이번에도 unseen object pose estimation 리뷰입니다.
전체적인 흐름은 unseen pose estimation 리뷰들과 비슷하지만, 차이점은 CNOS를 detector로 사용한다는 점과 DINOv2를 BoW의 형태로 representation 한다는 점이 큰 차이점입니다. refinement를 새롭게 제안을 하였으나, 마지막 실험에서 2년전에 나온 MegaPose의 refiner에 비해 성능 향상이 적어 조금 아쉬웠던 논문이었습니다.
리뷰 시작하겠습니다.
Introduction
이미지 기반의 물체에 대한 6D pose estimation은 공간 AI 분야에서 중요한 연구인데요. 예를 들어, 로봇 공학에서는 물체의 pose에 대한 정보를 통해 로봇이 물체를 조작할 수 있으므로 물류 창고 운영이나 조립을 위한 automatic한 해결책을 제시할 수도 있겠네요. Mixed Reality(MR)와 같이 어플리케이션에서의 해당 정보는 컴퓨터 키보드와 같은 실제 물체를 가상 공간에서 만든 것과 물리적 상호 작용을 가능하게 하여 텍스트 입력도 가능하도록 하는 애플의 비전 프로와 같이 제품을 생각해보면 좀 더 이해하기 쉬울 것이라고 생각합니다.
이번 FoundPose에서도 unseen 물체에 대한 6D pose estimation을 수행하는데요. 대상 물체에 대한 3D 모델을 사용할 수 있고, onboarding을 위한 cost가 제한이 되어 있다고 가정합니다. 이러한 가정은 large-scale의 데이터셋을 렌더링하고 신경망을 학습하기에는 충분하지 않은 상황을 제시하는 것으로 볼 수 있습니다. 이와 같은 제약적인 상황에서는 효율적인 onboarding 과정이 중요하겠네요.
일반적으로 novel 물체에 대한 인스턴스나 카테고리에 대해 많은 수의 학습 이미지와 긴 학습 과정이 필요하기 때문에 일반화 능력은 제한적이었는데요. 따라서, 이러한 방법의 대부분은 적은 물체 인스턴스 또는 카테고리에 초점을 맞추고 있습니다. 최근에는 seen object pose estimation(instance-level)의 정확도가 이제 saturation된 상태에 이르면서 6D pose estimation 분야는 다시 unseen object에 초점을 맞추기 시작하였습니다. 이번 FoundPose 또한 unseen 물체에 대한 pose estimation을 수행하기 위한 모델입니다.
이번 논문의 contribution은 다음과 같습니다.
- unseen object pose estimation을 위한 별도의 학습 없이 BOP challenge에서 뛰어난 성능을 보임
- DINOv2를 통한 patch descriptor를 이용하여 빠른 template retrieval은 강인한 2D-3D correspondecne를 생성함
- template-based object representation은 생성 속도가 빠르고 pose estimation에 효과적으로 사용할 수 있으며 저장 또한 효율적으로 가능함
- coarse pose를 개선하는 새로운 refinement를 적용하여 MegaPose의 refinement와 함께 사용하는 경우 더욱 효과적인 결과를 보임
FoundPose

Template-based object representation
Template generation
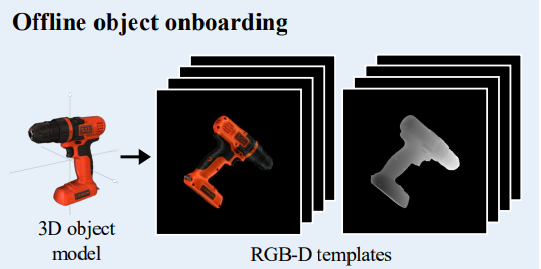
먼저, 사전에 template을 생성하는 과정입니다. 이전 리뷰에서 다루었던 방법론들과 크게 다르지 않는데요. 3D CAD 모델이 주어졌을 때, RGB-D를 가지는 template을 생성하는 렌더링 과정을 거칩니다. 다양한 방향으로 구성하며 해당 방향은 선행 연구 결과를 통해 uniform한 분포를 가지도록 샘플링 되었으며 이는 rotation에 커버하도록 합니다. 또한, 생성될때는 검은 배경과 고정된 조명을 가지도록 하는 standard rasterization technique을 사용하였다고 하네요. 레퍼런스를 보니 OpenGL 라이브러리를 이용한 것으로 보입니다.
