안녕하세요. 제가 이번에 리뷰할 논문은 3D Detection 논문입니다. 지금 작물의 3차원 인지를 하는 과제를 수행하고 있어서 3D Detection 분야를 읽고 리뷰하게 되었습니다.
Abstract
3D detection 방법론들은 일반적으로 객체의 중심점 feature들을 집계하여 후보 점들을 계산하는 파이프라인을 가지고있습니다. 그러나 후보 점들은 위치 정보만을 포함하며 객체 수준의 모양 정보는 대부분 무시되고 최적의 3D detection이 어렵게 합니다. 본 논문은 3D detection을 위해 의미론적 정보를 기반으로 객체 수준의 형태를 인코딩하는 multi-head attention을 활용한 AShapeFormer 모듈을 제안합니다. 그리고 모양 정보를 완전히 활용하기 위해 shape token과 object-scene positional emcoding을 제안합니다. 또한, 전경의 점들을 샘플링하고 배경 점들의 영향을 억제하기 위해 semantic guidance sub-module을 제안합니다. AShapeFormer를 이용하여 기존 방법론 대비 성능향상을 보였으며, SUN RGB-D와 ScanNetV2 데이터셋에 대한 다양한 실험을 통해 기존 방법론 대비 최대 8.1%의 개선이 이루어짐을 보였다고 합니다.
Introduction
3D detection은 point cloud scene에서 3D bounding box 및 카테고리를 예측하는 것을 목표로 하며, 이는 증강현실, 로봇, 자율주행 등의 다양한 downstream task에 중요한 역할을 합니다. object detection은 2D 도메인에서 상당한 발전이 이루어졌지만, point cloud 데이터의 sparse함과 불규칙하다는 특성으로 인해 3D detection으로의 적용이 어려웠습니다.
3D detection 초기에는 불규칙한 point cloud를 regular 3D 복셀로 매핑한 뒤 특징 추출 및 객체 인식을 위해 3DCNNs를 적용하였습니다. 그러나 이러한 복셀화는 point cloud의 세밀한 정보를 잃어 성능 하락을 일으킨다는 한계가 있습니다. 최근에는 point cloud를 직접 사용하는 방식이 연구되어왔으며, 이러한 방식은 정렬되지 않은 원래의 point cloud에서 3D bounding box를 직접 예측하는 것을 목표로 합니다. VoteNet과 VoteNet의 변형 방법론은 놀라운 성능을 달성하였으며, 이러한 point-wise 방식은 일반적으로 특정 포인트 feature를 후보 포인트로 집계한 뒤 이후 bounding box 예측을 위한 정보로 활용하는 파이프라인을 따릅니다.

이러한 방식은 위의 Figure 1에서 볼 수 있듯 좋은 성능을 보였으나 다음의 문제들이 존재합니다.
- 최종 예측이 후보 포인트의 품질에 크게 의존하지만, 이러한 포인트는 윤곽 및 object의 모양과 같은 중요한 object-level의 정보를 인코딩하지 못함.
- 후보 포인트들에 대하여 regression을 수행하며, 이러한 포인트들은 종종 배경 포인트의 영향을 받아 최종 pose에 오차를 발생함.
이러한 문제를 해결하고자 새로운 feature를 생성하거나 더 많은 포인트를 샘플링하는 시도들이 있었으나, 이러한 방식은 여전히 후보 포인트의 품질에 의존한다는 한계가 있습니다.
이러한 문제를 다루고자 본 논문에서는 AShapeFormer라는 새로운 pluge-n-play neural 모듈을 제안합니다. 이는 기존의 다양한 방법론에 쉽게 결합하여 상당한 성능 향상을 이룰 수 있으며, 저자들의 핵심 insight는 암시적으로 object-level의 정보를 활용함으로써 detector가 물체의 모양 분포를 인식할 수 있도록 하는 것이라고 합니다. 해당 모듈은 물체의 모양 정보를 인코딩하기 위해 multi-head attention 방식을 활용합니다. self-attention 메커니즘을 이용하여 객체 shape feature를 모으며, ViT와 BERT로부터 영감을 받아 pooling 방식과 같이 간단하게 최종 shape feature의 출력을 이용하여 모양 토큰을 도입하여 정보 손실을 방지하고자 하였습니다. 또한, 전경 영역을 더 많이 샘플링하고, 해당 특징에서 서로 다른 가중치를 할당하여 의미론적 정보를 안내하는 메커니즘을 고안하여 모양 feature를 개선시킵니다. Semantic segmentation score를 활용하여 voting 과정에서 관련 없는 포인트의 영향을 줄이고 더 나은 후보를 확보할 수 있도록 하였다고 합니다.
