Before Review
오늘은 Temporal Action Localization 논문인데 처음으로 Low/Few Shot 세팅의 논문을 읽어 보게 됐습니다.
해당 논문의 저자가 Temporal Action Localization 관련해서 좋은 연구를 많이 했는데 정말 아쉬운 게 코드를 공개해주지 않아 슬프네요…
리뷰 시작하도록 하겠습니다.
Introduction
Temporal Action Localization은 길이가 긴 비디오 내에서 action이 발생하는 구간을 찾아 내는 것이 목적인 연구 입니다. 기본적으로 Temporal Action Localization은 고정된 action category 만 대응할 수 있도록 연구가 되어 왔습니다. 하지만 연구가 고도화 되고 어느 정도 closed set 상황에서는 성능이 잘 나오다 보니 연구자들은 조금 더 어려운 연구를 하기 시작했습니다.
바로 Open-World Temporal Action Localization 입니다.
학습 때 사용했던 category 뿐 아니라 추론 단계에서 처음 보는 Category에 대해서도 unseen이라는 category로 올바르게 예측을 할 수 있는 연구입니다. 일반적으로 Real World에 등장하는 모든 상황을 학습 데이터에 미리 가정을 할 수 없습니다. 따라서 연구자들은 학습 데이터 구축에 어려움을 인정하며, 좀 더 일반적인 학습 모델을 구현하기 위해 Open-World Problem에 집중하기 시작했습니다.
Open-World Problem은 비단 Temporal Action Localization 뿐 아니라 다양한 Image/Video Understanding 연구들의 관심을 받고 있습니다. 지난번에 리뷰 했던 [ACM MM 2023] Open-Vocabulary Object Detection via Scene Graph Discovery 역시 Object Detection 상황에서 Train / Test의 다른 분포를 인정하며 대응할 수 있는 연구 였습니다.
Temporal Action Localization 상황에서 Open-World Detection은 주로 Cross-Modal Retrieval 방식으로 진행 되어 왔다고 합니다. 예를 들어 학습 때 보지 못한 Category에 대해서는 “an action video of [Class]” 이렇게 caption을 생성하고 이 caption과 가장 유사한 구간을 찾아내는 방식으로 진행 되었습니다.

하지만 이러한 접근 방식은 Category 단어에 대한 모호함이 존재했습니다. 위의 그림 처럼 Fencing이란 단어는 action category에 해당하는 단어 인데, 실제로 날카로운 검으로 상대방을 찌르는 의미도 있지만 단순히 담장을 치는 의미도 있습니다. 결국 하나의 단어는 다양한 의미를 가지기 때문에 모호함을 가진다는 것이죠.
기존의 연구들은 “an action video of [Class]” 이렇게 단순하게 text 정보를 처리해 버리기에 한계가 존재했습니다.
저자는 이러한 문제를 극복하기 위해 LLM을 이용하여 더 자세한 정보를 추출할 수 있는 자동화된 파이프라인을 구축했습니다. 예를 들면 LLM을 이용하여 “What tools are needed for [skiing]?” 에 대한 답변(ski board, ski stick, ski gogles, helmet)을 prompt로 사용하는 것이죠. 이런 LLM의 답변은 별다른 annotaion cost 없이 추가적인 학습 시그널을 제공합니다. 단순하게 category name만 사용하는 것이 아니라 category name과 human action의 특성을 조합하여 다양한 질문들을 LLM에게 던지고 더 많은 정보를 취하는 것이죠.
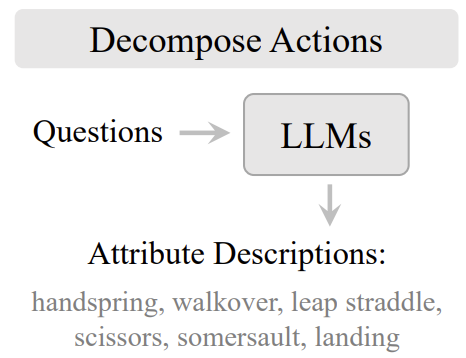
하지만 이렇게 LLM을 이용해도 조금 애매한 상황이 발생할 수 있다고 합니다. 명확하게 예시를 들어주지는 않았지만 아마 실험하다가 이런 경우가 있었나 봅니다. 조금 더 학습을 고도화 하기 위해 저자는 prompt를 LLM을 이용해서 만드는 것 뿐 아니라 RGB/Flow 데이터에서도 추출하여 좀 더 instance-specific한 prompt vector를 생성한다고 합니다.

