안녕하세요, 스물일곱 번째 X-Review입니다. 이번 논문은 2024년도 Infrared physics & technology에게재된 Thermal-visible stereo matching at night based on Multi-Modal Autoencoder 논문입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
현재 RGB 카메라 기반의 센서 기술은 여러 application 측면에서 성공적인 발전을 해오고 있지만, visible 스펙트럼의 한계로 인해 RGB 카메라 기반의 스테레오 매칭은 밤과 같은 scene에서는 적용하기 어렵습니다. 이에 따라 밤 상황에서의 RGB 카메라의 단점을 보완하기 위해 thermal 카메라와 같은 센서를 함께 사용하는 연구도 진행되고 있습니다.
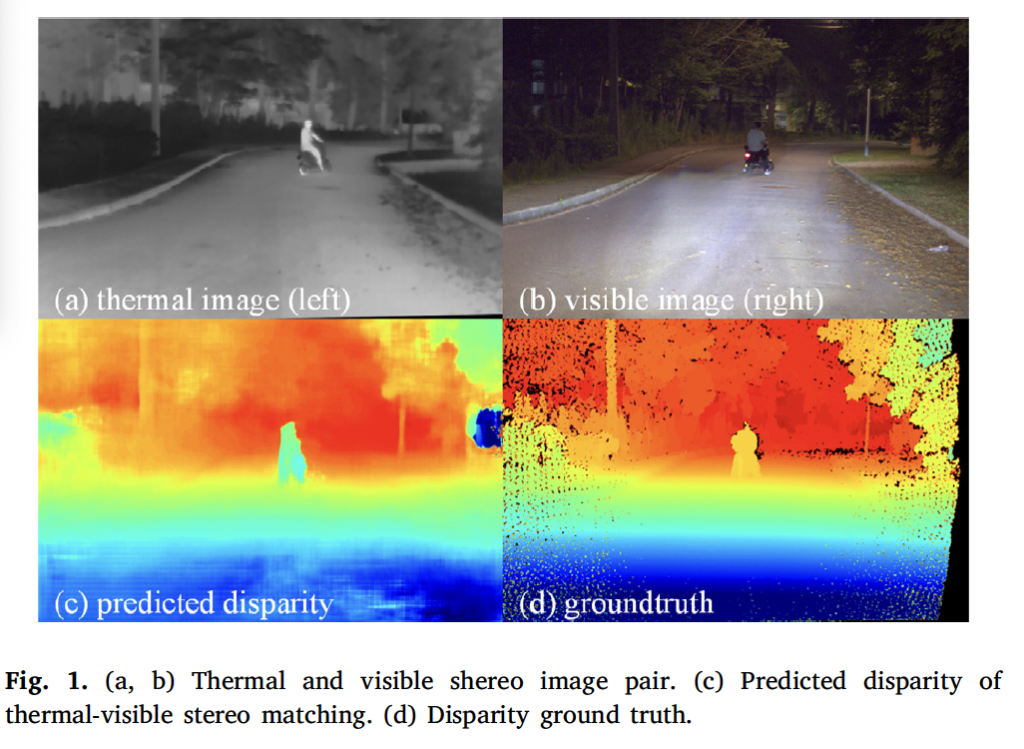
Fig 1의 (a), (b)에서 확인할 수 있듯이 thermal 카메라로 취득한 영상(a)는 주변 조명의 영향을 받지 않아서 all-day task, 특히 night vision task에 적용할 수 있습니다.
하지만, 이 열복사 기반 IR 영상은 일반적으로 해상도가 낮고 texture 정보도 좋지 않아서 thermal-visible 이미지 매칭 문제는 아직 미해결 문제로 남아있습니다.
이 thermal-visible matching은 image fusion 등과 같은 다양한 visual application에 사용될 수 있는데, visible 영상과 thermal 영상은 동일한 대상이나 scene에 대해 공통적인 정보나 보완할 수 있는 정보를 제공하게 됩니다. 이 凸보충 정보는 단일 모달리티 내에서 구별하기 어려운 대상을 보충하는데 사용될 수 있으며, 공통적인 정보같은 경우는 visual-thermal 매칭과정을 수행하는 데 중요하게 적용됩니다. 이 visual, thermal (multimodal) task에 관한 다양한 연구가 진행되어 왔지만 thermal 영상은 RGB 영상에 비해 객체에 대한 디테일한 정보가 부족하기 때문에 픽셀 수준으로 disparity를 예측해야 하는 작업을 처리하는데 어려움을 보였습니다. 그래서 대부분의 연구들은 thermal-visual image fusion이나 multi-modal detection에 집중되어 있었습니다. 하지만 최근에는 thermal-visible consistenct 정보가 modal-invariant 특징 추출이나 멀티모달 스테레오 매칭에 사용될 수 있음을 입증하는 연구들이 제안되었으며, 관련 데이터셋도 등장하였습니다.
근데, 밤 상황에서 현존하는 thermal-visible 스테레오 매칭 방법론들은 3가지 중요한 문제점이 존재합니다.
- RGB 영상에서 어두운 부분의 정보는 thermal 영상과 matching하는데 거의 사용할 수 없고, thermal 영상은 texture 정보도 부족하다.
- thermal-visible stereo camera 간단하고 효율적으로 calibration하지 못한다.
