이번에 소개드릴 논문은 CMRNext라고 하는 방법론입니다. 논문에서 다루는 task는 Visual Localization and Extrinsic Calibration이라는 task인데 앞에 Visual Localization보다는 Extrinsic Calibration 문제에 대해서 더 관심이 있어 읽어보게 된 논문입니다.
논문에서는 Visual Localization에 대한 얘기도 다루고 실험도 다루긴 하지만, 해당 논문이 제안하는 방법론 자체는 위에 두 task 모두에 적용할 수 있는 방법인지라 본 리뷰에서는 최대한 Extrinsic Calibration 관점에서 다뤄보도록 하겠습니다.
Intro
Lidar는 다양한 로보틱스 분야에서 활용되는 센서로 3차원 환경 정보를 필수적으로 취득해야하는 상황에서 항상 가장 먼저 활용되곤 했습니다. Lidar는 정확한 거리 측정이 가능하다는 명확한 이점이 존재하지만, 가격이 너무 비싸 실제 상용화 관점에서 카메라와 같은 다른 센서들과 비교해 쉽게 활용하기 어렵다는 단점이 존재하죠.
그래서 Lidar를 모델의 학습에만 사용하고 추론 때는 단안 카메라만으로 라이다의 기능을 대신하도록 하는 경우가 종종 있는데 가장 대표적으로는 Depth Estimation이 있겠죠. 또는 Visual Localization의 경우에도 미리 Lidar를 통해 경로에 대한 3D point clouds map을 DB에 저장해놓고, 추론때는 카메라와 DB에 저장된 Lidar를 활용해 위치를 인식하는 방법들도 존재하구요. 이러한 방법들의 핵심은 추론 때는 카메라만을 활용한다는 점에서 시스템 구축 비용이 크게 줄어든다는 점입니다.
아무튼 결국 모델이 영상을 입력으로, Lidar를 GT로 학습을 하든 또는 쿼리 Image와 DB의 Lidar 데이터 간에 매칭을 하든 간에 취득한 영상과 Lidar 사이에 정확한 정합이 맞아야만 합니다. (그림1 참고)

보통은 센서 캘리브레이션을 통해서 RGB와 Lidar 센서 간에 외부파라미터 Rotation|translation을 계산하고 이를 통해 Lidar를 영상 좌표로 투영시키는 방식을 많이들 활용합니다.
하지만 두 센서 간에 동기화가 잘 맞지 않는 경우에는 캘리브레이션으로 아무리 파라미터를 잘 구해도 한계가 존재할 수 있습니다. 그리고 동기화가 잘 맞았다는 가정하에 캘리브레이션을 통해 계산한 외부 파라미터로 정합을 잘 수행할 수 있다고 하더라도 진동, 온도변화, 센서 구성 변경 등으로 인하여 두 센서 사이에 외부파라미터가 변할 수 있으며 이러한 변화를 해결해주기 위해 주기적으로 보정 작업을 반복해주는 것은 상당히 번거로운 작업입니다.
그래서 딥러닝 모델을 이용하여 두 센서 간에 외부 파라미터를 계산하는 Auto Calibration 방법론들이 제안되는 중입니다. 보편적인 딥러닝 기반 방법론들은 주어진 입력 영상과 Lidar map의 표현에 대하여 네트워크에서 곧바로 카메라의 포즈를 계산한다고 합니다.
이러한 방식은 학습 때 사용한 카메라/라이다 구성에 대해서 좋은 결과를 보여줄 수 있으나, 학습 때 사용하지 않은 시스템 세팅에는 올바른 동작을 하지 못할 수 있다고 하네요. 모델이 특정 내부/외부 파라미터에 과적합되기 때문에 동일한 데이터셋이라고 할지라도 카메라 셋업이 달라지면 잘못된 파라미터를 계산한다고 합니다. 즉 네트워크를 통해 곧바로 외부파라미터를 추정하는 행위는 매번 새로운 카메라/라이다 셋업에 대해서 학습을 수행해주어야만 한다는 일반화 성능에 대한 단점이 존재합니다.
따라서 본 논문에서는 센서의 구성 변화와 상관없이 센서 고유 파라미터의 독립적인 Camera-Lidar 매칭 방법론을 제안합니다. 자신들이 제안하는 방법론은 monocular localzation in Lidar-map 뿐만 아니라 카메라-라이다 외부 파라미터 캘리브레이션에서도 사용이 가능하다고 하네요.
특히 metric pose estimation 단계로부터 camera-lidar matching 단계를 분리시켰기 때문에 자신들은 다른 환경과 다른 센서 구성에서도 올바른 pose를 계산할 수 있다고 주장합니다. 이는 CNN 기반 모델로 Camera와 Lidar의 매칭 관계를 먼저 계산하고 이렇게 계산된 매칭쌍들을 PnP-RANSAC이라는 고전적인 방식에 입력으로 외부 파라미터를 계산함으로써, 두 대응 관계만 잘 계산할 수 있다는 가정하에 기존 방법론들이 모델 output으로 pose를 구하는 것과 비교하여 한번도 보지 못한 셋업에서 더 강인한 pose estimation을 할 수 있다는 것이죠.
