
안녕하세요. 허재연입니다. 오늘은 Self-Supervised Learning 논문을 들고 왔습니다. 이전부터 Multispectral Pedetrian Detection에 Contrastive Learning을 활용하면 효과가 있지 않을까 하는 막연한 생각을 가지고 있었는데, 이 논문이 바로 해당 방법을 사용하는 논문이기에 관심을 가지고 읽어보았습니다.. 다만, 실제 예측에 있어 thermal image만 사용한다는 점과 feature map을 transformer 구조에 넣는다는 점에서 URP 과정에서 다루는 것과는 다른 점이 있습니다. 그럼 바로 리뷰 시작하겠습니다.
Abstract
자율 주행에 있어 환경에 대한 인지는 안전과 제어에 관한 결정에 있어 중요한 역할을 합니다. 이런 역할을 하는 알고리즘의 환경 인지는 인간과 비슷하게 환경에 대한 다양한 센서 정보를 활용합니다. 이런 주변 환경 정보를 취득하기 위해서 카메라, 라이다(Lidar)와 같은 센서들이 자율 주행 차량에 배치되어 정보를 수집합니다. 하지만, 이런 센서들은 visible spectrum domain에서는 잘 동작하지만 악천후나 야간 상황 등 시각 정보가 제한될 때는 그 기능이 저하되어 치명적인 사고로 이어질 수 있습니다. 본 논문에서는 Self-Supervised Contrastive Learning을 활용하여 view-invariant한 모델 표현력을 확보하는 thermal object detection을 연구하였습니다. 저자들은 contrastive learning을 이용하여 visible & infrared spectrum 간 정보를 잘 활용하는 feature embedding을 학습하기 위한 딥러닝 모델인 ‘Self-Supervised Thermal Network(SSTN)’을 제안합니다. 이후 이렇게 학습된 feature representation은 multi-scale 인코더-디코더 트랜스포머 네트워크를 활용한 thermal object detection에 활용됩니다. 실험은 LFIR-ADAS 데이터셋 및 KAIST PD 데이터셋에서 수행되었으며, 좋은 결과를 보여주었다고 합니다.
Introduction
최근 기술의 발전으로 자율 주행 기술이 크게 발전하였고, 실제로 도로 위를 달릴 수 있게 되었습니다. 자율 주행의 구현에 있어 인지(perception) 기술은 자율 주행 차량의 환경을 인식하는데 있어 중요한 역할을 합니다. 일반적으로는 이런 환경 인식을 위한 센서로 camera, Lidar, radar가 사용됩니다. 이들 센서는 각자만의 장단점을 가지고 있습니다. 카메라(visible spectrum)는 환경에 대한 고해상도 정보를 제공할 수 있지만 야간 환경에서는 활용이 어렵습니다. 라이다(Lidar)는 환경 모델링을 위해 레이저광을 사용하여 주위 환경에 대한 3D point-cloud 데이터를 제공할 수 있지만, 가격이 높고 악천후 조건에서 해상도가 떨어지는 문제가 있습니다. 레이더(Radar) 또한 자율 주행 차량 근처의 작은 물체들을 식별할 수 있지만 거리가 멀어지면 해상도가 떨어지게 됩니다. 따라서 이런 센서들로 자율 주행 차량이 야간 환경을 인식하는데는 한계가 있습니다. 야간 환경 인식에 열화상 카메라를 이용하는 것이 필요하지만 저자들은 아직 object detection의 맥락에서 더욱 효과적이고 뛰어난 인식 알고리즘이 필요하다고 합니다. 다양한 object detection 모델들(YOLO, SSD, Faster-RCNN 등등..)이 제안되며 상당한 개선을 이루었지만 대부분 가시광선(컬러) 영상에 초점이 맞춰져 있었으며 thermal object detection domain에는 아직 개선의 여지가 있다고 하네요. 기존의 몇몇 연구는 visible spectrum에서 thermal spectrum으로 지식을 전이하기 위해 domain adaption을 적용하고자 하였다고 하며, visible domain에서의 OD에서도 thermal domain을 사용한 선례가 있다고 합니다(우리에게 익숙한 multispectral fusion을 말하는 듯 합니다).