- 공간 정보를 보존하면서 thermal visible 영상의 모달리티 불변한 특징을 추출하는 것이 어렵다.
이런 문제점을 해결하기 위해 본 논문의 저자는 모달리티 불변한 특징을 추출해내는 MANet 프레임워크를 제안합니다. 추가로 아래 method부분에서 자세히 설명드릴 cross-consistency 제약 조건을 설계하여 특징 추출 능력을 향상시켰으며 추가로 실용적인 calibration 방식을 설계하여 thermal-visible stereo dataset을 구축하였습니다. 아래 method 단에서 자세히 살펴보도록 하겠습니다.
2. Proposed method
2.1. Feature extraction based on multi-modal autoencoder
스테레오 매칭은 한 이미지 쌍이 있을 때 기준 이미지의 각 픽셀에 대응하는 point를 타겟 이미지에서 찾아야 하는 pixel -level의 task입니다. 따라서 modality-invariant한 information map을 생성하는 것이 필요합니다. thermal영상과 visible 영상은 서로 다른 modality를 사용하여 같은 scene을 표현하며, 이때 scene feature는 modality-invariant한 속성을 갖게 됩니다. 이는 다시 말해 scene feature는 오직 사람이나 자동차, 나무, 도로 건물 등과 같은 object의 identity information(식별 정보)만 전달하기 때문에 다른 모달리티의 generator에 의해 scene feature를 해당 모달리티의 영상으로 변환할 수 있음을 의미합니다. 이에 기반하여 본 논문에서 제안된 멀티모달 오토인코더는 2가지 과정으로 구성됩니다. 1) scene feature에 대한 single modal 영상 생성 2) 모달리티-특수한 영상에 대한 scene feature 생성
본 논문에서 제안된 multi-modal autoencoder network(이하 MANet)은 2개의 encoder와 generator로 나눠볼 수 있습니다.
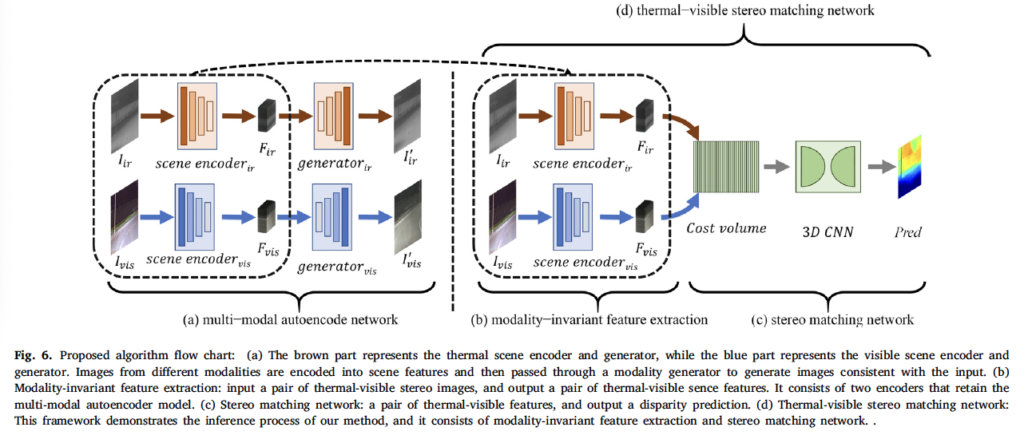
그림으로 살펴보자면, MANet은 그림 6의 (a)에 해당합니다. rgb, thermal 모달리티에 대해 각각의 인코더와 generator(decoder라고 봐도 무방)가 존재하는 것을 확인할 수 있습니다. 전체적인 아키텍처 구조는 (d)와 같은데, 이는 psmnet에서 영감을 받은 것으로 스테레오 매칭 네트워크와 유사하게 cost volume을 생성하고 3D convolution을 태워 aggregation 과정을 거쳐 disparity를 추정하게 됩니다. 이때 사용되는 scene encoder같은 경우에는 사전학습한 MANet을 사용하는 것입니다. 이 MANet에서는 추가적으로 consistency feature constraint와 self-reconstruction constraint를 제안하여 cross-modal feature를 추출할 수 있도록 하였습니다.