그럼 더 자세한 내용은 바로 밑에서 다뤄보겠습니다.
Method
그림1에서도 보셨듯이, 본 논문에서 수행하고자 하는 것은 그림1과 같이 Lidar에서 취득한 3D point map과 RGB image 간에 정합을 수행할 수 있는 외부 파라미터를 계산하는 것입니다.
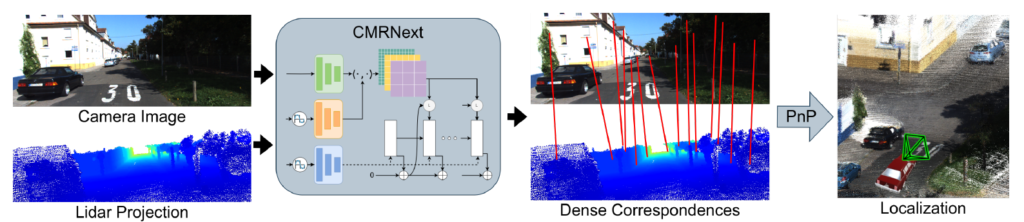
저자들이 제안하는 CMRNext를 통한 Camera-Lidar Calibration의 framework는 그림2를 통해서 확인하실 수 있습니다. 크게 2가지의 step으로 구성이 되어있는데, Camera에서 취득한 RGB image와 Lidar에서 취득한 3D map을 투영시켜서 만든 Depth image를 CMRNext 모델 입력으로 넣어 두 영상 사이에 대응점들을 계산하는 pixel to 3D point matching 단계와 이들 매칭쌍을 PnP 알고리즘을 이용해 pose를 계산하는 Pose Estimation 단계로 나뉘어집니다.
CMRNext는 사실 ECCV2020에서 제안된 RAFT라는 모델을 거의 그대로 활용한 것으로, RGB image와 Lidar projection (Depth image) 사이에 대응관계를 계산하기 위해 optical flow 모델을 사용했다고 이해하시면 될 것 같습니다.
그리고 이렇게 두 영상 간에 대응 관계를 잘 계산하였다면 둘 사이에 pose를 계산하는 것은 PnP RANSAC 알고리즘으로 수행하는 것이기 때문에 이 역시도 논문에서 새롭게 제안한 방식은 아닙니다.
따라서 이 논문에서 가장 큰 핵심적으로 봐야할 부분은 Lidar Porjection image(i.e, Depth map)을 만드는 과정이라고 저는 생각합니다. 방금 위에서 소개드린 것처럼 첫단계의 목표는 올바른 pose를 계산하면 Lidar를 영상에 투영시켰을 때 영상과 정확하게 정합이 맞아야 합니다. 그러기 위해서는 주어진 영상과 Lidar projection 사이에 비정합 상황에서 CNN을 통해 두 입력 사이에 픽셀레벨 offset을 계산하여 둘 사이에 대응 관계를 구해야만 하는데, 이때 모델 입력을 위하여 3D Lidar map을 2D Depth image 형식으로 projection 시켜주어야만 합니다.
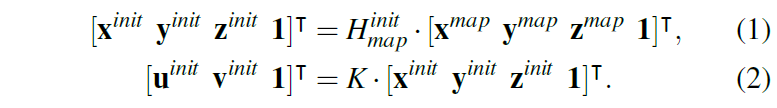
여기서 x^{map}, y^{map}, z^{map} 는 각각 3D point cloud의 x, y ,z 좌표를 의미하며, H^{init}_{map} 는 현재 카메라 프레임에 대한 초기 외부파라미터 [R|t]를 의미합니다. 즉 Lidar sensor를 기준으로 설정된 좌표계에서 현재 영상 프레임에 대한 초기 좌표 설정을 위해 임의의 H^{init}_{map} 를 곱해줌으로써 초기 카메라 좌표계로의 변환을 수행합니다. (init 좌표계라고 표기.)
이렇게 초기 카메라 좌표계로 변환된 3D points (i.e., x^{init}, y^{init}, z^{init} )에 해당 카메라의 내부 파라미터를 적용하여 init image coordinate ( u^{init}, v^{init} )를 생성합니다. (수식2 과정)
즉 수식2과정을 수행하기 위해서는 해당 카메라의 내부 파라미터 K가 필요하게 되며 저자들도 자신들이 제안한 네트워크의 가중치는 특정 카메라에 의존적이지 않지만, 추론 당시에 입력으로 사용할 Lidar를 투영시키고자 내부파라미터를 요구한다고 합니다.
아무튼 여기서 Lidar의 x,y 좌표를 영상 좌표 u, v로 투영시켰기 때문에 u, v에 대응되는 depth 정보도 함께 알고 있다는 가정이 깔리고, 따라서 Lidar projection을 통해 생성한 Depth image는 아래 수식 같이 표현할 수 있습니다.