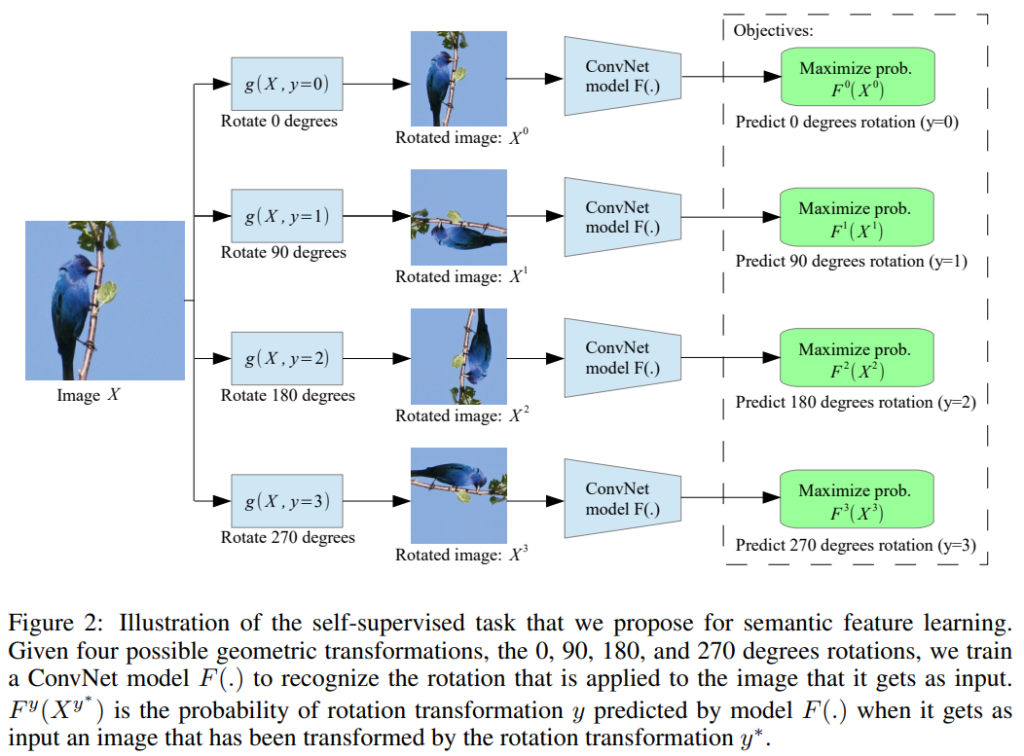
기존의 이러한 학습은 보통 supervised learning을 사용했지만, self-supervised learning을 활용해서도 표현력을 확보하게 할 수 있습니다. self-supervised learning은 라벨링이 되어있지 않은 데이터를 가지고 자체적인 학습을 통해 데이터에 대한 표현력을 확보하는 것을 목표로 합니다. 예를 들어, image data에 대해 무작위로 0, 90,180,270도의 회전을 가하고 모델에 회전 각도를 맞추게 하는 사전학습을 진행시키면 모델이 각도 맞추기 task를 수행하며 image data 자체에 대한 표현력을 확보할 수 있습니다. 이렇게 사람이 설계한 휴리스틱한 사전학습 방법을 pretext task라고 하며, self-supervised learning 방법론 중 한 줄기로 분류할 수 있습니다. rotation 방법 이외에도 대표적인 pretext-task로는 1. 직소 퍼즐 맞추기, 2. 이미지 패치 간의 관계 맞추기, 3. image inpainting(이미지 중심을 없애버리고 다시 reconstruction), 4. colorization(색상을 grascale로 drop하고 원래 색상 복원하기) 등이 있습니다.

또 다른 Self-Supervised Learning 방법으로는 Contrastive Learning을 이용한 방법이 있습니다. contrasive learning은 서로 연관되어 있는 데이터끼리는 서로 가까이 임베딩 되고, 서로 다른 데이터끼리는 멀리 임베딩되도록 학습하는 과정을 반복해 데이터에 대한 표현력을 확보하게 됩니다. 예를 들어, 이미지 데이터와 그에 대한 캡션(text형태)간의 관계를 어느정도 확보하는 모델을 만들기 위해서는 특정 image data와 그에 대한 caption을 positive pair로 묶어 임베딩 공간에서 서로 가깝게 projection 되도록 학습하고, 서로 관련이 없는 데이터 쌍 끼리는 negative pair로 묶어 임베딩 공간에서 서로 멀어지게 projection되도록 학습을 반복합니다. 유사도는 보통 cosine similarity로 측정하는것이 일반적이며, contrastive learning을 Self-Supervised Learning 방법으로 활용한 대표적인 방법론으로는 SimCLR와 MoCo가 있습니다. 본 논문에서는 정확히 어떤 contrastive learning을 적용했다는 직접적인 언급은 없지만 전체 프로세스를 살펴보니 SimCLR와 아주 유사합니다.(contrastive learning 관련 인용도 SimCLR가 걸려 있습니다)
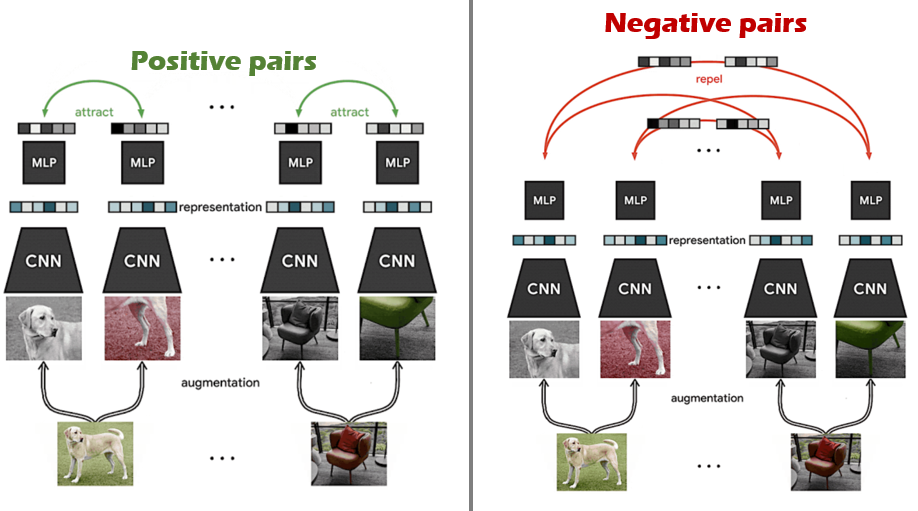
위 그림은 contrastive learning의 학습 과정을 대략적으로 나타낸 것입니다. 하나의 image에서 서로 다른 augmentation을 가한 동일한 image pair끼리는 positive pair로 묶어 feature extractor를 타고 나온 representation vector끼리 가까워지도록 학습시키고, 서로 다른 이미지끼리는 negative pair로 묶어 embedding space에서 서로 멀어지도록 학습을 반복합니다. 벡터 간 cosine similarity(유사도 측정 값의 범위는 [-1,1]가 되겠죠)를 측정해 positive pair 간 유사도는 1이 되는 방향으로, negative pair끼리의 유사도는 -1이 되는 방향으로 학습시키며 데이터에 대한 표현력을 학습하게 됩니다.
