안녕하세요, 오늘의 X-Review는 22년도 AAAI에 게재된 논문 <Weakly Supervised Video Moment Localization with Contrastive Negative Sample Mining>입니다. Video Localization 관련된 논문에 북경대 Yang Liu 교수님이 굉장히 자주 보이네요. 교수님 때문에 읽은 것은 아니고, 현재 작업중인 ACM MM 논문의 Weakly supervised Temporal Action Localization(WTAL) task에서 활용중인 text 정보를 weakly-supervised 상황에서 어떻게 효과적으로 이용할 수 있을지에 대한 아이디어를 얻고자 읽었습니다. 22년도 방법론이다보니 그리 복잡하지는 않고, 오히려 간단한 모델링으로 temporal annotation이 없는 상황에서 당시 좋은 성능을 기록한 논문입니다.

리뷰 바로 시작하겠습니다.
1. Introduction
Weakly-supervised 상황에서의 grounding은 기존에 제가 리뷰하던 Weakly-supervised Temporal Action Localization task와 유사하게 temporal annotation 없이 수행됩니다. 비디오 내 특정 구간에 대한 텍스트 쿼리가 주어지지만, 그 ‘특정 구간’이 어디인지는 모르는 채로 학습을 진행하고 테스트 시 주어지는 텍스트 쿼리에 상응하는 구간을 잘 찾는 것이 목적입니다. Weakly-supervised 기반의 grounding 논문을 많이 읽은 것은 아니지만 연구의 발전 흐름이 WTAL과 비슷하거나 반 발짝 늦게 따라오는 듯한 느낌이 좀 있네요. WTAL 연구에서도 구간을 모르니 하나의 포인트를 기준으로 가우시안 마스크를 proposal 삼아 학습하는 연구들이 있는데 본 연구도 유사한 방법론을 제안했다고 보시면 됩니다.
이제 저자가 이야기하는 기존 WS grounding 방법론들의 두 가지 문제점을 알아보겠습니다. 이전에 연구된 방법론들을 보면 비디오를 작은 단위(보통은 16프레임)인 segment 수준에서의 contrastive learning을 통해 쿼리에 상응하는 구간과 상응하지 않는 구간의 표현력을 분리하려는 시도들이 많이 있었습니다. 이를 위해 positive pair와 negative pair를 당연히 정해주어야겠죠. Grounding은 어디까지나 localization task로 하나의 untrimmed video 내 특정 구간을 다시 좁혀내야 하는 task입니다. 하지만 기존 방법론들은 contrastive learning을 수행할 때 negative pair를 단순히 배치 내 다른 비디오에서 가져왔다고 합니다.
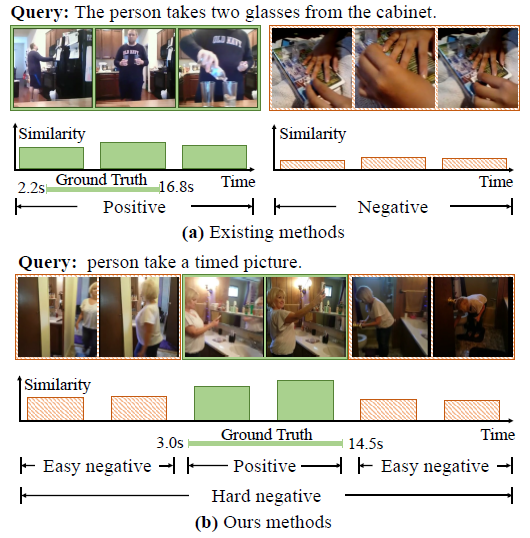
그림 1-(a)를 보시면 weakly-supervised이기 때문에, 비디오 내부 두드러지는 구간을 활용하는 방식 대신 특정 쿼리에 대해 현재 pair로 지정되어있는 비디오의 모든 segment를 초록색인 positive로 지정되어있고, 배치 내 다른 쿼리와 매칭되어있는 비디오의 전체 segment가 붉은색으로, 즉 negative로 지정되고 학습에 사용되는 모습입니다. 이러한 방식의 contrastive learning은 당연히 모델이 정답에 가까운 구간을 만들어 내는데에 큰 도움을 주지 못합니다. 앞서 말씀드렸듯 모델은 전체 비디오에서 특정 구간을 좁혀내야 하는데, 개인적으로 생각했을 때, 특히나 temporal annotation이 없는 상황에서는 상응 영역과 상응하지 않는 영역이 접하는 경계 지점을 어떻게 모델링하냐에 따라 localization 성능이 좌우되게 됩니다. 하지만 그림 1-(a)와 같은 모델링은 실질적으로 잘 구별해내야하는 경계 지점의 표현력을 더욱 모호해지게 만드는 방향으로 학습을 유도할 것입니다.
