이 논문의 주요 키워드
- Temporal Sentence Grounding
- Moment Retrieval
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- DETR 기반 Temporal Grounding에 대한 이해 (Moment-DETR 리뷰)
안녕하세요. 백지오입니다.
서른 두번째 X-REVIEW는 Fully Supervised Moment Retrieval 논문입니다. 이미 몇 차례 소개드린 적이 있지만, moment retrieval은 논문이나 데이터셋에 따라 Temporal Senctence Grounding in Video라고 부르기도 하고, Video Grounding이라고도 하는데요. 결국 자연어 텍스트 쿼리를 이용해 영상 속에서 해당하는 영역을 찾는 task라고 생각하시면 되겠습니다.
Moment retrieval은 어떤 영상 속에서 시작점과 끝점이 있는 영역인 moment를 찾고자 한다는 점에서 이미지 전체에서 어떤 물체의 위치를 특정(localize)하고자 하는 object detection과 유사한 점이 있습니다. 기존의 moment retrieval 방법들은 마치 object detection처럼 사전 정의된 proposal들 중 가장 찾고자 하는 영역일 확률이 높은 proposal들을 선정하고, non-max suppression (NMS)을 통해 중복을 제거하는 과정을 거쳤는데요. 이러한 방법은 사전정의된 요소들이 성능에 큰 영향을 주며, 연산량이 많이 요구되는 단점이 있었습니다. 그러던 2021년, object detection에서 제안된 DETR에 기반한 MomentDETR이 등장하며 이러한 단점들을 극복할 수 있었는데요. MomentDETR은 moment query를 통해 사전에 정의된 proposal이나 NMS와 같은 handcrafted 요소 없이 곧바로 moment의 timestamp를 예측할 수 있었기에, 이러한 방식에 기반한 DETR 기반 moment retrieval 방법론들이 연구되었습니다.(MomentDETR 리뷰) 그러나 이러한 방법들에는 moment query들이 input-agnostic하게 정의되기 때문에 각 입력 영상에 내재된 temporal structure를 간과하는 한계가 존재했습니다. 이러한 한계를 극복하기 위해 저자들은 event-aware 한 동적(dynamic) moment query를 설계하여 모델이 input-specific 한 예측을 수행할 수 있도록 하고자 하였습니다. 이렇게 제안된 EaTR은 대표적인 moment retrieval 데이터셋인 QVHighlights와 ActivityNet, Charades에서 SOTA를 달성하였습니다.

Video grounding은 그림 1a와 같이 주어진 자연어 쿼리에 해당하는 영역의 timestamp를 찾아내고자 하는 task입니다. 이렇게 영상 속에서 어떤 문장과 연관된 영역을 탐색하기 위해서는 video-language 정보를 잘 정합하고, temporal area를 정확히 추정하는 것이 중요합니다.
초기 연구들은 sliding window, temporal anchor와 같이 사전 정의된 구조의 temporal proposal을 수행하였는데, 이러한 방법들은 결국 모델이 handcrafted component에 의존적이게 만들기 때문에 좋은 결과를 얻기도 어렵고, non-max suppression로 인하여 실행 속도도 저하되는 한계가 있었습니다. 따라서, Object detection 분야에서 제안된 DETR을 video grounding에 적용하여 위와 같은 handcrafted component에 의존하지 않도록 한 연구가 최근 주류로 떠올랐습니다.
DETR 기반 방법들은 사전 정의된 proposal을 사용하여 중복이 포함된 여러 개의 예측을 수행하는 기존 방법들과 달리, 트랜스포머 구조를 통해 사전 정의된 proposal이나 중복 없이 예측을 수행할 수 있습니다. 이들은 proposal 대신 moment query라고 하는 학습 가능한 임베딩을 통해 referential search area를 학습하는데, 각 moment query는 먼저 영상과 문장 feature 간의 크로스 어텐션을 통해 찾고자 하는 영역을 탐색하고, 최종적으로 쿼리와 연관된 영역의 timestamp를 찾는 데 사용됩니다. 이러한 방식은 기존의 CNN 기반 방법들보다 높은 성능을 보였으나, 아직 전술한 moment query 기반 방식의 단점을 포함해 많은 부분의 연구가 부족한 상황이라고 합니다. 특히, moment query는 학습 시 general positional information을 포함하기 때문에 그림 1b와 같이 입력과 무관한 고정된 형태의 search area를 갖게 되는데, 이는 비디오가 다양한 길이의 semantic unit (=event)들로 구성되는 것과는 차이가 있습니다. 또한, moment query는 디코더 계층의 video-sentence representation로부터의 동일한 contribution으로 조정되어 중요한 정보를 놓치고 수렴이 늦어질 수밖에 없다고 합니다.
본 논문에서는 영상을 event unit들의 집합으로 정의하고 이들을 dynamic moment query로 처리하는 Event-aware Video Grounding TRansformer, EaTR을 제안합니다. EaTR은 두 가지 level에서의 reasoning을 수행하는데, 1) 영상 속 event unit을 찾고 content and positional queries를 생성하는 event reasoning과 2) moment query들을 입력된 문장과 fuse하고 timestamp를 예측하는 moment reasoning입니다. 먼저, 랜덤하게 초기화된 학습가능한 event slot들이 slot attention을 통해 영상 속에서 event unit들을 찾아냅니다. 찾아진 event unit들을 moment query로 이용하여 input-specific referential search area로 활용되어(그림 1c) 영상과 문장 간 interaction을 포착하고 moment timestamp를 예측하게 됩니다. 이때, gated fusion transformer layer를 통해 쿼리와 무관한 moment query들의 영향을 효과적으로 최소화하고 가장 informative 한 referential search area를 포착하게 됩니다. Gated fusion transformer에서는 moment query와 sentence representation이 유사도에 따라 병합되며, 이렇게 얻어진 video-sentence representation을 트랜스포머 디코더에 입력하여 최종 video grounding 결과를 예측합니다. 복잡하네요.
