안녕하세요, 스물여덟 번째 X-Review입니다. 이번 논문은 2023년도 arXiv에 올라온 CGI-Stereo: Accurate and Real-Time Stereo Matching via Context and Geometry Interaction입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
스테레오 매칭은 스테레오 영상 쌍으로부터 depth를 추정하는 task입니다. 최근 스테레오 매칭 sota 방법론 같은 경우 여전히 texture가 부족한 부분이나 occlusion 영역 혹은 반복되는 패턴이 있는 경우에서 어려움을 겪고 있습니다. 동시에 높은 정확도를 가지며 real-time으로 동작하는 부분도 문제로 남아있습니다.
스테레오 매칭에서는 영상 쌍 간의 matching cost를 계산하고 이를 disparity 축으로 쌓아서 cost volume이라는 것을 생성해낸 후 이로부터 pixel level로 disparity를 추정하게 됩니다. 몇 년 전부터 CNN이 스테레오 매칭에 도입되기 시작하면서 이 cost volume도 CNN으로 추출한 feature 기반으로 생성하게 되었습니다. 근데, 이 cost volume이 local matching cost에 대한 정보만을 담고 있어서 global한 정보가 부족하기 때문에 가려진 영역이나 텍스처가 부족한 영역, 혹은 반사되는 영역에서는 잘 동작하지 않게 됩니다.
이런 문제를 해결하기 위해, 초기 딥러닝 기반 스테레오 방법론인 GC-Net같은 경우 3D 인코더-디코더 구조를 제안하면서 global한 geometry 정보를 얻을 수 있도록 하였으며, 그 뒤에 나온 PSMNet이나 GwcNet 같은 경우도 유사하게 stacked 3D 인코더-디코더 구조를 제안하면서 cost volume을 가공하였습니다. 이 과정을 cost aggregation이라고 합니다. 하지만, 이렇게 3D conv기반으로 cost volume을 aggregation하다보니.. 계산량이나 메모리 코스트도 굉장히 많이 들었습니다.
이 3D conv의 단점을 해결하기 위해 GANet, AANet, CoEx, RAFT-Stereo 등이 제안되었습니다. 무튼 이 cost aggregation 과정은 스테레오 매칭에서 정확도와 효율성을 결정짓는 중요한 부분이라고 볼 수 있습니다. 본 논문도 역시 lightweight한 3D 인코더-디코더 구조의 aggregation 네트워크를 제안함으로써 정확한 결과와 실시간으로 동작하는 성능을 얻는 것을 목표로 합니다.
본 논문은 kaist rcv 논문인 CoEx에서 영감을 얻었는데, 이 CoEx는 오직 aggregation을 통해 얻은 geometry feature에만 의존해 disaprity를 추정하는 것보다 reference image(보통 왼쪽 이미지가 reference, 우측 이미지가 target)에서 얻은 context feature도 사용하는 것이 더 스테레오 geometry를 정확히 이해할 수 있다는 논문입니다. 무튼 본 논문의 저자는 특징 추출과정에서 얻은 feature와 cost volume에 인코딩된 geometry feature 간의 상호작용의 중요성을 파악하여 Context와 Geometry를 fusion한 CGF(Context Geometry Fusion)을 제안합니다.
추가적으로 Attention Feature Volume(이하 AFV)를 제안함으로써 informative하고 concise한 cost volume을 생성하여 사용하였습니다. 본 논문에서 제안한 CGF와 AFV에 가반하여 설계한 스테레오 매칭 네트워크는 아래부터는 CGI-Stereo라고 부르겠습니다. 본 논문의 contribution은 아래와 같습니다.
- Context, Geometry Fusion(CGF)를 제안함으로써 context feature와 geometry feature간의 상호작용을 통해 성능 개선.
- Attention Feature Volume(AFV)라고 하는 새로운 cost volume 제안
- 정확하고 실시간으로 동작하는 스테레오 매칭 네트워크 CGI-Stereo 제안. . 다른 KITTI 벤치마크 real-time 방법론들보다 성능 뛰어남.
