네 오늘도 마찬가지로 TTA 분야의 논문입니다.
CVPR 2023에 게재된 논문이구요, 제목에 Backward-free 라는 키워드가 뭔가 끌려서 한번 읽어보게 되었습니다.
그럼 리뷰 바로 시작하도록 하겠습니다.
1. Introduction
오늘 제가 리뷰드릴 논문은 앞서 작성한 TENT, 그리고 CoTTA 리뷰와 동일한 TTA라고 하는 task를 수행하게 됩니다.
Test-Time Adaptation, 줄여서 TTA는 이름에서도 알 수 있다시피 Test-Time에 domain adaptation을 잘 수행하고자 하는 task입니다. 상대적으로 더 활발하게 진행되고 있는 UDA(Unsupervised Domain Adaptation)와 비교했을 때 절대적으로 수행하고자 하는 것이 domain adaptation이라는 것은 같지만, 절대적인 목적과 세부적인 목표사항 등이 조금은 상이합니다.
UDA와 TTA의 가장 큰 차이점은 source domain으로의 접근 가능 여부 입니다. UDA는 source->target으로의 adaptation 수행 시 source dataset의 data와 label을 모두 사용할 수 있지만, TTA는 task 특성 상 source dataset으로의 직접적인 접근 없이 오로지 target dataset의 data x만을 사용하여 source to target adaptation을 수행하는 것이죠.
그렇기 때문에 UDA 대비 TTA는 조금 더 application적인 관점에서 많은 연구들이 수행되곤 합니다. 물론 모델의 성능도 중요한 관전 포인트이지만, 모델의 추론 속도나 adaptation 속도도 함께 고려되곤 하죠.
위에서 설명드렸다시피 real world로의 application을 고려한 TTA 연구들을 저자는 backward 관점에서 크게 2가지로 분류합니다. 1) backward-based 방법론, 2) backward-free 방법론으로 말이죠.
아래에서 2가지 방법론에 대한 효과적인 설명을 위해 그림을 미리 첨부하도록 하겠습니다.
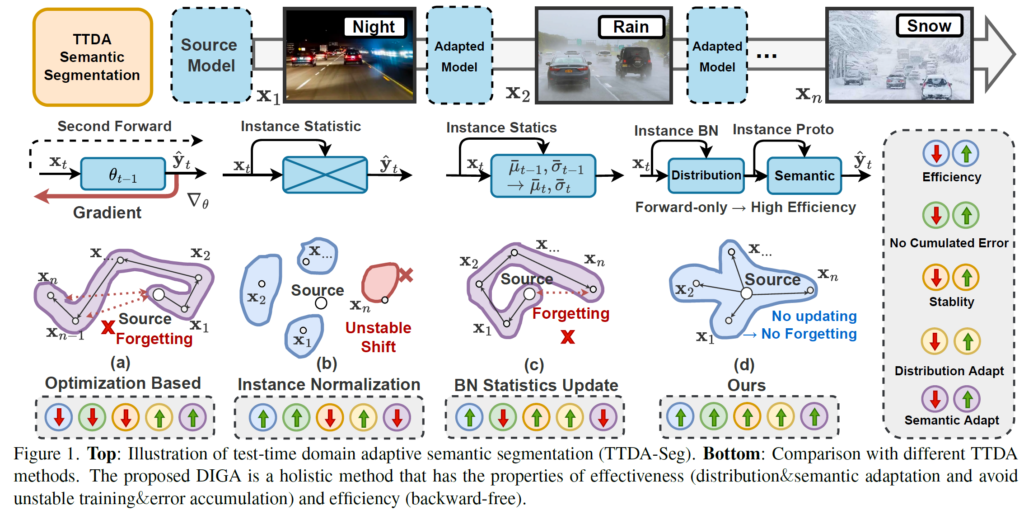
1) Backward-based TTA
첫번째로는 Backward 기반의 TTA 방식입니다.
제가 앞서 리뷰한 TENT, 그리고 CoTTA 도 이에 해당하며, 위 그림 1의 (a)에 해당합니다.
입력으로 들어오는 target sample x_t에 대해 gradient가 계산되면서 역으로 backward가 수행되는 것을 그림으로 확인하실 수 있습니다.
해당 방식들은 Test 단계에서 입력으로 들어오는 test sample에 대해 self supervision loss (ex. entropy loss)를 계산해서 모델을 backward 로 업데이트해 나갑니다. 이때 대부분의 연구들은 모델의 BN parameters만을 update하죠.
이를 통해 distribution adaptation뿐만 아니라, semantic adaptation 또한 수행된다고 저자는 표현합니다. 하지만 이들은 크게 2가지 문제점이 존재합니다.
i) Low-efficiency
어찌됐건 test 단계에서 entropy loss를 최소화하는 과정 속 backward 가 수행되기 때문에 그만큼의 computation cost가 필요합니다.
ii) Unstable optimization & Error accumulation
TTA의 특성 상 test 단계에서 입력으로 들어가는 batch size는 작습니다. 이런 작은 batch에 대해 gradient가 계산되고 모델이 update되기 때문에 모델이 어떠한 순서로 test sample을 만나는지, 즉 랜덤성에 의해 모델이 크게 좌지우지 되는 unstable optimization 문제가 존재합니다.
물론 이러한 문제는 test batch를 늘림으로써 해결할 수 있긴 하지만, 이 경우에는 누적된 error로 인해 모델이 이전 source data에 대해 잘 학습된 지식을 forgetting 하게 됨으로써 성능의 degration이 발생하게 된다는 문제가 추가적으로 발생합니다.
2) Backward-free TTA
두번째로는 Backward-free 기반의 TTA 방식입니다.
이들은 backward 과정이 아닌 forward 과정에서 batch normalization의 통계값(평균, 표준편차)을 사용해서 모델의 distribution 관점에서의 adaptation을 수행하고자 합니다.