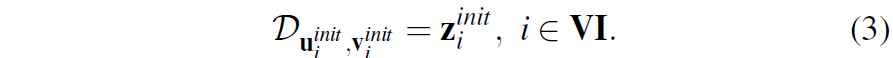
여기서 VI는 3d point map에서 valid point만을 지니는 set이라고 이해하시면 됩니다. 그리고 수식4를 통해 실제 올바른 pose를 적용한 경우의 영상 좌표계도 생성합니다.
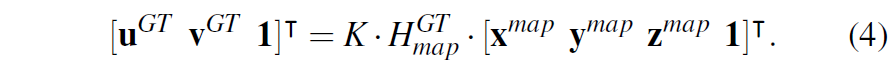
수식4를 통해 생성된 영상 좌표 u^{GT}, v^{GT} 는 초기 좌표 u^{init}, v^{init} 에서 모델의 추론값인 flow map을 통해 도착해야하는 target 지점이라고 생각하시면 됩니다. 이는 반대로 모델의 GT로 사용할 수 있는 flow map은 아래 수식5를 통해서 계산할 수 있게 됩니다.
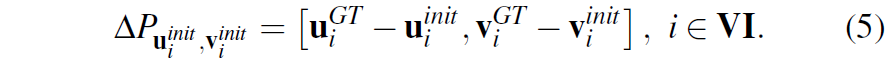
target 좌표와 source 좌표간에 차이를 통해 offset을 계산하는 것이죠. 또한 lidar는 sparse하기 때문에 해당 값들을 영상 좌표계에 투영했을 때 영상 좌표계 전체를 모두 차지하지 못하는데, 이렇게 차지하지 못한 픽셀들에 대해서는 0값으로 처리하고 유효한 픽셀과 그렇지 않은 픽셀을 구분하는 마스크를 아래와 같이 생성하였다고 합니다.
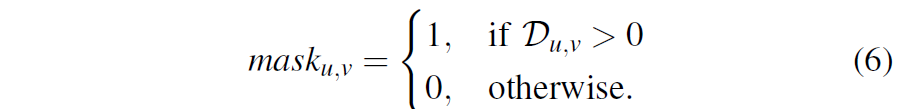
위에 과정을 정리하자면, 데이터셋으로 3D point map이 존재하게 되는데 이때 저희가 원하는 것은 t라는 프레임의 영상 좌표로 정확하게 투영할 수 있는 외부 파라미터 H를 구하는 것이 목적이며, 이때 영상 좌표계와 정합이 일치하지 않은 초기 H^{init} 과 정합이 정확히 일치하는 H^{GT} 외부 파라미터를 통해 각각 source와 target 영상 좌표계를 생성하고 이들 간의 displacement( or offset)을 모델 학습의 GT로 사용한다는 의미입니다.
Occlusion Filtering
위에 Lidar projection과 관련하여 카메라 기하학에 대해 조금 공부하셨더라면 쉽게 이해하실 수 있을거라고 생각합니다. 다만 이론적인 내용과 다르게 3D point map을 영상 좌표계로 단순히 투영시킬 때 발생할 수 있는 문제가 하나 있는데요. 바로 Occlusion과 관련된 내용입니다.

그림3은 occluson filter가 있고 없을 때에 대한 Lidar projection image와 RGB image를 함께 나타낸 그림입니다. 먼저 RGB 영상을 살펴보시면 우측에 제일 가까운 건물에 대한 Lidar point( 파란색)만이 존재해야하지만, 아래 occlusion filter가 적용이 안된 그림을 살펴보시면 저 뒤에 있는 건물에 lidar point (초록색)들이 앞에 건물에 파란색 Lidar point들과 함께 나타나는 것을 볼 수 있습니다.
이는 실제 이미지 상에서는 앞에 건물이 뒤에 건물을 가렸기 때문에 가려진 영역에 대해서는 Lidar point 역시 projection되면 안되지만, 이미 사전에 만들어둔 3D 지도에 대하여 현재 프레임에 대한 투영을 시키다보니 ray 상에 정확히 일치하지 않는 Depth들이 occlusion 영역에 대해서 투영된 것이죠.
아마도 3D map이 없고, 실제 추론 단계에서 Lidar와 카메라를 함께 쓰는 상황이라면 사실 이러한 occlusion 문제가 없을 겁니다. 하지만 Localization과 같이 이미 DB에 3D map이 다 작성되어 있는 상황에서 어떤 frame으로 projection 시킬 때 발생할 수 있는 문제라는 것을 말씀드리고 싶네요.
저자들은 문제를 해결하기 위해 occlusion을 측정하는 필터 기반의 z-buffer technique을 적용하였다고 합니다. 사실 이것도 저자들이 직접 제안한 것은 아니고.. ICVR?이라고 하는 국제 VR 학회에서 2011년에 제안된 “Real-time rendering of massive unstructured raw point clouds using screen-space operators.”라는 논문의 기법을 구현해서 활용했다고 합니다.