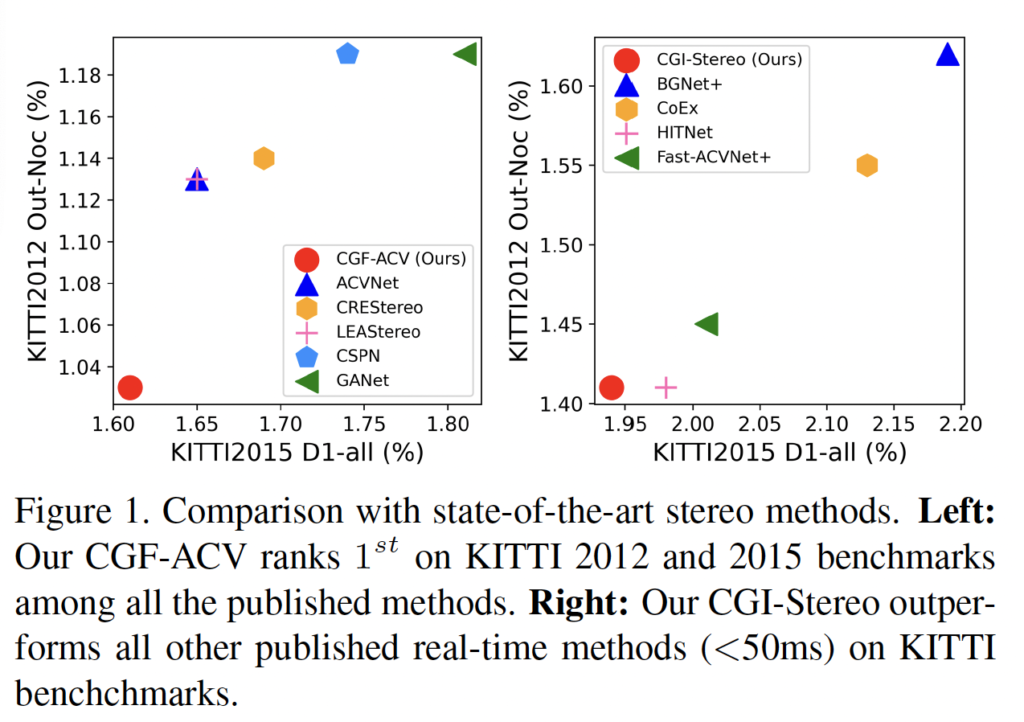
sota 방법론들과의 비교 figure입니다. 왼쪽에 있는 그림이 CGF-ACV가 KITTI 2012, 2015에서 SOTA를 달성했다는 것을 보여주고 있습니다. CVF-ACV는 기존 ACVNet 네트워크에 본 논문에서 제안한 CGF(context geomtry fusion)을 붙인 네트워크입니다. 오른쪽 그림은 50ms 이하로 동작하는 real-time 방법론들 중에서 CGI-Stereo가 가장 성능이 높다는 것을 보여줍니다.
2. Method
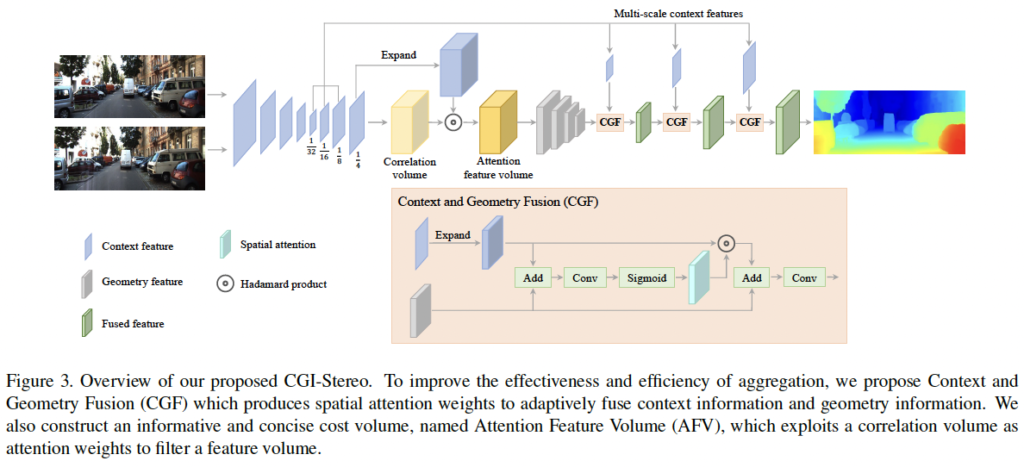
CGI-Stereo 아키텍처 구조는 fig 3과 같습니다. 크게 multi-scale 특징 추출(앞단의 하늘색), attention feature volume 생성(노란색 블럭), cost aggregation(회색 ~ 초록), disparity 추정 파트로 나눠볼 수 있습니다. 각 파트에 대해 자세히 알아보도록 하겠습니다.
2.1. Context and Geometry Fusion
먼저 Context and Geometry fusion 부분입니다. 이 CGF는 cost aggregation 과정에서 수행되는 부분으로, 단순하게 말하자면 저해상도 geometry에서 context 정보의 assist를 통해 고해상도 geometry 정보를 디코딩하는 것입니다.
