
안녕하세요. 해당 논문은 연구실에서 제출 예정인 과제의 1차년도에 사용될 방법으로, 그래서 자세히 읽어본 점도 있지만 RGB 영상에 비해 Depth 영상의 이점, 활용 방안 등을 모색해보고자 읽게 되었습니다. 현재 저는 뇌과학 기반의 OWOD 아이디어를 구상 중에 있는데, 약 80% 정도 구상되었지만 추가적인 Novelty를 위해 이, 저, 그 논문 등을 읽으며 추가적인 아이디어를 얻고 있습니다. 구상이 완전히 마치면, 실험해본 이후 논문을 쓰고 싶네요. 뇌과학 기반이여서 사람의 인지와 관련된 논문도 잠깐 들여다 봤는데 AI 논문이 아니여서 그런지 정말 재미없습니다. 바로 리뷰 시작하겠습니다.
Preliminaries
본 논문의 대주제는 “open-world class-agnostic object detection” 또는 “open-world object proposal (owop)“에 해당합니다. 아직 wood 논문의 시초인 “Towards Open World Object Detection“을 리뷰하진 않았지만, 분명히 owod와는 다른 태스크입니다. 해당 태스크에 대한 저자의 설명을 보면 “detecting every object in an image by learning from a limited number of base object classes“로, known class인 base object class의 객체로부터 영상 내 모든 객체를 찾는 태스크입니다. 분명히 다른 점은 해당 태스크는 owod와 달리 객체의 클래스를 예측하지 않습니다. 그렇지만, 논문을 읽어도 known class의 지식을 어떤 방식으로 활용하자는 내용은 명확치 않습니다. 추측하자면 pseudo label을 위해 네트워크의 입력 시 known class의 bounding box를 사용합니다.
Introduction
어떤 태스크든 포화 상태 (saturation)에 이르렀다고 말할때가 있습니다. 전통적인 image classification 태스크는 OmniVec이 ImageNet에서 92.4%의 정확도를 보입니다. object detection의 대표 벤치마크인 MS COCO는 Co-DETR이 66%의 mAP를 보입니다. 물론 누구는 100%의 정확도가 아닌데?와 같은 질문을 하며 “그래. MNIST에서는 100%여도 다른 벤치마크에서는 100%가 아니잖아?”는 의문을 품으며 domain generalization의 태스크가 등장하기도 하고, 또는 “그런데 있잖아. 데이터의 양이 중요한데 모두 annotation해서 학습하기엔 힘들지 않아?”는 의문을 품으며 self-supervised learning 태스크를 만들어내기도 합니다. 지금의 object detection에서의 추세 또한 마찬가지입니다. 제가 얼마전 눈문을 쓴 multispectral pedestrian detection도, kaist 데이터에서 5.5의 miss-rate를 보입니다. 일반적인 pedestrian detection에서는, 리뷰와 세미나 했었던 LSFM 이름의 논문 (2023 cvpr)은 0.18%의 miss-rate를 보입니다. 엄청난 수치죠. 위와 동일한 방식으로 이제 연구자들은 일반적인 object detection에 다음의 의문점을 품습니다. “그런데, COCO는 80개의 클래스에서 평가하잖아? PascalVOC는 20개의 클래스에서 평가하잖아? 그런데 100개의 클래스, 아니 현실에서는 그 이상의 수 많은 클래스가 존재하는데, 해당 클래스의 객체에 대해서도 강인하게 작동할 수 있을까?”
open-world object detection은 바로 위의 물음에서 출발한 태스크입니다 (2021 cvpr). 위의 물음에서 다양한 방식의 접근법이 존재할 수 있겠죠. few-shot objecct detection, zero-shot object detection, open-vocabulary object detection (ovod) 등이 대표 주자일텐데, 제 생각에는 다음의 문제점이 존재합니다. “정말 open-world, 즉 위에서 말한 현실 세계의 모든 객체들을 찾고자하는 목적인데, 소수의 학습을 위한 base-class가 존재하는 few-shot의 방식 혹은 텍스트를 필요로 하는 zero-shot, ovod가 정말 open-world로 볼 수 있을까?” 그렇기에 owod는 제게 훨씬 매혹적이였으며, 석사 기간 간 연구 방향이 되었습니다.
introduction에서는 해당 내용이 첫 번째 핵심입니다. 사실 앞선 논문들에서도 그리고 owod 태스크를 다른 연구원에게 소개할 때도 몇 번을 언급하였지만, 제게는 그 출발점이 매혹적이였기에 다시 한 번 언급하였습니다. 그렇다면 본 논문의 저자는 open-world 태스크에서 (predefined known 클래스 외의 객체를 찾아야 하는 설정) 현존하는 object detector가 원만히 수행되지 않는 이유에 대해 어떻게 설명했을까요? 저는 저자가 말한 이유가 직관적으로 충분히 납득되었습니다. 현존하는 object detector (이하 od)는 학습 동안 모델이 known 클래스가 아닌 다른 클래스에 대해 예측 시 (이러한 예측을 objectness로 이해하면 좋을듯합니다. objectness란 “객체스러운데?”, “객체 아닐까?”하며 모델이 예측한 결과를 의미합니다), 배경 (background, 이하 bg)으로 예측하도록 패널티 (loss)를 줍니다. 줄이자면 학습 동안 objectness에 대해 bg로 예측하도록 유도되니, 당연히도 open-world에서는 known 이외의 객체들은 bg로 판명나게됩니다. 만약, 그렇게 하지 않고자 단순한 방법으로 oracle이 학습 중간에 개입하여 unknown에 대한 라벨을 부여한다면 다음부터는 해당 클래스로 잘 예측할 수 있을까요? 물론 그렇지 않을때보다는 좋겠지만, 마치 known 클래스의 객체 수에 압도되듯 known 클래스의 한 클래스로 예측하게 됩니다. 한마디로 bias됩니다.
그렇기에 기존 연구들은 모델의 예측이 bg로 유도되지 않도록, 즉 objectness를 예측하는데 suppress되지 않도록 loss를 수정하도록 하였습니다. 그러나 저자는 이 때 전혀 다른 두 번째 문제를 내세웁니다. 이는 모델이 현재 RGB 영상만으로 학습하는데, 그렇다면 appearance (texture) cue에 너무 의존한다는 점입니다. 즉 모델이 open-world에서 좋은 검출 결과를 보이고자 한다면 일반성 (generalization)이 중요한데, RGB 영상의 semantic cue에 의존되어 unknown으로 보이는 (novel-looking) 객체에 대해서는 known과는 다른 외형이므로, 이를 검출하는데 어려움을 겪는다는 의미입니다. 사실 이는 “오히려 known과 unknwon이 다른 appearance cue를 가지므로 ood (out-of-distribution)로 풀 수 있을텐데?”의 질문으로 반박할 수 있습니다. 하지만 저자의 또 다른 주장은 “unknown이 known과 차별된 점을 배울 때, appearance cue에 over-fitting되어 일반성을 보장하지 못한다“고 말합니다. 사실 위 ood의 질문으로 반박하는 등의 내용은 그냥 제가 논문을 읽을 때 하는 생각들인데요, 예전에는 논문의 주장이 모두 타당하다고만 생각하니 문제점 제기가 쉽지 않더군요. 그래서 위와 같이 문장들에 대해 내가 아는 범주의 지식들로 반박해보며 읽습니다.
