안녕하세요. 박성준입니다.
오늘의 x-review는 2024 CVPR에 개재된 UCA 데이터셋입니다.
Introduction
감시 영상은 보안에 관련해 많은 관심을 이끌고 있지만, 기존의 감시 영상 데이터셋들은 이상 사건들을 분류하고 위치시키는 것에만 집중하고 있었습니다. 저자는 위 문제를 지적하며 감시 영상에서의 비디오, 자연어로 구성된 멀티모달 데이터셋을 제공합니다. 저자는기존의 UCF-Crime 데이터셋에서 영상을 그대로 사용하며 annotation만 바꾼 형태로 UCF-Crime Annotation (UCA)데이터셋을 제안합니다. UCA 데이터셋은 23542개의 문장을 포함하고 있으며 각 문장은 평균적으로 20단어의 길이로 구성되어 있으며, 영상의 길이는 총 110.7시간입니다. 저자는 영상을 구간별로 나누어 각 구간에 해당하는 장면을 자연어 문장으로 설명하는 annotation을 제공했으며, 위 데이터셋을 이용하여 TSGV, VC, DVC, MAD 총 4가지 task의 벤치마크로 활용할 수 있다고 설명합니다.
TSGV(Temporal Sentence Grounding in VIdeo)는 Moment Retrieval과 같은 말로 영상 내에 자연어 쿼리에 해당하는 구간을 반환하는 task입니다.
VC(Video Captioning)은 비디오의 한 장면을 보고 그 장면을 자연어로 설명하는 task입니다.
DVC(Dense Video Captioning)은 사건의 구간을 찾고 그 사건에 대한 자연어 설명을 하는 task입니다.
MAD(Multimodal Anomaly Detection)은 caption을 자연어 기능을 하는 소스로 활용하여 multimodal을 이용해 이상 감지를 하는 task입니다.
저자는 위 4가지 task를 모두 활용할 수 있으며 동시에 각 task별 현 sota 모델을을 벤치마킹하여 UCA 데이터셋의 baseline을 생성해 공합니다.

Related Work
Surveillance Video Datasets
UCSD Ped1, UCSD Ped2, Avenue 등등의 기존의 감시 데이터셋들은 모두 현실 세계에서의 영상과는 다른다는 한계가 존재했습니다. 하지만 UCF-Crime 데이터셋은 실제 감시 영상을 기반으로 만들어진 데이터셋으로 1900개의 감시 영상과 13개의 실제 상황의 이상현상(Abuse, Burglary, Explosion 등)을 영상의 카테고리로 담고 있습니다. 하지만 이런 형태의 annotation은 moment retrieval이나 video captioning과 같은 더 복잡한 multimodal 학습 task에는 적합하지 않습니다. 이러한 문제를 해결하기 위하여 저자는 UCF-Crime 데이터셋에 새로운 annotation을 진행했습니다. 이를 UCF_Crime Annotation, 줄여서 UCA 데이터셋으로 명명했습니다. 기존의 SAVCHOI 데이터셋 또한 UCF-Crime 데이터를 활용하여 annotation만 다르게 했지만 300개의 영상만을 활용했을 뿐만아니라 temporal 정보 또한 많이 부족했습니다. UCA 데이터셋은 1854개의 데이터셋과 상세한 annotation을 했습니다.
Multimodal Video Datasets
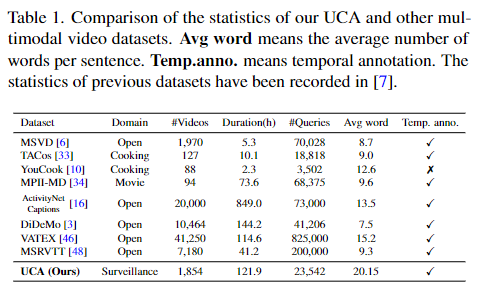
표1은 기존에 있던 다른 multimodal 데이터셋들과의 비교입니다. domain이 감시 영상인 데이터셋은 UCA가 처음입니다.
최근에 상당히 많은 수의 multimodal 비디오 데이터셋이 공개되었습니다. video caption, moment retrieval 등의 다양한 multimodal video task를 해결하기 위해 공개된 데이터셋들은 표1에서 UCA에 비교했습니다. 표1의 모든 데이터셋들은 높은 퀄리티의 영상들을 가지고 있으며, 디테일한 annotation을 가지고 있습니다. UCA와 다른 데이터셋과의 차이점은 바로 도메인입니다. UCA는 특별히 감시 상황을 위해서 준비된 데이터셋이라는 다른 데이터셋들과의 타별점을 가지고 있습니다.