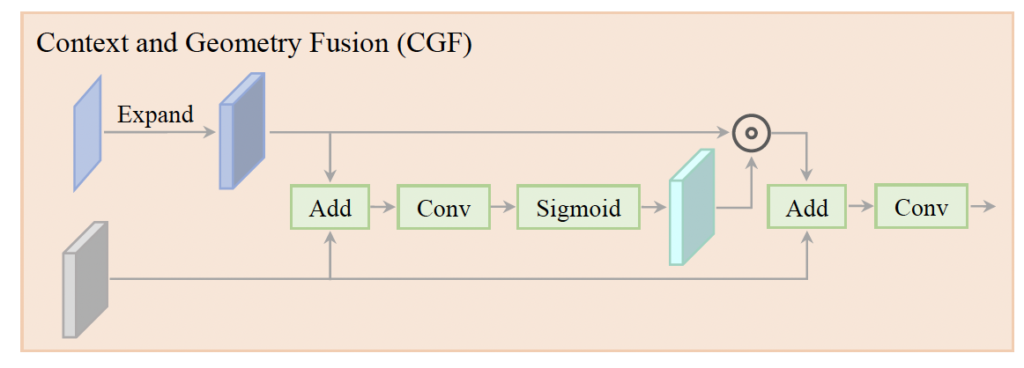
Figure 3에서 이 부분에 해당합니다. 먼저 좌측 영상에서 얻은 context feature C ∈ R^{B \times C_0 \times H_0 \times W_0}와 geometry feature G ∈ R^{B \times C_0 \times D_0 \times H_0 \times W_0}가 있을 때 C를 B \times C_0 \times D_0 \times H_0 \times W_0로 expand하여 C_{expand}를 생성합니다. 그림에서 C, G는 각각 파란색 feature, 회색 feature map에 해당하며, C_0, D_0는 각각 채널과 disparity를 의미합니다. C_{expand}를 생성한 이유는 G와 연산하기 위해 shape을 맞춰준 것으로 볼 수 있습니다. 이렇게 C_{expand}를 생성한 후 이를 단순히 G와 더하여 fusion하지 않고 attention 방식을 사용하여 fusion하였다고 합니다.
Geometry feature는 disparity 차원에 대해 unimodal distribution을 가지다 보니 C_{expand}와 geometry feature를 직접적으로 더하게 되면 context feature가 disparity 차원에 걸쳐서 공유되게 되고 이는 disparity 간의 차이를 무시하게 되는 효과적이지 못한 fusion이 됩니다. 그래서 저자는 CBAM에서 영감을 받아서 context와 geometry feature 사이의 spatial한 관계를 통해 spatial attention weight를 생성하여 사용하였습니다.
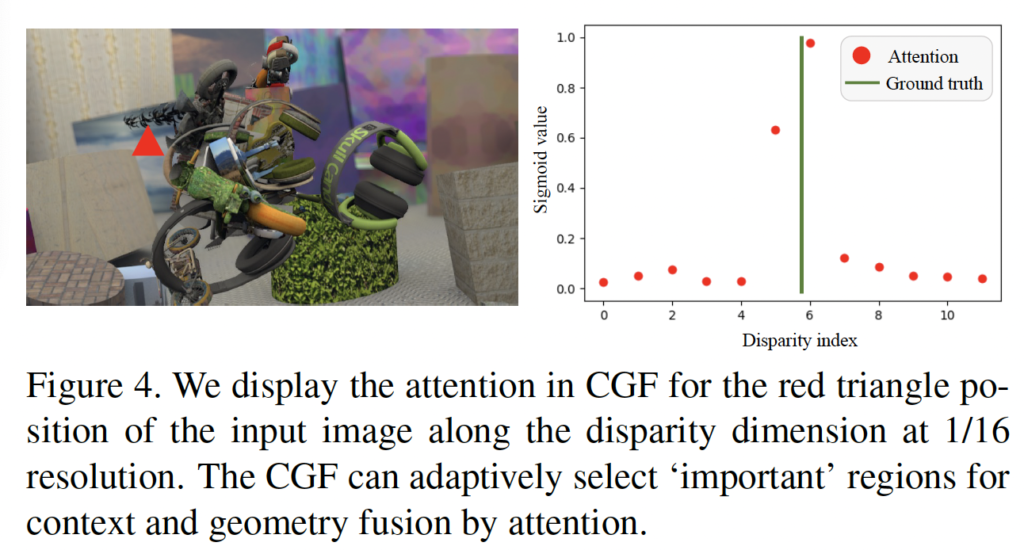
위 그림은 좌측 input 영상의 빨간 삼각형 부분에 대한 CGF의 attention 결과를 보여줍니다. 우측 그래프를 보면 x축이 disparity이고, y축이 sigmoid value로 attention 정도를 보여줍니다. 초록색 선인 GT disparity가 6부근인데, 그 근처를 attention 하고 있음을 보여줍니다.
