
안녕하세요, 이번 제안서 작업을 위해 unseen object 6D pose estimation을 알아보았는데요. 서베이 중 찾은 논문 중 하나이고 이를 기반으로 계속 연구가 나아가는 것이 보이네요. 이번 CNOS 같은 경우 Meta에서 만든 SAM, DINOv2를 사용하는 것 말고는 방법론 자체는 심플합니다. 이번 논문을 읽으면서 앞으로는 Foundation model을 활용하는 것이 앞으로의 연구 방향이 될 수도 있겠다고 예상이 되네요.
SAM은 너무 유명한 Foundation model이죠. 타겟으로 하는 물체의 누끼를 따주는 segmentation 모델입니다.
정윤서 연구원님이 리뷰한 DINOv1는 Self-Supervised Learning에서 좋은 성능을 보였던 모델입니다. large-scale의 이미지 데이터를 활용하여 미리 정의된 작업을 수행하지 않고도 풍부한 visual feature를 학습합니다. 논문을 읽지 않아 정확한 개선점이 무엇인지는 모르지만 foundation model이므로 이를 학습 및 속도 측면에서 많이 개선한 것으로 보입니다. 이러한 DINOv2를 활용하여 image-level의 visual task로는 image classification, instance retrieval, video understanding과 pixel-level에서는 depth estimation, semantic segmentation에 적합한 범용적인 feature를 생성하는 Foundation model 입니다. DINOv2 링크를 들어가서 보시면 좀 더 직관적으로 이해하실 거라고 생각합니다.
리뷰 시작하겠습니다.
Introduction
Object pose estimation은 로봇 공학 및 증강 현실 애플리케이션에서 중요한 역할을 합니다. Supervised-based 딥러닝 방법론 우수한 성능을 달성했지만, 각 타겟이 되는 물체와 관련된 광범위한 학습 데이터에 의존하는 모습이 보입니다. 따라서, 학습 중에 Unseen 물체에 대한 도입을 위해서는 데이터를 합성하거나 annotation하고 모델을 재학습하는 데 상당한 노력과 비용이 필요합니다. 이는 산업에서 supervised 방법의 적용을 제한합니다. 예를 들어 물류 창고에서는 모든 신제품에 대한 pose estimation 방법을 재학습하는 것은 비현실적으로 보입니다.
Object pose estimation에는 일반적으로 2-stage로 수행합니다.
(1) 입력 이미지에서 대상 물체를 detect/segmentation
(2) RoI에 대한 6D 객체 포즈를 추정합니다
제가 이전에 리뷰한 MegaPose와 같은 연구에서는 효과적인 CAD-base의 Object pose estimation 방법론을 다루었습니다. 하지만 이러한 방법은 주로 2D bbox만을 입력으로 해야 합니다. 이는 다시 말하면 정밀한 2D bbox를 사용할 수 있는 시나리오에만 적용된다고도 볼 수 있습니다.
이러한 문제를 해결하기 위해 대상 물체의 CAD 모델만 있으면 물체를 detection하고 segmentation 할 수 있는 간단한 방법을 제안합니다. 저자는 해당 방법론을 CNOS(CAD-based Novel Object Segmentation)라고 합니다.