The UCA Dataset
UCA 데이터셋은 real-world 감시 영상으로 구성된 UCF-Crime 데이터셋을 기반으로 하고 있습니다. 기존의 13가지 카테고리로 분류를 하기 위해 구성된 데이터셋을 새로 annotation을 하는 것으로 기존의 퀄리티가 좋고 real-world 기반의 영상들을 활용했고 분류를 위한 카테고리가 존재하는 데이터셋이 아닌 영상의 구간을 세부화시키고 각 구간에 맞는 영상의 장면을 설명하는 자연어 문장 현태의 annotation을 새로 달아 구성한 데이터셋입니다. 구간별로 살세한 자연어 annotation이 존재하기에 TSGV, VC, DVC, MAD의 4가지 video 기반의 multimodal task에서 UCA 데이터셋을 활용할 수 있습니다.
Collection and Annotation
영상을 수집하는 과정에 저자는 UCF-Crime데이터셋에서 퀄리티가 낮은 몇몇 영상을 제외시켰습니다. 낮은 퀄리티라고 함은 반복적인 영상이거나 지나치게 빠른 재생이 포함되어 있어 annotation의 명확성, 구간의 정확성 등을 해칠 수 있는 영상들을 의미합니다. 46개의 영상이 이에 해당되었으며 기존의 1900개의 영상에서 46개를 제외한 1954개의 영상을 UCA에서 채용하여 활용했습니다. UCA데이터셋을 구성하며 UCA데이터셋의 목표는 fine-grained annotations을 제공하는 것입니다. 각각의 사건에 대한 매우 구체적인 자연어 문장으로 annotation을 함으로써 fine-grained annotation을 가능케 했습니다. 각각의 사전이 abnormal(이상)한지 아니면 normal(정상)인지를 구분할 수 있도록 하였으며 총 영상의 86.8퍼센트의 영상에 annotation을 했습니다. annotaion을 하는 과정에서 저자는 총 10명의 자원자를 구해 annotation을 했고 총 3명의 AI 연구자가 이를 검토했습니다. annotation의 정확도와 항상성을 위해 몇몇 가이드라인을 사전에 제작했고 각각의 구간을 정확하게 annotate할 수 있도록 하였습니다.
Dataset Analysis
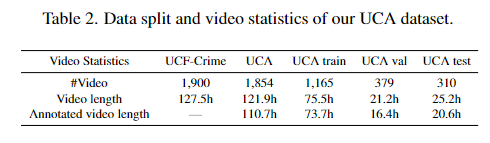
표2는 UCA 데이터셋에서의 영상의 개수 그리고 길이를 보여줍니다. 위에서 설명 드린 것처럼 기존의 UCF-Crime 데이터셋의 1900개의 영상 그리고 127.5시간의 길이를 몇몇 낮은 퀄리티의 영상을 제외하는 것으로 1854개의 영상과 121.9시간의 길이로 구성했으며 이중 annotate되어있는 영상은 총 86.8퍼센트로 110.7시간에 해당합니다.
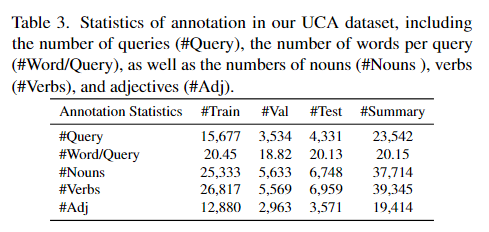
표3은 UCA데이터셋의 자연어 annotation의 통계를 보여주는 표입니다.
