안녕하세요. 백지오입니다.
서른 한번째 X-REVIEW는 BERT, GPT, LLaMA를 중심으로 한 LLM 리뷰를 해보고자 합니다.
오늘날 거대 언어 모델(Large Language Models; LLM)은 기술의 최첨단부터 일반 사용자까지 사회 전반에 영향을 주고 있습니다. ChatGPT의 사용자수는 이제 1억 8천만 명에 달하며, CVPR 2024에 accept된 논문 중 LLM 관련 단어가 제목에 들어간 논문만 40편에 달합니다. NVIDIA의 CEO 젠슨 황은 한 인터뷰에서 2023년 AI 분야의 가장 큰 성과가 LLaMA2라고 발언하기도 했습니다.
이제 더 이상 “내 연구분야와는 다른 분야니까”라고 치부하기에는 LLM의 영향력이 커지고 있는만큼, 지금까지 LLM의 발전을 간단히 되짚어보고, CloseAI 형태로 전환한 GPT를 대체할만한 오픈소스 LLM인 LLaMA를 정리해 보도록 하겠습니다.
본 글은 Zhao et al.의 A Survey of Large Language Models을 비롯하여 여러 논문, 포스트들을 기반으로 작성하였으며, 출처는 글 하단에 표기하도록 하겠습니다.
Pretrained Language Models (PLM)
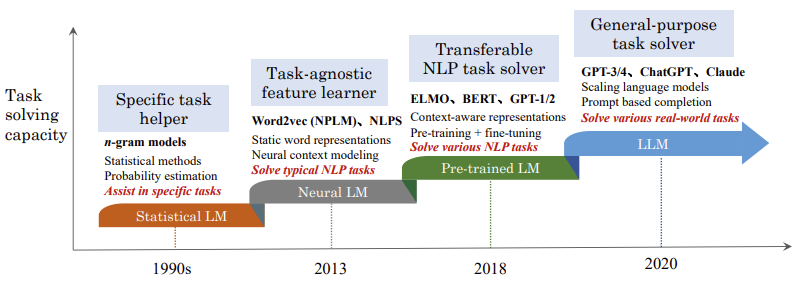
거대 언어 모델과 중규모/소규모 언어 모델을 나누는 기준이 무 자르듯 깔끔하게 정의되어 있지는 않지만, 학계에서 대규모 언어 모델이라는 표현을 널리 사용하기 시작한 것은 GPT-3가 등장한 2021년경으로 보입니다. 본격적으로 LLM을 살펴보기에 앞서, GPT-3와 같은 LLM의 기반이 된 사전 학습 언어 모델(Pretrained Language Models; PLM)을 살펴보겠습니다.
2017년, Google에서 개발한 트랜스포머는 기존에 자연어 처리(Natural Language Processing; NLP) 모델들이 사용하던 RNN, LSTM 등의 구조 대비 월등한 성능을 보여주었습니다. 특히, 기존 딥러닝 방식의 큰 한계 중 하나였던 포화(saturation) 문제에 트랜스포머가 굉장히 강건하다는 것이 밝혀짐에 따라, 기존에는 불가능했던 대규모 사전학습 모델의 개발이 가능해졌습니다.
Generative Pre-Training (GPT-1)은 2018년 OpenAI에서 발표한 PLM으로, 트랜스포머의 디코더만으로 구성된 사전학습 모델입니다. 트랜스포머 디코더는 입력 데이터를 이용하여 뒤에 이어질 단어(토큰)를 예측하게 되는데, GPT-1은 이러한 Next Word Prediction 방식을 활용하여 8억 개의 단어를 가진 BooksCorpus 데이터셋에서 사전학습되었습니다.
Bidrectional Encoder Representations from Transformers (BERT)는 2019년 구글이 발표한 PLM으로, GPT와 반대로 트랜스포머의 인코더만으로 구성된 사전학습 모델입니다. BERT는 텍스트 데이터에서 일부 단어를 마스킹한 후 마스킹된 단어가 무엇인지 복원하는 Masked Language Modeling (MLM)과 주어진 문장에 이어질 다음 문장을 예측하는 Next Sentence Prediction 두 가지 task를 통해 자기지도학습(Self-Supervised Learning; SSL) 방식으로 사전학습을 진행하였습니다.
