안녕하세요. 박성준입니다.
오늘은 또 다른 Moment Retrieval 리뷰입니다. Moment Retrieval은 자연어 쿼리에 해당하는 구간을 비디오에서 찾아서 반환하는 task입니다. input으로 untrimmed video(편집되지 않은 영상)와 text query가 주어지고, input으로 주어진 untrimmed video 내에서 쿼리의 내용에 해당하는 구간을 반환하여 사용자로 하여금 원하는 사건이 있는 위치를 찾을 수 있게 도와주는 task입니다. 이번에 리뷰할 논문은 Moment Retrieval을 zero-shot으로 시도한 논문입니다.
Introduction
자연어 쿼리들로 비디오를 이해하고 검색하는 task의 관심이 늘어나며 natural language video localization (NLVL)는 최근에 많이 연구 되고 있습니다. 여기서의 NLVL은 자연어를 활용하여 비디오의 구간을 반환하는 tasks들로 여기서의 NLVL은 Moment Retrieval로 이해해주시면 될 것 같습니다. NLVL의 annotation cost는 큰 편입니다. 자연어에 해당하는 비디오의 구간을 시작점, 끝점으로 표현해야 하기에 사람이 직접 자연어 쿼리를 인지한 채로 영상을 전부 확인해야 하기 때문입니다.(Fig.1 (a)에 해당합니다.) 이러한 annotation cost가 큰 문제를 완화하기 위해 weakly-supervised setup을 이용한 연구들도 존재합니다. 이는 annotation cost를 어느 정도 완화할 수 있지만 완전히 해결할 수는 없습니다.(Fig.1 (b)가 이에 해당합니다.)
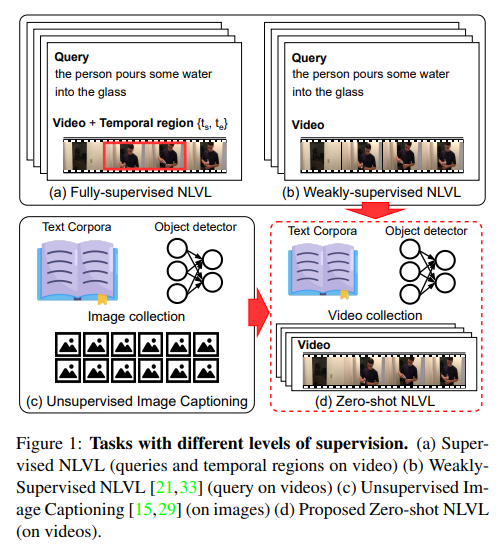
따라서 annotation cost를 아예 제외하기 위해 저자는 zero-shot NLVL(ZS-NLVL)을 제안합니다. 저자는 image captioning에서 unpaired 이미지, 자연어 corpora 그리고 객체 검출기 만을 활용하여 zero-shot 학습하는 것(Fig.1 (c))에서 영감을 받아 video에서 어느 부분을 localizing해야 하는지에 대한 정보 없이 비디오, 자연어 corpora 그리고 off-the-shelf 객체 검출기를 활용했다고 합니다.(Fig.1 (d)) 여기서 off-the-shelf는 직역하면 ‘구매한’이지만 해당 논문에서의 off-the-shelf는 ‘기존에 있던’이라는 뜻으로 다른 연구에서 제안한 객체 검출기를 사용한다는 것을 의미합니다.
zero-shot으로 task를 해결하기 위해 저자는 pseudo-supervision을 생성하는 방법을 활용했습니다. pseudo-supervision 방법은 몇가지 장점이 있습니다. 첫번째로 pseudo-supervision은 NLVL모델을 학습하기 위한 해석 가능한 자원(생성된 구역 및 문장)을 제공합니다. 두번째로 pseudo-supervision은 annotation cost를 줄일 수 있을 뿐만 아니라 사람이 annotation을 해야하는 상황에도 초기 annotation 제안을 해 annotation을 더 원활히 진행할 수 있도록 합니다. 마지막으로 pseudo-supervision은 기존의 fully-supervision 모델에 쉽게 적용할 수 있습니다.
