이번 리뷰 논문으로 Depth completion 논문을 들고 왔습니다. 이번 리뷰 논문은 일반적인 deptn completion 논문에서 다루는 방향과 다른 방향을 가지고 있습니다. 대체로 depth completion 태스크에서는 lidar로부터 추정된 sparse point cloud나, ORB와 같은 영상 특징점으로부터 추정된 sparse point cloud를 보완하는 방법론들을 위주로 발전되어 왔습니다. 이러한 문제를 해결하고자 하는 방법론들에서는 Kinect, realsense와 같은 상용 깊이 센서나측정 시, 대기 시간이 필요한 structure light 기반의 센서(e.g. matterport)를 이용해 얻은 깊이 정보들을 GT로 사용합니다. 하지만 이러한 센서들도 완벽하지 못하기 때문에 fig 1과 같이 환경적 요소에 의해 잘못된 측정이 이뤄지는 경우가 있습니다. 대표적으로 가시 영역의 빛을 제대로 반사하지 못하는 물체들에서는 제대로된 깊이 추정이 어려워집니다. 또한 시차 혹은 물체의 가려짐으로 인해 깊이 정보들이 제대로 측정되지 못하는 경우가 등장합니다. 제가 풀고자 하는 문제는 상용 깊이 센서들이 제대로 동작하지 못하는 경우를 다루고 싶었습니다. 이번 논문은 제가 다루고 싶은 문제점을 꼬집고 해결안을 제시한 논문으로 이후 연구에서도 해당 논문이 다룬 방법을 착안하여 제 연구를 확장하고자 합니다.
Intro
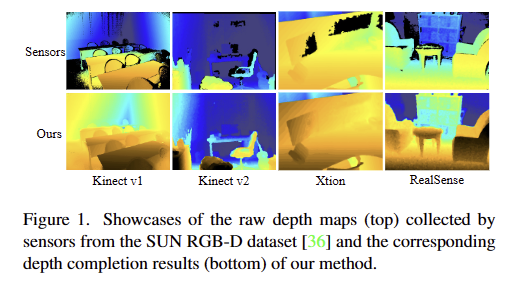
현존하는 실내 깊이 센서들은 증강 현실, 실내 네비게이션, 3D 재구성 등 3차원 인지를 위한 3차원 공간 정보를 제공하는 역할을 합니다. 그러나 대부분의 상용 깊이 센서(e.g. kienct, realsense)는 투명, 유광, 어두운 표면을 가진 물체에서 노이즈가 발생할 뿐더러, 너무 가깝거나 시차 차이로 인해 구멍(hole)이 발생합니다. 이러한 구멍은 깊이 센서를 활용한 다운 스트림의 성능에 큰 영향을 줄 수 있습니다. 이런 불완전한 깊이 맵에서 발생하는 문제를 해결하기 위해서 raw depth map을 재구성하는 depth completion이라 불리우는 연구들이 제안 되어 왔습니다. 깊이 맵에 비해 풍부한 색상과 텍스쳐를 제공하는 RGB는 일반적으로 불완전한 깊이를 보완하기 위한 정보로 활용됩니다. 좀 더 구체적으로 언급하자면, depth completion은 일반적으로 깊이 값을 보완하고 다듬기 위해서 하나의 깊이 센서로 캡처된 raw depth와 RGB로 구성된 한 쌍의 정보를 사용하여 수행됩니다.
대표적인 접근 방법으로는 CNN을 활용한 방법들이 큰 진전을 이루어왔으며, hour-glass network를 이용하여 sparse depth map과 RGB를 이용하여 dense depth map을 직접 회귀하는 방법이 있습니다. 해당 방법은 기존 전통적인 기법 대비 큰 진전을 보였지만, 예측된 깊이 맵이 흐릿하다는 단점이 있습니다. 이후 연구들은 두 가지 다른 방법으로 나눠져서 발달합니다. 첫번째 그룹은 상대 픽셀에 대한 유사성을 학습하고 예측된 깊이 정보를 반복적으로 개선합니다. 이러한 방법은 raw global depth map의 정확성에 크게 의존하며, 비효율적인 문제가 있습니다. 다른 그룹에서는 기하학적 특성을 기반으로 접근하는 방식으로 surface normal을 추정하거나 discrete planes에 깊이를 투영하여 feature network의 구조를 구성하는 방식을 이용합니다. 해당 접근 방법은 기하학적인 완전성을 확보하기 위해서 누락된 영역이 없는 깊이 정보를 GT로 요구합니다. 또한, 학습된 모델이 다른 장면에서 효율적으로 일반화되기 어렵다는 문제가 있습니다(+ 기하학적인 규제를 강하게 주고 학습된 모델이기 때문). 두 그룹 모두 RGB는 단순하게 표면적인 안내나 보조적인 정보로만 활용하며, 질감과 맥락 정보를 고려하는 연구들은 거의 없습니다. 이러한 점에서 depth completion은 개념적으로는 간단하지만 실제로는 어려운 단안 깊이 추정으로 변환된다고 볼 수 있습니다.