방금 그림 1-(a)를 보며 말씀드린 것이 첫 번째 문제점이었고, 두 번째 문제점은 기존 방식이 구간에 대한 proposal을 만들어내기 위해 사용하는 sliding window에 관련된 것입니다. Weakly-supervised 연구 초기에는 비디오 내에서 쿼리에 상응하는 구간이 어디인지 모르기에 사전 정의된 특정 너비를 갖는 window를 시간 축에 대해 쭉 sliding해가며 각각의 점수를 산출하고 이를 활용해 NMS를 적용한 후 얻은 결과물을 최종 proposal로 여겨 성능을 측정하였습니다. 아마 최근 방법론들은 거의 이 방식을 사용하지 않을텐데요, 이와 같은 방식은 연산량이 굉장히 많고 사람이 직접 window 크기를 heuristic하게 조절해주어야 한다는 점 뿐만 아니라 일차원적으로 생각해도 유동적인 구간의 길이에 대응할 수 없다는 치명적 단점이 존재한다는 것을 생각해볼 수 있습니다.
또한 저자가 이 방식에 대해 조금 더 지적하고 있는 점을 살펴보자면, sliding window를 사용하는 경우 사건 내부적으로 존재하는 시간적 전개 요소인 (시작-정점-끝)을 모델링할 수 없게 됩니다. 단순히 window 내부에 포함되냐 안되냐를 기준으로 proposal 학습이 이루어지기에 비디오 내 사건에 존재하는 temporal structure(시작-정점-끝)을 고려하지 못하고 있다는 이야기입니다.
이렇게 살펴본 두 가지 문제점을 통해, 저자가 유동적이며 구간 내 temporal structure를 고려할 수 있는 방법론 한 가지와, 비디오 내부에서 negative sample을 가져와 contrastive learning을 수행하는 방법론을 제안함을 대략적으로 예상해볼 수 있습니다. Contribution을 정리한 뒤 본격적으로 방법론에 대해 설명드리겠습니다.
Contribution
- We propose to generate a Gaussian mask as a proposal, which can represent the temporal structure of an event and can be learned by the network
- In contrast to collecting negative samples from different videos, we propose to mine the hard and easy negatives within the same video and train the system with Intra-Video Contrastive loss.
- SOTA on ActivityNet Captions and Charades-STA datsets.
2. Approach
참고로 저자가 제안하는 방법론의 이름은 Contrastive Negative Sample Mining을 줄여 CNM이라고 부르겠습니다.
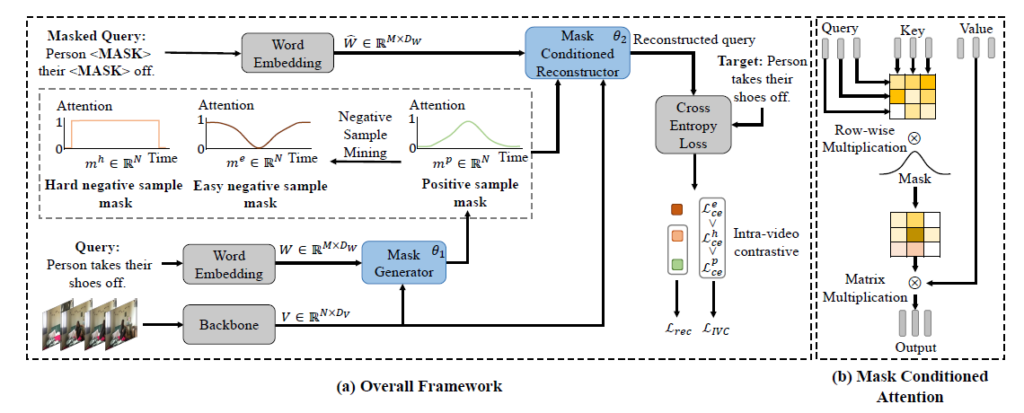
CNM의 전체 프레임워크는 그림 2를 통해 확인할 수 있는데, 중요하게 볼 점은 Mask Generator 부분에서 정의되는 hard negative, easy negative, positive 샘플들과 쿼리에 대한 masking 후 reconstruction 과정에서 이들이 어떠한 관계로 활용되는지일 것입니다. 가우시안 형태의 점수 분포를 갖는 proposal들이 활용된다는 점을 엿볼 수 있겠네요.