이 spatial attention weight를 계산해내기 위해 가장 먼저 C_{expand}와 G를 더하고 convolution을 태웠습니다.
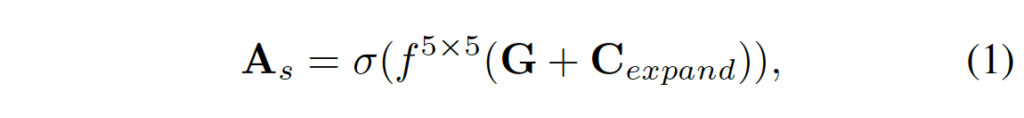
식1을 통해 spatial attention weight를 생성하게 되는 것입니다. σ는 sigmoid입니다. 이렇게 생성된 attention weight는 B \times C_0 \times D_0 \times H_0 \times W_0크기를 갖게 되며, disparity 축에 대해 강조하거나 억제할 위치를 인코딩하고 있다고 보면 됩니다.
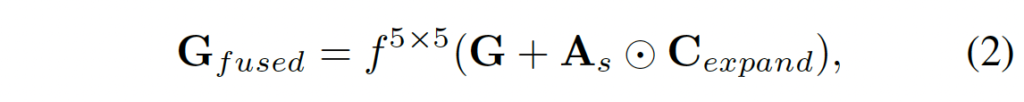
그 다음 식 2를 통해 최종적으로 fusion하게 됩니다. 단순하게 weight를 통해 C_{expand}를 filtering하고 G(geometry feature)를 더한 후 conv 태우는 게 끝입니다. ☉는 Hadamard product입니다.
2.2. Network Architecture of CGI-Stereo
2.2.1 Multi-scale Feature Extraction
이제 특징 추출단에 대해 살펴보도록 하겠습니다. 백본으로는 ImageNet으로 사전학습한 MobileNetv2를 사용하였으며, 입력 해상도의 1/4, 1/8, 1/16, 1/32 해상도를 갖는 4개의 multi-scale feature map을 추출하게 됩니다. 이어서 CoEx 논문에서 제안된 방식에 따라 feature map의 크기가 H/4 x W/4에 도달할 때까지 반복적으로 upsampling하고 skip connection을 통해 concat된다고 하는데, 크게 중요한 부분은 아니라 자세한 설명은 생략하겠습니다.
2.2.2 Attention Feature Volume Construction
이제, 저자가 제안한 Attention Feature Volume(AFV)에 대해 살펴보겠습니다. 이 AFV는 correlation volume을 통해 얻은 attention weight를 통해 초기 cost volume을 filtering하는 부분입니다. 이로써 좀 더 informative하고 간결한 cost volume을 얻을 수 있는 것이죠. Fig3에서 해당 부분을 떼왔습니다.
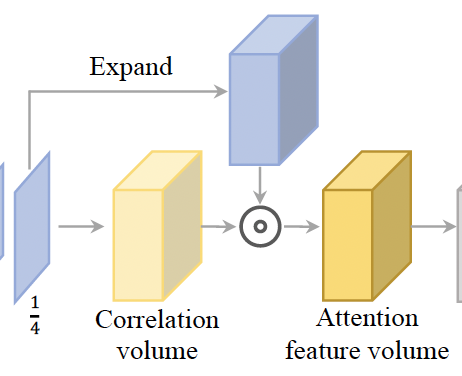
먼저, correlation volume V_{corr}는 아래 식3을 통해 생성할 수 있습니다. 그냥 cosine similarity 계산입니다.
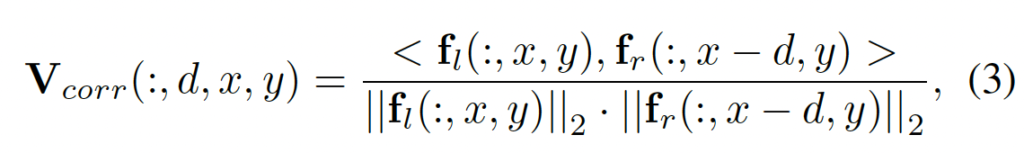
- d : disparity index
- (x, y) : 픽셀 좌표
- f_l, f_r : 좌 우 feature map
cosine similarity로 계산한 correlation volume의 채널이 오직 1이기 때문에 8로 늘려줬다고 하며, 이에 따라 F_l도 B \times C \times D/4 \times H/4 \times W/4 크기로 expand해서 크기를 맞춰줬다고 합니다. 최종적으로 attention feature volume V_{AF}는 아래와 같이 계산됩니다.