아무튼 그래서, 저자는 해당 문제점을 극복하고자 depth를 가져옵니다. 정확히는 depth map으로, 3D에서 z축 좌표가 존재하는 depth와는 다르지만 depth map은 객체의 외형 (contour) 정보에 대한 단서와 객체 간 location에 대한 연관성을 고려할 수 있습니다. depth 외에도 객체의 선 정보에 집중한 normal map을 소개하는데, 결국 이들은 모두 기하학적 단서 (geometric cue)로써 RGB의 texture (semantic) 정보와 분명한 차이점이 존재합니다. 다시 설명하자면 RGB의 appearance cue (high-level cue)에 비해 depth, normal map의 geometric cue (mid-level cue)는 known과 unknown 사이의 차이가 불분명한데, 오히려 이 점이 unknown 클래스의 객체를 구별할 수 있는 좋은 시그널이라고 주장합니다.

그렇다고해서 저자는 depth와 normal만을 사용하지는 않고, RGB는 objectness를 구별해낼 수 있는 중요한 단서를 지니고 있다는 점에 착안하여 depth로부터 pseudo-bbox를 만든 이후 RGB 영상을 입력으로 하는 최종 object detector가 objectness를 판단하도록 설계하였습니다.
이 과정을 자세히는 아래 방법론에서 풀겠지만 해당 태스크에 큰 관심이 없더라도 이 글을 읽는 연구원분들이 주목하면 좋을 점은 저자의 방법론보다도 글의 흐름이라고 생각합니다. 여기까지의 글만 읽고 이해가 어려운 부분이 있을 수 있다는 점에는 동의하나, 글에서 저자가 문제점을 제기하고 방법론을 제안하는 과정의 연결성이 짙다고 표현하고 싶습니다. 물론 저의 이해력이 부족한 점도 한 목 하겠지만 몇몇의 글은 좋은 학회의 논문에 붙었다고 해서 논문의 핵심 요소인 문제점 제기와 저자의 제안 간 연결성이 미약한 점도 존재합니다. 미약하여 추상적인 표현으로 설명한 글도 다수 존재합니다. 하지만 해당 글은 문제점 제기에서부터 “왜 내가 이렇게 하는지”를 제안하고, 본인이 제안하는 방법의 순서가 “왜 그래야 좋을지”에 대한 설득력도 충분합니다. 제가 생각하기엔 방법론이 혁신적인 논문은 물론 좋은 논문이거니와 동시에 이러한 논문도 굉장한 가치가 있다고 생각합니다. 제가 읽은 논문 중에서는 손가락 안에 들만큼 좋은 연결성을 보입니다. 시간이 부족하다면 논문의 introduction만을 영어로 쓱 읽어보면 좋지 않을까 싶습니다.
Related Work
Related work는 저자가 말하는 핵심적인 두 논문의 내용만 훑겠습니다. “Open-world class-agnostic object detection“의 OLN (KAIST 권인소 교수님의 김다훈 박사님, 현재는구글 딥마인드에 계시네요)은 unannotated unknown 클래스의 객체가 bg로 학습되지 않도록 유도하는 기존 od의 문제점을 해결하고자 Faster RCNN의 classification-head를 class-agnostic head로 (loss 계산 시 positive sample에 대해서만 계산하도록 함. 즉, predefined class 내 존재하지 않아 negative로 판명날 수 있는 objectness들에 대해서는 bg로 분류되지 않게 하고자 loss 계산을 하지 않도록 함) 바꾸었습니다. 해당 태스크의 시초 논문으로 보입니다. 다음으로 GGN이라는 논문은 객체 간 유사성을 예측하는 (학습하지 않는) 네트워크 통해 unannotated 객체에 대해 특정 pseudo-label을 부여 (예를 들어 유사하지 않으면 “unknown”, “unannotated” 등의 pseudo-label을 부여) 하는 방식입니다.
다음으로 “Incorporating geometric cues for generalization“은 geometric cue가 일반성을 위해 사용된 예시로, Omnidata는 large-scale의 데이터로 학습하여 depth map을 생성해내는 연구입니다. large-scale로 학습한만큼 일반성을 보장하며 해당 논문에서는 geometric cue가 RGB의 appearance detail을 제거하고 형태와 같은 객체의 사실적인 정보만을 보존하여 다양한 연구에서 일반성을 보였다고 합니다.
뒤의 method에 대한 리뷰를 보면 느끼겠지만, method가 굉장히 짧습니다. 위에서 말한 모델을 대부분 차용하여 네트워크를 구성합니다. 혹 이러면 novelty가 떨어지지 않나는 의문을 품을 수 있겠지만, depth map을 도입한 novelty가 분명하며 이보다도 저는 위에서 해당 논문의 서사 과정을 극찬하였듯 문제 제기와 depth map을 사용하는 과정이 글만으로도 충분히 납득되었기에 ICLR (다들 아시다시피 ICLR는 인공지능 전체 분야로 보면 1위급에 해당합니다)에 기고될 수 있었다고 봅니다. 물론 SotA인 면도 존재하겠지만, 그 또한 depth map을 사용함으로 SotA임을 보여 그 성능이 더더욱 납득될 수 있다고 봅니다. 너무 예찬만 하였네요.
Method
“Our goal is to incorporate geometric cues for an improved open-world class-agnostic object detection performance.“
3.1 Exploiting Geometric Cues
논문의 순서는 “open-world class-agnostic object detection problem”으로 시작하나, 우선 저자가 제안하는 depth map을 어떻게 사용할지가 가장 궁금합니다 (normal map도 물론 존재하나, depth map의 성능이 더 좋으며 비교적 원초적으로 보고 있으므로 depth map을 중점으로 설명합니다. normal map도 동작과정은 동일합니다).
다시 다음의 문제점을 상기하며 “RGB 이미지는 appearance cue에 의존하여 base class와 매우 다른 외형의 novel 객체를 탐지하는 데에 어려움”을 겪지만, depth map과 normal map은 각각 “객체 간의 상대적인 공간 상의 차이”와 “객체 내 외곽 차이(법선 벡터다 보니, 객체의 외형이 스케치하듯이 그려집니다. 위의 Figure 참고) 로부터 오는 정보”의 강점을 가집니다. 하지만 저자는 depth map을 추출하기 위한 네트워크를 구상하진 않고, 기존에 존재하는 (영어로는 off-the-shelf pretrained model이라 하는데, 해당 표현이 꽤나 자주 쓰이니 알아두면 좋습니다) 모델, 위의 Related Work에서 언급한 Omnidata의 벤치마크 모델을 사용합니다. 비록 해당 모델이 VOC, COCO 등에서 사전학습되진 않았으나 일반성을 보인다고 합니다. depth map을 추출 시에는 저자가 네트워크를 따로 제안하지 않았습니다.