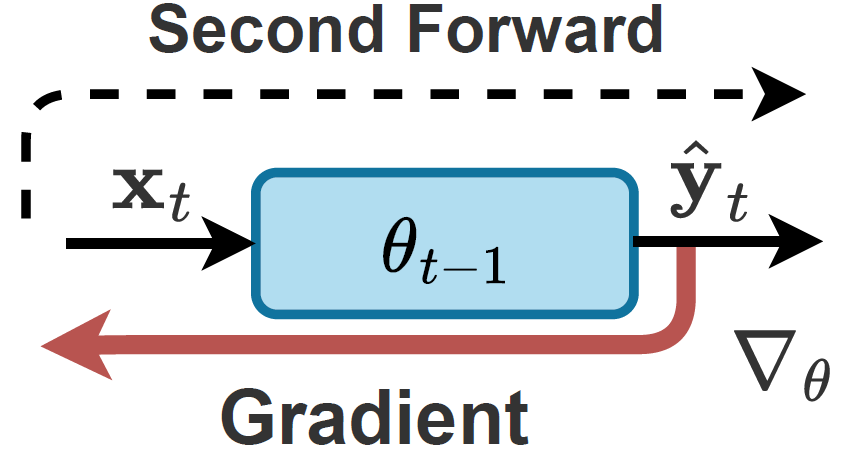
위 그림 1의 (b)는 backward-free TTA 기법 중 하나입니다. 이는 아래 그림과 같이 기존 source에서 계산된 통계값 대신 test sample(instance)의 통계값을 대체해서 사용하게 됩니다. 하지만 이 경우 source에 대해 축적해놓은 기존 지식을 버리는 것이기 때문에 test sample의 variation이 크다면 매우 불안정한 adaptation이 수행될 수 있다고 저자는 주장합니다.
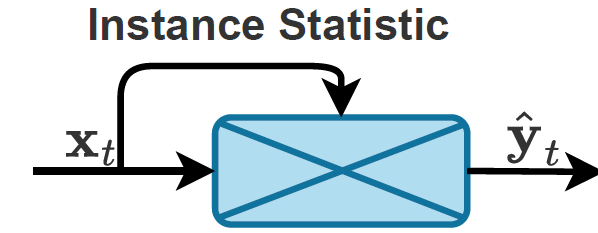
또한 위 그림 1의 (c)는 test sample(instance)의 통계값으로 source 통계값을 대체해 버리는 (b)의 hard한(?) 방식과는 달리 momentum을 적용해서 점차적으로 update해 나가는 방식을 채택합니다. 아래에서 보시는 것과 같이 t-1시점의 통계값에 target sample 통계값을 잘 버무려서(?) t 시점의 통계값으로 사용하는 것을 보실 수 있습니다.
하지만 이러한 방식은 semantic한 정보에 대한 고려 없이 단순히 통계값, 즉 data의 distribution관점에서만 adaptation을 진행하는 것이기 때문에 부적절한 target sample이 입력으로 연속해서 들어오게 되면 점차적으로 에러가 누적되는 문제가 발생합니다. momentum 방식으로 통계값을 update해 나가기 때문에 계속 누적이 되겠죠.
이전 연구들의 단점들은 보완하고, 장점만을 취합해서 저자들은 Dynamically Instance-Guided Adaptation(DIGA) 라고 하는 새로운 접근법을 제안하게 되며, 이에 대한 모식도는 아래와 같습니다.
DIGA의 메인 핵심은 기존 TENT, CoTTA와는 다르게 non-parametric 방식으로 adaptation을 수행하고자 했습니다. Backward-free 라는 이야기죠.
또한 distribution 관점에서 뿐만 아니라 semantic 관점에서도 adaptation을 수행하기 위한 장치를 마련하게 됩니다.
이를 위해 저자가 설계한 두 모듈은 distribution adaptation module (DAM), 그리고 semantic adaptation module (SAM) 입니다.
(Segment Anything Model 아닙니다..ㅎ)
DAM은 한층 더 robust한 representation을 습득하고자 단순 현재의 target sample에 대한 BN 통계값만이 아닌, source와 현재 target 통계값을 weighted sum 계산하여 사용한다고 합니다.
(음.. 어떻게 보면 기존 backward-free 방식의 momentum update와 컨셉은 비슷하다고 생각이 드네요)
또한 semantic adaptation 수행을 위한 SAM은 과거의 prototype과 현재 target instance의 prototype을 잘 섞어서 dynamic non-parametric classifier를 만들게 됩니다.
말이 조금 어려울 수 있는데, non-parametric방식을 유지하면서 semantic 한 정보까지 고려하기 위해 semantic prototype 개념을 도입해서 target instance sample이 들어올 때 마다 점차적으로 update해 나간다고 이해하시면 됩니다.
이에 대한 자세한 설명은 아래 method에서 드리도록 하겠습니다.
2. Method
본 논문에서 설계한 distribution adaptation module (DAM)과 semantic adaptation module (SAM) 은 기존 model에 plug-in 방식으로 간단하게 탈부착이 가능하다고 합니다. 아래처럼 말이죠.
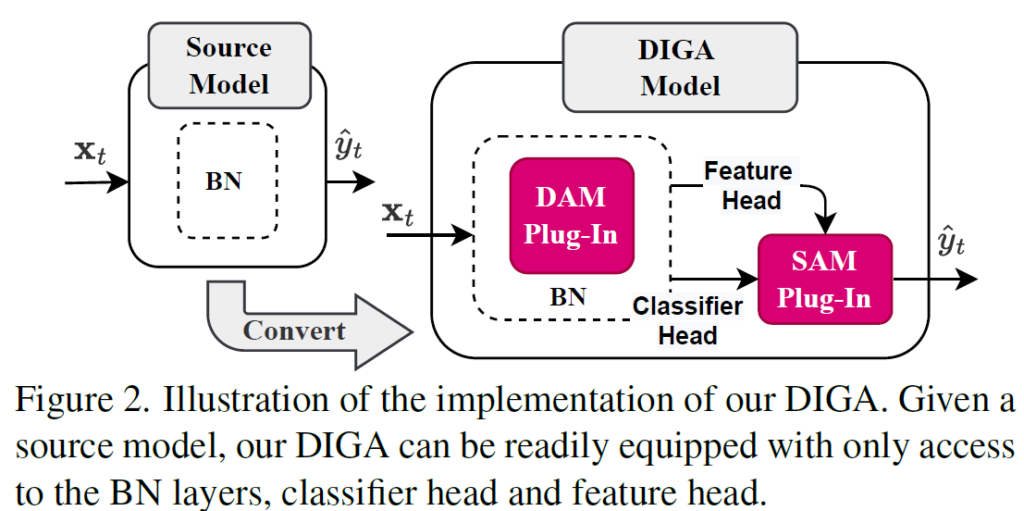
우측 DIGA 모델 구조를 보시면 기존 BN layer내에 DAM 모듈이 plug-in 된 것을 보실 수 있습니다.
