최근 multi-modal 모델이 해당 모델을 구성하는 특정 single modality에 대해 의존성을 가지고 있는 지 검증하기 위해 관련 방법론을 서베이하였습니다. 이 논문은 서베이 중 발견한 논문으로, MSA task에서 modality의 의존성을 분석한다는 키워드를 보고 읽게 되었습니다.
본격적으로 논문을 소개해 보자면 해당 논문은 modality robustness에 초첨을 맞주고 있습니다. MSA 모델이 wild환경에서 신뢰할 만한 성능을 달성하기 위해서는 강인한 multimodal 모델을 생성하는 것이 중요하다는 것으로 시작합니다. 그럼에도 Multimodal Sentiment Analysis(MSA) 모델을 발전시키는 것에는 그다지 관심이 없었다는 점을 언급하며, 저자들은 본 논문에서 MSA모델들을 다양한 관점에서 분석하여 robust한 multimodal model을 설계하는 토대를 마련하고자 하였습니다.
먼저 사전 학습된 MSA 모델에서 각 모달리티의 robustness를 검증하는 방식을 제안하였는데, 해당 방법을 통해 기존 MSA 모델들을 분석한 결과 멀티모달은 단일 모달리티에 상당히 민감하다는 결론을 도출하였습니다.
다음으로는 issue를 alleviate하기 위해 기존에 널리 알려진 학습 방식을 분석하였는데, 기존 성능과의 타협 없이 robust한 모델을 완성할 수 있음을 확인하였습니다.
저자들은 총 5개의 모델과 2개의 데이터셋에서 분석을 진행하였습니다.
Introduction
저자들은 ‘multimodal robustness’에 집중하고자 하였는데요, 기존 연구들을 통해 MSA는 language(text)가 가장 효과적으로 작용하는 경향이 있다고 알려져 있습니다. 여기서 language가 가장 효과적으로 작용한다는 것은 multimodal 모델에서 language를 핵심 moality로 활용하는 것을 의미하며, 전체 모달리티를 사용한 성능이 text에 의존적이라고 이해하시면 될 것 같습니다. 이러한 현상을 바탕으로, 본 논문의 저자들은 skewed dependence on language와 이들이 MSA모델의 robustness에 어떤 영향을 주는지 분석하는 데 집중하였고, 구체적으로는 아래와 같은 의문을 중심으로 각각에 답하고자 하였습니다.
RQ1: Are models in MSA over-reliant on a subset of modalities, particularly language?
RQ2: If yes, what implications does it have on modality robustness?
RQ1, MSA 모델이 특정 모달리티, 그 중에서도 language(text)에 의존하는지 확인하기 위해 저자들은 text+audio+visual 데이터로 사전 학습된 MSA 모델에 두 가지 모달리티만을 사용하여 평가를 진행하였습니다. 즉, 하나의 모달리티가 제거되었을 때 성능 변화를 확인함으로써, 가장 변화가 큰 모달리티가 가장 영향력이 있다고 분석하고자 한 것입니다. 아래의 [그림 1]이 MISA 모델과 CMU-MOSI 데이터셋으로 실험한 결과입니다.
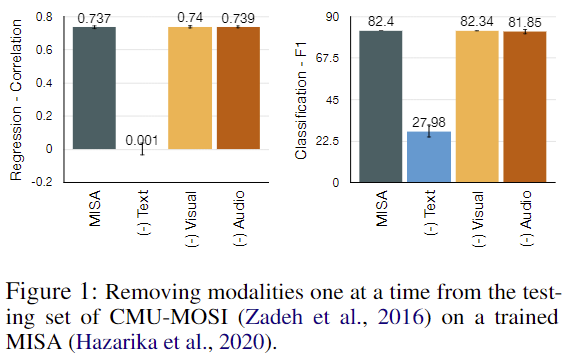
[그림 1]을 보면 text를 제거하였을 때 상당한 성능 하락을 보여주는데요, 반면에 audio, vision은 거의 성능 변화가 없습니다. 이는 앞서 언급했던 ‘MSA 모델은 text에 의존적이라는 것을 의미합니다. 이러한 결과를 바탕으로, 저자들은 text 의존적인 MSA의 특성이 MSA의 modality robustness에는 어떻게 작용하는 지 이해하고자 하였습니다. 이를 위해 MSA의 modality robustness를 진단하는 방법을 설계하여 MSA가 missing 혹은 noisy modality error에 얼마나 robust하게 대응하는 지 분석하였으며, 해당 결과는 method 부분에서 설명드리도록 하겠습니다.
저자들은 위의 분석 결과를 바탕으로 아래와 같은 의문을 추가적으로 제기하였습니다.
RQ3: How can we improve the robustness of these models?
RQ4: Does robust training lead to a performance trade-off?