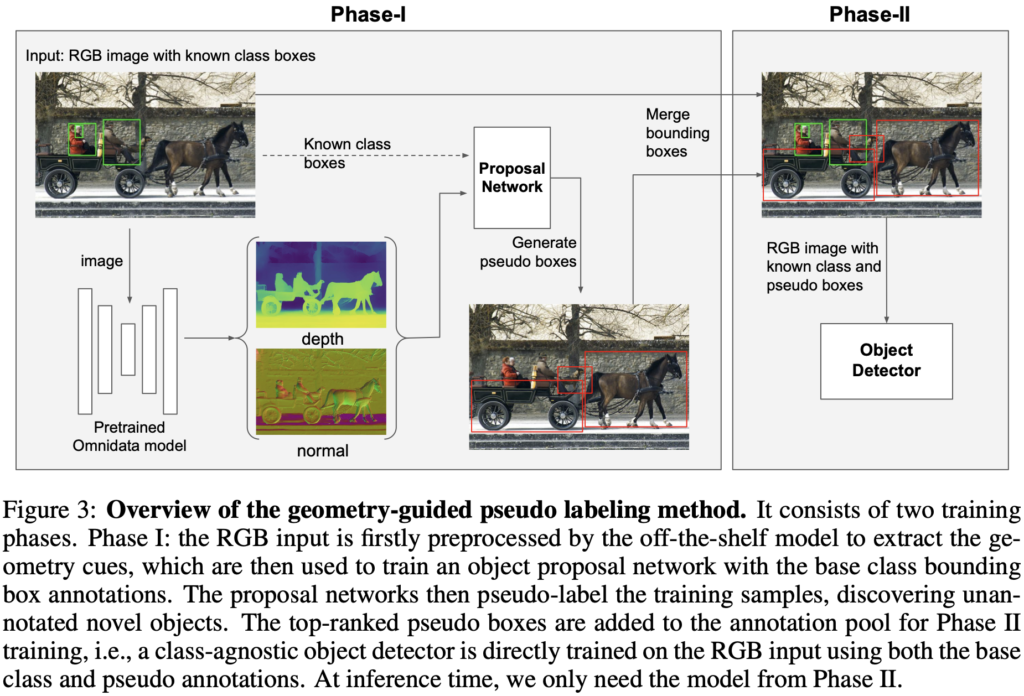
3.2 Pseudo Labeling Method
이제 depth map을 입력으로 하는 object proposal network로부터 pseudo label을 생성하는 단계입니다. 먼저, depth map을 입력으로 받는 object proposal network (OLN 모델 : Faster RCNN의 class-agnostic classification-head)를 학습합니다 (Figure 3의 Phase-I). 해당 모델의 결과는 RPN으로부터 후보군 (bounding box)에 해당합니다. 해당 후보군들 중, known 클래스의 객체와 겹치는 후보를 제거한 이후, 최대 k (top-k: 보통 1,2,3을 사용한다고 함)개의 후보군을 pseudo label로 두어 (ground truth에 해당 annotation을 추가, 현 태스크에서 클래스 정보는 무관함을 상기) Phase-II의 학습에 사용됩니다. Phase-II는 depth map이 아닌 RGB 이미지를 입력으로 받으며, 이 때 기존의 known 클래스의 bounding box와 동시에 pseudo-label의 bounding box가 입력됩니다. 분명 RGB는 objectness를 구별해낼 수 있는 중요한 단서를 지니고 있다는 점에 착안한다고 하였던 점을 상기하여, 해당 pseudo label이 1) 해당 bounding box가 object에 그려진 좌표인지 (regression, objectness 점수를 비교합니다), 2) object에 해당하는 bounding box의 좌표가 적절한지 (regression, 직접적으로 bounding box의 좌표를 비교합니다)를 학습합니다.
3.3 Open-world Class-agnostic Object Detection Problem
closed-set 내 od의 프레임워크는 pre-specified(defined) 리스트 \mathcal{K} 개의 클래스에 대해 bounding box 어노테이션 \left \{ t_i \right\} 에 대해 학습합니다. od에서 일반적인 loss는 아래와 같이 구성됩니다.
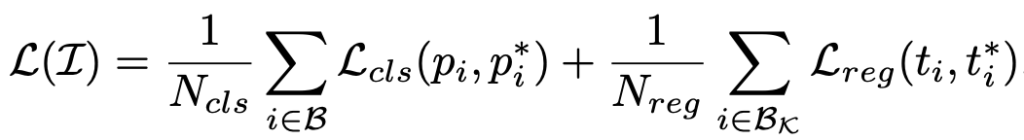
위 수식-(1)은 i 는 모델의 예측 앵커 \mathcal{B} : \left\{ p_i, t_i \right\} (레이블, bounding box 순)와 각 예측에 대응되는 gt인 \left\{ p_i^*, t_i^* \right\} 에 대해 loss를 계산합니다. N_{cls} , N_{reg} 는 모델 예측의 전체 수와 gt에 매칭된 앵커 (bg로 판별된 앵커를 제외한)이며, 이 때 gt의 레이블에 해당하는 p_i^* 는 예측 앵커가 closed-set 내의 클래스 ( \mathcal{K} )에 해당하면 1, 그렇지 않으면 0 (bg)입니다. 일반적인 od의 classification loss와 localization loss로, localization 시에는 known class와 비교한 positive sample만 bounding box에 대한 regression을 수행합니다.