그래서 위의 그림을 보면 왼쪽의 경우에 기존 연구들의 프레임 워크이며 오른쪽의 그림이 저자가 제안하는 프레임 워크 입니다. 결국 핵심은 Vision-conditional prompt Tuning과 LLM을 이용한 Attribute Description을 활용하여 좀 더 풍부한 정보를 CLIP Text Encoder에 입력으로 넣어주고, RGB 뿐 아니라 Flow에 대한 Representation 도 같이 Align을 맞추는 것이라 볼 수 있습니다.
간단한 소개는 끝나고 이제 제안하는 방법론에 대해서 살펴보도록 하겠습니다.
Method
Problem Scenario

원래라면 Problem Definition과 같은 부분은 생략하는데 최근에 새로운 연구원들이 합류를 했으니 한번만 더 다뤄보도록 하겠습니다. 기본적으로 T_{i}의 프레임을 가지는 비디오가 N개 존재하는 상황에서 TAL의 목적은 프레임 단위의 action category를 잘 예측하는 것이 목적입니다.
이 때 우리는 Open-World Problem을 해결하고 있으니 Zero shot/Few Shot을 고려해야 합니다. 기본적으로 Zero shot은 학습 데이터와 추론 데이터 간의 교집합이 없고 Few Shot은 부분적으로 겹친다고 보시면 됩니다. Closed Set은 학습 데이터와 추론 데이터가 완전하게 같다고 보시면 됩니다.
Architecture
RGB Frame Encoder의 경우 가장 기본적인 세팅으로 I3D RGB와 CLIP Image Encoder를 사용했다고 합니다.
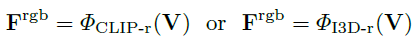
Flow Encoder는 역시 기본적인 세팅으로 TV-L1을 사용했다고 합니다.
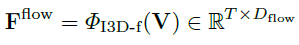
여기서는 그냥 notation만 참고하시면 될 거 같습니다.
그리고 다음으로 Temporal Aggregation Module 입니다. 저는 여기서 조금 놀랐는데 약간의 디테일이 있더라구요. 기본적으로는 Transformer Encoder Layer를 연속적으로 태워서 사용한다고 합니다. 하지만 action 마다 길이가 다양하게 존재하기 때문에 기존 연구들은 multi scale pyramid 구조를 활용한다고 합니다.
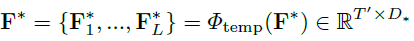
L은 레이어의 갯수 입니다. 그리고 이 구조에서는 레이어를 통과할 때 마다 Temporal length를 절반으로 줄인다고 합니다. 깊은 레이어에서는 long action에 집중하고 얕은 레이어에서는 short action에 집중하기 위함이라고 합니다. 따라서 i 번째 레이어 에서는 \mathbf{F}_{i}\in \mathbb{R}^{{T/2^i}\times D} 형태의 feature를 얻게 됩니다. 그리고 이들을 모두 concat 하여 사용하고 있네요.
저는 이 논문을 읽기 전 이러한 디테일이 있는 줄 몰랐는데 해당 디테일은 이미 22년도 논문에서 제안된 방법이라고 하네요. 논문 리딩을 더욱 열심히 해야겠습니다.
자 아무튼 feature들이 어떻게 준비 되는지 살펴 봤습니다. 여기까지는 저자의 contribution이 아닙니다. 저자의 contribution에 해당되는 부분들은 이제 같이 한번 살펴보도록 하겠습니다.