위에 occlusion 측정 방식에 대하여 간략하게 소개를 드리면.. 어떠한 중심 3D point P_{i} 가 있을 때 해당 점 기준 k x k 개의 이웃 점들을 P_{j} 라고 합니다. 그러면 P_{i} 와 P_{j} 간에 정규화 벡터 c_{ij} = \frac{P_{j} - P_{i}}{||P_{j} - P_{i}} 를 계산합니다.
그리고 P_{i} 와 카메라의 중심 (핀홀)에 대한 정규화 벡터를 v_{i} 라고 하였을 때 두 벡터 사이에 각도 \alpha_{ij} = v_{i} \dot c_{ij} 를 계산합니다.
저자들은 KxK occlusion kernel을 4개의 섹터로 나누고 각 섹터별로 알파의 최대값들을 계산한다고 합니다. 이때 4개의 섹터의 최대값의 합이 특정 임계치보다 더 크면, 해당 projection point P는 시각화된다고 보는 것이며, 그 반대는 occlusion으로 판단합니다. 음.. 논문에 작성된 소개 내용만으로는 직관적으로 이해하기 어렵네요.. 11년도 논문을 자세히 읽어봐야 해당 기전을 이해할 수 있을 것 같습니다.
아무튼 이러한 occlusion filter를 계산해서 적용하면 그림3의 상단 결과처럼 올바른 필터링을 수행할 수 있다고 하며, 해당 필터 계산은 영상 평면에서 진행되기 때문에 GPU 기반으로 수행이 가능하다고 합니다.
Estimate Pose
다시 프레임워크에 대해서 소개를 드리자면, 지금까지 3D Lidar map을 영상 평면으로 투영시키는 방법, 그리고 초기 포즈와 GT 포즈를 통해 GT flow map을 생성하는 법까지 다루었습니다. 이번 부분은 실제 모델이 학습이 되고 나면, 어떤식으로 외부 pose를 추정할 수 있는지에 대해서 다뤄보겠습니다.
학습된 모델이 Lidar와 Camera 간에 pose를 추정하기 위해서는 먼저 아래와 같은 정보가 주어져야 합니다.
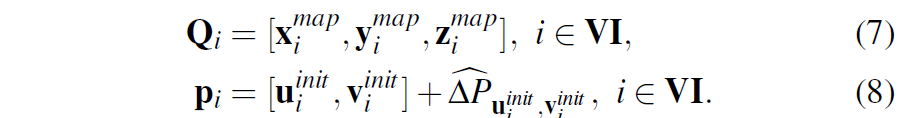
여기서 Q는 Lidar의 3D map을 의미하고, p는 RGB와 Lidar projection image 간의 matching points들을 의미합니다. 여기서 offset값인 \delta P_{u^{init}_{i}, v^{init}_{i}} 는 모델이 projection lidar와 image를 입력으로 하여 추론한 결과값이죠.
그럼 이제 해당 Q와 p값을 토대로 두 센서간에 외부 파라미터를 아래와 같이 계산할 수 있습니다.
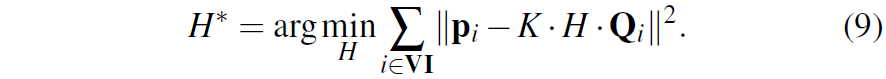
여기서 K는 카메라의 내부 파라미터, H는 pose 값으로 reprojection error값을 최소한으로 하는 H가 저희가 구하고자 하는 최종 결과값입니다. 이때 p혹은 Q 등에 outlier 등이 존재하게 되면 MSE로 근사화하는 방식이 잘 동작하지 않기 때문에 outlier에 강인한 추정을 위하여 RANSAC을 같이 활용했다고 보시면 됩니다.
Network Architecture
다음은 네트워크 구조에 대해서 살펴보겠습니다. 저자들이 제안하는 CMRNext 모델은 optical flow의 근본 방법론인 RAFT 모델을 수정하여 만들었는데, 크게 feature encoder, context encoder, multi-scale cost volume 그리고 iterative flow refinement라는 4개의 모듈로 구성이 됩니다.