Patch descriptors registered in 3D
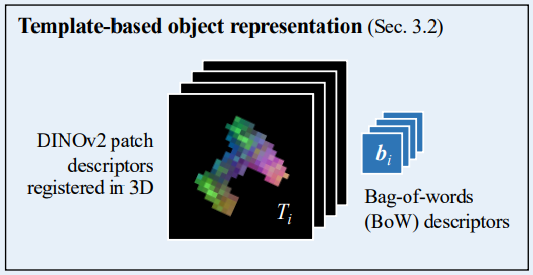
생성된 template들을 어떻게 representation을 할 것인지에 대한 과정인데요. 결론부터 말씀드리자면 DINOv2를 이용하여 descriptor를 생성하였습니다. 좀 더 구체적으로 살펴보면, DINO는 ViT backbone을 사용하므로 patch-wise descriptor가 추출되게 됩니다. 해당 patch descriptor는 DINOv2에서 추출된 patch descriptor입니다. 저희가 사용하게 되는 descriptor는 n개의 template의 유효한 patch descriptor에서 계산된 상위 d개를 PCA의 compoent에 projection하여 차원 축소를 적용하여 사용합니다. template의 depth 채널과 intrinsic parameter로 계산되는 3D 위치는 이후 수행되는 2D-3D correspondence를 설정할 수 있도록 해주는 역할을 하게 됩니다.
Bag-of-words descriptors
이전 방법론들과 또 다른 차이점을 보이는 것은 뽑은 descriptor를 Bag-of-words(BoW)를 이용한 image retrieval 방법론을 적용한다는 점인데요. inference 할 때 효율적으로 template retrieval이 가능하도록 하는 것을 목표로 하여 모든 template의 BoW descriptor를 사전에 계산해놓습니다. 유사한 특징들은 onboarding 과정에서 각 template에 대한 clustering을 수행하고 쿼리 이미지가 주어졌을 때 distance를 계산하여 매칭하기 위한 과정으로 이해하시면 되겠습니다. 즉, visual words를 물체의 모든 template에서 추출한 patch descriptor의 k-means cluster들에 대한 중심점으로 정의하는 것입니다.
Template retrieval by bag-of-words matching
Perspective cropping
이번 FoundPose는 이전에 리뷰한 CNOS를 detector로 사용하게 되는데요. inference할 때는 이전의 방법론들과 동일하게 물체가 존재하는 RoI 영역에 대해 segmentation mask를 필요로 합니다. 따라서, 해당 영역에 대한 crop 과정이 필요한데요. 쿼리 이미지가 들어왔을 때, 해당 이미지가 생성된 template과 유사한 crop을 얻기 위해 bbox을 기준으로 S \times S의 크기를 가지도록 하며, 대부분의 bbox는 정사각형 보다는 직사각형의 형태가 많을 것입니다. 따라서, 장축을 기준으로하여 S를 구성합니다. 그리고 위 그림(2)을 보시면 쿼리 이미지로부터 RoI를 뽑아서 나온 결과를 보면 정확히 물체에 대한 bbox를 사용하는 것이 아니라, 넓은 영역의 이미지를 사용하는 것을 확인할 수 있는데, 이는 생성된 template과의 크기를 맞춰주기 위해 \delta라는 값을 곱해주어 조정을 해주게 됩니다.
Retrieving similar templates

입력으로 들어온 쿼리 이미지로부터 이제 생성된 template들과 유사한 것을 찾는 과정인데요. 이는, 이전 과정에서 적용된 BoW가 적용된 template들과 매칭을 해야 합니다. maching을 위한 유사도 측정은 코사인 유사도를 사용합니다. 코사인 유사도가 가장 높은 h개의 template를 선택하여 물체에 대한 coarse한 pose 정보를 주도록 설계한 것인데요. 쉽게 말하면 대략적인 pose 정보를 주고 pose estimator 과정에서 좀 더 refine을 하자는 의미입니다. 이러한 retrieval 방법론을 사용하면 좀 더 부분적인 occlusion에 강인하고 효율적으로도 상당히 좋다고 하네요.
BoW descriptor 같은 경우, 이미지에 대해 추가적으로 순서가 정의되지 않은채로 representation하는 것이기 때문에 일반적으로 spatial verifivcation stage(공간적 검증 단계)를 거치게 되면 retrieval에 대한 성능을 개선할 수 있지만, 이번 FoundPose의 경우, PnP-RANSAC을 적용하게 되므로 암시적으로 유사한 검증이 수행되긴 하나 BoW가 구성되는 DINOv2 layer에서 사용된 patch descriptor가 2차원의 위치 정보만을 가지므로 순서를 정렬하기에는 부족하다는 의미입니다.
