
이번에 소개드릴 논문은 VisionAdapter라는 논문입니다. 방법론의 컨셉 자체는 단순한 것 같은데 ViT 구조에 언제든지 붙일 수 있다보니 그 범용성이 좋고 성능 향상도 크게 올리다보니 다양한 테스크의 챌린지에서 수상한 팀들이 기본적으로 활용하는 방법론인 것 같습니다.
Intro
Transformer는 NLP에서부터 시작해서 지금은 Image, Audio, Video, Text 등등 데이터를 가리지 않고 어떤 모달리티에서도 강인한게 잘 동작하는 신경망 구조로 알려져있습니다. 아무래도 트랜스포머의 self-attention이라는 연산 자체가 입력 모달리티의 관계를 계산하다보니 어떤 모달리티에서도 잘 어울리는게 아닌가 싶습니다.
이러한 트랜스포머가 image domain에서 가장 처음 등장하는 것은 vision transformer라고 하는 논문에서 시작됐습니다. 영상의 16×16 패치 영역을 마치 문장 속 단어 하나로 보고 이들의 관계성을 추론하는 구조였죠. 이러한 원조? ViT는 영상의 특성을 크게 고려하기보다는, NLP에서 처음 등장한 트랜스포머의 구조를 최대한 따라가는 것에 초점을 맞추었습니다. 그러다보니 단순히 영상 뿐만 아니라 영상과 텍스트 또는 오디오와 같이 멀티모달 데이터로 사전학습을 할 수 있으며 이를 통해 더욱 풍부한 의미적 표현을 학습할 수 있게 되었죠.
하지만 원조 ViT는 vision modal에 중점이 되는 transformer들(swin 등)과 비교했을 때는 영상과 관련된 사전 지식이 부족하여 수렴도 느리고 성능도 부족하다는 단점이 존재했습니다. 예를 들어, 영상 데이터는 예로부터 스케일에 대한 개념을 상당히 중요시 여겼으며 이러한 스케일 정보 포착 및 연산량을 줄이는 관점에서 CNN은 풀링 과정이 적용된 계층적 구조를 많이 활용하였습니다.
이러한 CNN의 구조를 따라서 Pyramid ViT, Swin Transformer와 같이 계층적 구조의 트랜스포머 방법론들이 제안되었으며 이들은 원조 ViT보다 더 좋은 영상 인식 성능을 보여주었습니다. 이러한 관점에서, 저자들은 원조 ViT도 구조적 특성을 크게 변경하지 않고 영상 모달리티에 초점을 둔 다른 트랜스포머와 비슷하거나 더 좋은 성능을 낼 수 있도록 하는 것을 목표로 두었습니다.
그리고 NLP 분야에서 사용되는 adpter라는 것에 영감을 받아서, 원조 ViT와 Vision 맞춤형 트랜스포머들 과의 성능 갭을 줄이고자 하였죠. 원조 ViT와 영상 맞춤형 트랜스포머들의 가장 큰 차이점은 CNN의 inductive bias를 어떻게 추가하느냐였는데, 저자들은 영상 맞춤형 inductive bias를 원조 ViT에게도 도입하기 위해 3가지 모듈을 설계하였습니다.
먼저 공간적 사전지식 모듈(Spatial Prior Module)을 통해 공간적 의미론적인 정보를 포착할 수 있게 하고, 공간특징을 주입하는 모듈(Injector)을 통해 ViT가 해당 정보를 활용할 수 있도록 하였으며, Dense prediction 분야에서 필수적인 다중 스케일의 특징들을 잘 구축하기 위해 multi-scale 특징 추출기(multi-scale feature extractor)를 도입했다고 합니다.
즉 저자들이 제안하는 Adapter라고 하는 것은 위에 3가지 모듈로 구성이 되어있다고 생각하시면 되는데, 보다 자세한 내용은 아래에서 다루도록 하겠습니다.
