안녕하세요, 스물 일곱 번째 x-review 입니다. 이번 논문은 2023년도 NeuRIPS에 게재된 Uni3DETR: Unified 3D Detection Transformer입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3D Object Detection은 이제 많은 분들이 아시다시피 포인트 클라우드 집합으로 주어지는 실제 scene에서 물체에 대한 3차원 바운딩 박스와 클래스 정보를 검출하는 task 입니다. 3D detection은 현재 크게 indoor와 outdoor 환경으로 나누어 연구가 진행되고 있는데, 그 이유는 두 환경에서 3D detection의 방향성이 다르기 때문입니다. 먼저 indoor는 보통 포인트들을 그룹화 혹은 클러스터링을 하고 각 그룹에 대한 분류가 진행되는 반면, outdoor 검출기는 일반적으로 2차원 BEV 공간으로 feature을 변환시키는 경향을 보입니다. 이렇게 3D detection을 수행하는 방식이 다른 이유는 취득할 수 있는 포인트 클라우드 데이터의 차이 때문이며 이 차이가 두 환경에서 모두 잘 동작하는 통합된 3D 검출기 모델 개발에 어려움을 주고 있습니다. 일반적으로 indoor는 다양한 카테고리의 물체가 서로 가까이 배치되어 있고 scene의 대부분을 차지하면서 보다 복잡한 구성으로 이루어져 있습니다. 반면 outdoor의 물체라고 함은 보통 자동차이며 매우 크기가 작고 포인트 클라우드 자체가 indoor 보다 훨씬 sparse하게 주어질 뿐만 아니라 전체 포인트 클라우드에서 백그라운드에 해당하는 포인트 클라우드가 대다수 입니다. 그렇다면 이런 데이터의 차이가 왜 통합된 검출기 설계에 어려움이 되는 것일까요? 먼저 detection head에서 outdoor 포인트 클라우드에 너무 많은 배경 포인트가 존재하는데, indoor 방법론에서 사용하는 그룹화와 관련된 하이퍼 파라미터가 민감하게 반응하기 때문에 그룹화 기반의 indoor 검출기는 oudoor 검출기로 사용 할 수가 없습니다. 또한 outdoor의 물체는 아까 BEV 공간에서 보았을 때 겹치지 않고 완전히 분리된 형태를 보이지만, indoor 물체는 그렇지 않습니다. 만약 수직으로 물체가 겹쳐져 있을 경우 물체 바운딩 박스의 height가 겹치게 되는데, 이를 BEV 공간으로 변환해서 검출하는 것은 적절한 방식이 될 수 없죠. 두번째로 feature extractor 관점에서, indoor 검출기는 일반적으로 PointNet, PointNet++과 같은 포인트 기반의 백본 네트워크 혹은 3D sparse 컨볼루션 기반의 백본 네트워크를 사용합니다. 포인트 기반의 모델은 일반적으로 scene 마다의 포인트 클라우드가 형성하는 다양한 구조를 파악하는데 취약하며 sparse 컨볼루션 모델은 물체의 중심 feature에 대한 representation이 부족합니다. 반면에 outdoor 검출기에서 BEV 공간의 feature을 추출하는데 사용하는 2D 컨볼루션은 indoor 검출기에 대한 큰 정보 손실을 발생시킬 수 있습니다.
그래서 본 논문에서는 트랜스포머 기반의 통합된 3D 검출기 모델인 Unified 3D DEtection Transformer (Uni3DETR) 을 제안합니다. 가장 큰 장점이라고 하면 indoor/outdoor 환경에서 모두 강인하게 물체 검출이 가능하다는 범용성을 이야기할 수 있습니다. 본 논문의 구조는 feature 추출을 위해서 3D sparse 컨볼루션과 dense한 컨볼루션을 합친 하이브리드 구조를 사용합니다. 이러한 구조는 indoor 포인트 클라우드에 대한 height가 압축되는 것을 막을 수 있다고 합니다. sparse 컨볼루션은 large-range의 outdoor 데이터에 대한 큰 메모리 소비를 줄일 수 있고, dense 컨볼루션은 sparse한 oudoor 포인트 중 center 포인트에 대한 feature가 손실되는 문제를 완화할 수 있습니다. 