와 A가 모두 haze 이미지로 되어있는데 혹시 I가 haze 이미지에서 dehazing된 이미지이고 A가 본래 haze 이미지를 의미하는걸까요 ?? 그런데 그러면 아래의 A를 추정한다는 것이 무슨 의미인지 이해가 되지 않아 .. 식에서 각각이 의미하는 것을 한번만 더 설명해주시면 감사하겠습니다
다음으로 AGM의 처음 입력으로 들어가는 feature map은 입력 이미지에서 어떻게 생성되는지 궁금합니다.
감사합니다.
질문 감사합니다.
A는 global atmospheric light를 의미합니다. 해당 부분의 오타에 대해서 수정하였습니다.
haze를 거쳐 초록색의 clear한 이미지 중 일부만이 통과하고, haze를 거쳐 나머지는 주변의 노이즈한 빛으로 이해하였습니다. 따라서 clear한 이미지를 얻기 위해 A와 t를 예측하는 것 입니다.
또한 AGN의 입력되는 feature는 원본 이미지에 대하여 ReflectionPad2D-Conv7x7-PReLU를 통해 구해지는 feature map으로 해당 과정을 거친 뒤, Figure 4에 해당하는 DAU 모듈을 통과하게 됩니다.
안녕하세요. 리뷰 잘 읽었습니다.
음, 전반적으로 이해하였는데, 본 논문의 hazing 구역에 집중하기 위한 attention 외의, 결국의 dehazing이라 함은 결국 dehazing 이미지를 복원하는 과정이 supervision으로 이루어지는가요? 맨 처음 Figure를 보니 안개로 가려진 영역을 복원한다고 되어 있는데, 그럼 데이터 자체가 hazing 상황과 Non-hazed (hazing이 존재하지 않은) 상황이 같이 존재하는 데이터로 보이는데 또한 학습 및 평가 데이터 자체가 워낙 작은 수준인데 그럼에도 해당 데이터들이 사용될 수 밖에 없는 이유도 존재하지 않을까 싶어서요..
질문 감사합니다.
해당 데이터는 동일 scene에서 haze의 유무 쌍으로 이루어집니다. 따라서 Supervision으로 학습을 진행하게 됩니다.
일단 데이터를 구축하는 과정 자체가 시간이 오래 걸리고 쉽지않다보니 다른 대용량 데이터에 비해 작은 수준이라도 사용하는 것으로 알고있습니다.(real haze를 촬영해야한다고 할 경우, 시간과 날씨에 따라 단순 haze 유무의 차이 뿐만 아니라 외부 조도의 변화 등이 발생하므로 이를 조절하기 쉽지 않기 때문입니다. 만일 haze machine을 이용한다고 하더라도 시간이 지나 조도가 변하기 때문에 데이터 셋 촬영이 쉽지 않다고 합니다.)
안녕하세요. 좋은 리뷰 감사합니다.
로스 함수에서 각각의 가중치는 1, 0.3, 0.01, 0.5, 0.000으로 설정했다고 하는데, 마지막 adverarial loss의 가중치는 0인건가요 . . . 1?!? 또 실험에서 NTIRE2020, 2021, 2023 데이터셋을 사용했다고 했는데 세 데이터셋 모두 학습 이미지가 50장이 되지 않는데 이럼에도 학습이 잘 되는 것인지 궁금합니다.
마지막으로 정성적 결과에서 DCP로 생성된 결과는 색상이 왜곡되는 문제가 있는데 왜 이런 문제가 생기는 건지 알 수 있을까요 ?!??
감사합니다.
질문 감사합니다.
가중치는 마지막에 0이 아니라 0.0005인데 제가 5를 빼먹었네요.. 해당 부분은 수정해두었습니다.
데이터 셋의 크기는 해당 데이터를 구축하는 과정 자체가 시간이 오래 걸리고 쉽지 않다 보니 적은 양의 데이터라도 사용하는 것으로 알고있습니다.(real haze를 촬영해야한다고 할 경우, 시간과 날씨에 따라 단순 haze 유무의 차이 뿐만 아니라 외부 조도의 변화 등이 발생하므로 이를 조절하기 쉽지 않기 때문입니다. 만일 haze machine을 이용한다고 하더라도 시간이 지나 조도가 변하기 때문에 데이터 셋 촬영이 쉽지 않다고 합니다.)
또한 아무래도 생성모델이다보니 왜곡이 발생하는 것으로 보입니다.
안녕하세요. 좋은 리뷰 감사합니다.
이 논문에서 주요 contribution이 self-paced semi-curricular learning인 것 같은데 처음 보는 개념이라 헷갈려 질문드립니다. self-paced semi-curricular learning이 쉬운 것부터 학습하여 점차 어려운 것을 학습하도록 하는것이라고 하셨는데 식 3번을 보면 가중치에 따라서 M_gt에 집중할 것인지 M_g에 더 집중할 것인지를 결정한다고 하였는데 이러한 과정을 self-paced semi-curricular learning이라고 말씀하시는 걸까요? 그렇다면 전체 epoch 중 초반 25%에만 semi-curricular learning을 적용 했다는 말은 나중에는 m_gt는 거의 사용하지 않았다는 의미로 받아들이면 되는 걸까요?
감사합니다.
질문 감사합니다.
loss가 줄어들수로, 람다가 커져서 결국 M_g에만 집중하도록 하는 것이고, 쉬운 GT를 이용하다가 나중에는 모호성이 포함된 어려운 attention map만을 이용한다는 점에서 self-paced seim-curricular learning이라고 이해하였습니다. 또한 이해하신것처럼 loss가 잘 안떨어질 경우 M_GT에 의존하게 되는 데 이를 줄이고자 전체 epoch 중 25에 해당하는 값은 semi-curricular learning을 적용하고 나머지는 M_g를 이용하여 학습을 수행한 것으로 이해하시면 될 것 같습니다.