(1) Multi-modal Autoencoder (MANet)
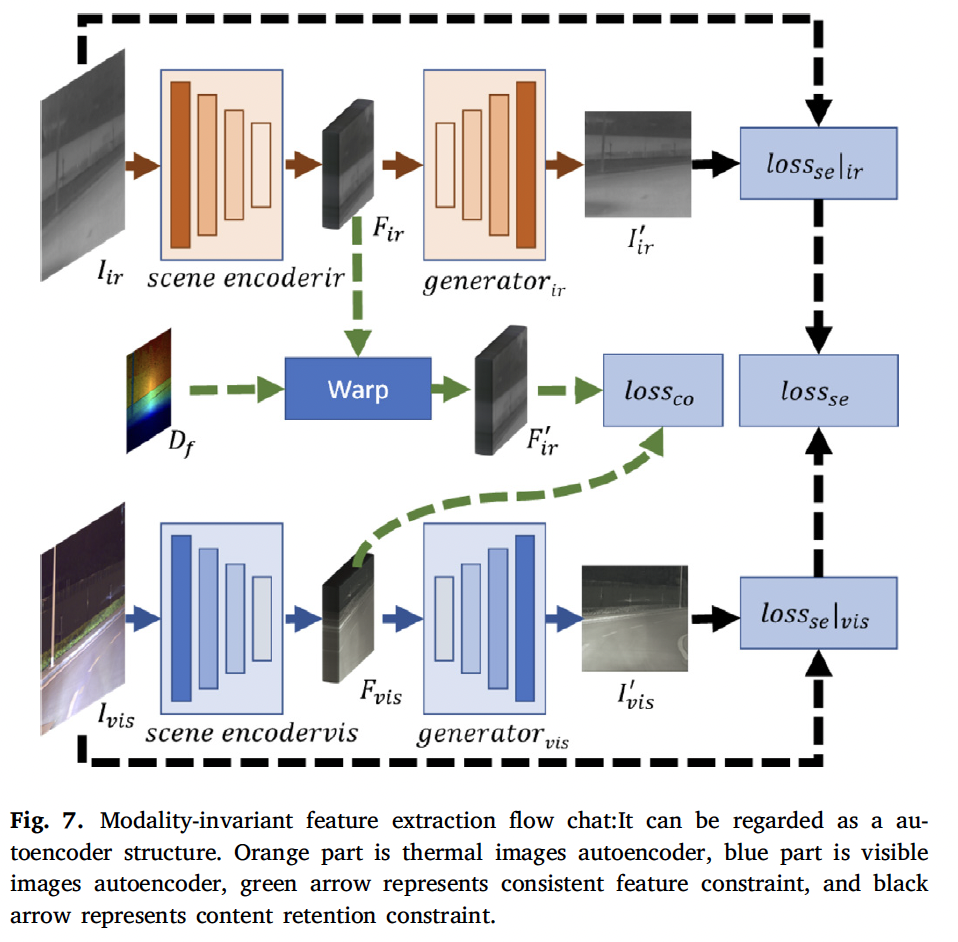
MANet 구조는 fig7에서 확인할 수 있듯이 scene encoder와 generator로 나눌 수 있습니다. scene encoder는 multi-channel의 scene feature layer를 생성하며, generator는 이 scene feature layer 해당 모달리티의 이미지로 변환하는 역할을 수행합니다. 하나씩 알아보도록 하겠습니다.
Scene Encoder
scene encoder는 다양한 모달리티에서 scene feature를 추출하는데, 이때 모달리티 간의 scene feature를 일관성있게 추출하도록 합니다. 즉, 같은 장면에 대한 입력이 들어왔을 때 추출된 feature가 유사해야하고 일관성이 있어야 함을 의미하겠습니다.
또 이 특징 추출 네트워크는 dual-path 구조를 가집니다. 일반적으로 단일 모달 스테레오 매칭에서는 대부분 siamese network(샴 네트워크)라고 불리는 ,, 파라미터를 공유하는 네트워크를 사용하여 feature를 추출하는데 본 논문에서는 서로 다른 모달리티에서의 invariant한 feautre를 추출하는 것이 목표이기 때문에 두 인코더 간의 파라미터 공유를 하지 않고 feature extract layer가 다른 모달리티의 정보를 동일한 feautre space 상으로 보낼 수 있도록 하였습니다. 즉, 이 dual-path 구조를 통해 visible-thermal 영상에서 modality invariant한 feature를 추출하기 위해 샴 네트워크의 sharing parameter를 해체하여 다른 모달리티에서의 featuer extraction 성능을 개선한 것으로 보면 되겠습니다.
Modality Generator
thermal과 visible scene encoder는 각각 다른 모달리티 이미지를 feature로 추출하게 되고 이런 feature layer는 feature consistency loss를 통해 학습되며 일관성을 갖도록 학습되게 됩니다. 모달리티 generator같은 경우는 여러개의 deconvolution layer를 사용하여 입력과 동일한 크기로 feature를 upsampling하고 이렇게 획득한 영상과 원본 영상 간의 mse loss를 계산하여 scene encoder가 정보를 잃지 않도록 하는 과정을 수행합니다. 이 decoder(generator)는 MANet을 학습할 때 encoder의 학습을 보조하는 역할로 실제 thermal-visible matching 과정에는 이 decoder는 제거됩니다.
(2) Modality-invariant feature constraint
본 논문의 constraint는 크게 3가지 부분으로 나눌 수 있습니다. 1) consistency feature constraint 2) self-reconstruction constraint, 3) cross-reconstruction constraint
그림 6(a)에서 I_{ir}, I_{vis}는 각각 thermal, visible 영상이며 MANet을 통해 생성된 영상들은 각각I^{’}_{ir}, I^{’}_{vis}
입니다. 아래 식과 같이 표현되겠죠.

그리고 추출된 feature는 사전학습한 MANet에서 encoder 부분에 각 입력 영상을 넣음으로써 생성되겠죠. 아래 식과 같이 표현할 수 있습니다.

이제 저자가 설계한 각 loss에 대해 살펴보도록 하겠습니다.
Consistent Feature Constraint
먼저, 일관성있는 feature에 대한 손실 함수는 두 scene encoder가 동일한 feature를 출력하도록 설계되었습니다. 그림 7에서 Loss{co}를 통해 같은 feature space에 cross-modal 정보를 매핑하게 됩니다. feature layer의 크기는 입력 영상의 1/4이며, 식 15를 통해 disparity map도 동일한 크기로 resize하였습니다. (그림 7에서 D_f에 해당합니다.)