그리고, 해당 output이 SAM으로 향하고 있구요.
위는 간단한 구조도이고, 구체적인 pipeline은 아래와 같습니다.
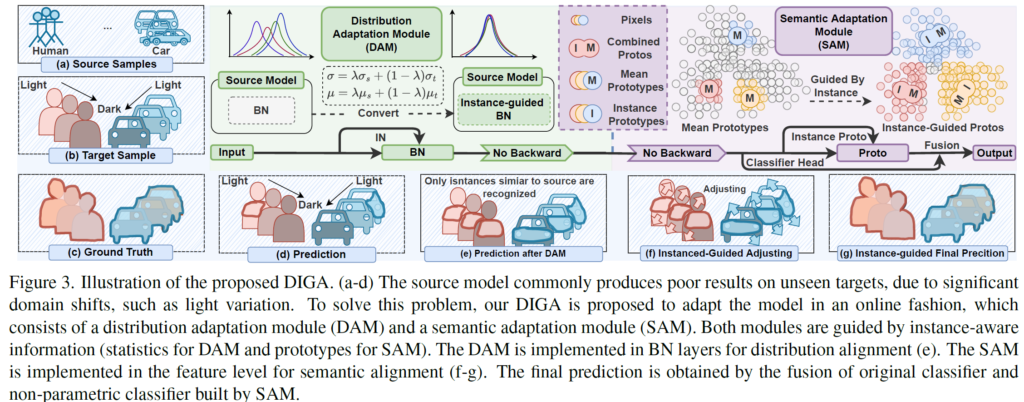
DAM과 SAM 모듈에 대한 자세한 설명은 아래 sub-section에서 진행하는 것으로 하고,
우선 좌측&하단 영역의 파랑색 background 부분을 보시길 바랍니다.
저자가 설계한 DIGA 모델이 어떻게 결과적으로 동작하는지를 (a)~(g) 까지 순서대로 나타낸 것을 보여주고 있습니다. 개인적으로 figure를 정말 잘 만들었다고 생각이 들었습니다..
(a)~(d): source sample과 target sample 사이의 큰 domain gap 때문에 (d)의 예측을 보시면 (c)의 gt와 비교했을때 매우 낮은 성능을 보여주는 것을 볼 수 있습니다. target sample에 매우 다양한 light variation이 존재하기 때문에 (d) 예측에서 밝은 영역에 대해서만 조금의 예측을 수행한 것을 볼 수 있네요.
(e): DAM 수행 후의 결과입니다. DAM에서 distribution 수행 시 source data의 통계값과 현재 target sample의 통계값을 weighted sum해서 normalization이 수행되기 때문에, 시각화 결과를 보시면 source 와 유사한 instance에 대해 예측이 어느정도 수행된 것을 보실 수 있습니다.
(f-g): SAM 수행 후의 결과입니다. SAM 모듈을 통해 semantic adaptation을 수행함으로써 결론적으로 정확한 예측을 수행하였다고 저자들은 주장하고 있습니다.
2.1. Distribution Adaptation Module(DAM)
사실 Distribution을 맞추기 위해서는 adversarial training, KL Divergence 등의 기법들을 사용하는 것이 제격이긴 합니다. 하지만 이들을 사용하기 위해서는 source data로의 접근이 필수적인데, TTA의 세팅 특성 상 불가능하죠.
그렇기 이전 TTA 연구들에서는 Batch Normalization이 data distribution 관련이 있다는 점에 착안하여 BN parameters를 통해 adaptation을 수행하고자 하였습니다. data의 분포를 평균0-분산1로 만들어주는 normalization과정과, 해당 분포를 새로운 data 분포로 보내주는 transformation 과정을 통해 말이죠.

본 논문에서도 위와 동일한 과정을 거치긴 합니다.
다만 \mu, \sigma, \gamma, \beta 를 어떻게 구성하고 업데이트해 나가는지가 차별포인트죠.
우선 기존 TTA에서는 normalization시 반영되는 \mu, \sigma 는 매번 test batch마다 계산을 수행하였습니다. test batch sample에 대해 평균, 표준편차를 계산해서 해당 통계값을 normalization 시에 사용하는 것이죠.
그리고 새로운 분포로 뿌려주는(?_) \gamma, \beta 값은 source train 시에 계산된 값을 잘 보존한 뒤 이를 조금씩 update해 나가는 방식을 사용하곤 합니다.
물론 위 과정을 통해 매번 \gamma, \beta가 update 되면서 입력 test batch에 맞게 distribution이 변화하긴 합니다만, 저자들은 위 과정 속 update rate가 매우 낮아서 instance-level까지 명확하게 반영이 되지 않는다고 합니다(그림 3-(d) 참고). 또한 backward 기반으로 update 해야하기 때문에 그만큼의 cost가 들고요.
그렇기 때문에 저자는 앞선 \gamma, \beta 를 update하는 방식과는 달리, Distribution Adaptation Module (DAM) 모듈을 설계하여 instance 정보까지 잘 반영하고자 하였습니다.