또한 기존 트랜스포머 기반 모델은 set-to-set 예측 방식을 통해 예측한 물체 후보와 GT를 직접 비교하기 때문에 데이터끼리의 비교가 비교적 어려운 경향이 있다고 합니다. 그래서 트랜스포머 디코더는 복셀 feature을 기반으로 구축하고, scene에서의 포인트 클라우드를 쿼리로 계산하여 포인트와 복셀 사이의 cross attention을 수행하는 구조로 변형하였습니다. 이러한 트랜스포머 구조를 기반으론 환경에 구애받지 않고 다양한 scene에서 일반성을 보일 수 있는 두 가지 구성을 추가적으로 제안하게 됩니다. 첫번째는 쿼리로 사용하는 포인트 종류인데, 기존에 사용하는 learnable한 쿼리 뿐만 아니라 복셀화된 구조 내의 포인트와 raw한 포인트를 샘플링하여 초기화된 non learnable한 쿼리로 사용하였습니다. 저자가 말하기를, learnable 쿼리 포인트는 대부분 로컬한 정보를 포함하고 있어 outdoor 물체 검출에 적절하며 non learnable 쿼리 포인트는 글로벌한 정보를 강조함으로써 비교적 dense한 indoor scene에서의 물체 검출에 더 효과적인 것을 확인하였다고 합니다. 두번째 새로운 구성은 decoupled 3D IoU 입니다. 일반적인 3D IoU와 다르게 IoU에서 xyz축을 분리하여 3차원 공간의 모든 방향을 포함할 뿐만 아니라 디코더의 최적화에 도움이 되는 position 정규화를 제공한다고 하는데, 자세한 내용은 본문에서 살펴보도록 하겠습니다. 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 포인트 클라우드 기반의 indoor/outdoor scene에서 모두 효과적으로 동작할 수 있는 통합된 3D detector을 최초로 설계
- learnable/non-learnable 쿼리가 포함된 쿼리 포인트 혼합 방식 제안
- 3차원 공간의 모든 방향을 분리한 decoupled 3D IoU 제안
2. Uni3DETR
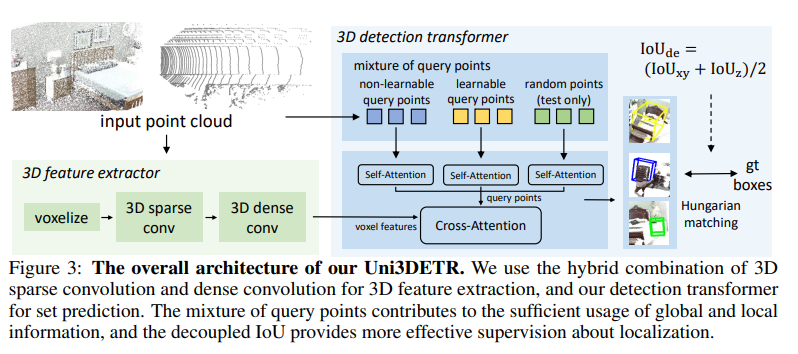
먼저 간략한 파이프라인을 살펴보면, 크게 feature extractor와 detection 트랜스포머 모듈로 이루어져 있습니다. 먼저 feature extractor는 PointNet이나 PointNet++과 같은 raw 포인트 입력 기반의 백본 네트워크는 사용하지 않았는데요, 그 이유는 포인트 set abstraction에 효율적이지 않다는 점을 고려하여 복셀 기반의 모델을 활용하였다고 합니다. 그렇게 복셀 형태로 변환하고 나면 3D sparse 컨볼루션 레이어를 통과하면서 3차원 feature을 인코딩 및 다운 샘플링하게 되는데, 이 과정에서 lare range의 outdoor scene 데이터에 대한 메모리 소비를 줄일 수 있습니다. 다음엔 추출한 spare feature를 dense feature로 변환하고 3D dense 컨볼루션을 적용하여 추가적으로 feature를 처리합니다. 이러한 dense 컨볼루션을 통해 앞서 언급한 sparse 컨볼루션만을 사용했을 때의 문제점이었던 중심 feature의 손실 문제를 완화할 수 있습니다. 이렇게 feature extractor 모듈을 지나고 나면 혼합된 쿼리 포인트가 3차원 박스를 예측하기 위해서 트랜스포머 디코더 모듈로 들어가게 됩니다.
2.1. Unified 3D Detection Transformer for Diverse Scenes
이어서 트랜스포머 디코더 모듈에 대해서 살펴보도록 하겠습니다. 먼저 트랜스포머는 추출된 복셀 feature을 기반으로 작동하며 3차원 물체 검출을 위해 set 예측 방식을 사용합니다. 쿼리를 앵커 박스로 계산하는 최근 2D 트랜스포머 기반 검출기에서 영감을 받아 3차원 공간의 3D 포인트를 쿼리로 활용하며 트랜스포머 모듈의 구조는 Fig. 4와 같습니다.
