오늘의 X-Review에서는 Zero-shot 기반으로 Temporal Action Localization을 수행하기 위해 CLIP을 활용한 논문에 대해 소개해드리겠습니다. 22년도 ECCV에 게재되었습니다.
1. Introduction
22년도는 그 당시 CLIP의 등장으로 다양한 영상 관련 task에서 zero-shot 방법론들이 큰 성능 향상을 이룩하던 시기입니다. 저자도 이에 맞게 CLIP의 knowledge를 비디오 분야에서의 zero-shot detection이 가능하도록 가져오려고 한 것이죠. 그 당시까지는 어떻게하면 CLIP을 비디오에 적용할 수 있을지 또는 적용 시 어떠한 문제점이 있는지에 대한 연구가 그리 많지 않았습니다. CLIP을 비디오 task에 적용하는 방법론들은 Action Recognition과 같은 비디오 단위 task에 적용되는 것이 대부분이었습니다. 하지만 Temporal Action Detection(Localization)과 같이 조금 더 dense한, 즉 frame-level로 비디오를 살펴봐야하는 task에는 적용되지 않고 있었는데, 이를 가능하게 한 방법론들이 22년도 ECCV에 최초로 몇 개 정도 게재되기 시작합니다. 본 논문이 그 중 한 가지에 해당합니다.
CLIP이 무엇이고 어떻게 이를 통해 zero-shot 기반 task가 수행 가능한지는 워낙 여러 번 이야기했으니 이번 리뷰에서는 넘어가도록 하겠습니다. 저자는 CLIP을 비디오에, 더욱이 dense한 비디오 task인 action localization에 가져다 붙이는 과정에서 극복해야 할 두 가지 문제가 있다고 합니다. 이는 저희가 현재 작업중인, CLIP을 활용한 action localization 방법론 논문에서도 동일하게 고민중인 포인트라, 저자가 문제를 어떻게 해결하였는지 보는 것이 유의미할 것 같네요. 저자가 언급하는 두 가지 문제점은 아래와 같습니다.
- CLIP은 image-text 기반 사전학습이기에 temporal 정보 없음
- TAL에서 중요한 ‘background’ 클래스를 명시적으로 모델링하기 어려움
각각의 문제를 해결하며 CLIP의 knowledge를 가져오기 위해 저자가 어떠한 방식을 사용하는지 알아보기 전, 전체 파이프라인 구조에 대해 설명하기 위해 기존 방법론들의 문제점을 먼저 알아보겠습니다. 기존에 CLIP을 활용하여 action localizaiton을 수행하는 논문은 2-stage로 구성되어있었습니다. 첫 번째 stage에서는 비디오만을 활용해 proposal을 생성(BMN 등 활용)하고, 이를 바탕으로 두 번째 stage에서는 CLIP feature와의 alignment를 수행해 localization을 진행합니다. 이렇게 되면 첫 번째 stage에서 생기는 error는 CLIP을 통해 개선될 수 없고 단지 CLIP은 앞에서 던져주는 proposal이 어떠한 퀄리티를 가지든 alignment만 수행하게 되는 것입니다. 저자는 이러한 error의 propagation을 방지하기 위해 one-stage 기반의 Zero-Shot Temporal Action Detection Model via Vision-Language Prompting(STALE)을 제안합니다.
다시 두 가지 문제점으로 돌아와 설명하겠습니다. 일반적으로 첫 번째 temporal modeling과 관련된 문제는 본 논문 뿐만 아니라 이후 다양한 논문들이 단순히 CLIP feature를 Transformer에 태워 해결합니다. 본 논문에서도 마찬가지로 Transformer를 통해 temporal modeling을 수행하고 있습니다. 저자는 error propagation을 중간에서 끊어주기 위해 classification과 localization module을 병렬적으로 구성합니다. 기존 방법론들과의 구조 차이는 아래 그림 1을 통해 알아볼 수 있습니다.