Comparison with Existing Datasets
표1에서 다른 데이터셋들과 비교한 것과 같이 UCA와 다른 multimodal video 데이터셋들과의 가장 큰 차이점은 도메인이 다르다는 점입니다. 다른 데이터셋들과는 다르게 UCA는 감시 영상으로 구성된 데이터셋이기 때문입니다. 다른 데이터셋들과의 비교를 통해 UCA데이터셋은 영상의 길이에 알맞은 자연어 문장으로 annotate되어 있다는 것을 저자가 강조하며 자신들이 UCA데이터셋이 잘 annotate되어 있다고 설명합니다. 또한 UCA데이터셋의 영상의 퀄리티가 다른 데이터셋들에 비해 좋다는 것을 강조하는데, UCF-Crime 데이터셋의 영상들을 가져오고 annotation 작업만 수행했지만, 영상의 퀄리티를 자신들의 데이터셋의 강점으로 강조하는 것이 재밌네요. 다른 감시 영상 데이터셋과의 차별점으로는 앞에서의 내용과 마찬가지로 간단한 카테고리 annotation과는 다르게 자연어로 구체적인 이벤트 설명을 한다는 차이점이 있습니다. 결과적으로 UCA 데이터셋은 감시 시나리오에서 다양한 비디오 및 자연어 이해 작업을 수행하는 데에 사용될 수 있습니다. 아직까지 없던 multimodal 감시 영상을 제공한다는 점에서 의의를 가집니다.
Experiments
저자는 3090에서 UCA데이터셋을 이용하여 다양한 task에서의 sota 모델을 활용하여 baseline을 설정했습니다.
Temporal Sentence Grounding in Videos
TSGV는 Moment Retrieval이라고 불리는 task로 비디오와 자연어 문장이 주어졌을때, 자연어 문장에 해당하는 비디오의 구간을 반환하는 task입니다. 비디오와 자연어 문장을 모두 활용하기에 multimodal video task라고 할 수 있습니다. 평가 방법으로는 R@K, IoU=$\theta$를 사용합니다. 이는 $\theta$보다 큰 GT와의 IoU를 갖는 상위 K개의 예측 momnet중에 하나의 비율을 뜻합니다. 예를 들어 R@5, $\theta$=0.3라고 한다면 0.3보다 큰 GT와의 IoU를 갖는 상위 5개의 예측 중에 하나가 GT일 비율입니다. 저자는 R@K for IoU=$\theta$에서 K=1,5 $\theta$=0.3, 0.5, 0.7로 설정했습니다.
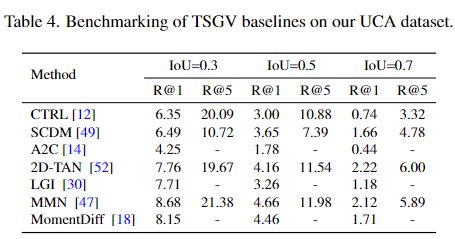
저자는 총 7개의 2017~2023년도 TSGV 방법론들을 활용하여 baseline을 설정했습니다. 위 결과는 UCA에서의 TSGV가 굉장히 challenging한 task임을 보여주고 있습니다. 감시영상인만큼 대상 객체의 크기가 작은데다가 동작또한 큼직하지 않기에 기본적으로 visual feature를 추출하기가 어려웠을 것이라 추측됩니다. 또한 주어지는 자연어 문장이 fine-grained로 굉장히 구체적이고 상세하게 적혀있기에 기존의 모델들이 UCA 데이터셋에서의 성능이 낮게 나오는 것으로 추측됩니다. 밑의 Figure 3.은 TSGV를 시각화한 모습입니다.

Video Captioning
video captioning은 비디오 클립을 이해하고 그에 대한 자연어 설명을 반환하는 task입니다. 평가 메트릭으로는 Bilingual Evaluation Understudy(BLEU)를 사용하여 B@n, n=1,2,3,4로 표현합니다. BLEU는 기본적으로 기계번역에서 쓰이는 평가 방법이지만 caption에서도 생성된 자연어가 얼마나 GT와 유사한가를 통해 평가하기에 BLEU를 사용합니다. BLEU는 측정 기준은 n-gram에 기반합니다.
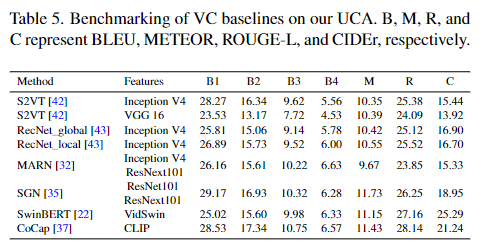
2015 ~ 2023년에 제안된 총 6개의 모델을 baseline으로 설정했으며, TSGV와 마찬가지로 전체적으로 낮은 성능을 보여주고 있습니다. 이또한 TSGV와 마찬가지의 이유로 annotation이 fine-grained하게 정교하고 상세하게 되어있다보니 생성된 자연어 문장과의 유사도가 비교적 낮에 측정되기 때문으로 생각됩니다.