Method
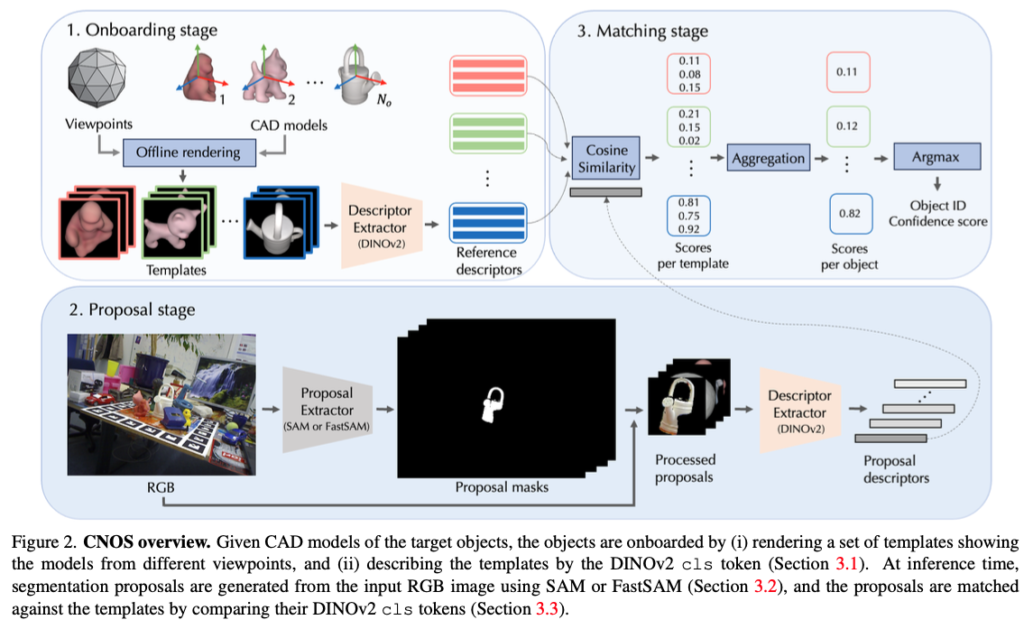
전체적인 CNOS의 오버뷰는 그림(2)와 같습니다. CAD 기반의 novel 물체에 대한 segmentation을 위해 3-stage의 형태로 진행됩니다. 먼저 Onboarding stage에서는 CAD 모델의 렌더링 과정을 거쳐 visual descriptor를 추출하고, Proposal stage에서는 입력 이미지로부터 물체가 존재하는 만큼의 mask를 생성하여 mask로부터 descriptor를 얻게 되고, 최종적으로 CAD 모델의 visual descriptor를 기반으로 물체에 대한 mask를 retrieval하여 클래스를 부여하는 매칭 과정을 거치게 됩니다.
1. Onboarding stage
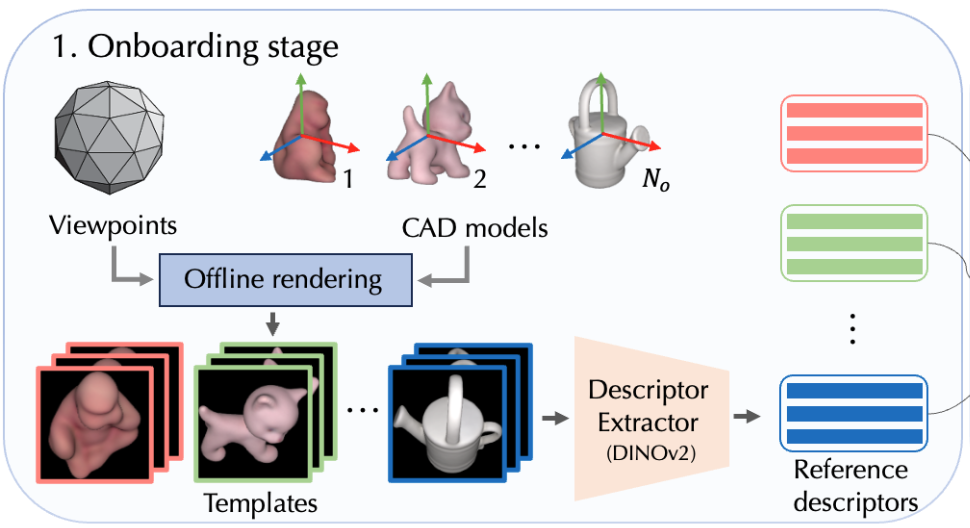
먼저, onboarding 과정은 결국 CAD 모델에 대한 렌더링 과정을 나타냅니다. 여러 뷰포인트에 대한 template들을 생성하는 과정이라고 보시면 됩니다. 렌더링 과정을 거쳐 DINOv2를 사용하여 visual descriptor를 추출하게 됩니다. 다양한 뷰포인트라고 말씀을 드렸었는데 저자는 42개의 시점을 사용했다고 하네요. 42개를 실험적으로 세팅한 것이라고 합니다. 이는 선행 연구[1]에 따라 뷰포인트 범위가 잘 분산되어 제공하게 됩니다. 이러한 렌더링 과정은 총 \mathbf {N_{o}V}만큼 생성하게 되는데 이때, \mathbf N_o는 CAD 모델의 수, \mathbf V는 뷰포인트 수를 나타냅니다. 예를들면 LINEMOD 같은 경우는 모두 15개의 CAD 모델을 사용하므로 630장만큼 생성하겠네요. 해당 과정은 오프라인 과정이므로 사전에 생성해놓은 정보라고 보시면 되겠습니다.
[1] Van Nguyen Nguyen, Yinlin Hu, Yang Xiao, Mathieu Salz-mann, and Vincent Lepetit. Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions. In CVPR, 2022.