2.1 Mask Generator
2.1.1 Feature Extraction
방법론의 첫 절에서는 비디오, 텍스트 쿼리 각각에 대한 feature extraction 과정을 먼저 살펴보며 notation을 정리하고 가겠습니다.
우선 텍스트 쿼리 임베딩을 위해 GloVe feature를 활용합니다. 하나의 문장이 총 M개의 단어로 구성된다고 하면 이를 특징으로 추출했을 때 W=\{w_{1}, \cdots{}, w_{M}\} \in{} \mathbb{R}^{M \times{} D_{W}}로 표현합니다. D_{W}를 GloVe feature의 차원을 의미합니다. 다음으로 비디오는 사전학습된 3D network로부터 특징을 추출하는데 이는 V=\{v_{1}, \cdots{}, v_{N}\} \in{} \mathbb{R}^{N \times{} D_{v}}와 같이 표현합니다.
2.1.2 Mask Generation
이제 추출한 비디오와 텍스트 쿼리의 feature를 가지고 비디오 내 구간에 대한 mask를 만들어주어야 합니다. 앞서 그림에서 보았듯 segment 별 점수는 가우시안 분포를 갖도록 모델링하게 됩니다. Introduction에서 이야기한 (시작-정점-끝)이라는 temporal structure를 유지하기 위해서겠죠. 결국 특정 feature를 가우시안 분포로 모델링한다는 것은 분포의 평균과 표준편차를 구하는 것과 동일하다고 볼 수 있는데, 저자는 이에 Transformer를 활용합니다. 우선 두 모달의 feature가 합쳐진 fused feature H=\{h_{1}, \cdots{}, h_{N}\}은 아래 수식 (1) 과정을 거쳐 얻을 수 있습니다.
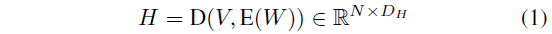
수식 (1)에서 E(\cdot{}), D(\cdot{})은 각각 Transformer의 encoder, decoder를 의미합니다. 먼저 encoder를 통해 텍스트 쿼리의 feature W에 self attention을 적용한 뒤 decoder를 통해 비디오와 E(W)의 cross attention을 적용해 fusion을 수행하는 것으로 볼 수 있겠습니다.

앞서 이야기했듯 가우시안 분포로 무언가를 모델링한다는 것은 분포의 평균과 표준편차를 구한다는 것과 동일한 것인데, 위 수식 (2)와 수식 (3)을 통해 중심 지점과 너비 각각이 계산되게 됩니다. 단순하게 1차원 scalar를 내뱉는 FC layer와 sigmoid를 거쳐 얻은 값을 사용하고 있네요. 이제 중심과 너비를 얻었으니 이를 기준으로 모든 segment의 score를 가우시안 분포로 표현해주면 됩니다. 이는 아래 수식 (4)와 같습니다.
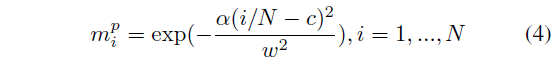
수식 (4)는 positive mask를 의미하고 분포 너비를 조절하는 하이퍼퍼라마터 \alpha{}와 앞서 구한 c, w로 비디오 내부 segment 별 positive score m_{i}^{p}를 얻을 수 있는 것입니다.
여기까지는 positive mask를 구하는 과정으로, 굉장히 간단했습니다. 정리하자면 추출한 각 모달의 feature를 Transformer를 통해 fuse해주고, 해당 fused feature로부터 학습 기반의 c, w를 추출해 가우시안 마스크를 만들어주고 있는 모습입니다.