MLM task는 주어진 텍스트 데이터에서 랜덤 하게 일부 단어를 마스킹하여 입력 데이터로 사용하고 마스킹되지 않은 원본 데이터를 정답 데이터로 사용하며, Next Sentence Prediction 역시 두 개의 연속된 문장 중 앞의 문장을 입력, 뒤의 문장을 정답 데이터로 사용하므로 사람에 의한 라벨링 작업이 요구되지 않는 자기지도학습 방식으로 학습을 수행할 수 있습니다. 이를 통해 BERT는 8억 개의 단어를 가진 BookCorpus와 25억 개의 단어를 가진 Wikipedia 데이터를 활용해 사전학습을 수행할 수 있었으며, 이 과정에서 자연어에 내재된 다양한 패턴을 스스로 학습할 수 있었습니다.
이렇게 사전학습된 GPT-1이나 BERT를 풀고자 하는 자연어 task에 맞게 미세조정(fine tuning)하여 활용함으로써, 다양한 NLP task에서 높은 성능을 달성할 수 있었습니다.
GPT-2. 앞선 GPT-1 모델 공개로부터 얼마 지나지 않은 2019년, OpenAI는 GPT-2를 공개하였습니다. GPT-2의 목적은 다른 task를 수행하기 위해서는 미세조정을 거쳐야만 하는 기존 PLM의 한계를 극복하여 사전학습만 진행된 상황에서도 다른 task를 수행할 수 있는 모델을 개발하는 것이었습니다.
먼저, 특정 task를 수행하기 위한 출력 계층을 설계하고 미세조정하는 대신, task가 무엇인지 입력 단계에서 자연어로 지시하는 질의응답(Question Answering) 방식의 task conditioning 방식을 적용하였습니다. 기존 방법들이 영-한 번역 모델은 영-한 번역만, 요약 모델은 요약만 수행할 수 있는 형태였다면, GPT-2는 (“I love coffee”, “영-한 번역”)과 같이 입력 데이터와 수행하고자 하는 task를 함께 입력하여 다양한 task를 수행할 수 있는 것이죠. 이때부터 우리가 흔히 아는 ChatGPT와 같은 대화형 인공지능의 면모가 보이기 시작한 것 같네요.
저자들은 GPT-2가 최대한 다양한 task에서 작동할 수 있도록 인터넷에서 수집하고 사람들이 필터링한 WebText 데이터셋을 이용해 학습을 진행하였으며, 모델과 데이터셋을 깃허브를 통해 공개하였습니다. [코드] [데이터셋]
Large Language Models (LLM)
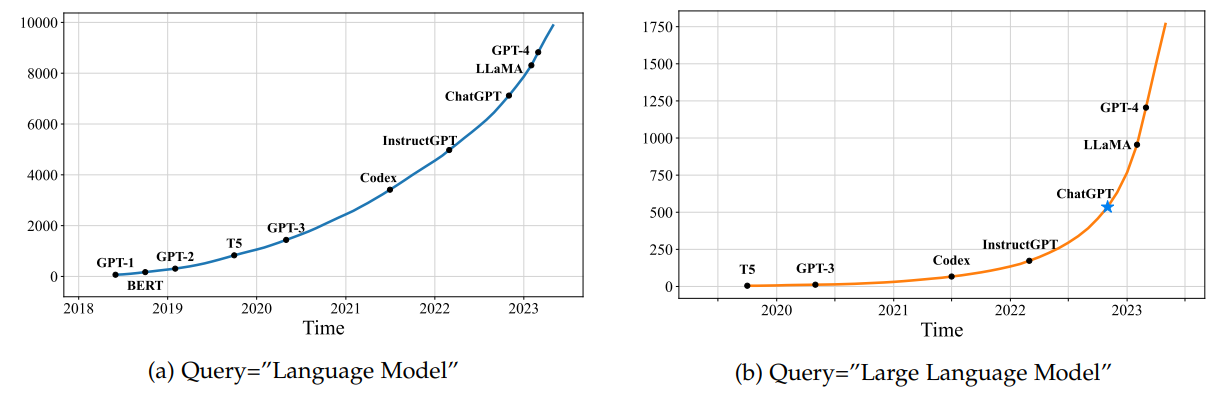
LLM이 본격적으로 주목을 받기 시작한 것은 GPT-3가 등장한 2020년 전후입니다. 당시에 SNS 상에서 GPT-3의 API가 유출되었다던가, 우회적으로 사용할 수 있다던가 하는 이슈가 하루가 멀다 하고 터졌던 기억이 나네요. 당시에 작성한 제 GPT-3 체험글도 지금보니 추억이 새록새록합니다. 아무튼, LLM의 발전사를 본격적으로 살펴봅시다.