2. Proposal stage
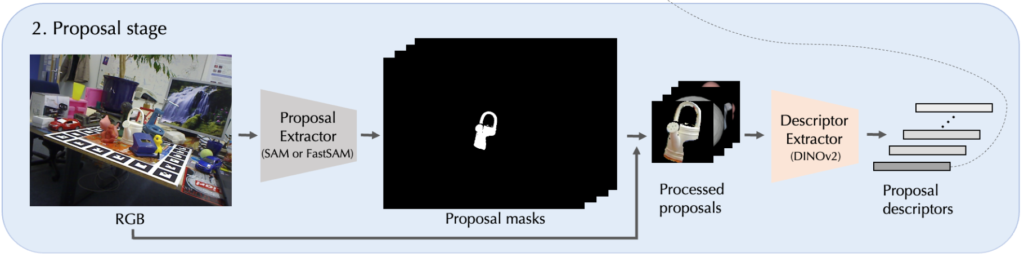
테스트로 사용되는 이미지에 대해 SAM/Fast-SAM이 적용되어 클래스가 정해지지 않은 \mathbf N_p개의 proposal mask가 생성되고, 각 proposal i(instance)의 mask는 \mathbf M_i를 나타냅니다. 당연히 \mathbf N_p는 고정되어 있지 않은 값이고 무엇을 타겟으로 하는지에 따라 달라집니다.
각각에 대한 proposal i에 대한 visual descriptor를 계산하기 위해서는 먼저 해당 mask \mathbf M_i를 사용하여 입력된 이미지로부터 배경을 제거해야 합니다. 그런 다음 \mathbf M_{i}에서 나온 bbox를 이용하여 이미지를 crop합니다. 하지만, 각 proposal mask는 bbox크기가 다를텐데요. 저자는 이러한 문제를 해결하기 위해 proposal의 크기를 모두 224×224의 크기로 조정하여 사용했다고 합니다. 이렇게 얻은 processed proposal들을 DINOv2를 이용하여 visual descriptor \mathbf D_{p}를 추출하여 사용하게 됩니다.
3. Matching stage
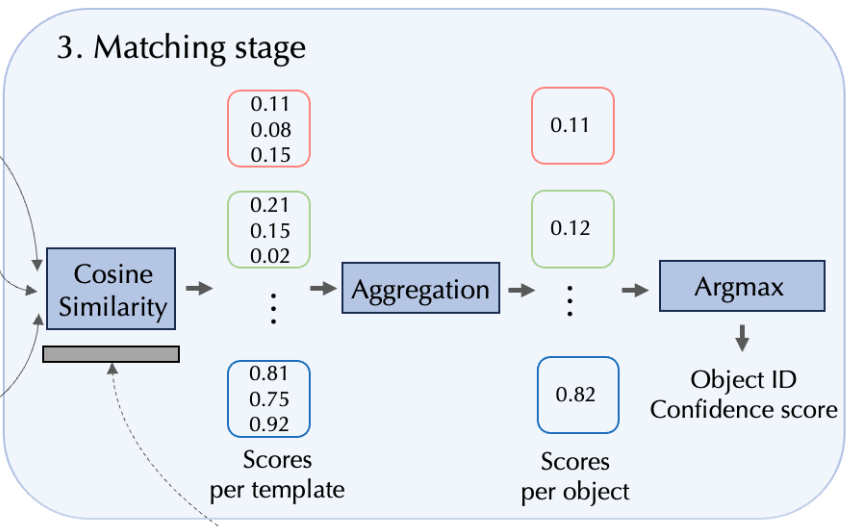
이번 과정의 목표는 각 proposal i에 물체에 대한 ID \mathbf o_{i}와 confidence score \mathbf s_{i}를 부여하는 것인데요. 이를 위해 다들 아시는 cosine similarity를 사용하여 각 proposal descriptor \mathbf D_{p}를 \mathbf D_{r}(사전에 렌더링 된 descriptor)와 함께 유사도를 측정하는 과정입니다.
View aggregation
각 CAD 모델에 대한 모든 template 수는 뷰포인트 \mathbf V만큼 생성된다고 말씀을 드렸었는데요. 유사도를 측정한 점수들을 합산한 행렬을 얻습니다. 해당 matrix의 크기는 각 proposal \mathbf p_i와 각 CAD 모델간의 유사도를 측정한 것이므로 \mathbf N_p \times \mathbf N_{o}가 되겠네요. 저자는 Mean, Max, Median, Mean of top k highest(\mathbf {Mean_k})으로 실험을 해봤을 때 \mathbf {Mean_k}가 가장 좋은 성능을 보였다고 하네요.
