안녕하세요. 제가 이번에 리뷰할 논문은 CVPR 2024에 accept된 6D Pose Estimation 논문입니다. CVPR 2024논문 리스트를 보니 이번에는 6D 관련 논문들이 작년에 비해 증가하였고, 대부분 Novel object, Unseen object, Diffusion 등의 키워드를 함께 가지고 있는 것으로 보입니다. 아무래도 6D에서도 점차 real application을 위한 연구로 나아가는 것으로 보입니다. 그중에서도 제가 리뷰할 논문은 Unseen object에 대한 연구입니다. 본격적으로 논문에 대한 리뷰를 하기에 앞서, 해당 논문에서는 Unseen을 학습하지 않은 객체로, inference 과정에선 CAD 모델을 이용할 수 있다는 전제가 있습니다. (6D에서는 pose를 구하기 위해서 기준이 필요하므로 3D 모델이 있다는 가정이 있거나, reference 이미지와 비교하여 상대적인 pose를 구하는 식으로 Unseen에 대한 문제를 해결하고자 합니다.)
Abstract
최근 학습 기반의 6D pose Estimation은 각 인스턴스나 카테고리에 대해 개별적으로 학습을 요구하므로 학습한 적 없는 객체에 대하여 대응 하지 못하여 real application에 적용하기에 어려움이 있습니다. 본 논문에서는 RGB-D를 이용하여 MatchU라는 Fuse-Describe-Match 방식을 제안합니다. MatchU는 2D texture와 3D 기하학 단서를 융합하여 학습한 적 없는 Unseen 객체에 대하여 Pose를 추정하는 방법론 입니다. 저자들은 rotation-invariant한 기하학적 3D descriptor를 설계하여 pose에 구애받지 않는 기하학적 특성을 인코딩함으로써 Unseen object를 일반화하고 대칭 정보를 포착하는 descriptor를 학습할 수 있다고 합니다. 여기에 기하학적으로 유사한 부분에 대한 모호성을 해결하기 위해 RGB정보를 descriptor에 추가하였다고 합니다. 다양한 실험을 통해 RGB-D를 융합하는 방식의 일반화 가능성과 descriptor의 효율성도 보였다고 합니다.
Introduction
6D Pose Estimation 연구는 물체 조작이나 증강 현실 등에 활용 가능하지만, 학습하지 않은 객체에 대한 pose 정보를 추정하기는 어렵다는 점에서 한계가 있습니다. 기존 연구 중, Desnefusion**은 데이터 셋에 포함된 다중 객체의 pose를 구할 수 있으나, 학습하지 않은 새로운 instance에는 동작하지 않으며, 카테고리 레벨의 방식들도 학습을 한 카테고리 내의 Unseen 객체에서만 작동한다는 한계가 있습니다. 이러한 방법론은 각 인스턴스나 카테고리, 데이터 셋의 특정 분포에 과적합되도록 설계되어있어서 실제 활용 관점으로 적용하기에는 여러움이 있습니다.
**Wang, Chen, et al. “Densefusion: 6d object pose estimation by iterative dense fusion.” CVPR 2019.
일부의 one-shot 방식은 템플릿 매칭 방식으로 객체의 3D 모델을 정렬하거나 SfM 방식을 통해 Unseen객체의 구조를 파악하고자 합지만, 이러한 방식은 객체에 특화된 전처리 과정이 필요하다는 한계가 있습니다. 또한 Unseen객체의 pose를 추정하기 위해 handcrafted feature와 CAD 모델간의 대응을 구하는 전통적인 방식은 많은 pose hypotheses를 구하고 반복적인 refinement 과정을 거쳐야하므로 연산량이 과도하게 높아집니다.
최근 연구들은 pose hypotheses를 평가하고 refinement하는 학습 모델을 통해 일반적인 pose 추정을 위한 연구를 수행하였으나, 이를 위해서는 시간이 많이 소요되는 render-and-compare 과정(3D 모델을 추정한 pose만큼 변화시킨 뒤 비교하고 refinement를 수행하는 과정을 반복하는 것으로 이해하시면 됩니다.)이 포함됩니다. 또 다른 접근법은 6D Pose Estimation 방식을 point cloud registration task(두 point cloud 세트가 주어졌을 때 공통 좌표계에서 정렬하기 위한 변환 관계를 찾는 task)로 정의하여 문제를 해결하고자 하며, 이러한 방식은 point cloud의 기하학적 특성을 활용한다는 이점이 있으나, RGB 이미지의 texture 정보를 무시한다는 문제가 있습니다. 따라서 해당 방법론을 통해 구해진 descriptor는 RGB의 texture 정보를 포함하지 못하여 덜 discriminative하며, 학습 과정에 객체의 대칭 정보와 같은 사전 정보를 제공해야 한다는 한계가 있습니다.
