안녕하세요, 이번에는 이전에 리뷰한 CNOS로부터 확장되어 최종 6D pose까지 추정하는 올해 CVPR accept된 논문입니다.
Foundation model 기반으로 하는 이러한 연구 트렌드가 앞으로도 계속해서 이어지는지는 지켜보아야 할 것 같습니다. 방법론 자체의 컨셉은 이해하는 것이 어렵지 않으나, 디테일한 부분은 많이 어려웠던 논문이었습니다. 6D Pose Estimation 대회인 BOP challenge의 리더보드를 보니 2등이네요. 또 foundation model을 기반으로 하기 때문에 상당히 무거울 것이라고 생각했으나, 4초면 상당히 빠른 게 아닌가 싶은 생각도 듭니다.
리뷰 시작하겠습니다.
Introduction
Object Pose Estimation은 로봇 조작 및 증강 현실과 같은 많은 실제 어플리케이션 측면에서 보았을 때 기본이 되는 테스크입니다. 해당 기술은 딥러닝 모델의 등장으로 큰 영향을 받아 현재까지 발전하고 있는데요. 주로 많이 되고 있는 연구는 instance-level에서의 6D pose estimation으로, 이는 target object에 대한 annotation된 학습 이미지가 필요로 합니다. 하지만 최근에는 unseen object를 다루기 위해 category-level 6D pose estimation의 연구가 활발히 진행되고 있습니다. 이번에는 학습 중에 다루지 않은 새로운 물체의 모든 instance를 검출하고 최종적으로 6D pose를 예측하는 SAM-6D에 대해 살펴보도록 하겠습니다.
Methodology of SAM-6D
이번 SAM-6D에서는 Zero-shot으로 6D pose estimation 문제를 풀어나가고자 합니다. 이름에서도 직관적으로 알 수 있듯이, Foundation 모델인 SAM(Segment Anything Model)을 사용하여 unseen object에 대한 모든 인스턴스를 RGB-D 이미지의 입력을 통해 detection + 6D pose estimation까지 수행하는 것을 목표로 합니다. 이전에 리뷰를 했었던 CNOS에서는 segmentation 까지 수행하는 detector의 역할만을 했었다면, 이번에는 더 나아가 6D pose estimation까지 수행합니다.
1. Instance Segmentation Model(ISM)
SAM-6D에서는 해당 섹션의 제목과 같이 ISM을 사용하여 novel object \mathcal O에 대한 segmentation을 수행합니다. RGB 이미지 \mathcal I가 주어졌을 때, ISM에서는 SAM에서 사용되는 zero-shot이 적용되어 이미지 내의 가능한 영역에 대한 모든 proposal \mathcal M을 생성합니다. 각 proposal m는 semantic, appearance, geometry 측면에서 m과 \mathcal O의 일치 정도를 평가하기 위해 matching score s_{m}을 계산하고 나온 값에 대해 설정된 threshold \delta_{m}에 대해 \mathcal O와 최종적으로 일치하는 인스턴스를 얻을 수 있습니다.
Preliminaries of Segment Anything Model
SAM에 대한 간단하게 설명을 해보면, RGB 이미지 \mathcal I이 주어졌을 때, Bounding box, text, mask와 같은 다양한 유형의 프롬프트 \mathcal P_{r}로부터 논문에서는 promptable segmentation을 할 수 있다라고 표현을 하네요. SAM은 3가지의 구성 요소로 되어있는데요. image encoder \Phi_{\scriptstyle\text{Image}}, prompt encoder \Phi_{\scriptstyle\text{Prompt}}, mask decoder \Psi_{\scriptstyle\text{Mask}}로 되어있습니다.
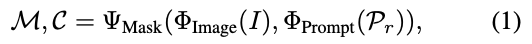
식으로 나타내면, 식(1)과 같이 나타낼 수 있습니다. 입력(이미지, 프롬프트)로부터 Mask를 생성하여 저희는 예측된 proposals \mathcal M, confidence scores \mathcal C를 얻을 수 있겠네요.