2.1.3 Negative Sample Mining
가우시안 마스크와 더불어 본 절에서 설명할 비디오 내 negative sample mining 방식 또한 저자의 큰 contribution이라 볼 수 있겠죠. 우선 negative sample도 easy negative와 hard negative로 나뉘게 됩니다. Easy negative sample에 대한 mask m^{e}는 아래 수식 (5)와 같이 구해줍니다.
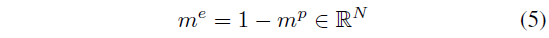
앞서 얻은 positive mask m^{p}에 해당하지 않는 구간을 의미한다고 볼 수 있습니다. 물론 이 부분이 실제 negative이려면 m^{p}가 잘 구해졌어야 한다는 가정이 반드시 필요하지만, temporal annotation이 주어지지 않는 상황에서는 어느 정도 모델 능력에 기댈 수 밖에 없다는 한계가 존재하는 것으로 생각됩니다. 같은 비디오 내 존재하는 Easy negative sample들을 학습에 활용함으로써, 배경도 비슷하고 의미론적으로 유사해 보이는듯한 segment들에 대한 구별력을 기를 수 있게 될 것으로 기대할 수 있습니다.
다음으로 Hard negative sample에 대한 mask인 m^{h}를 구하는 방식이 조금 새로웠습니다. 저자에 따르면 기존의 많은 논문들이 이러한 방식을 흔히 사용했다고 하는데, 저에게는 조금 낯서네요. 아무튼 이는 아래 수식 (6)과 같습니다.
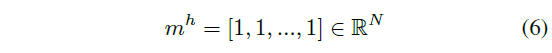
결국 수식 (6)에 따르면 비디오의 모든 segment를 uniform하게 엮어 hard negative로 두겠다는 것인데요, 전체 비디오에는 postive sample과 negative sample이 함께 들어있습니다. 이는 모델이 찾아야하는 최적의 구간이 아니기에 negative에 해당되고, 앞서 구한 m^{e}에 비해 positive segment들이 더욱 포함되어있기에 hard negative라고 볼 수 있는 것입니다. 물론 어느 비디오는 거의 전체가 상응 구간에 해당할 수도 있겠지만, 저자가 그렇게 특수한 경우는 배제한 것으로 보입니다.
앞서 이야기한 세 가지 샘플의 관계를 생각해보았을 때 각 mask m과 텍스트 쿼리 W의 relevance R은 아래 수식 (7)과 같은 관계를 만족할 것입니다.
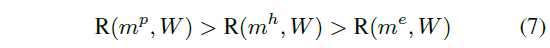
이제 positive, easy negative, hard negative sample을 모두 구했으니 이들을 대상으로 어떠한 contrastive learning을 수행하는지 알아보겠습니다.
2.2 Mask Conditioned Reconstructor
저자가 제안하는 CNM은 기존 연구에서 활용되던 Reconstruction 방법론을 활용합니다. Reconstruction 방법론의 가장 기본이 되는 아이디어는, 어떤 구간이 masking된 텍스트 쿼리에 대한 reconstruction을 잘 수행할수록 잘 상응하는 구간일 것이라는 점입니다. 두 모달 간 특징이 의미론적으로 유사할수록 비어있는 단어를 잘 맞춰낼 것이라는 의미입니다.
이 reconstruction 또한 Transformer(E(\cdot{}), D(\cdot{}))를 기반으로 진행되며, 기존 프레임워크에서 저자가 제안하는 mask conditioned attnetion만 변경해서 제안하는 것이라고 합니다. 앞서 말씀드린 수식 (7)에서 각 mask들의 관계를 정의하였으니, 이 relevance R을 reconstruction 능력이라고 볼 수 있고 저자는 이를 바탕으로 어느정도 heuristic하게 정의되는 Intra-Video Contrastive loss (\mathcal{L}_{IVC})를 제안합니다.
2.2.1 Mask Conditioned Attention
Reconstruction을 위한 encoder E_{m}(\cdot{})는 mask m \in{} \mathbb{R}^{N}과 비디오 feature V \in{} \mathbb{R}^{N \times{} D_{v}}를 입력으로 받습니다. E(\cdot{})의 attention 연산에 필요한 Query Q_{a}, Key K_{a}, Value V_{a}는 모두 V로부터 얻게 됩니다.