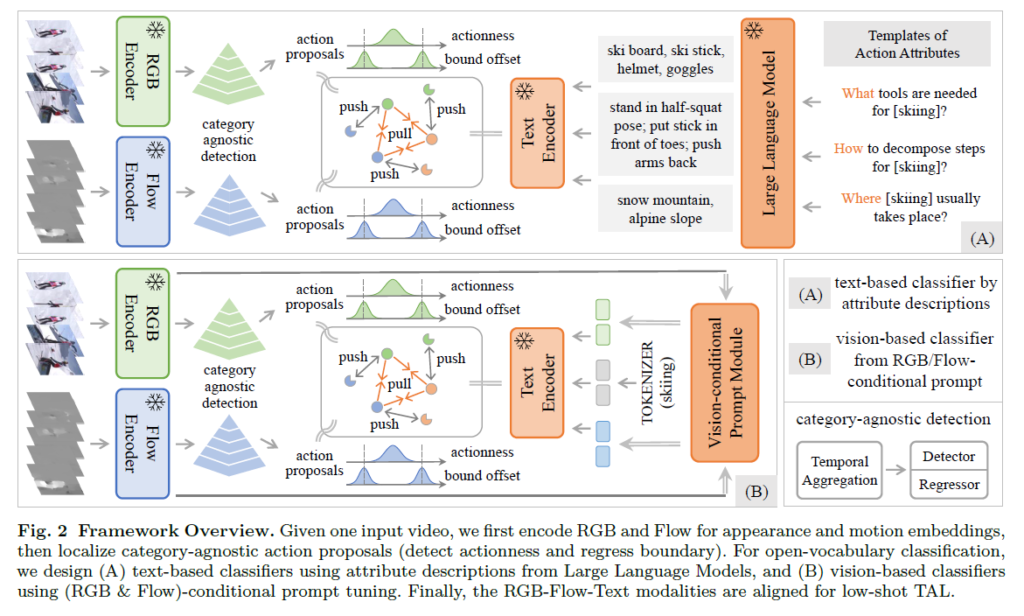
Open-vocabulary Action Classification
저자는 우선 GPT3나 OPT와 같은 LLM 모델에게 salient objects, event elds, 그리고 motion interactions 와 같은 action query에 대해 디테일 한 정보를 얻기 위해
- what tools are needed for [action]?”
- where [action] usually takes place?”
- how to decompose steps for [action]?”
와 같은 질문을 던졌다고 합니다.
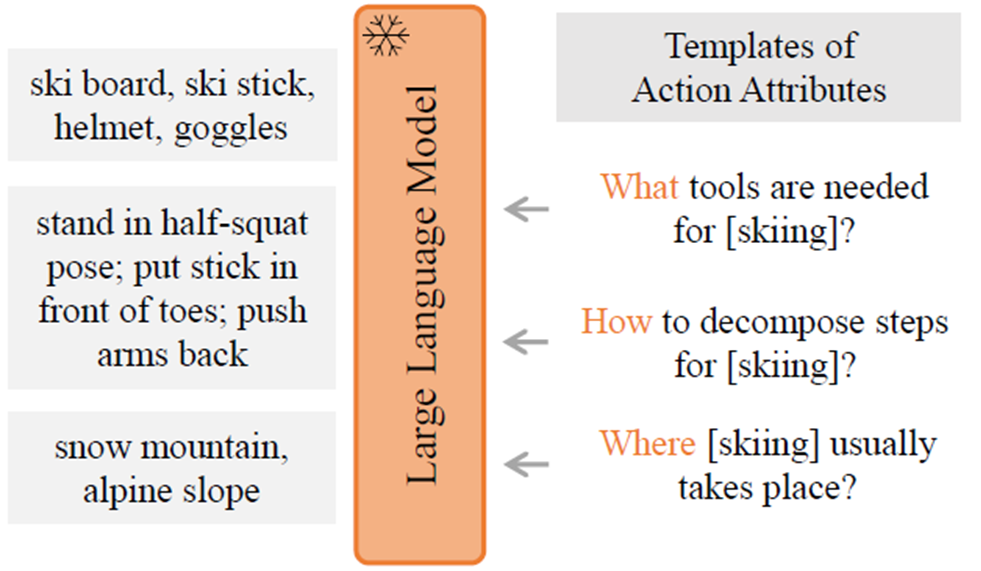
위의 그림과 같이 얻은 다양한 description 들을 tokenize 하고 CLIP text Encoder에 넣으면 action category에 대한 text embedding을 얻을 수 있습니다. 이는 기존의 접근 방식보다 더 다양한 정보를 바탕으로 생성되었기 때문에 더 좋은 표현력을 가진다고 볼 수 있죠.