제안한 모델은 여러 video grounding task에서 SOTA를 달성하였으며 저자들의 contribution은 다음과 같습니다.
- Video-specific event information을 학습하여 temporal reasoning 능력을 향상한 EaTR 제안
- 효과적인 event reasoning과 gated fusion transformer를 통하여 주어진 영상과 문장에서 distinctive한 event를 포착할 수 있음
- QVHighlights, Charades-STA, ActivityNet Captions에서 SOTA 달성
Related Work
Video Grounding. 기존의 video grounding 방법은 크게 두 가지로 나눌 수 있습니다. Proposal 기반 방법은 먼저 여러 개의 후보 proposal을 생성한 후, 자연어 쿼리와의 유사도 순서로 정렬하여 가장 높은 proposal을 예측으로 삼습니다. 대부분의 방법들이 sliding window나 temporal anchor와 같은 사전정의된 proposal을 사용하며, 일부 방법은 가능한 모든 시작-끝 구간을 기반으로 예측을 수행하거나 sentence guidance를 기반으로 proposal을 생성합니다. Proposal-free 방법은 video-sentence interactions를 학습하여 target moment를 바로 예측하는 방식입니다. 어텐션 기법이나 dense prediction 등 다양한 방법을 통해 비디오에서 proposal 없이 예측을 생성하게 됩니다. 그러나 앞선 방법들은 모두 사전 정의된 proposal이나 NMS와 같은 handcrafted 한 요소들, 혹은 중복성으로 인하여 효율이 좋지 않았습니다.
앞선 한계를 극복하고자 최근에는 end-to-end의 DETR 기반의 방법론이 등장하였습니다. 그러나 아직 연구가 많이 진행되지는 않았음에도 DETR 기반 방법의 moment query가 모델의 temporal reasoning 능력을 제한한다는 것이 관측되고 있는 상황이라고 합니다. UMT는 오디오나 optical flow와 같은 추가적인 모달리티를 통해 moment query를 개선하고자 하였으나, 저자들은 추가적인 입력 없이 비디오 자체를 이용해 positional guidance를 개선해보고자 합니다.
DETR and its variants. DETR은 object detection에서 제안된 모델로, 전체 예측 과정에서 모든 handcrafted 요소들을 제거하면서도 성능을 향상한 모델입니다. DETR은 기존 방법론들에 비하여 좋은 성능을 보여주었지만 수렴이 느리다는 단점도 가지고 있었습니다. 후속 연구들은 DETR에서 사용하는 object query의 구조와 cross-attention에서의 작동 방식이 너무 naive하여 query가 cross-attention 모듈에서 어떤 요소에 집중해야 할지 정확히 학습하는데 많은 시간이 걸리는 것이라 주장하였으며, 일부 연구는 object query를 2D 중심 좌표나 4D box 좌표로 재설계하여 spatial prior가 수렴 속도와 성능에 큰 영향을 준다는 것을 밝히기도 하였습니다.
Generic event boundary detection. GEBD는 영상에서 event가 변화하는 경계를 찾고자 하는 task입니다. Event boudnary는 주제 혹은 행동, 환경의 변화 등으로 정의될 수 있으며, 사람이 인지하는 것을 기준으로 합니다. 최근 연구들은 프레임 단위 유사도를 나타내는 Temporal Self-similarity Matrix (TSM)를 활용하여 이를 수행하고자 하였습니다. 특히, UBoCo는 boundary-sensitive feature를 unsupervised recursive TSM parsing 방식으로 찾아내고자 하였습니다. 이러한 연구들은 supervision 없이 event를 찾고자 한다는 점에서 저자들이 제안한 모델과 유사한 점이 있으며, 저자들은 GEBD 연구에서 사용되는 contrastive kernel을 pseudo event information을 생성하는데 활용하였다고 합니다. 그렇다고 전체 process를 가져온 것은 아니고, DETR기반의 video grounding에 적합한 event reasoning network를 새로이 설계하였다고 하네요.
Slot attention. 슬롯 어텐션은 최근 제안된 반복적(iterative) 어텐션 방식으로, object-centric한 representation을 학습하는 것을 목표로 합니다. EaTR에서는 event localization loss와 event reasoning network에 적용되어 시각적으로 유사한 프레임들을 event로 묶는 데 사용되었습니다.
Proposed Method
Background and motivation
Video grounding은 편집되지 않은 영상 $\mathcal U$ 내부에서 주어진 문장 $\mathcal S$와 관련된 영역(moment)의 timestamp를 찾고자 하는 task입니다. 최근 DETR 기반의 방법론들은 학습가능한 referential search area 집합을 의미하는 학습가능한 query embeddings $\mathbf Q$ (moment query)를 정의하고, 트랜스포머를 통해 영역을 end-to-end로 학습하게 하였습니다. Moment query는 역할에 따라 2개의 부분으로 나눌 수 있는데, content query $\mathbf C$와 positional query $\mathbf P$입니다. Content query는 영상과 문장 간의 semantic 유사도를 기반으로, positional query는 위치적 유사도를 기반으로 aggregation을 수행합니다. 기존 연구들은 content와 positional query들을 각각 zero embedding과 학습가능한 임베딩으로 초기화하고, 트랜스포머 디코더를 통해 영상-문장 information을 aggregate 하였습니다. 이러한 방식의 DETR 방법론들은 효과적이지만, input-agnostic 한 moment query는 search area를 모호하게 만들고 학습을 어렵게 합니다.