즉, RQ1, 2를 통해 알아낸 특정 모달리티에 민감한 MSA 모델을 modality robust하게 만들 수 있는 학습 방법론을 제안하였고 해당 방법론으로 학습한 결과가 robustness와 performance간의 trade-off 여부까지 실험하였습니다.
Testing Robustness via Diagnostic Checks
논문의 저자들은 MSA의 deployment 과정에서 발생할 수 있는 modality error를 모델링하여 modality robustness에 대한 고찰을 진행하였습니다. 실험의 보편성을 검증하기 위해 RNN-based부터 transformer-based까지 다양한 구조의 sota 모델을 선정하여 실험하였고 사용한 모델은 MISA, BBFN, Self-MM, MMM, MulT의 5 종류이며, 데이터셋으로는 MSA에서 가장 보편적으로 사용되는 CMU-MOSI와 CMU-MOSI를 사용하였다고 합니다.
Proposed Diagnostic Checks
논문에서는 MSA 모델의 분석을 위해 두 가지 방법을 사용하였습니다. 하나는 Missing Modality 상황을 모사하기 위해 데이터셋에서 특정 모달리티를 제거하는 방법이고, 다른 하나는 Noisy modality를 가정하여 각 모달리티 별 representation에 가우시안 노이즈를 더해줌으로써 random change를 발생시키는 방법입니다. 논문에서는 realistic scenario를 위해 전체 데이터셋의 30%에 위의 변형을 가하였다고 언급하였습니다. 또한 intro 부분에서 잠시 언급했듯 MSA 모델은 text 모달리티에 의존적인 경향이 있는데, 이로 인해 논문에서는 연구의 일반성을 잃지 않으면서도, text 정보에서 발생할 수 있는 오류가 모델의 성능에 미치는 영향을 보다 집중적으로 분석했다고 합니다.
위의 접근 방식을 통한 MSA 모델의 분석 결과는 real world의 데이터 손실, 왜곡이 발생하는 환경에서 모델이 얼마나 robust한 지 평가할 수 있는 요소로써 사용될 수 있다고 합니다.
구체적인 구현 과정을 수식으로 나타내 보겠습니다. language(text) 모달리티 l에 대해 모든 모델은 T_l개의 token으로 구성된 자연어 sequence가 입력되면 각 token을 d_l차원의 벡터로 임베딩을 진행합니다. 여기서 출력된 low-level embedding U_l은 T_l \times d_l크기의 벡터가 되는데, U_l을 BERT와 같은 encoder를 통해 language representation u_l을 추출하여 우리가 알고 있는 딥러닝 모델의 input으로 사용됩니다. 