해당 논문은 MatchU라는 Unseen 객체에 대한 Pose Estimation 방법론을 제안하며, rotation-invariant한 descriptor를 설계함으로써, 대칭 정보를 주지 않아도 이를 네트워크가 포착하고 모델링하여 Unseen 객체에 대한 일반화가 용이하도록 하였다고 합니다. 그러나 rotation-invariant한 descriptor는 기하학적으로 유사한 부분에 대해서는 모호성이 존재한다는 문제가 있어 해당 논문에서는 texture와 기하학적 정보를 효과적으로 융합하기 위해 Latent Fusion Attention Module이라는 새로운 2D-3D fusion 모듈을 제안하였습니다. 이를 통해 외관 정보와 형태 정보를 상호보완적이고 일반적인 방식으로 표현하는 descriptor를 추출하였다고 합니다. 게다가 기하학적 descriptor의 표현력을 강화하기 위해 RGB 정보를 활용하는 새로운 Bridged Coarse-level Matching loss를 제안하여 두 특징간의 연관성을 강화하여 CAD 모델과 Unseen 객체의 RGB-D 이미지 사이의 보다 정확한 매칭이 가능하도록 하였다고 합니다.
해당 논문의 contribution을 정리하면
- unseen 3D CAD 모델과 이미지 사이의 매칭을 위해 RGB-D 입력으로부터 융합된 특징을 추출하는 MatchU라는 fuse-describe-match 방식의 6D Pose estimation 방식을 제안
- texture 정보와 기하학적 특징을 효과적으로 융합하기 위한 새로운 Latent Fusion Attention 모듈과 MatchU 학습을 위한 Bridged Coarse-level Matching Loss 제안
- 융합된 feature representation을 학습하므로써 MatchU는 사전 정보를 주지 않아도 대칭 정보를 포착하여 pose의 모호성이 줄어듦
Method
1. Problem Formulation
Unseen Object Pose Estimation은 학습 과정에 보지 못한 CAD모델과 RGB/Depth 이미지의 일부분 사이의 6D Pose를 추정하는 것을 목표로 하며, 본 논문에서는 RGB-D 데이터와 CAD 모델 사이의 학습된 descriptor를 매칭하여 Unseen 객체에 대한 pose를 추정합니다. Unseen객체의 CAD 모델의 point cloud를 P= \{ p_i ∈\mathbb{R}^3 |1 ≤ i ≤ n \}, depth 데이터에 표현되 객체의 일부분으로부터 구한 point cloud를 Q= \{ q_i ∈\mathbb{R}^3 |1 ≤ j ≤ m \}, 객체 영역에 대하여 crop된 RGB 이미지를 K라 할 때, 아래의 식(1)을 최적화하여 대응되는 두 point p_i ↔ q_i를 correspondence point 집합 \mathcal{C}에 추가하여 6D Pose를 추정합니다.
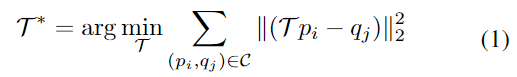
이때, \mathcal{T}∈SE(3)는 새로운 객체의 6D Pose를 나타냅니다.