이러한 문제들을 해결하기 위해 저자들은 영상을 set of event unit으로 정의하는 event-aware video grounding transformer (EaTR)을 제안합니다. EaTR은 주어진 영상 속 event unit을 식별하여 정밀한 referential search area를 나타낼 수 있는 동적 moment query를 제안하며 이들을 sentence information과 융합하여 input-dependent한 예측을 수행하게 됩니다.
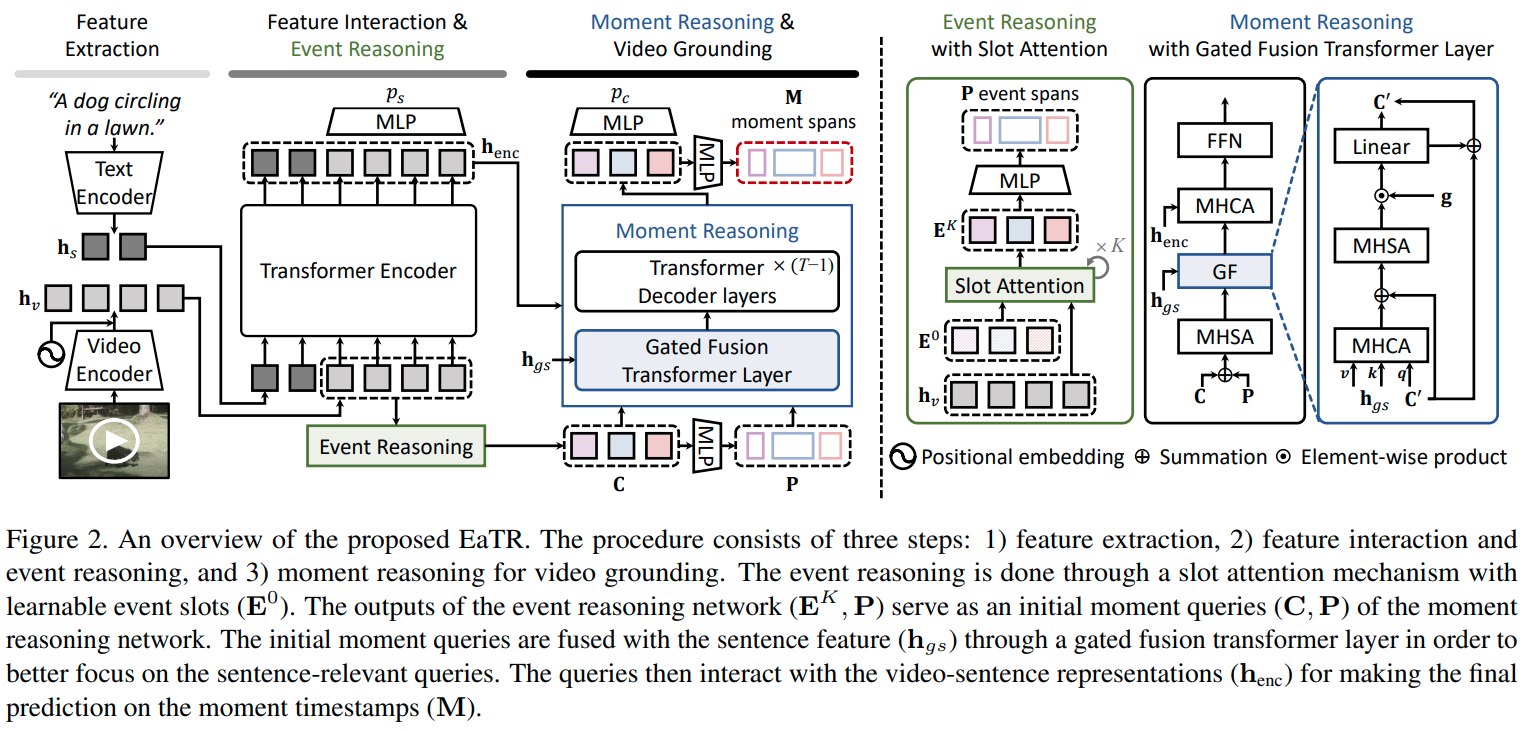
Feature extraction and interaction
길이 $L_v$의 영상 $\mathcal V$와 길이 $L_s$의 쿼리 문장 $\mathcal S$가 주어질 때, 먼저 각각을 사전학습된 백본 신경망으로 인코딩 해줍니다. 이때, 영상은 I3D, 문장은 CLIP을 백본으로 사용하였다고 합니다.
$$ \mathbf h_v = f_v(\mathcal V) + PE\in \mathbb R^{L_v\times d}, \mathbf h_s = f_s(\mathcal S)\in \mathbb R^{L_v \times d}$$
수식에 문장의 임베딩 $\mathbf h_s$가 $L_v\times d$의 크기를 갖는다고 하는데, $L_s\times d$의 오타인 것 같습니다… 아무튼 계속 봅시다. PE는 영상 프레임에 대한 positional embedding, $f_v(\cdot), f_s(\cdot)$는 각각 사전학습된 백본 신경망입니다. Moment-DETR과 유사하게, 저자들은 $T$개의 트랜스포머 인코더를 통해 두 모달리티의 representation이 서로 상호작용하여 영상-문장 representation $\mathbf h_\text{enc}$를 얻었습니다.