Pose estimation from 2D-3D correspondences

Crop-to-template patch matching

retrieval된 각 template과 patch descriptor(쿼리 이미지)와의 가장 가까운 거리에 있는 descriptor와 2D-3D correspondence를 생성하는 과정을 거치게 됩니다. 이러한 crop-to-template patch mathcing을 통해 2D-3D correspondence를 설정하는 것은 모든 template의 patch descriptor에 대해 일일이 매칭하는 것보다 훨씬 효율적인 방법입니다. 또한 template-based 방법론의 경우 일반적으로 비대칭 물체, 텍스처가 부족한 물체와 같이 challenge한 상황이 발생해도 어느정도 물체에 대해 대처가 가능하므로 효과적인 것을 보여주네요. 즉, 2D-3D correspondence에 대한 모호성을 candidate descriptor들을 single descriptor로 제한하여 semantic한 정보와 2D 위치 정보를 모두 포함하는 DINOv2의 중간 layer에서 patch descriptor를 사용하므로 제거할 수 있게 됩니다. 해당 위치 정보는 대칭이나 텍스처 부족으로 인한 semantic 정보가 차이가 없을 때 기하학적으로 일관성 있는 correspondence를 생성하는 데에 핵심적인 역할을 수행하게 됩니다. 이전 섹션에서 설명드린 순서를 정렬하는 과정에 있어 이러한 correspondence를 생성하면서 2차원의 위치 정보뿐만 아니라 공간적 정보(기하학적 요소)를 고려할 수 있다고 보시면 되겠습니다. 실험을 통해 FoundPose에 DINOv2를 적용하였을 때 layer 18을 사용하는 것이 positional과 semantic 정보를 가지는 것에 가장 적합한 것으로 사용하였습니다.
Pose fitting
coarse pose estimation을 과정입니다.
물체에 대한 pose는 이전에 생성된 2D-3D correspondence를 이용하여 추정할 수 있는데요. 2D-3D correspondence를 생성하는 과정은 PnP(Perspective-n-Point) 알고리즘을 통해 해결할 수 있으며 RANSAC을 통해 outlier를 제거하여 pose를 추정하게 됩니다. PnP 알고리즘을 적용하기 위해 최소 n=3부터 설정할 수 있는데, 저자는 무작위로 4개의 correspodences를 사용하여 pose hypothesis로 사용하였다고 합니다.
Featuremetric pose refinement
Featuremetric alignment

마지막으로 coase pose를 refinement하는 과정입니다.
coarse pose(R_{c}, t_{c})는 반복적인 비선형 최적화 알고리즘인 Levenberg-Marquardt(LM)을 적용하여 refinement를 적용하였다고 합니다. 즉 어떤 cost function이 주어졌을 때 이를 최적화하는 파라미터 값을 찾기 위한 과정이라고만 이해하였습니다. 즉, Featuremetric error를 최소화 하는 pose를 얻는 것이 목표입니다.

위 식과 같이 refinement pose를 얻는 최적화 과정을 거칩니다. cost function은 \rho를 의미하며 [1]에서 제안된 강인한 cost function으로 설명하네요. notation을 좀 더 살펴보면, (\mathbf p_{i}, \mathbf x_{i})는 각각 descriptor와 correspondence로 생성된 patch i에 대한 3차원 위치, \pi는 2D projection을 의미합니다. \mathbf F_{q}는 feature map을 의미하는데, 해당 feature map의 크기는 a \times a \times d을 가지며, d는 쿼리 이미지의 descriptor를 스택하여 얻게 됩니다. 해당 내용을 이해하는 것이 꽤 어려웠는데, 제가 이해한 것으로는 쿼리 이미지의 descriptor를 반복적인 과정을 통한 결과들을 스택을 시킨다고 이해를 했습니다. a=S/s를 의미하는데, S는 이전에 설명했던대로 template resolution == RoI 영역에 대한 crop 영역에 대한 resolution(=patch descriptor)입니다. s는 ViT에 사용되는 patch의 크기를 의미합니다. 저자는 featuremetric alignment 관련 논문에서 사용되었으며, LM을 위해 학습된 feature와 사용되었으므로, 추가적인 학습없이 DINOv2 feature에 최적화를 적용하였다고 합니다.