하지만 여기서 text description에 대해 좋은 서술을 얻기 힘들 때 저자는 다른 대안을 RGB/FLOW feature 부터 가져왔습니다. 예를 들어 복잡한 포즈 패턴을 요구하는 gymnastics에 대해서는 서술이 매우 길어져서 사용하기 조금 어려워지는 부분이 있다고 합니다.
저자는 LLM을 사용하지는 못하지만 RGB/Flow feature가 instance에 대한 서술은 잘 해줄 수 있으니 학습 가능한 모듈(MLP나 Transformer Encoder)을 사용하여 RGB/Flow feature를 K개의 prompt vector로 만들어서 text encoding을 진행한다고 합니다.
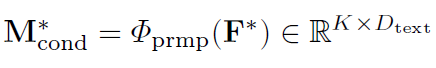
다음으로는 이 prompt vector를 action category 앞 뒤에 붙여주고 CLIP Text Encoder를 태워서 Category에 대한 embedding을 얻어냅니다.
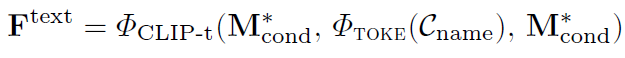
여기서 학습 과정에서는 CLIP encoder 가 학습 되는 건 아니고 gradient 전달만 해주어서 prompt vector를 만들어주는 모듈만 학습 시켜주게 됩니다.
이렇게 action category에 대한 text feature를 얻었으니 우리가 할 수 있는 가장 간단한 loss는 similarity를 이용한 classification 문제를 푸는 것 입니다. 프레임 단위의 rgb, flow feature를 text feature와 유사도를 계산하고 이를 바탕으로 프레임 단위의 action classification을 하는 것이죠.
이를 위해서 동일한 embedding space에 놓여져 있어야 하니
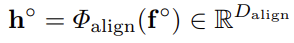
모든 모달리티의 feature들을 동일한 차원으로 맞춰줄 수 있도록 학습 가능한 MLP나 Transformer를 사용해줍니다.
Training and Inference
Category-agnostic Proposal 부분은 저자의 contribution은 아닙니다. 사실 여기서는 이전의 방법들을 따라했다고 했는데 저도 처음 보는 부분이라 일단 제가 텍스트를 달아 두었으니 필요하신 분들은 참고해주시길 바랍니다.

다음으로 Open Vocabulary Classification 입니다. 굉장히 간단한데 결국 프레임 단위의 어노테이션이 있으니 프레임 단위의 rgb, flow feature와 action category text feature를 활용해서 유사도를 계산하고 유사도가 가장 높은 text를 예측한 action category로 정의하는 것이죠.
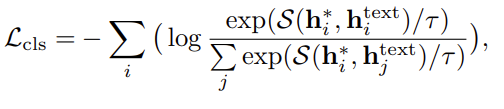
즉, InfoNCE Loss를 사용해주고 있습니다.
Experiments
Text-based classi ers from detailed language descriptions.
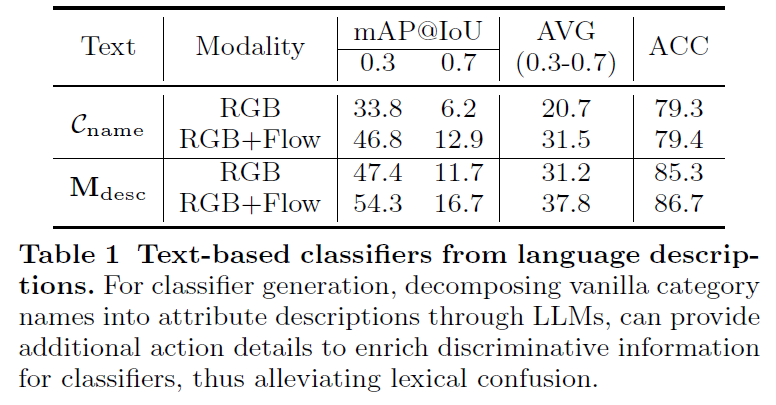
가장 먼저 LLM을 활용한 attribute description에 대한 실험 입니다. \mathcal{C}_{name}이 action category name만 활용한 경우이고 \mathbf{M}_{desc}는 LLM을 활용하여 category name에 대한 attribute description을 추가적으로 활용한 경우 입니다.
mAP 관점에서도 그렇고 ACC 관점에서도 그렇고 모두 LLM을 활용하여 더욱 풍부한 정보를 활용했을 때 높은 성능을 보여주고 있습니다.