논문에서는 u_l에 missing과 noise를 추가하였는데, test set에서 u_i의 30%를 sampling하고 샘플링된 u_i를 \hat u_l = f(u_l)로 변경하였습니다. f(x)는 missing인 경우 f(x)=x⊙0으로 \hat u_l은 zero vector가 되고, noise인 경우에는 f(x)=x+N(0,1) 즉, white noise를 더해주는 연산이 됩니다.
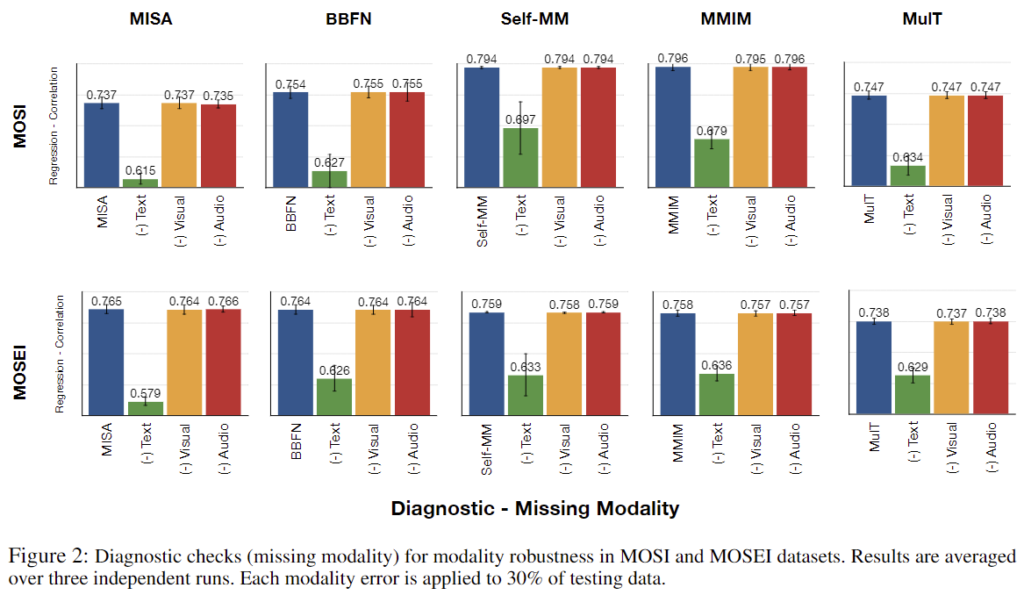
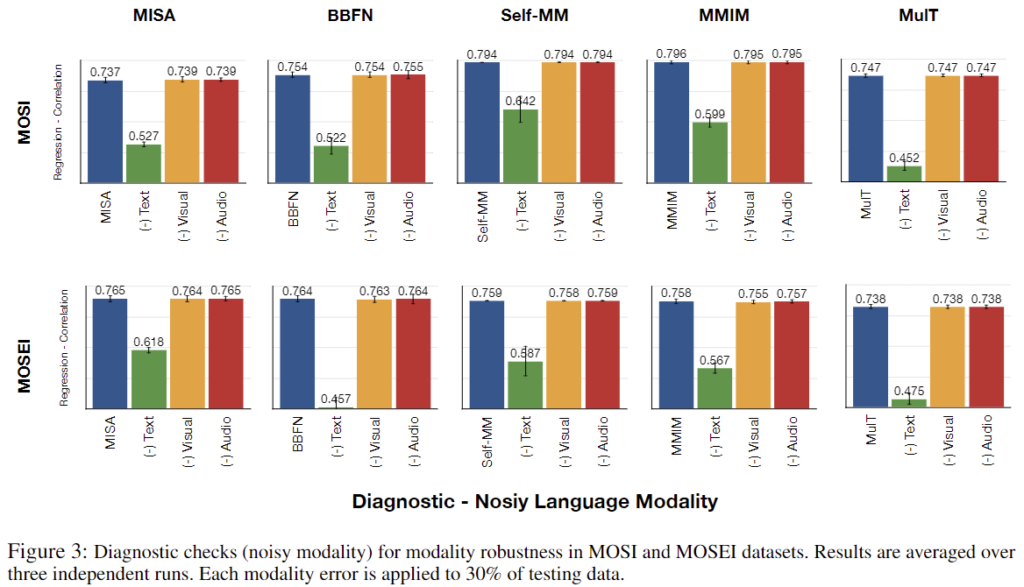
위의 diagnostic checks를 통해 사전 학습된 MSA 모델의 결과를 측정한 결과는 [그림 2]와 [그림 3]과 같습니다. MOSI와 MOSEI 데이터셋 모두 text 모달리티의 하락폭이 큰 것을 확인할 수 있는데, 이를 통해 text 모달리티가 text의 modality error에 민감하다는 것을 확인할 수 있습니다. 즉, real world에서도 멀티모달 감성 분류를 수행할 때 text 모달리티에 이상이 발생할 경우 성능에 치명적인 영향을 줄 수 있다는 것입니다.
Robust Training
논문에서는 modality robustness를 확보하기 위해서 dominant modality, 즉 text에 대한 민잠성을 줄이는 방법을 고안하였는데요, 해당 방법은 단순히 학습 중에 text의 modality error 시나리오를 추가하여 모델이 다양한 상황에 대응하도록 하는 것입니다. 이러한 접근 방식을 modality perturbation이라 칭하였으며, 과정은 아래와 같습니다.
Training
- 어떤 data batch에서 pertubate될 데이터를 지정된 비율만큼 sampling.
- sampling된 데이터의 dominant modality를 [Proposed Diagnostic Checks]에서 언급된 바와 같이 변형함. 이때 sampling된 데이터의 50%는 missing, 나머지는 noise pertubation을 수행함. 이를 batch 마다 반복.
위의 방법은 단순히 dropout이나 nosing과 같은 regularization을 특정 모달리티에 적용한 것으로 모델이 text 모달리티의 누락이나 데이터의 변형 같은 시나리오에 더 잘 적응하도록 함으로써, real world 조건에서도 모델의 robustness와 generalization을 향상시키게 됩니다. 결과적으로, 모델이 단순히 text 정보에만 의존하지 않고, 다른 모달리티에서 얻은 정보를 활용하여 성능을 도출하도록 할 수 있습니다.