Method
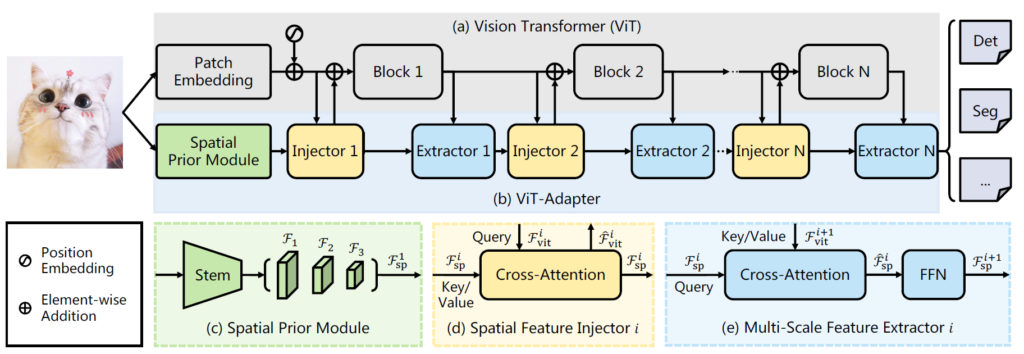
우선 그림1은 ViT-Adapter의 전체 프레임워크를 나타냅니다. 크게 2가지 브랜치로 나뉘는 것을 보실 수 있을텐데, 회색부분(a)는 원조 ViT의 흐름을 나타낸 것입니다. 그리고 가운데 파란색 부분(b)의 경우 저자들이 제안하는 Adapter의 브랜치를 나타냅니다.
실제 저희가 downstream task에서 모델을 학습시킬 때, (a) 부분을 fine-tuning했던 반면, ViT-Adapter의 경우에는 (a)는 freeze시키고 (b)만을 학습시키는 방향으로 학습을 진행하기 때문에 모델 학습에 사용하는 파라미터의 수가 상대적으로 크게 감소하며, 특정 task에 맞췃 Adapter만을 학습시켜주면 pretrained ViT를 기반으로 다양한 sub task를 수행할 수 있다는 이점이 있습니다.
아무튼 다시 Adapter로 넘어오면, Adapter의 가장 처음 시작은 Spatial Prior Module(SPM)로 시작을 합니다. 즉 입력 영상을 SPM에 태워서 1/8, 1/16, 1/32 스케일의 feature map을 추출하게 되며, 그 뒤로 ViT의 token들과 SPM의 feature 들 사이에 feature interaction을 수행하기 위해 SPM의 특징맵들이 flatten & concat이 되게 됩니다.
이러한 spatial prior를 injector를 통해 ViT block에 삽입함. 그리고나서 ViT의 출력에 multi-scale feature extractor를 적용하여 계층적 특징을 추출하게 됩니다. injector와 MS extractor의 반복 과정을 통해 다양한 해상도의 고퀄리티 image feature를 추출할 수 있게 됩니다.
그럼 각각의 모듈 (SPM, Injector, MS Extractor)에 대해서는 아래 섹션에서 더 자세히 설명하겠습니다.
Spatial Prior Module
우선 SPM은 컨볼루션 레이어로만 구성된 모듈로 어찌보면 작은 CNN이라고 생각하셔도 될 것 같습니다. max pooling이랑 3개의 컨볼루션으로 구성된 RESNet의 conv stem으로 구성되며, stride2, 3×3 컨볼루션을 반복적으로 태워서 채널은 키우고 해상도는 줄이는 과정을 진행합니다.
이렇게 추출한 multi-scale feature map에 대하여 1×1 conv layer를 태워서 각 특징맵들의 차원을 하나로 통일해줍니다. 그리고 이 모든 특징들을 위에서도 설명드렸다시피 flatten & concat을 하여 \frac{HW}{8^{2}} + \frac{HW}{16^{2}} + \frac{HW}{32^{2}} \times D 의 shape을 가지도록 합니다.
Spatial Feature Injector
다음은 Injector에 대한 설명입니다. Injector의 역할은 SPM을 통해 추출한 영상의 spatial feature를 (inductive bias가 부족한) ViT token에다가 injection하는 모듈인데요, 사실 injection이라고 해서 뭐 거창한 연산이 들어가는 것은 아니고 ViT의 token을 Query로 두었을 때 SPM에서 추출한 Multi-scale feature map을 Key와 Value로 두고 cross-attention 연산을 수행하는 것입니다.