이후 식 16과 같이 이 disparity map을 가지고 thermal feature layer를 와핑하는 작업을 거칩니다. 이때 와핑 후 thermal feature는 visible feature와 근사해야 한다는 목적을 가지고 아래와 같이 손실 함수를 구성하였습니다.

이 Loss{co}가 첫번째 Consistent Feature Constraint에 해당합니다.
Self-reconstruction Constraint
방금 설명한 feature consistency constraint같은 경우 cross-modal 정보에서 매칭되지 않은 부분들은 배제되게 됩니다. 이는 modal-invariant한 feature가 사라진다는 것을 의미하게 되겠죠. 그래서 이 content 정보를 유지하기 위해 self-reconstruction 손실 함수를 제안하게 됩니다.
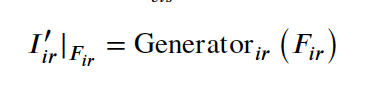
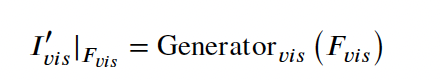
위와 같이 generator를 통해 생성된 feature를 I^{’}_{ir}|_{F_ir}, I^{’}_{vis}|_{F_vis}라고 하겠습니다.
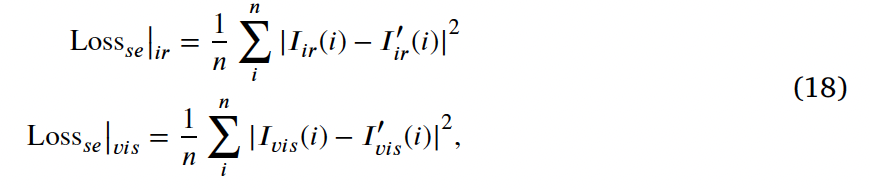
- n : 전체 픽셀 수

이때 loss 함수는 다음과 같이 구성됩니다. 이는 I_{ir}, I^{’}_{ir}, I_{vis}, I^{’}_{vis}가 입력 정보를 유지하도록 하는 방향으로 학습하도록 한 것입니다. 이렇게 하면 scene encoder가 single consistent constraint(첫번째 loss)에 의해 정보가 손실되는 것을 막을 수 있습니다.
Cross-reconstruction Constraint
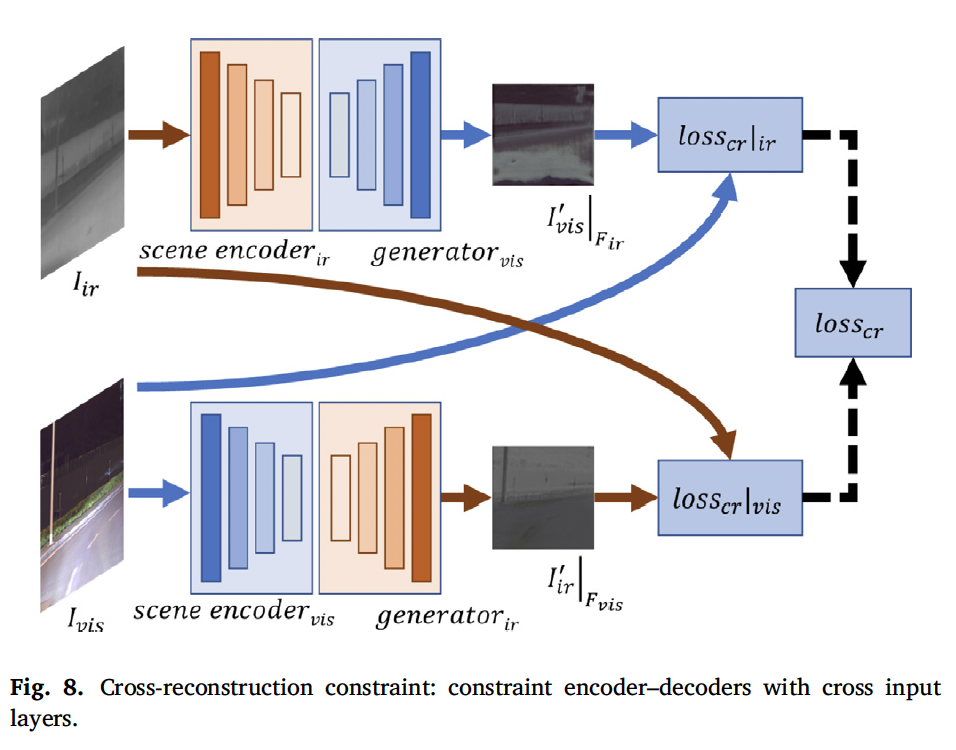
마지막으로 self-reconstruction constraint입니다. scene feature가 입력 모달리티의 영향을 덜 받는다는 점을 고려하여 제안된 loss인데, 그림 8과 같이 전체 모달리티 영상에 대한 cross reconstruction을 수행하는 것입니다. 이는 cross 입력 layer로 decoder의 output에 제한을 주는 것인데, 예를 들어 thermal decoder 같은 경우에는 thermal feature를 decoding하는데 집중하면서 동시에 visible encoder가 RGB 영상에서 모달리티 invariant한 정보를 추출할 수 있도록 하는 것입니다. 식은 아래와 같습니다.