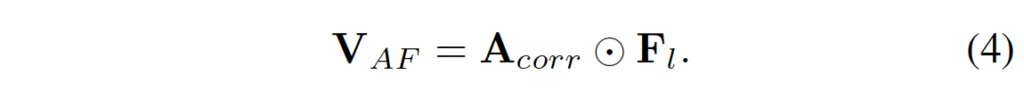
CGF와 마찬가지로 Hadamard Product입니다. 이렇게 생성된 attention feature volume은 GwcNet, ACVNet에서 제안된 볼륨들보다 더 효율적이라고 하는데, 이에 대한 실험은 없고 그냥 이 둘은 volume을 생성하는데 추가적인 cost가 드는데 본인들은 기존 feature map을 expand해서 사용하는 것뿐이니 더 효율적이다라고 주장하는 것 같습니다.
2.2.3 Cost Aggregation
다음은 cost aggregation 단계입니다. 앞단에서 설명했듯이 고해상도의 geometry feature를 디코딩하는 방식으로 multi-scale의 context feature를 geometry feature와 fusion하는 CGF를 제안했었습니다.
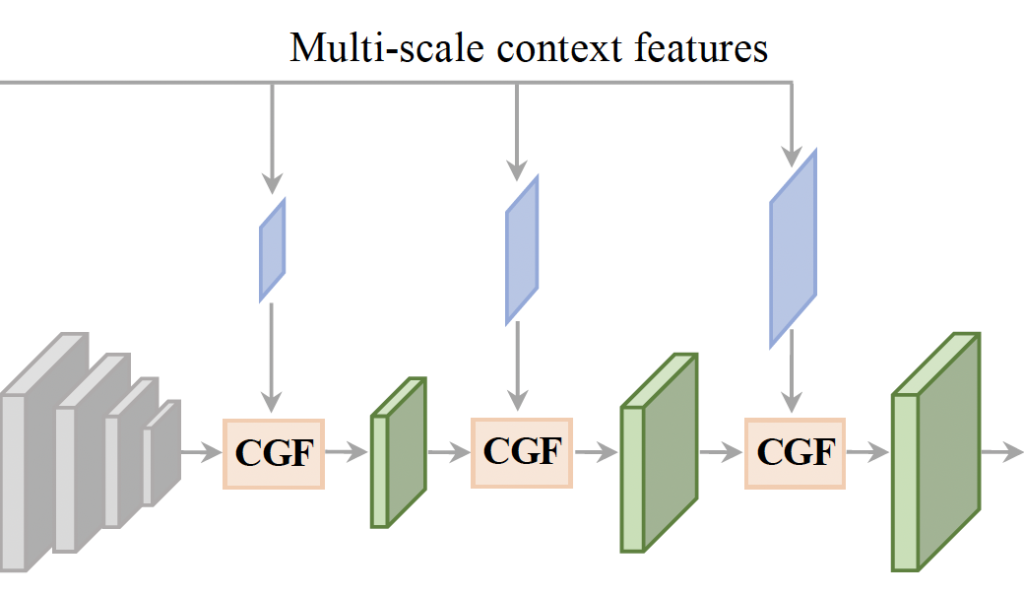
그림에서 보시다시피 그 부분이 aggregation 과정의 전부입니다 . . 간단히 설명드리자면 3D convolution을 사용하여 downsampling하면(그림에서 회색 부분) B \times 6C \times D/32 \times H/32 \times W/32 크기의 geometry feature가 생성되는데 이를 CFG 모듈과 upsampling 모듈을 사용해 고해상도 geometry feature로 디코딩하는 것입니다.
2.2.4 Disparity Prediction
마지막으로 disparity를 추정하는 부분인데 앞선 cost aggregation을 마치고 최종적으로 feature map이 나오게 됐다면, CoEx에서 제안된 방식을 따라 모든 픽셀에 대해 가장 top 2를 뽑았다고 합니다. 그 다음 이 두 value에 대해 softmax를 태워 disparity를 예측하였습니다. 그냥 top2 soft-argmax disparity regression이라고 생각하면 됩니다.
이렇게 계산된 disparity map d_0는 B x 1 x H/4 x W/4 크기이므로 원본 영상과 같은 크기로 만들어주는 과정에서 [superpixel segmentation with fully convolution networks]논문에서 제안된 ‘superpixel’ 가중치를 사용하였다고 합니다.