Object ID assignment
각 proposal에 물체에 대한 ID \mathbf o_{i}와 confidence score \mathbf s_{i}를 부여하기 위해서는 similiarity matrix에 argmax를 N_o에 대해 취해주기만 됩니다. 이렇게 최종적으로 \mathbf N_p 만큼의 proposal에 대한 confidence score를 정의하는 similarity matrix가 생성이 되겠네요.
Output
이렇게 matching-stage가 끝나면 어떤 클래스가 지정된 proposal 집합들이 생성될 것입니다. 각 proposal들은 \{ \mathbf M_i, \mathbf o_{i}, \mathbf s_{i} \}로 정의된 집합입니다. 해당 proposal 중 일부는 여전히 잘못 라벨링이 되었을 수도 있기 때문에 해당 문제를 해결하기 위해 confidence score에 threshold \delta를 적용하였다고 합니다.
Experiments
CNOS에 대한 실험에 대한 setup과 BOP challenge의 7개의 코어 데이터셋에 대해서 선행 연구로 이루어진 방법론들과 비교합니다. 그리고 방법론을 설명하면서 View aggregation function, 렌더링 뷰포인트의 수, 런타임에 따른 정확도를 설명합니다.
Experimental setup
먼저 setup 입니다. 데이터셋은 BOP challenge에서 제공하고 있는 데이터셋을 사용합니다. 그 중 코어 데이터셋인 LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB, YCB-V로 7개의 데이터셋을 사용합니다. 해당 데이터셋에 대해서 모두 총 132개의 다른 물체와 clutter, occlusion한 scene들로 구성되어있습니다. 물체는 texture의 유무, 대칭/비대칭, 가정용/산업용 등으로 다양한 유형으로 구성되어 있습니다.
Evaluation metric
평가 지표는 Average Precision(AP)를 사용하여 평가합니다. 다시 말하지만, CNOS는 최종적으로는 pose가 아닌 segmentation을 하는 task입니다. AP 메트릭은 0.5~0.95 범위에서 IoU 임계값을 0.05씩 점차 증가시키면서 AP의 평균으로 계산합니다.
Baseline
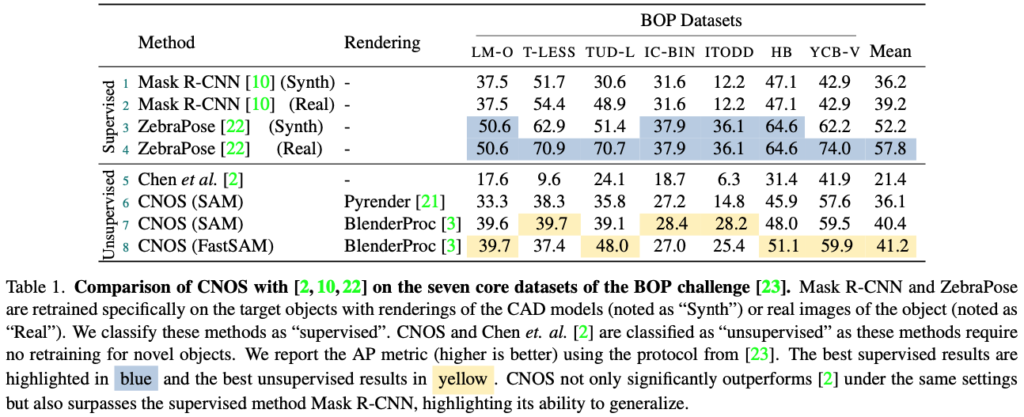
표(1)과 같이 이번 방법론과 가장 관련이 높은 논문인 [2]를 베이스라인으로 잡아 비교를 진행하였다고 합니다. [2]에서는 CAD 모델 당 72개의 template를 사용한 결과 SOTA를 달성하였다고 합니다. 그리고 표1과 같이 unsupervised/supervised 를 비교하여 나타냅니다. 각 데이터셋 특정한 real 또는 synthetic으로 구성된 학습 데이터로 학습시켜 Mask R-CNN ZebraPose를 비교합니다.
[2] Jianqiu Chen, Mingshan Sun, Tianpeng Bao, Rui Zhao, Li-wei Wu, and Zhenyu He. 3D Model Based Zero-Shot Pose Estimation Pipeline. In arXiv Preprint, 2023.