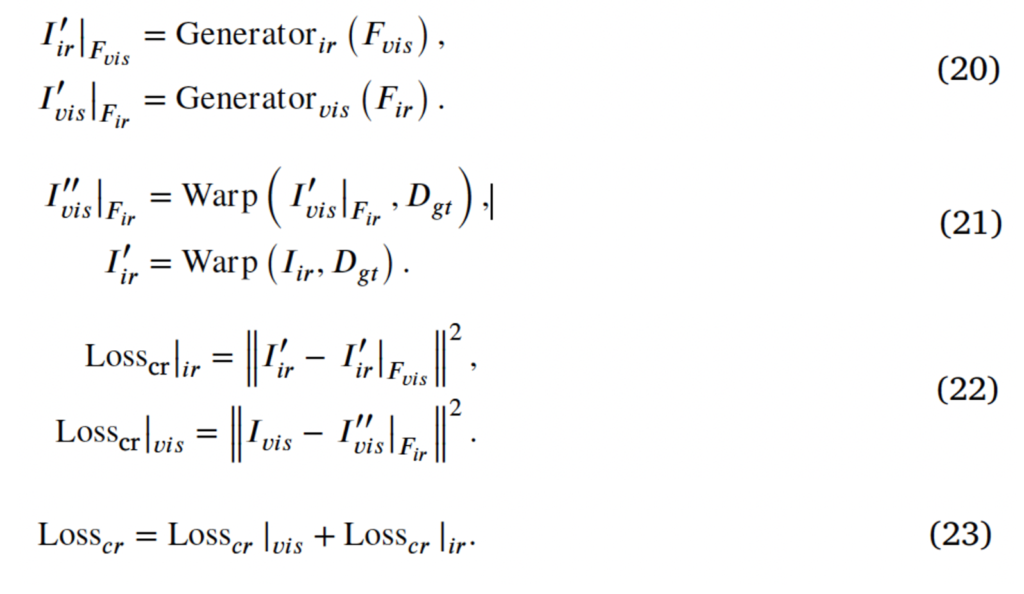
2.2. Thermal-visible stereo matching network
방금까지는 MANet의 loss를 살펴봤다면 이제 사전학습한 MANet의 encoder를 포함한 thermal-visible stereo matching network에 대해 살펴보겠습니다. 이 네트워크를 SMNet(Stereo matching network)라고 칭한다면 입력으로 thermal-visible 영상이 들어오게 되겠고 이를 통해 disparity map을 최종적으로 출력하게 되겠죠.

위와 같이 표현할 수 있겠습니다.
이때 GCNet의 아이디어를 차용하여 cost volume을 생성하도록 하였는데, 간단하게 말하자면 feature로부터 correlation을 계산하는 것을 통해 cost volume을 생성하는 것입니다. 이후 aggregation 과정을 거치는데 이는 encoder-decoder(stacked hourglass 구조)를 사용하였습니다. 이 aggregatioㅜ 과정은 더 많은 context 정보를 학습하는 과정입니다.
스테레오 매칭이 어려운 밤 장면에 대해서는 thermal-visible 영상의 특성을 기반으로 한 가중치 맵을 사용하였습니다. 이때 SNR(신호 대비 noise 비율) map에 따라 다른 모달리티에 대한 attention map을 설계하여 사용하였다고 합니다. 이게 아래 식에서 w_v에 해당합니다. 또 w_c는 대비에 대한 가중치입니다. RGB 영상을 HSV로 변환하고 V 채널을 가중치로 사용하였다고 하네요.
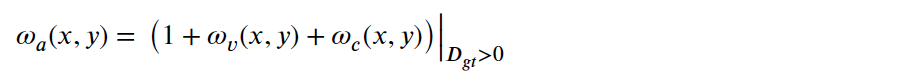
이 가중치 맵 생성 과정은 위 식으로 계산됩니다.
최종적으로 네트워크를 학습하는 손실함수는 아래와 같습니다.
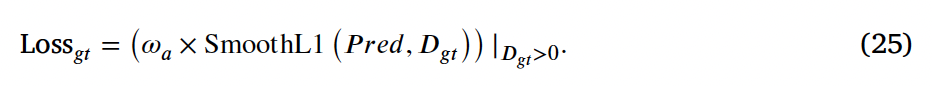
일반적으로 많이 사용하는 Smooth1 loss를 사용하였으며 여기에 위에서 계산한 가중치를 곱한 것이 최종 loss 값으로 계산되게 됩니다.
3. Experiment
cross modal task에서 사용할 수 있는 데이터셋으로는 LITIV, CATS, KAIST 등이 있는데, LITIV, KAIST 데이터셋을 스테레오 매칭 테스크에 사용하기에는 density가 너무 낮다고 하며 CATS 데이터셋의 변형이 너무 크다고 합니다. (변형이 크다는게 먼지는 잘 모르겠습니다. . .) 그래서 본 논문에서 저자는 새로운 데이터셋을 제안하였습니다. thermal 카메라 RGB 카메라, LiDAR를 사용해서 말이죠. 제안된 데이터셋은 총 762장으로 640은 학습에 122는 test에 사용했다고 합니다.