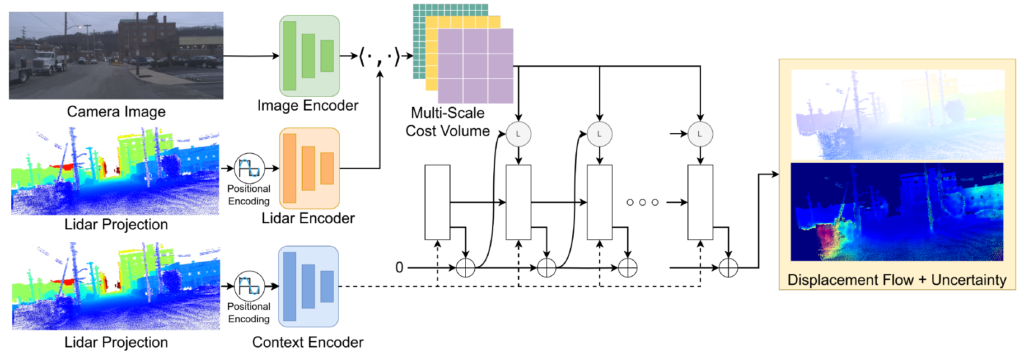
근데 사실 말이 기존 모델에 수정을 가한 것이지 제가 보았을 땐 거의 RAFT 모든 구성을 다 따랐다고 보셔도 됩니다. Image Encoder는 6개의 residual block 연산을 수행하는데 1/8 해상도의 feature map을 추출한다고 하며, 그림4에 Lidar Encoder, Context Encoder도 Image Encoder와 동일한 네트워크 구조를 지니고 있습니다.
한가지 차이점으로, Fourier feature라는 것이 coordinate 기반의 DNN이 고주파 함수를 학습하는데 도움이 된다는 이전 연구에 영감을 받아 저자들도 Fourier feature mapping module이라는 것을 맨 처음에 붙였다고 합니다. Fourier feature mapping이라는 이름이 붙었다고해서 막 어려운 개념은 아니고 그냥 Transformer나 NERF에서 많이들 사용하는 positional encoding의 개념으로 보시면 됩니다.
이렇게 Encoder를 통해 영상과 Lidar에 대한 feature map을 잘 추출하였다면, Lidar feature와 Image feature 간에 내적 연산을 통하여 cost volume을 생성합니다. 각각의 feature map이 H/8 x W/8 x D 였기 때문에 이를 내적하면 코스트 볼륨의 shape은 H/8 x W/8 x H/8 x W/8 꼴로 구성이 됩니다.
그리고 해당 cost volume에 다운샘플링 연산을 적용하여 1, 2, 4, 8의 multi-scale cost volume을 제작하며, 이러한 cost volume들은 GRU 기반의 Decoder에 입력으로 들어가 flow map을 생성하게 됩니다. 사실 이러한 과정은 RAFT의 구조를 그대로 따라한 것이기 때문에, 네트워크의 자세한 동작 과정이 궁금하신 분들은 제가 예전에 작성한 RAFT 리뷰를 참고하시면 좋겠습니다.
Loss function
Loss function은 RAFT에서 사용하는 방식과 동일하게 negative log-likelihood loss를 이용합니다.
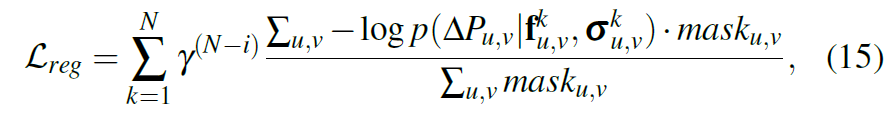
여기서 mask는 valid pixel만을 계산하는 마스크로 수식6에서 계산한거구 delta P는 수식5에서 계산한 GT 결과입니다.
Experiments
실험 섹션 소개드리고 리뷰 마치도록 하겠습니다. 가장 먼저 아래 표를 살펴보시면 KITTI ODOMETRY Dataset에서의 Lidar-Camera 외부 파라미터 캘리브레이션에 대한 결과를 확인하실 수 있습니다.
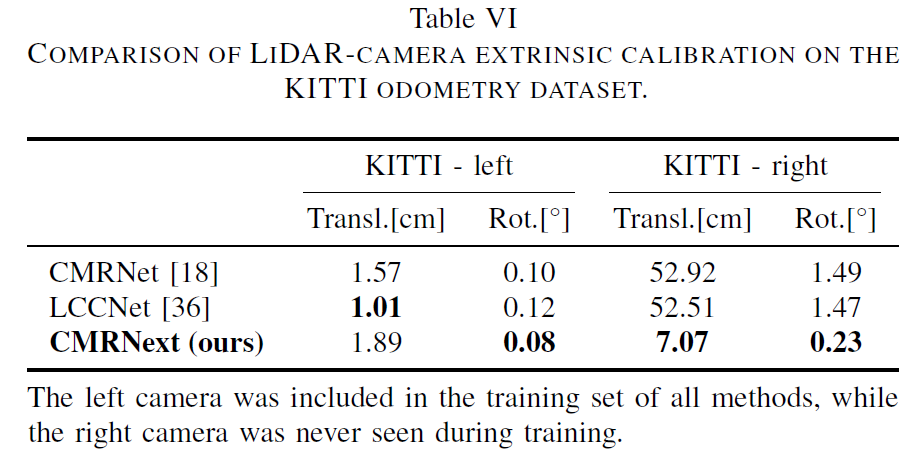
Rotation과 Translation에 대한 GT와 예측 값 사이에 오차를 나타낸 것으로, 값이 작으면 작을수록 좋은 것입니다. 지금 모든 방법론들의 학습 세팅이 왼쪽 카메라와 Lidar 사이에 정합을 맞추도록 학습을 진행한 것이기 때문에 3가지 방법론들 모두 1cm 수준의 translation 오차를 보여주고 있습니다.