Implementation details
proposal-stage에서는 런타임의 효율성 측면에서 뛰어난 결과를 보여준 SAM의 ViT-H 모델 또는 FastSAM 모델을 사용하였다고 합니다. visual descriptor를 추출하기 위해 DINOv2의 ViT-H 모델을 사용합니다.
저자는 성능을 추가적으로 평가하기 위해 두 가지의 template set을 사용하여 비교하였는데요. 사전에 정의된 42개의 뷰포인트에 따른 template set을 생성하는데, 이는 Pyrender 라이브러리를 사용합니다. Pyrender 같은 경우 Direct illumination을 계산하기 때문에 이미지 당 평균 0.0026초가 소요될 정도로 매우 빠른 속도를 보여준다고 합니다. 참고로 Direct illumination은 조명이 특정 지점의 표면에 직접적으로 도달하는 조명의 양을 의미합니다. 간단히 말해 빛이 표면에 직접 반사되는 부분을 의미합니다. 3D 렌더링에서는 빛의 반사 및 조명을 정확하게 시뮬레이션하여 실제감 있는 이미지를 생성해야 합니다. Direct illumination을 계산하는 것은 주로 광원에서 표면까지의 직접적인 광선의 경로를 추적하고 해당 지점에서의 조명을 계산하는 작업을 의미합니다. 이러한 작업이 빠른 장점이 있나봅니다.
두 번째 template set는 BOP challnge에서 제공된 PBR-BlenderProc4BOP 학습 데이터셋으로 사용 가능한 합성 이미지에서 선택한 42개의 realistic한 렌더링 템플릿으로 구성하였다고 합니다. 해당 template들은은 첫 번째 set에서 사전에 정의된 42개의 뷰포인트의 방향과 거의 일치하도록 선택하였다고 합니다. PBR-BlenderProc4BOP 학습 이미지에는 occlusion이 있을 수 있으므로 대상 물체가 완전히 보이는 이미지만 선택했습니다. GT maks를 사용하여 배경을 검정색으로 만들고 GT bbox로 영역을 crop하면 대상 물체의 template을 최종적으로 얻을 수 있습니다.
모든 데이터셋에서 일관된 런타임을 유지하기 위해 이미지의 가로 세로 비율을 유지하면서 이미지 크기를 조정합니다. 특히 각 입력으로 들어가는 테스트 이미지의 너비를 640으로 고정하였고, 모든 실험은 V100 1장으로 진행하였다고 하네요.
Comparison with the state of the art

표(1)에서는 CNOS가 [2]보다 19.8% 차이로 우수한 성능을 보였습니다. 또한, BOP 데이터셋의 타겟 물체에 대해 학습되지 않았음에도 불구하고, CNOS는 이러한 물체에 대해 학습된 Mask R-CNN의 성능을 보다 좋은 것을 확인할 수 있으며, 저자는 CNOS의 일반화 능력을 강조합니다.
저자는 질적으로 생성된 segmentation proposal에는 일반적으로 대상 물체의 인스턴스와 매우 잘 일치하는 proposal이 사용되는 것을 확인하였으며, 대부분의 오류는 proposal의 잘못된 DINOv2 기반 classification로 인한 것임을 확인했다고 합니다. proposal의 calssification를 개선하는 것이 향후 연구 방향이 되겠네요. 그림(4)는 CNOS의 정성적 결과를 보여주고 있습니다.
Abalation study
Model size vs. run-time
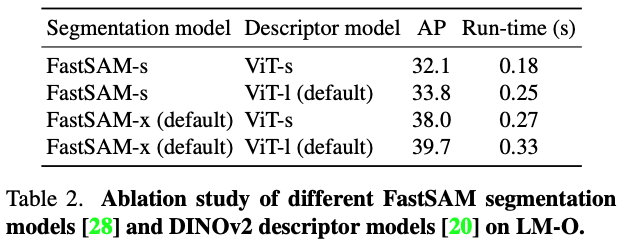
표(2)는 정확도와 런타임 간의 비교 결과를 나타내고 있습니다
Rendering

표(1)의 아래는 두 가지의 렌더링 방법(Pyrender, BlenderProc)에 대한 결과를 나타내고 있습니다. Pyrender 보다는 BlenderProc을 사용하는 것이 조금 더 성능이 좋은 모습을 보이네요.