저자들은 point-based 방식과 Transformer 베이스라인을 모두 개선시켜 저자들이 제안한 모듈을 활용할 경우 성능 개선이 가능함을 실험적으로 보였으며, 실험 결과를 통해 AShapeFormer의 multi-class mAP가 SUN RGB-D에서 최대 3.5%, ScanNet v2에서 최대 8.1% 개선이 가능함을 보였습니다.
해당 논문의 contribution을 정리하면
- 기존 다양한 3D detection 네트워크와 결합하여 상당한 성능 개선이 가능한 plug-and-play 방식의 active shape encoding 모듈 AShapeFormer를 제안합니다.
- 강인한 classification과 정확한 bounding box를 regression하기 위해 객체의 shape feature을 인코딩하기 위해 multi-head attention과 semantic guidance를 결합을 최초로 제안하였다고 주장합니다.
- SOTA 방법론을 개선하여 SUN RGB-D(mAP@0.25)와 ScanNet v2에서 상당한 mAP 개선을 이루었음을 실험적으로 벼였습니다.
Proposed Appropach
1. Overview
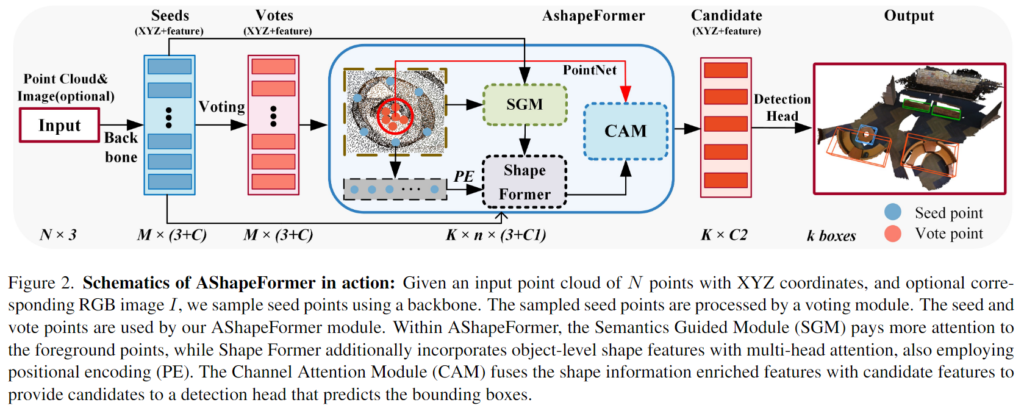
위의 Figure 2는 해당 방법론의 개요로, 3D point cloud P를 입력으로 사용하며 PointNet++ 백본을 이용하여 seed point를 샘플링하고 feature를 추출합니다. 이때, RGB 이미지 I를 선택적으로 입력으로 사용하며, 이미지가 입력으로 주어질 경우 2D 백본을 추가합니다. 이후 voting 단계를 통해 vote points를 구하며, seed point와 vote points를 AShapeFormer 모듈에 입력합니다. AShapeFormer는 Semantics Guided Module(SGM), Channel Attention Module(CAM), ShapeFormer라는 하위 모듈로 이루어져있습니다. object-level의 모양 정보를 더 잘 인코딩하기 위해 SGM은 seed point를 샘플링할 때 전경 포인트에 더 많은 가중치를 주고, ShapeFormer는 multi-head attention 메커니즘을 통해 object-level의 feature를 인코딩합니다. CAM은 shape과 후보 feature를 적응적으로 융합하며, 최종적으로 object-level의 모양 정보를 포함한 feature를 detection head로 공급하여 3D bounding box를 예측하게 됩니다.
2. Object-Level Shape Encoding
저자들은 객체 수준의 형태 정보를 인코딩하기 위해 객체 수준의 shape feature와 후보 feature를 융합하는 CAM(Channel Attention Module)을 제안합니다. indoor 3D detection은 일반적으로 일부의 중심 feature를 예측한 뒤, 후보 포인트 feature를 집계하는 파이프라인을 따릅니다. 먼저 seed point 집합을 \{s_i\}^M_{i=1}(이때, s_i=[x_i;f_i], x_i∈\mathbb{R}^3, f_i∈\mathbb{R}^3), vote point 집합을 \{v_i\}^M_{i=1}(이때, v_i=[y_i;g_i] ∈\mathbb{R}^{3+C})라 정의합니다. 이때, x_i와 y_i 는 seed 와 vote point의 좌표를 나타내며, vote point y_i는 voting 모듈에 의해 x_i 위치가 예측되는 객체의 중심점입니다. 또한, f_i와 g_i는 seed와 vote points의 feature를 의미합니다.