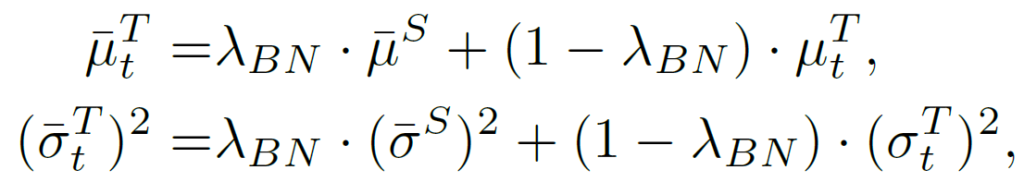
target기준 t시점의 \bar{\mu}_t^T, \bar{\sigma}_t^T를 구성하는데에 있어 source에서 학습된 \mu^S, \sigma^S와 현재 test sample에서 계산된 \mu, \sigma를 \lambda_{BN}만큼의 가중치로 ema update 하였습니다. 해당 가중치는 실험적으로 0.8을 사용하였다고 하네요.
해당 섹션에 \gamma, \beta에 대한 추가적인 update 방법이 없는데,,,
우선 본 논문이 backward-free 방식이니 loss기반으로 update하는 것은 아닐테고, 아마 source 학습 시 저장된 값을 그대로 사용하는 거 같습니다.
2.2. Semantic Adaptation Module(SAM)
본 2.2절에서 소개드릴 Semantic Adaptation Module(SAM) 은 이름 그대로 semantic 정보를 부여하기 위한 모듈입니다.
앞선 DAM만을 사용하면 feature map에서의 distribution만 정렬하기 때문에 class의 semantic 정보에 대한 고려가 없습니다. Segmentation task의 특성 상 semantic 정보가 매우 중요하기 때문에 저자는 semantic 정보를 고려하고자 SAM 을 설계하게 됩니다.
물론 이를 위해 이전 work에서 pseudo label 방법을 사용하면 되긴 합니다만, 본 work은 backward-free 방식을 제안하기 때문에 loss 기반의 backward연산 수행이 불가능합니다. 따라서 이를 위해 few-shot과 UDA에서 자주 사용되는 prototype 개념을 도입합니다.
입력 이미지에 대해 feature를 추출한 뒤 이를 통해 class별 prototype을 구성해서 non-parametric 기반 예측을 수행하는 것입니다.
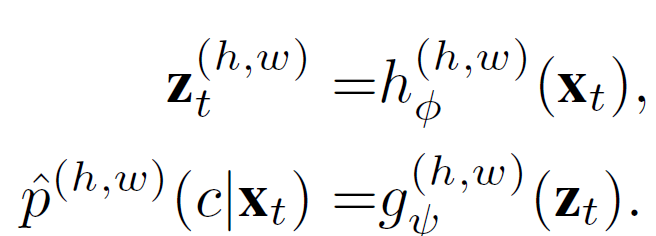
x_t 는 입력 target image, h_{\phi}는 source-pretrained feature extractor, g_{\psi}는 source-pretrained classifier 입니다. 당연한 말이지만, 본 논문은 backward-free 기반이기 때문에 h_{\phi}와 g_{\psi}는 loss를 기반으로 update 되지 않습니다.
그리고 수식의 결과인 z_t와 \hat{p}는 각각 feature map과, class별 확률 정보가 들어있는 seg map이 되겠죠. \hat{p}는 class수 만큼의 channel 수를 지니고 있는데, pixel-level로 각 class별 예측 확률을 담고 있습니다.
그리고 추출된 \hat{p}를 기반으로 prototype q_t를 계산할 수 있게 됩니다. 다만 이때 confidence가 P_0(0.9 사용) 이상인 pixel에 대해서만 prototype 계산에 반영하였고, 최종적으로 각 class 별 하나의 prototype이 계산되게 됩니다.
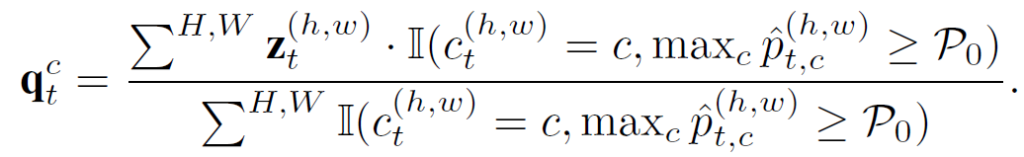
물론 test 시 입력으로 들어오는 target sample 에 대해 매번 prototype을 계산하여 사용할 수도 있긴 하지만, 안정성을 위해 아래 식을 통해 0.8의 가중치로 update 해 나가게 됩니다.
t 시점의 prototype \bar{q}_t계산 시 t-1까지 계산된 prototype 및 현 t 시점에 입력으로 들어온 sample로 계산된 prototype q_t이 함께 반영되게 됩니다.
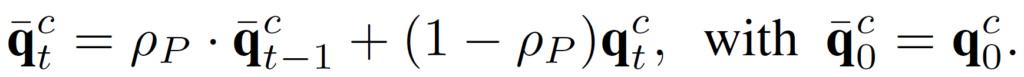
그리고 아래 식은 계산된 prototype을 기반으로 non-parametric prediction을 수행하는 식입니다.
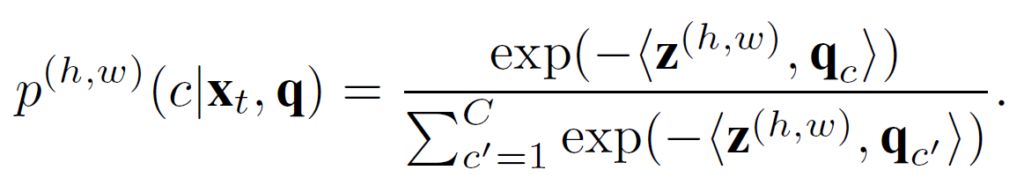
말로 설명하자면,
현 t 시점의 target image로 부터 추출된 feature map z_t와 prototype 사이의 내적을 수행하고 이를 softmax 를 태운겁니다. 그렇게 되면 유력한 class 에 대해 가장 높은 값을 가지는, channel 축이 c개인 예측 seg map 이 생성되게 되는 것이죠.