[1] Jonathan T. Barron. A general and adaptive robust loss function. CVPR, 2019
Reducing 2D-3D discrepancy
2D-3D correspondence는 2D patch의 중심에 의해 주어진 쿼리 이미지의 규칙적인 grid에서 추출된 patch descriptor와 매칭시켜 설정하게 되는데요. 하지만 coarse sample들은 매칭된 patch의 중심이 동일한 3D 포인트의 2D projection 결과와 align이 안 맞을 수도 있습니다. 이러한 결과는 pose estimation의 정확도를 떨어뜨리는 원인이 됩니다. 이를 potential discrepancy라고 하며 해당 문제를 해결하기 위해 쿼리 이미지에서 최적의 위치에 template patch를 align을 맞춰주어 pose estimation을 좀 더 용이하게 합니다. 해당 과정에 대한 설명이 전혀 없어 어떻게 했다는 것인지 알 수가 없어 아쉽네요.
Experiments
Experimental setup
Evaluation protocol
AR=(AR_{VSD}+AR_{MSSD}+AR_{MSPD})/3 – 이승현 연구원님 리뷰(평가지표 섹션 참고)
Datasets
BOP challenge에서 사용되는 7개의 코어 데이터셋(LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB, YCB-V)를 사용합니다.
Main Results
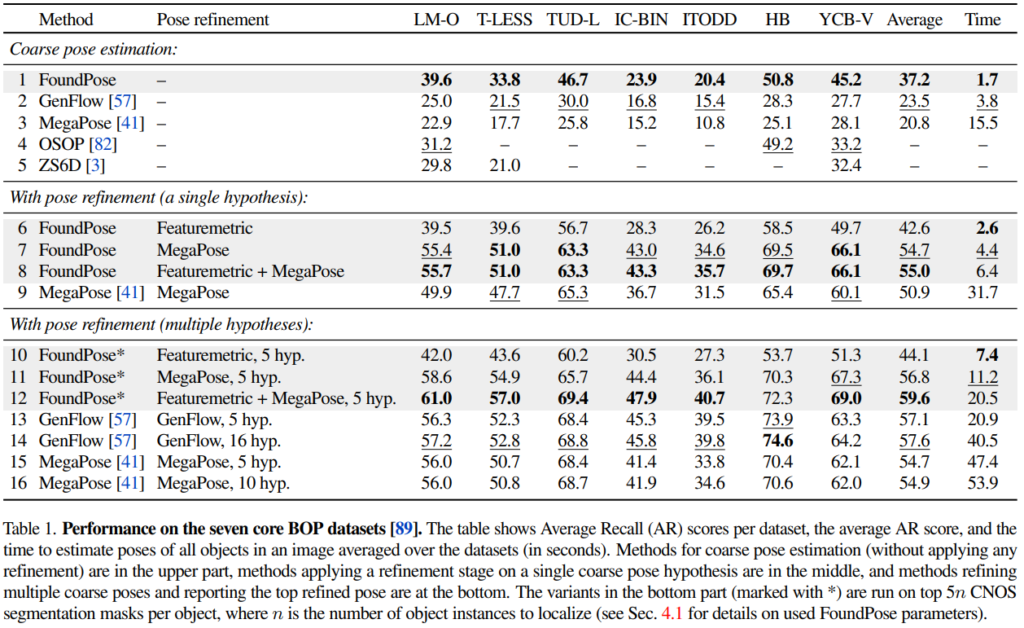
Accuracy
표(1)의 1-5행과 같이 refinement 과정을 적용하지 않는 과정 중, FoundPose는 다른 모델들 보다 전체적으로 우수한 성능을 보이고 있습니다. 6행과 같이 제안한 refinement 과정을 적용하게 되면 LM-O를 제외한 모든 데이터셋에서 우수한 성능을 보이고 있습니다. 7행을 통해 MegaPose에서 사용하는 refiner를 같이 사용하면 좀 더 좋은 결과를 보여주는 것을 확인할 수 있으나, 후속 연구에도 불구하고 MegaPose의 refiner보다는 우세하지 못한점이 아쉬운 것 같습니다.
Speed
표(1)의 1, 6, 10행을 보았을 때 refinement 과정을 수행하게 되면 그만큼 속도가 느려지긴 하지만 기존의 방법론들보다 FoundPose가 우세한 것을 확인할 수 있습니다.