GPT-3는 2020년 5월 28일에 공개되었습니다. GPT-2 대비 100배 이상 많은 하이퍼파라미터를 가진 GPT-3는 번역, 코딩, 작문 등 굉장히 다양한 task를 미세조정 없이 zero-shot으로 수행할 수 있었습니다.
GPT-3는 기본적으로 GPT-2와 같은 구조를 사용하되, 변형된 초기화 기법, 사전 정규화, dense/locally banded sparse attention과 같은 기법들을 추가로 적용하고, 모델의 크기를 훨씬 크게 설계하였습니다. GPT-2가 15억 개의 파라미터를 가졌던 반면, GPT-3는 1750억 개의 파라미터로 구성됩니다. 늘어난 크기만큼이나 학습 데이터도 더 요구되었는데, 인터넷에서 크롤링된 Common Crawl 데이터 4100억 개, WebText2 데이터 190억 개, Books 데이터 670억 개, Wikipedia 30억 개의 토큰으로 학습했다고 합니다.
이를 통해 GPT-3는 in-context learning을 수행할 수 있게 되었는데요. 앞서 GPT-2가 수행하고자 하는 task를 명시적으로 입력받아 다양한 task를 미세조정없이 풀고자 했다면, GPT-3는 아예 입력된 텍스트의 맥락을 통해 적절한 응답을 생성하는 수준으로 더 발전하였습니다. 예를 들어 “사과 -> apple, 포도 -> grape, 바나나->?”라고 입력해 주면 GPT-3는 맥락상 생성해야 할 응답이 마지막 단어의 영-한 번역 결과인 banana임을 알 수 있는 것이죠.
OpenAI는 GPT-3가 범죄에 악용되는 등의 잠재적 위험이 있다고 경고하며, GPT-3부터는 LLM의 코드와 데이터셋을 비공개하기로 결정하였습니다. 따라서 GPT-3 이후의 모델들은 OpenAI에서 공개하거나 유출된 내용로 세부 구조를 추측할 수 있을 뿐, 정확한 구조를 알 방법이 없습니다.
LLMs after GPT-3
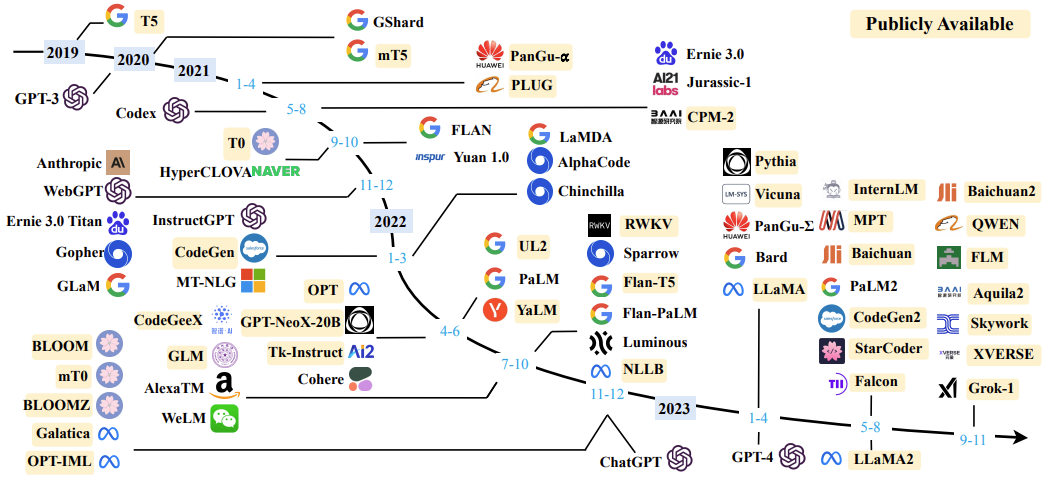
한편 GPT-3가 등장하며 LLM이 가진 잠재력이 점차 알려짐에 따라 수많은 LLM이 개발되기 시작했습니다. 특히, 학습 데이터의 주류 언어나 도메인에 따라 성능이 달라지는 LLM의 특성에 따라 네이버의 HyperCLOVA와 같이 기업 수요에 따른 다양한 LLM이 개발된 것을 알 수 있습니다.