Object Matching Score
SAM을 통해 얻은 proposals \mathcal M이 주어지면 다음 스텝은 matching score s_{m}를 측정하는 과정입니다. 세 가지(Semantic, Apperance, Geometry) 측면에서 각각 일치 하는 항목을 평가합니다. 이를 통해 특정 물체 \mathcal O와 일치하는 항목을 찾을 수 있습니다. 선행연구로 진행된 CNOS와 동일하게 물체에 대한 pose를 샘플링 N_{\mathcal {T}} 합니다. 샘플링 된 pose에 대해 template을 렌더링 \{{\mathcal T_k}\}^{N_{\mathcal T}}_{k=1}(샘플링 된 pose만큼 template 생성)합니다. 이를 DINOv2의 사전학습 된 ViT backbone 모델에 태우기 위해 template \mathcal T_{k}의 class embedding \mathcal f^{cls}_{\mathcal T_{k}} 및 N^{patch}_{\mathcal T_{k}}에 대한 patch embedding \{\mathcal f^{patch}_{\mathcal T_{k}, i}\}^{N^{patch}_{\mathcal T_{k}}}_{i=1}(물체 영역에 대한 patch)을 생성합니다. 각 proposal m에 대해서 입력 이미지로부터 detection된 영역을 crop하고 해상도를 고정하여 사용합니다. notation을 참고하셔야 다음 각각의 matching score에 대한 식들도 이해할 수 있을 것이라고 생각합니다.
Semantic Matching Score
\{\frac {<\mathcal f^{cls}_{\mathcal I_m}, \mathcal f^{cls}_{\mathcal T_{k}}>} {|\mathcal f^{cls}_{\mathcal I_{m}}| \cdot |f^{cls}{\mathcal T_{k}}|} \}^{N_{\mathcal T}}_{k=1}
class embedding을 통해 semantic score s_{sem}를 측정하는데요.
위 식을 통해 얻은 Top K의 값에 대해 평균을 취해 robust한 semantic matching을 이룰 수 있다고 합니다. 식을 살펴보면, template과 proposal 마스크 간의 값을 계산하는 것을 볼 수 있습니다. 분자쪽은 내적을 계산하고, 분자쪽은 norm으로 얻은 스칼라 값을 곱하는 것을 볼 수 있네요. 이렇게 모든 proposals 만큼 구한 후 average를 취하여 Top K를 뽑습니다. 이를 저자는 이미지 내의 가장 semantic한 값으로 하네요. 이는 다시 말하면 가장 잘 mathcing 된 tamplate으로 볼 수 있겠네요. 이처럼 가장 잘 얻은 template을 \mathcal T_{best}로 나타냅니다. 참고로 \mathcal I_{m}은 crop된 proposal mask을 의미합니다.
Appearance Matching Score
sematic matching을 통해 얻은 \mathcal T_{best}이 주어지면, patch embedding을 기반으로 appearance score s_{appe}을 측정합니다.
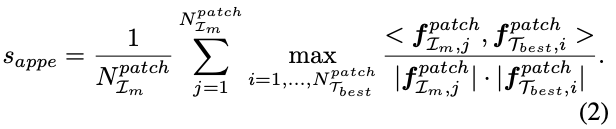
위 식(2)와 같이 \mathcal I_{m}과 T_{best}를 외관 측면에서 비교를 진행합니다. 이미지 내의 patch들에 대한 값을 모두 계산하여 최댓값을 취한 후, 모두 더하는 연산을 통해 semantic적으로는 유사하지만, 외관이 다른 물체를 구별합니다.
Geometric Matching Score
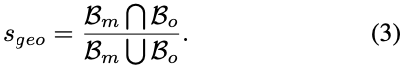
마지막으로 Geometry 측면에서는 어떻게 측정하는지 알아보겠습니다.
이는 물체의 shape, size와 같은 요소를 고려하여 proposal m에 대한 점수를 측정하게 되는데요. 여기서도 앞서 구한 best template \mathcal T_{best}을 사용합니다. 이때는 rotation, translation으로부터 projection 시켜 식(3)과 같이 2D bbox로부터 IoU를 계산하여 s_{geo}를 측정하였다고 합니다.
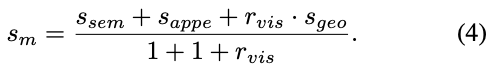
이로써, 최종적으로 mathcing score를 식(4)와 같이 계산하여 도출하게 됩니다. 이때 r_{vis}는 s_{geo}에서 구하는 IoU를 구할 때 occlusion을 방지하기 위한 visible ratio를 의미합니다.
2. Pose Estimation Model(PEM)
다음으로 pose estimation model(PEM)입니다. 이를 통해 물체 \mathcal O와 일치하는 proposal로부터 6D pose를 예측합니다. 각 물체에 대한 proposal m에 대해 PEM은 point registation strategy를 통해 \mathcal O에 대한 6D pose를 예측하는데요.