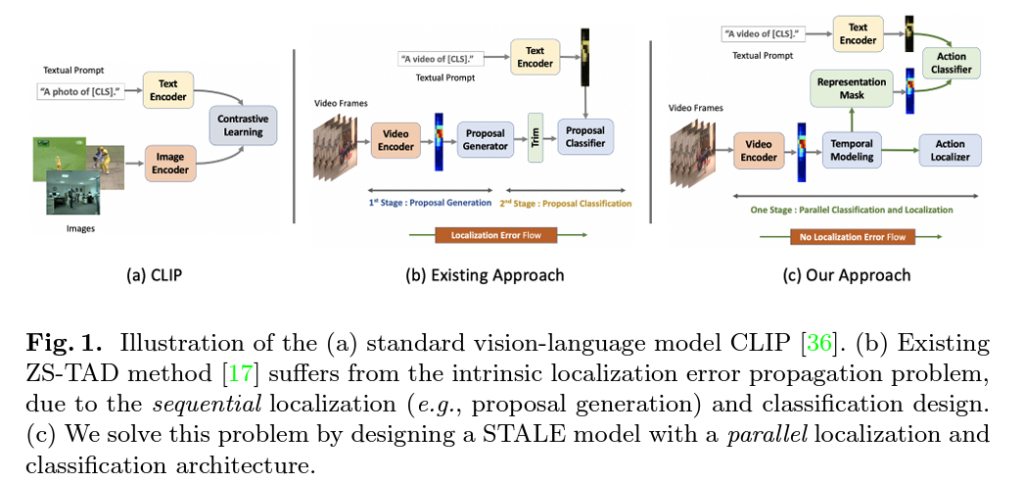
또한 localization을 수행하기 위해 background 모델링을 도울 수 있는 representation masking 개념을 활용하였으며 이외에도 다양한 contribution에 대해서는 방법론에서 자세히 알아보겠습니다.
2. Methodology
2.1 Language Guided Temporal Action Detection
저자가 제안하는 모델은 CLIP의 language priors를 더 잘 활용하기 위해 proposal-free 형태입니다.
Problem definition
데이터셋 D_{train}은 학습 데이터셋이고 N개의 \{V_{i}, \psi{}_{i}\} 쌍으로 구성됩니다. Fully-supervised이므로 학습 때 temporal annotation에까지 접근 가능합니다. 만약 train set과 성능을 평가할 val set이 동일하다면 closed-set, 둘 간의 교집합이 전혀 없다면 open-set이라고 볼 수 있겠죠.
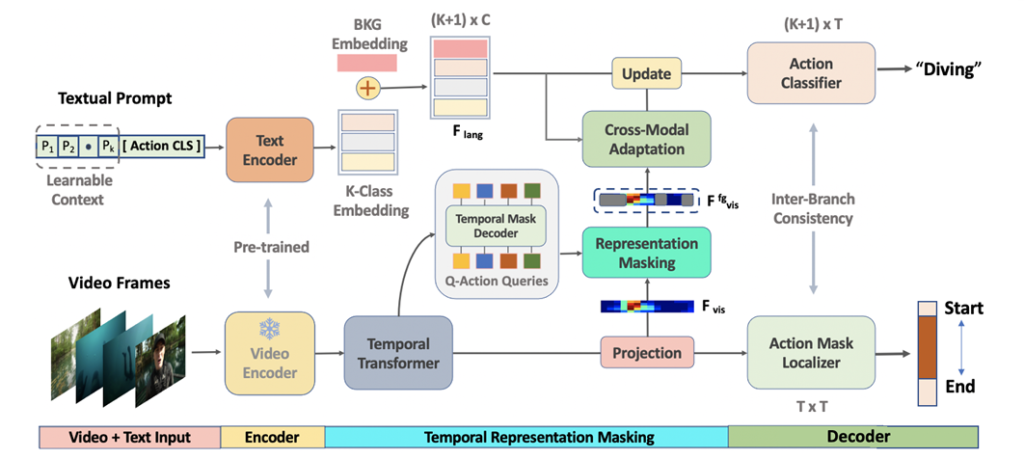
그림 2는 저자가 제안하는 모델 STALE의 전체 구조를 보여주고 있습니다.