특히 LLM의 높은 학습 비용에 따라 수많은 오픈소스 LLM이 등장하였습니다. GPT-3의 학습 비용은 약 400만 달러 ~ 1500만 달러로 추정되는데, 이는 도저히 대학 연구실이나 개별기업에서 감당할 수 있는 비용이 아닌 만큼 오픈소스 LLM을 개발하여 연구를 활성화하고자 한 것이죠.
LLaMA
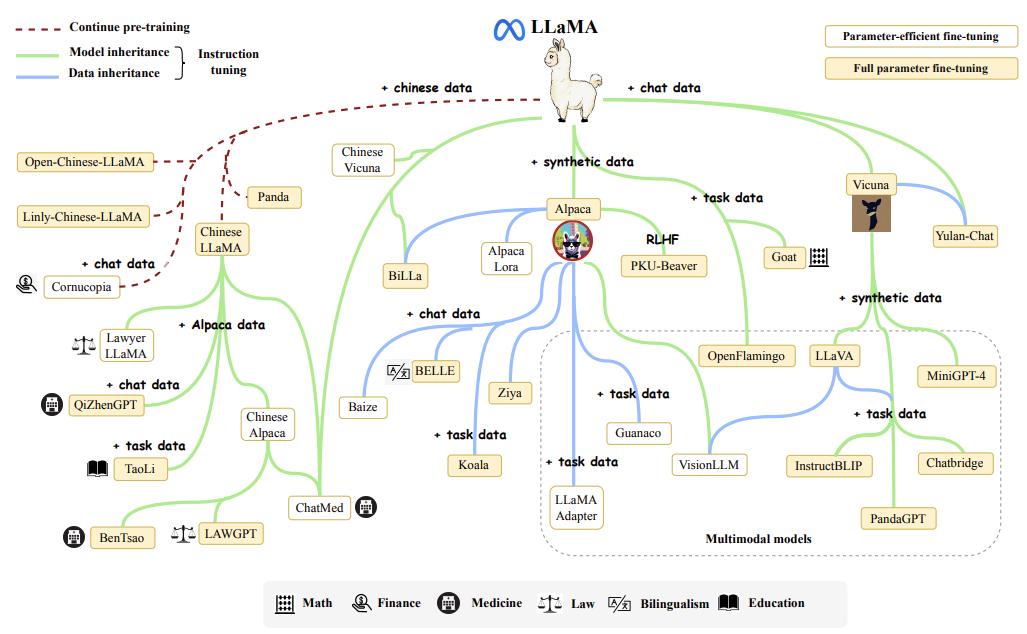
대표적인 오픈소스 LLM이 바로 Meta에서 개발한 LLaMA인데요, LLaMA는 누구나 접근 가능한 공개 데이터셋으로만 학습하고, 소스코드와 사전학습 가중치가 공개되어 있어 자원만 허락한다면 충분히 학습부터 활용까지 가능합니다. LLaMa는 첫 버전이 2023년 2월, 버전 2가 2023년 7월에 공개되어 굉장히 빠른 속도로 발전하고 있습니다. 아래 이미지를 보면, LLaMA에서 비롯된 다양한 후속 연구들을 볼 수 있습니다.