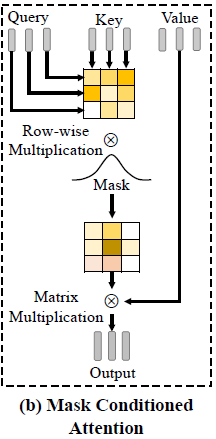
우선 attention map A = \frac{Q_{a}K_{a}}{\sqrt{D_{H}}} \in{} \mathbb{R}^{N \times{} N}을 얻어줍니다. 이를 바로 V_{a}에 곱하는 것이 아니라 그 사이에 mask m을 temporal 축으로 곱해줌으로써 다시 한 번 attention을 주는 것으로 이해하시면 됩니다. 이후 row-wise로 softmax를 적용해 encoder의 최종 출력을 아래 수식 (8)과 같이 얻습니다.
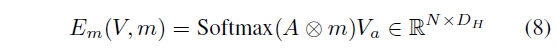
2.2.2 Mask Conditioned Semantic Completion
이제 E_{m}(V, m)과 마스킹된 텍스트 쿼리 값을 함께 reconstructor의 decoder D_{m}(\cdot{})의 입력으로 주어 복원을 수행하게 됩니다. 텍스트 쿼리의 마스킹은 전체 문장의 1/3을 랜덤하게 지우고 특히 명사, 동사, 형용사는 높은 가중치를 주어 지운다고 합니다. 이렇게 특정 단어들이 지워진 텍스트 쿼리의 GloVe feature는 \hat{W}로 표현합니다. 이를 이용해 positive mask m^{p} 기준의 reconstructed representation H^{p}는 아래 수식 (9)와 같습니다.
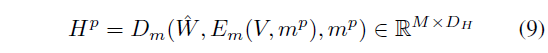
이제 H^{p}를 FC layer에 태워 예측한 단어와 실제 단어 간 CE Loss로 분류 학습을 진행하게 됩니다.
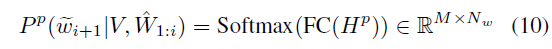
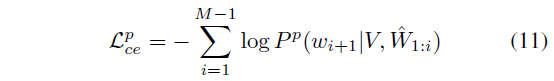
여기서 N_{w}는 vocab size로, 등장할 수 있는 전체 단어의 개수라고 보시면 됩니다. 사전 정의되어있는 GloVe feature의 개수를 의미하겠죠. 수식에서의 예시는 positive mask m^{p}만을 보여주고 있지만, m^{e}, m^{h}로도 동일한 과정을 거쳐 reconstruction에 대한 예측값 및 loss를 구할 수 있습니다.
우선 reconstruction에 대한 최적화는 \mathcal{L}_{ce}^{p}, \mathcal{L}_{ce}^{h}만을 대상으로 진행합니다. \mathcal{L}_{ce}^{e} 또한 계산은 되지만 backward되지 않는 이유는, easy negative에는 정의 상 실제 상응 구간이 포함되지 않기 떄문에 정답 단어를 reconstruction하지 못하는 것이 맞기 때문입니다.
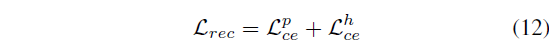
2.2.3 Intra-Video Contrastive
그렇다면 \mathcal{L}_{ce}^{e}는 어디에서 사용될까요? 이는 아까 저희가 정의한 수식 (7)의 관계를 만족시켜주기 위해 활용됩니다. 정답과 가장 많이 상응하는 구간일수록 마스킹된 문장을 잘 reconstruction할 것이라는게 가장 첫 번째 가정이었고, 그 가정에 따라 상응 구간 포함 정도를 기준으로 수식 (7)과 같은 관계를 정의했었죠. 저자는 방금 구한 각 mask의 CE Loss 들이 해당 관계를 유지하도록 설계해줍니다. 이것이 바로 저자가 제안하는 \mathcal{L}_{IVC}입니다. 이는 아래 수식 (13)과 같고, 식에서 \beta{}_{1} < \beta{}_{2}입니다.
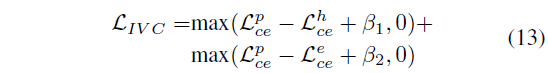
여기까지 모델 방법론에 대해 알아보았고, 학습과 inference 방식에 대해 알아본 뒤 실험 결과를 살펴보겠습니다.