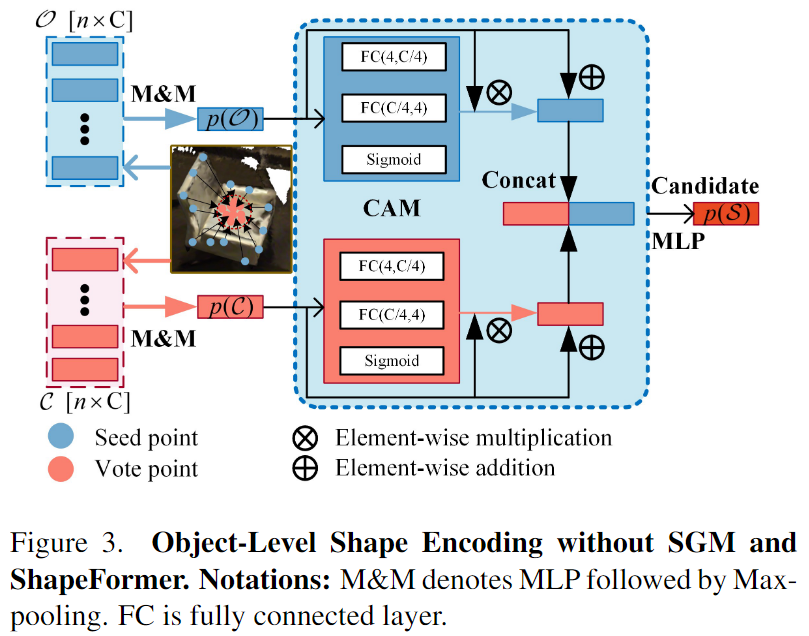
M개의 후보 points \{v_j\}^M_{i=1}를 샘플링하여 K개의 후보 points \{v_j\}^K_{j=1}를 구한 뒤, ball query[1]방식을 기반으로 local grouping을 수행하여 \{v_j\}^K_{j=1}를 중심으로 하는 후보 클러스터 집합 \{\mathcal{C}_1,\mathcal{C}_2,...,\mathcal{C}_k\}를 구합니다. 위의 Figure 3에서 확인할 수 있듯이 각 클러스터 \mathcal{C}=\{v^1_j, v^2_j, ...,v^n_j\}는 아래의 식(1)과 같이 단일 벡터 표현을 얻게 됩니다.
[1] Qi, Charles Ruizhongtai, et al. “Pointnet++: Deep hierarchical feature learning on point sets in a metric space.” Advances in neural information processing systems 30 (2017).
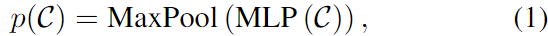
- p(\mathcal{C}): 후보 feature
저자들은 Figure 3에서 볼 수 있듯이 동일한 객체에 위치한 seed point를 사용하여 object-level의 shape feature를 인코딩합니다. 동일한 객체 속하는 vote points는 seed point보다 더 컴팩트하므로 후보 local 그룹핑의 인덱스를 이용하면 seed point를 동일한 객체에 속하는 클러스터 \mathcal{O}=\{s^1_j,s^2_j,...,s^n_j\}로 그룹핑 하는 것이 좋습니다. 객체 모양의 p(\mathcal{O})의 단일 벡터 표현을 얻기 위해 후보 point의 local grouping과 유사한 방식(MLP와 MaxPooling)을 이용할 수 있으며 아래의 식 (2)로 나타낼 수 있습니다.
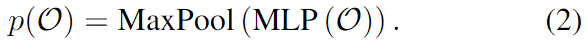
후보 특징 p(\mathcal{C})와 object-level의 shape feature p(\mathcal{O})는 서로 다른 feature space에 분포되므로 이러한 feature를 융합하기 위해 CAM(Channel Attention Module)을 제안하였다고 합니다. CAM은 위의 Figure 3에서 확인할 수 있듯 Sigmoid를 포함한 fully connected layer로 구성되며 다양한 공간의 feature에 대하여 가중치를 적응적으로 학습하여 두 특징을 융합합니다. 후보 feature와 모양 feature는 다음과 같이 결합됩니다.
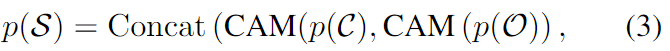
- p(\mathcal{S}): 객체 수준의 모양 정보를 포함한 새로운 후보 feature
p(\mathcal{S})는 detection head에 공급되어 3D bounding box를 생성하며, 실험을 통해 효과를 증명합니다.(실험 참고) 그러나 저자들은 (1)shape key points의 상호작용 과정에 세밀한 정보 손실이 발생하며, (2) 배경 포인트로 인해 정보가 손상됨을 경험적으로 확인하였고, 이를 해결하고자 아래에서 설명하는 ShapeFormer와 Semantic Guided Module(SGM)을 설계하였습니다.
3. ShapeFormer
우선 저자들은 Multi-head attention이 맥락 정보를 모델링하는 능력이 있다고 알려져 있음을 언급합니다. 그리고 이러한 특징은 point cloud를 처리하는 데 적합하지만 많은 연산이 요구되어 어려움이 있고, 이를 회피하고자 객체에 특화된 point를 이용하는 방식을 제안합니다.