본 논문의 경우에는 multispectral image pair를 가지고 contrastive learning을 수행하는데, 동일 씬에 대한 visible-thermal pair끼리는 positive pair로, 서로 다른 씬에 대해서는 negative pair로 간주하고 contrastive learning을 수행합니다.
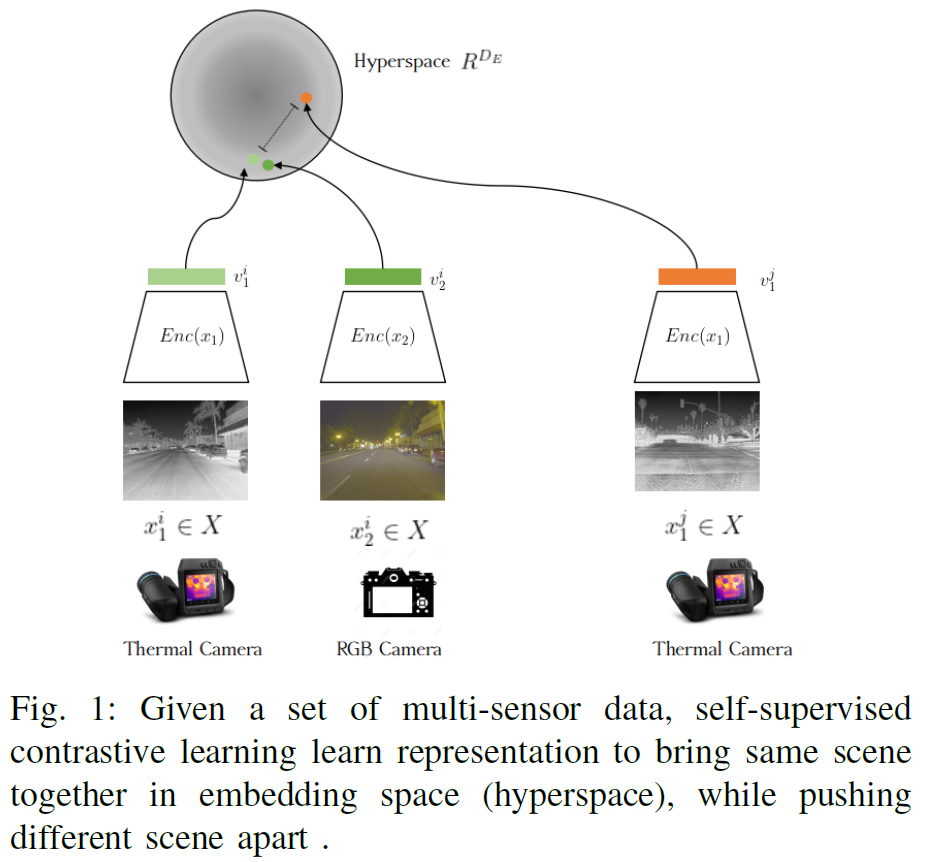
Fig 1을 통해 제안된 프레임워크의 개요를 확인할 수 있습니다. 제안된 SSTN은 2단계로 구성됩니다. 1단계인 self-supervised contrastive learning 단계에서는 동일 씬에 대해서 thermal-visible contrastive learning을 수행하며 두 도메인 간 mutual information을 극대화한다고 하며, 그 다음 단계에서는 multi-scale encoder-decoder transformer 구조로 thermal object detection을 수행합니다. 제안된 방법의 encoder로는 ResNet101이 사용되었으며, 기존 방법론들(thermal object detection)보다 FLIR-ADAS 데이터셋에서는 2.57% 및 KAIST Multi-Spectral 데이터셋에서는 2.37%개선된 결과를 보였다고 합니다. 저자들이 주장하는 main contribution들은 다음과 같습니다 :
- 저자들은 thermal object detection을 위해 Self-Supervised domain adaptation framework (SSTN)을 설계하였다. 제안된 SSTN 네트워크는 thermal domain에서의 OD에서 visible 및 thermal domain 모두의 정보를 최대한으로 활용하기 위해 self-supervised contrastive learning 방법을 사용하였다.