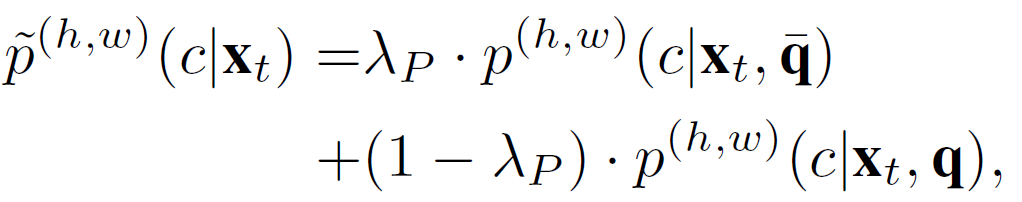
저자는 non-parametric prediction 과정에서 \bar{q} 와 q를 사용한 각각의 예측에 대해 0.8의 비율로 섞어서 prototype 기반 예측인 \tilde{p}을 수행합니다.
최종적으로 본 network를 통해 예측한 segmentation map은 총 2개입니다.
source에서 학습된 classifier를 통해 계산한 \hat{p}과, prototype을 통해 예측한 \tilde{p} 이죠. 이를 0.8:0.2의 비율로 섞어서 최종적인 prediction p가 계산됩니다.
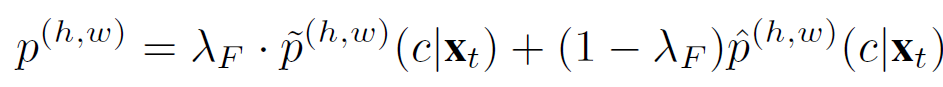
최종적인 pipeline의 알고리즘은 아래와 같습니다.

3. Experiment
실험은 기존 UDA및 TTA based segmentation에서 흔하게 수행되는 synthetic->real 상황을 벤치마킹 합니다.
synthetic 으로 사용되는 dataset은 GTA5, Synthia 이렇게 2가지이고,
real로 사용되는 dataset은 CS: CityScapes, BDD: BDD100K, MA: Mapillary, IDD: IDD, CC: Cross-City 이렇게 5가지 입니다.
source, 즉 synthetic dataset에 의해 모델을 미리 학습 시키고
test 단계에서 target, 즉 real dataset에 대한 TTA를 수행하게 됩니다.
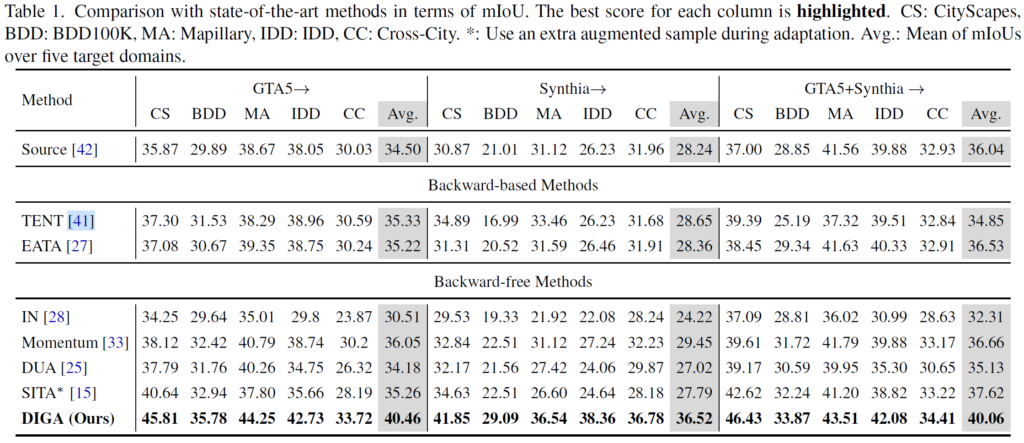
위 표에서 dataset별 모든 실험 결과를 보여주고 있습니다.
우선 위 표에서 TENT와 EATA는 모두 backward 기반 BN parameters update 방식입니다.
두 방법론은 모두 classification task에 대해 설계되었는데, segmentation도 pixel level로 entropy를 계산할 수 있기 때문에 저자는 re-implementation을 수행했다고 합니다.
그리고 아래쪽 IN,Momentum, DUA, SITA는 모두 backward-free 기반 방법론입니다.
이들 모두 target sample에 대한 통계값을 기반으로 BN layer를 update해 나가는 방식입니다.
어떤식으로 update해 나가는지에 따라 조금씩의 디테일 차이가 있습니다.
TENT와 EATA 수행 시 성능이 오르는 case도 있지만 오히려 degradation되는 경우도 존재합니다.
backward-free 벤치마킹 방법론들도 마찬가지이구요.
본 논문에서 설계한 DIGA는 모든 경우에 대해 꽤나 큰 성능향상, 타 방법론과 비교했을 때에도 높은 향상을 보여주고 있습니다. Backward 기반인 TENT, EATA와 비교했을 때에도 성능이 큰 폭으로 향상했습니다.
DAM과 SAM중 어떤 모듈이 성능 향상에 큰 기여를 했는지 궁금해지네요,,,

위는 정성적 결과입니다.
Cityscape와 Crosscity dataset에서 결과가 타 방법론 대비 좋네요.
BDD100K는 dataset이 어려운건지, 해당 scene이 어려운건지 모르겠지만 Ours에서도 도로 부분이 조금 뭉개지네요.