Dense Video Captioning
DVC는 기본적으로 VC와 똑같은 task이지만 추가적으로 captioning을 하는 영상 또한 모델이 찾는 다는 점에서 TSGV와 VC가 섞인 task입니다. 모델이 event가 있는 구간을 제안하고 그 event가 있는 구간에 대한 captioning을 진행합니다. 평가 방법으로는 proposal이 얼마나 정확한지는 recall과 precision을 사용하고 proposal된 영상 클립에 대해 생성한 자연어 문장이 얼마나 GT와 유사한지는 VC에서의 BLEU를 사용하여 평가합니다.
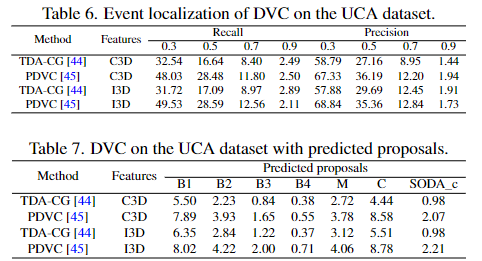
표6은 proposal의 성능을, 표7은 proposal된 구간에 대한 captioning의 성능을 보여줍니다.
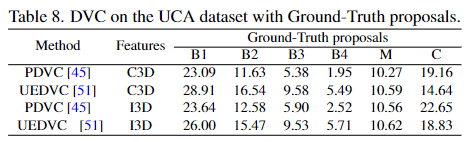
표8은 proposal이 정확하는 것을 전제로 실험한 표로 proposal이 GT일때의 성능을 보여줍니다.
Multimodal Anomaly Detection
MAD는 기본적으로 이상탐지 즉, Anomaly Detection과 일치하지만, 기존의 영상만을 활용하던 task에서 벗어나 자연어까지 활용한다는 점에서 multimodal이 앞에 추가되어 있는 형태입니다. SwinBERT와 같은 video captioning 모델을 활용하여 영상에 대한 caption을 생성하고 영상과 생성된 caption을 모두 활용하여 이상탐지를 하는 task입니다. 따라서 영상의 feature와 caption을 통해 생성된 자연어의 feature를 활용하는 multimodal video task라고 할 수 있습니다.
저자는 기존의 TEVAD 모델을 MAD의 baseline으로 설정했습니다. TEVAD에서와 마찬가지로 저자는 micro-averaged AUC를 사용했다고 밝힙니다. micro-averaged AUC는 모든 비디오 프레임의 AUC score를 concat한 후에 평균낸 지표입니다.
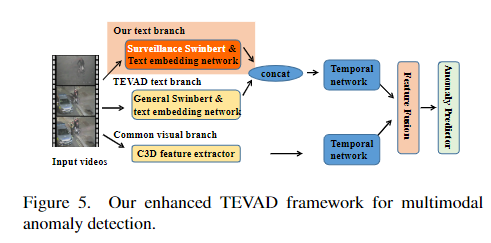
저자는 visual features, temporal features, caption features 총 3개의 features를 합하여 multimodal로 anomaly detection을 수행했고, 기존의 TEVAD에서 SwinBERT를 사용하여 text를 추가하여 활용했습니다.

표9는 visual만 사용했을때, TEVAD를 사용했을때, 그리고 저자가 제안하는 Enhanced TEVAD의 결과를 비교하는 표입니다.

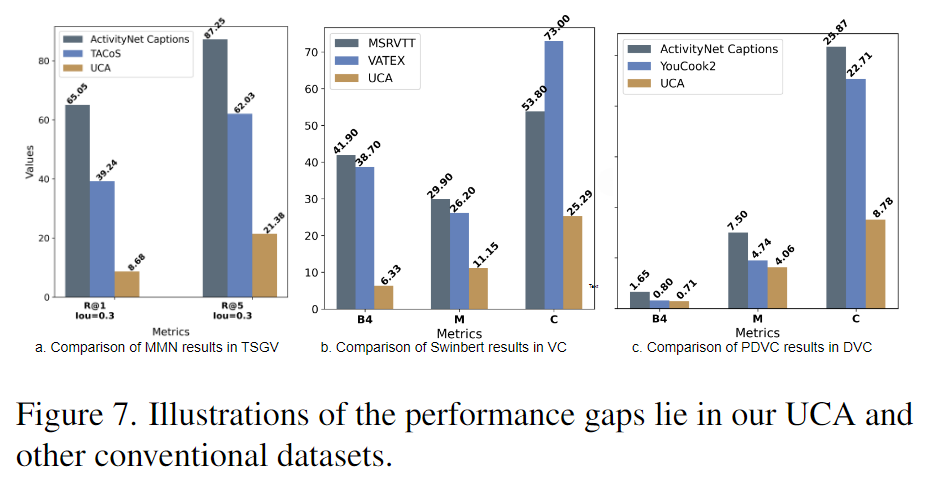
Figure 7.은 UCA와 다른 데이터셋들과의 baseline 모델의 성능들의 비교한 표입니다. UCA가 전체적으로 다른 데이터셋들에 비해 낮은 성능을 보입니다.