데이터셋은 outdoor 데이터셋이며 예시는 fig9에서 확인할 수 있습니다. 맨 위가 thermal, 가운데가 RGB 맨 아래가 gt disparity map에 해당합니다.
Training
전체 학습 과정은 두 단계로 나뉩니다. 먼저 MANet을 사전학습 하는 것과 사전학습한 MANet의 encoder가 포함된 네트워크를 end-to-end로 학습하는 것으로 말이죠. end-to-end로 학습한 결과를 평가할 때는 MAE 평가지표를 사용하였습니다.
Results
(1) Results of the Ablation Experiments

ablation 결과는 표 1과 같습니다. 본 논문에서 제안된 3개의 loss에 대한 실험인데, loss의 가중치를 달리해가며 실험한 결과는 표의 오른쪽 MAE로 비교하면 되겠습니다. 이 self, cross, disp에 대한 각각의 MAE는 아래와 같이 계산됩니다.
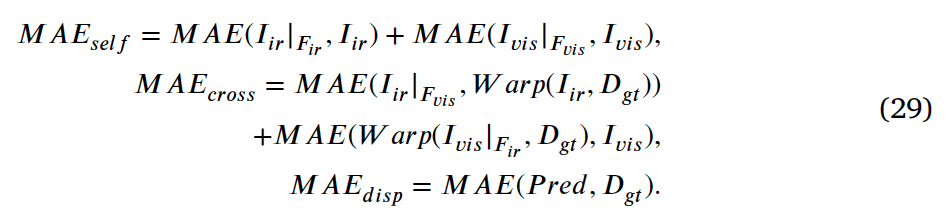
결과적으로 표의 맨 아래쪽 결과가 가장 낮은 MAE를 보였기에 이를 선택하였다고 합니다.
(2) Results of the Comparitive Experiments
다음으로는 다른 방법론들과의 정량적 정성적 비교 실험입니다. 스테레오 매칭 task에서 전통적인 알고리즘들은 cross-modal 특징을 추출하는데에 한계점이 존재한다고 합니다. 그래서 본 논문에서는 전통적인 알고리즘인 DASC와 SPS를 포함하여 네트워크 기반의 알고리즘들도 실험하였다고 합니다. 저자는 s2dNet이라고 하는 depth prediction 네트워크를 한 개의 visible 영상에 대해 실험함으로써 밤 상황에 대한 multi-modal 매칭의 우수성을 증명하였으며, 추가적으로 cross-modal 스테레오 매칭 알고리즘인 CS와 고전 스테레오 매칭 알고리즘인 PSMNet도 실험에 사용하였습니다.

실험 결과는 표 3과 같습니다. 전통적인 알고리즘인 SPS와 DASC의 성능을 보면 MAE가 가장 높은 것으로 매칭 성능이 좋지 않습니다. 추가적으로 thermal을 사용하지 않고 rgb만 사용한 s2dNet의 경우에는 딥러닝 기반 방법론들 중 가장 성능이 좋지 않은 것을 보아 밤 상황에서의 cross-modal stereo matching 방법론이 효과적임을 보입니다. 저자가 제안한 방법론이 아무래도 멀티 모달에 특화된 스테레오 매칭 방법론이다보니 가장 성능이 높은 것을 확인할 수 있습니다.
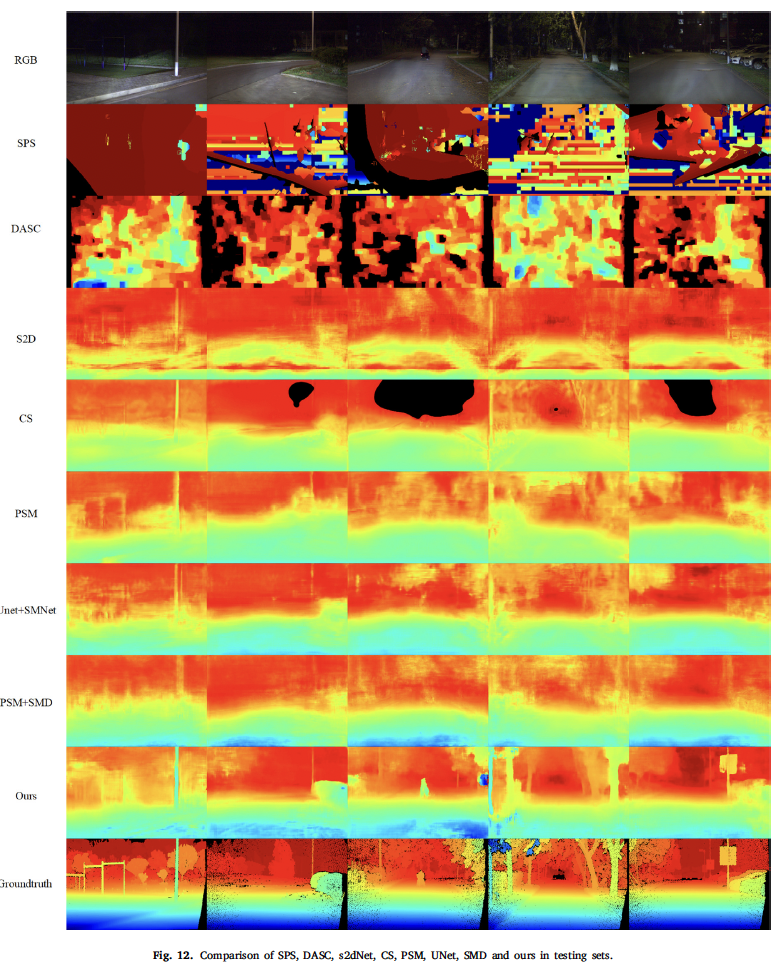
정성적인 결과는 위와 같습니다.