좀 더 다루자면, 위에서 언급한 대부분의 방법론들은 dense depth map에서 특정 수 만큼의 valid 픽셀을 균일하게 무작위로 샘플링하여 훈련 및 평가를 위한 sparse depth map을 모사합니다. 이러한 샘플링 기법은 일부 장면에서는 신뢰할 수 있습니다만, 샘플링된 패턴은 fig 1에서 보이는 것과 같이 실내 깊이 맵에서 보이는 실제 누락 패턴과는 상당히 다릅니다. 기존 방법론들은 균일하게 희소한 깊이 맵을 완성하는 데에 있어서는 효과적으로 보이지만, 실내 깊이 완성에 대해서는 잘 동작하지 않을 가능성이 있습니다.
저자는 이러한 문제를 지적하고 해결하기 위해서 실내 환경에서 완성된 밀집 깊이 맵을 생성하기 위한 새로운 two-branch end-to-end network를 제안합니다. GAN에 영감을 받아, RGB와 depth map을 융합하기 위한 RGB-depth Fusion GAN (RDF-GAN)을 제안합니다. RDF-GAN은 불완전한 깊이 맵에 의해 생성된 latent spatial vector 변환하여 RGB 도메인을 조건부 정보로 주입함으로써, dense depth map에 맵핑합니다. 해당 네트워크는 RGB 조건부 정보를 효과적으로 주입하는 weighted-adaptive instance normalization (W-AdaIN)과 융합된 정보의 깊이 값에 제약을 주는 constraint network를 추가적으로 제안합니다. 마지막으로 confidence fusion head를 통해 최종적은 depth completion을 수행합니다. 추가로 저자는 훈련을 위해 raw depth map을 실내 깊이 누락의 특성을 따라 RGB와 segmeation lable을 활용하여 가상의 깊이 맵을 생성하는 기법을 제안합니다. NYU-Depth V2와 SUN RGB-D에서의 실험적인 분석을 통해 해당 기법이 실내에서 누락 영역을 효과적으로 채움을 증명합니다.
또한, NYU-Depth V2와 SUN RGB-D에서 SOTA를 달성하고 다운스트림(3D detection)에서 성능 향상을 보임으로써 해당 기법의 우수성을 입증합니다.
Method
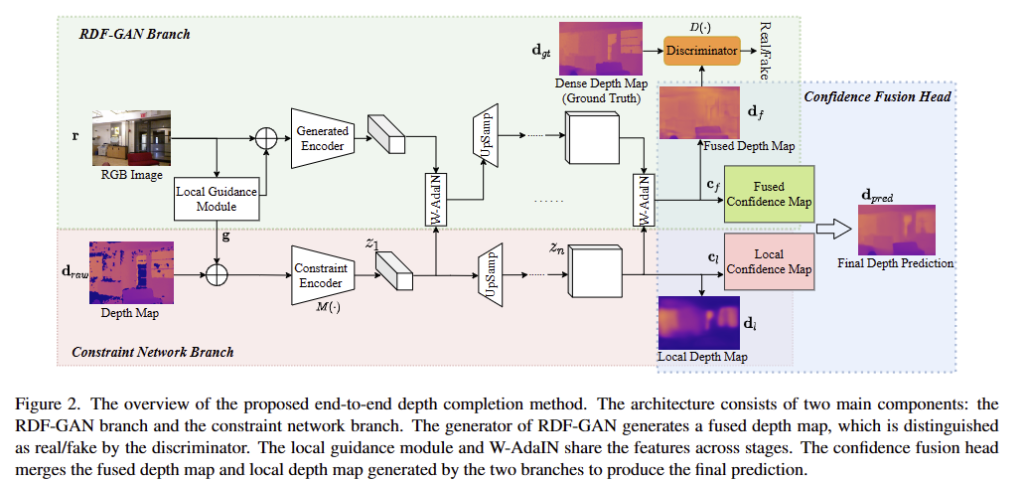
저자가 제안하는 모델은 raw depth map (noise and possibly incomplete)과 쌍을 이루는 RGB 영상을 입력으로 하여 completed and refined dense depth map을 출력합니다. 해당 모델은 두 분기(constraint network branch와 RGB-depth Fusion GAN branch)로 구성됩니다. 두 브랜치는 각각 depth map과 RGB를 입력으로 하여 depth completion results를 출력합니다. 두 분기 간의 표현을 융합하기 위해 local guidance module과 W-AdaIn이라는 중간 융합 모듈을 여러 단계에서 적용합니다. 마지막으로 Confidence Fusion head를 통해 두 브랜치의 출력을 결합하여 보다 안정적이고 높은 정확도를 가진 깊이 완성 결과를 생성합니다. 더 나아가, pseudo depth maps과 전체 손실 함수를 소개합니다.