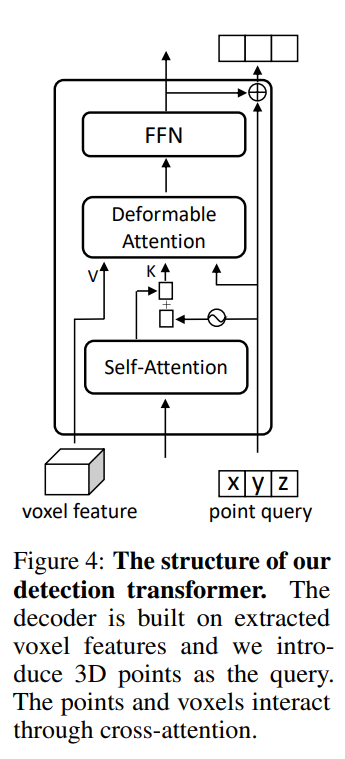
q번째 물체를 표현하기 위한 q번째 포인트를 P_q = (x_q, y_q, z_q)라고 정의하면 C_q \in \mathbb{R}^D가 해당 포인트의 content 쿼리가 되고, D는 디코더 임베딩의 차원 입니다. 크로스 어텐션 모듈에 대해서 deformable 어텐션을 사용하고, P_q를 포인트-복셀 상호작용의 기준이 되는 포인트로 간주합니다. deformable DETR의 디코더와 다르게, 본 논문의 디코더에서는 기준 포인트 P_q를 직접 학습합니다. 복셀 feature을 V로 가정하였을 때 크로스 어텐션의 과정을 식으로 정의하면 식(1)과 같습니다.
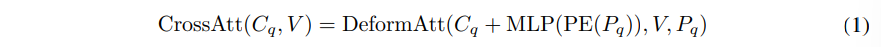
- PE : sinusoidal position encoding
결국 트랜스포머 디코더는 쿼리 포인트들에 대한 상대적인 위치 (\vartriangle x_q, \vartriangle y_q, \vartriangle z_q) 를 예측합니다. 예측된 상대적인 정보들을 기반으로 쿼리 포인트들은 layer-by-layer로 refinement 하게 됩니다. 이러한 트랜스포머 구조는 2D detection 트랜스포머와 비교할 때 3차원 상에서는 position 정보가 더 큰 의미를 가지기 때문에 refinement를 위해 필요한 레이어가 더 적습니다. 여러 레이어에 대한 정보를 활용하기 위해서 refinement를 위한 레이어 중 첫번째 레이어를 제외한 모든 트랜스포머 디코더의 예측 결과의 평균을 구합니다.
학습 과정에서 위의 과정에서 사용한다고 이야기한 쿼리 포인트는 더 나은 3차원 검출을 위해 객체의 인스턴스를 거치게 됩니다. 저자는 이러한 쿼리 포인트가 학습 중에 계속 업데이트 되기 때문에 학습 가능한 쿼리 포인트라고 정의합니다. 이러한 학습 가능한 쿼리 포인트는 최종적으로 물체에 근접한 포인트들에 집중하기 때문에 주로 scene 내에서 로컬한 정보들을 알게 됩니다. 이러한 정보는 넓은 범위가 촬영된 scene 내에서 물체가 sparse하고 작게 존재하는 outdoor 포인트 클라우드에 대한 물체 검출에서 배경 포인트를 피하는데 도움을 줄 수 있습니다. 그렇다면 비교적 scene의 범위가 작고 물체의 크기가 좀 더 크고 다양한 indoor 데이터셋에도 학습 가능한 쿼리 포인트가 적절할까요? indoor 환경에서 트랜스포머 디코더는 로컬 정보 이외에 추가적으로 전체 scene 내 물체 사이의 글로벌한 정보까지 활용할 수 있어야 더 나은 물체 검출이 가능해집니다. 그래서 본 논문에서는 글로벌 정보에 대한 학습 불가능한 쿼리를 도입합니다. raw한 입력 포인트 클라우드 데이터에서 FPS로 샘플링한 포인트들을 쿼리 포인트로 사용하며 이러한 쿼리 포인트들은 학습 동안에 freeze 되겠죠. FPS로 인해서 샘플링한 포인트는 전체 장면을 아우르는 형태를 띌 수 있으며 학습 가능한 쿼리 포인트가 무시하는 물체들 간의 관계에 대해서도 캐치할 수 있습니다.