Feature Extraction
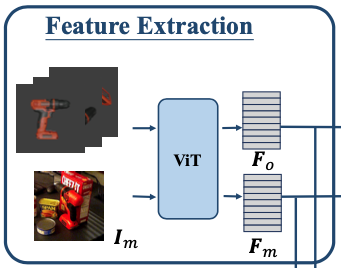
특징 추출 모듈은 proposal m과 주어진 물체 \mathcal O에 대한 포인트 클라우드인 \mathcal P_{m}, \mathcal P_{o}을 추출하는 데에 사용하게 되는데요. backbone으로 사용되는 ViT를 통해 F_{m}을 구할 수 있으며 물체 \mathcal O를 여러 카메라 뷰포인트에 대해서 렌더링된 template으로 구성하고 샘플링하여 \mathcal P_{o}를 생성합니다. 여기서도 동일하게 ViT를 태워 F_o을 형성합니다.
Coarse Point Matching
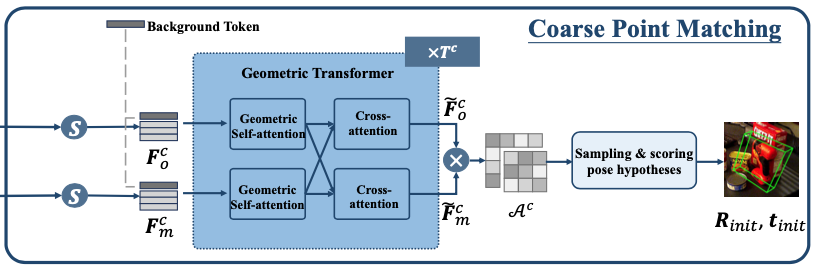
이번 모듈에서의 최종 목적은 coarse한 pose로 initialize하는 것을 목표로 합니다.
위 그림과 같이, 샘플링 된 두 개의 포인트 클라우드(F^{C}{o}, F^{C}{m} – C : coarse)로부터 learnable background token과 같이 각각에 대해 concat하고 이를 Geometric Transformer가 수행하게 되는데요. Geometric Transformer에서는 intra-point-set에 대한 feature learning을 위한 Geometric self-attention과 intra-point-set에 대한 correspondence modeling을 위해 Cross attention을 수행합니다. 이렇게 수행된 feature \tilde F^{C}{o}, \tilde F^{C}{m}에 대해 softmax 를 취하여 \mathcal A^c을 얻고, 확률 값을 가지는 행렬(attention matrix)을 만듭니다. 이를 통해, \mathcal P^{c}{m}와 \mathcal P^{c}{o} 간의 겹치는 점 사이의 일치 확률을 구할 수 있으며, 이는 point pair을 샘플링 하고 pose hypothesis를 계산하기 위한 분포로 사용할 수 있다고 합니다[이승현 연구원님이 리뷰한 SurfEmb – 3. From Embeddings to Pose 참고].
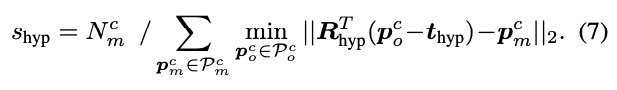
각 pose hypothesis R_{\scriptstyle\text{hyp}},t_{\scriptstyle\text{hyp}}(rotation, translation)에 대한 pose mathcing score s_{\scriptstyle\text{hyp}}을 식(7)과 같이 할당하여 matching score가 가장 높은 pose를 init pose로 선택하여 다음 Fine Point Matching 모듈에 전달합니다.
(참고) 여기서 적용되는 learnable background token은 두 포인트 클라우드 집합에서 겹치지 않는 점에 대해서는 할당하지 않도록하고 최종적으로 attention 행렬을 만들기 위해 partial-to-partial correspondence을 효과적으로 구축하도록 유도합니다.