$$ \mathbf h_\text{enc}=f_\text{enc}(\mathbf h_v || \mathbf h_s)$$
$f_\text{enc}(\cdot)$은 트랜스포머 인코더, $||$는 concatenate 연산입니다. 이어서, $\mathbf h_\text{enc}$에서 비디오 토큰에 해당하는 영역의 출력을 선형 계층에 입력하여 saliency score $p_s\in \mathbb R^{L_v}$를 얻어줍니다. $p_s$는 각 비디오 프레임(혹은 클립)과 쿼리 문장의 유사도를 나타냅니다. 문장과 유사한 프레임과 유사하지 않은 프레임의 saliency score gap을 키우기 위해 saliency loss를 도입합니다. 여기까지는 MomentDETR과 동일한 구조입니다.
$$ \mathcal L_\text{sal} = \max(0, \alpha + \bar p_{s, out} – \bar p_{s, in})$$
$\bar p_{s, out}, \bar p_{s, in}$은 각각 GT time interval의 안팎에서 랜덤 하게 샘플링된 프레임들의 평균 saliency score이며 $\alpha$는 margin 하이퍼파라미터입니다.
Event reasoning
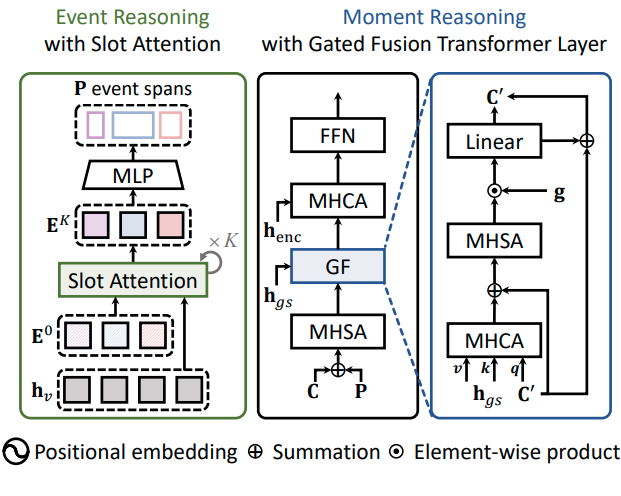
본 논문의 핵심 contribution인 event reasoning 파트입니다. 기존 모델들이 입력과 무관한 moment query를 사용하여 모호한 referential search area를 형성한 반면, EaTR은 영상 속에서 구별적인 event unit들을 찾아내어 이 정보들을 통해 동적 moment query를 초기화합니다.
먼저 $N$개의 학습가능한 event slot $\mathbf E\in\mathbb R^{N\times d}$를 통한 slot attention 방식으로 video representation $\mathbf h_v$로부터 $N$개의 event unit들을 추출해 줍니다. Event slot들은 $\mathbf h_v$와 $K$번 반복적으로 interact 하며 시각적으로 유사한 프레임들을 그룹화하고, final event unit $\mathbf E^K$를 얻습니다. 이때 매 $k$번째 반복마다 $\mathbf h_v$와 $E^k$에 아래와 같이 layer normalization을 수행해 줍니다.
$$\mathbf h’_v = (\text{LN}(\mathbf h_v))\mathbf W_1, \mathbf E’^{k-1} = (\text{LN}(\mathbf E^{k-1}))\mathbf W_2$$
이때 $\mathbf h’_v$와 $\mathbf E’^{k-1}$은 각각 임베딩된 video representation과 event slot들을 의미하며, $\text{LN}(\cdot)$은 layer normalization, $\mathbf W_1, \mathbf W_2$는 각각 선형 투영을 위한 행렬입니다. $h’_v$와 $E’^{k-1}$간의 $k$번째 반복 행렬은 다음과 같이 구할 수 있습니다.
$$\mathbf A^k = \text{Softmax}(\frac{(\mathbf h’_v)(\mathbf E’^{k-1})^\top}{\sqrt d})\in\mathbb R^{L_v\times N}$$
$\text{Softmax}(\cdot)$는 event slot 방향으로의 softmax 함수를 의미합니다. $\mathbf A^k$에서 $k$번째 event slot은 다음 식을 통해 업데이트됩니다. $\mathbf W_3, \mathbf W_4$은 추가적인 선형 투영 행렬입니다.
$$\mathbf U=(\hat{\mathbf A}^k)^\top(\mathbf h_v)\mathbf W_3 + \mathbf E^{k-1}, \text{where }\hat{\mathbf A}^k_{l,n}=\frac{\mathbf A^k_{l,n}}{\sum_{L_v}\mathbf A^k_{l,n}}\\
\mathbf E^k=(\text{LN}(\mathbf U))\mathbf W_4+U$$
일반적인 slot attention과 달리, 저자들은 GRU 계층을 residual summation 연산으로 바꾸어 연산 효율을 올렸다고 합니다. event slot $\mathbf e^K_n\in\mathbf E^K$가 영상 속 각 event에 해당하는 시각적 정보를 가지고 있기 때문에, $\mathbf E^K$를 content query $\mathbf C$의 초기값으로 활용합니다. 추가로, $\mathbf E^K$를 2차원 임베딩 공간으로 투영하여 referential search area의 중심과 길이를 나타내는 초기 positional query $\mathbf P$를 유도합니다.
$$\mathbf P=\mathbf E^K\mathbf W_p = \{ (c_n, w_n) \}^N_{n=1}$$
$c_n$과 $w_n$은 각각 $n$번째 content query에 대응되는 referential time span의 중심과 너비를 의미합니다.