Constraint Network Branch
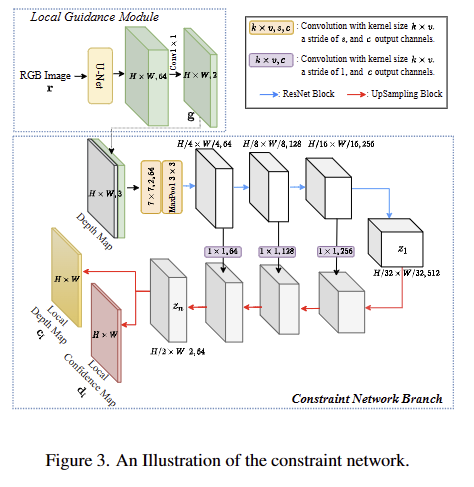
Constraint Network Branch는 raw depth map d_raw 와 RGB 영상 r으로부터 local depth map d_l와 confidence map c_l를 회귀하기 위한 ImageNet으로 사전 학습된 ResNet-18을 기반의 encoder-decoder 구조로 설계되어 있습니다. fig 3과 같이 입력 정보로는 depth map d_{raw} \in R^{H \times W \times 1} )과 Local Guidance Module을 통해 3채널을 가진 RGB로부터 추론된 2채널을 가진 local guidance map g, 두 값을 결합한 정보를 사용합니다. 여기서 local guidance map은 fig 3의 왼쪽 상단과 같이 원본 깊이 정보에서 cue를 얻기 힘든 가시적인 정보로부터 공간적인 가이드를 주기 위해 U-Net을 이용하여 추출됩니다. 이렇게 입력된 정보는 encoder M()을 통해서 latent feature z를 생성하고 생성된 z는 encoder와 skip-connection을 가진 decoder를 통해 local depth map d_l과 local confidence map c_l을 추정합니다.
RDF-GAN Branch
해당 브랜치는 RGB와 raw depth를 융합하여 보다 fine-grainded texture and dense depth mpa을 생성하기 위해서 GAN을 이용하는 방법을 제안합니다. 기존 fusion-based methods이 서로 다른 두 도메인을 직접적으로 융합하는 것과 다르게 conditional GAN과 style GAN으로부터 영감을 얻어 조건부 정보를 이용하는 방법을 제안합니다. Fig 2의 왼쪽 상단에 표시된 것처럼 raw depth map의 latent feature를 입력으로 사용하고 RGB를 조건으로 사용하여 depse depth map과 confidance map을 생성합니다. 생성된 깊이 정보와 GT depth를 구별하기 위해 discriminator D()를 사용합니다. 해당 브랜치의 generator G()는 앞서 소개드린 constraint network와 유사한 구조를 가지고 있습니다. RGB 정보가 조건부로 latent depth feature z를 입력으로 받아 fused dense depth map d_f와 fused confidence map c_f를 생성합니다. (W-AdaIN은 아래 섹션에서 다룹니다.) 생성된 d_f는 PatchGAN을 따르는 discriminator를 사용하며, loss는 WGAN을 따른다고 합니다. 구체적인 수식은 다음과 같습니다.
Feature Fusion Modules
앞서 소개한 두 브랜치에서 모두 두 도메인 정보가 원활하게 융합하기 위한 2가지 기법 local guidance module과 W-AdaIN을 소개합니다.
local guidance module. 해당 모듈은 Fig 3 왼쪽 상단에서 확인 가능하며, U-Net 구조를 가지고 있으며, 3채널의 RGB 정보를 2 채널을 가진 정보 local guidance map g로 추정합니다. local guidance map의 첫 번째와 두 번째 채널은 각각 전경 확률과 의미론적 특징을 나타냅니다. 이를 통해 입력 정보 간의 상관 관계에 초점을 맞추도록 안내할 수 있습니다.