Fine Point Matching
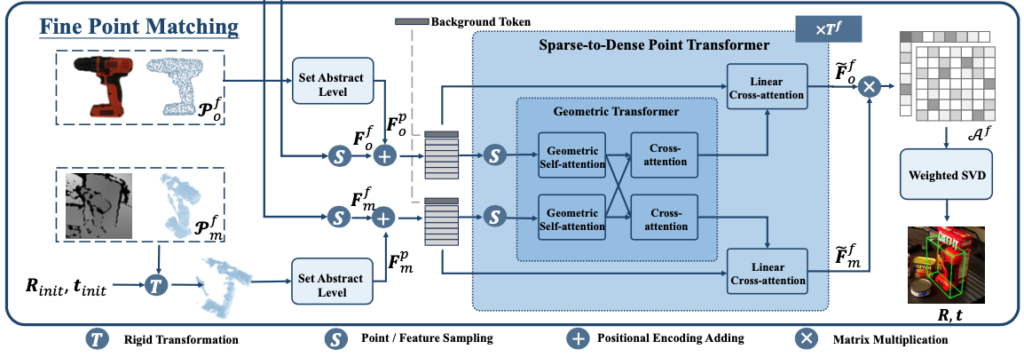
방법론의 마지막 과정입니다. 이번 모듈에서는 이름 그대로 coarse pose를 refinement하는 과정입니다. 핵심은 Dense한 correspondence를 생성하여 좀 더 정확한 pose를 추정하는 것입니다.
앞서 구한 coarse point matching 보다 좀 더 dense한 correspondence를 생성하기 위해서 앞서 feature extractor를 통한 결과 (F^{f}{o}, F^{f}{m} – f : fine)를 샘플링하여 사용하는 것까지는 동일하나, 여기서 Set Abstract 과정이 추가된 것을 확인할 수 있습니다. 해당 과정은 3D 모델에 대해 PointNet++ 모델을 사용하여 얻은 feature와 같이 Positional Encoding을 통하여 F^{p}{o}을 얻으며, 깊이 영상으로부터 물체에 대한 포인트 클라우드를 얻어 해당 포인트 클라우드에 init pose를 적용하여 얻은 포인트 클라우드로부터 feature extractor를 통해 얻은 결과를 positional encoding 한 F^{p}{m}결과를 사용합니다. 여기서도 동일하게 Background token이 들어가게 되는데요. 이렇게 dense한 feature를 사용하게 되면 transformer 연산은 계산면에서 상당한 cost가 발생하게 되는데요. 이러한 문제를 해결하기 위해 Sparse-to-Dense Point Transformer(SDPT)를 적용합니다. 부가적인 설명을 하자면, dense한 feature가 주어진 현재 상황에서 SDPT는 sparse하게 sampling을 하고 Geometry Transformer를 적용하여 상호 작용을 향상시키는 효과를 준 결과에 Linear Cross-attention을 적용하여 key, value에서 query로 정보를 확산시켜 주게 됩니다. 이러한 과정을 통해 Dense correspondence를 모델링한 이전과 동일한 과정을 통해 attention 행렬 \mathcal A^{f}를 얻어 weighted SVD를 통해 최종적인 R, t를 얻습니다.
(참고) Weighted SVD는 기존의 SVD를 A=U\Sigma V^{T}라고 할 때, 가중치 행렬을 W라고 할 때, 추가적으로 가중치를 고려하는 것이며, 기존 A의 주대각 원소에 대한 가중치를 고려하여 A'=W \circ A로 했을 때, A'=U'\Sigma' (V')^{T}로 나타낼 수 있습니다.
Experiments
Datasets
BOP challenge에서 core dataset으로 사용되고 있는 LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB, YCB-V에서 평가를 진행합니다.
PEM(Pose Estimation Model)은 MegaPose와 동일하게 SO(ShapeNet-Objects), GSO(Google-Scanned-Objects)로 학습되었습니다.
Instance Segmentation of Novel Objects
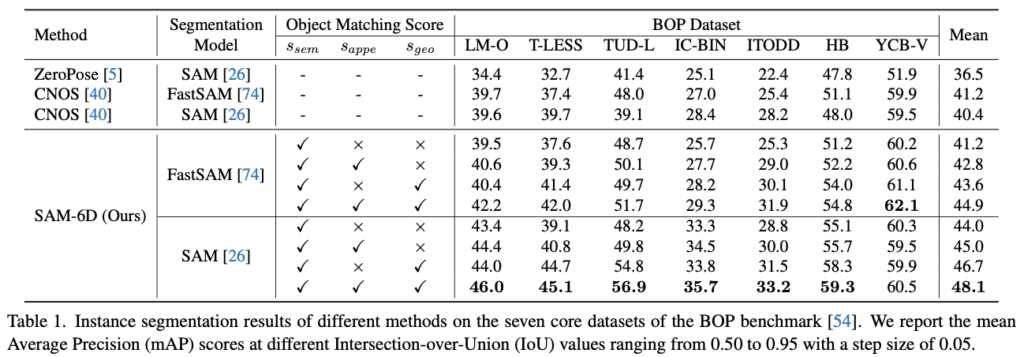
Novel object에 대한 segmentation과 같이 semantic한 측면에서의 proposal에 대한 점수를 측정하는 ZeroPose, CNOS와 이번 SAM-6D에서의 ISM(Instance Segmentation Model)을 비교합니다. 표(1)에 나와있듯이, FastSAM/SAM을 사용하여 특별한 재학습이나 fine-tune 과정 없이도 성능이 좀 더 좋은 것을 정량적 결과를 통해 입증합니다.