- contrastive learning 방법은 labelled dataset이 부족한 문제를 해소할 수 있는 방법이며, 저자들이 아는 한 본 연구는 multi-sensor framwork에 self-supervised learning을 최초로 접목시킨 연구이다.
- 또한, 저자들은 thermal object detection을 위해 self-supervised 방법으로 학습된 feature embedding을 multi-scale encoder-decoder transformer network로 확장하였다.
Method
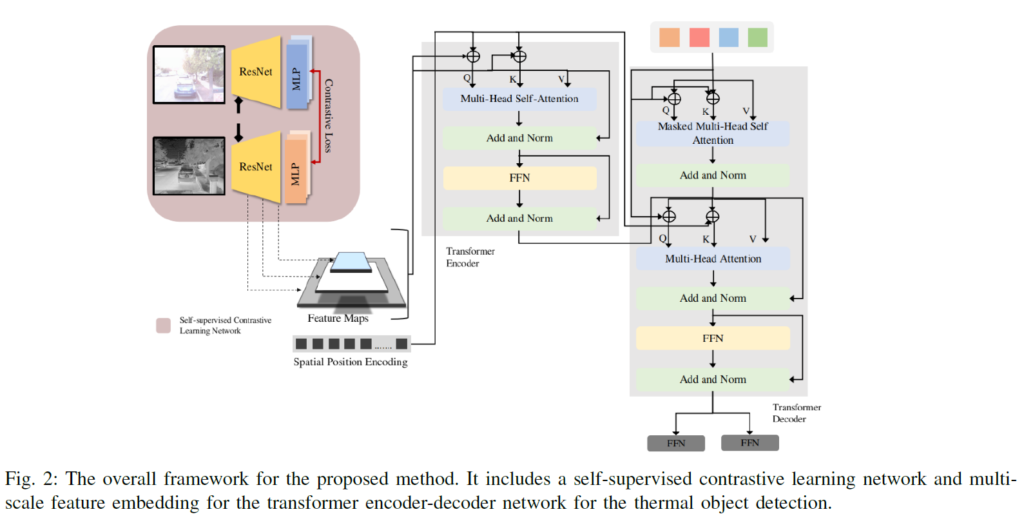
Fig 2는 전체 프레임워크를 한눈에 확인할 수 있는 그림입니다. 먼저 ResNet을 feature extracter로 사용하여 visible-thermal 도메인에 대해 contrastive learning을 수행하여 사전학습을 한 뒤, 그 이후에는 사전학습이 끝난 ResNet에서 Multi-scale feature map을 추출하여 트랜스포머의 인코더-디코더에 각각 태웁니다.
A. Self-supervised Contrastive Learning
동일한 장면에 대한 visible / thermal 이미지 데이터를 x1,x2라 하겠습니다. 그럼 x1,x2는 동일한 장면에 대한 정보를 공유하고 있을 것입니다. feature extracter에 넣기 전에 x1,x2에 random augmentation을 적용한 뒤, feature extractor+MLP에 태워 각 데이터를 representation vector로 매핑하고, 이 벡터들을 unit hyperspace로 정규화(normalize)합니다. 여기서는 feature extractor로 ResNet이 사용되었습니다. MLP는 single hidden layer로 구성되었으며, output layer의 크기는 128차원입니다. 정규화 된 벡터들은 unit hypersphere 위에 위치하게 되겠죠. 정규화가 되었으면 벡터의 내적을 활용해 cosine similarity를 구할 수 있습니다. contrastive learning은 배치 단위로 수행되며, N개의 random pair를 사용하게 됩니다. 한 번에 활용하는 이미지 수는 2N개가 되겠죠. 여기서 negative pair를 선택하는 특별한 전략을 기대했었는데 그냥 단순히 random selection을 한다고 합니다. self-supervised contrastive learning의 손실함수는 다음과 같습니다 :
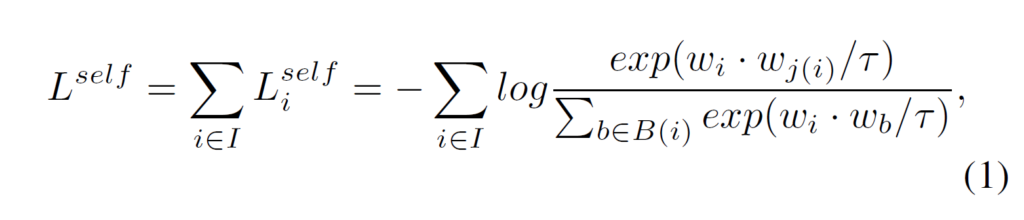
i ∈ {1 .. 2N}은 무작위로 선택된 thermal sample의 index이고, j(i)는 이에 대응되는 RGB 샘플의 index입니다. wi는 Augmentation-ResNet(feature extracter)-MLP-normalization을 거친 벡터입니다. 벡터 간 내적을 한 뒤 temperature parameter τ로 나누어 cosine similarity를 연산한 것이라고 생각하시면 됩니다. contrastive learning에 temperature parameter의 효과가 궁금하신 분들은 이를 다룬 리뷰를 참고하시면 좋을 것 같습니다.
contrastive learning을 통해 학습된 feature map은 그 다음 단계에서 transformer encoder의 input이 됩니다.