2.3. Loss Function
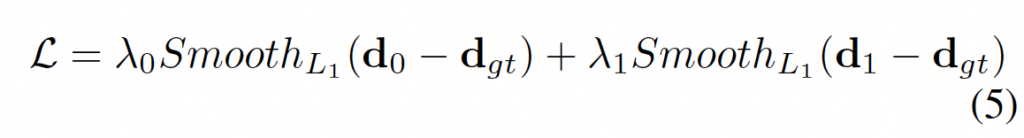
네트워크는 end-to-end로 동작하며, 최종 loss는 위 식 5와 같습니다.
d_0는 원본 영상의 1/4 크기인 disparity map이며, d_1는 superpixel을 통해 원본 영상 해상도로 크기를 키운 최종 dispairty map입니다. loss는 예측한 dispairty와 gt disparity간의 smooth L1 loss입니다.
3. Experiment
3.1. Datasets and Evaluation Metrics
데이터셋은 합성 데이터셋인 SceneFlow와 real dataset인 KITTI 2012, 2015, Middlebury 2014, ETH3D입니다. Scene Flow 데이터셋의 평가지표로는 EPE(end-point-error)와 disparity 아웃라이어 비율인 D1을 사용하였습니다. EPE는 gt disparity와 예측한 dispairty간의 픽셀 차이를 평균 낸 것이며, D1에서 outlier를 판단한느 기준은 disparity 오차가 max(3px, 0.05d_{gt})보다 큰 픽셀로 정의됩니다.
다음으로 Real dataset인 KITTI의 경우 LIDAR로 취득한 gt disparity가 sparse하며, 2012의 평가지표로는 EPE와 함께 occluded되지 않은 영역(x-noc)과 모든 영역(x-all)을 구분지어서 gt disparity와 predict한 dispairty 사이 픽셀 차이가 x보다 큰 것을 error로 보고 이 비율을 평가지표로 삼았습니다. KITTI 2015에서는 background영역, foreground 영역, all로 나눠 EPE가 3pixel 이상인 비율을 리포팅하였습니다.
MIddlebury 2014데이터셋은 학습 이미지가 15장, 평가 이미지가 15장으로, 본 실험에서는 학습 이미지 쌍을 domain generalization 성능을 평가하는데 사용하였으며 pixel 차이가 2이상인 비율을 평가지표로 삼았으며, ETH3D의 경우도 유사하게 27장의 학습 이미지를 사용해 cross-domain generalization 성능을 평가하였으며 gt와 예측한 dispairty 픽셀 차이가 1 이상인 픽셀들의 피율을 평가지표로 삼았습니다.
3.2. Ablation Study
먼저 본 논문에서 제안된 AFV(attention feature volume)과 CGF(context and geometry fusion)에 대한 ablation study 결과입니다.
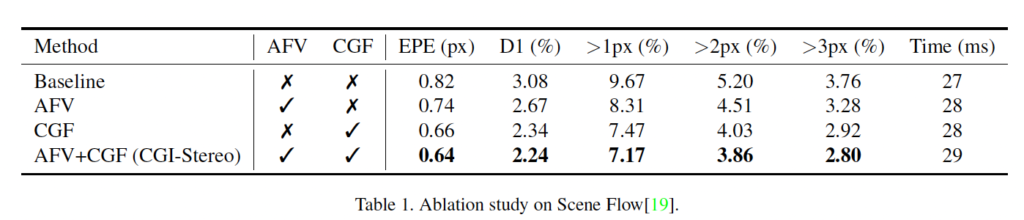
표 1을 보시면 CGF를 적용했을 때 눈에 띄는 성능 변화가 있었지만, AFV같은 경우는 성능 차이가 좀 미미하긴 합니다. 아무래도 이 AFV같은 경우는 그냥 cosine similarity가 전부라고 봐도 무방하기 때문이지 않을까 싶습니다.
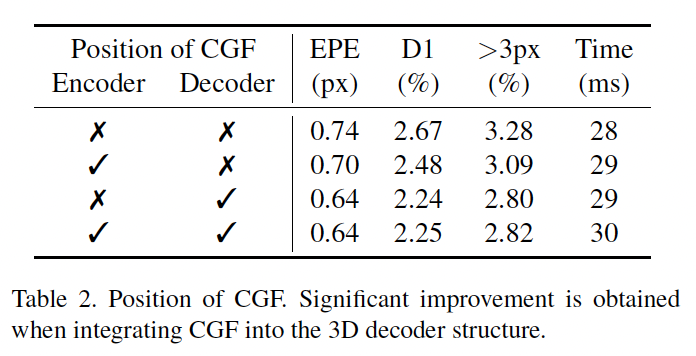
다음으로는 CGF를 어디에 적용하는지에 따른 실험 결과입니다. 맨 위 행은 CGF는 적용하지 않고 AFV만 적용한 성능입니다. 표를 보시면, encoder에만 CGF를 사용했을 경우에는 성능 개선이 미미하지만, 디코더에만 적용했을 때는 성능이 확실히 개선된 것으로 보입니다. 저자들이 이에 대해 분석하기로는 AFV에는 3D encoder가 context 정보를 정보를 추출하는데 사용할 수 있는 충분한 context 정보가 포함되어 있지만, 3D decoder같은 경우에는 저해상도 geometry 정보로부터 고해상도 geometry 정보를 복원해내기가 어렵기 때문에 context 정보를 가이드 삼아낼 수 있었다고 합니다.