2. Method Overview
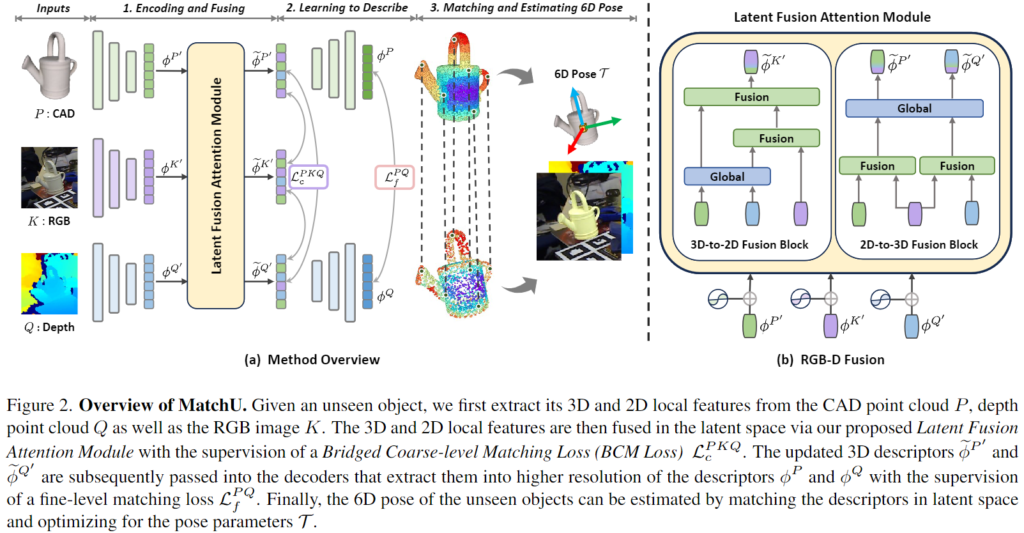
CAD와 Depth로부터 각각 descriptor \phi^P와 \phi^Q를 추출한 뒤, 두 descriptor의 유사도를 계산하여 대응 집합 \mathcal{C}= \{ (p_i,q_i)| \phi^P_i↔ \phi^Q_j \}를 구합니다.( \phi^P_i↔ \phi^Q_j 는 매칭된 두 point를 의미합니다) 이후 이상치에 강인하도록 RANSAC을 활용한 least square 방식으로 식 (1)을 최적화하여 pose를 추정합니다.
본 논문에서 제안한 매핑 함수 \psi는 CAD와 Depth의 대응되는 point cloud를 매칭시키며 각 descriptor는 cross-modality 정보를 융합합니다. ( \phi^P=\psi(P|(Q,K)) ∈\mathbb{R}^{n⨉d}, \phi^Q=\psi(Q|(P,K)) ∈\mathbb{R}^{m⨉d}) 두 point간의 매칭을 통해 최종적으로 Unseen 객체의 pose 정보를 추정하게 되며, 이에 대한 전체적인 프레임워크는 위의 [Figure 2]를 통해 확인하실 수 있습니다.
2. Encoding and Fusion Descriptors
cross-modality descriptor를 융합하기 위해 3D와 2D local feature를 추출합니다.
Local 3D Feature Extraction
저자들은 rotation-invariant한 3D local feature를 추출하기 위해 최신 연구인 transformer기반의 구조인 RoITr** 구조를 이용하였다고 합니다.(RoITr은 transformer기반의 descriptor를 고안한 방법론으로, point cloud에 대하여 superpoint를 구한 뒤, 각 superpoint로부터 기하학적 특징을 추출하고 각 특징들을 집계하여 global한 feature를 구함으로서 rotation-invariant한 descriptor를 구할 수 있도록 한 논문입니다)CAD 모델과 Depth 이미지의 point cloud로부터 추출한 descriptor의 rotation-invariant한 특성은 기하학적 단서에 대하여 강인한 특징을 제공하며 Unseen 객체에 대한 일반화 가능성을 보장할 수 있다고 합니다. P와 Q가 주어졌을 때, 인코더는 FPS(Farthest Point Sampling)를 통해 P' = \{ p'_i ∈\mathbb{R}^3 | 1≤i ≤n' \} 와 Q' = \{ q'_j ∈\mathbb{R}^3 | 1≤j ≤m' \}로 다운샘플링하여 superpoints를 구한 뒤, RoITr의 방식을 따라 각 superpoint에 대해 반경 r 이내의 이웃한 point로부터 local한 기하학적 특징을 추출합니다. 추출한 특징은 연속적인 attention blocks를 통과하여 latent space에 투영되며, 이를 통해 rotation-invariant한 local 3D 기하학적 descriptor \phi_{p'_i}∈\mathbb{R}^d와 \phi_{q'_j}∈\mathbb{R}^d를 얻을 수 있습니다.