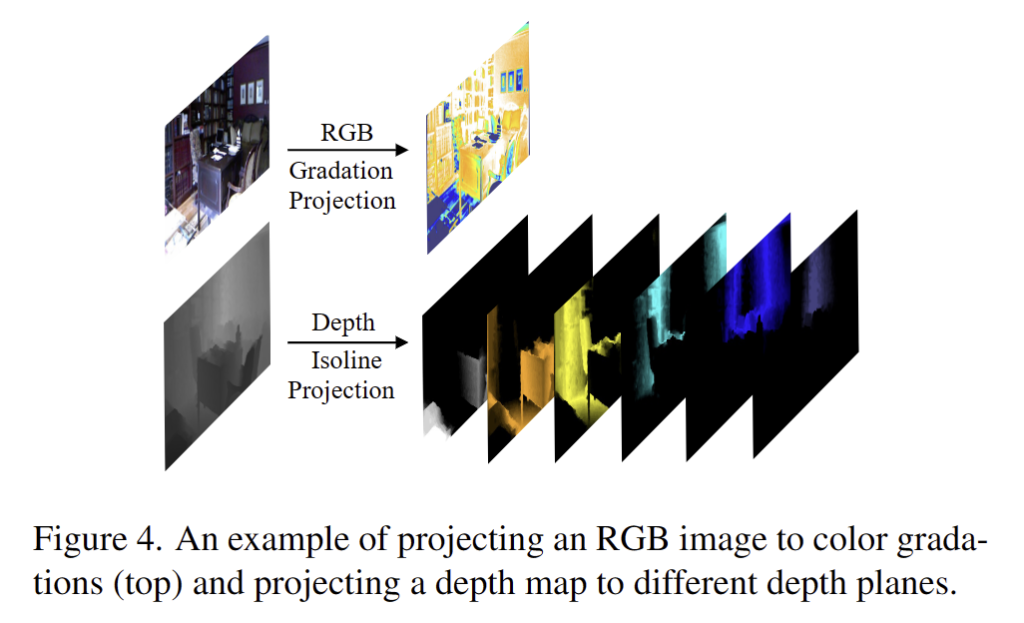
W-AdaIN. 우선 Fig 4의 아래와 같이 깊이 정보를 사전 정의된 깊이에 따른 이산화된 깊이 평면에 투영합니다. 국소 영역의 깊이 정보들은 서로 차이가 적은 깊이 정보를 가지고 있다는 특징이 있기 때문에 깊이 영역을 추론하기 더 쉬워집니다. 또한 RGB 영상들은 유사한 색상 gradation을 가지고 있으면, 유사한 깊이 정보를 가진다는 경험적인 지식을 토대로 색상 기울기에 따라 비슷한 깊이 값을 가지고 있습니다. 이러한 점을 토대로 W-AdaIN을 아래와 같이 설계하는 것을 제안합니다.
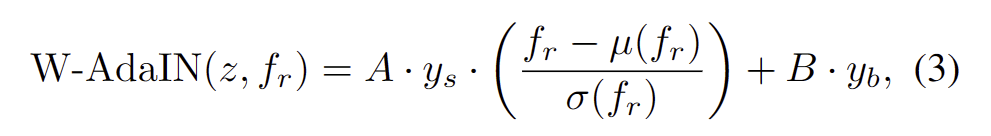
여기서 RGB의 feature map f_r, depth latent vector z, A = Attention(z)와 B = Attention(f_r)는 각각, z와 f_r에 대한 Attention에 의해 생성된 가중치 행렬, y_s와 y_b는 z를 이용한 아핀 변환을 통해 얻은 공간적 스케일링과 bias이며, u(f_r)과 sigma(f_r)은 각각 f_r의 평균 및 표준편차에 해당합니다. 설계에 따라 A는 유사한 깊이 값을 가진 영역에 유사한 가중치 값을 할당합니다. 마찬가지로 B는 로컬 유사 색상 그라데이션의 유사한 가중치 값을 할당하여 깊이 블록을 평활화합니다.