Conclusion
현재 multimodal 감시 비디오 데이터셋 연구가 진행되고 있지 않습니다. 저자는 UCF-Crime 데이터셋에 annotation을 새로 다는 것으로 첫번째 multimodal 감시 데이터셋인 UCA를 제안합니다. 저자는 UCA 데이터셋을 통하여 데이터셋 및 모델의 추가 연구의 필요성을 언급합니다.
감사합니다.
안녕하세요. 박성준 연구원님.
길고 낯선 분야의 논문이라 읽기 쉽지 않았을 것 같은데, 수고하셨습니다.
간단히 궁굼한 점이 있는데요, 본 논문에서 제안한 데이터셋이 기존 UCF 데이터셋에서 저퀄리티 영상 일부를 제거하고 어노테이션을 추가로 진행한 것으로 이해했는데 저품질 영상을 제외한 영상 중 annotation 되지 않은 영상은 이벤트가 없는 영상인 것인가요?
감사합니다.
안녕하세요 백지오 연구원님 좋은 댓글 감사합니다.
저자는 퀄리티가 낮은 영상을 분류하는 기준으로 심각한 occlusion, 흐릿한 내용, 지나치게 빠른 재생속도, 그리고 중복 동영상의 존재라고 밝히고있습니다. 실제 감시CCTV로부터 얻은 데이터다보니 심하게 가려지거나, 흐릿한 영상이 존재하고 또 재생속도가 실제 속도와 다르게 너무 빠른 경우, 그리고 같은 영상이 존재하는 경우 UCA 데이터에 포함시키지 않았습니다. 포함시키지 않은 영상은 총 46개로 1900개의 UCF-Crime 데이터셋에서 46개의 영상을 제외한 1854개의 영상을 활용한다고 밝히고있습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
멀티모달을 사용하는 감시 영상 데이터셋에 관련된 연구가 활발하지 않아 제작만으로도 무려 CVPR에 게재될 정도로 큰 contribution을 한 것으로 보이네요.
궁금한 점은 annotation 과정 중에 normal/abnormal을 판별하는 classifier 모델을 사용한 것인가요? 이후 과정은 참여하는 연구자가 직접 fine-grained 하는 과정까지를 annotation 하는 것으로 보이는데, 딥러닝을 통한 annotation 과정은 결국 모델에 의존할 수 밖에 없을텐데 초래하는 문제는 없었는지 궁금합니다.
감사합니다.
안녕하세요 양희진 연구원님 좋은 댓글 감사합니다.
normal과 abnormal을 판별하는 것은 classifier모델을 활용한 것이 아니라 사람이 구분했습니다. abnormal의 경우 총 13가지의 카테고리가 존재하며 각각은 Abuse(학대), Arrest(체포), Arson(방화), Assault(폭행) 등이 존재합니다. normal의 경우에는 위의 13가지 카테고리의 행동이 존재하지 않는 영상으로 실제로 영상을 확인해본 결과 사람이 길을 걸어가는 것과 같은 CCTV에서 흔히 보이는 영상을 normal로 사용합니다. annotation과정은 참여하는 연구자를 포함해 사람이 딥러닝을 통해 나온 annotation의 결과를 확인하고 수정을 하는 과정을 거쳤다고 밝히고있습니다. 딥러닝을 활용하여 수도 라벨링을 하고 다시 사람이 fine-grained하는 과정을 통해 annotation을 진행했는데, 논문에서는 위 과정을 겪으며 생긴 문제에 대해서는 다루고 있지 않습니다. 아무래도 모델의 성능에 따라 결과가 만족스럽지 못한 경우가 존재할 것이라 예상되는데 사실상 사람이 직접 annotation을 진행했다고 봐도 무방할 것 같습니다.