B. transformer Encoder-Decoder
transformer encoder-decoder 부분은 DETR이 레퍼런스가 걸린 것으로 봐서 DETR을 활용한 것으로 생각하시면 될 것 같습니다. 제가 DETR에 대해서 자세하게 알지는 못하지만.. 이상인 연구원님의 리뷰가 자세히 작성되어 있어 함께 읽었으며, 궁금하신 분들은 함게 참고하시면 좋을 것 같습니다. transforemr encoder는 CNN 백본에서 얻은 low-resolution feature map을 input으로 받습니다. 트랜스포머 인코더의 input과 output은 동일한 resolution feature map을 가지며, multi-scale, multi-head self-attention 모듈을 가집니다. self-attention에서는 attention 메커니즘을 사용해 픽셀 간 관계를 학습하게 됩니다. 디코더 부분은 multi-scale cross-attention 및 self-attention module로 이루어져 있으며, N개의 object query를 output embeddings로 변환합니다. output embedding들은 이후 feed-forward network(그림에서의 FFN)으로 들어가고, 바운딩 박스와 클래스 라벨을 예측하게 됩니다.
C. Feed-Forward Network
Feed-Forward Network(FFN)은 트랜스포머 디코더의 출력을 입력으로 받습니다. 3계층짜리 퍼셉트론 네트워크로 이루어졌으며, 마지막 층에서 class label과 bounding box(중앙 좌표 및 높이, 넓이)를 예측하는 output을 산출합니다.
Experiment
해당 연구에서는, 1. FLIR-ADAS 데이터셋 및 2. KAIST Multi-Spectral 데이터셋이 사용되었습니다. FLIR-ADAS의 경우에는 9214개의 RGB-Thermal pair로 이루어져 있고 MS-CoCo format으로 annotation되어있다고 합니다. car, person, bicyle의 3개 클래스가 있으며, 낮과 밤에서 수집되었다고 합니다.