Confidence Fusion Head
RDF-GAN branch는 영상의 텍스처 특징을 기반으로 누락된 깊이를 추정 가능하지만 raw depth의 추정 편차를 생성할 수 있습니다. Encoder-Decoder 구조를 갖춘 constrain network branch는 유효한 raw depth에 의존적으로 정확한 깊이 맵을 생성 가능하지만, local 영역에깊이 정보가 얻으면 추론이 어려워집니다. 따라서 fig 2의 오른쪽에 표시된 Confidence Fusion Head에 의해 두 분기의 깊이 맵을 상호보완적으로 통합하기 위한 Confidence Map을 소개합니다. 일반적으로 local depth map은 raw depth map이 더 정확한 영역에서 더 높은 신뢰도를 얻는 반면 fuse depth map은 큰 누락 및 노이즈 영역에서 더 높은 신뢰도를 갖습니다. 해당 신뢰도 맵에 의해 가중치가 부여된 두 깊이 맵의 합은 최종 깊이 예측이며 다음과 같이 공식화됩니다.
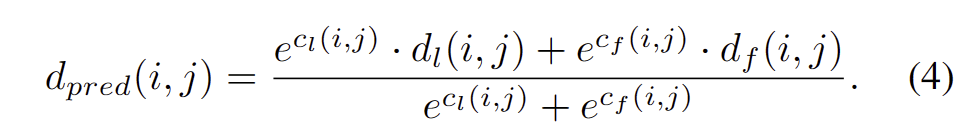
Pseudo Depth Map for Training
대부분의 기존 깊이 완성 방법은 무작위 희소 샘플링 방법으로 훈련되고 평가됩니다. 샘플링된 깊이 맵은 실외 깊이를 잘 모방하지만 깊이 분포 및 누락 패턴은 실제 실내 깊이 완성 장면과 상당히 다릅니다. 무작위로 다운샘플링된 깊이 픽셀은 장면의 거의 모든 영역을 포함하는 반면, 실내 환경에서 누락된 깊이 픽셀은 일반적으로 연속 영역을 형성합니다. 따라서 우리는 원시 깊이 이미지를 합리적인 불완전(의사) 깊이 맵에 매핑하기 위해 RGB 이미지와 의미론적 마스크를 사용하는 모델 훈련을 위한 깊이 맵을 생성하는 일련의 합성 방법을 제안합니다. 의사 깊이 맵은 깊이 누락 패턴을 모방하며 무작위로 샘플링된 깊이 맵보다 실제 원시 깊이 데이터와 더 유사합니다.
이 기술은 주로 RGB 이미지와 segmentation을 사용하여 raw depth에 대한 마스킹 영역을 생성합니다. 이를 통해, 간단한 균일 샘플링보다 더 현실적인 누락 패턴을 가진 합성 깊이 맵을 만듭니다. 다음은 이를 생성하기 위한 다섯 가지 방법입니다:
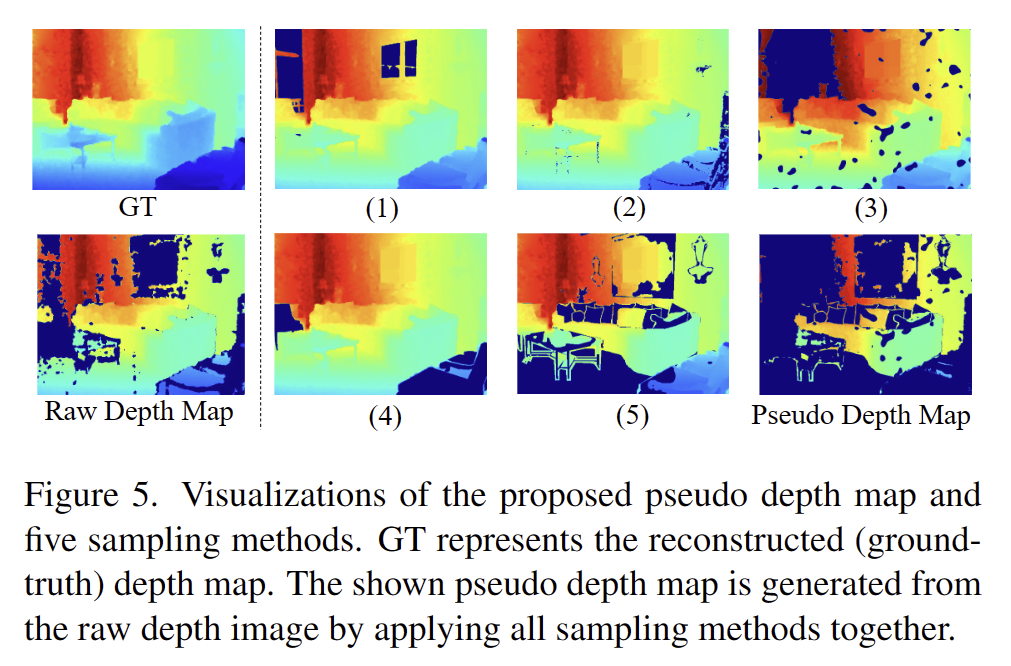
- Highlight Masking: RGB 이미지에서 추정한 반사 또는 광택 있는 영역을 마스킹합니다. 이는 투명하거나 반사적인 표면에 의해 발생할 수 있는 깊이 정보의 누락을 모방합니다.