**Yu, Hao, et al. “Rotation-invariant transformer for point cloud matching.” CVPR 2023.
Local 2D Feature Extraction
FPN구조의 CNN 백본을 이용하여 이미지로부터 local feature를 추출하였으며, 2D 인코더는 객체 영역으로 crop된 HxW 크기의 입력 이미지로부터 {{H}\over{8}} ⨉ {{W}\over{8}}크기의 feature map으로 다운샘플링하며 local texture 정보를 3D geometric 특징과 동일하게 d 차원의 latent space로 투영합니다. 그 다음, 이미지의 local feature map을 \phi^{K'}=\{k_t \mathbb{R}^d|1≤t≤ {{H}\over{8}} ⨉ {{W}\over{8}}\}로 flatten하며, 이때 2D superpixel을 K'로 나타냅니다.
**Sun, Jiaming, et al. “LoFTR: Detector-free local feature matching with transformers.” CVPR 2021.
Latent Fusion Attention Module
저자들은 3D와 2D local feature를 융합하기 위해 Latent Fusion Attention Module을 제안하였습니다. 네트워크의 일반화 가능성을 유지하고 객체에 대한 과적합을 방지하기 위해 coarse-level의 latent space에서 두 feature를 융합하고, 두 방면에서 특징을 융합하기 위해 3D-to-2D Fusion Block과 2D-to-3D Fusion Block을 이용할 것을 제안합니다. Latent Fusion Attention Module은 Latent Fusion Transformers([Figure 2]-(b)에서 초록색)와 Global Transformers([Figure 2]-(b)에서 파란색)를 이용하며 positional encoding을 이용하여 공간 정보를 통합합니다. 2D feature는 2D feature map의 공간정보를 feature space로 인코딩하고, 3D feature는 point의 위치를 직접 인코딩하는 대신 pose에 구애받지 않는 PPF(Point pair Feature]를 위치 정보로 활용하는 것을 제안하여 Unseen 객체에 대한 rotation-invariant와 일반화 가능성을 보장합니다.
Latent Fusion Transformer는 2D superpixel feature와 3D superpoint feature를 융합하기 위해 일련의 self-attention과 cross-attention 레이어로 구성되었으며, 이때 계산 복잡도를 낮추기 위해 모든 self/cross-attention 레이어에 대하여 linear attention을 채택하였다고 합니다. 각 Latent Fusion transformer마다 g개의 self/cross-attention 레이어를 쌓았으며 Global Transformer는 3D의 global context 정보와 3D feature를 모으도록 설계된 RoITr의 구조를 따랐다고 합니다.
3D-to-2D Fusion Block과 2D-to-3D Fusion Block은 [Figure 2]에서 확인할 수 있으며,
- 3D-to-2D Fusion Block
- CAD의 \phi^{P'}와 depth의 \phi^{Q'}의 superpoint features를 Global Transformer를 이용하여 집계
- RGB feature \phi^{K'}를 depth와 CAD의 global-aware feature와 Latent Fusion Transformer를 통해 순차적으로 융합
- 각 superpixel에 대한 cross-modal 2D feature \tilde{\phi}^{K'}를 구함
- 2D-to-3D Fusion Block
- Latent Fusion Transformer를 이용하여 CAD의 \phi^{P'}와 depth의 \phi^{Q'}에 GB feature를 융합하여 feature를 개선함
- Global Transformer를 통해 CAD와 Depth에 대해 2D-aware 3D superpoint feature \tilde{\phi}^{P'}, \tilde{\phi}^{Q'}를 구함
4. Learning to Describe
저자들은 융합된 descriptor를 학습하기 위해 새로운 loss function을 제안합니다. 먼저 RGB로부터 추출한 latent feature를 이용하 서로 다른 두 3D latent space의 통합을 촉진하고 superpoint사이의 보다 강력하고 안정적인 대응 관계를 생성하기 위해 Bridged Coarse-level Matching Loss를 정의하며, superpoint와 point의 대응을 정밀하게 조정하기 위한 Fine-level Matching Loss도 정의하였습니다.
Bridged Coarse-level Matching Loss
RGB 기반의 2D 정보의 요율성을 보장하기 위해 2D와 3D feature 사이의 cross-modal 매칭을 설정하여 2D와 3D 모두에 학습 신호를 제공합니다. superpoint P'와 Q'사이의 정렬은 GT 변환행렬곽 nearest neighbor search를 통해 구할 수 있으며, superpoint와 superpixel 사이의 GT 3D-2D 대응은 RGB-D 쌍을 통해 구할 수 있습니다.