Optimal language descriptions
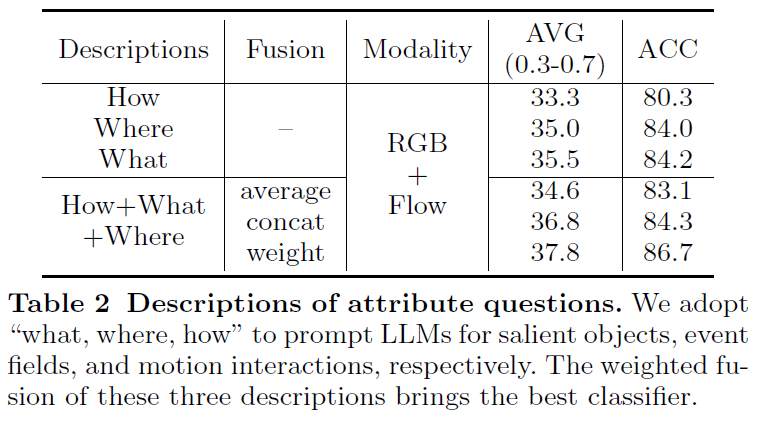
해당 실험은 LLM을 활용하여 attribute description을 생성할 때 질문을 어떻게 정의 하는 지에 대한 실험 입니다. 하나의 description만을 사용하는 것은 marginal한 성능 향상을 보여주는 반면 How, What, Where에 대한 모든 정보를 활용해주는 것이 가장 좋다고 하네요.
또한 fusion 방식에서도 average, concat, weight 방식마다 성능 차이가 좀 있는데 weighted sum 방식이 가장 좋은 성능을 보여주고 있습니다.
Vision-conditional prompt tuning
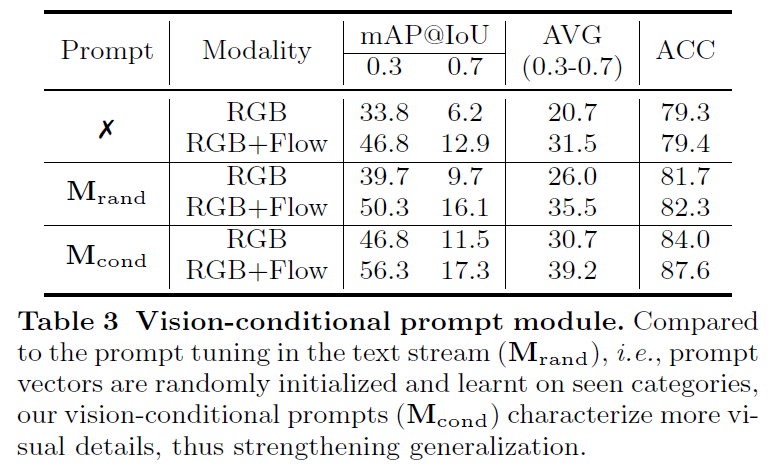
LLM을 이용하여 attribute에 대한 description을 얻기 어려울 때는 RGB/FLOW 부터 prompt vector를 생성했습니다. 여기서는 사용하지 않은 것과, 랜덤 벡터 그리고 제안하는 Vision-conditional prompt vector를 비교하고 있습니다.
보통 prompt vector는 학습 가능한 랜덤 벡터를 사용하는데 저자는 RGB/Flow feature를 다시 projection 시켜서 instance specific 한 prompt vector를 정의하였고 실제로 효과가 있음을 보여주고 있습니다.
Detailed Comparison & Module Choice
디테일한 비교와 디자인 초이스를 보여주고 있습니다.