2.3 Model Training and Inference
2.3.1 Training
우선 학습에 사용되는 loss는 크게 두가지였습니다. Positive, Hard negative 마스크를 활용해 reconstruction을 잘하도록 유도하는 \mathcal{L}_{rec}과 세 mask들 간 정의된 관계를 유지하도록 설계된 \mathcal{L}_{IVC}였습니다. 각 loss의 역할에 대해 생각해보면, \mathcal{L}_{IVC}는 mask generator가 좋은 mask를 만들어내도록 유도하고, \mathcal{L}_{rec}은 mask conditioned reconstructor가 좋은 reconstruction을 수행하도록 유도합니다.
만약 이 두 loss를 한 번에 최적화한다면, 학습 초반 reconstructor가 negative sample에 대해 항상 낮은 값을 내는 trivial solution에 빠질 수 있게 됩니다. 이렇게 되면 \mathcal{L}_{IVC}를 통한 유의미한 학습이 어려워지겠죠. 따라서 저자는 이러한 상황을 방지하고자 \mathcal{L}_{rec}을 먼저 최적화하여 reconstruction이 어느정도 수행되는 상황을 만들어두고 reconstructor를 freeze 한 뒤 \mathcal{L}_{IVC}를 최적화했다고 합니다.
2.3.2 Inference
Positive mask를 통해 모델의 최종 예측을 만들어낼 수 있을 것으로 보이는데, 실질적으로 어떻게 하는지 알아보겠습니다. 이는 아래 수식 (15)와 같습니다. 예측한 c를 기준으로 w의 절반만큼을 앞뒤로 빼고 더해 시작과 끝 지점을 정해줍니다.
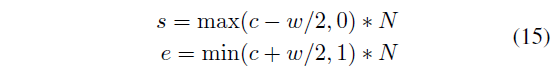
앞서 Introduction에서 sliding window 등의 방식은 NMS를 마지막에 거쳐줘야 중복을 제거할 수 있는데, 저자의 방식을 따르면 연산량이 큰 NMS를 거칠 필요가 없어 효율적이라고 볼 수 있습니다. 추가로 말씀드리자면 당시에 벤치마킹되던 ActivityNet Captions 데이터셋과 Charades-STA 데이터셋은 비디오 하나당 하나의 쿼리만이 쌍으로 주어지기 때문에 비디오 당 하나의 예측을 만들어내는 본 방법론의 방식이 유효합니다. 하지만 하나의 비디오 내 여러 쿼리가 매칭되어 있는 최신 데이터셋 QVHighlights에는 대응할 수 없다는 단점이 존재하겠네요. 물론 쌍 개수만큼 반복해서 돌리면 해결되겠지만 최근에는 DETR 프레임워크를 따와 그보다 효과적이고 효율적인 프레임워크들이 많이 연구되고 있는 상황입니다.
3. Experiments
3.1 Datasets & Evaluation Metric
데이터셋은 ActivityNet Captions와 Charades-STA가 벤치마크에 사용되었습니다. 평가지표는 Recall@1, IoU=m이 사용되었는데, temporal 축에 대한 IoU m을 기준으로 True Positive proposal을 측정하고 이에 대한 Recall@1, 즉 Accuracy를 측정하여 타 방법론들과 성능을 비교합니다.
3.2 Implementation Details
3.2.1 Data Preprocessing
비디오 feature 추출 시 ActivityNet Captions 데이터셋에 대해서는 CLIP, Charades-STA 데이터셋에 대해서는 I3D를 활용했다고 합니다. CLIP 모델을 feature extractor로 사용하는 논문은 처음 보는데, 다른 backbone들과 유사하게 꽤 효과적으로 동작하나봅니다. 텍스트 쿼리의 feature 추출을 위해서는 GloVe embedding이 활용되었으며 ActivityNet Captions에 대해서는 최대 vocabulary size를 8,000, Charades-STA에 대해서는 1,111을 사용했다고 합니다. ActivityNet Captions 데이터셋에 존재하는 쿼리의 단어 다양성이 더 크다는 의미이겠죠.