LLaMA 1과 2는 각각 70억개에서 650억 개, 70억 개에서 700억 개의 파라미터로 구성된 LLM인데요. 이는 GPT-3의 1750억 개에 비해 훨씬 적은 수임에도 불구하고, 대부분의 벤치마크에서 LLaMA 1-13B가 파라미터가 10배 이상 많은 GPT-3을 앞서는 모습을 보여줬다고 합니다. 참고로 LLaMA 모델 중 가장 큰 크기의 LLaMA 2-70B의 경우 추론 시 약 140GB의 GPU memory가 요구되는데 이는 개인용 GPU에서는 감당하기 힘든 수준이지만 연구용 워크스테이션에서는 충분히 감당할 수 있는 크기이며, 양자화를 통해 메모리 사용량을 줄이면 하이엔드급 개인용 GPU에서도 활용 가능한 수준입니다. LLM을 로컬 환경에서 사용할 수 있는 것이죠. 그럼 LLaMA 1과 2를 각각 살펴봅시다.
LLaMA 1은 English CommonCrawl, C4, Github, Wikipedia, Gutenberg and Books3, ArXiv, Stack Exchange 데이터에서 학습되었으며, 이는 토큰 수로는 총 1조 4천억개에 달합니다. 학습에는 GPT3의 pre-normalization, PaLM의 SwiGLU 활성화 함수, GPTNeo의 Rotary Positional Embedding 기법을 활용하였고, 최적화는 AdamW optimizer로 진행하였습니다. 또한, 학습 과정을 최대한 효율적으로 만들기 위하여 선형 계층의 출력과 같은 활성화 값들을 저장해 두고, 역전파 시에 이를 다시 계산하지 않도록 하는 등의 테크닉을 활용했는데, 이를 위해 pytorch의 역전파 함수를 활용하지 않고 역전파 함수 자체를 새로 짰다고 합니다. 이러한 최적화를 통해 LLaMA 1-65B 모델을 학습하는 과정에서 초당/GPU당 380개의 토큰을 처리할 수 있었고, 2048개의 A100 GPU w/ 80GB RAM에서 21일간 학습을 수행하였습니다. 역시 학습은 스케일이 어마어마하네요.
Pre-normalization (GPT-3): 각 트랜스포머 계층의 입력을 normalize하여 학습을 안정화하는 기법
SwiGLU 활성화 함수 (PaLM): Swish 활성화 함수와 GLU 활성화 함수를 결합한 활성화 함수입니다. 자연어 분야에서는 널리 쓰이는 활성화 함수라고 합니다.
Rotary Positional Embedding (GPT Neo): 기존 트랜스포머의 삼각함수 기반 PE과 같이 절대적인 PE가 아니라, 각 토큰 간의 상대적 거리를 고려하는 Relative Positional Embedding 방법이라고 합니다.
LLaMA 1은 파라미터의 수에 따라 6.7B, 13B, 32.5B, 65.2B의 네가지 버전이 존재하는데, 각각의 모델은 GPU가 1개, 2개, 4개, 8개 요구된다고 합니다. 이 중, 가장 작은 6.7B 모델은 단일 V100에서 돌아간다고 하니 V100 유저로서 굉장히 매력적입니다.
LLaMA 2는 LLaMA 1에 비해 40% 가량 증가한 2조 개의 토큰으로 학습하고, 기억할 수 있는 Context의 길이는 4K로 2배 증가한 LLM입니다. 파라미터 수에 따라 7B, 13B, 70B 세 가지 버전이 존재하며, Grouped-Query Attention을 추가로 적용하여 성능을 개선하였다고 합니다. LLaMA 1 공개 후 채 6개월이 지나지 않은 시점에 공개된 만큼 규모 이외에 차이점이 많지는 않은 것 같습니다.
Grouped-Query Attention: Multi-Head Attention -> Multi-Query Attention에서 이어지는 어텐션 기법으로, 추론 속도를 향상할 수 있는 기법 중 하나입니다. MHA에서는 Query, Key, Value를 각각 head의 수만큼 쪼개어 만든 후 합쳤는데, 이후에 메모리 대역폭을 절약하고자 MQA가 제안되었습니다. MQA는 쿼리만 head 수만큼 만들고 Key와 Value는 하나만 만들어서 어텐션을 수행합니다. 따라서 메모리는 절약되지만 그만큼 성능이 저하되는 이슈가 있습니다. GQA는 MHA와 MQA의 타협(?)점으로 여러 개의 Key와 Value를 사용하되 head의 수보다는 적게 사용합니다. 아래 그림을 보면 직관적으로 이해할 수 있습니다.