감사합니다.
안녕하세요
1. Related work에서 저자가 UCSD Ped1, UCSD Ped2, Avenue 등등의 기존 데이터셋이 현실 세계와 다르다고 언급한 이유가 무엇인가요? 실제 세계에서 수집한 비디오가 아니라 연기자들이 범죄 클래스를 상정하고 촬영한 데이터셋이라는 의미인가요?
2. 또한 표 3에서 #Summary는 무엇을 의미하는 것인지 궁금합니다.
3. 그리고 Grounding 벤치마크를 위해 UCA 데이터셋의 비디오와 텍스트 feature는 어떠한 backbone으로 추출된 것인가요? 그런 자세한 정보들이 성능을 보는데에 중요하게 작용할 것 같은데, grounding 벤치마크 표에만 해당 정보가 없어 여쭤봅니다.
안녕하세요 김현우 연구원님 좋은 댓글 감사합니다.
1. 논문에서 저자는 기존의 UCSD Ped1, UCSD Ped2 등의 데이터셋들은 현실 세계와 다르거나 데이터의 양이 적다는 한계점이 있다고 언급하고 있습니다만 정확히 어떤 점이 현실에서 다른 것인지는 언급하지 않습니다. 해당 데이터셋들을 실제로 찾아서 확인해 본 결과 USCD Ped1, USCD Ped2 데이터셋은 실제 CCTV감시 영상이지만, 사람이 길을 가고 있는 영상들만 존재합니다. 해당 데이터셋에서의 abnormal 이벤트는 보도에서 보행자가 아닌 객체(자동차, 오토바이 등)가 있는 경우, 혹은 보행자의 일반적인 패턴(걷기, 뛰기 등)이 아닌 경우가 포함됩니다. 영상또한 약 200프레임 정도의 영상으로 짧은 영상인 편에 속합니다. Avenue 데이터셋 또한 CCTV영상이지만 사람들이 다니는 도로의 영상만이 존재합니다. Avenue데이터셋은 16개의 학습 영상, 21개의 test 영상만 존재합니다. 또한 abnormal로 분류되는 행동 역시 USCD Ped 데이터셋과 마찬가지로 사람이 다른 방향으로 걷고 있거나 자전거를 끌고가는 것과 같은 보행이 아닌 경우를 모두 abnormal로 분류하고 있습니다. 저자는 UCF-Crime데이터셋이 다른 데이터셋들에 비해 더 다양한 상황과 더 많은 영상을 가지고 있다는 차별점이 있다고 언급하고 있습니다.
2. 표 3에서의 #Summary는 Train, Test, Val에 있는 모든 쿼리, 단어, 명사, 동사 등의 총 개수입니다.
3. UCA 데이터셋에서 사용한 모델의 backbone으로 저자는 C3D를 사용했습니다. 논문의 마지막 Appendix에서 grounding에서의 implementation 디테일을 설명합니다. 저자는 grounding task를 위해 3090 GPU 24GB를 사용했으며, Sport1M 데이터셋에서 사전학습을 진행하고 UCA에 대해서도 학습을 진행한 후에 사용했다고 밝히고 있습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
본문에서 저자가 제안한 데이터셋은 매우 구체적인 자연어 문장으로 annotation했다고 하셨는데 이렇게 영상에 대한 annotation이 길어지면 Video Captioning 모델이 기존 데이터셋은 간단하게 상황을 어노테이션 했다면 영상에 대한 어노테이션이 길어짐에 따라 모델이 출력하는 스크립도 데이터셋에 따라 길어지나요? Video Captioning 모델의 출력에는 길이 제한이 있는지 궁금합니다.
감사합니다.
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
저자가 논문에서 Video Captioning을 시각화를 한 Figure4 이미지를 보면 GT annotation은 한 장면에 대해서 굉장히 구체적으로 설명하고 있는 것을 확인 할 수 있습니다. 하지만 모델이 Captioning한 자연어는 굉장히 짧은 것을 확인할 수 있습니다. Video Captioning task를 진행해 본적이 없어 확실하지는 않지만, 영상에 대한 annotation이 길어짐에 따라 모델의 captioning도 길어지는 것은 아닌 것으로 생각됩니다. Video Captioning 모델의 출력에 길이 제한은 존재하지 않습니다.
감사합니다.