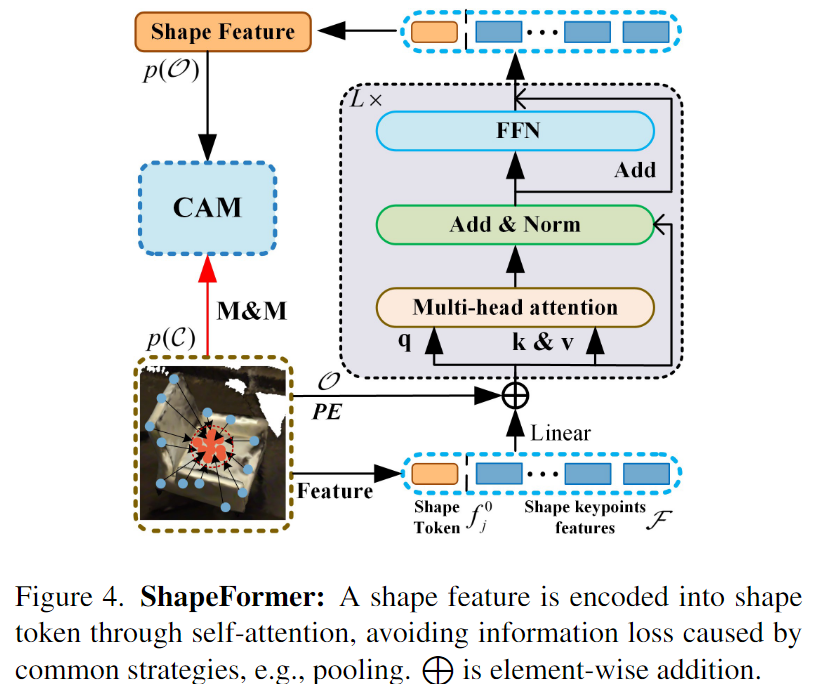
저자들은 ShapeFormer라는 multi-head attention을 기반으로 한 shape 인코딩 모듈을 제안합니다. 위에서 설명한 단순한 방식의 모양 정보 인코딩과 비교하여 ShapeFormer는 더 강력하게 모양 정보를 인코딩합니다. 앞서 설명한 단순한 방식은 MaxPooling을 통해 단일 벡터 표현을 얻기 때문에 디테일한 정보를 잃게 됩니다. 이를 해결하고자 학습 가능한 embedding shape token을 points feature 시퀀스 앞에 추가하고, ShapeFormer의 output의 상태가 object-level의 shape feature 역할을 하도록 합니다. 동일한 객체에 seed points cluster가 주어진 경우(shape key points)\mathcal{O}=\{s^1_j, s^2_j,...,s^n_j\}, 대응되는feature는 \mathcal{F}=\{f^1_j, f^2_j,...,f^n_j\}이며, ShapeFormer의 입력 \mathbf{z}^{(\mathbf{0})}는 다음과 같습니다.
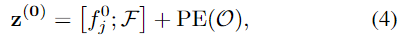
- f^0_j: shape token
- PE(.): positional encoding 함수
입력 \mathbf{z}는 학습 가능한 가중치 행렬 W_q, W_k, W_v에 의하여 query, key, value를 얻게 됩니다.
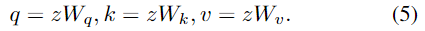
이후 attention 모듈은 다음의 연산을 거치게 되며, 이때 y'는 단일 attention head의 출력이고, m은 attention head의 개수입니다.
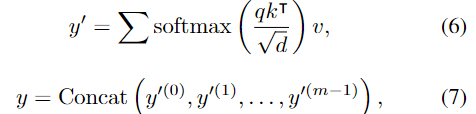
이후 normalization 연산\mathcal{A}(.)과 ReLU와 2개의 linear layer로 구성된 FFN \mathcal{F}(.)을 거쳐 output \mathbf{o}를 구합니다.
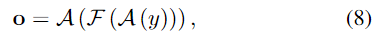
식 (6)-(8)의 연산은 하나의 ShapeFormer layer로 구성되며, l번째 레이어의 출력은 다음과 같습니다.
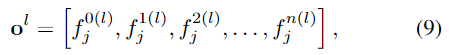
shape token f^{0(l)}_j은 MLP에 입력되어 shape feature p(\mathcal{O})를 얻게 됩니다. p(\mathcal{O})=\mathbf{MLP}(f_j^{0(l)})
Object-Scene Positional Encoding
ShapeFormer에서는 shape key point와 객체의 중심 사이의 상대적 위치 관계에 집중해야 하며, 이러한 관계를 통해 object-level에서 모양 정보를 인코딩할 수 있다고 합니다. 따라서 저자들은 point cloud의 절대적 위치 뿐만 아니라 object-level의 위치를 인코딩하기 위해 Object Scene Positional Encoding을 제안하였으며, 이는 두가지 구성요소로 이루어집니다.