ISM의 정성적 결과는 그림(1)의 (d)에 나와 있습니다. semantic matching score를 측정하는 방법은 CNOS에서 한 방법과 완전히 동일한 결과를 사용하지만, 좀 더 다양한 mathcing score를 제공함으로써 성능을 향상시킬 수 있었던 것입니다.
Pose Estimation of Novel Objects
Comparisons with Existing Methods
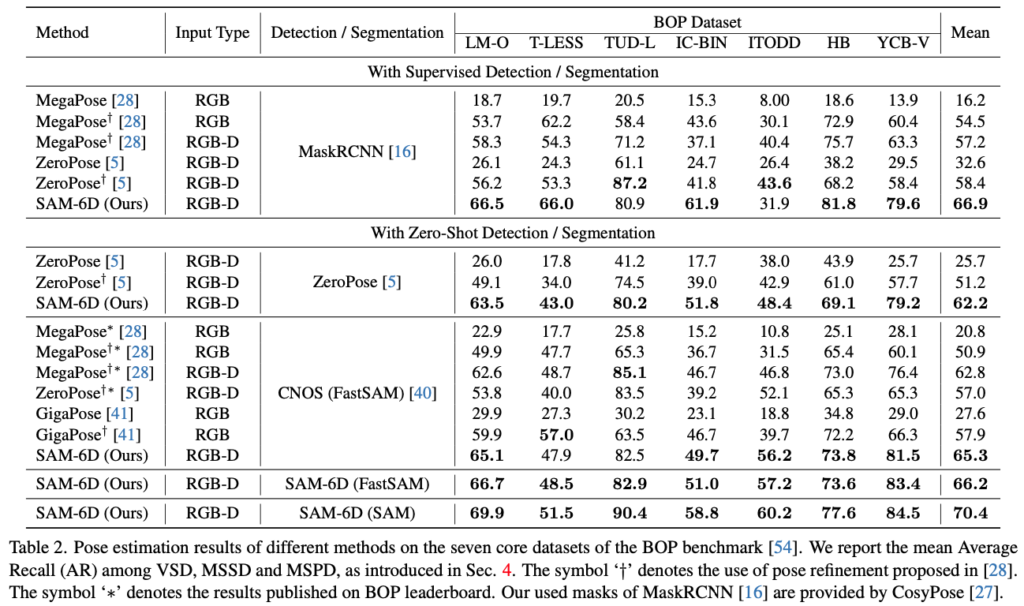
이번에는 Novel object에 대한 pose estimation을 수행하는 지금까지 현존하는 방법론들과 SAM-6D의 PEM을 비교합니다. 표(2)의 정량적 결과를 보았을 때, 시간적인 cost가 많이 드는 rendering-based의 refiner를 수행하는 MegaPose보다 PEM에서 다양한 mask 예측을 통해 얻은 결과가 더 좋은 결과를 낸 것을 확인할 수 있습니다. ISM의 결과로 나온 적절한 mask 예측이 다른 방법론의 mask 예측 결과보다 PEM의 최종 성능을 향상시켰으므로 ISM의 장점을 좀 더 잘 보였다고도 볼 수 있겠네요. PEM의 정성적 결과는 그림(1)의 (e)에서 확인할 수 있습니다.
Ablation Studies and Analysis
Efficacy of Background Tokens
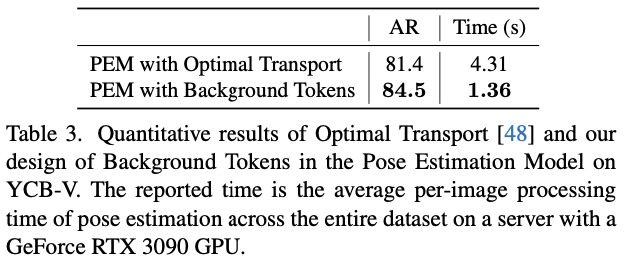
저자는 간단한 설계를 통해 partial-to-partial point mathcing 문제를 해결했었는데요. 해당 방법 말고도 Optimal Transport라는 최적화 방법도 있었지만 결과를 보았을 때, 정확도/속도 측면에서 간단하지만 더 효율적인 결과를 얻었다고 합니다.