하지만 이러한 pseudo-supervision을 도입하는 데에는 두가지 어려움이 존재합니다. 쿼리의 가능성이 있는(쿼리로 표현할 수 있는) 의미있는 temporal region을 찾는 어려움과 찾은 temporal region과 일치하는 쿼리 문장을 획득하는 것의 어려움입니다. 저자는 가능성 있는 temporal regions를 찾기 위해 cluster visual information을 제안합니다. 또한 매칭되는 쿼리를 찾기 위해 저자는 off-the-shelf 객체 검출기를 활용하여 프레임에서 볼 수 있는 명사를 추출한 후에 자연어 corpora에서 명사-동사 쌍의 통계적 패턴을 활용하여 검출된 명사(객체)와 함께 나타날 가능성이 높은 동사를 예측하는 것을 제안하고 이러한 명사-동사 집합을 pseudo-query(이하 수도 쿼리)라고 부릅니다.
아무래도 수도 쿼리는 실제 자연어 쿼리에 비하면 구조도 다르고 항상 의미있는 데이터가 아닐 수도 있지만, 저자는 이러한 pseudo-supervision에 잘 맞는 단순한 구조의 모델을 제안하며 이를 Pseudo-Supervision Video Localization(PSVL)이라고 칭합니다.
PSVL은 zero-shot에서 유의미한 성능을 보여줬으며 다음과 같은 contribution을 가집니다.
- 해당 논문은 첫 zero-shot NLVL 연구입니다.
- peudo-supervision을 활용하여 temporal event regions와 구간에 일치하는 쿼리 문장을 예측하는 PSVL모델을 제안합니다.
- 저자는 간단한 NLVL 모델 아키텍쳐를 제안합니다.
- 다른 stronger supervision과도 비교할 수 있는 zero-shot NLVL task의 baseline을 제공합니다.
Related Work
NLVL(Moment Retrieval)
Charedes-STA, ActivityNet-Captions와 같은 데이터셋들이 공개되며 NLVL연구에 많은 발전이 있었습니다. 이후로 fully-supervised 방법론들이 많이 공개되었으며 annotation cost가 높은 것을 문제삼아 weakly-supervised 방법을 활용하는 연구들도 진행되었습니다. 대부분의 weakly-supervised 방법론들은 비디오와 쿼리만 주어지고 쿼리에 해당하는 비디오의 구간에 대한 정보는 없는 형태로 연구됩니다. weakly-supervised도 결국 annotation이 필요하지만 이런 cost를 줄이기 위한 zero-shot 연구는 이전에는 존재하지 않았습니다.
Action recognition without annotation
annotation없이 actions를 분류하거나 localize하려는 시도가 몇번 있었습니다. 대부분의 이러한 연구들은 large corpora에서 object-action의 동시 발생 패턴을 활용했고 이는 저자가 소개하는 수도 쿼리와 비슷한 방식입니다.
Grounded language generation
라벨이 없는 데이터에서 자연어 문장을 만드는 것은 저자가 제안하는 수도 쿼리와 비슷한 점이 많습니다. unsupervised 기계 번역은 수도 쿼리와 비슷한 점이 많습니다. 객체 검출기와 image-sentence 집합을 활용하는 unsupervised image captioning에서 영감을 받아 객체 검출기와 video-sentence 집합을 활용하는 방법을 고안했습니다. 저자는 video가 image에 비해 더 복잡한 것을 강조하며 저자가 제안하는 수도 쿼리가 더 어려운 작업이라고 언급합니다.