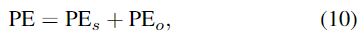
- PE_s: Scene-level positional encoding (절대적 위치로 이해하시면 될 것 같습니다.)
- PE_o: Object-level positional encooding (object-level이라는 것은 객체의 각 요소간의 상대적 위치로 이해하시면 될 것 같습니다)
각 요소는 아래의 식으로 정의되며, s_j^c는 candidate 좌표, s_j^n은 shape key point 좌표, \mathbf{0}는 s와 같은 차원의 0벡터를 나타냅니다.
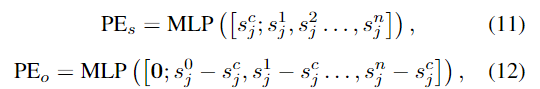
4. Semantics Guided Module
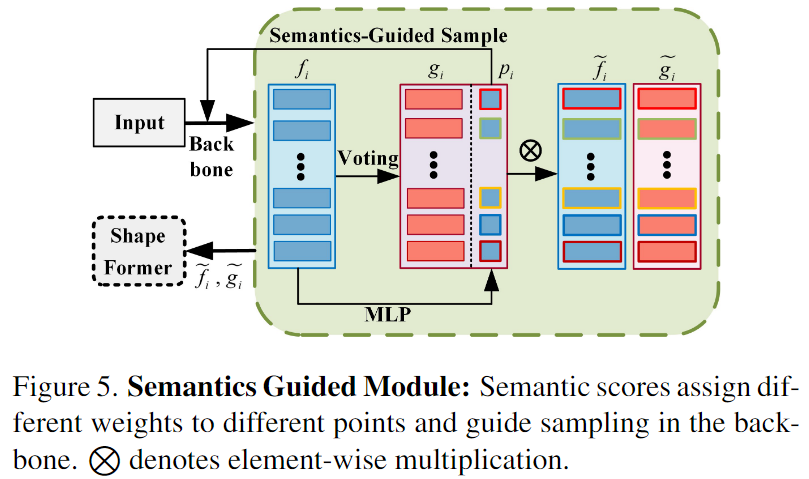
배경의 points는 local feature 추출에 영향을 주며, 이는 필연적으로 shape key point를 통해 모양 정보 인코딩에 부정적인 영향을 주게 됩니다. 따라서 배경의 영향을 완화하기 위해 Semantic Guided Module(SGM)을 제안하여 ShapeFormer를 더욱 개선하였다고합니다. 위의 Figure 5에서 확인할 수 있듯 point cloud의 semantic segmentation score를 예측하기 위해 seed point features f_i는 MLP layer에 입력되어 point cloud가 전경에 속할 확률을 예측하게 됩니다. 이때, point cloud가 bounding box를 기준으로 범위 내에 있을 경우 전경으로 간주하고 그렇지 않을 경우 배경이라 간주합니다. foreground confidence p_i∈[0,1]는 아래의 식 (13)으로 구할 수 있으며, 이때 MLP_s는 다중 MLP layers, \sigma (.)는 sigmoid 활성화함수를 나타냅니다.
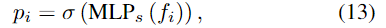
Binary cross-entropy loss를 이용하여 semantic segmentation을 학습하며, segmentation score는 shape feature에 대해 다양한 seed point의 가중치를 조절하는 데 사용됩니다.

가중치를 재할당 한 feature \tilde{f}_i는 ShapeFormer 모듈로 들어가 모양 정보를 인코딩하며, 동일한 방식으로 vote feature의 가중치도 재할당하여 더 나은 aggregation을 수행합니다. 즉, SGM 모듈은 AShapeFormer에서 배경의 영향을 줄이고 전경 point의 feature에 집중하여 보다 정확한 모양 정보를 인코딩하도록 도움을 주는 역할을 합니다.
5. Network Loss
AShapeFormer의 loss는 다음과 같이 정의되며, 이를 통해 end-to-end로 전체 네트워크를 학습한다고 합니다.
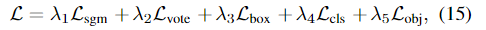
이때, \mathcal{L}_{sgm}는 SGM에서 seed point의 전경과 배경을 예측하는 데 사용되며 아래의 식으로 정의되며,
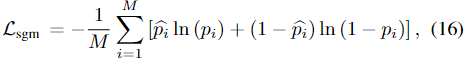
- p_i: 예측된 segmentation score
- \hat{p}_i: GT segmentation score(1: 전경, 0: 배경)
- M: 전체 입력 point 수
\mathcal{L}_{vote}, \mathcal{L}_{obj}, \mathcal{L}_{cls}, \mathcal{L}_{box}는 VoteNet에서 사용한 각 point별 vote regression loss, objectness loss, classification loss, bounding box loss를 의미합니다.