(3) The Experimental Results on the CATS
마지막으로 CATS 데이터셋에서의 결과입니다.

위 데이블은 CATS 데이터셋에 대한 표입니다. CATS 데이터셋은 indoor와 outdoor에 대한 scene을 포함하고 있고 high normal low라고 되어 있는 것은 여러 이상상황 condition에 대한 정도를 의미합니다. 구체적으로는 fog와 light에 대한 정도를 달리하며 촬영되었습니다. 저자는 본 방법론의 강인함과 일반화 성능을 확인하기 위해 CATS 데이터셋은 80%의 학습 데이터셋과 (오직 normal 상황) 20%의 test 데이터셋으로 나누었습니다. 이전과 마찬가지로 평가지표로는 MAE를 사용하였습니다.

실험 결과는 표5와 같습니다. 전통적인 방법론 DASC와 네트워크 기반 방법론 CS, PSMNet에 대한 실험을 수행하였는데, CATS 데이터셋에서도 마찬가지로 본 논문에서 제안된 방법론이 가장 성능이 높은 것을 확인할 수 있습니다.
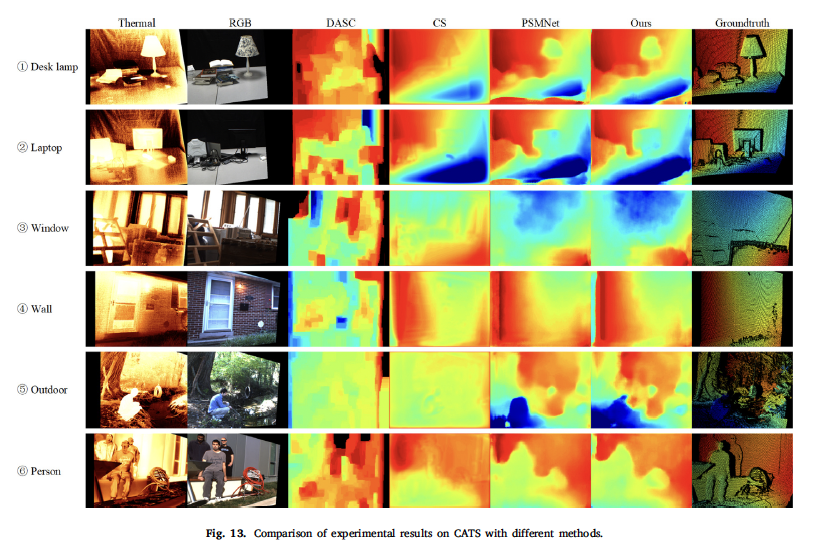
Fig13은 CATS 데이터셋에서의 정성적인 결과입니다. 위로부터 3장은 indoor scene이며 4~6번째 영상은 outdoor scene입니다. 실내 영상의 검은색 모니터를 정확하게 감지하는 것은 어려웠지만 다른 방법론과 비교했을 때 disparity를 잘 추정했다고 합니다.
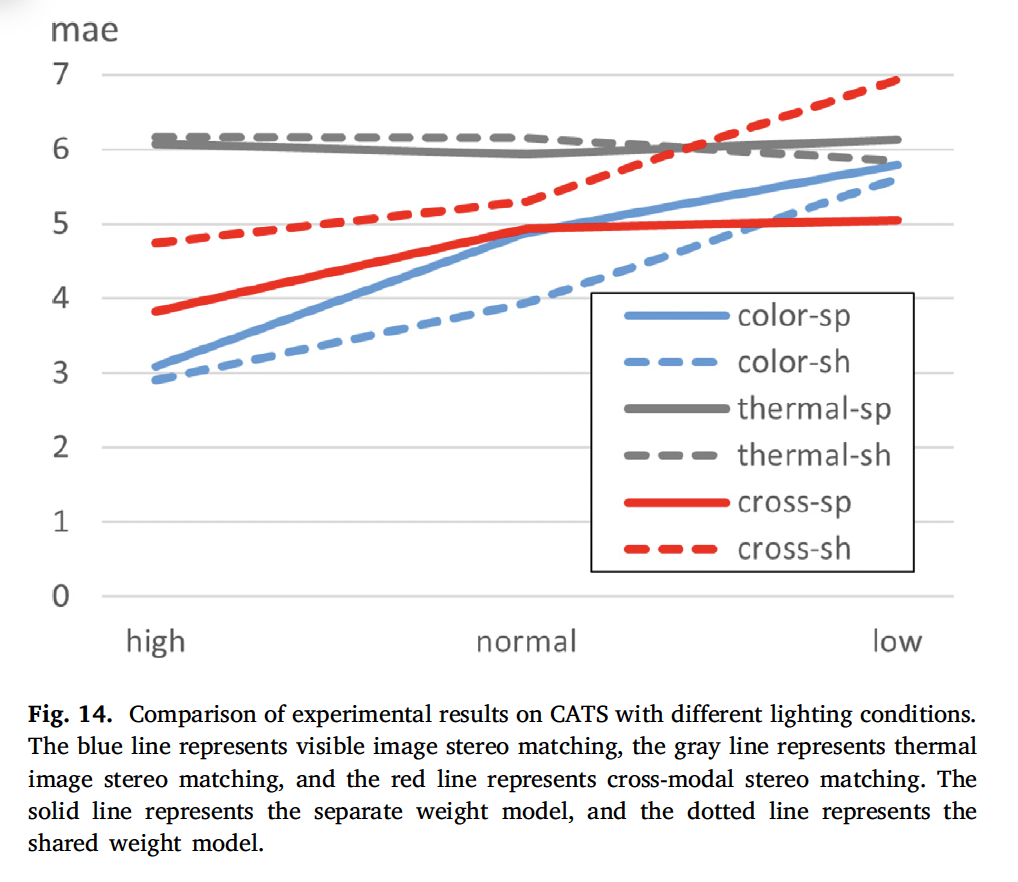
마지막으로 여러 조도 환경을 갖는 CATS 데이터셋에서 조도 변화에 따른 실험 결과입니다. visible 스테레오 매칭은 항상 조명 조건의 영향을 받고, thermal 스테레오 매칭은 해상도가 작아서 항상 좋은 결과를 얻을 수 없었습니다. 이를 해결하고자 제안된 MANet은 scene에 대한 특징 추출을 학습하는 과정에서 visible 인코더는 저조도 환경에서 thermal 모달리티의 강인함을 학습하고, thermal 인코더는 visible 영상의 디테일한 정보를 학습하도록 하였습니다. 이에 대한 성능을 입증하는 실험이라고 보면 되겠습니다. CATS 데이터셋에는 high, normal, low로 세 단계의 조도 변화를 준 데이터셋이 존재하는데 이 중 각각 10개의 샘플을 선택하여 test영상으로 사용하였고 나머지는 전부 학습 데이터셋으로 사용하였습니다.
fig14에서 회색 라인은 thermal 스테레오 매칭 결과이며, 파란색은 visible 스테레오 매칭, 빨간색이 cross 스테레오 매칭입니다. 점선은 둘 간의 weight를 공유한 것에 해당합니다.