기존 트랜스포머 디코더 구조와 다르게 본 논문에서는 포인트-복셀 사이의 상호 작용을 거친다고 이야기했는데, feature 추출을 위해서 복셀화를 진행하면서 raw 포인트 클라우드 기존의 좌표와 수가 동일하게 유지되지 않을 수 있습니다. 그래서 복셀화 후의 포인트와 raw 포인트 데이터 사이의 구조 변화를 고려하여, 학습 불가능한 쿼리의 종류를 두 가지(P_{nl}, P_{nlv})로 나누었습니다. 먼저 P_{nl}은 raw 포인트 클라우드에서 FPS로 샘플링하여 얻는다고 앞서 설명한 포인트를 의미하며 P_{nlv}는 복셀 후에 포인트를 샘플링하여 얻는 포인트 입니다. 결국에 디코더에서 사용되는 쿼리 포인트는 학습 가능한 P_l까지 합쳐서 P = \{P_l, P_{nl}, P_{nlv}\}로 이루어집니다. 본 논문에서는 이러한 세 종류의 쿼리 포인트가 서로 상호 작용하지 않으면서 독립적으로 group-wise self attention을 수행합니다. 즉 트랜스 포머 디코더를 거치면 세 개의 예측된 3차원 박스 집합 \{bb_l, bb_{nl}, bb_{nlv}\}이 만들어집니다. 만들어진 박스 집합에 대해 헝가리 매칭 알고리즘을 독립적으로 적용하고, 해당하는 loss를 계산하여 트랜스포머를 학습합니다.
inference에는 앞선 세 가지의 쿼리 포인트 이외에 3차원 복셀 공간에서 무작위로, 하지만 균일하게 추가적인 포인트를 또 다른 쿼리 포인트 P_{rd}로 사용합니다. 이렇게 무작위로 생성된 포인트는 전체 scene을 균일하게 채우기 때문에 특히나 indoor scene에서 놓치기 쉬운 일부 물체에 대한 포인트를 포함하고 있습니다. 다시 말해서 inference에 활용하는 쿼리 포인트는 P = \{P_l, P_{nl}, P_{nlv}, P_{rd}\}이며 이러한 쿼리 포인트들을 독립적으로 사용해서 만들어지는 예측되는 3차원 박스는 \{bb_l, bb_{nl}, bb_{nlv}, bb_{rd}\}이 되게죠. 일대일 할당을 통해서 개별적인 박스 집합마다의 중복되는 박스를 제거하기 위한 별도의 후처리 과정이 필요하지는 않습니다만, 네 개의 집합 사이에 여전히 중복되는 예측이 존재할 수는 있습니다. 따라서 글로벌, 로컬 정보를 모두 최대한 활용하면서 중복되는 예측은 제거할 수 있도록 최종적인 박스들을 결정하는 과정을 수행합니다. 이 과정이 바로 기존의 3차원 물체 검출에서 3D IoU를 기준으로 3차원 바운딩 박스를 클러스터링하고 그 중에서 중앙값을 최종 예측값으로 삼는데, 여기서 최종 예측으로 쓰이는 박스의 confidence score는 클러스터링된 박스 중 최대값이겠죠. 저자는 여기서 Decoupled IoU라는 개념을 새로 도입하였습니다.
2.2 Decoupled IoU
기존 트랜스포머 기반의 2D 검출기는 보통 L1 loss와 일반화된 IoU loss를 이용하는데요, 여기서 일반화된 IoU는 다양한 스케일에 대해서 L1 loss의 문제를 완화할 수 있다고 합니다. 그러나 3차원 바운딩 박스의 경우에는 IoU loss를 계산이 2D보다 더 복잡합니다. 하나의 3차원 바운딩 박스는 일반적으로 bb = (x, y, z, w, l, h, \theta)로 표시되는데, 여기서 (x, y, z)는 박스의 중심 좌표이며 (w, l, h)는 박스의 크기 그리고 \theta는 회전 각도를 나타냅니다. 이러한 박스 bb1, bb2 두 개의 일반적인 3D IoU 계산을 정의하면 식(2)와 같습니다.
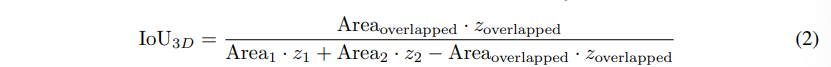
- latex]Area[/latex] : xy 공간에서 박스의 영역
식(2)를 통해서 3D IoU 계산은 (x, y, w, l, \theta)를 포함하는 바운딩 박스 영역인 xy 공간과 박스 height에 해당하는 z 공간, 이렇게 두 공간으로 구성된다는 것을 확인할 수 있습니다. 학습할 때 이 두 공간의 gradient가 합쳐져 한 공간에서의 최적화가 다른 공간에서의 최적화에 방해가 되어 학습 과정이 불안정해질 수 있다고 합니다. 결국 식(2)와 같은 일반적인 3D IoU는 검출기에서 최적화하는 데 어려움이 존재합니다. 바운딩 박스의 regression을 위해 이미 L1 loss가 존재하는 트랜스포머 기반 3차원 물체 검출기에서 3D IoU의 최적화 문제는 기존에 2D 트랜스포머 기반 검출기에서는 스케일 문제를 완화할 수 있었던 효과가 크게 감소하게 됩니다.