식이 엄청 길었는데, 결국 slot attention이라는 반복적인 연산으로 구성된 어텐션을 통해 video representation $\mathbf h_v$로부터 content query $\mathbf C$와 positional query $\mathbf P$를 유도한 것입니다. Slot attention 대신 크로스 어텐션을 사용할 수도 있지만, slot attention은 slot 간의 경쟁과 선형 투영 행렬 $\mathbf W$의 재활용을 통해 더 효율적으로 더 높은 성능을 보인다고 합니다.
Moment query가 event unit들을 포함하도록 보장하기 위해, event reasoning을 학습하는 과정에서 temporal self-similarity 행렬로부터 pseudo event timestamp를 생성해 줍니다. Uboco에서 사용한 contrastive kernel 방법을 통해 TSM의 대각 성분으로부터 event boundary를 찾아낸다고 합니다. Uboco는 Generic Event Boundary Detection task의 모델인데, moment retrieval에 가져다 쓰는 건 처음 보네요. Boundary score의 thresholding과 sampling을 통하여 각 event unit $\hat{\mathbf P}$의 timestamp를 구하게 되며, 이때 $\hat{\mathbf P}_i \in [0, 1]^2$는 event의 normalized center coordinate와 duration을 나타냅니다. 이렇게 얻어진 pseudo timestamp들로부터 positional query와 pseudo event timestamp 사이의 event localization loss를 정의해줍니다. 예측된 이벤트 집합의 순서가 독립적이기 때문에, positional query들과 pseudo event span들의 optimal assignment를 헝가리안 매칭 알고리즘으로 찾아줍니다. Optimal assignment $\hat{\sigma}$는 pseudo event spans $\hat{\mathbf P}$와 예측된 event spans $\mathbf P$로 아래와 같이 정의됩니다.
$$\hat{\sigma}\arg\min_{\sigma\in\mathfrak G_N}\sum^N_i\mathcal C(\hat{\mathbf P}_i, \mathbf P_{\sigma(i)})\\
\mathcal C(\hat{\mathbf P}_i, \mathbf P_{\sigma(i)}) = \lambda_{l_1}||\hat{\mathbf P}_i – \mathbf P_{\sigma(i)}||_1 + \lambda_\text{iou}\mathcal L_\text{iou}(\hat{\mathbf P}_i, \mathbf P_{\sigma(i)})$$
$\mathcal L_\text{iou}$은 generalized temporal IoU이고 $\lambda_{l_i}, \lambda_\text{iou}$는 밸런싱 하이퍼파라미터입니다. Optimal Assignment가 주어졌을 때, event localization loss는 아래와 같습니다.
$$\mathcal L_\text{event}=\sum^N_i\mathcal C(\hat{\mathbf P}_i, \mathbf P_{\hat\sigma(i)})$$
요약하면, 비디오 feature $\mathbf h_v$와 학습가능한 event slot $\mathbf E^0$에 대하여 slot attention을 $k$번 반복하여 $\mathbf E^k$를 얻고, 이를 MLP에 태워 event span $\mathbf P$를 얻게 됩니다. 이때, GEBD 기법인 Uboco로 얻은 pseudo timestamp $\hat{\mathbf P}$로 학습을 진행하게 되고, 결과적으로 Event들의 timestamp들을 얻게 되는 것입니다.
글로 보면 긴데, 그림 2를 함께 보면 생각보다는 별게 없습니다.
Moment reasoning
이 단계에서는 video-sentence representation과 moment query들을 $T$개의 트랜스포머 디코더 계층을 통하여 aggregate 하여 최종적으로 쿼리와 관련된 이벤트의 moment timestamp를 얻습니다. 앞서 event reasoning 단계에서, moment query들은 입력 영상 속 이벤트들에 대한 정보를 담게 되었습니다. 이제 그들 중에서, 주어진 쿼리 문장과 연관된 moment query를 찾아내고자 하는 것입니다. 저자들은 gated fusion (GF) 트랜스포머 계층을 통해 sentence representation과 moment query를 융합하여 문장과 연관된 moment query를 강화하고 무관한 것들은 억제하고자 합니다.
Enhanced moment query. 먼저 각 positional query $\mathbf p_n=(c_n,w_n)$를 sinusoidal positional encodeing (PE), concat, MLP를 통해 $d$차원 공간으로 투영해 줍니다.
$$ \mathbf p_n \leftarrow \text{MLP}(\text{Concat}(PE(c_n), PE(w_n)))$$
Positional query를 $d$차원 공간으로 확장함으로써, multi-head self attention (MHSA)과 cross attention (MHCA)이 content와 positional query를 입력으로 함께 받을 수 있습니다. Moment query와 global sentence representation을 융합하기 전에, content와 positional query의 합을 MHSA 계층에 입력하여 enhanced moment query $\mathbf C’$를 얻어줍니다.
$$ \mathbf C’ = \text{MHSA}(\mathbf C \oplus \mathbf P)\in\mathbb R^{N\times d}$$
$\oplus$는 element-wise summation입니다. 갑자기 $\mathbf C$가 나와서 뭔가 했는데, 그냥 Event Reasoning에서 slot attention 결과로 나오는 $\mathbf E^k$와 동일한, content query입니다.