Vision language embedding
Visual feature에 대해서는, I3D 모델을 활용해 RGB feature와 Optical flow feature를 추출합니다. 이후 둘을 concat하여 feature E \in{} \mathbb{R}^{2d \times{} T}를 만들어줍니다. 본 feature에 local한 spatio-temporal 정보가 담겨있다고 볼 수 있지만 Action detection을 수행하기 위해 필수적인 global 정보는 담겨있다고 보기 어렵습니다. 따라서 이를 모델링해주고자 Transformer의 self-attention 연산을 적용해 F_{vis}를 얻어줍니다.
- F_{vis} \in{} \mathbb{R}^{C \times{} T}
Textual feature는 CLIP의 사전학습된 text encoder를 활용합니다. 원래 CLIP의 방식과 동일하게 k번째 class name의 CLIP embedding인 G_{e}^{k} 앞에 learnable prompt G_{p}를 붙여 F_{lan}을 만들어줍니다.
- F_{lan} = [G_{p};G_{e}^{k}]
여기서 background는 “background”라는 text를 활용하여 임베딩하기엔 너무나 다양한 컨텐츠를 포함하고 있기에 단순히 learnable vector로 임베딩하여 모델이 알아서 학습하기를 기대하는 방식을 선택합니다.
Class agnostic representation masking
저자는 CLIP으로 ZSTAL을 수행하기 위해 class와 관계 없이 masking을 수행하고 이를 바탕으로 foreground 영역을 찾고자 하는 방식을 제안합니다. 앞서 추출한 F_{vis}와 총 N_{z}개의 mask query를 활용합니다. DETR과 같이 transformer decoder를 활용해 쿼리들에 대한 embedding N_{z}개를 얻게 됩니다. 이후에는 각각에 대해 projection을 수행해주어 mask embedding B_{q} \in{} \mathbb{R}^{q \times{} C}를 얻어줍니다. 여기서 q는 쿼리에 대한 인덱스를 의미합니다. 다음으로 각 쿼리에 대한 mask prediction을 얻기 위해 아래 수식 3과 같은 연산을 수행합니다.
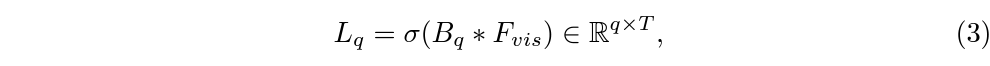
쿼리 임베딩에 기존 visual feature를 곱하고 이에 sigmoid를 태워 각 쿼리의 각 snippet에 대한 score를 얻어줄 수 있습니다. 각 snippet 별 적절한 foreground mask를 얻기 위해선 위치 별로 최적의 쿼리를 선택할 수 있도록 학습해야 합니다. 이는 아래 수식 4와 같이 수행됩니다.
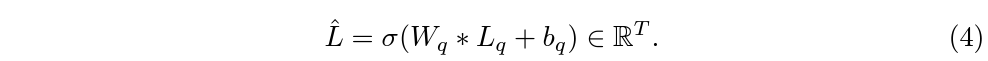
Learnable vector W_{q}를 활용해 snippet 별 0~1 score를 만들어주고, 이후엔 thresholding을 통해 \hat{L}_{bin}을 계산합니다. 이를 mask로 사용하고 기존 visual feature에 곱해 masking된 feature가 foreground에 대한 feature F_{vis}^{fg}인 것입니다. 이것이 결국 visual feature를 고려한 쿼리들의 foreground score라고 볼 수 있습니다. 왜 foreground score인지는 뒤에서 masking된 feature를 foreground로 활용하고 해당 방향으로 학습하기 때문입니다.
처음엔 이게 무슨 모델링인가 싶어 이해하기 어려웠는데, Fully-supervised이기 때문에 어떻게 모델링하든 뒷단에서 temnporal annotation으로 학습하면 되는 것이었습니다. 여러 mask를 활용해 학습 가능한 방식으로 foreground 구간을 찾아내는 방법론이라고 볼 수 있습니다.
Vision-language cross-modal adaption
CLIP의 기존 prompt와 동일하게 “a video of a man playing kickball”이라는 문장보다, “a video of a man playing kickball in a big park”와 같은 문장이 더욱 깊고 풍부한 표현력을 가진다는 것을 알 수 있습니다. 두 문장의 차이는 “in a big park”인데, 이러한 세부 사항은 visual feature로부터 얻을 수 있겠죠. 따라서 저자는 visual feature를 활용해 text prompt를 한번 더 enhance해주는 방식을 제안합니다.