open-world에 대한 탐지를 위해선 (i.e. unknown novel 클래스의 객체를 탐지하기 위해선) unannoted sample이 nagative sample (“background” 클래스)로 판별되어 regression을 계산하지 않도록 하는, 그 지점을 바꾸어야합니다. 해당 논문의 베이스 네트워크가 되는 OLN은 위 문제점을 피하고자, 수식-(1)의 classification loss를 objectness score prediction loss로 변경하였습니다. (수식-(2))
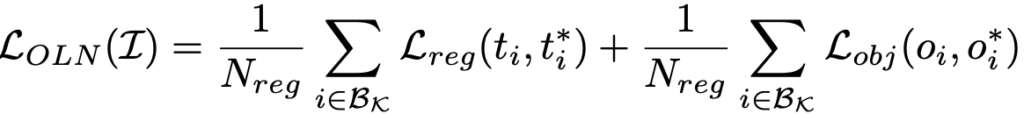
classification loss를 objectness score prediction loss로 변경하였다함은 단순히 말해 “예측한 anchor가 object로 판명될 (Faster RCNN이 objectness binary classification – multiclass classification 순서임을 상기하면, objectness binary classification과 유사한 역할을 할 수 있습니다) score를 예측하는 방식으로 학습을 진행합니다. notation에 대해서는 위 수식-(2)에서 변경된 점은 \mathcal{L}_{obj}, o_i, o_i^* 는 각각 objectness prediction loss, 예측 objectness score와 gt objectness score (위 수식-(1)의 p_i^* = 1의 객체만 포함)에 해당합니다. 해당 objectness score는 inference 시 prediction의 rank로 사용되어 예측 box 중 top-k를 추론하는 데에 사용됩니다. 하지만, 위의 수식에서는 anchor들이 결국 objectness score를 예측 시에 gt와 비교하므로, gt의 클래스 (base class)에 overfitting된다는 약점이 있습니다. 사실 위 loss에서는 novel 클래스의 객체들이 어느 gt에 매칭되어 학습되어야할지에 대해 모호한데, 저자는 이 점을 짚습니다. 따라서 추가적인 loss의 변경을 제안하지는 않지만 단순한 방식으로: unknown, novel에 해당하는 “object” 클래스 (위에서 생성한 pseudo-label들이 이 “object” 클래스에 해당함)를 만들어 novel 클래스 객체들이 모두 “object” 클래스에 매칭되어 objectness를 예측하도록 유도합니다. 이와 같이 한 이유는 결과적으로 “bg를 suppression하지 않도록 하는 목표”에 있습니다.
Experiments
본 태스크는 owod와의 분명한 차이가 있지만, 클래스를 예측하지 않는다는 점에서 owod에 비해 많은 연구자들의 주목을 받지 못한 것은 사실인듯합니다. 비교 실험 대상은 Related Work에서 소개한 OLN, GGN이며 추가적으로 Faster RCNN을 oracle (COCO 사전학습: 다음 소개할 cross-category에 대한 벤치마크에서 upper bound에 해당함)과 class agnostic한 방식으로 학습한 FRCNN, 이외 pseudo labeling에 depth / normal이 아닌 RGB 기반의 pseudo labeling을 진행한 (self-training) SelfTrain-RGB로 평가합니다.
본 연구에 사용되는 데이터 셋은 Pascal과 COCO입니다. 평가 방식은 두 방식을 따르는데, 예를 들어 COCO에서 base class로 Person / 이외의 class는 novel class (person vs non-person)로 지정한 방식의 평가 방식을 cross-category 평가, owod 방식과 동일하게 Pascal를 base class (20개의 클래스) / Pascal과 겹치지 않는 COCO의 클래스를 novel class로 지정한 방식 (voc->non-voc)의 평가 방식 또한 cross-category 평가로 설정합니다 (person->non-person에 비해 voc->non-voc가 도메인의 차이로 인해 성능이 낮을 수 있다고 생각하였지만, 아래의 벤치마크 표를 보면 그렇지 않다는 점을 통해 base class의 수 또한 (known 클래스의 객체가 많을 수록 좋은 성능을 보임) 매우 중요하다는 점을 유추할 수도 있습니다).
흥미로운 점은 implementation detail을 살펴보면, Faster RCNN을 기반으로 하는 OLN의 구조를 사용하며, depth map 생성시에는 앞서 말한 Omnidata 벤치마크 모델을 사용합니다. 즉, 본인들이 아키텍쳐를 설계하지는 않았으나, ICLR 2023에 붙은 이유는 아무래도 depth map을 사용하는 부분이 명확한 contribution으로 인정받을 수 있지 않았나 싶네요. 최근 어느 연구든 LLM을 붙여 좋은 학회에 다수 붙는단 이야기들이 나오는데, LLM 자체가 붙이는 이유를 무한정 만들 수 있어 그 자체만으로도 contribution이 될 수 있었으리라 생각듭니다. 또한 기존에 학습된 모델들을 사용하여서인지 depth map으로부터 나온 pseudo label을 학습하는 epoch는 단 8 (뒤에 flipping, resizing과 같은 augmentation을 사용하는데, 그때도 16)에 불과합니다.
평가 방식은 Average Recall (AR@k)로, 이 때 k는 몇 개의 object proposal을 사용하는지에 따라 상이합니다 (budget으로 표현되며, default는 100: 최대 100개의 object에 대해 검출하겠단 의미입니다). AR_A, AR_N, AR^{s/m/l} 은 순서대로 base class와 novel class 전체에 대한 평가 (All), novel class에 대한 평가 (Novel), 객체의 크기에 따른 평가 (small, medium, large)입니다. 제 생각엔 주로 주목할 지표는 AR_N 으로 보입니다. base class는 gt로 주어져 학습을 진행하기 때문입니다.
실험은 각 목적을 가지고 진행됩니다. 벤치마크, depth의 중요성 (geometric cue), RGB로부터 다른 geometric cue를 만드는 방법에 대한 비교 평가, 해당 방법에서 augmentation의 중요성 (결론부터 언급하자면, augmentation을 통해 pseudo label (bounding box)의 noise함을 줄일 수 있다고 합니다)에 대해 순서대로 실험을 보입니다. 이 점도 논문 전개가 흥미롭습니다. 웬만한 연구들이 해당 프로토콜을 따르긴 하지만, 소제목 별로 구분지으며 차근차근 이야기를 풀어내는 느낌으로 읽을 수 있었습니다.