Gated fusion (GF) transformer layer. GF 트랜스포머 계층은 $\mathbf C’$와 $\mathbf h_s$에 max pooling을 통하여 얻어지는 global sentence representation $\mathbf h_{gs}$를 입력으로 받습니다. 이때, $\mathbf C’$는 쿼리, $mathbf h_{gs}$는 키와 벨류로 사용하여 MHCA를 수행해 줌으로써 쿼리와 연관된 sentence information을 aggreagte 한 aggreagted sentence representations $\hat{\mathbf C}$를 얻어줍니다.
$$\hat{\mathbf C} = \text{MHCA}(\mathbf C’, \mathbf h_{gs}, \mathbf h_gs) \in \mathbb R^{N\times d}$$
이때, $n$번째 moment query $\mathbf c’_n$과 aggregated sentence representation $\hat{\mathbf c}_n$의 유사도는 무관한 쿼리를 억제하기 위한 gate로 사용됩니다. 즉, 이 값이 높은 쿼리는 sentence와 유사한 것이고 반대는 그렇지 않다는 것이죠. $n$번째 moment query에 대한 gate는 아래의 식을 통해 하나의 스칼라로 나타납니다.
$g_n = \text{Sigmoid}(\mathbf c’_n \cdot \hat{\mathbf c}_n^\top)$$
Gated fusion은 이어서 다음과 같이 정의됩니다.
$$\mathbf C’ \leftarrow \text{Linear}(\mathbf g\odot \text{MHSA}(\mathbf C’ \oplus \hat{\mathbf C})) + \mathbf C’$$
$\odot$은 element-wise multiplication입니다. Enhanced moment query는 이제 video-sentence representation $\mathbf h_\text{enc}$와 modulated MHCA를 통해 상호작용된 후, feed-forward network(FFN)에 입력됩니다.
Moment prediction. GF 트랜스포머 계층 다음으로, moment query는 남은 $(T-1)$개의 트랜스포머 디코더 계층에 입력됩니다. 출력 $\mathbf h_\text{dec}$는 FFN에 입력되어 moment span $\mathbf M$을 예측합니다. 또한 linear layer를 통해 confidence score $p_c \in \mathbb R^N$을 moment query별로 예측해 줍니다. Moment localization을 학습하기 위하여 이진 매칭이 적용된 set prediction loss가 도입됩니다. (이는 기본적인 DETR 구조입니다.) GT moment timestamp $\hat{\mathbf M}_i \in [0, 1]^2$이 주어질 때, optimal assignment를 timestamp 유사도와 confidence score를 통해 헝가리안 매칭 알고리즘으로 구해줍니다.
$$ \hat\sigma’ = \arg\min_{\sigma’\in \mathfrak G_N}\sum^N_i [-\lambda_cp_{c,\sigma'(i)}+\mathcal C(\hat{\mathbf M}_i, \mathbf M_{\sigma'(i)})]\\
\mathcal C(\hat{\mathbf M}_i, \mathbf M_{\sigma'(i)})=\lambda_{l_1}||\hat{\mathbf M}_i – \mathbf M_{\sigma'(1)}||_1 + \lambda_\text{iou}\mathcal L_\text{iou}(\hat{\mathbf M}_i, \mathbf M_{\sigma'(i)})$$
각 $\lambda$는 밸런싱 파라미터입니다. Moment localization loss는 optimal assignment $\hat\sigma’$를 이용해 아래와 같이 정의됩니다.
$$\mathcal L_\text{moment} = \sum^N_i[-\lambda_c\log p_{c, \hat\sigma'(i)} + \mathcal C(\hat{\mathbf M}_i, \mathbf M_{\hat\sigma'(i)}]$$
Overall objectives. 최종 목적함수는 밸런싱 파라미터 $\lambda$들과 함께 아래와 같이 정의됩니다.
$$\mathcal L_\text{overall} = \mathcal L_\text{moment} + \lambda_\text{sal}\mathcal L_\text{sal} + \lambda_\text{event}\mathcal L_\text{event}$$
모델의 전체적인 구조는 DETR을 통해 입력 영상 속 모든 이벤트에 대한 moment query를 만들고, 그걸 이용해서 또 DETR을 통해 쿼리와 연관된 moment를 찾는 것인데, 중간중간에 Slot Attention, Gated Fusion, Uboco를 통한 학습 등 다양한 기법이 추가되어 복잡하게 느껴지는 것 같습니다. 밸런싱 파라미터도 많고 최적화가 쉽지 않을 것 같네요…
Experiments
Datasets and evaluation protocols
저자들은 일반적으로 video grounding에서 사용하는 QVHighlights, Charades-STA, ActivityNet-Captions를 사용했습니다. 평가지표로는 Recall1@IoU m을 사용하였고, QVHighlights에 대해서는 HI@1과 mAP지표를 통한 Highlight Detection도 평가하였네요. 이들은 일반적으로 TSGV에서 사용하는 지표라, 별도로 설명하지는 않겠습니다.
Implementation Details
Feature representations. QVHighlights 데이터셋에는 사전학습된 SlowFast와 CLIP으로 video feature를 추출하였고, 2초마다 feature를 사전추출하였습니다. Charades와 ANet에서는 각각 I3D와 C3D로 feature를 추출하였고, 각 feature vector는 연속된 16개 프레임에 해당하며 50%의 overlap이 존재합니다. 저자들은 ANET에서 각 영상마다 200 개의 feature vector를 uniform 하게 추출하였고, sentence feature로는 CLIP text feature를 활용하였습니다.