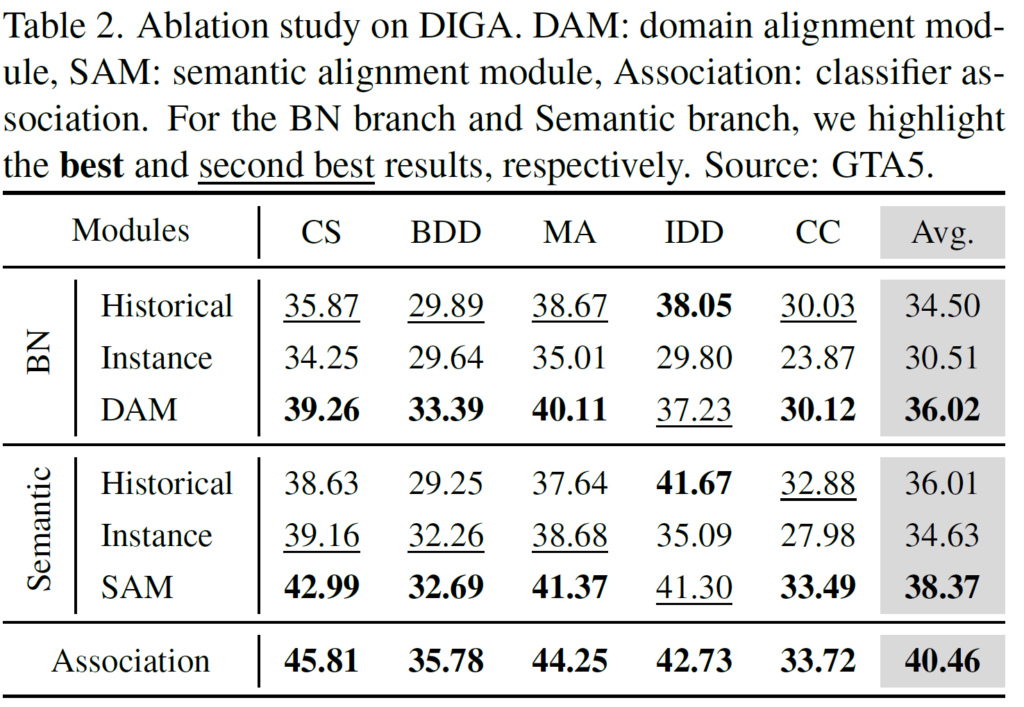
그리고 위 표는 DAM, SAM에 대한 ablation 결과입니다.
각각을 나눠서 살펴보겠습니다.
DAM
위 표에서 BN 섹션을 보시면 됩니다.
Historical은 source dataset으로 계산된 통계값(평균, 분산)을 그대로 사용했을 때의 결과를 보여줍니다.
그리고 Instance는 현 test 단계에서 입력으로 들어오는 target sample에 대해 매번 새롭게 계산한 값을 사용한 결과입니다.
둘 사이의 결과도 조금 재밌는게, Instance대비 Historical의 성능이 4나 높네요.
source와 target이 아무래도 합성과 real이라는 큰 차이가 있기 때문에 source(합성)에 대해 학습한 통계값을 그대로 사용해서 normalization을 수행하게 되면 성능 하락이 많이 일어날 줄 알았는데,,,, target sample 1장에 대해서 계산한 Instance보다 높네요.
domain이 다르더라도, data빨이 확실히 중요하긴 한가봅니다 ㅎ
DAM을 통해 통계값을 계산 후 사용 시 Historical 대비 1.5의 향상이 있네요.
SAM
위 표에서 Semantic 섹션을 보시면 됩니다.
Historical은 prototype으로 \bar{q}를 사용하는 것을 의미합니다.
아래 식을 보면 아시다시피 \bar{q} 구성 시 t-1 시점의 \bar{q}와 현재 sample에 대한 q와의 조합으로 계산되게 됩니다.
풀어서 말하자면, test dataset에 대한 ema update가 수행된 prototype으로 예측을 한 결과지요.
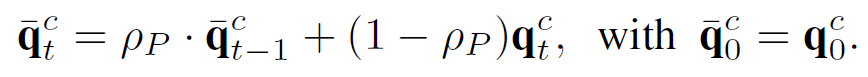
그리고 Instance는 오직 현재 sample에 대한 prototype q만을 사용해서 예측을 한 결과입니다.
뭐 당연한 소리겠지만 둘을 비교했을때에는 역시 더 많은 정보가 담겨있는 Historical이 더 높은 성능을 보여주고 있네요.
그리고 SAM은 위 두 예측을 다 활용하기 때문에 최종적으로 38.37의 성능을 보여주고 있습니다.
마지막으로, DAM과 SAM을 결합해서 사용했을 시의 성능이 제일 높습니다.
DAM과 SAM모두 어느 한쪽에 치우침 없이, 유사한 가중치를 가진 채 최종 성능에 기여했네요.
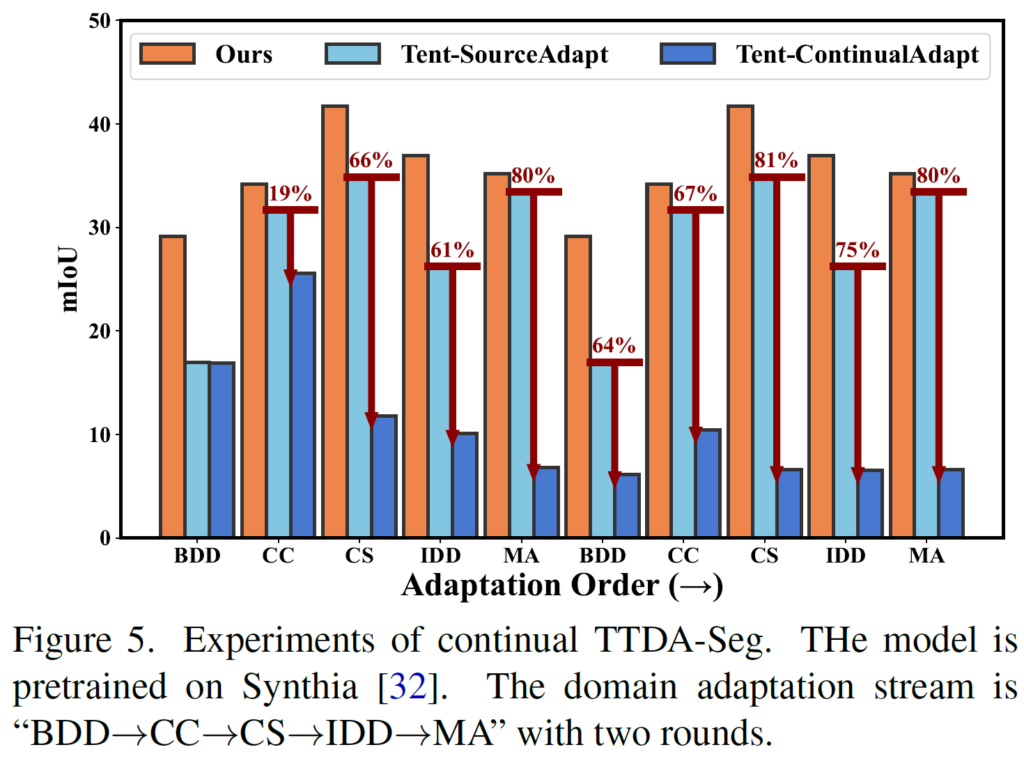
본 논문은 continual한 상황을 고려하여 설계한 방법론은 아닙니다만,
실험 섹션에서 간단하게 continual한 상황을 가정한 실험 결과를 보여주고 있네요.