따라서 3D 트랜스포머 디코더의 가장 이상적인 metric은 다음과 같은 조건을 만족시켜야 한다고 정의하였는데요, 먼저 최적화가 쉬워야 한다고 합니다. 특히나 서로 다른 방향에 대한 coupling 효과의 경우 위에서 언급한 것과 같은 부정적인 영향이 완화되어야 합니다. 두번째로는 사용되는 바운딩 박스의 모든 shape에 대한 특성을 고려해야 합니다. 마지막으로는 L1 loss 문제를 완화하기 위해서 metric은 scale invariance 해야 하기 때문에 이러한 세 가지 조건을 기반으로 본 논문에서는 decoupled IoU를 제안합니다.

decoupled IoU는 xy 공간과 z 공간의 IoU를 기존 식(2)처럼 곱하지 않고 평균한 값을 의미합니다. summation 연산에서 두 공간의 gradient는 분리되어 독립적으로 유지할 수 있기 때문에 coupling 효과를 피할 수 있습니다. 이전 연구들에 따르면, 1D나 2D IoU에서는 coupling 문제가 존재하지 않기 때문에 이 점을 활용하여 decoupling IoU에서는 기존 3D IoU에서 coupling으로 인해 발생하던 문제를 완화할 수 있습니다.
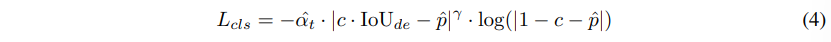
- c : 타겟 클래스 라벨
- \hat{p} : 예측한 클래스의 확률
- \hat{a}_t : a \cdot c \cdot IoU{de} + (1 - \alpha) \cdot (1 - c \cdot IoU_{de})
이러한 decoupled IoU는 학습 loss와 매칭 코스트에 모두 사용될 뿐만 아니라 classification loss에도 식(4)와 같이 이를 사용합니다. classification loss에서 focal loss에 소프트 타겟인 IoU_{de}를 사용하였는데, 설계한 목적처럼 decoupled IoU는 최적화하기 쉽기 때문에 IoU_{de}에서 stop-gradient를 수행할 필요가 없게 됩니다. 따라서 classification과 localization의 학습이 분리되지 않아 보다 정확한 confidence score을 예측할 수 있습니다. 식(4)는 \hat{p}을 IoUde로 강제하게 되며, 이는 inference에서 사용하는 IoU3D와 일치하지 않을 수 있습니다. 따라서 네트워크에 IoU branch를 추가하여 3D IoU도 예측하도록 합니다. 일반적인 IoU_{3D}는 IoU branch로 학습하며, 이를 위해 cross entropy loss를 사용합니다. 예측된 3D IoU와 분류 점수의 가중 기하 평균이 최종 신뢰 점수에 활용됩니다. 즉 Uni3DETR 학습을 위한 최종 loss 함수는 classification loss (식4)와 regression을 위한 L1 loss, IoU_{de}를 사용한 IoU loss, IoU_{3D} 예측을 위한 cross entropy loss로 구성됩니다.
3. Experiments
실험은 indoor 데이터셋인 SUN RGB-D, ScanNet V2, 그리고 S3DIS와 outdoor 데이터셋인 KITTI, nuScenes에서 진행하였습니다.
3.1. Indoor 3D Object Detection
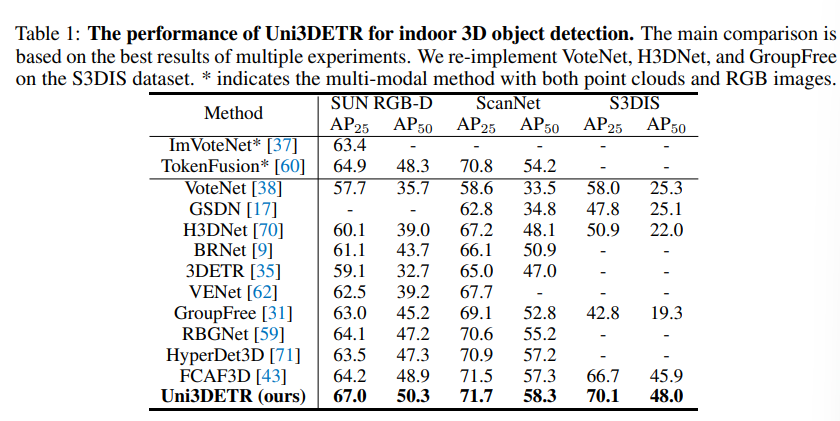
먼저 indoor 데이터셋에 대한 실험 결과로 SUN RGB-D에서는 AP25와 AP50에서 각각 67.0%, 50.3%로 CNN 기반 SOTA였던 FACF3D와 3% 이상의 차이를 보이며 SOTA를 달성하였습니다. ScanNet에서 역시 SOTA를 달성하였고, 특히 포인트 클라우드만 사용하면서 기존의 멀티모달 접근 방식(TokenFusion)보다 더 나은 성능을 보이며 Uni3DETR의 효과를 강조하고 있습니다. 또한 트랜스포머 기반 3DETR, GF3D과 비교하여 혼합된 쿼리 포인트를 사용한 decoder가 포함된 본 논문의 모델이 3D 물체 검출에 더 적합함을 입증하고 있습니다.