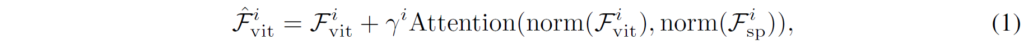
자 여기서 norm은 Layer normalization을 의미하며, F^{i}_{vit}, F^{i}_{sp} 는 각각 i번째 ViT 블록에서 가져온 ViT token과 SPM의 feature를 의미합니다. 그리고 attention 연산은 query key value에 대한 attention으로 트랜스포머에 대해 잘 아실거라 생각하고 구체적인 설명 없이 넘어가겠습니다.
아무튼 이렇게 cross-attention을 마친 결과값들은 바로 ViT block으로 다시 전달되는 것이 아닙니다. 기존의 ViT block과 더해주는데 이때 수식(1)에서 잘 보시면 감마 값이 하나 존재합니다. 즉 감마값을 통해 SPM 모듈의 injection 결과값을 얼마나 반영할지를 정하게 되는 것이죠.
이러한 감마값 또한 학습 가능한 파라미터로써, 모델이 injection을 얼만큼 할지 말지를 학습하여 상황에 맞게 적응적으로 vision feature를 전달해주게 됩니다. 아무튼 수식 1을 통해 vision feature가 적용된 \hat{F}^{i}_{vit} 가 ViT block을 통과하여 Self-attention과 FFN을 반복해 i+1번째의 ViT 토큰을 생성하게 됩니다.
Multi-Scale Feature Extractor
그 다음은 MS Feature Extractor 부분입니다. 저희가 아까 수식1을 통해 injection 과정을 거쳐서 \hat{F}^{i}_{vit} 를 생성하였고, 이를 i번째 ViT block에 태워서 i+1번째의 ViT token ( F^{i+1}_{vit} 를 생성하였다면, 해당 i+1 ViT token이 i번째 SPM feature ( F^{sp}_{i} )에 전달되어 보다 표현력이 좋은 multi-scale feature를 생성하는 과정을 거치게 됩니다.
이 과정은 반대로 생각하면 Injector가 ViT block에 SPM의 vision feature를 전달해주는 역할이었다면, 반대로 MS Feature Extractor의 경우 ViT block이 SPM에서 추출된 feature map에 ViT의 좋은 feature 정보를 injection한다고 보시면 되는데요, 실제 연산 자체도 Injector에서는 Query가 ViT였던 반면 MS Feature Extractor에서는 Query가 SPM의 feature map들이고 Key와 Value가 i+1번째 ViT Token이 되게 됩니다.
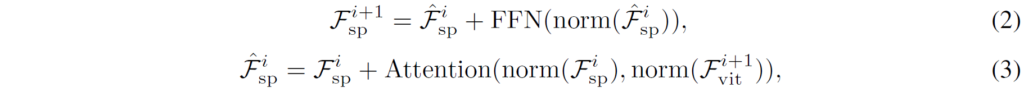
MS feature extractor 부분은 ViT token과의 cross attention 이후에 Feed Forward Network까지 거치게 되면서 더 고품질의 feature map을 생성하게 됩니다.
사실 이게 끝입니다. 이러한 MS Feature Extractor 과정이 마치게 되면 다시 또 그 다음번째 step에서 Injector를 수행하고 다시 Feature Extractor를 수행하는 식으로 계속 반복을 하게 됩니다.
저자들은 참고로 Injector와 Feature Extractor에서 Cross-attention을 수행할 때 ViT의 Global attention을 수행하는 것이 아닌 Deformable Attention을 수행하였다고 합니다. 이는 Global Attention보다 Deformable attention이 연산량도 훨씬 적으면서 정확도는 더 좋았기 때문이라고 합니다.
Experiments
그럼 정량적 결과 비교와 Ablation study를 소개하고 리뷰 마치도록 하겠습니다. 우선 첫번째로는 COCO dataset에서 MaskRCNN을 이용한 Object Detection과 Instance Segmentation에 대한 결과입니다.