비교군으로 사용한 TENT도 마찬가지로 continual한 상황을 고려한 것은 아닙니다.
TENT의 continual성능, 즉 위 그래프에서 진한 파랑색과의 성능 비교를 했을 때 꽤나 많은 성능차가 있네요.
해당 결과는 리뷰어가 보이라고 해서 보인걸까요,,? ㅎ
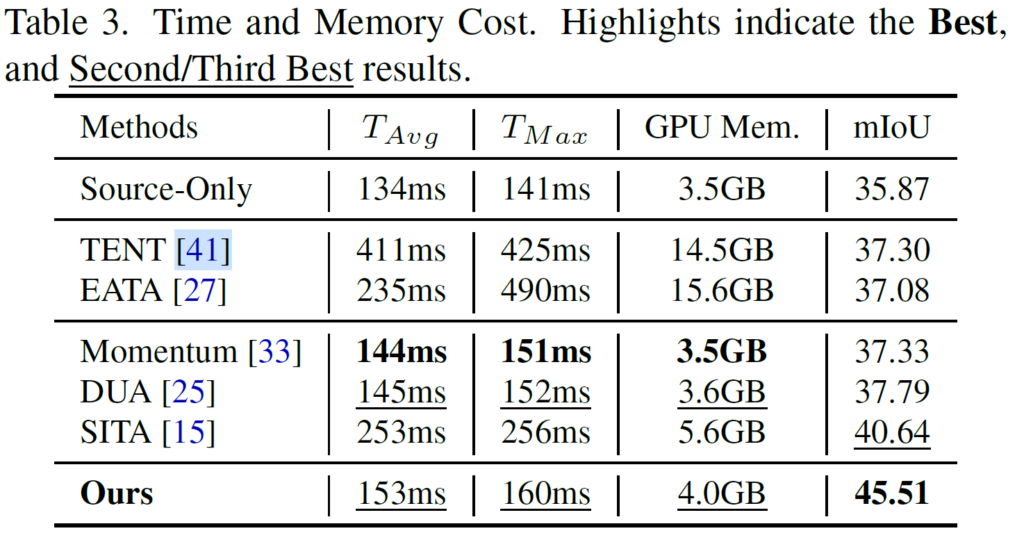
위 결과는 Time과 Memory, 그리고 최종 성능과 관련된 표입니다.
확실히 backward-based 방법론인 TENT, EATA에 비해 backward-free 방법론인 Ours의 소요 시간과, 특히 GPU 메모리 사용량 차이가 확 눈에 띄네요.
그러면서 성능도 앞선 두 방법론보다 더 높으니,,,
대단합니다.
backward-free라는 제목에 이끌려서 논문을 읽은 후 X-review까지 작성하게 되었네요.
실제 on-device 상황을 고려했을 때 모델은 가벼우면 가벼울수록 좋다고 생각하기 때문에 이에 대한 insight를 조금 얻으 ㄴ듯 합니다.
다만 본 논문에서 설계한 backward-free 기반의 방법론에서 BN의 transformation parameter인 \gamma, \beta가 어떤 식으로 구성이 되는지, 가령 source에서 학습된걸 그대로 고정하는지 아니면 뭔가 추가 처리가 있는지 등에 대한 설명이 조금 부족해서 해당 부분에 대해서는 조금 더 찾아봐야 할 듯 합니다.
(사실 이 부분이 제일 중요한데,,, 제가 놓쳤을 수도 있으니 다시한번 읽어보려고 합니다.)
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
기존 TTA에서는 normalization시 반영되는 μ,σ를 매 test batch마다 계산을 하는 것인데 본 논문에서 제안된 DAM 모듈은 source에서 학습된 μ,σ를 같이 사용한다는 점과, γ,β를 update해나가지 않는다는 점이 기존과의 차이점인 것인가요 ?
또, prototype을 통해 예측한 P와 source에서 학습된 classifier를 통해 계산한 p를 0.2:0.8 비율로 합해 최종 prediction이 계산된다고 했는데, 이 비율에 대한 ablation study는 따로 없었는지 궁금합니다.
감사합니다.
댓글 감사합니다.
1. 기존 연구들에서 μ,σ 은 test time forward시에 입력으로 들어오는 sample들에 대해서만 고려하였는데, 본 논문에서는 source시에 학습된 정보를 기반으로 매 test time t 때 들어오는 이미지들에 대한 μ,σ를 moving averate 방식으로 가중합 하여 구성해 나가는 점이 차별점입니다.
γ,β의 경우에는,, 본 논문에서 자세하게 서술이 되어있지 않아서 제가 정말 궁금함에도 불구하고 그 궁금증을 해소하지 못하였는데요,,, 아마 본 논문에서 밀고나가는 것이 backward-free 방식이므로 γ,β는 learnable하게 update가 되지 않고 source의 것을 그냥 그대로 사용하는 것이 아닐까 생각됩니다.
2. 비율에 따른 실험은 따로 없었습니다.
안녕하세요. 질문이 몇가지 있는데,
먼저. test 이미지에 대하여 적은 batch size로 학습하기 때문에 batch norm layer를 backward 할 때 ~~단점이 있다라는 내용에 대해서 궁금한게 있습니다. 보통 inference는 영상 한장이 들어온다라는 가정으로 저는 생각을 했는데 inference를 batch 단위로 한다라 함은 가령 30FPS 속도로 카메라가 촬영을 했을 때 5FPS 당 한장씩 샘플링한다는 가정하에 6장이 남으니 1초에 6장을 추론한다고 보는건가요? inference를 배치 사이즈 최소 2이상으로 한다는 부분이 직관적으로 이해가 안가서 설명 부탁드립니다.