LLaMA v.s. GPT
결국 연구자인 우리에게 있어 중요한 것은, 내 연구에서 어떤 LLM을 활용할 수 있을까, 어떻게 활용할 수 있을까입니다. 이름만 OpenAI가 만든 고성능 유료 모델인 GPT-4와 성능이 조금 아쉽지만 오픈소스이며, 로컬에서 실험이 가능한 LLaMA를 비교해 봅시다.
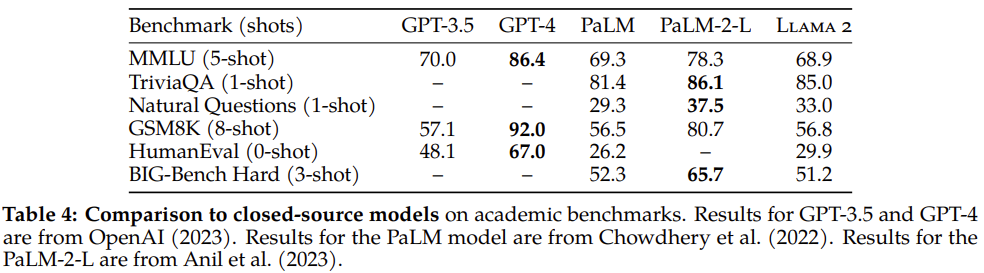
OpenAI의 GPT와 Google의 PaLM, 그리고 LLaMA 2를 비교한 표입니다. 학계에서 LLM을 평가하는데 흔히 사용되는 지표들을 담았다고 하며 각각은 아래와 같습니다.
- MMLU: 여러 가지 능력을 종합적으로 평가하는 벤치마크
- TriviaQA: World knowledge를 평가
- Natural Questions: World knowledge를 평가
- GSM8 K: 수학(math) 능력
- HumanEval: 코딩
- BIG-Bench Hard: 여러 가지 능력을 종합적으로 평가하는 벤치마크
사실 각 수치보다도 LLaMA가 GPT-3.5에도 아직 미치지 못한다는 점이 조금 아쉬운 것 같습니다. GPT-3.5 기반의 ChatGPT를 사용하면서 아쉬운 점들이 많았는데, LLaMA가 그보다 조금 못한 수준이라는 의미니까요.
한편 요구 성능의 측면에서 보면, LLaMA는 어느 정도 장점이 존재하는 것 같습니다. GPT와 같은 고성능 LLM이 모두 API 형식으로 요금을 지불해야 하는 반면, LLaMA 2-70B는 로컬 환경에서도 충분히 사용할 수 있으니까요. 4-bit 양자화를 거친 LLaMA 2-70B는 37.6 GB의 VRAM만 있으면 추론을 수행할 수 있습니다. Full precision으로 활용하거나 파인튜닝을 진행하려면 꽤 높은 사양이 요구되지만, 추론을 수행할 수 있다는 것만 해도 Frozen 상태로 모델에 넣을 수 있다는 얘기니 나름 의미가 있는 것 같습니다.
다만 결국 4-bit 양자화 과정에서 성능이 더욱 희생되므로, 높은 성능이 요구되고 forward를 많이 진행하지 않아도 되는 경우에는 GPT를 유료로 사용하고, 여러 번의 실험을 진행해 보거나 아예 모델 구조 안에 LLM을 넣고자 한다면 LLaMA를 고려하면 될 것 같습니다.
결론
이번 리뷰에서는 LLM의 발전사와 연구 관점에서 LLaMA와 GPT의 비교를 수행해 보았습니다. LLM의 성능이 빠르게 발전하면서, 간단하게는 데이터 증식부터 프롬프팅 등 정말 다양한 곳에 활용되는 것 같습니다.
이번 리뷰를 작성하면서 생각 이상으로 다양한 LLM이 존재한다는 것과, 기술의 발전이 정말 빠르다는 것을 새삼 다시 실감한 것 같습니다. 벌써 올해 11월에 GPT-5가 나온다는 소문이 돌던데, 넋 놓고 있다가는 정말 기술에 뒤처질 것 같으니 앞으로도 틈틈이 follow up 해야겠습니다.