3.2.2 Model Settings
Mask generator와 Mask conditioned reconstructor로 사용되는 Transformer의 embedding 차원은 256, head 개수는 4개, layer 개수는 3으로 지정했다고 합니다. 수식 (13)에 등장하는 \beta{}_{1}=0.1, \beta{}_{2}=0.15를 사용하였고 가우시안 분포를 조정해주는 \alpha{}=5를 사용했다고 합니다.
3.3 Comparisons to the State-Of-The-Art
타 방법론들과의 벤치마크 성능 비교입니다.
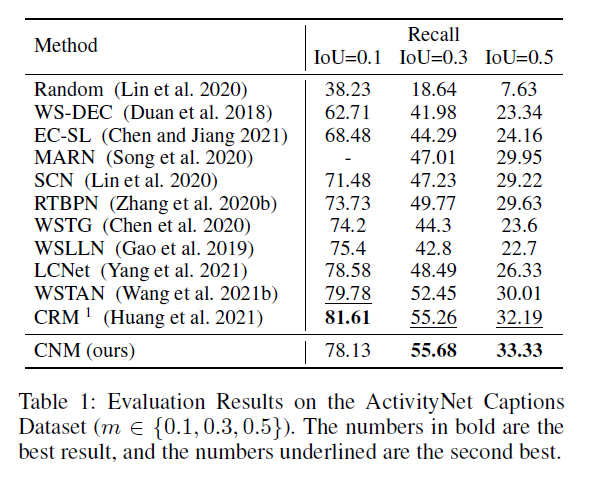
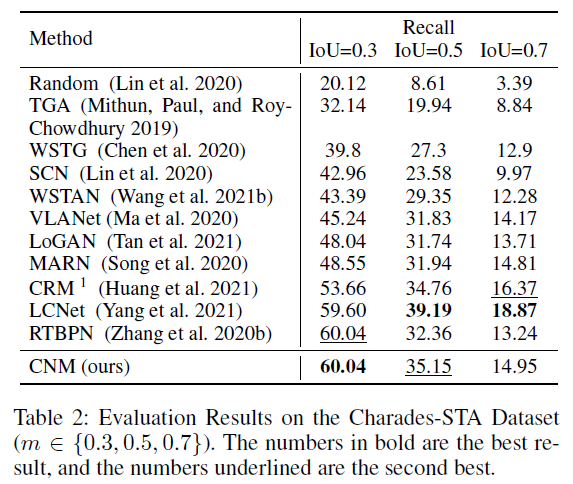
표 1, 2는 각각 ActivityNet Captions, Charades-STA 데이터셋에서의 성능 비교 표입니다.
저자에 따르면 여기서 CRM이라는 방법론과의 직접적인 비교는 fair comparison이 아니라고 하네요. CRM의 경우 학습 중 텍스트 쿼리 이외에 paragraph description annotation을 추가로 요구하기에 성능이 높은 것이라고 합니다. 표 1을 보았을 때 IoU=0.1 제외 SOTA를 달성했음을 알 수 있습니다. 0.1에서는 CRM을 제외하더라도 SOTA 성능이 아닌데, 이에 대한 분석은 따로 하고있지 않네요.
다음으로 표 2에서는 IoU=0.1을 제외하고 타 방법론들보다 성능이 크게 떨어지는 것을 볼 수 있습니다. 이에 대해 저자는, CNM이 reconstruction 기반으로 학습되어 문장을 잘 완성하기 위해 좀 더 긴 영역을 살펴보게 되었고, 이로 인해 긴 proposal을 출력으로 내뱉는 경향이 있었다고 합니다. 그러다보니 조금 더 정밀하게 맞춰야 하는 IoU=0.5, 0.7에서는 성능이 떨어진 것이라고 하네요. 참고로 Charades-STA 데이터셋의 평균 구간 길이는 8.1초로 평균 구간 길이가 24.6초인 ActivityNet Captions 데이터셋보다 짧아 이런 경향성을 보인다고 생각할 수 있습니다. AAAI와 같은 높은 학회에서 이 정도의 분석으로 낮은 성능 측면에서 문제되지 않을 수 있다는 점이 놀랍습니다.
3.4. Ablation Study
모든 ablation study는 ActivityNet Captions 데이터셋에서 진행되었습니다.