Ablation experiments
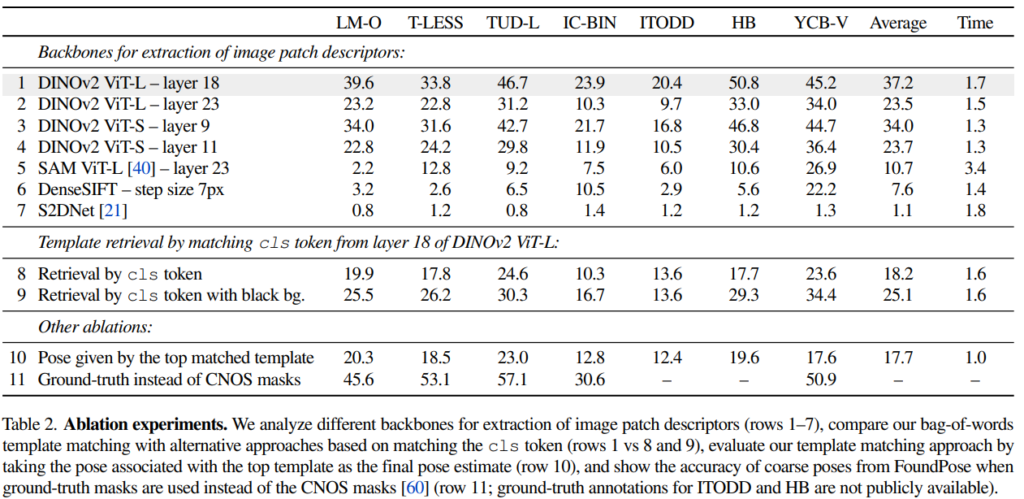
Feature extractors
표(2)는 다양한 patch descriptor를 사용한 FoundPose의 성능을 평가하는데요. 이때 refinement 과정은 제외하고 측정합니다. Crop-to-template patch matching 섹션에서 layer 18을 사용하였을 때가 가장 좋은 성능을 보였다고 말씀을 드렸었는데, 이에 대한 실험 결과를 바탕으로 하였습니다. 해당 실험 결과는 location 정보와 semantic 정보 간의 적절한 밸런스를 가지면서 제공한다는 것을 정량적 결과를 통해 증명을 하네요.
Template retrieval
계속해서 표(2)의 8-9행을 보시면, BoW template retrieval을 DINOv2의 cls token 매칭을 기반으로 할 때 배경을 어떻게 주는지에 따른 결과를 보여줍니다. cls token이 배경에 대한 영향을 피하기 위해 물체에 대한 mask 외의 픽셀은 모두 검은색으로 하도록 설계를 하는 게 성능이 좀 더 좋은 것을 확인할 수 있습니다.
BoW로 retrieval된 template에 대한 성능을 분석하기 위해 가장 많이 retrieval된 template과 관련된 물체에 대한 pose를 평가합니다. 이는 성능 면으로는 크게 좋진 않지만 MegaPose에 비해 15배 빠른 결과를 보였다고 하네요.
Ground-truth segmentation masks
결국 성능이 잘 안나오는 원인은 segmentation의 결과인데요. CNOS에서 예측한 mask를 사용하는 것이 아니라 GT를 사용하게 되면 더 좋은 결과를 보여주므로 1행과 11행을 비교하는데 제가 보기에는 GT를 사용하는 것에도 불구하고 드라마틱한 성능 개선을 이루지 못한 게 의문이네요.
Conclusion
Unseen object에 대한 pose estimation을 수행하는 FoundPose는 DINOv2를 이용하여 고전적인 컴퓨터 비전의 방법론을 좀 더 효과적으로 사용할 수 있는 파이프라인을 제공하였습니다. 또한, 2D-3D correspondence를 생성하는 이후 과정을 단순화하는 BoW template retrieval을 통해 계산적으로도 효율적인 모습을 보여주었습니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
n개의 template에 대해 각각 descriptors를 생성한 뒤, 그 중 상위 d개의 descriptors를 선별하였다는 것으로 이해하였습니다. 제가 이해한 것이 맞나요? 그렇다면 어떤 것을 기준으로 d개의 descriptor를 선별하는 지도 궁금합니다.
또한 Featuremetric alignment 과정을 통해 최종 pose를 구하는 것으로 이해하였는데, 해당 과정은 결국 template의 pose와 query 이미지의 상대적 차이의 pose를 구하는 것인지, 아니면 단순히 GT와 query를 비교하는 것인 지 궁금합니다.