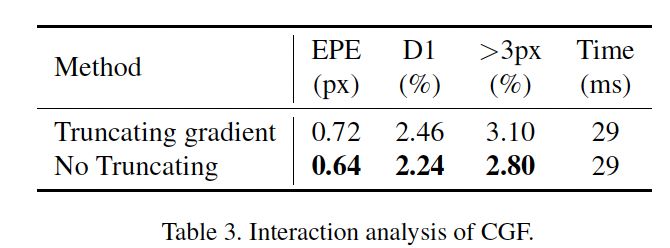
다음으로는 CGF가 context와 geometry feature를 학습하는 과정에서 context와 geometry가 서로 상호작용한다는 점에 대한 실험입니다. 표 3에서 볼 수 있듯이 CGF에서 context feature의 gradient를 끊었을 때 (truncating gradient)보다 끊지 않았을 때 성능향상이 있는 것으로 보입니다. 즉, geometry feature가 context feature의 학습에도 영향을 미치는 것으로 해석할 수 있겠습니다.
3.3. Performance of CGF
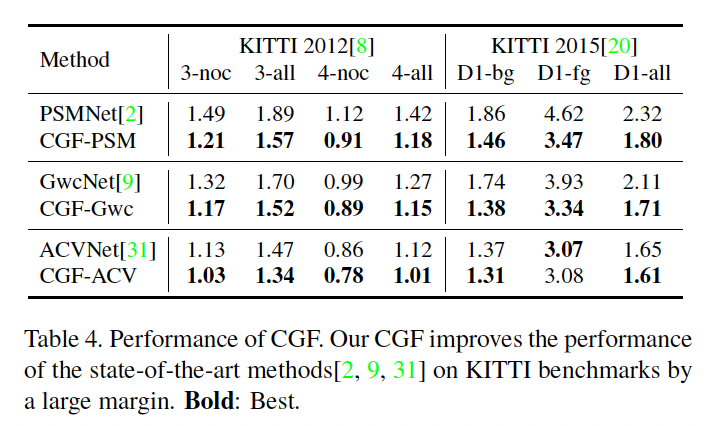
이제, CGF를 다른 sota모델에 붙여 CGF의 우수성을 확인한 실험입니다. 저자는 sota모델에 붙였다고 하면서 PSMNet, GwcNet, ACVNet을 들고오긴 했는데, 사실 ACVNet은 그렇다 쳐도 PSMNet, GwcNet은 2019년에 나온 방법론으로 … sota라고 볼 수는 없는 것들입니다. 무튼 결과를 보시면, CGF를 붙였을 때 전부 성능이 향상되었습니다.
3.4. Comparisons with State-of-the-art
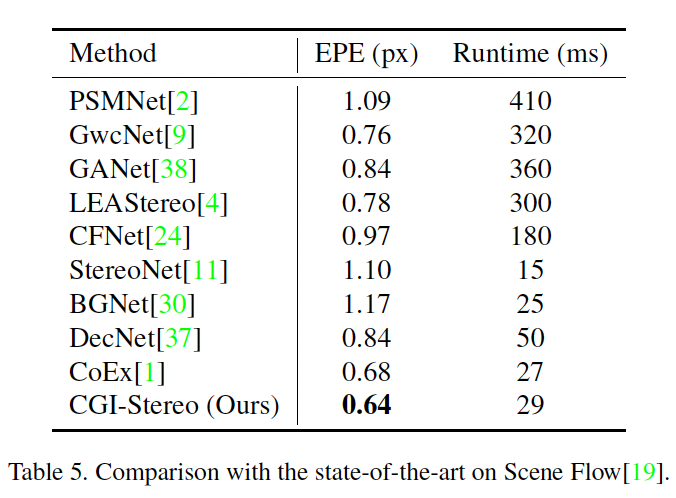
표5는 합성데이터셋인 Scene Flow에 대한 비교 실험입니다. BGNet, DecNet, CoEx는 runtime이 50 이하로 real-time method라고 볼 수 있는데 이 중에서 가장 좋은 성능을 보이고 있으며, 전체로 봤을 때도 무거운 모델들과 비교해봤을 때도 성능이 가장 높습니다. 다만, 벤치마킹 된 방법론들 중 가장 최근 방법론이 2021년도에 나온 것이고,, 나머지도 다 꽤 예전 방법론들을 가져와 비교했다는 점이 아쉬운 것 같습니다.