Experiments
AShapeFormer는 plug-n-play라는 속성을 가지고있어 저자들은 기존 3D detection 방법론인 VoteNet, imVoteNet, RBGNet , GroupFree3D에 적용하여 실험을 수행하였습니다. ScanNet 데이터와 SUN RGB-D 데이터에 대하여 AShapeFormer의 성능을 평가하였습니다.
Comparisons with SOTA
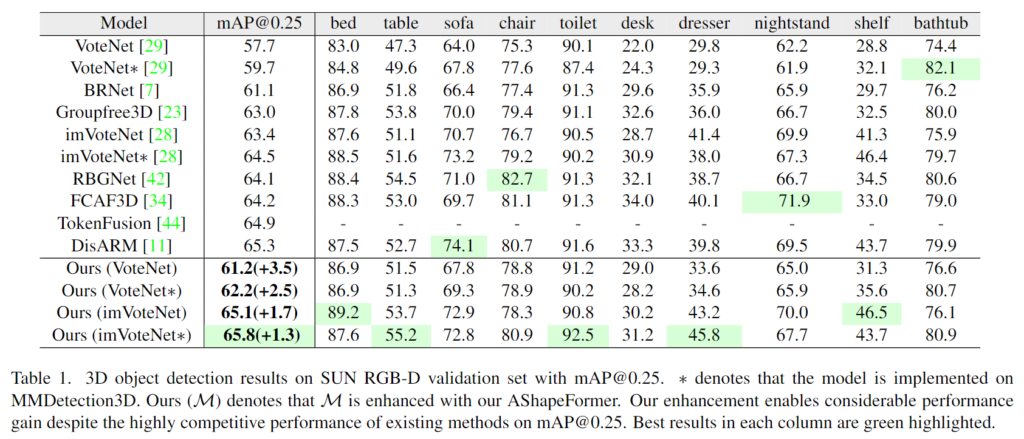
위의 Table 1은 SUN RGB-D에 대한 결과로, VoteNet과 imVoteNet에 대하여 각각 3.5%와 1.7% 이상의 성능 개선을 확인할 수 있습니다. 특히 imVoteNet*에 적용된 AShapeFormer는 mAP@0.25에서 65.8%의 성능을 달성하여 기존 방법론 대비 가장 높은 정확도를 기록하여 저자들의 방법론의 효과를 입증하였습니다.
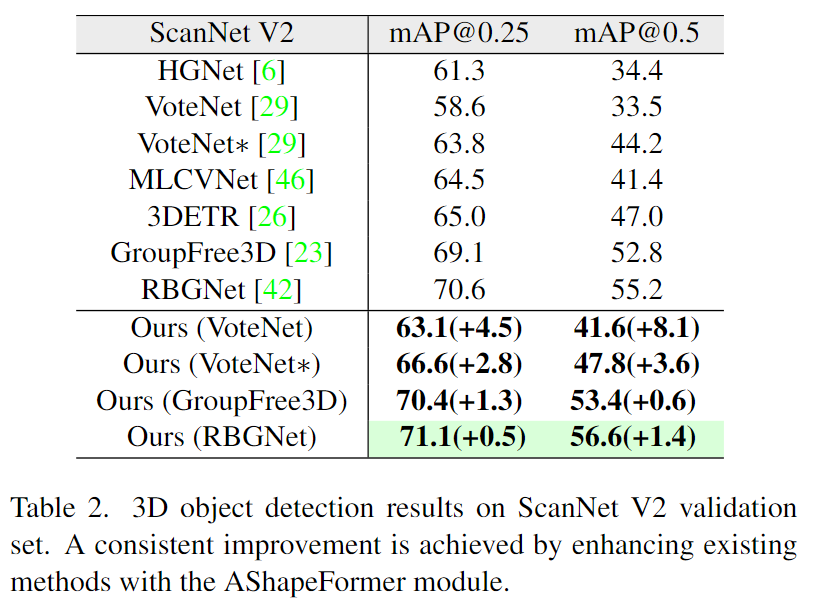
위의 Table 2는 ScanNet v2의 결과로, VoteNet을 기준으로 해당 방법론은 mAP@0.25와 mAP@0.5에서 각각 4.5%와 8.1% 성능 개선을 보였습니다. ASahpeFormer를 최신 Transformer 방법론인 GroupFree3D와 RBGNet에 적용할 경우에서 성능 개선이 이루어짐을 실험적으로 보였습니다.