그리고 저자들이 제안하는 방법론이 나머지 두 방법론들보다 Translation 정확도가 가장 나쁜 것으로 보여지지만, 우측 카메라와 Lidar 사이에 캘리브레이션 오차 결과를 살펴보면 나머지 두 방법론들은 완전히 잘못된 캘리브레이션 결과값을 보여주는 것을 확인할 수 있습니다.
반대로 저자들이 제안하는 방식은 대응 관계를 잘 계산해두면 pose를 구하는 행위 자체는 PnP RANSAC 알고리즘으로 계산하기 때문에 타 방법론들과 비교하여 더 준수한 성능을 보여준다고 합니다. 그래도 translation이 7cm 정도의 오차가 있는 것으로 보았을 때 정확한 캘리브레이션을 하고 있다 라고 보기는 어려울 것 같긴 합니다.
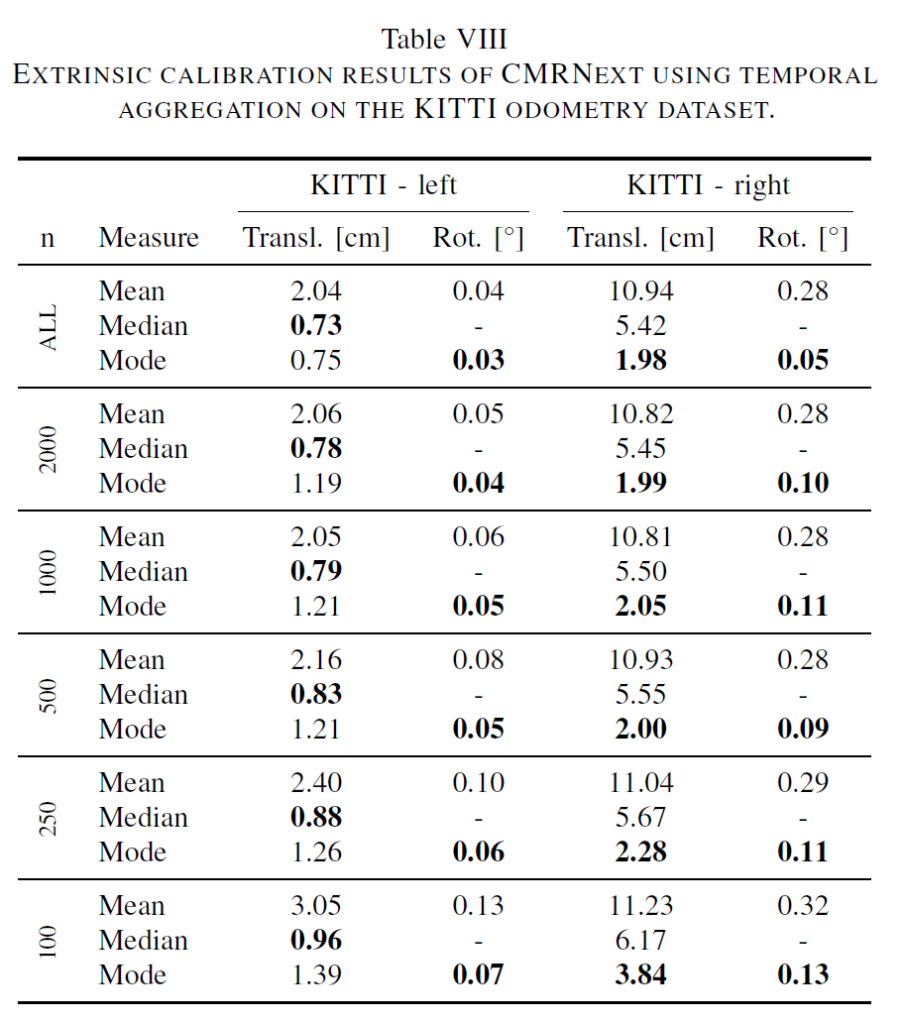
위에 표는 동일한 KITTI ODOMETRY Dataset에서의 평가이지만, 첫번째 표와는 다르게 temporal 정보를 활용하여 추론한 결과값을 의미합니다. temporal 정보라 함은 저자들 주장에 따르면 하나의 sequence에 대해서는 센서의 구성이 크게 바뀌는 일이 없을 것이기 때문에 모델이 매 sequence마다 추론한 Calibration 값들을 통합하자는 것을 의미합니다.
그래서 표 좌측에 n이라고 적힌 부분이 n개의 frame에 대한 모델의 추론 값을 합친 것을 의미하는데, 이때 합치는 방식으로는 크게 Mean, Median, Mode라는 3가지 방식을 사용했다고 합니다.