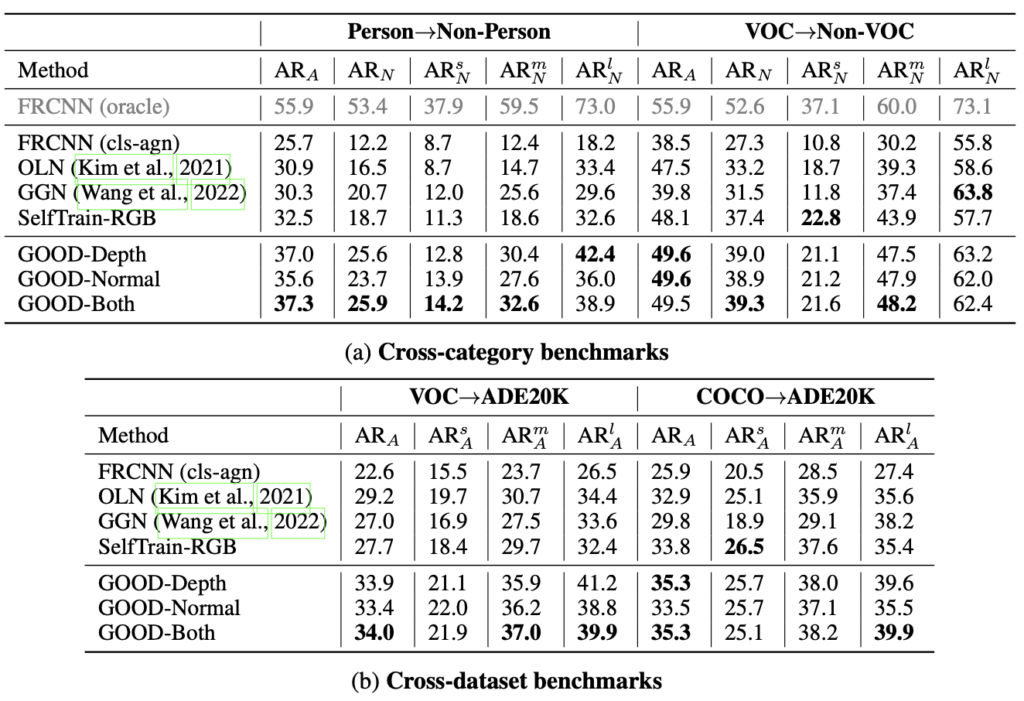
표-(1)은 벤치마크 성능입니다. GOOD-Depth / GOOD-Normal, 그리고 GOOD-Both가 있는데, 이 때 GOOD-Both는 depth map과 normal map으로부터 나온 pseudo box를 합친 (중복된 박스는 제거한 채) pseudo box를 생성하는 방법입니다. GOOD-Both가 Person->Non-Person 실험의 AR_A, AR_N 에서 최고의 성능을 보이지만, 둘을 믹스한 방법이므로 더 주목되는 점은 “그럼 depth map과 normal map 중에선 어떤 방법이 더 좋은가?”로 보았을 때, normal에 비해 depth map을 사용했을 때 더 좋은 성능을 보입니다 (제가 depth map를 중점으로 리뷰하겠단 이유입니다). 물론 성능만으로도, 기존의 OLN과 GGN에 비해 성능 차이가 약 7퍼센트 이상 큰 향상을 이룬다는 점에서 depth map을 사용해야하는 이유가 더 설득력 있어 보입니다. 또한 표-(1)에서 당연히 cross-category는 cross-dataset에 비해 더 좋은 성능을 보임을 예상하였지만 (데이터 사이의 domain gap이 존재하므로), 막상 그렇지도 않습니다. 앞서 한 번 언급은 하였지만, base (known) 클래스의 객체 수가 일반된 성능을 보임에 매우 중요하며, FRCNN(oracle)이 모델이 할 수 있는 최대치로 두었으므로, VOC->Non-VOC로 평가하였을 때 6% 가량의 차이만을 보인다는 점도 주목됩니다.
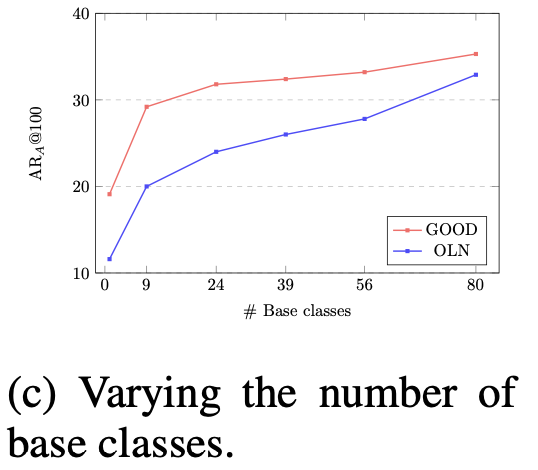
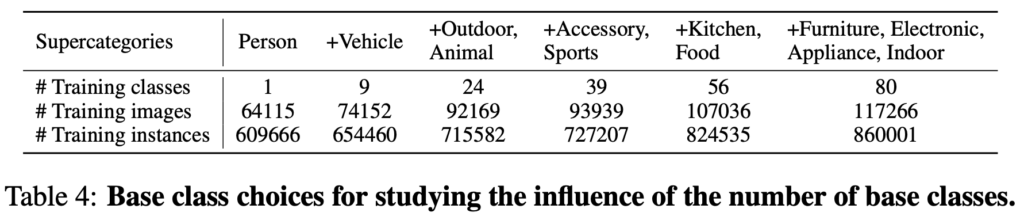
Base 클래스의 수가 중요하다하였으니 이에 대한 ablation study를 먼저 살펴보면, 저자가 제안한 GOOD 외에 OLN도 마찬가지로 base 클래스의 수에 따른 일정한 성능 향상을 보입니다. 이는 해당 태스크의 명확한 단서로 보이기도 합니다. known의 데이터 베이스가 많을 수록 즉, 데이터의 양이 중요한 역할을 한다고 해석할 수도 있습니다.
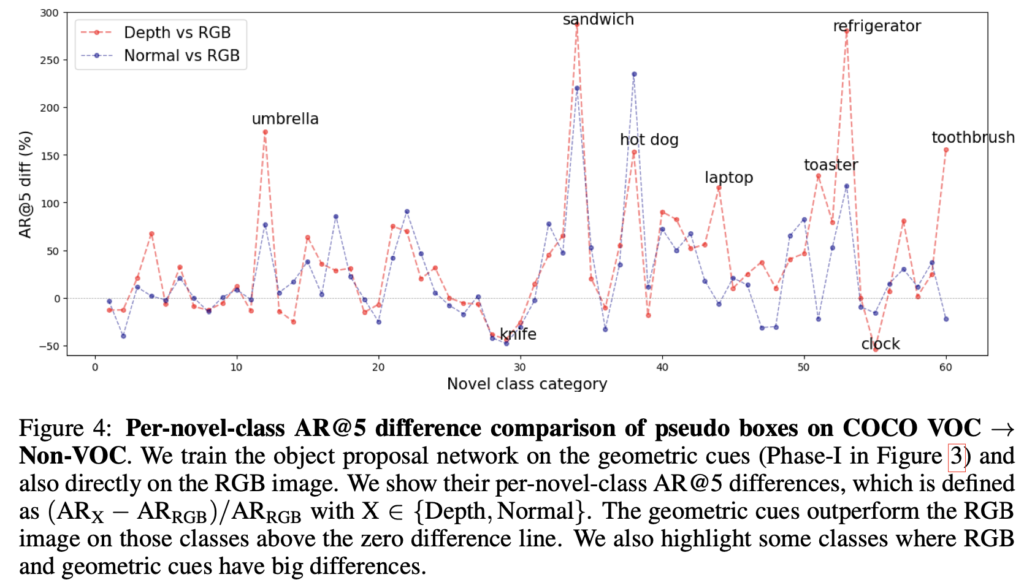
또한 저자는 위 Figure 4의 실험을 통해 벤치마크 표의 VOC->Non-VOC 실험에서 대부분의 클래스에 대해 RGB 기반의 방법에 비해 depth map, normal map을 사용하는 편이 더 좋다고 설명합니다 (해당 그래프는 RGB-depth, RGB-normal 간의 차이를 보입니다, Y축을 보면 0인 지점이 중앙에 있는데, 이처럼 RGB 기반의 성능이 더 좋을때도 있습니다. 이 이야기는 뒤에서 다시 풀겠습니다). 전체 성능을 보여준 이후, 몇몇 클래스 때문이 아닌 모든 클래스에 동일하다를 보이고 있습니다. 다음 실험은 어떤 실험일까요? “그럼 RGB에서는 다른 geometric cue를 추출할 수 없을까?“에 대한 궁금증에서 출발합니다.