3.2. Outdoor 3D Object Detection
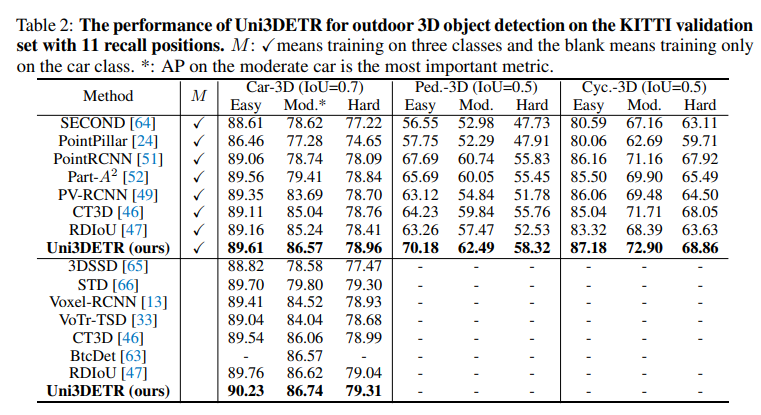
outdoor 데이터셋에서 먼저 쉬움, 보통, 어려움의 세 가지 난이도로 설정된 KITTI validation set에서 성능 리포팅을 하며, 그 중 가장 중요한 KITTI 지표인 보통 수준의 차 클래스에서 기존 CT3D보다 1.5% 이상, RDIoU보다 1.3% 이상 높은 86.57%의 성능을 달성합니다. 또한 보행자 및 자전거 클래스에서도 Uni3DETR의 일관되게 좋은 성능을 보이며 기존 indoor detector가 outdoor에서 힘들어하는 작고 자동차보다 클래스가 희소 물체도 잘 구분하고 있음을 알 수 있습니다.
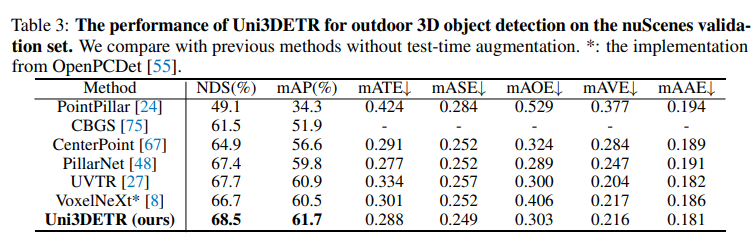
다음은 KITTI 대비 scene 범위가 더 넓고 front 뷰만이 아니라 LiDAR로 촬영한 360도 범위의 더 sparse한 포인트 클라우드를 제공하는 nuScenes에서의 실험 결과 입니다. 기존 outdoor detector도 challenge한 데이터셋인 nuscenes에서도 최신 방법론을 능가하면서 challenge oudoor scene에서의 강인성을 검증하고 있습니다.
3.3 Ablation Study
3D Detection transformer
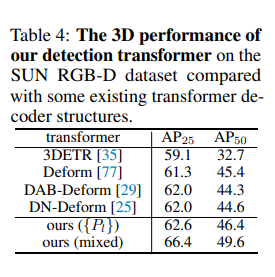
타 트랜스포머 기반 방법론과 비교한 ablation study 입니다. 3DETR은 point 기반 feature extractor을 사용하여 point representation여서 성능이 다른 복셀 기반 방법론에 비해 제한되었다고 합니다. 해당 실험을 통해 저자는 3D 앵커 박스를 쿼리로 사용하는 기존 방법론이 쿼리 포인트보다 비교적 덜 효과적이라고 주장하고 있습니다.