이는 단순히 text-vis feature 간 cross attention을 통해 foreground feature 내에서 text feature와 연관된 부분을 따오고 residual 연산을 해주는 것으로 수행됩니다. 이는 아래 수식 (5), (6) 같습니다.
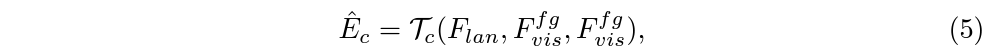
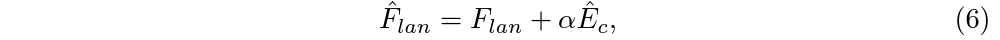
여기까지 수행하여 foreground visual feature와 enhanced text feature를 얻었습니다. 이제는 이 feature들을 통해 어떻게 classification과 localization이 수행되는지 보겠습니다.
(1) Contextualized vision-language classifier
분류는 visual feature F_{vis}^{fg}와 \hat{F}_{lan}의 내적으로 얻은 확률로 진행됩니다. 이는 아래 수식 (7)과 같습니다.
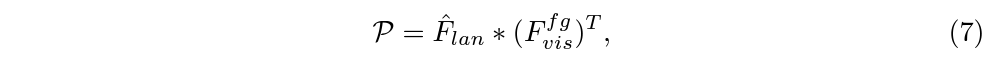
Shape은 \mathbb{R}^{(K+1) \times{} T}입니다. 이는 각 snippet이 각 클래스에 해당할 확률은 담은 matrix CAS라고도 볼 수 있겠죠.
(2) Action mask localizer
Foreground feature로부터 구간을 localize 하기 위한 본 모듈의 목적은 1차원 mask를 만들어내는 것입니다. 여기서 저자는 각 branch마다 독립적으로 타 unit과의 관계를 고려할 수 있는 dynamic convolution을 사용했다고 합니다. 총 T개의 snippet이 존재하고 각 snippet마다 모든 타 snippet과의 관계를 고려했으니 dynamic convolution 모듈 H_{m}을 거쳐 얻은 mask score는 \mathbb{R}^{T \times{} T}이 아래 수식 (8)과 같이 표현할 수 있습니다.
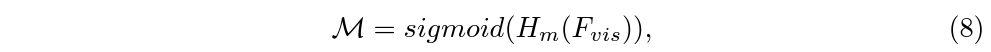
분류할 때는 foreground feature, localization을 수행할 때는 원본 visual feature를 사용하고 있는 모습입니다.
2.2 Model Training and Inference
분류를 위해 앞서 뽑은 CAS 형태의 \mathcal{P}에 대해 GT label로 CE Loss를 적용해줍니다. 해당 loss가 L_{c}입니다. Localization을 위해서는 수식 8에서 뽑은 mask와 GT를 활용해 학습합니다. 이는 아래 수식 (10)과 같습니다.
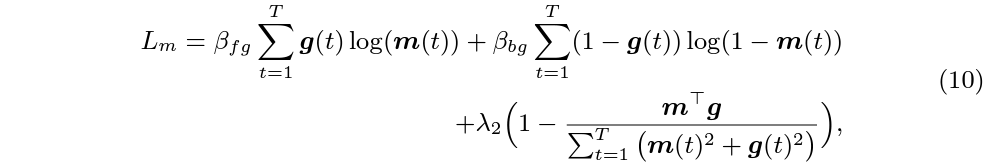
\beta{}는 전체 snippet 중 fg, bg에 해당하는 snippet 개수의 역수입니다. 해당 loss에 추가로 completeness loss L_{comp}를 함께 사용합니다. 이는 gt one-hot mask와 foreground masking output \hat{L} 간 BCE loss 입니다.
다음으로 STALE에서 제안하는 loss입니다. 분류와 localization branch 간 consistency를 위해 각 branch로부터 얻은 결과값 간의 코사인 유사도를 최대화해줍니다. 이는 아래 수식과 같습니다.