Efficacy of Two Point Matching Stages

앞서 사용한 Background token을 사용하여 coarse matching 모듈을 거쳐 fine matching module까지 최종적으로 2-stage로 PEM은 동작하는데요. 표(4)와 같이 coarse 모듈에서 나온 결과를 통해 fine module이 개선함으로써 보완해주는 효과를 입증합니다.
Efficacy of Sparse-to-Dense Point Transformers

Dense한 point간의 상호 작용을 다루기 위해서 fine matching 모듈에서는 SDPT(Sparse-to-Dense Point Transformer)를 설계했었습니다. 196개의 포인트로 구성된 Sparse한 포인트 클라우드를 사용하는 Geometric Transformer(GT)와 2048개의 포인트로 구성된 Dense한 포인트 클라우드를 사용하는 Linear Transformer(LT)에 대한 실험입니다. 정량적 결과를 보았을 때, GT만을 사용하는 것은 큰 계산 cost가 발생함에 따라 dense한 포인트 클라우드를 처리하는 데 어려움을 겪는 반면, LT만을 사용하는 것은 특징 차원을 따라 cross-attention과의 dense한 correspondence를 생성하는 데에 오히려 비효율적인 것을 정량적 결과를 통해 알 수 있습니다.
Runtime Analysis

해당 실험은 RTX 3090에서 평가를 수행했으며 표(6)은 앞서 언급한 core dataset에 대해 평균을 취한 결과를 보여주고 있습니다. 단위는 초입니다.
Conclusion
이번에는 Zero-shot 6D pose estimationd을 위해 ISM과 PEM으로 구성된 SAM-6D라는 새로운 프레임워크를 제안하였습니다. ISM에서는 SAM을 사용하여 여러 가지 matching score을 적용하여 best template을 찾는 과정이며, PEM에서는 best template으로부터 최적의 pose를 찾기 위해 coarse matching과 fine matching으로 2-stage 과정을 통해 최종 pose를 추정합니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
appearance matching 과정에서 패치중 가장 유사도가 높은 패치들을 더하는 연산을 통해 외관이 다른 물체를 구별한다고 하셨는데, 식 (2)를 보면 feature의 최대 유사도를 측정하는 것으로 보입니다. 혹시 픽셀값이 아닌 feature의 최대값들을 더하는 이유나 픽셀값을 이용한 실험이 있는지 궁금합니다.
또한, semantic, appearance, geometric loss에 대한 ablation 실험 결과에 대한 분석이 궁금합니다. 조금 더 구체적으로는 Table 1에 ablation 실험이 있는데, appearance에 대한 loss나 geometric loss는 하나씩 적용 될 때는 성능 개선 폭이 적은데, 두 loss를 함께 적용할 경우 성능이 유의미한 정도로 개선되는 것으로 보여 이에 대한 저자들의 분석이 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 식(2)에서 사용되는 식은 제가 이해한 바로는 DINOv2 모델에서 사용되는 backbone인 ViT에 입력으로 태우기 위해 Patch embedding으로 들어가는 부분이라 pixel이 아닌 feature를 patch단위로 분할하여 사용하기 때문이라고 생각합니다. 따라서 추가적으로 pixel 값을 이용하거나 하는 추가적인 실험은 없었습니다.
2. 먼저, loss가 아닌 matching score를 구하는 것으로 외관정보와 기하학적 정보를 각각 사용함에 있어서도 성능의 오름이 보였고, 둘 다 같이 고려를 하여 베이스라인으로 잡았던 s_sem보다 우수한 성능을 보였다고 분석을 끝내었습니다. 제가 고찰한 바로는 기존의 의미론적인 정보만을 보는 게 아니라, 좀 더 구체적으로 외관정보, 기하학적 정보를 동시에 고려하는 게 매칭에 조금 더 유의미한 정보를 전달한 것으로 생각합니다. 하지만, 식(2)과 같이 단순히 패치와의 최댓값을 취하여 appearance가 가장 유사하다고 하는 것은 조금 의문이 들고 조금 더 추가적인 고려 사항이 있어야 되지 않나라는 생각이 드네요.
감사합니다.