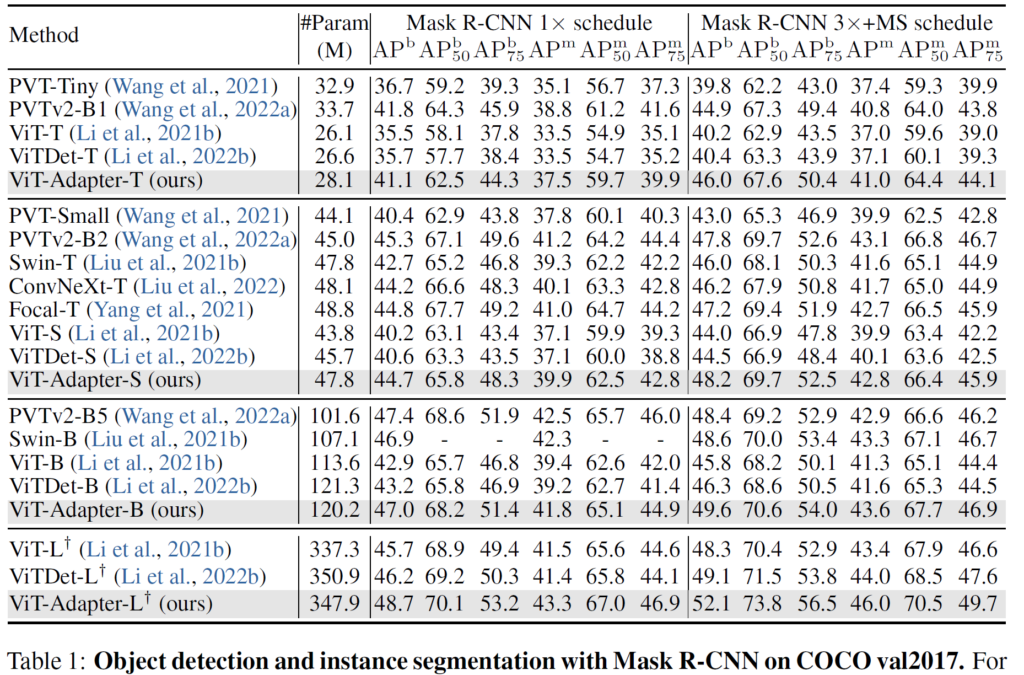
먼저 기존의 ViT-?, ViTDet-?라고 명칭붙은 방법론들은 원조 ViT 백본을 기반으로 검출 및 분할을 수행한 실험들입니다. 이들은 image의 특성들을 고려해서 계층적 구조로 설계한 PvT나 Swin 트랜스포머의 비해 영상의 특성을 잘 파악하지 못하여 검출 및 분할 성능이 상대적으로 아쉬운 모습을 보여준다고 합니다.
하지만 저자들이 제안한 ViT-Adapter-? 계열들은 Adapter를 추가하였지만 파라미터의 수가 크게 증가하지 않았을 뿐더러 오히려 성능은 기존 PVT나 Swin transformer와 유사한 (혹은 더 높은) 성능을 달성해주는 모습을 확인하실 수 있습니다.
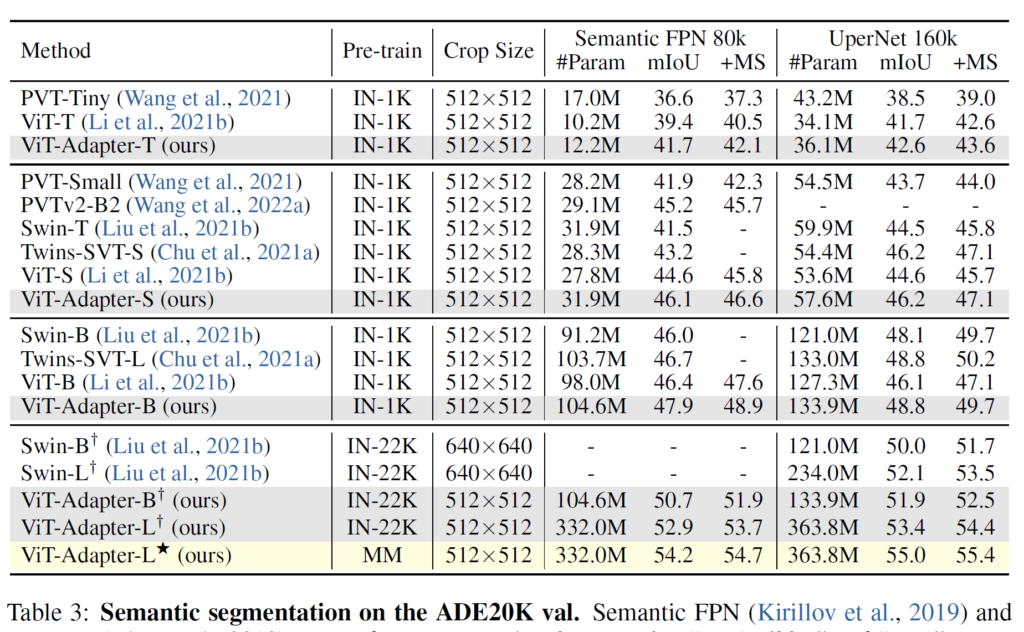
또한 이러한 경향성은 Semantic Segmentation에서도 잘 나타나게 됩니다. ViT 백본을 활용한 방법론과 비교해서 Adapter만을 추가했을 뿐인데 조금의 파라미터 증가로 mIOU 성능은 2%정도 이상의 향상폭을 보여주고 있습니다.