그리고 두번째로는 기존의 Instance Statics 방식과 저자들이 Instance BN으로 하는 방식이 어떤 차이가 있는 것인가요? 기존 방식과 달리 감마 베타를 업데이트하는 것이 아니라 저자들이 새롭게 제안한 DAM 모듈 방식으로 계산하는 것이 instance 레벨까지 잘 반영한다고 리뷰에 작성해주셨는데, 저자들이 새롭게 제안한 수식이 어떻게 instance level까지 고려한다는 것인지 잘 모르겠습니다.
그리고 마지막으로 해당 방법론은 inference 단게에서도 prototype으로 segmentation을 예측하는 방법론이라고 이해하면 되는지요? 보통 Decoder 혹은 Encoder에서 뽑은 feature를 바로 upsampling해서 segmentation map을 생성하는 것으로 알고 있는데 해당 방법론은 prototype을 갱신하는 것이면 모델의 segmentation 추론 값으로 prototype을 새로 만들고 해당 prototype을 통해서 최종 segmentation map을 다시 만든다..로 이해하면 되나요?
감사합니다.
댓글 감사합니다.
1. 첫번째 질문에 대한 대답은,., 사실 저도 이 TTA 기법이 실제 상황에 적용될 때의 구체적인 hyperparameters (batch size, fps 등,,) 에 대해 궁금하긴 한데 아무래도 논문에서는 실험 상황에서의 값들만을 리포팅하다 보니 제 갈증을 해결해줄만한 내용은 없었습니다.
다만, 이전 리뷰한 CoTTA 방법론에서 experiment단을 살펴봤을 때, 기존 8 batch로 사용하던 모델을 test 단계에서는 online TTA를 위해 1 batch로 inference를 수행하였다~ 라는 부분을 살펴봤을 때 실험적으로 1 batch를 사용하는 거 같습니다.
(질문해주신 사항이 제 리뷰속 내용과 매치가 되지 않아서,, 우선 일반적인 답변을 하였습니다)
2. 저자들이 설계한 Distribution Adaptation Module(DAM) 방식에서의 μ,σ 계산 방식과 기존 연구들과의 가장 핵심적인 차이점은 ‘현재 시점(t) 외의 추가적인 정보를 고려하는지~’ 입니다.
기존 연구들은 test time t에 입력으로 들어오는 target sample에 대해 새롭게 μ,σ를 매번 계산하고 이를 사용하였습니다. person class에 대해 이를 살펴보자면, 현재 μ,σ 에 반영된 person 정보는 person에 대한 여러 instance 정보들을 모두 반영하고 있는 것이 아니라 현재 sample 속 person에 대한 것만 고려하고 있다는 것이죠.
반면 기존 연구들은 source로 부터 미리 구해진 μ,σ 에다가 test time t 시점의 μ,σ 값들을 가중합 형식으로 점차 더해가면서 구성하였습니다. 이를 통해 instance level까지의 고려가 가능하게 된 것입니다.
3. 이해하신 부분이 맞습니다.
핵심은 prototype을 사용한 non-parametric prediction이 되겠네요
안녕하세요. 권석준 연구원님. 좋은 리뷰 감사합니다. 리뷰를 읽다 보니 몇가지 모르는게 있어서 질문 드리겠습니다!
1. backward-based TTA에서 ‘backward를 할 때 대부분 연구들이 모델의 BN parameters만을 update한다’라고 하셨는데, 모델의 BN parameter만을 업데이트 한다는게 무슨 뜻인가요?
2. 리뷰를 읽다보면 계속 distribution adaptation, semantic adaptation에 대해서 설명하는데, 각각이 정확히 무엇을 의미하는 것인지 모르겠습니다. distribution 기반으로 adaptation을 하고, semantic 정보를 adaptation한다는 것 같은데, 더 자세한 설명이 가능하실까요?
감사합니다.
댓글 감사합니다.
1. 제가 리뷰한 TTA 분야 리뷰 중 ‘[ICLR 2021 Spotlight] Tent- Fully Test time Adaptation by Entropy Minimization’ (이하 TENT) 논문이 있습니다. TTA의 baseline 격이라고도 불리는 논문인데요, 해당 paper에서는 test time t 에 계속해서 새롭게 들어오는 target sample에 대한 직접적인 supervision을 줄 수 없는 상황에서, entropy minimization을 목적함수로 설계해서 모델을 update하는 방식을 채택합니다. 그리고 이때 모델의 전체 layer가 아닌 BN parameters 만을 update 하게 됩니다.
BN parameters 만을 update하는 이유로는 TTA 특성 상 시간적 효율이 중요한 것도 있지만, BN 에 관여하는 4가지 parameter의 특성과도 관련이 있습니다. 특정 layer를 기준으로 입력으로 들어오는 data를 평균0 분산1로 만들어 주는데에 관여하는 normalization param μ,σ 그리고 이 평균0 분산1을 현 시점 입력 데이터의 분포에 맞게 새로운 분포로 뿌려주는 transformation param γ,β 가 있습니다.
Domain 의 변화라는 것이 결국 data의 분포와 관련이 있는 것이기에 많은 TTA 연구들에서는 data의 분포와 관련이 있는 BN parameters 를 adaptation 과정에서 update 하곤 합니다.
(충분한 설명이 되었을지,, 모르겠네요 ㅎㅎ)
2. 음.. 이해하신 바가 맞는 거 같습니다.
위 1번 응답에서 설명드린 것 처럼 앞선 많은 연구들에서는 data의 분포(distribution)적인 측면에 집중해서 TTA를 수행하였습니다. 따라서 distribution 적인 adaptation뿐만 아니라 semantic, 즉 class의 의미정보를 반영하여 adaptation을 수행하고자 SAM 이라고 하는 기법을 설계한 것입니다./