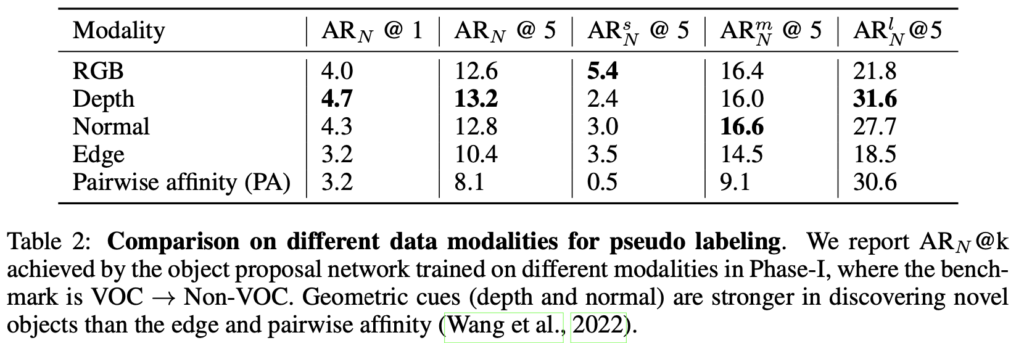
표-(2)의 Edge와 Pairwise affinity (PA)는 각각 2D edge map을 추출해내는 방식, 그리고 객체 간의 경계 (boundary)를 추출해내는 방식의, depth와 normal와는 다른 geometric cue에 해당합니다. 결과적으로 보았을 때 두 방식은 좋은 성능을 보이지 못합니다. 이에 대해 저자는 “2D edge와 PA는 객체의 경계에 집중하는 반면, depth와 normal은 이외의 추가적인 공간 상의 (spatial) 이해를 학습할 수 있어 (이를 설명하면, depth는 각 객체 간 가까운 정도, 먼 정도, 위치 정보를 내재합니다. 단순히 객체 간 경계만 구분하는 것에 비해 이점을 보입니다) 더 좋은 성능을 보인다”고 설명합니다.
이제 저자는 다시 생각해봅니다. “RGB가 appearance cue에만 의존하고, over-fitting된다고 하였으니, 이에 대한 규제를 하면 depth와 normal에 비해 더 좋은 성능을 보일 수도 있지 않을까?” 잘 생각해보면 위의 과정이 아니라면,이 실험은 “정말 depth가 추가적인 geometric cue를 주고 그 덕분에 좋은 성능을 보일 수 있었음”을 반증하는 실험이기도 합니다.
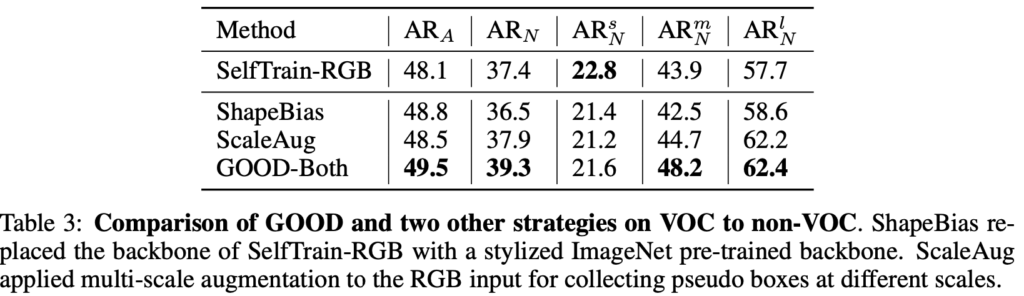
즉 저자는 텍스쳐 정보에 편향되지 않도록, augmentation 기반의 ShapeBias, ScaleAug의 방법을 사용합니다. 해당 방법에 대해선 표에 설명되어있듯이 style-based augmentation, multi-scale augmentation이라고 설명하지만, 지금은 “해당 방법이 정말 RGB의 appearance cue에 편향되지 않도록 하는 방법일까?” 보다는 해당 방법이 성능을 올리고, depth에 비해 더 좋은 성능을 보일까?입니다 (해당 방법에 대해 자세히 알아보기 어려울뿐더러, ShapeBias와 ScaleAug라는 방법이 augmentation 기반이니, augmentation의 본질이 학습 데이터의 bias를 줄이기 위함을 내재하고 있으니 넘어가도 좋다는 의미입니다).
결과적으로는, depth와 normal을 사용하는 GOOD-Both가 RGB 기반의 augmentation에 비해 더 좋은 성능을 보입니다 (depth만 사용하는 성능, normal만 사용하는 성능이 해당 평가에서 더 좋은 성능을 보임을 벤치마크 표-(1)을 통해 이미 확인하였습니다). 자 여기까지의 실험을 통해 또 재미있는 사실을 볼 수 있습니다. 저자가 이미 언급하였지만, RGB 기반의 방법들이 웬만해서 AR_N^s 에선 더 좋은 성능을 보인다는 점입니다. 표-(1)과 표-(2)도 동일합니다. 심지어 Figure 4에 대한 설명에서 이미 한 번 언급했습니다. 이에 대해 저자는 “작은 크기의 객체는 구분지을 수 있는 점이 appearance cue가 더 도움이 될 수 있으며 이 때 geometric cue는 작은 객체에 대해서는 불충분한 정보 또는 해당 정보 자체를 잃어버릴 수 있다 (depth map을 생성하는 과정에서)”고 설명합니다.
잠시 고민해봅시다. 그럼 저자는 해당 이야기를 왜 했을까? 해당 논문의 파이프라인을 잘 살펴보면, depth map은 pseudo labeling에 관여하며, 실제 객체 검출 시에는 RGB 영상을 활용합니다. 이는 다른 말로, depth map과 RGB 영상을 상호보완적으로 활용한다고 해석할 수 있습니다. 정말 depth가 모든 면에서 최고였다면, 객체 추론 시에도 depth 영상을 사용하는 편을 생각해볼 수도 있을텐데 말이죠 (억까일수도 있지만). 저자도 동일하게 설명합니다. 그 둘은 상호보완적인 정보를 가지고 있다고 설명하며, appearance detail이 known과 unknown을 구분 시에 특히 작은 크기의 객체에 대해선 더욱 상호보완적인 도움이 된다고 설명합니다.