Results
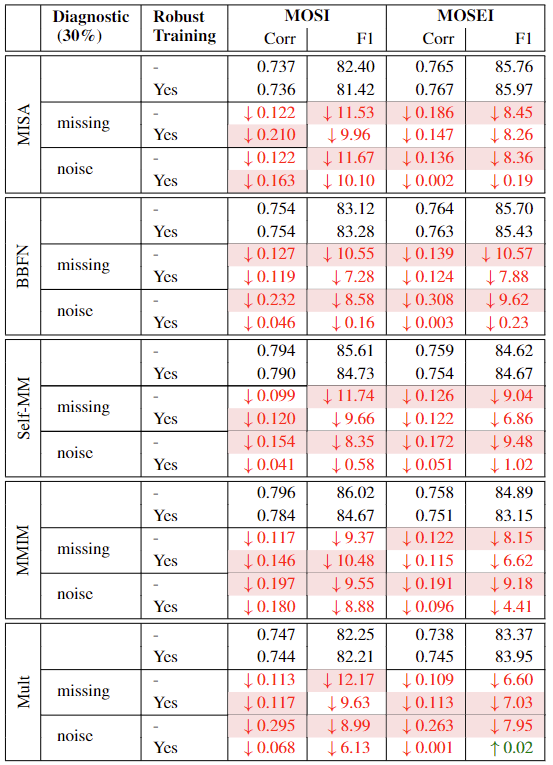
먼저 robustness에 대한 결과부터 살펴보겠습니다. [표 1]은 평가 시 test 데이터의 왜곡 여부와 training 시 robust training의 적용 여부에 따른 MSA 모델의 성능을 나타내고 있습니다. perturbation을 통해 성능 하락을 줄인 것을 확인할 수 있는데요, f1기준으로 missing은 31%, noise는 98%가량으로 감소치가 줄어들었습니다.
(Self-MM, MOSI)와 같이 missing diagnostic에서 Corr의 성능 하락이 약간 증가한 경우도 있으나, 다른 모든 경우에서 robust training이 잘 동작한 것을 확인할 수 있으며, 논문에서는 이를 통해 RNN 기반 및 Transformer 기반 모델 모두 robust training이 의미있는 결과를 가져왔음을 언급하였습니다.
다음으로는 performance trade-off에 관해 살펴보겠습니다. Regularization을 통해 robustness를 완화하는 경우, 모델의 robustness는 확보할 수 있으나, original test setting에서의 성능보다 낮은 성능을 달성하는 trade-off가 발생할 수 있습니다. 이에 저자들은 modality-perturbatioin을 통한 robustness 확보가 원래 test 환경, 즉, 어떠한 왜곡도 발생하지 않은 test 데이터의 평가 성능의 저하를 가져오는 지 실험하고자 하였습니다. [표 1]에서 (test)Diagnostic이 적용되지 않은 실험 결과를 보면 robust training에 의해 발생하는 성능 변화가 크지 않으며, 어떤 우에는 증가하는 것을 통해 clean data 성능에 대해 trade-off가 발생하지 않고 모델의 robustness를 확보한 것을 확인할 수 있습니다.
좋은 리뷰 감사합니다.
Proposed Diagnostic Checks 파트에서, 전체 데이터셋의 30%에 대하여 가우시안 노이즈를 주는 변형을 주었다고 하셨는데, 모달리티별로 다른 데이터에 대한 30인지 아니면 전체 데이터 중 30%를 선택하여 세 모달리티에 모두 가우시안 노이즈를 더하는 것인지 궁금합니다. 공정한 비교를 위해서는 후자일 것이라 생각되는데, 그렇다면 각 데이터에 대하여 의미론적으로 동일한 부분에 동일한 정도의 노이즈를 주는 것인지도 궁금합니다.
또한, Robust Training을 위해 text 도메인에 대하여 노이즈한 입력을 학습하도록 한다고 하셨는데, 다른 모달리티에 오류를 학습하는 실험은 따로 없었는 지, 혹은 다른 모달리티에 대한 노이즈 학습이 필요한지에 대한 혜원님의 의견이 궁금합니다.
마지막으로, 제가 해당 태스그에 익숙하지 않아서 그런지, results의 표를 어떻게 해석해야할 지 잘 이해가 되지 않아서 질문드립니다. missing과 noise에 대한 실험 결과는 성능 하락 정도를 표현한 것이 맞을까요? 또한, 해당 표의 어떤 값을 통해 ‘f1 기준 missing의 31%, noise는 98% 가량으로 감소치가 줄어들었’는지 조금 더 설명해주실 수 있나요??
안녕하세요, 혜원님! 좋은 리뷰 감사합니다.
멀티모달 모델에서 어떤 종류의 데이터가 성능에 가장 큰 영향을 끼치는 것인지 분석하고
그렇다면, 실제 다양한 변수가 존재하는 real world상황에서 지배적인 모달리티의 데이터의 누락 또한 손상에 대한 경우를 고려하여 모델의 의존성을 낮추는 것을 목적으로 한 학습과 실험이 인상적이었습니다!
제가 자연어처리 분야에 대해서 잘 알지 못하여 한 가지 질문 사항이 생겼습니다.
텍스트의 language representation에 noise를 추가하면, 원본 텍스트데이터가 어떤 식으로 변형되는 것인지 궁금합니다. 그리고 그렇게 변형된 텍스트 데이터가 실제 상황에도 자주 등장하는 것인지 궁금합니다.
감사합니다.