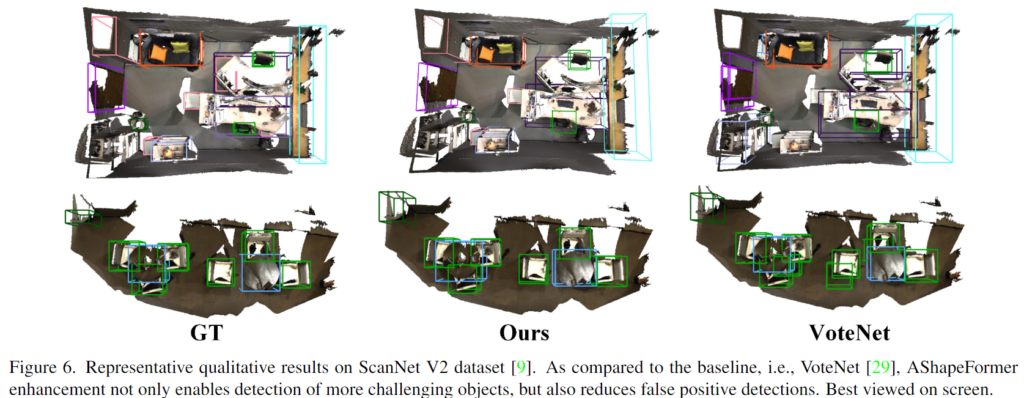
다음은 두 데이터셋에서의 정성적 결과를 나타낸 것으로 기존 방법론 대비 더 정확한 bounding box를 안정적으로 얻을 수 있음을 보입니다. 먼저 Figure 6은 ScanNet에서의 VoteNet과의 비교 결과로, 첫번째 행을 통해 VoteNet이 놓친 왼쪽 위의 객체를 AShapeFormer를 이용할 경우 탐지할 수 있었으며, 두번째 행의 경우 테이블 주변에 3개의 의자가 있을 때, VoteNet은 오탐지하여 5개의 의자가 있다고 판단하는 반면 ASahpeFormer를 이용할 경우 3개의 의자만을 탐지하는 것을 확인할 수 있습니다.
아래의 Figure 7은 SUN RGB-D에 대한 실험 결과로, imVoteNet과 imVoteNet에 AShapeFormer를 적용한 결과를 정성적으로 나타내었습니다. 2,3열을 통해 imVoteNet에 비해 오탐지가 줄어듦을 확인할 수 있습니다. 또한, 1열에서 보라색 박스에 대해 저자들은 GT에서 라벨링되어있지 않은 테이블을 감지할 수 있다는 것이라고 하며, 이를 통해 AP 지표로는 확인하기 어려운 AShapeFormer의 능력을 어필합니다.

Ablation Study and Disscussion

위의 Table 3은 IoU가 0.25일 때 SUN RGB-D 데이터에서 각 요소를 VoteNet에 적용하여 비교 실험을 수행한 것입니다. Naive 방식은 배경의 point가 포함되며 pooling layer를 통해 shape 정보를 잃게 되므로 비교적 적은 수준의 성능 개선이 이루어지는 것을 확인하였다고합니다. SGM를 함께 사용할 경우 의미론적 정보를 통해 더 많은 전경 point를 샘플링하고 shape encoding에서 배경의 영향을 줄일 수 있으므로 상당한 개선(1.8%)이 이루어짐을 확인할 수 있습니다. Shape Former를 이용할 경우 Naive+SGM을 이용한 결과보다 더 좋은 성능을 확인할 수 있으며, 추가로 SGM을 함께 사용할 경우 디테일한 정보 손실을 막아 성능이 크게 개선됨을 확인할 수 있습니다.

위의 Figure 8은 SGM모듈의 장점을 확인하기 위한 것으로, 위의 행에서는 seed point와 vote point에 상당한 이상치(배경에 존재하는 point)가 존재함을 확인할 수 있습니다. 그에 비해 두번째 행은 SGM을 적용한 실험 결과로, 객체 영역에 포인트가 집중되어있음을 확인할 수 있습니다. 이를 통해 shape encoding 및 voting에 유의미한 영역이 영향을 주어 더 좋은 후보 point를 제공할 수 있음을 입증하였습니다. 해당 시각화 결과를 통해 저자들이 의도한 목적에 따라 설계한 네트워크가 제대로 역할을 수행하고 있음을 확인할 수 있어서 상당히 인상적이였습니다.
안녕하세요, 좋은 리뷰 감사합니다.
3D detection task에서는 주로 포인트 클라우드의 특징을 어떻게 임베딩 잘하는지에 다양한 연구가 활발하게 진행되고 있는 것 같습니다.
질문 두 가지 정도만 드리자면,
1. voting은 결국 seed point에 대한 representation point를 뽑기 위한 과정인가요? 아니면 seed point들에 대한 clustering points를 형성하는 과정인가요? 혼동이 와서 간단하게 설명해주시면 감사하겠습니다.
2. 식(10)에서 설명해주신 positional encoding 각각(scene-level/object-level) 6D에서 사용되는 3D 모델을 기준으로 하는 것처럼 사전에 정의된 3D 모델의 좌표를 scene-level, 영상 내 존재하는 포인트 클라우드 만큼 변환된 정도를 object-level로 보면 되는 걸까요?