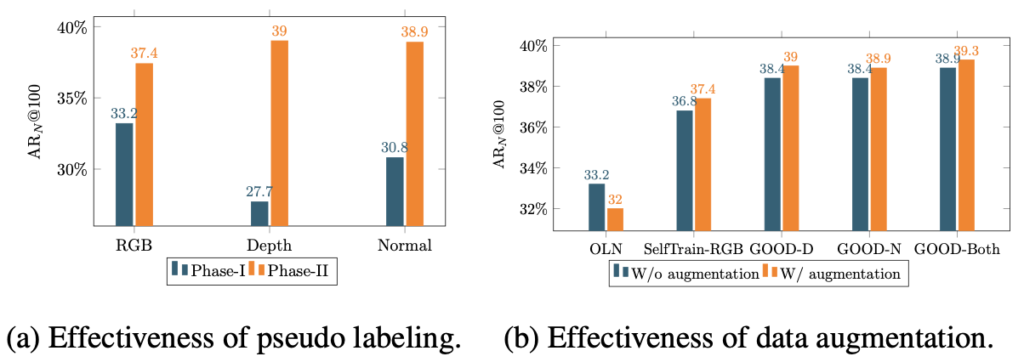
마지막은 일반적인 ablation study로 보이는 “(a) 왜 우리가 pseudo labeling을 선택한지”, “(b) pseudo labeling 시 bounding box가 noise로 작용될 수 있다면, 이를 어떻게 보완할지”에 대한 실험입니다. 표를 살펴보았을 때 (a)는 pseudo labeling 덕분에 Phase-II에서 성능 향상이 극적으로 높아짐을 (depth 만으로 AR@100이 많이 낮긴 하지만 얼추 나온다는 점도 흥미롭네요. 사실 저는 depth만으로 객체에 bounding box를 친다는 점은 상상도 하지 않았습니다) 보입니다. (b)는 augmentation이 noise bounding box에 대응할 수 있음을 보입니다. 다시, augmentation은 이미지를 변형합니다. 다양하게 변형된 이미지에 pseudo labeling을 진행할 때 noise가, noise가 아닐 수도 있습니다 (pseudo labeling 자체는 pretrained-frozen model을 사용하므로 해당 모델을 학습시키진 않습니다. 즉, 여기서 저는 “모델이 pseudo labeling을 잘 하도록 학습된다”는 표현을 사용하고 싶지 않았습니다). 그런 면 자체가 결국 일반성을 보장한다고 돌려 설명할 수 있습니다.
Conclusion

마지막으로 위의 RGB, depth map, normal map의 예시를 살펴보며 마치겠습니다. 해당 논문을 읽으며 새로운 인사이트를 얻기도 하였으며 또한 제가 몇번이나 극착하였듯 해당 논문의 과정이 정말 저자의 주장을 다양한 면에서 뒷받침하며, 글을 다 읽은 이후에는 해당 주장이 제게는 완전히 납득되었습니다. 아직은 연구실에서 해당 태스크에 대해 큰 관심을 보이는 분이 많이 없지만, 이 리뷰를 읽는다면 해당 논문을 읽어보는 것은 강력히 추천드리고 싶습니다. 논문에서 타인을 설득할때는, 이러한 이야기 과정이 정말 좋아보입니다. 제가 엑스리뷰를 작성한 이후 가장 자세히 읽고, 자세히 작성한 논문이 아닐까 싶습니다. 그럼, 리뷰마치겠습니다.
Appendix


논문 내 Top-k의 pseudo-label을 생성한다고 설명하였는데, 이에 대한 정성적 결과입니다. figure의 설명대로, known class bounding box (GT)와의 overlap을 제거한 bbox를 시각화하여 보였는데, known과 동시에 보였을 때 어떻게 pseudo-label bounding box가 생성되는지가 궁금합니다. Figure 설명에 보이는 바와 같이, 저자는 RGB에 비해 depth map과 normal map에서 비교적 큼직큼직한 객체가 pseudo-label로 생성된다 (RGB는 비교적 작은 크기의 pseudo-bbox를 생성)고 설명합니다.
리뷰 잘 보았습니다.
먼저 depth map을 proposal network에 태워서 pseudo label을 생성하게 되는데, 이때 Proposal Network가 학습을 해야하는 것으로 이해했습니다.
그렇다면 Proposal Network가 학습을 하는데 활용하는 Loss는 수식2인건가요? 그리고 이를 통해서 Unknown object에 대한 Pseudo label을 생성할 수 있게 되면 Phase2에서 Detector를 학습시킬 때는 수식1로 학습을 시키면 되는건가요?
아니면 단순히 Depth map을 입력으로 하고, 기존 GT를 통해서 known object에 대한 Proposal을 추론하도록 학습하는 것이고, 이렇게 생성된 pseudo label을 기존 GT와 함께 활용해서 (수식2를 통해) Detector를 class-agnostic하게 학습시키는 건가요?
만약 후자라면 Pseudo Label을 생성하는 과정에서 기존 GT와 겹치는 영역들은 제거한 뒤, 남은 Top-k개의 box들을 pseudo label로 활용한다고 들었는데 혹시 논문에서 pseudo label에 대한 정성적 결과는 없나요? 그림3에서는 아주 이상적으로 사람에 대한 GT가 있을 때 마차, 말에 대해 pseudo label을 생성하는 것처럼 그려놨는데, 실제로 구하는 방식을 보면 저렇게 이쁘게 pseudo label이 생성될 것 같지는 않아서요.
즉, 단순히 Depth map을 RPN에 태운 후 기존 GT box랑 안겹치지만 가장 유사한 박스를 고르는 방식이라면, GT box 주변부 박스들이 pseudo label로 마구잡이 잡힐 것 같은데.. 과연 예시 사진처럼 object에 대해 이쁘게 형성이 되는지 조금 걱정스럽네요.
안녕하세요 정민님. 리뷰 읽어주셔서 감사합니다.
depth map을 proposal network에 태울 때의 (학습할 때의) Loss는 수식 2가 맞습니다. 수식 2를 사용하는 이유는 (비록 이전 연구인 OLN에서 제안한 방법이나) pseudo-label 시 objectness score를 기반으로 proposals를 생성하기 위함입니다. – 이어서, Phase 2에서는 “아니면 단순히 ~”에 말씀해주신 바와 같이 GT와 pseudo-label을 동시에 활용하여 objectness score를 예측하도록 합니다 (수식-(2)).