여기서 \hat{F}_{clf}는 CAS 형태의 분류 score로부터 얻은 매트릭스에 대해 thresholding 후 top-k개만 1로, 나머지는 0으로 binarization한 매트릭스입니다. 또 \hat{F}_{mask}는 localization branch에서 얻은 mask 값을 임베딩하고 thresholding하여 binarization한 1차원 matrix입니다.
STALE의 inference는 분류 branch에서 얻은 값을 통해 비디오에 존재하는 class를 뽑고, localization branch에서 얻은 snippet 별 score에서 해당 클래스에 대한 점수를 잘라 다양한 threshold를 기반으로 구간을 엮어냅니다.
이제 실험 결과를 보겠습니다.
3. Experiments
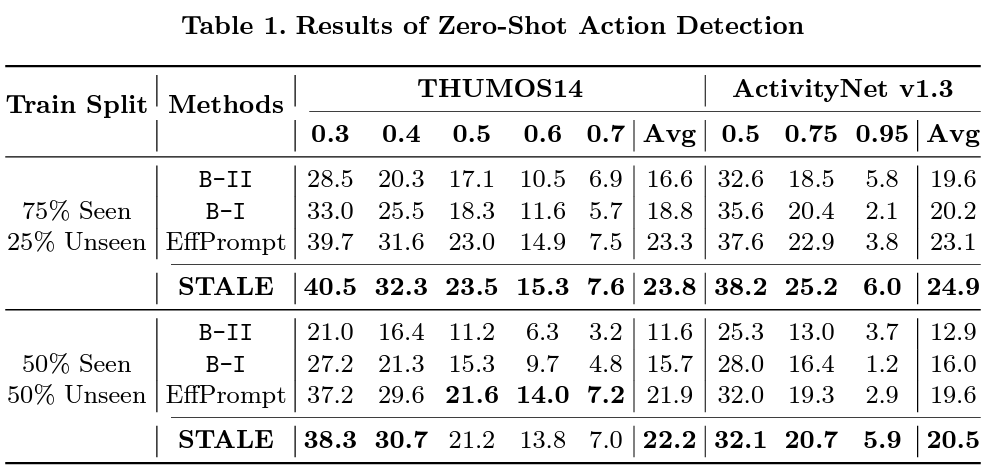
표 1은 Zero-shot 성능입니다. B-1은 BMN으로 proposal을 생성한 후 handcrafted prompt와 CLIP을 활용해 localization을 수행한 방식입니다. 다음으로 B-2는 one-stage이고 TAD 방법론에 CLIP을 붙이되 learnable prompt를 활용한, 즉 저자가 제안하는 STALE의 완전한 baseline 모델에 해당합니다. EffPrompt는 BMN+Learnable prompt로 2-stage 모델이며 동일하게 22년도 ECCV 논문입니다.
볼만한 점은 B-2가 B-1보다 성능이 낮은데, BMN에 의존하는 일반적인 2 stage 방식이 성능이 더 높다는 것입니다. 하지만 STALE은 더욱 높은 성능을 달성함으로써 BMN으로부터 전파될 수 있는 error를 효과적으로 제거했음을 알 수 있습니다.