Approach
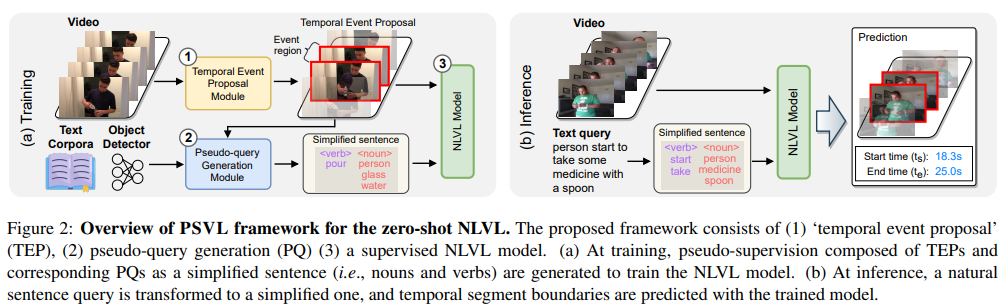
라벨링되지 않은 데이터셋을 활용하여 학습하는 대표적인 방법 중에 하나는 바로 self-supervised representation 학습입니다. 해당 방법은 두 모달리티의 paired supervision이 필요하지만, 저자의 setup은 그러항 paired annotations를 제공하지 않습니다. 대신에 pseudo-supervision을 활용하기로 결정했고, Figure 2에서 설명하는 방식을 따릅니다. temporal event proposal module을 거쳐 event가 있을 것으로 예상되는 구간을 찾은 후에 pseudo-query generation module을 거칩니다. pseudo-query module은 기존의 객체 검출기와 text corpora를 활용하여 프레임 내에 있는 객체(명사)를 추출한 후에 명사와 맞는 동사들을 더해 단어 집합으로 구성하고 이를 통해 수도 쿼리를 생성합니다. 이렇게 생성한 비디오의 event와 수도 쿼리를 활용하여 NLVL모델을 거쳐 zero-shot 학습을 진행합니다. Inference할 때에는 자연어 쿼리를 simplified sentence의 형태로 바꾼 후에 진행합니다.
Temporal Event Proposal
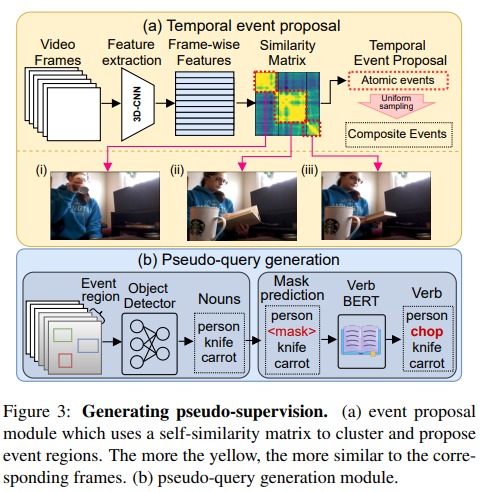
프레임워크의 첫 단계에서 의미있는 temporal event regions를 추출합니다. 여기서 가장 중요한 것은 바로 의미있는 temporal segments를 정의하는 것입니다. 저자는 atomic temporal regions에서 의미있는 구간을 추출해낼 수 있다고 가정합니다.(atomic은 원자의 라는 뜻으로 여기서는 가장 작은 단위인 프레임 level에서 추출한다는 것을 의미한다고 생각됩니다.) 하지만 이러한 atomic 단위의 의미있는 구간 추출은 비디오의 contextual 정보를 담을 수 없습니다. event를 찾는 데에 필요한 global context를 다루기 위해 저자는 프레임 단위의 유사성 행렬을 이용한 column vector를 활용하고 이를 contextualized feature이라 칭합니다.(Fig.3 (a))
Pseudo-Query Generation
의미있는 temporal regions를 생성했다면 다음 단계는 temporal regions에 맞는 쿼리를 생성하는 것입니다. 이 과정에는 두가지 문제점이 발생합니다. 하나는 쿼리는 temporal region에 일치해야된다는 것과 두번째는 semantic하게 자연스러워야 한다는 것입니다. 하지만 이를 문장으로 표현하는 것을 학습하기 위해서는 large supervised 데이터가 필요합니다.