- Black Masking: 매우 어두운 RGB 값이 있는 영역[0, 5]을 무작위로 마스킹합니다. 이는 카메라가 인식하기 어려운 어두운 표면에서의 누락을 시뮬레이션합니다.
- Graph-based Segmentation Masking: RGB 이미지에 기반한 그래프 기반 분할로 인식된 잠재적으로 노이즈가 많은 픽셀을 마스킹합니다.
++ 그래프 기반 분할? 찾아볼 것 - Semantic Masking: 특정 물질을 가진 객체의 깊이 값이 주로 누락되는 것을 반영하여, 의미적 라벨에 따라 하나 또는 두 객체를 무작위로 마스킹합니다.
- Semantic XOR Masking: 의미적 분할 모델을 사용하여 RGB 이미지를 분할하고, 분할 결과와 실제 의미적 라벨 사이의 차이(XOR 연산 결과)에 기반해 깊이 픽셀을 마스킹합니다.
마지막으로 위의 5가지 방법에서 마스크를 무작위로 선택하고 결합하여 더 그럴듯한 누락 깊이 분포를 모방하는 의사 깊이 맵을 생성합니다.
Loss Function
깊이 추정에 있어 L1 loss를 사용하여 L_D, L_G는 수식 (1-2)를 따릅니다. 전체 loss는 아래와 같습니다.
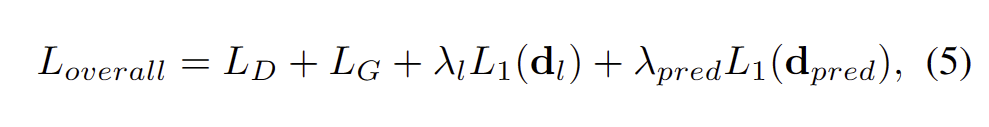
Experiments
Datasets. 아래 두 데이터셋 중 NYU-Depth V2는 특히 실내 장면에서의 다양한 객체와 구조를 포함하여, 모델이 복잡한 실내 환경을 이해하고 처리할 수 있도록 합니다. SUN RGB-D는 다양한 센서와 장면 유형을 포함하여 모델의 범용성과 실제 환경에서의 적용 가능성을 평가하는 데 중점을 둡니다.
- NYU-Depth V2: 다양한 실내 장면에서 수집된 RGB 및 깊이 이미지 쌍을 포함합니다. 이 데이터셋은 Microsoft Kinect를 사용하여 캡처되었으며, 464개의 실내 장면으로부터 얻은 이미지를 포함합니다. 795개의 훈련 이미지와 654개의 테스트 이미지로 구성된 밀도 라벨이 부여된 이미지 쌍을 사용합니다. 입력 이미지는 320×240으로 크기 조정되고, 중앙에서 304×228으로 크롭됩니다. 훈련에는 라벨이 없는 약 50,000개의 추가 이미지가 사용되며, 이는 모델이 더 다양한 장면을 학습할 수 있게 합니다.
- SUN RGB-D: 다양한 센서로부터 캡처된 10,335개의 RGB-D 이미지를 포함하고 있으며, 이는 실내 장면 인식 및 3D 재구성 연구에 널리 사용됩니다. 데이터셋에는 실내 장면의 다양성을 대표하는 여러 센서와 장면 유형이 포함되어 있습니다. 공식 분할에 따라 4,845개의 훈련 이미지와 4,659개의 테스트 이미지를 사용합니다. SUN RGB-D 데이터셋은 다양한 센서로부터의 이미지를 포함하기 때문에, 모델의 일반화 능력을 평가하는 데 유용합니다. 입력 이미지는 마찬가지로 320×240으로 크기 조정되고, 무작위로 304×228으로 크롭됩니다.
Comparisons with State-of-the-Art Methods
T는 reconstruction depth~dense depth, R은 raw depth, R*은 500 sampling depth map에 해당합니다. T*은 T로부터 500 sampling된 sparse depth map에 해당합니다.