self-supervised contrastive learning의 경우 input image pair에 대해 random crop, resize, horizontal flip, colour jittering이 적용되었다고 하며, encoder(feature extracter)로는 ResNet 50/101이 사용되었다고 합니다. 베이스라인으로는 ResNet을 백본으로 사용한 faster-RCNN을 사용했다고 합니다. 사전학습 없이 thermal image만으로 supervised learning한 실험과, contrastive learning으로 사전학습한 것에 대한 실험이 수행되었습니다. (task는 thermal object detection으로, 본래 task의 input은 thermal image입니다)
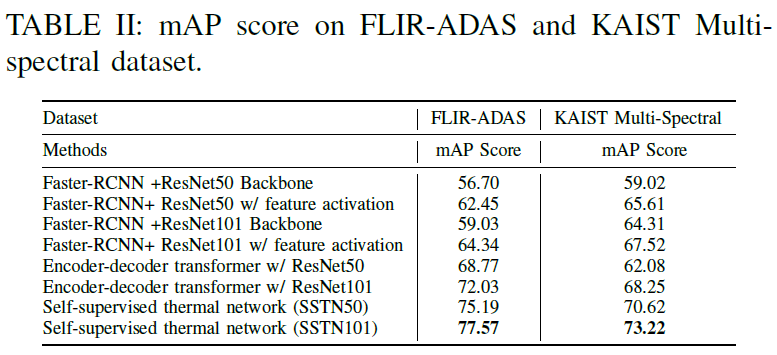
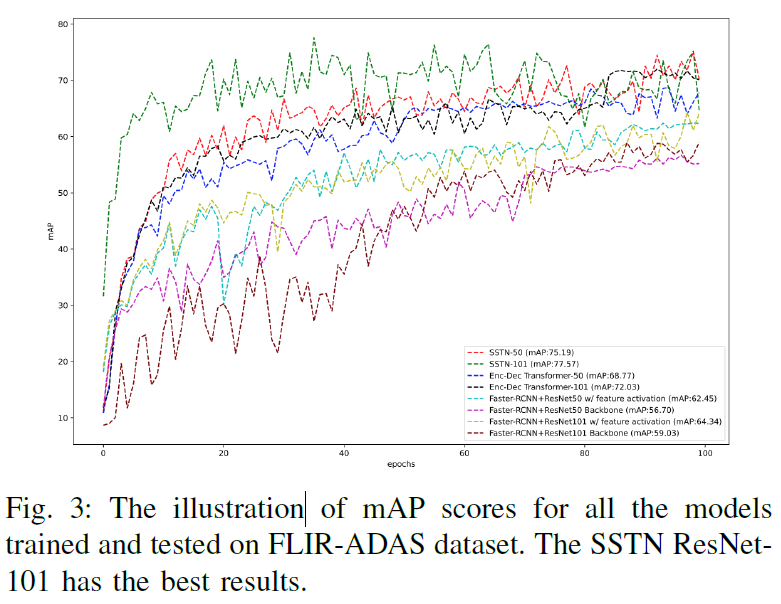
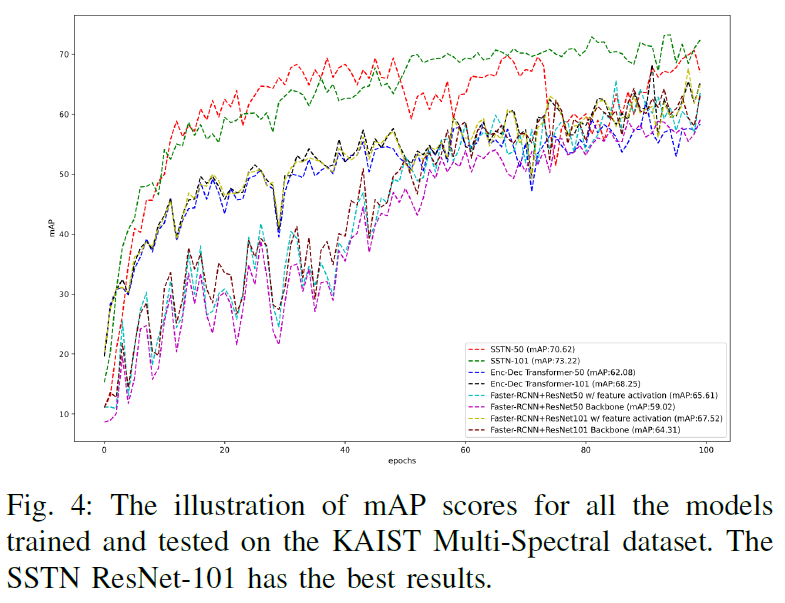
contrastive learning을 수행했을 때에 사전학습을 하지 않은 것보다 더욱 안정적인 학습을 하는 것을 확인할 수 있습니다. 저자들은 contrastive leaning의 적용 여부 뿐만 아니라, 기존 thermal object detection benchmark의 SOTA 방법론들과도 비교를 수행했습니다.
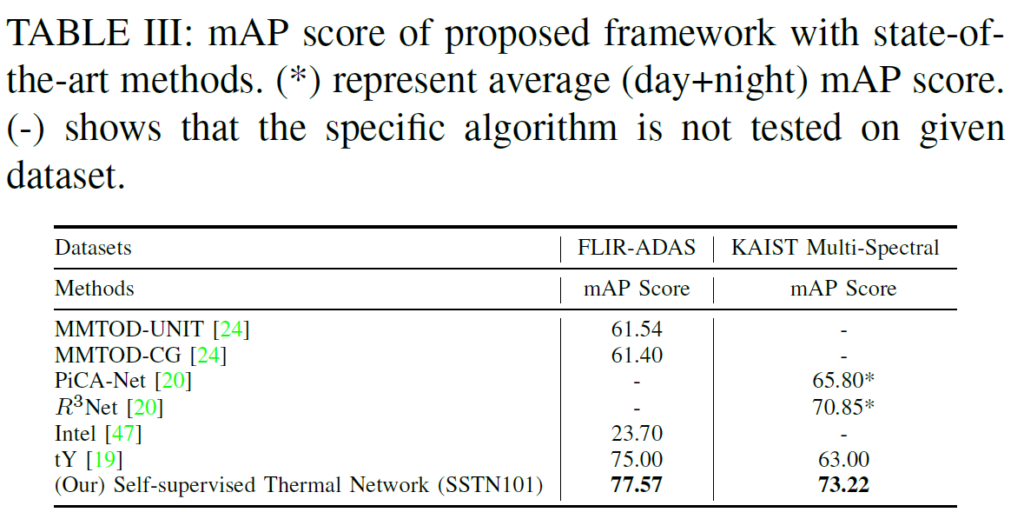
TABLE 3는 thermal object detection에 대한 기존의 방법론들과의 비교입니다. 사전학습을 수행한 것이 더욱 좋은 결과를 내는 것을 확인할 수 있습니다(비교군이 되는 방법론들은 self-supervised 방법론이 아닌, thermal object detection benchmark에서 기존에 제안되었던 방법론들입니다).
Conclusion
저자들은 thermal object detection에 대해 multispectral image pair를 활용한 contrastive leaning으로 사전학습을 수행해 좋은 결과를 얻었습니다. 논문을 읽으면서 아쉬웠던 점은 negative pair를 선정하는 별다른 방법이 없었다는 것이었습니다. KAIST data의 경우 인접 프레임이 매우 비슷하기 때문에 이들을 negative pair로 묶어버리면 문제가 있지 않을까.. 하는 개인적인 생각이 있었는데 전체 데이터셋이 크기 때문에 random sampling을 해버리면 소수의 인접 프레임을 무시해도 되는 것인가 하고 이해했습니다.
감사합니다
안녕하세요. 재연님! 좋은 리뷰 감사합니다.