Simplified sentence
따라서 저자는 문장을 생성하는 것 대신에 simplified sentence를 생성하는 것을 제안합니다. 프레임워크를 설명할때 나왔던 기존의 객체 검출기를 통해 객체(명사)를 추출하고 명사들을 토대로 자연어 corpora에서 잘 어울리는 동사를 추출하는 방법입니다. 하지만 simplified sentence 말 그래도 명사와 동사로 구성된 집합으로 단순화된 형태로만 존재하고 자연스러운 문장의 형태로 존재하지 않습니다.
NLP literature에서 한 사건은 frame elements와 lexical units의 집합으로 표현될 수 있으며 이를 사용하여 사건의 대표적인 의미를 전달할 수 있다고 믿습니다. 예를 들어 “The person stands up and eats pizza”는 “stand eat pizza person”으로 표현할 수 있고 이를 simplified sentence 즉, 해당 논문에서 저자가 주장하는 명사와 동사들의 집합의 형태로 표현할 수 있게 됩니다.
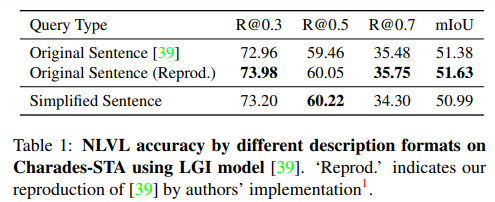
저자는 이러한 simplified sentence가 실제로 자연스러운 쿼리 문장을 대체해도 괜찮을지에 대해 진행한 실험의 결과를 Table 1에 나타냅니다. Table 1에 의하면 자연스러운 문장이 아닌 단순화된 문장을 사용해도 성능에는 큰 영향을 미치지 않는 것을 확인할 수 있습니다.
Nouns
unsupervised image captioning에서 영감을 받아 객체 검출기를 통해 객체를 검출하고 여기서 명사를 추출합니다. 여기서 객체 검출기의 성능에 따라 명사가 제대로 추출되지 않을 수 있고, 또 객체 검출기의 클래스가 비디오에서 중요한 내용을 담고 있지 않을 가능성도 있습니다. 따라서 저자는 top-N개의 빈도수를 가지는 객체(명사)만을 활용한다고 합니다.
Verbs
동사를 예측하기 위해 저자는 처음에는 사전학습된 action recognition 모델을 활용하려 했지만, action recognition에서의 action labels는 일반적인 비디오에서의 많은 동작들을 포함하지 못하는 경우가 많습니다. 때문에 저자는 다른 방식을 채용했습니다.
바로 명사들을 토대로 동사들을 생성하는 방법입니다. 하지만 이방법은 두가지 어려운 점이 존재합니다. 첫번째는 동사 생성은 closed set of action을 가정하지만 NLVL에서의 task는 open set of action인 문제입니다. 두번째는 명사는 종종 문장에서 어색한 경우가 많다는 문제입니다.
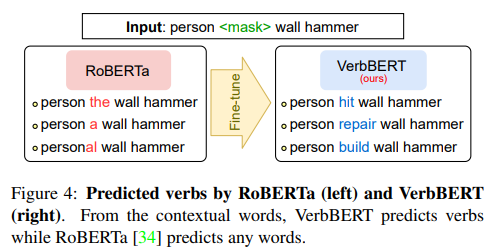
따라서 Figure4에서 나오는 것처럼 기존 RoBERTa는 명사들이 들어가도 명사를 생성하는 경우가 많지만 이 모델을 fine-tuning하여 VerbBERT로 만들어 동사만을 생성하는 모델을 만들어 활용합니다.
A simple NLVL Model
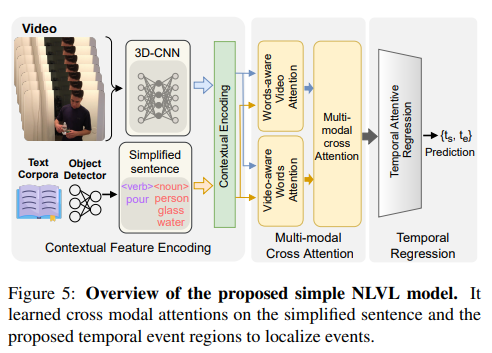
저자는 simplified sentence에 더 잘 어울리는 NLVL 모델을 제안합니다. 주체적으로 3가지 파트로 구성되어 있으면 첫번째 파트는 비디오와 simplified 문장의 임베딩 특징을 global하게 인코딩하기 위한 contextualized embedding, 두번째 파트는 multi-modal cross attention 네트워크, 그리고 세번째는 simplified 문장에 해당하는 temporal event region을 regress하기 위한 temporal attentive regression입니다.