Cicle Loss를 적용하여 positive superpoint 쌍의 유사도는 최대화하고, negative쌍의 유사도는 최소화하도록 설계합니다. superpoint사이의 overlap \mathcal{V}는 아래의 식 (2)로 구할 수 있으며,
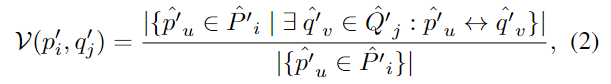
- \hat{P}'_i와 \hat{Q}'_j는 각각 p'_i와 q'_j에 할당된 주변 point 그룹을 의미
\mathcal{V}(p'_i,q'_j)>\tau_r(\tau_r는 설정한 임계치)를 만족할 경우 p'_i와 q'_i는 positive쌍으로 간주하며 Q'로부터 positive한 superpoint쌍을 샘플링하고, P'로부터 negative 쌍을 샘플링하여 overlab 가중치를 이용하여 P'에 대한 coarse-level superpoint Circle Loss \mathcal{L}^{P'}_c를 구합니다.(정확하게 loss에 대한 정의는 appendix에 있다고 하는데, 찾아봤지만 찾지 못했습니다.. overlap이 적을수록 loss가 커지도록 설계되었다는 정도로 이해하였으며, 해당 파트는 추후 업데이트 하도록 하겠습니다) Q’에 대해서도 동일하게 loss를 구하며 두 superpoints P’와 Q’ 사이의 loss는 아래의 식(3)으로 정의됩니다.
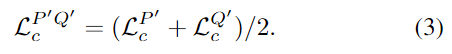
마찬가지로 3D-2D coarse-level matching에 Circle Loss를 적용하며, 이때 먼저 3D positive와 negative 샘플을 2D 평면에 투영한 뒤, 2D superpixel과 3D superpoint 사이의 positive와 negative 쌍을 얻어 Loss를 구합니다. 이때, K’와 Q’사이의 Loss는 \mathcal{L}^{K'Q'}_c, K’와 P’ 사이의 Loss는 \mathcal{L}^{K'Q'}_c로 나타내며, 전체 Bridege Coarse-level Matching Loss는 아래의 식 (4)로 정의됩니다.
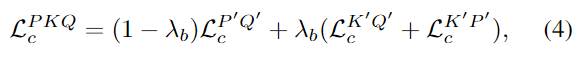
- \lambda_b: 가중치행렬
Fine-level Matching Loss와
3D-3D 대응의 정밀도를 높이기 위해 CAD의 point cloud P와 depth의 point cloud Q에 fine-level matching loss를 적용하고, 일련의 decoder blocks를 이용하여 coarse-level의 superpionts P’와 Q’에서 더 dense한 P와 Q를 생성합니다. superpoint의 대응관계가 주어졌을 때, fine-level point feature는 각 superpoint로 할당되고, 해당 그룹사이의 유사도 행렬을 구합니다. 유사도행렬에 negative log-likelihood를 적용하여 fine-level matching loss \mathcal{L}^{PQ}_f를 구하고, 전체 loss는 아래의 식(5)로 정의됩니다.
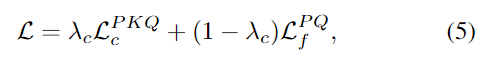
- \lambda_c: 가중치행렬
5. Matching Descriptors and Estimating 6D Poses
다양한 objects와 이미지를 학습하여 descriptor를 구합니다. inference과정에는 CAD와 depth로부터 추출된 특징을 이용하여 3D-3D mathe를 구한 뒤, 공분산 분석을 이용하여 normalized 된 feature의 유사도를 확인합니다. η개의 pose hypotheses를 생성하여 상위 k개의 3D-3D matches를 결정합니다. 이때, hypothesis \mathcal{T}_{v} (1≤ v ≤η)는 먼저 \mathcal{C}로부터 랜덤하게 s개 (s≪k)를 선택하여 식(1)을 통해 구한 6D Pose값이며, 해당 과정은 η에 따라 속도가 결정됩니다. 모든 hypotheses는 3D와 RGB 사이의 평균 점수를 기준으로 순위를 매겨 가장 높은 점수를 가지는 값을 pose \mathcal{T}로 예측합니다.