3.4.1 Effect of Mask Generator
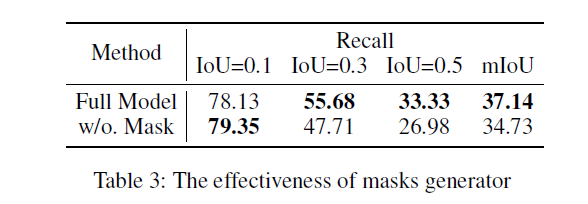
Mask generator를 제거한 뒤 기존의 sliding window 방식으로 대체하는 경우 성능을 살펴보겠습니다. 나머지 IoU를 기준으로는 압도적으로 높은 성능을 보여주지만 IoU=0.1 기준에서는 오히려 sliding window 방식이 더 높은 것을 볼 수 있습니다. 하지만 w/o Mask 방법론은 많은 window를 기준으로 연산량이 큰 NMS를 적용해야 하기에 효율성 측면에서 부족한 모습을 보입니다. 저자에 따르면 CNM은 비디오 당 inference 속도가 55.8ms, w/o Mask는 124ms라고 합니다. 두 배 이상의 빠른 속도로 높은 성능을 보여준다는 점이 설득력있게 작용한 것 같습니다.
3.4.2 Effect of Intra-Video Negative Sample Mining
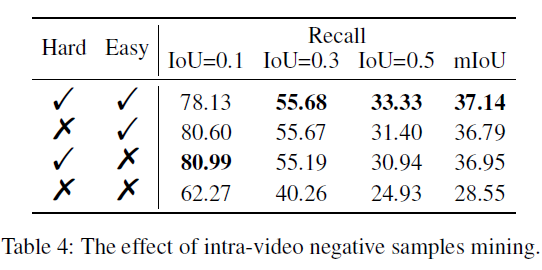
표 4는 easy와 hard negative sample mining 여부에 따른 ablation 성능입니다. 우선 hard와 easy를 모두 사용하는 것이 가장 좋은 성능을 보여주고 있습니다. 처음에는 비디오 전체를 엮어 hard negative로 활용하는 것이 잘 와닿지 않았는데, ablation 성능과 같이 보니 확실히 유효했다는 점을 알 수 있었습니다.
3.4.3 Effect of Training Strategy
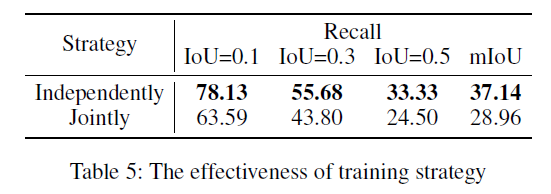
표 5는 앞서 언급한 학습 방식에 대한 실험 성능 비교 표입니다. 저자가 처음 joint하게 학습한 성능을 본 뒤 분석을 통해 reconstructor가 항상 negative sample에 대한 예측을 낮은 점수로만 하는 trivial solution에 빠져있다는 것을 확인하고 위와 같은 방식을 제안한 것인데, 논문 작업을 해보니 그러한 중간중간의 분석 과정이 참 어려운 것 같습니다.. 아무튼 저자의 방식을 따라 문제를 해결할 수 있었고 높은 성능을 달성했음을 알 수 있었습니다.
3.5 Qualitative Results

마지막 그림 3은 정성적 결과입니다. 베이스라인으로 삼은 SCN보다 정확하게 구간을 맞추고 있지만 마지막 예시의 경우 CNM이 문장을 잘 reconstruct 하기 위해 긴 구간을 예측으로 내뱉는 경향이 있다는 점을 본 연구의 한계점으로 지적하고 있습니다.
4. Conclusion
Weakly-supervised 쪽 grounding 연구는 처음 읽어보았는데, 결국 중요한 것은 temporal annotation이 없는 상황에서 heuristic한 가정을 어떻게 잘 줄 것이고 이것이 모델에게 어떠한 supervision을 주는지에 대한 분석이 중요하다는 점을 깨닫게 해준 논문입니다. 지금 작업하고 있는 논문에서 gaussian-based score을 활용하고 있진 않은데, 본 논문처럼 video-level로 적용해보는 것도 좋은 결과를 만들어낼 수 있을 것으로 생각됩니다.
이상으로 리뷰 마치겠습니다. 감사합니다.