감사합니다.
참고자료
- 논문
- Zhao et al., “A Survey of Large Language Models“, arxiv 2023
- Radford et al., “Improving Language Understanding by Generative Pre-Training“, 2018
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding“, arxiv 2019
- Radford et al., “Language Models are Unsupervised Multitask Learners“, 2019
- Brown et al., “Language Models are Few-Shot Learners“, 2020
- Touvron et al., “LLaMA: Open and Efficient Foundation Language Models“, 2023
- Touvron et al., “LLAMA 2: Open Foundation and Fine-Tuned Chat Models“, 2023
- 포스트
좋은 리뷰 감사합니다.
안그래도 최근 비디오도 함께 엮여있는 LLM을 찾아보다가 23년도부터 현재까지 거의 20개에 육박하는 모델이 쏟아져 나온 것을 보고 깜짝 놀란적이 있어 더욱 재밌게 읽었던 것 같습니다. 리뷰에 첨부해주신 그림에도 확실히 23년도 중후반부터 다양한 기업에서 많은 모델을 공개하고 있는 것 처럼 보이네요.
이전에 읽었던, 거대 모델을 활용하는 논문에서 LLaMa의 in-context learning 능력이 gpt보다 뛰어나다는 주장을 본적이 있는데, 혹시 이에 대해 살펴보신 내용이 있으신가요? 그리고 LLM의 사전학습 과정 중 in-context learning과 같이 prompt를 주고 뒷내용을 맞추는 과정이 pretext task로 포함되어있는 것인지도 궁금합니다. 그런 것이 아님에도 in-context learning을 잘 수행하는 것이었다면 정말 대단하다는 생각이 듭니다.
나중에 여유가 되면 같이 비디오를 입력받는 LLM에 대해서도 함께 서베이할 수 있었으면 좋겠습니다.
안녕하세요. 김현우 연구원님.
정확히 “LLaMa가 GPT보다 in-context learning 능력이 뛰어나다”라는 서술은 보지 못하였으나, LLaMa가 동일한 크기의 GPT-3보다 성능이 좋다는 것과 같은 맥락으로 생각됩니다. LLaMa에서 특별히 in-context learning을 위해 추가로 제안한 loss는 없습니다. 기존에 GPT와 같은 모델에서 널리 사용한 방식과 같이, 어떤 입력이 주어졌을 때 이어질 단어를 예측하는 방식으로 학습을 진행하였습니다.
다만 GPT가 좋은 성능을 내기 위해 모델 크기를 키운 반면, LLaMa는 GPT-3보다 더 많은 학습 데이터를 사용하고, GPT 뿐 아니라 PaLM, GPTNeo 등에서 사용한 기법들을 추가로 적용하여 같은 크기에서 더 좋은 성능을 보였습니다.
멀티모달 LLM 서베이… 좋습니다! ㅋㅋ
감사합니다.
안녕하세요 지오님 좋은 리뷰 감사합니다.
LLM이 말그대로 large 모델임에도 불구하고 LLaMA는 오픈소스로 공개되어있다는 점과 LLaMA의 작은 버전은 단일 GPU 1개만으로도 학습이 가능한 것이 굉장히 매력적으로 느껴지네요. LLaMA의 구조 또한 GPT와 마찬가지로 Decoder를 쌓은 구조인가요? 또 GQA 즉 Grouped-query attention에 대해 설명해주셨는데 multi-head attention에 비하면 메모리는 절약되지만 성능이 저하될 것같은데 어째서 GQA를 추가로 적용하는 것이 성능이 개선되는 것인지 궁금합니다.
감사합니다.
안녕하세요. 박성준 연구원님.
네, 세부적인 구조(MLP 노드 갯수 등)에는 차이가 있겠지만 LLaMA도 Decoder를 적층한 구조입니다.
GQA 관련해서는 성능이라는 표현으로 인해 혼란을 드린 것 같습니다. GQA로 개선된 성능은 메모리 사용량과 연산 속도를 의미합니다.