이 가중치를 분리한 결과는 cross-modal stereo mathing에서만 성능이 더 나으며, 가중치를 공유하는 것은 단일 모달 스테레오 매칭에서 성능이 더 좋습니다. 또 조도가 낮아짐에 따라 visible, cross 매칭의 경우에는 성능이 하락함을 보이지만 thermal 스테레오 매칭은 조명의 변화에 영황을 받지 않음을 보입니다. 이에 따라 cross modal 에서도 visible 스테레오 매칭만큼 성능 하락이 심하지 않네요. 즉, 극도로 조도가 낮은 상황에서는 cross-modal stereo matching이 visible stereo matching보다 성능이 뛰어나다는 결론은 내릴 수 있겠습니다.
안녕하세요 윤서님, 좋은 리뷰 감사합니다.
스테레오 매칭이란 것이 결국 disparity map이나 depth map을 잘 얻어내기 위한 과정이며, 저자가 말하는 MAnet을 이용하면 cross-modal 스테레오 매칭이 저조도 상황에서 성능이 뛰어나다라는 것으로 받아들였습니다.
일단 scene encoder에서 scene feature를 일관성있게 추출하도록 하기 위해, Consistent Feature Constraint 가 필요했고, 이것은 Loss_co 설명으로 이어지면서 같은 feature space에 cross-modal 정보를 매핑한다고 이해했습니다.
이때 Fig.7와 식 16에서 disparity map을 가지고 thermal feature layer를 와핑하여 visible feature와 근사하게 해야한다고 언급하셨는데, visible feauture를 와핑하여 thermal feature에 근사하는 것보다 thermal feature를 와핑해서 visible feature에 근사하는 이유가 무엇인가요?
결국에 scene feature는 object의 identity information만을 전달하기 위해 필요했는데, thermal modality에서의 feature 에서는 해상도가 작고, 픽셀 수준의 texture 정보 등도 더 부족했기 때문에 와핑을 수행해서 더 정보가 많은 visible 쪽으로 근사하는 것이라고 이해해도 될까요..?
그리고 멀티모달 오토인코더 2가지 과정에서
1. scene feature 에 대한 single model 영상 생성
2. 모달리티 특수한 영상에 대한 scene feature 생성
등이 있다고 하셨는데 모달리티-특수한 영상이란 것이 어떤 걸 뜻하는 건가요?
해당 리뷰에 대해 옳게 이해한 것이 맞는지 궁금하여 질문 드립니다
감사합니다
안녕하세요 윤서님 좋은 리뷰 감사합니다.
1. 먼저 수식 15번에서 질문이 있습니다. Df의 경우 Fig1 에서의 Disparity gt를 의미하는 것 같은데 nearest는 무엇을 의미하는 건가요?
2. 와핑이 무슨 작업을 하는지 궁금한데 Fir을 와핑후 나온 F’ir는 Fir과 어떤 차이가 있나요?
3. RGB 영상을 HSV로 변환하고 V 채널을 가중치로 사용했다 하셨는데 V 채널은 무엇을 의미하며 어떤 역할을 하나요?
감사합니다.