Mixture of query points
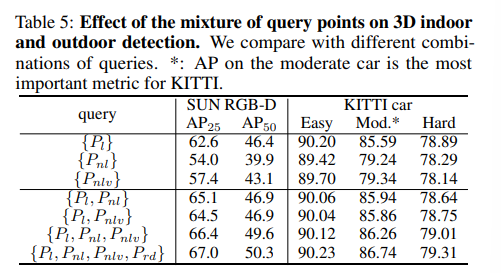
다음은 쿼리 포인트 혼합에 대한 영향력을 분석한 실험으로 SUN RGB-D에서는 학습 가능한 쿼리 포인트 \{P_l\}을 단순 사용하면 62.6%의 성능이며 이를 학습 불가능한 쿼리로 대체하면 성능이 저하됩니다. 이는 학습 불가능한 쿼리는 학습 중에 고정 되어 객체 주변의 정보에 적응적으로 대응할 수 없기 때문이죠. 혼합 사용으로 \{P_l, P_{nl}\}을 도입한 후 AP25가 62.6%에서 65.1%로 가장 크게 향상되는데, 이는 \{P_{nl}l\}의 글로벌 정보가 \{P_l\}이 로컬 정보에 주로 집중되어 있는 점을 완화해주고 있음을 알 수 있습니다. \{P_l, P_{nlv}\}를 사용하면 성능이 비슷하게 향상하지만 \{P_{nl}l\}보다는 낮은 효과를 보이는데, 그 이유는 복셀화로 인해 일부 포인트가 제거되어 global한 정보가 그다지 완전하지 않기 때문 입니다. inference 시에만 사용되는 \{P_{rd}l\}가 포함된 케이스를 제외하면 \{Pl, P_{nl}, P_{nlv}\}를 사용할 때 세 가지 쿼리 포인트가 성능을 더욱 향상시키고 있습니다.
KITTI에서는 학습 불가능한 쿼리 포인트의 효과가 indoor scene에 비해 덜 중요하다는 것 확인할 수 있는데, 이는 outdoor 포인트 클라우드는 범위가 넓고 sparse하여 학습 불가능한 쿼리의 글로벌 정보 효과가 많은 배경 정보로 인해 상쇄될 수 있기 때문이라고 해석할 수 있습니다.
Decoupled IoU
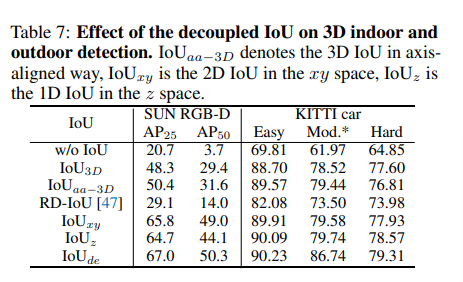
다음은 3D에서 사용하는 다양한 유형의 IoU와 Decoupled IoU와의 비교 실험 입니다. IoU loss 없이 classification, L1 regression loss로만 최적화 하게 되면 20.7%의 성능을 보이는데, L1 loss의 scale 문제를 해결하기 위해 3D IoU가 필요하게 됩니다. 그래서 일반 IoU3D를 사용하면 L1 loss의 문제가 어느 정도 완화되지만 역시 커플링 효과로 인해 성능 향상이 제한적 입니다. 본 실험을 통해 2D IoU 커플링 문제 존재하지 않는다는 사실을 확인할 수 있는데 그 이유는 z축을 고려하지 않는 IoUxy 조차도 IoU3D보다 무려 17.5% 더 높은 성능을 보이기 때문 입니다. 마지막으로 Decoupled IoU에서 가장 높은 결과가 나타나며 이를 통해 모든 방향을 고려한 새로운 IoU 방식의 효과를 입증하고 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
간단한 질문 두 가지만 남기겠습니다.
1. 그림(3)의 마지막 과정인 hungarian matching 과정은 2D detection의 DETR 수행할때와 동일하게 loss를 계산하는 건가요? 아니면 다르게 동작하는 건가요?
2. 3D detection을 수행할 때 pre-processing 과정인 voxelization 과정은 시간이 얼마나 걸리나요? 꽤 오래걸릴 것 같은데 성능 개선을 위해 필수적인 과정인가요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. hungarian matching 과정은 2D detection의 DETR과 동일하나, loss에서 decoupled IoU를 사용한다는 점이 DETR과 차이가 납니다.
2. voxelization 과정은 input으로 포인트 클라우드가 얼마나 들어오는지에 따라 차이가 나지만, 메모리와 시간 비용이 굉장히 많이 소모되는 것은 사실 입니다. 이러한 리소스 사용에도 불구하고 voxelization 과정이 필요한 이유는 포인트 클라우드가 raw한 형태로 CNN 구조의 입력으로 들어갈 수 없기 때문에 3D CNN이나 sparse conv로 모델을 설계하기 위해서는 voxelization을 필수적인 처리 과정 입니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽으며 outdoor에서도 작동하고 indoor에서도 작동하는 방법론이라 흥미로웠고, 특히 learnable/non-learnable 쿼리가 포함된 쿼리 포인트 혼합 방식이 흥미로웠습니다. 궁금한 점이 있는데요. 여기서 non learnable 쿼리를 복셀화된 구조 내의 포인트와 raw한 포인트를 샘플링하여 사용하였다고 했는데, 이 복셀화된 구조 내의 포인트와 raw한 포인트 자체가 원래부터 글로벌 정도를 가지고 있는 건가요? 어떻게 저자들이 non-learnable 쿼리가 글로벌 정보를 가지고 있어 효과적으로 작동할 수 있었음을 알았는지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
쿼리에 사용되는 포인트 자체에 원래 글로벌 정보가 들어있는 것은 아니고, 샘플링 과정에서 FPS를 통해 전체 입력으로 들어오는 포인트 클라우드에 전반적인 영역에서 샘플링이 가능하기 때문에 샘플링 이후의 포인트는 전체 영역을 아우르는 형태를 가지고 있고, 이러한 포인트들이 결국 글로벌한 정보를 가지고 있다고 판단할 수 있습니다.