multi-modal cross attention network에서 저자는 비디오와 자연어의 multi-modal 정보를 융합하기 위한 query-guided attention dynamic filter(Words-aware Video Attention or WVA)와 비디오-aware 쿼리 임베딩을 학습하기 위한 video-guided attention filter(Video-aware Words Attention or VWA) 그리고 위의 모든 정보를 융합하기 위한 multi-modal cross attenrion mechanism(Multi-model Cross Attention or MCA)를 사용합니다. 그 이후 Non-Local Block(NL-Block)을 사용해 cross-attention module의 global한 contextual 정보를 인코딩합니다. 마지막에는 temporal boundary regions를 MLP를 활용하여 예측합니다.
손실함수는 temporal boundary regression loss $\mathcal{L}_{reg}$와 temporal attention guided loss $\mathcal{L}_{guide}$를 더한
$\mathcal{L}_{total}=\mathcal{L}_{reg}+\lambda \mathcal{L}_{guide}$를 사용합니다. $\lambda$는 밸런싱 파라미터입니다. $\mathcal{L}_{reg}$는 Huber loss를 사용했습니다.
Experiments
데이터셋으로는 Charades-STA와 ActivityNet-Captions를 활용했습니다. 두 데이터셋 모두 NLVL에서 흔히 사용되는 데이터셋으로 자연어 쿼리와 비디오가 존재합니다.
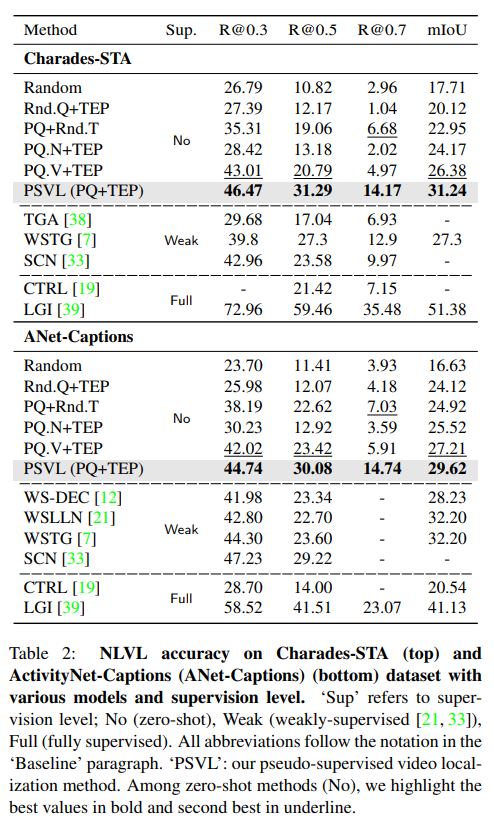
이 논문이 NLVL에 대해 zero-shot을 처음으로 적용하는 논문이다보니 저자는 baseline 설정을 어떻게 했는지에 대해서도 설명합니다. 여러가지 조건으로 baseline을 설정했으며, Random은 예측 region을 랜덤하게 가져가는 것, Rnd.Q+TEP는 랜덤 쿼리를 temporal event proposal에 적용하는 것, PQ+TEP는 random temporal regions에 수도 쿼리를 적용한 것, PQ.N+TEP는 PQ+TEP와 동일하지만 수도 쿼리에 명사만 활용한 것, PQ.V+TEP는 수도 쿼리에 동사만 활용한 것입니다. 그리고 PSVL이 저자가 제안하는 방법을 모두 활용한 모델입니다. 또한 저자는 weakly-supervised 모델과 fully-supervised 모델 몇개도 같이 성능을 비교합니다. TGA, WSLLN, SCN 세모델은 weakly-supervised 모델이며 CTRL, LGI 두 모델은 fully-supervised 모델입니다. 여기서 PQ는 qseudo-query, TEP는 temporal event proposal입니다.