리뷰를 읽던 중 궁금한 점에 대해서 질문드립니다.
첫 번째는 self-supervised learning은 라벨링이 되어있지 않은 데이터를 가지고 자체적인 학습을 통해 데이터에 대한 표현력을 확보하는 것을 목표로 한다고 말씀해주셨습니다.
그렇다면, 무작위로 0, 90,180,270도의 회전을 가하고 그 라벨을 맞추는 task를 통하여 학습한 특징추출기와 colorization task를 통해 학습된 특징추출기는 유사한 특징을 보게 되는 것인지 궁금합니다.
그리고 라벨링이 되어있지 않은 데이터에서 위와 같은 pretext task를 진행하려면, pretest task를 위한 라벨이 또 필요할 것 같다고 생각됩니다. 그런데 pretest task를 위한 GT는 상대적으로 간단하게 구할 수 있기 때문에 해당 방법으로 학습을 하는 것인가요?
두 번째는 rgb와 thermal이미지 페어를 통해서 self-supervised contrastive learning으로 ResNet과 MLP의 사전학습을 진행하고, 나중에 object detection task를 할 때는 Thermal에 해당하는 부분만 사용을 하는 것인가요?
감사합니다!
안녕하세요, 조현석 연구원님. 좋은 질문 주셨는데, 하나씩 답변 드리겠습니다.
1. pretext task를 이용한 self-supervised learning의 경우 사람이 직접 설계한 휴리스틱한 학습을 하기 때문에 학습 task에 따라 모델이 학습하는 feature가 다르긴 합니다. 그래서 pretext task를 설계할 때는 데이터 자체의 표현력을 모델이 잘 확보할 수 있게 설계해야 합니다. 예를 들어, 직소 퍼즐을 푸는 pretext task의 경우에는 모델이 퍼즐 조각의 이음매나 사진의 색수차에 집중하여 shortcut learning을 하는 것을 방지하고자 다양한 augmentation을 가하게 됩니다(퍼즐의 이음매를 잘라버린다던가 등).
2. 조현석 연구원님 말씀대로 pretext task를 진행하는데 있어서는 pretext task 자체의 라벨값이 필요합니다. 하지만 이는 사전학습을 하는 과정에서 스스로 생성해서 이용할 수 있습니다. rotation의 경우에는 몇 도 만큼 이미지를 회전시킬 지 정할 수 있고, image inpainting 같은 경우에는 이미지 가운데를 drop시키지 않은 원본 이미지가 정답 값이 될 것이고, colorization에서도 색상을 drop시키지 않은 원본 이미지가 GT가 되겠죠
3. 네 맞습니다. 해당 논문의 task는 multispectral object detection이 아닌, thermal detection입니다. 실제 추론에는 thermal image만 input으로 사용합니다.
낯선 분야여서 읽기 쉽지 않았을텐데, 좋은 질문 주셨네요. 화이팅입니다.
감사합니다.
안녕하세요 재연님, 좋은 리뷰 감사합니다.
우선 저 또한 읽으면서 든 첫 번째 의문은 다음과 같습니다. 어찌보면 재연님의 결론과 동일한데요. 본 논문에서 contrasitve learning과정 중 visible-thermal pair간의 동일 씬에 대한 기준을 어떻게 잡을 수 있었던 것인가 입니다.
특히 궁극적으로 이해가 안되는 부분은, self-supervised는 라벨링되어있지 않은 데이터를 가지고 자체적인 학습을 진행하는 것이 핵심인 것으로 이해했는데,
visible image와 thermal image간의 positive pair와 negative pair로 묶이는 과정 자체가 사람의 labeling적인 요소가 들어가는 것이 아닌가 하는 생각이 듭니다. 이것이 self-supervised의 의미에 속할 수도 있는 것인지 의문이 듭니다! 아니면 위 댓글에서 언급하신 것과 같이 pretext task에서의 자체 라벨값을 생성하는 것과 같이 작동하는 것일까요?
만일 random sampling인 경우여도 너무 랜덤성에만 의존하는 것은 아닌가 싶고,,, 그래서 인접 프레임의 영향을 무시할 수는 없을 것 같아, 저도 의문이 듭니다!
여기부터는 본 질문을 드리겠습니다.
일단 이 논문의 주제가 라벨링된 데이터가 아니더라도 visible-thermal modality 모두에 대한 pair 정보를 self-supervised learning으로 잘 학습한 OD가, 기존의 multi spectral supervised learning을 활용한 thermal OD 기법들보다 효과적이었다를 보이고 싶어하는 것으로 이해했습니다.
그런데 제가 생각했을 때 저자의 실험에서 의문인 점은, contrastive learning은 visible-thermal에 정보에 대한 사전학습을 모두 가져간 채로 실험을 진행했는데, 공정한 비교 실험이 되기 위해선 베이스라인으로 사용한 Faster-RCNN 실험 또한 visible-thermal feature를 모두 활용한 multi-spectral 사전학습을 거친 모델에 대한 supervised learning 실험도 비교해야되지 않았을까하는 의문이 듭니다!