Experiments and Results
본 방법론은 5개의 BOP core dataset에 대하여 평가를 수행하였다고 합니다.
모델의 학습을 위해 MegaPose에서 제안하는 Google-Scanned-Object(GSO) 데이터 셋을 이용하여 학습을 수행하였으며, 해당 데이터는 800K개의 렌더링 이미지가 포함된 850개의 GSO object로 학습데이터가 구성되며, 나머지 94개의 객체에 대한 200K의 이미지가 평가데이터로 구성됩니다. Unseen object에 대한 평가를 위해 LM-O, T-LESS, TUD-L, IC-BIN, YCB-V라는 5개의 BOP core 데이터 셋을 이용하여 평가를 수행하였으며, 그중 LM-O를 이용하여 ablation study를 수행하였다고 합니다.
평가지표는 BOP 챌린지에서 사용하는 3가지 recall에 대한 Average Recall(AR)을 채택하였으며, 또한 타 베잇으라인 방법론과의 비교를 위해 6D Pose Estimation에서 많이 사용하는 ADD-0.1d(객체의 크기의 10%만큼의 오차를 허용하는 ADD 평가지표)에 대한 성능을 Table 2에 리포팅하였다고 합니다.
Evaluation on 5 BOP Core Benchmark Datasets
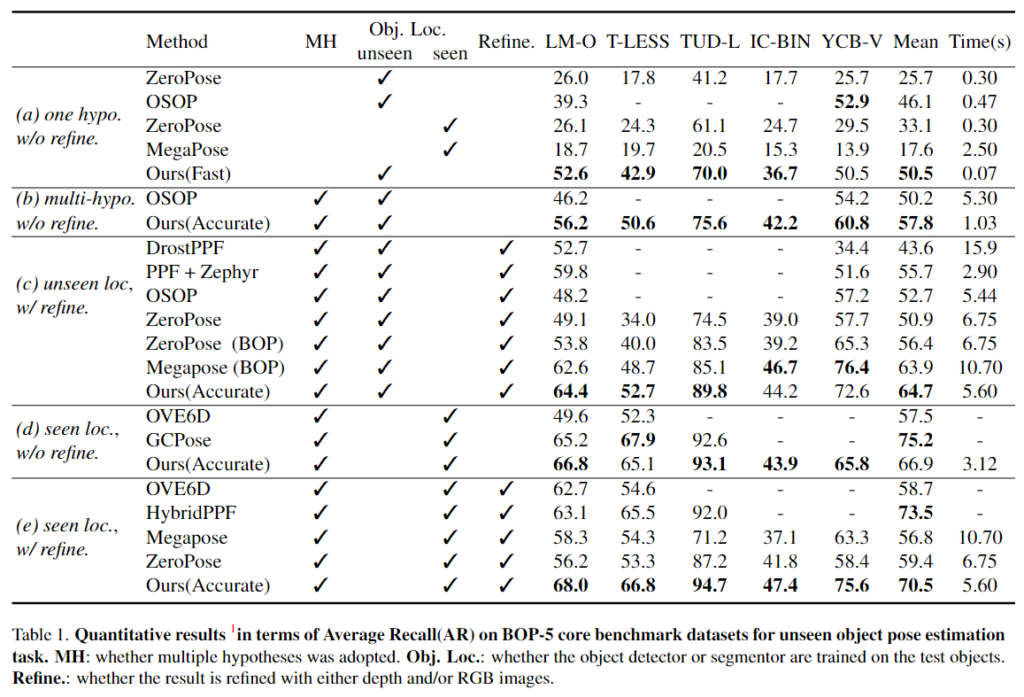
- 위의 Table 1을 통해 BOP core 데이터 셋에 대한 베이스라인과의 성능을 비교할 수 있으며 Unseen object에 대한 pose estimation에서 SOTA를 달성하였다고 합니다.
- 하나의 pose 가설을 이용하는 방식에 대해서 Ours(Fast), 여러개의 가설을 이용하는 방식을 Ours(Accurate)로 표현하였으며, 공정한 비교를 위해 baseline에 따라 5가지로 나누어 평가를 수행하였다고 합니다. (seen loc.라는 표현은, detector의 학습 과정에 해당 객체를 학습하였는지를 의미합니다. 6D Pose Estimation은 여전히 unseen인 것으로 이해하시면 될 것 같습니다.)