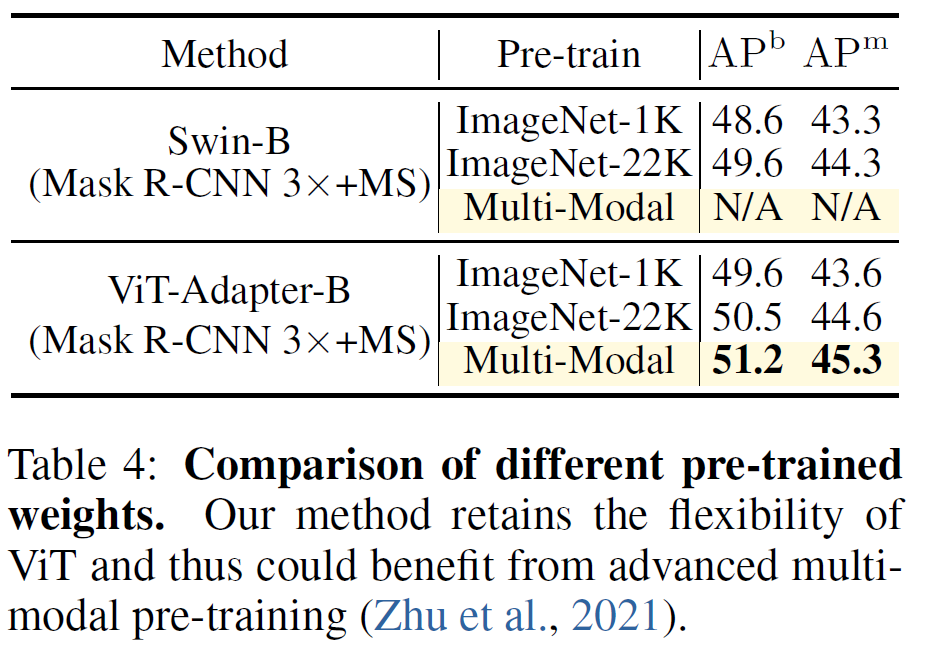
그리고 pretrain에서 MM이라고 명시된 부분은 Multi modal dataset으로 학습한 결과라고하는데, 원조 ViT의 경우 인트로에서도 소개드렸다시피 이미지 특성에 초점을 맞추어 설계한 모델은 아니다보니 다양한 멀티모달 데이터 셋으로 사전학습 할 수 있으며, 이러한 멀티 모달의 특징 표현력을 지님과 동시에 영상의 부족한 특징을 adapter로 보완하여 더 좋은 segmentation 성능을 달성하는 모습입니다.
이러한 멀티모달의 경향성은 아래 ViT-B 사이즈의 모델에서도 동일하게 관측할 수 있습니다.
Ablation Study
다음은 Ablation study에 대한 결과입니다. 우선 아래 표는 ViT-S를 기본 backbone으로 두고, 저자가 제안한 SPM, Injector, Extractor 각각이 어 떠한 성능 이점을 가져오는지를 나타낸 결과입니다.