Prompt Positions
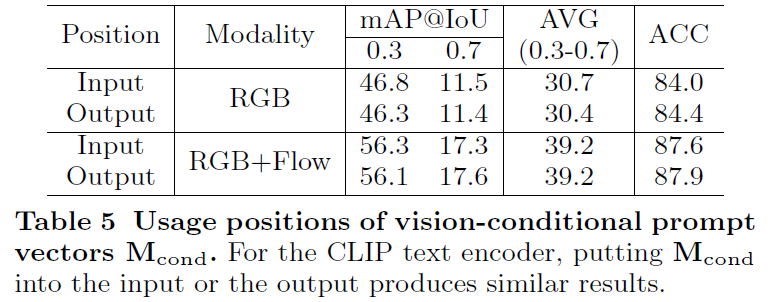
우선 학습 가능한 prompt vector를 CLIP text encoder에 넣어주기 전과 후에 모두 사용해줄 수 있습니다. 결국 입력에 넣어줄 것이냐 출력에 넣어줄 것이냐 에 대한 차이인데, 실험 결과를 확인하니 미세하게 입력에 넣어주는 것이 더 높은 성능을 보여주고 있습니다.
Sharing visual backbone
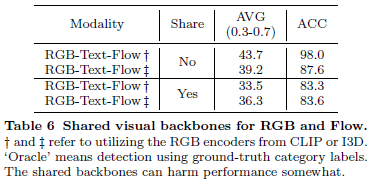
RGB와 Flow feature를 early fusion 방식으로 backbone을 공유해버리면 나중에 alignment 과정에 안좋은 영향을 끼칠 수 있다고 합니다. 성능 테이블을 보면 Share를 하지 않은 방식이 더 높은 성능을 보여주고 있습니다.
Freeze encoders vs end-to-end fine-tuning
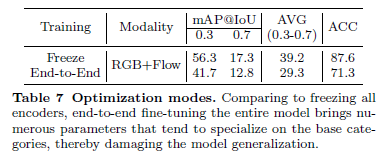
Freeze 방식과 Finetune 방식을 비교하고 있습니다. 놀랍게도 finetune 방식의 성능이 떨어지는 모습을 확인할 수 있습니다. 아마도 거대한 모델을 소규모의 데이터 셋으로 학습 시켜 버리면 overfitting 이슈가 존재하여 저러한 결과를 보여주고 있지 않나 싶네요.
Comparison with state-of-the-art methods
The zero-shot performance
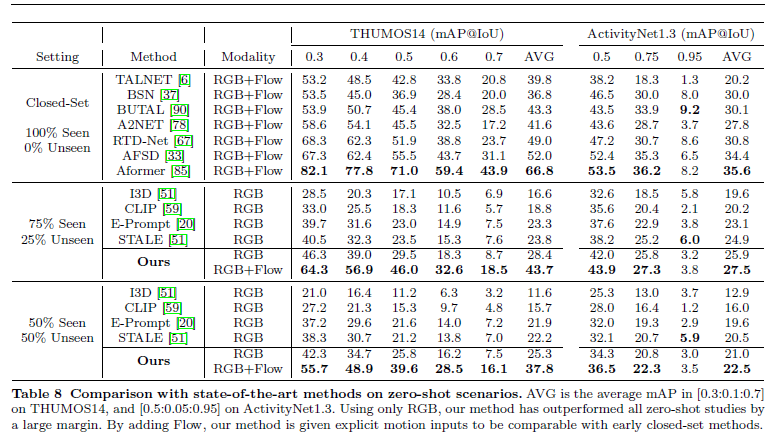
Zero shot 분야에서 벤치 마킹 입니다. 정말 fair comparison을 위해서는 RGB 단일 모달리티에서의 성능을 확인하는게 좋을 거 같습니다.
RGB 단일 모달리티만을 사용하면 THUMOS14 벤치마킹에서는 평균적으로 3~5% 정도의 성능 향상이 있고 Flow 까지 같이 활용하면 성능 향상 폭이 매우 올라가는 모습을 확인할 수 있습니다.
벤치마킹 테이블을 보니 조금 궁금해지는 점은 왜 기존 방법들은 Flow를 사용하지 않았을까 라는 생각이 드네요.
Conclusion
저자는 Low-shot Action Localization 문제를 LLM을 이용하여 효과적으로 풀 수 있는 프레임 워크를 제안하였습니다. 저희가 이번에 Access에 냈던 논문도 비슷한 접근을 취했는데 이번에 해당 연구를 고도화 하는과정에서 LLM을 사용하거나 지식 그래프를 활용할 예정입니다.
코드가 공개 됐으면 앞으로의 연구에 많은 도움이 됐을 텐데 참 아쉽네요. 메일이나 한번 보내봐야겠습니다.
리뷰 읽어주셔서 감사합니다.