결론부터 말씀드리면 Mean으로 하는 경우보다는 median 값을 활용하는 경우가 성능이 항상 더 좋았지만, 대신 학습 때 보지 못한 센서 구성 (즉 Right Camera & Lidar)의 경우에는 median의 성능 보다 Mode 방식으로 취합하는게 가장 좋은 성능을 보여주었다고 합니다.
해당 실험을 보고 느낀 의문은 Mode라고 함은 최빈값을 의미하는데, 캘리브레이션의 R|T의 값은 이산적인 값이 아니라 연속적인 값이라 어떻게 최빈값을 계산하였는지 잘 모르겠네요. 논문에서 디테일하게 설명하지 않고 최빈값의 경우 그냥 Rotation과 Translation을 각각 소수점 4자리, 2자리에 대하여 반올림을 진행하였다고만 하는데.. 무작정 히스토그램 계산 함수를 사용했는지 잘 모르겠네요.
아무튼 매번 구하는 것보다는 여러 프레임에서 계산한 결과값의 통계적인 누적 값을 사용하는 것이 성능에 더 좋았다라는 실험이지만, 사실 해당 실험도 조금 애매하긴 합니다. 지금은 평가 환경이니깐 매 프레임마다 결과를 다 뽑아놓고 그 다음에 저자 입맛에 맞추어 결과값들을 합친 것 같은데, 실제 inference 상황을 고려해보면 자신이 추론하는 환경에 대해 미리 inference를 해보지 못하기 때문이죠. (즉 미래 상황에 대한 추론 값을 미리 뽑아두지 못함.)
그래서 제가 생각했을 때 위에 실험을 진행하려면 t번째 frame에 대한 평가를 진행할 때 1~t까지의 frame에서 뽑은 결과값을 평균하거나 median 하는 식으로 평가를 진행해야 하지 않았나 싶습니다.
Ablation Study
다음은 Ablation study에 대해서 살펴보겠습니다.
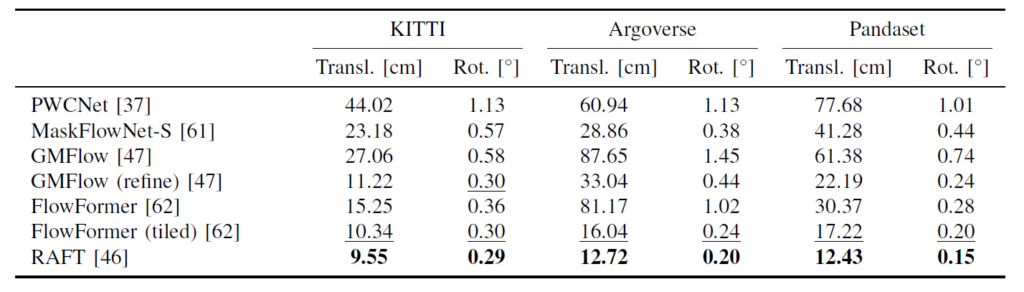
위에 표는 optical flow 방법론들에 대한 localization 결과값들입니다. Method 파트에서 소개드렸다시피 저자들은 RAFT라고 하는 20년도 optical flow 방법론의 구조를 거의 그대로 사용한다고 말씀드렸습니다. 근데 지금이 24년도이긴 하니 RAFT 이후에도 사실 더 좋은 optical flow 방법론들이 꾸준히 제안되어왔었죠. 대표적으로 GMFlow나 FLowFormer같은 경우에는 RAFT와 비교하였을 때 optical flow에서는 상당히 큰 성능 향상 폭을 보여주고 있는 방법론들입니다.
하지만 Localization 관점에서는 저자들이 평가하기로 GMFlow나 FLowFormer보다 RAFT가 더 좋은 성능을 보여주었다고 합니다. 왜 이쪽에서는 성능이 안좋은지..에 대해서 잘 모르겠네요. 혹시나 scratch 레벨에서부터 저 모델을 학습시켰다면 RAFT가 더 좋을 수도 있을 것 같은게, FlowFormer나 GMFlow는 모두 Transformer 기반 방법론들이어서 학습 데이터의 수가 많을수록 더 좋은 결과를 보여주긴 할 것 같습니다.
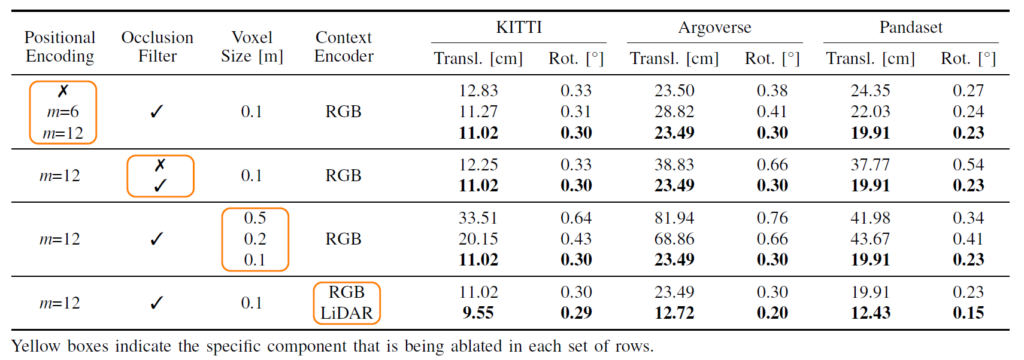
위에 표는 GMNext모델에 대한 ablation study인데, 먼저 Positonal Encoding을 적용하는 것이 더 좋은 성능을 보여준다는 점이며 m=6, m=12 각각이 Fourier frequencies가 6개인지 12개인지를 나타내는 변수 값이라고 합니다.