보시면 확실히 각각의 모듈을 추가했을 때 성능이 점진적으로 향상되는 것을 확인하실 수 있습니다. 이는 ViT backbone에 CNN의 inductive bias를 추가하는 것이 영상 인식 관점에서 더 유효하다는 점, 그리고 Injector와 Extractor 과정을 통해 보다 적극적으로 feature들 간에 상호작용을 수행하는 것이 중요하다고 볼 수 있습니다.

위에 표는 injector와 extractor에서 cross-attention을 수행할 때 어떠한 attention 연산을 수행하는 것이 계산 복잡도 및 성능의 trade-off 관계를 잘 반영하는지를 보여주는 실험입니다. 가장 기본이 되는 Global Attention의 경우 feature resolution의 제곱배 만큼 연산량이 늘어나기 때문에 FLOPS가 기하급수적으로 늘어나는 반면에 인식 성능은 또 가장 좋지도 않은 모습을 보여줍니다.
반면 그 외에 다른 attention 연산들은 Linear한 복잡도를 가지고 있어 FLOPS가 500G 아래로 크게 감소하게 되는데 여기서, Deformable Attention이라고 하는 방법론이 가장 적은 연산량을 가지면서 도잇에 가장 좋은 인식 성능을 보여주고 있어 저자들은 Deformable attention을 활용하였다고 합니다.
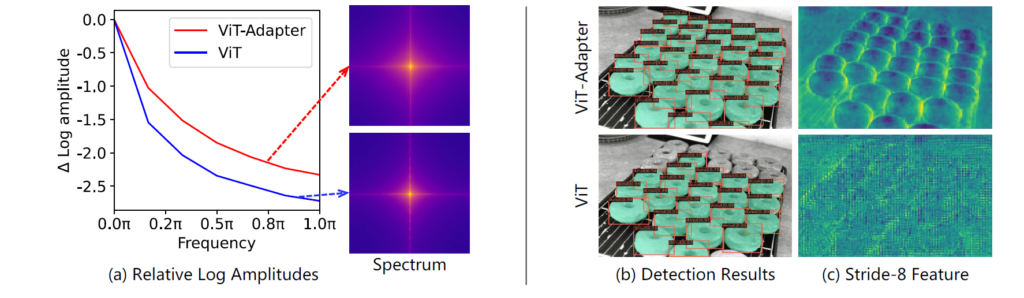
마지막으로 위에 그림2는 과연 Adapter가 저자들이 의도한대로, ViT의 부족한 image modal의 feature를 잘 학습할 수 있었는지, inductive bias를 잘 학습할 수 있었는지를 확인하기 위한 실험입니다. 예전에 ML 쪽 논문에서 CNN과 ViT 모델이 추출하는 특징에는 어떤 차이가 있는지 분석한 논문에서 CNN은 고주파의 성분(local edge & textures)을, ViT는 저주파 성분을(global feature)를 추출한다는 차이가 있다고 주장하였습니다.
저자들은 그 논문의 관측 결과를 참고하여 ViT와 ViT-Adapter의 feature map들의 주파수 성분을 분석하였는데, 대충 좌측에 (a) 그림이 그 결과입니다. 보시면 frequency의 강도에 대하여 ViT-adapter가 vit보다 더 높은 것을 볼 수 있는데 이는 곧 CNN처럼 고주파의 성분을 상대적으로 나타내고 있더라~ 라고 해석할 수 있겠습니다.
그리고 우측에 feature의 정성적 결과 역시 살펴보시면 ViT 모델의 경우 object의 shape이 많이 뭉게지고 blur한 것을 볼 수 있는 반면에 Adapter로 추출한 특징의 경우 object의 shape이 선명하게 나타난 것으로 보아 CNN처럼 고주파의 성분들을 잘 표현하구 있구나~ 라고 간접적으로 확인할 수 있습니다.
결론
방법론 자체는 단순히 간단합니다. 하지만 adapter라고 하는 이 모듈은 결국 ViT라는 백본에 항상 붙이고 그때마다 좋은 성능을 보여준다는 보장?이 있기 때문에 그 범용성과 효율성 덕분에 많은 연구에서 인기를 받는 것이 아닌가 싶습니다. 그리고 ViT는 지금도 계속해서 새로운 학습 기법 (DINOv2, Multi-modal pretraining, MAE 등등)을 통해 모델의 구조 변경 없이 계속해서 성장하고 Foundation model로 잡혀가는 것이 지금 연구의 흐름이기에, 이때 Adapter가 한층 더 강화된 ViT의 표현력을 등에 업고 다양한 downstream task에서 좋은 활약을 보여주지 않을까 싶습니다.