놀랍게도 PSVL은 당시에 존재하던 weakly-supervised 모델들 보다 더 좋은 성능을 보여주며 zero-shot의 가능성을 보여줍니다. fully-supervised에 비하면 낮은 성능이긴하지만 zero-shot임을 감안하면 충분한 성능이라고 논문에서 리포팅하고 있습니다.

Figure 7은 정성적 결과로 PSVL이 실제 inference시에도 준수한 성능을 낸다는 것을 보여줍니다.
Conclusion
저자는 처음으로 NLVL task에서 zero-shot 학습을 연구하며 unsupervised image captioning에서 효과적이었던 object detector를 활용한 방식을 채용해 어느 정도의 annotation이 되어있던 기존의 weakly-supervised 모델들을 오히려 뛰어넘는 성능을 보여주며 zero-shot 연구의 baseline을 제공합니다. 감사합니다.
안녕하세요. 박성준 연구원님.
좋은 리뷰 감사합니다.
Temporal event proposal 단계에서, 프레임 단위 feature를 생성하고 이들의 유사도 행렬을 만드는 것까지는 이해가 되었는데, 이 유사도 행렬로부터 proposal을 생성하는 것은 어떻게 수행되는 건가요? 그림 3에는 uniform sampling이라고 적혀있는 것 같은데, 구체적으로 어떻게 작동하는 것인지 조금만 더 설명해주시면 좋을 것 같습니다.
감사합니다!
안녕하세요 지오님 좋은 댓글 감사합니다.
유사도 행렬에서 노란색 부분일수록 해당 프레임에 유사한 구간임을 나타냅니다. 유사도 행렬을 통해 유사도가 높은 구간을 찾아 atomic events라고 합니다. 이러한 atomic events들을 활용하여 temporal event proposal을 생성하게 되는데 TEP는 균일한 분포를 따라 연속적인 사건들의 조합을 샘플링합니다. 저자는 이러한 균일한 분포를 따라 샘플링하는 것은 uniform sampling이라고 표현한 것 같습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문의 Pseudo-Query Generation에서 동사를 생성하는 부분에서 질문이 있습니다. Fig 2의 Simplified sentence 부분에서 명사에 해당하는 person,glass,water를 통해 pour라는 동사를 생성해 내는 것 같습니다. pour라는 동사가 자연스럽기는 하지만 비디오 영상에 따라 다른 동사가 올 가능성이 있다고 생각하는데 어떤 기준으로 동사가 선택되는 건가요? 예를 들면 Text Corpora에서 person,glass,water를 포함하는 문장을 찾은다음 거기서 가장 많이 나온 동사를 선택하는건가요?
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
1. 중간에 설명해주신 simplified sentence와 관련해서, “The person stands up and eats pizza”는 “stand eat pizza person”으로 표현될 수 있다고 말씀해주셨습니다. 이 때 방법론에서 활용하는 단순화 된 문장은 다른 문맥을 고려해서 모델이 만들어주는 것이 아니라 문장에 존재하는 명사와 동사만을 뽑아내어 순서 상관 없이 하나의 토큰들로 임베딩해준다는 의미인 것인가요?
2. 본 방법론이 당시를 기준으로 제안된 최초의 zero-shot 연구이고 성능도 준수하다는 점에서 contribution이 부족하다는 생각은 안들지만, 혹시 inference time에 대한 실험 결과는 없나요? 사전학습된 detector를 돌려 명사를 얻고 동사를 연관짓는 과정이 어느 정도의 시간을 수반하는지 궁금합니다.
또한 논문을 직접 찾아보니 첫 zero-shot 방법론인만큼 볼만한 ablation 실험이 많은데, 다음부터는 리뷰에 함께 포함해주시면 좋을 것으로 생각됩니다.
감사합니다.