- (a) 추론 과정에 1개의 Pose 가설만을 이용하며 refinement 수행하지 않음(Zero-Pose, OSOP, MegaPose): 타 방식에 비해 속도가 크게 개선되었으며, 타 방법론과 비교했을 때 대부분 우수한 성능을 보이는 것을 확인하였습니다.
- (b) 여러개의 pose 가설을 이용하며 refinement 수행하지 않음(OSOP): pose가설이 늘어남에 따라 성능이 개선됨을 확인할 수 있습니다.
- (c) ICP refinement를 추가하여 평가를 수행하였으며, unseen에 대한 평가 중 가장 좋은 성능을 달성하였습니다. 특히 렌더링을 이용하는 타 방법론(ZeroPose, MegaPose)에 비해 훨씬 적은 시간이 소요됩니다.
- (d) 학습한 객체에 대한 평가를 수행(OVE6D, GCPose): Ours 방법론들과 비교하였을 때 대체로 성능이 조금 더 좋아진 것을 확인할 수 있습니다.
- (e) 객체에 대해 학습한 detector를 이용하고 refinement를 수행하여 높은 성능을 달성하였으며,(HybridPPF는 3개의 데이터에 대한 결과이므로 비교에서 제외한 것으로 파악됨) 이에 대한 정성적 결과는 아래의 [Figure 3]을 통해 확인할 수 있습니다.

Capturing Symmetry and Texture
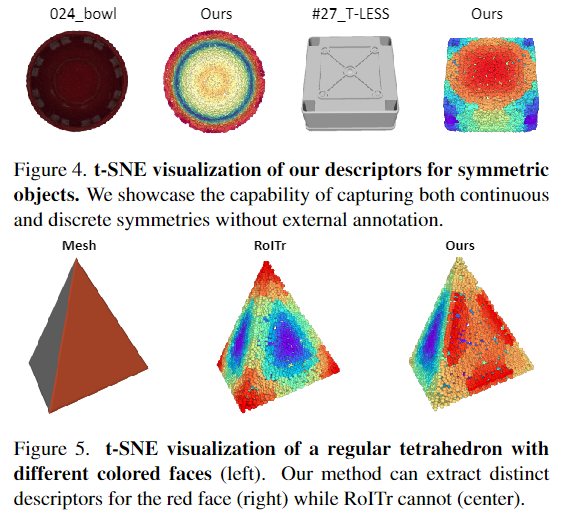
위의 [Figure 4]는 대칭 객체에 대한 descriptor를 t-SNE로 시각화 한 결과로, 연속적인 대칭(024_bowl)과 discrete한 대칭(#27_T-LESS)을 인식할 수 있음을 확인하였습니다. 또한, [Figure 5]에서 빨간 면과 흰색 면으로 이루어진 기하학적으로 유사하지만, 색상이 다른 객체에 대한 t-SNE 결과를 통해 저자들이 제안한 방식은 기하학적 유사성을 파악할 수 있는 rotation-invariant한 RoITr에 비해 texture 정보를 추가함으로써, 구조적으로 유사한 경우 발생하는 모호성을 해결할 수 있음을 보였습니다.
Comparison with RGB-D Fusion Pipelines
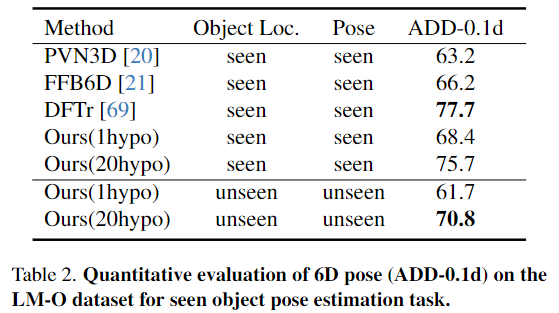
Table 2는 RGB-D 융합 방식의 효과를 입증하기 위해 LM-O에 대한 최신 방법론(PVN3D, FFB6D,DFTr)과 비교 실험을 수행한 결과로, 기존 방법론 대비 좋은 성능을 보였으며, 많은 pose 가설을 이용하는 DFTr과 비슷한 성능을 보이는 것을 실험적으로 확인하였습니다.