NYU-depth V2
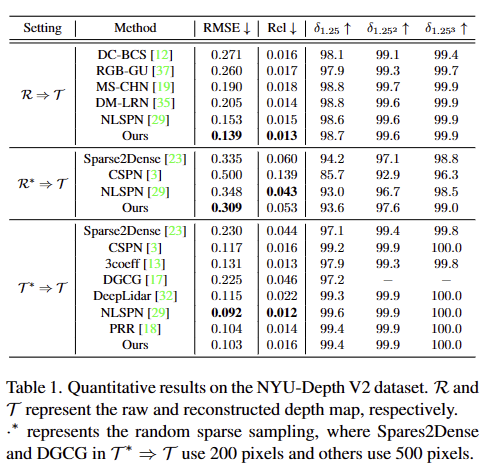
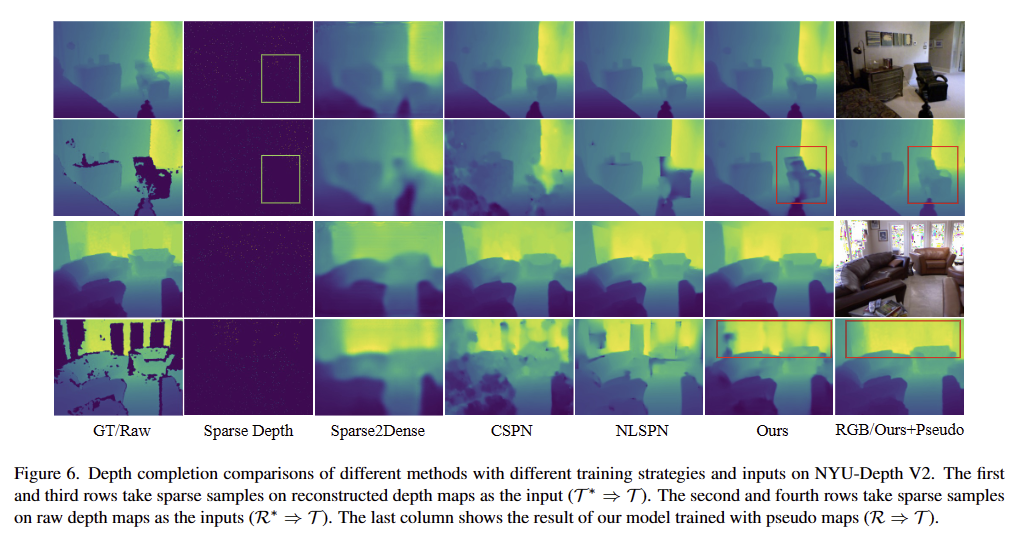

T*->T (fig 7)에서는 SOTA를 달성하지 못했지만 현실적인 설정의 평가 방법인 R->T와 R*->T에서 가장 월등한 성능(fig 6)을 보여주고 있습니다.
SUN RGB-D
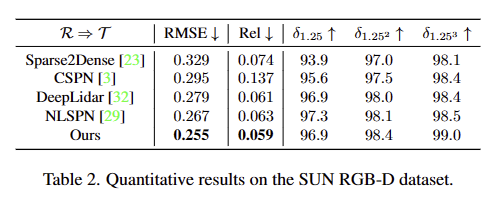
다양한 센서로부터 캡쳐된 이미지에 대한 모델의 일반화 성능을 평가하기 위한 데이터 셋으로 다른 방법론 대비 가장 우수한 성능을 보여줌으로써, 제시한 모델의 강인성을 입증합니다.
Ablation study

Settings of λs. Tab 3에서는 loss에 따른 실험 결과를 보입니다. 먼저, A에서는 최종 깊이 예측에만 L1 Loss를 적용한 성능이며, B와 C에서는 각각 RDF-GAN과 Constraint Network에 L1 Loss를 적용한 결과 입니다. 먼저, B는 fig 8-(a)에서 볼 수 있듯이 텍스처 정보에 지나치게 초점을 맞춰 많은 지역적 이상값을 생성했으며 많은 지역에서 예측된 깊이 값은 실제 값에서 큰 편차를 보였습니다. C에서는 직접적으로 예측하기 때문에 정량적 성능은 조금 더 좋아졌지만 모델이 인코더-디코더 구조로 변질됨에 따라 정성적 결과는 fig 8-(b)와 같이 흐릿한 깊이 정보가 형성됩니다. 최종적으로 두 branch의 정보를 모두 활용하는 D에서는 정량/정성적 결과 모두 나아진 결과를 보입니다.