말씀하신 것처럼 GQA를 사용하게 되면 MHA에 비해 메모리 사용량과 연산량은 크게 감소하지만, 동시에 정확도와 같은 성능은 조금 하락할 수 있습니다. 다만 GQA 논문을 보면, 성능 하락을 감수하더라도 거의 MHA에 준하는 성능을 보인다고 합니다. 그래도 성능 하락이 있기는 해서인지 LLaMA2에서는 모델 중 가장 크기가 큰 2개 버전에만 GQA를 적용한 모습입니다.
감사합니다.
안녕하세요 지오님. 좋은 리뷰 감사합니다.
RCV 합류 후 첫 X-review 댓글을 지오님 리뷰로 달게 되었습니다.
저는 LLM에 대해 어느 정도의 관심만 있었으나 직접 논문을 찾아보지는 못하고, 블로그 글만을 스치듯 읽어본 것이 전부였었는데,
지오님이 정리해주신 리뷰를 토대로 LLM이란게 어떤 흐름으로 발전되어 왔는지 큰 흐름에서의 마일스톤을 짚어볼 수 있어서 좋았던 것 같습니다.
사실 리뷰를 읽고도 아직은 굵직한 흐름만 이해했을 뿐이고, 이제 막 논문읽기에 천천히 발을 들이고 있는 중이라 아직 모든 논문을 follow up 하지 못해 깊이 있는 이해가 부족합니다.
그리하여 궁금한 것이 하나 생겨 질문 남깁니다.
Benchmark 지표들에서 여러 지표들이 있었는데, 여기서 사용되는 shot들의 숫자가 정확히 어떤 것을 의미하는 지 궁금합니다.
감사합니다.
안녕하세요. 이재찬 연구원님.
첫 리뷰로 골라주셔서 감사합니다. 🙂
벤치마크에 적혀있는 shots는 few-shot learning에 관련된 단어입니다. few-shot learning이란, 어떤 사전학습된 모델을 새로운 task에 적용할 때, 대량의 데이터가 아닌 적은(few) 양의 데이터를 사용해 fine-tuning하면서도 좋은 성능을 내고자 하는 task인데요. 이때, 사용되는 데이터의 양을 shot으로 정의합니다. 예를 들어, 클래스가 100개 있는 분류 데이터로 few-shot learning을 하고자 할 때, 클래스별로 5개의 샘플을 학습에 사용하여 총 500개의 데이터를 학습에 사용하면, 5-shot 이라고 부르게 됩니다.
위 벤치마크의 경우 NLP task들에 관련된 부분이라 저도 shot이 정확히 어떻게 정의되는지는 모르지만.. 어떤 지표에 shot이 등장한다면 이 모델이 적은 데이터만 가지고도 새로운 task에 잘 적용될 수 있는가 하는, 일반화 성능을 평가하고자 하는 것이라 생각할 수 있습니다!
감사합니다.
안녕하세요, 백지오 연구원님. 좋은 리뷰 감사합니다. NLP 및 LLM에 대한 이해가 필요하다고 느끼고 있었는데, 잘 정리된 글을 작성해주셔서 흐름을 파악할 수 있었습니다. 재밌게 읽었네요.
질문 하나 남기겠습니다. 성능 비교 면에서 다양한 벤치마크를 보여주셨는데, 각각이 대충 어떤 능력을 측정하고자 하는지는 알겠지만 구체적으로 어떻게 성능을 측정하는지 감이 잡히지 않습니다. 해당 모델들은 결국 언어 생성 모델인데, 언어 생성 모델들의 성능은 어떻게 측정하게 되나요?
감사합니다.
안녕하세요. 허재연 연구원님.
저도 자연어 처리 분야의 평가지표까지 관심깊게 살펴보지는 않아 정확한 설명을 드리기는 어렵습니다만, 위 논문에서 리포팅한 성능은 자연어 생성 모델의 여러 측면을 평가하는 벤치마크 점수인 것으로 알고 있습니다. 예를들어, MMLU는 Massive Multitask Language Understanding이라는 데이터셋에서 다양한 다지선다 문제를 푼 결과를 나타낸다고 하네요.
찾아보니 대부분의 벤치마크가 QA의 형식을 취하고 있는데, 각 벤치마크가 어떤 질문으로 이루어져있는지가 모델의 성능을 가늠하는데 중요할 것 같습니다.
감사합니다.