그렇게 해야 같은 multi spectral learning을 활용한 thermal OD 태스크에서의 self-supervised와 그냥 supervised의 차이를 알 수 있게 되지 않나라는 생각입니다!
혹시 이것에 관련해서 논문에서 언급한 부분이 있는 것인지, 혹은 제가 잘못 이해하거나 놓친 부분이 있는 것인지 알고 싶습니다!
마지막 질문으로는,
TABLE 2에 있는 Methods에서 w/ feature activation과 그냥 w/ 의 뜻이 무엇인지 궁금합니다!
감사합니다.
안녕하세요, 이재찬 연구원님. 질문에 대한 답변 드리도록 하겠습니다.
1. 결론부터 말씀드리면, 본 논문의 contrastive learning에서 동일 씬에 대한 pair를 이용하는 것은 GT를 사용하지 않는 것이라고 생각됩니다. 해당 방법론에서 학습하고 하는 목표는 detection에 있어서 물체의 class가 무엇인지, 해당 물체의 bounding box는 어디에 있을지이지, 해당 씬들이 어떤 씬인지에 있지 않기 때문입니다. 저희가 URP를 진행할때를 떠올려보면 inference를 수행할 때도 RGB-Thermal pair를 함께 사용했었습니다. 이런 부분을 생각해보시면 어디까지가 GT의 영역인지 감이 오실거라 생각됩니다.
하지만 이재찬 연구원님이 제기해주신 의문이 아예 의미 없지는 않습니다. 일반적으로 우리가 취득하여 가지고 있는 RGB-Thermal pair가 align된 상태의 데이터르 가지고 있다고 상정하지만, 데이터가 완전히 무작위로 섞여 버린 상황도 가정할 수 있을 것 같네요.
2. 두번째로 supervised learning의 경우 thermal image만 이용한 점을 지적해 주셨는데, 그 부분은 이 논문의 task가 multispectral detection이 아닌, thermal detection이기에 그렇다고 생각하시면 될 것 같습니다. 본래 task에 맞게 supervised 방법으로는 thermal object detection만 수행한 것이죠. contrastive learning을 이용한 사전학습을 진행한 뒤에도 downstream task에서는 thermal image만을 사용하여 detection을 수행합니다. 결국 목적은 thermal object detection인데, 여기에 contrastive learning의 적용 유무를 비교한 것이라고 받아들이시면 됩니다. thermal object detection이면 사전학습 단계에서도 RGB 데이터를 이용하면 안되는 것인가? 하고 생각이 들 수는 있는데(저도 그런 의문이 듭니다). 저자가 애초에 실험 세팅을 이렇게 했으니.. 우리로써는 RGB-Thermal pair를 가지고 사전학습을 하고 thermal에 적용하면 이렇게 되는구나 정도로 생각할수밖에 없습니다. 논문들이 항상 완벽한 것은 아니니, 어느정도 비판적인 자세로 읽는 것은 좋은 태도입니다.
3. 저도 해당 부분이 궁금해서 컨에프로 찾아봤는데 TABLE 2 이외에는 어떤 부분에서도 feature activation에 대한 언급이 없었습니다. 아마 기존 방법론들에서 사용된 요소들 중 하나가 아닐까 합니다.
신입 연구원 두 분이 열심히 리뷰를 읽고 열심히 질문을 남겨주시는 모습이 보기 좋습니다. 앞으로도 열심히 하시기 바랍니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
저도 이번 연구를 진행하면서 contrastive learning에서의 negative pair 선정에 대한 방법이 뭐가 있을까 많이 고민해보고 관련 논문을 서베이하는 중에 있습니다. 이 논문에서는 negative pair를 단순히 random sampling해서 선정하였는데 재연님께서는 어떤 방식으로 negative pair를 선정해야 조금 더 좋은 성능을 얻을 수 있을지 따로 생각해보신게 있나요??
그리고 본문에서 transformer Encoder-Decoder의 역할은 무엇인지도 궁금합니다.
감사합니다.
안녕하세요. 정의철 연구원님. 질문에 대한 답변 드리겠습니다.
1. 기존의 SimCLR, MoCo등의 contrastive learning 방법을 차용한다면 적어도 유사한 앞뒤 프레임은 negative pair끼리 묶지 않는 것이 좋지 않을까 하는 생각이 들긴 하지만, 사실 전체 데이터에서 random sampling을 해 버리면 scene에 대한 차이가 의미가 없을 정도로 유사한 인접 프레임들끼리 묶일 확률이 너무 낮기에 크게 고려하지 않아도 되지 않을까 싶습니다. 오히려 instance 단위의 contrastive learning 과정보다는 small object에 대한 정보를 충분히 확보할 수 있는 dense한 contrastive learning을 고민해봐야하지 않나 합니다.
2. 본문에서 transformer Encoder-Decoder는 해당 논문에서 사용하는 Detector인 DETR( https://arxiv.org/abs/2005.12872 )입니다. transformer 기반 detector이니, 그냥 해당 부분은 사전학습 부분이 아니라 feature map을 detector에 넣어서 detection을 수행한 부분이라고 받아들이시면 됩니다.
감사합니다.