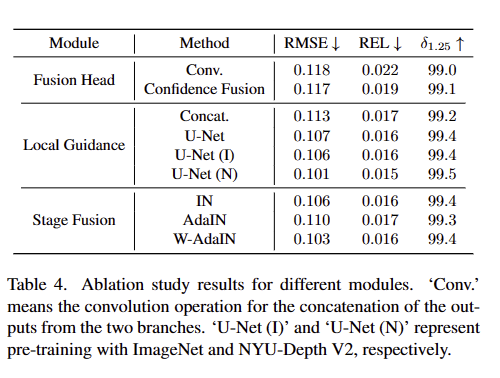
Modules. Tab 4에서는 모듈에 따른 성능 변화를 볼 수 있음
– Fusion Head. convolution을 이용한 예측 대신, 신뢰도 기반의 융합을 사용했을 때 더 좋은 성능을 보였습니다.
– Local Guidance Module. 단순히 RGB와 깊이 특징을 concatenation하는 대신, U-Net 기반의 local guidance module을 사용하여 특징을 추출했을 때 성능이 개선되었습니다. 특히, 사전 훈련된 모델 U-Net (I: ImageNet)이나 U-Net (N: NYU-Depth V2)을 사용했을 때 더 좋은 결과를 보였습니다.
– Stage Fusion Module. 기존의 Instance Noramalization (IN)나 AdaIN 대신에 W-AdaIN을 사용했을 때 가장 좋은 성능을 보여줌. 이로써 W-AdaIN이 깊이 정보와 RGB 정보의 융합을 더욱 효과적으로 수행함을 증명합니다.
Object Detection on the Completed Depth Map
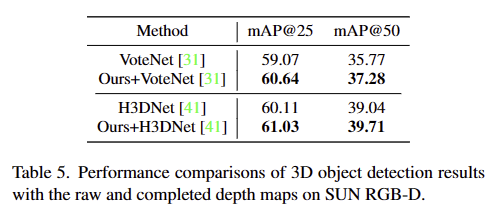
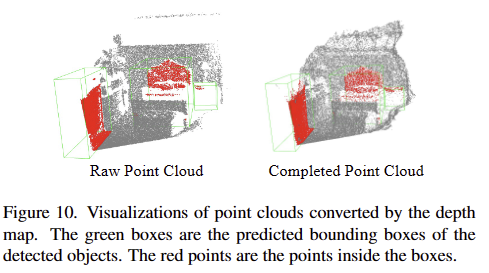
해당 기법을 통해 보완된 깊이 정보를 활용하여 SUN RGB-D에서의 3D object detection을 수행했을 때, tab 5와 같이 기존 모델들도 개선되는 결과를 보여줍니다. 이에 대한 정성적인 결과는 fig 10에서 확인 가능하며, 보이는 바와 같이 제안된 깊이 완성 모델이 더 정확하고 정보가 풍부한 깊이 맵을 생성하여 다운스트림 태스크에서도 긍정적인 영향을 줌을 입증합니다.
안녕하세요, 좋은 리뷰 감사합니다.
1. 그림(4)의 아래에 있는 depth projection 과정에서 캡션을 보니 다양한 plane에 대한 projection 결과로 보이는데 6개는 어떤 plane을 의미하는지 궁금합니다.
2. raw depth에서 생기는 hole을 채우는 것을 GAN을 활용하여 pseudo depth을 만들어 학습하는 과정이 인상깊었는데요, GAN은 생성모델이라 잘못된 pseudo depth를 생성하는 그런 결과는 없었는지 궁금합니다.
감사합니다.
Q1. 그림(4)의 아래에 있는 depth projection 과정에서 캡션을 보니 다양한 plane에 대한 projection 결과로 보이는데 6개는 어떤 plane을 의미하는지 궁금합니다.
A1. 해당 내용은 Feature Fusion Modules의 W-AdaIn에서 확인 가능하며, 해당 내용 이상의 정보가 따로 없어서 제 뇌피셜로 설명드리도록 하겠습니다. 깊이 정보에서 표현 가능한 min-max 거리 값들을 6등분으로 범위 지정한 값들은 이진화 시킨 맵이라고 보시면 될 것 같습니다.
2. raw depth에서 생기는 hole을 채우는 것을 GAN을 활용하여 pseudo depth을 만들어 학습하는 과정이 인상깊었는데요, GAN은 생성모델이라 잘못된 pseudo depth를 생성하는 그런 결과는 없었는지 궁금합니다.
A. 아쉽게도 해당 논문에서는 failure case를 다루지 않았어요.