Training settings. 트랜스포머 인코더와 디코더의 개수는 $T=3$으로 하였고, 밸런싱 파라미터는 $\lambda_{l_1}=10, \lambda_\text{iou}=1, \lambda_c=4, \alpha=0.2$를 적용했고, $\lambda_\text{sal}$의 경우 QVHighlishgts는 1, Charades와 ANET은 4를 썼습니다. Hidden dimension은 256, 어텐션 헤드는 8을 썼고, 학습은 배치 사이즈 32에서 AdamW로 200 에포크 진행했습니다. weight decay는 1e-4를 썼고 초기 learning rate는 QVHighlights는 1e-4, Charades와 ANET은 2e-4를 썼습니다. 실험은 파이토치 1.12.1과 한 장의 A6000에서 진행했는데, 복원해 보니까 복원이 안되더라고요 하하… 그래도 저자들이 여러 시드에서 실험을 진행하는 등 투명성을 위한 노력은 보여준 것 같은데, 조금 아쉽습니다.
Comparison with SOTAs

먼저 QVHighlights입니다. Video Grounding의 일부 지표에서 EaTR이 SOTA를 달성하였다고 하는데, QD-DETR과 성능차이가 근소하고 오차범위 내에 있어서 애매합니다만, 아무튼 좋은 성능을 보여주긴 한 것 같습니다. QD-DETR과 contribution이 비슷한지 살펴봐야겠네요.
Highlight Detection에서는 다른 방법론들보다 낮은 성능을 보여주는데, 저자들은 highlight를 검출하는 것이 temporal reasoning보다는 오로지 cross-modal interaction 능력에 의존적이기 때문에 EaTR의 contribution과 결이 안 맞는 것으로 보고 있습니다. Highlight의 정의자체가 조금 모호한 감이 있어 일리가 있는 설명인 것 같습니다. 저자들은 모델의 연산량 (GFLOPs)을 함께 리포팅하였는데, 이 부분은 QD-DETR보다 확연히 낮아 좋은 모습을 보여줍니다.
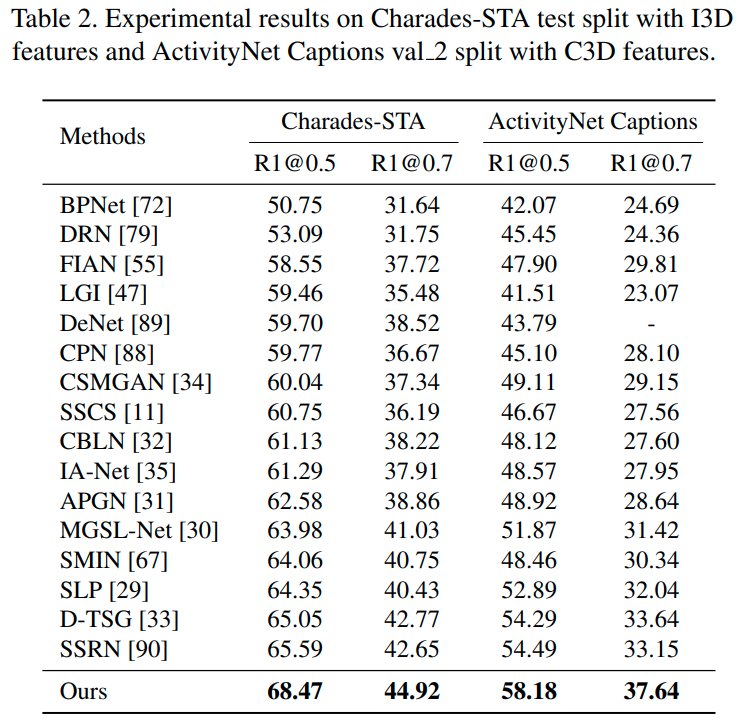
Charades-STA와 ActivityNet Captions에서의 결과입니다. 함께 리포팅한 기존 방법론들의 경우 DETR 방법론이 아니기에 handcrafted 요소들이 많다는 차이가 크다고 합니다. 두 데이터셋에서는 EaTR이 확실히 SOTA를 달성하였네요. 그런데 Moment-DETR과 같은 DETR 기반 방법론들을 함께 보여주지 않은 것은 좀 의아합니다.
Ablation study and dscussion
저자들은 제안한 방법의 핵심 요소를 QVHighlights에서 조금 더 들여다보았습니다.
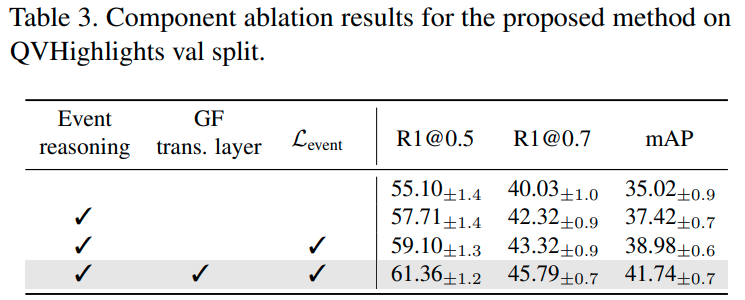
Compoment ablation. 빠지면 섭섭한 제안된 요소별 ablation입니다. Event reasoning, GF 트랜스포머 계층, event localization loss 모두 성능을 향상하는 모습입니다.

Number of moment queries. Moment query의 수 $N$에 대한 비교 실험입니다. Moment query의 수가 곧 referential search area의 granularity와 연관되어 있으므로, $N$이 증가할수록 성능이 증가하지만 너무 커지면 모델이 긴 이벤트를 찾기 어려워지는 문제가 발생하며 성능이 감속합니다. 10에서 가장 좋은 모습을 보였습니다.