그리고 occlusion filter를 사용하는 것이 localization 성능에 더 좋다라는 것을 보여주고 있는데, 사실 지금 평가 방식이 Localization이다보니 occlusion filter가 유의미한 것이지 제가 관심있어 하는 Lidar-Camera Calibaration 관점에서는 occlsuion filter가 사용될 필요가 없다고 보시면 됩니다. (시간 동기화가 맞다는 가정하에 occlsuion이 올바르게 나타남.)
Voxel Size는 Lidar projection을 시키기 전에 3D map을 Voxel화 시키는 과정을 의미합니다. 여기서도 사이즈를 작게 할수록 localization 성능이 더 크게 오르는 것을 확인할 수 있습니다.
그리고 Context Encoder의 경우에는 RGB 영상과 Lidar 영상 각각에 대해여 실험을 진행해보았는데 저자들 주장에 따르면 Lidar에 적용하는 것이 가장 좋은 성능을 보여주었다고 합니다. 근데 RGB랑 Lidar 모두한테 Context ENcoder를 적용한다던지, 혹은 Context Encoder를 전혀 사용하지 않았을 때의 성능을 보여주지 않은 것은 조금 아쉽네요.
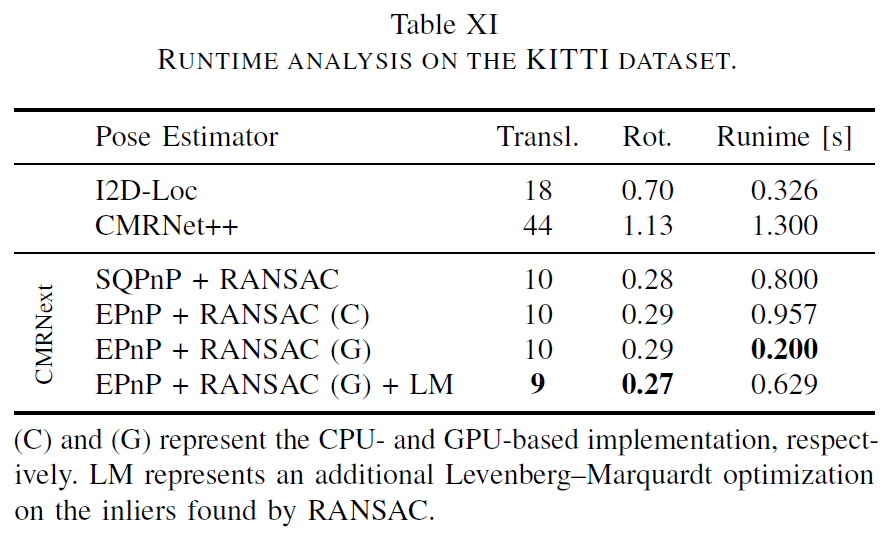
마지막으로 추론 속도에 대한 결과입니다. RTX 2080 Ti에서 평가한 것으로 자신들이 다른 방법론들과 비교하여 더 빠른 속도를 지니고 있다~라는 식으로 주장을 하고는 있습니다만, 왜 I2D-Loc와 CMRNet++랑만 비교하는지 모르겠네요. 분명 다른 표에서는 CMRNet, LCCNet 등 여러 방법론들의 성능을 보여주었음에도 불구하고 속도 테이블에서는 빠진 이유가 혹여나 그 방법론들이 더 빠르기 때문이 아닐까 라는 생각도 듭니다.
그리고 사실 저 위에 표에서는 자신들이 가장 빠르다는 식으로 보여주었지만 0.2 s인거면 초당 5FPS를 처리한다는 것인데 외부 파라미터를 calibration하는 가장 첫번째 전처리 단계에서 저렇게 느리다는 것은 조금 문제가 아닌가 라는 생각이 듭니다.
결론
이 논문이 아직 arxiv에만 올라온 논문이라서 그런지 오타도 조금씩 있고 저자가 지칭하는 figure와 실제 figure가 다르다는 등 논문에 오류가 제법 존재합니다. 그리고 제안하는 방법론 자체나 실험적인 부분들 역시 제가 생각했을 때는 설득력이 좋다고 보기는 어려워서.. 이 논문이 어디에 붙을지 잘 모르겠네요.