안녕하세요, 손건화 연구원님. 좋은 리뷰 감사합니다. 리뷰를 읽다가 앞 부분에서 잘 이해가 가지 않는 부분이 있어 질문 남기고자 합니다.
본 논문에서 제안하는 구조가 feature 추출을 위해서 3D sparse 컨볼루션과 dense한 컨볼루션을 합친 하이브리드 구조를 사용하였고, 이러한 구조가 indoor 포인트 클라우드에 대한 height가 압축된다고 하셨는데, 이 부분이 무슨 뜻인지 잘 이해가 되지 않네요. indoor 포인트 클라우드에 대한 height가 압축되는 것이 어떤 뜻인지 좀 더 자세히 설명해주실 수 있을까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
기존에 outdoor 데이터셋에 대한 3D detection은 BEV 공간에서의 feautre 추출을 위해 dense 컨볼루션을 사용하였는데, 이러한 파이프라인을 indoor에의 사용이 적절하지 않았습니다. 그 이유는 여러 물체가 수직으로 쌓여있는 형태로도 배치되어 있기 때문에 이를 BEV 공간으로 눌러버리면 제대로 된 검출을 할 수가 없었기 때문입니다. 이렇게 수직으로 배치되어 있을 경우 3D 바운딩 박스의 height는 아예 예측을 할 수가 없게 되고 이를 height가 압축된다고 논문에서 표현하였습니다. 그래서 기존의 height가 압축되는 현상을 BEV 공간으로 누르지 않고 sparse conv와 하이브리드 구조로 설계하여 완화하고자 한 것 입니다 !
좋은 리뷰 감사합니다.
introduction에서 indoor와 outdoor 데이터의 차이에 대해 설명해주셨는 데,
데이터의 sparse하고 dense함의 차이는 사용하는 센서가 다르기때문인지 아니면 대상 장면이 정적/동적 이라는 차이 때문인지 궁금합니다. 혹은 둘다 인가요??
또한 복셀화한 point를 3D sparse conv를 거친 다음 3D dense conv를 거친다고 하셨는데, 병렬 방식이 아닌 이미 sparse conv를 통과한 feature를 이용하여 dsen conv를 통과하는 방식도 손실된 feature를 복원할 수 있는것인가요??
본 논문의 핵심 요소 중 하나인 decoupled IoU에 대하여, 최적화가 방해되는 문제를 해결하기 위해 z축에 대한 IoU를 분리한 것으로 이해하였습니다. 1D나 2D에 대해서는 coupling문제가 발생하지 않아 coupling문제가 발생하는 3D에 대해 2차원에서 추가된 z축에 대해서만 따로 분리한 것으로 이해하였습니다. x, y, z축을 다 분리하거나 x축과 yz, y축과 xz축으로 결합하는 방식도 시도해볼 법 하다는 생각이 드는 데 이에 대한 언급이나 실험은 없었는 지 궁금합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
논문에서 서술한 내용을 제가 이해한 바로는 두 데이터의 차이는 사용하는 센서로부터 취득되는 포인트 클라우드 형태 차이로 이해하였습니다. 대상 장면이 정적/동적인 점도 이유가 될 순 있겠지만 제 개인적인 생각으로는 3D detection에서 정적/동적이 큰 이유가 되지는 않을 것 같습니다.
sparse conv를 통과한 feature을 dense feature로 변형하고 dense conv를 통과하게 되는데, 손실된 feature을 복원한다는 의미보다는 기존에 각각의 데이터셋에서 손실되던 정보들을 이렇게 하이브리드 구조로 사용할 경우에 정보 손실이 줄어든다고 이해해주시면 좋을 것 같습니다.
마지막으로 축 분리에 대해서는 마지막 Table 7이 현재 사용되는 IoU 종류에 대해서 실험을 진행한 것으로 현재까지 승현님께서 말씀하신 결합 방식에 대한 시도는 아직까지 없었고 저자도 다른 축으로의 분리에 대해서는 언급이나 실험을 진행하지는 않았습니다.