Effect of $\lambda_\text{event}$. 밸런싱 파라미터 $\lambda_\text{event}$는 저자들이 제안한 event localization loss의 비율을 조절합니다. 비교 실험 결과, 1~3 구간에서는 $\lambda$의 증가에 따라 성능이 단조적으로 증가하다가 그 이후로 감소하는 모습이 보입니다. 이런 밸런싱 파라미터가 참 설정하기 어려운 것 같은데, 3 이후로 성능이 확 감소하는 것이 참 조절하기 힘들다는 걸 보여주는 것 같습니다.
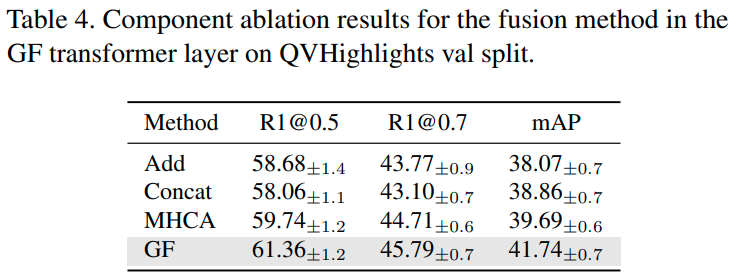
Fusion method in the GF layer. GF 계층에서의 fusion 방식을 비교한 실험입니다. Add와 Concat은 성능이 형편없고, 적어도 MHCA와 같은 계층을 사용해 줘야 문장과 유관한 쿼리와 그렇지 않은 쿼리를 잘 구분할 수 있는 것 같습니다.
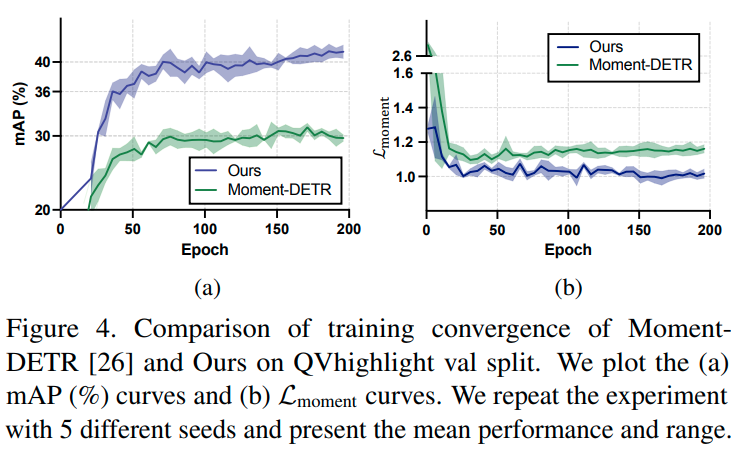
Convergence analysis. 앞서 저자들이 제안한 moment query 기반의 동적 search area 설정이 학습 효율이 좋을 것이라 하였는데, 이를 증명하기 위한 비교실험을 진행했습니다. 확실히 일반 Moment DETR보다 EaTR이 빠르게 수렴하는 모습을 볼 수 있네요.

Attention visualization. 저자들은 initial positional query와 frame positional embedding (첫 줄), final positional query와 frame positional embedding (둘째 줄), final content query와 video-sentence representation (셋째 줄), 전체 moment query와 video-sentence representations with frame positional embedding (마지막줄) 간의 어텐션을 시각화하였습니다. 각 어텐션 맵에서 수평 축과 수직 축은 각각 frame과 query를 나타냅니다. Moment-DETR의 init. positional query들은 고정된 input-agnostic search area를 가지고 있어 서로 다른 두 영상에서도 유사한 어텐션을 보이고 있습니다. 한편, EaTR의 어텐션은 입력 영상에 따라 달라지는 모습을 확인할 수 있습니다.
Conclusion
본 논문에서는 Event-aware Video Grounding Transformer, EaTR을 제안했습니다.
EaTR의 핵심 아이디어는 고정된 쿼리로 인해 어떤 영상이든 input-agnostic 한 search area를 갖는 기존의 DETR 방법과 달리, input-dependent 한 moment query를 사용하여 입력 영상마다 다른 search area를 갖도록 하고, 이를 기반으로 TSGV를 사용하여 학습 속도와 정확도를 개선한 것입니다.
기존 모델의 critical 한 한계를 잘 정의하고 극복한 모델이라 생각되며 그 결과도 실험에서 잘 보인 것 같습니다.
다만, 모델 전체적으로 Slot Attention이나 GF 트랜스포머 등 성능을 개선하기 위한 서로 다른 컨셉의 contribution이 여러 개 들어가면서 method 부분이 상당히 길고 사전지식이 요구되게 된 것 같습니다.
또한, 지적한 기존 모델들의 한계와 contribution 대비 QVHighlights에서의 성능 향상폭이 크지 않은데, 이는 어쩌면 기존 모델들이 QVHighlight에 fit 되어 지적한 한계의 악영향을 크게 받지 않았기 때문으로 보입니다. 따라서 generalization 능력을 볼 수 있는 새로운 지표나, 기존 모델들의 fit 된 정도, 혹은 데이터셋의 bias 등을 추가로 밝혔다면 작은 성능 향상폭을 커버할 수 있는 좋은 근거가 되지 않았을까 하는 생각이 듭니다. (지금도 부족하지는 않지만요.)
감사합니다.