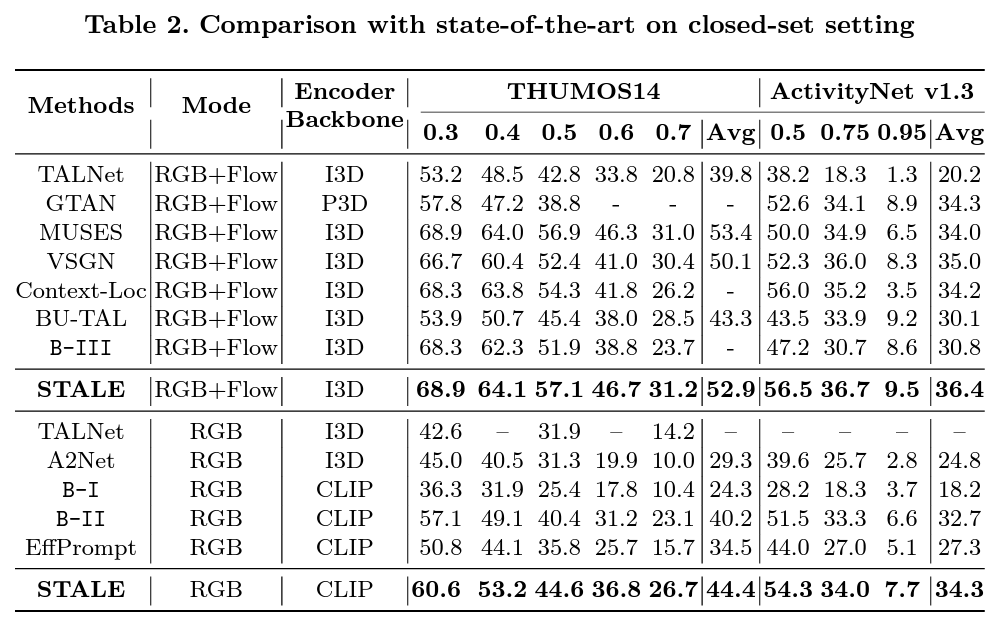
표 2는 Closed-set에서의 벤치마크입니다. Modal에 따라 표가 분리되어 있으며 B-3은 B-2의 visual encoder를 CLIP에서 I3D로 바꾸었을 때의 성능입니다. 앞선 zero-shot setting과 다르게 closed set인 경우 기존 방법론들과의 성능 차이가 더욱 커지며 STALE이 효과적인 방법론임을 입증하고 있습니다. 또한 backbone을 I3D에서 CLIP으로 변경하여도 기존 SOTA와의 성능 차이가 유지되는 것을 보았을 때, STALE이 feature agnostic하다는 점도 알 수 있습니다.
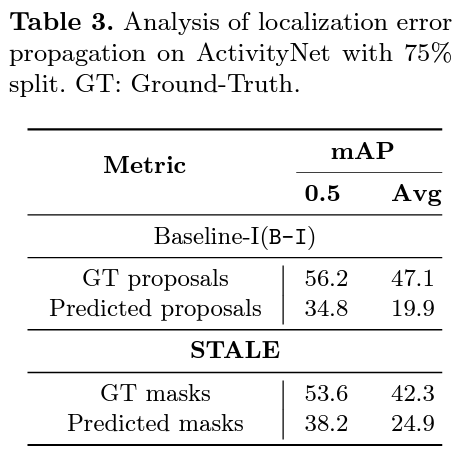
표 3은 2-stage 방법론들의 error propagation 정도 대비 STALE의 1-stage 방법론의 효과를 보여주기 위한 실험입니다. 2-stage 모델은 GT proposal을 처음에 주었을 때보다 BMN으로부터 얻은 proposal을 활용했을 때 성능이 2배 이상 하락하지만, STALE의 경우 1-stage로 학습되며 error propagation이 확실히 적은 모습을 보여주고 있습니다.
이외에도 다양한 ablation 실험과 모델에 따른 성능이 리포팅되어 있으니 궁금하신 분들은 질문 주시거나 논문을 참고하시면 좋을 것 같습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다.
Vision-language cross-modal adaptation에서 language feature를 visual feature로 강화해주는 부분이 인상깊었는데, 그 방식이 cross-attention인 것은 약간 naive하다는 생각이 드네요.. 재밌는 컨셉인 것 같습니다.
읽다보니 이 부분에서 약간 헷갈리는 부분이 있어 질문드립니다. 본 모델에서 classification을 visual feature와 enhanced language feature로 수행하는데, enhanced language feature가 classification 이전에 visual feature와 상호작용을 하기 때문에, visual feature의 정보가 language feature로 넘어가 무관한 클래스와의 유사도도 올라가버리지는 않을까요?
감사합니다.
물론 visual feature에는 실제 찾고자 하는 클래스의 정보가 포함되어있을 수도 있습니다. 하지만 특정 action이 발생하고 있는 비디오의 visual feature가 language feature와 결합되었을 때 다른 클래스의 action에 대한 정보를 주입해주는 것은 어려울 것으로 보이고, language feature에 대한 정답 클래스의 표현력을 강화해줄 것으로 이해했던 부분이었습니다.
두 모달리티 간 상호작용이 요구되는 task인 만큼 최대한 서로 간의 정보를 주입해주는 것이 잘 동작한 상황이라고 이해하시면 좋을 것 같습니다.