Number of viewpoints
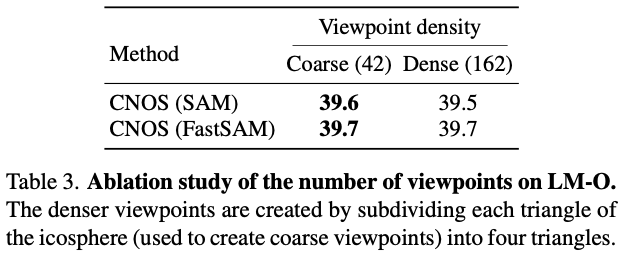
표(3)은 Dense(더 많은 뷰포인트)를 사용해도 Coarse(비교적 적은)에 비해 개선된 점보다 성능의 개선이 없는 것을 확인할 수있습니다. 해당 결과는 현재 42개의 뷰포인트가 이미 3D 오브젝트를 충분히 커버하고 있다고 볼 수 있겠네요.
Aggregating function
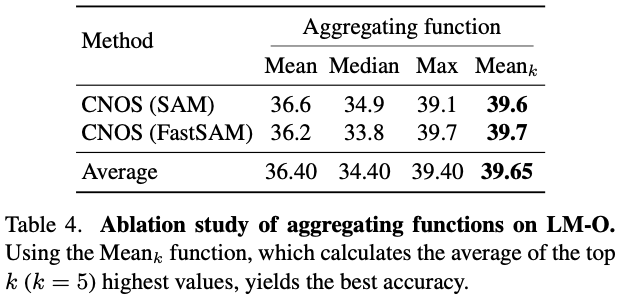
표(4)에서는 template과 proposal의 descriptor 간의 유사도를 aggregation하는 다양한 함수들에 대한 비교입니다. 유사도가 가장 높은 k개의 평균을 구하는 \mathbf {Mean_{k}}(k=5)가 가장 우수한 성능을 보였습니다.
Run-time
표(5)에는 제공되는 CAD 모델에 대한 CNOS의 각 stage별로 평균 런타임이 나와 있습니다.
onboarding-stage에서 Pyrender를 사용한 이미지 한 장의 평균 렌더링 시간은 0.026초인 반면, BlenderProc을 사용한 경우 단일 V100에서 이미지당 약 1초가 소요된다고 하네요. onboarding-stage는 각 CAD 모델마다 한 번씩 수행된다는 점도 고려해야 합니다. 런타임 측면에서 onboarding-stage는 template 생성으로 인해 bottleneck이 발생하는 반면, proposal-stage는 segmentation 알고리즘으로 인해 bottleneck 현상이 발생합니다.
Conclusion
이번 CNOS는 별도의 학습 없이 CAD 모델만을 기반으로 novel 물체에 대한 segmentation을 위한 간단하면서도 효과적인 방법을 제안했는데요. lage-scale annotation된 데이터셋에 대해 학습된 이전의 supervised 방식과 비교할 수 있을 정도로 높은 정확도를 달성합니다. 마지막으로, 저자는 제안한 CNOS가 CAD 기반의 novel 물체의 segmentation의 표준 기준이 되고, novel object pose estimation 파이프라인의 초기 단계로 활용되는 것을 기대합니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요. 희진님! 좋은 리뷰 감사드립니다.
새로운 물체를 위해서 모델을 다시 학습시키지 않아도 된다는 점과 어떠한 물체든 그 물체에 대한 CAD model만 존재한다면, 강인하게 segment하고 그 category와 confidence를 뽑을 수 있는 점이 굉장히 흥미로웠습니다.
review를 이해함에 있어서 두가지 질문사항이 있습니다.
첫번째는 2. Proposal stage에서 SAM or FastSAM을 통해서 proposal mask를 생성해냅니다.
이 과정에서 정확히 타겟 물체에 대한 mask를 생성해내기 위해, Foundation모델은 이미 대상물체를 알고
학습이 되어있는 상태인 것인지 궁금합니다.
또한, 두번째로 SAM or FastSAM을 통해서 RGB이미지와 사이즈가 같은 이진영상(Proposal mask)을 뽑고,
색상정보를 주기 위해서 원본영상과 결합하여 segmentation이 진행되는 것으로 생각되는 데. 해당 내용을 옳게 이해한 것인지 궁금합니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
질문에 답변을 드리자면,
1. SAM을 따로 학습하지는 않고, CAD 모델을 입력으로 주어 동일한 물체 영역에 대한 누끼를 따는 것이라고 이해하시면 될 것 같습니다.
2. 넵 잘 이해한 것 같습니다. proposal mask에 존재하는 RoI 영역에 존재하는 물체에 대해 그대로 visible한 상태를 그대로 넣은 것으로 보입니다.
감사합니다.