안녕하세요 정민님 좋은 리뷰 감사합니다.
Adapter에 관련된 내용은 처음 보는 거라 신기한 점이 많네요. adapter는 사전학습 모델을 fine-tuning하는 과정에서 생기는 단점을 보완하기 위해 처음 제안된 개념으로 알고있었는데 해당 논문에서는 3가지 모듈을 활용하여 ViT의 단점인 영상에 관련된 사전지식이 부족하다는 것을 보완하기 위한 방법론으로 이해했습니다. 공간적 의미론적 정보를 ViT에 더해주는 역할을 하는 것이 왜 adapter라고 불리는지 궁금합니다. 기존 모델의 파라미터를 freeze하고 추가된 layer만 학습하기 때문인가요? 또한 Spatial Feature Injector에서 감마 값을 활용하여 SPM 모듈의 injection 결과값을 얼마나 반영하는지를 정한다고 했는데 감마값은 학습가능한 파라미터인지 정해진 상수값인지 궁금합니다.
감사합니다.
안녕하세요.
adapter라는 이름을 붙인 것은 저자이기 때문에 저자가 그 이유를 가장 잘 알지 않을까 싶습니다만 제 개인적인 생각으로는 사전 학습된 ViT는 유지한체, 원하는 dataset 혹은 downstream task를 수행하기 위해서 그때그때 adapter를 붙여서 학습시키면 되는 것이기 때문에 그 활용성 측면에서 adapter라고 명칭이 붙은 것 같습니다.
그리고 리뷰에도 언급됐다시피, 감마값은 학습가능한 파라미터입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽으며 전체적으로 Adapter의 역할이 ViT Feature의 역할을 보강해줌과 동시에 회색 부분의 원조 ViT Block을 Freeze할 수 있어 비교적 적은 Resource로 학습할 수 있는 장점이 있다고 이해하였습니다.
이 때, (b)의 Adapter가 기존 block인 (a)에 Injection된다고 하는데, 그렇다면 (a) 모듈도 동시에 학습해야하지 않나요?? (a)를 Freeze해도 되는 이유에 대해 궁금합니다.
그렇다면 해당 방법은, 어떠한 ViT 기반의 (Transformer 기반의) 방법에서는 상용적으로 사용될 수 있는 방법일까요?
좋은 리뷰 감사합니다.
안녕하세요.
ViT block (a)를 freeze하는 이유는 잘 아시다시피 딥러닝 모델이 학습을 하게 될 경우 이전 지식을 잊어버리는 문제점이 존재하기에 ViT 백본을 대용량 셋으로 사전학습을 하다가 특정 task에 fine-tuning하게 될 경우 generalization performance를 잃어버릴 가능성이 있습니다. 그리고 ViT 모델의 사이즈가 클 수록 fine-tuning을 수행하는데 있어 많은 시간과 메모리를 잡아먹기도 하구요.
저자는 이러한 관점에서 ViT 백본은 freeze시키고, 상대적으로 매우 가벼운 adapter만을 학습시키게 되는 것인데, 이때 ViT가 freeze된 상태에서 adapter와의 연산이 적용되는 상황은 어찌보면 adapter보고 ViT의 사전학습된 특징을 최대한 활용하면서 반대로 ViT가 부족한 부분(vision modal의 특징 부족)을 adapter가 보완하도록 학습이 된다고 이해하시면 될 것 같습니다.
물론 ViT도 함께 학습에 참여시키면 더 빠르게 수렴이 되겠습니다만, 그렇게 할 경우 위에서 말씀드린 이전 지식을 잃어버리는 현상이 발생하기에 ViT를 freeze한 뒤 adapter를 학습시킴으로써 Adapter가 ViT의 표현력은 최대한 활용하면서 부족한 점을 보충하도록 학습한다고 이해하시면 될 것 같습니다.
마지막으로 adapter라는 방법론은 제가 생각했을 때 ViT가 아니더라도 다양한 backbone에서 활용이 가능할 것으로 보입니다.
감사합니다.