만약 그렇다면 기준은 모두 포인트 클라우드가 되는데, 3D detection에서의 포인트 클라우드에 대한 절대적인 위치는 어떻게 정의가 되는지 궁금합니다.
감사합니다.
안녕하세요. 리뷰에 대하여 몇가지 질문이 있는데요.
가장 먼저 Seed point와 Vote point의 차이가 무엇인가요? 3D point cloud에서 특징이 될만한 대표적인 포인트들을 Seed point라고 하고, voting point들은 객체의 중심지점을 가리키는 점들을 말하는건가요? 그럼 voting point들은 입력으로 seed point를 받는 건가요? 그림2를 보니깐 Seed point를 입력으로 하는 것 같아 보이긴 하네요.
둘째로, 그림3 (또는 수식1~2)에서 Seed point와 Vote point에 대하여 MLP layer 이후 Max pooling을 한다고 나와있는데, 3D point를 max pooling한다 함은 무엇을 의미하나요?? 이미지는 일정 커널 내부에 값들 중 가장 큰 값을 픽하는 것인데, 3D point 같은 경우에는 maxpooling을 어떤식으로 진행하는지 궁금하네요.
마지막으로 shape token이라고 함은 어떻게 구현이 되는건가요? 그냥 다른 shape keypoint feature와 동일한 차원을 가지는 learnable parameter를 추가해준 뒤 input으로 함께 넣어주면 되는건가요?
그럼 여기서 shape token이 정말로 object의 detail shape을 가지고 있다라는 것을 어떻게 증명하는거죠? 가령 ViT가 classification을 수행할 때는 classification token이라는 것을 임의로 추가해준 뒤 최종적으로 classification token을 토대로 Cross Entropy loss를 계산하기 때문에 classification token이 영상의 분류를 수행하는 정보를 담게 되는 것인데, 실제로 shape token의 경우에는 어떻게 loss를 계산하거나 또는 활용되기에 shape keypoint가 지니지 못하는 디테일한 정보들을 담고 있는 것인가요??
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
최근에 기존 votenet의 voting 방식 결과로 만들어지는 grouping 결과를 문제로 정의한 논문을 읽었는데 비슷한 문제를 해결하고자 하는 논문인 것 같아 흥미롭게 읽었습니다.
먼저 궁금한 점은 shape feature라고 함은 정확히 어떤 정보를 의미하나요 ?? 저는 보통 xyz 좌표와 기존의 백본을 타고 나온 feature를 사용하는 것을 기본으로 알고 있어서 추가적으로 어떤 정보를 담고자 하였는지가 궁금합니다. 하나의 포인트에서 shape에 대한 정보를 알 수 있다는게 신기하네요 ..
다음은 “동일한 객체에 속하는 vote points는 seed point보다 더 컴팩트하므로 후보 local 그룹핑의 인덱스를 이용하면 seed 포인트를 동일한 객체에 속하는 클러스터로 그룹핑하는 것이 좋습니다“라는 설명이 잘 이해가 되지 않는데, 시드 포인트를 일차적으로 그룹화한 집합이 C라고 이해하였는데 후보 로컬 그룹핑의 인데스를 이용하여 시드 포인트를 동일한 객체에 속하는 클러스터로 다시 그룹핑하게 되는걸까요 ..? 제가 이해한 것이 맞다면 해당 과정이 필요한 이유가 무엇인지, 혹 아니라면 과정에 대한 추가적인 설명 해주시면 감사하겠습니다 !
이승현 연구원님 좋은 리뷰 감사합니다.
몇 가지 궁금한 점이 있어 댓글 남깁니다!
Figure1에 대한 언급을 하셨을 때,
“최종 예측이 후보 포인트의 품질에 크게 의존하지만,
이러한 포인트는 윤곽 및 object의 모양과 같은 중요한 object-level의 정보를 인코딩하지 못함.”
이라고 작성해주셨는데, object-level의 정보를 인코딩하지 못하는 가장 큰 원인이 무엇인가요?
2번째 이유인 배경 포인트에 대한 영향 때문인가요?
품질이 좋으면 당연히 윤곽이나 모양 정보도 당연히 쉽게 알아차릴 것 같은데 그렇지 않다는 것이 신기해서 질문드립니다.
다음으로 윤곽이나 모양 정보에 대한 추가적 정보 획득이 어려워서, 클래스 별 성능 차이가 큰 것인가요?
저자가 제안하는 방법론이 자세한 모양 정보를 추가해서 학습에서 바라보겠다는 것 같았는데…
테이블 1을 보면, Sofa/Chair/Desk/Nightstand 와 같이 다리가 있는 클래스에 대해서는
오히려 성능 드랍이 일어났다는 점에서 정말 Shape feature를 잘 뽑아낸게 맞는지 궁금합니다.