다음 질문으로 후자일 시, Pseudo-label을 생성하는 과정에서 남은 Top-k개의 box에 대한 정성적 결과는 Appendix에서 확인할 수 있습니다. 제가 해당 논문에 관심이 있어 Appendix까지 읽었으나, Depth를 사용하는 이유에 대한 실험 결과를 중점으로 보이고자 해당 내용을 추가해놓진 않았습니다. 해당 내용을 포함하여 리뷰 글에 보이겠습니다. 이 때, 저또한 pseudo-bbox가 예쁘게 생성되진 않았을 것 같지만, 정성적 결과를 확인 시 depth map이 RGB와 비교 시 큼직큼직한 형상처럼 보여, GT에는 어쩌면 큰 영향을은안받을수도 있겠다 생각했습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
depth map을 일반적인 RPN 네트워크를 통과하여 pseudo box을 생성한다는 점이 매우 흥미로웠습니다. depth map을 중점으로 설명해주시며 normal map에 대해서도 동일한 과정을 거친다고 설명해주셨는데, 그렇다면 Figure 3에서 proposal network를 거쳐서 나온 pseudo box는 두 map에서의 결과를 모두 합친 것인가요 ? 두 map 모두 기하학적인 cue를 사용하기 위함은 맞지만 어쨌든 서로 다른 정보를 제공하고 있기 때문에 만들어지는 proposal이 다를 것 같은데, 이를 어떻게 처리해서 최종 pseudo box를 만드는지가 궁금합니다. 단순히 두 map에서 만들어지는 모든 proposal을 GT annotation에 추가하여 학습하게 되나요 ?
안녕하세요 건화님. 리뷰 읽어주셔서 감사합니다.
우선, Figure 3에서 proposal network를 거쳐 나온 pseudo box는 두 map에서의 결과를 합친 것일 수도 있고 (GOOD-Both), 한 가지만 사용한 경우도 있습니다 (GOOD-Depth, GOOD-Normal).
그렇다면 이 때의 궁금증이 GOOD-Both의 경우, top-k개의 pseudo-box를 어떻게 정하는지에 대한 질문으로 보입니다. 이는 각각의 pseudo-box에 대해 NMS를 한 이후, 나머지의 box들에 대해 단순히 objectness score가 높은 k개의 box만 남기는 방법을 사용합니다. (GOOD-Depth, GOOD-Normal과의 pair comparison을 위함입니다)
꼼꼼한 리뷰 잘 읽었습니다.
요즘 과제 제안서 작업 때문에 OWOD 관련 자료들을 조금씩 찾아서 읽는 중이라 그런지 아주 흥미롭네요.
———————————————-
우선 제가 이해한 것을 정리해보자면
=> 일반적인 detector에서 unknown class에 대해선 background로 예측하게 되는데, 이때 unknown이 background로 유도되지 않도록 OLN 등의 연구에선 loss를 기반으로 이를 해결하고자 함. (positive 에 대해서만 cls loss 계산)
=> 하지만 저자는 이런 loss적 측면과는 달리, 기존 연구들이 RGB만의 hight level feature에 overfitting 된다는 것을 문제삼음. 왜냐면 known과 unknown을 구분하기 위해 모델이 차이가 명확한 RGB apperance queue에만 너무 의존해서 일반성이 떨어지기 때문.
=> 따라서 모델의 일반성을 위해 추가적인 모달리티 도입?? (여기선 depth&normal map. known과 unknown과의 구분이 RGB 대비 불명확 하기 때문에 과적합 방지 및 일반성 확보?)
———————————————-
그리고 리뷰를 읽으면서 생긴 궁금증/질문이 몇개 있는데 한번 해보겠습니다.
1. (본 논문이 아닌 OWOD에 대한 근본적 질문이긴 합니다.) 이미지 내 unknown, 즉 background로 예측한 box에 대해 사람이 직접 class 정보를 annotation을 하는 것으로 알고 있습니다.(본 논문은 class-agnostic이기 때문에 예외이긴 하지만요.) 이때 한 이미지 내 bg box 중 보통 몇개를 annotation 하며, 어떤 기준으로 이를 수행하는지가 궁금합니다. 가령 i) bg boxes중 confidence를 기준으로 top-k개만을 수행한다거나, 혹은 ii) 사람이 직접 pred box를 시각화해보고 정말로 unknown object라면 annotation을 수행한다거나,,,
2. intro 부분에서 기존 owod 모델이 RGB의 high-level cue에 overfitting 된다는 부분에서 semantic==appearance==texture로 동일하게 표현이 된 것으로 보여집니다. 사실 제 기존 지식에 의하면 appearace==texture이지만 semantic은 앞선 둘과는 조금 결이 다른, 조금 더 클래스의 의미론적 정보를 담은 최상위 high level feature의 느낌이 강한 것으로 알고 있습니다.
여기서 말하는 high-level cue라는 것이 의미론적 정보가 아닌, 외형적인 high-level cue가 맞는거죠? 그렇기 때문에 depth&normal map을 도입한 것이구요..!
3. 일반적인 Detection 방법론, 대표적으로 SSD 에서는 어쨌든 background에 대해서도 고려를 하기 위해 1:3으로 hard negative mining을 하는 것으로 알고 있습니다. 그런데 리뷰를 읽어보니 OWOD에서는 unknown이 background로 유도되지 않도록 하기 위해 OLN 등에서 positive boxes에 대해서만 cls score loss를 계산하는 거 같은데,, 그럼 이런 OWOD 에서는 background에 대한 학습 및 고려를 전혀 하지 않아도 모델 입장에서 상관이 없는건가요??
음 질문을 하고 보니 본 논문에 대한 질문보다도 OWOD 자체에 대한 질문이 더 많은거 같기도 하네요..ㅎ 하지만 상인님이라면 잘 답변해 주실 것이라 믿습니다 ^^.
다시한번, 리뷰 잘 봤습니다.
안녕하세요. 이상인 연구원님. 좋은 리뷰 감사합니다. 평소에 전혀 생각해 본 적 없는 주제인데, saturated task의 이후 발전 방향에 대해 생각을 해 볼 수 있는 계기였습니다. RGB cue에 대한 단점을 이전에는 생각해 본 적이 없는데, low,mid-level feature 정보가 부족하다는 것을 생각하지 못했네요. 질문 하나 남기겠습니다
depth map 이외에도 다른 input도 고려해 볼 수 있을 것 같다는 생각이 드는데, 다른 domain에 대한 언급은 없었나요? depth map 이외의 input을 추가적으로 고려해 볼 수 있는지 궁금합니다.
감사합니다.
안녕하세요! 좋은 리뷰 감사합니다.
논문 중 RGB cue에만 overfitting된다고하는데, 이는 어떻게 해석할 수 있을까요? overfitting된다는 것이 RGB 정보가 비슷한 객체들은 비슷한 카테고리로 분류될 수 있다는 말과 같은 의미일까요??
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
GOOD 자체가 Open-World 세팅을 염두에 둔 방법론이기 때문에 depth와 normal로부터 unknown object에 대한 proposal을 생성한 뒤 클래스는 지정할 수 없는 것이죠? 그렇다면 이 proposal들은 뒤 Phase 2에서 Object Detector에 들어가게 되는데, 여기에서 말하는 Object Detector는 base class는 그대로 학습하고, depth와 normal로 뽑은 박스들은 그냥 obj score만 높이도록 학습되는 것인가요?