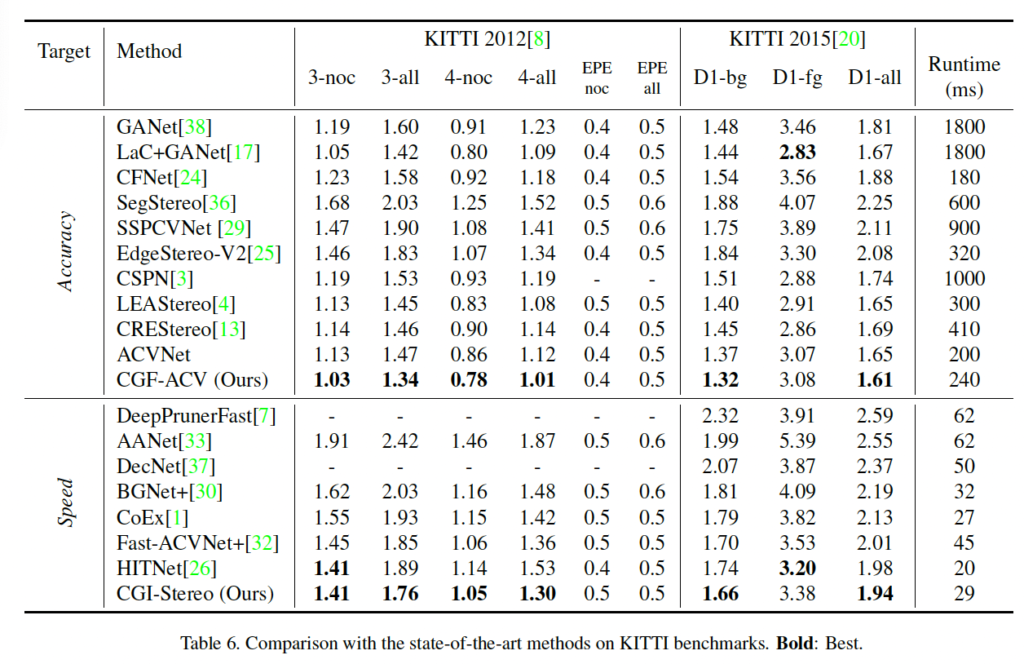
다음으로는 KITTI 데이터셋에 대한 실험입니다. 비교적 빠르게 동작하는 방법론들과 비교했을 때 가장 성능이 좋으며, 성능이 비슷한 HITNet과 비교해보았을 때 약간 성능이 더 좋음과 동시에 더 빠르게 동작합니다. 또 Accuracy 측면에서는 ACVNet에다가 본 논문에서 제안된 CGF를 붙인 CGF-ACV가 가장성능이 좋습니다. .

마지막으로 MIddlebury 2014, ETH3D에서의 generalization에 대한 정성적 결과입니다.
좋은 리뷰 감사합니다.
제가 해당 분야에 대해 잘 몰라서 잘 몰라서 질문드립니다.
global한 영역의 정보를 이용하기 위해 cost volume을 도입하셨다고 하셨는데,
스테레오 매칭에서는 cost volume 외의 global 정보를 고려하기 위한 시도가 없었는 지 궁금합니다.
또한, Context and Geometry Fusion부분에서 G와 연산을 하기위해 C_expand를 생성한다고 하셨는데, 이 expand는 어떻게 생성하는 것인지 궁금합니다. geometric한 단서를 가져가려면 위치 정보에 대한 고려가 필요할 것이라 생각되고, 단순히 padding을 하지는 않았을 것 같아서 질문드립니다.
안녕하세요. ! 댓글 감사합니다.
기존 cost volume은 local matching cost에 대한 정보만을 담고 있어서 global한 정보가 부족합니다. global 정보를 얻기 위해서 생성된 cost volume을 aggregation하는 과정을 거칩니다.
또, C_expand는 단순히 conv를 태워 channel을 맞춰줌으로써 생성됩니다. C_expand를 통해 geometric한 정보를 고려한 것이 아니라, aggregation과정에서 geometry 정보를 얻는데, 이때 중간 중간 context 정보를 넣어줌으로써 fusion하는 것입니다 .