안녕하세요. 박성준입니다.
최근에 Moment Retrieval에 대해 서베이를 진행하며 관련 논문을 읽던 중 비디오와 텍스트를 활용하는 task의 특성상 자연어 처리에 대한 이해가 부족해 이해가 안되는 경우가 많았고 모르고 넘어가기보다 이번 기회에 공부해보면 좋을 것 같아 오늘은 그 유명한(?) GPT에 대해 리뷰하겠습니다.
Generative Pre-trained Transformer
GPT는 OpenAI가 2018년에 선보인 LLM(Large Language Model)입니다. 이름에서 알 수 있듯이 사전 학습 모델로 레이블이 없는 대량의 데이터셋으로 사전 학습을 진행하고 downstream task에 fine-tuning하여 사용하는 모델입니다. 현재는 GPT-2, 3, 4와 같은 GPT-n의 형태로 OpenAI에서 지속적으로 발전시키고 있는 모델입니다. GPT 이전의 모델들은 레이블이 있는 데이터셋에 대해 학습을 진행하여 성능을 개선시키는 것에 집중했지만 레이블이 되어 있는 대량의 데이터를 확보하는 것은 쉬운 일이 아닙니다. 따라서 GPT는 기존의 언어 모델들이 레이블된 데이터에 의존하는 것에서 벗어나 레이블 되어있지 않은 대량의 데이터를 활용하여 언어 모델을 사전 학습하는 것에 초점을 맞춰 제안된 모델입니다.
Architecture
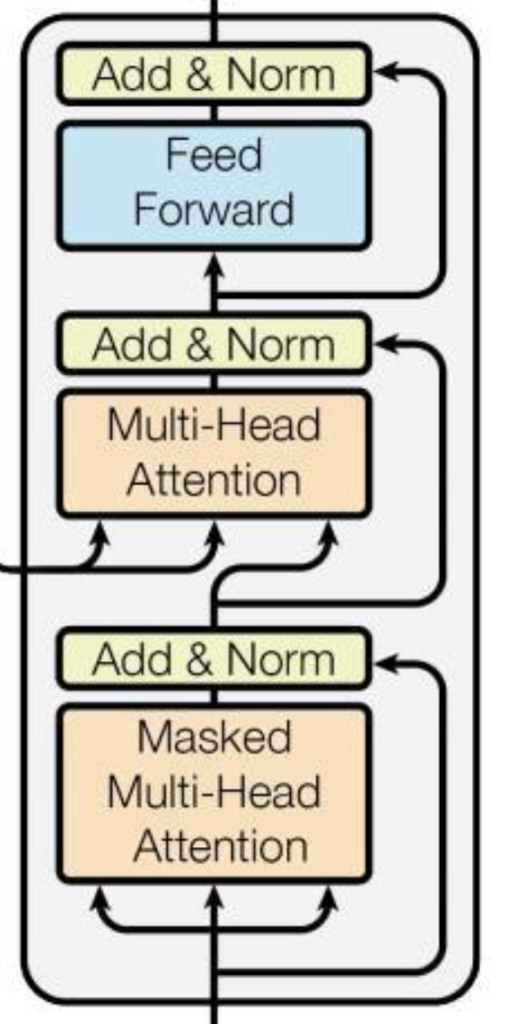
위 이미지는 Transformer의 Decoder의 구조입니다. GPT는 Transformer의 Decoder만을 활용합니다. 하지만 Transformer는 Encoder의 output을 활용하여 cross self-attention을 적용하지만 GPT는 Encoder가 없기에 Transformer Decoder의 Multi-Head Attention module이 없는 형태입니다. 즉, 아래 이미지의 Decoder가 겹겹이 쌓인 형태를 갖습니다.
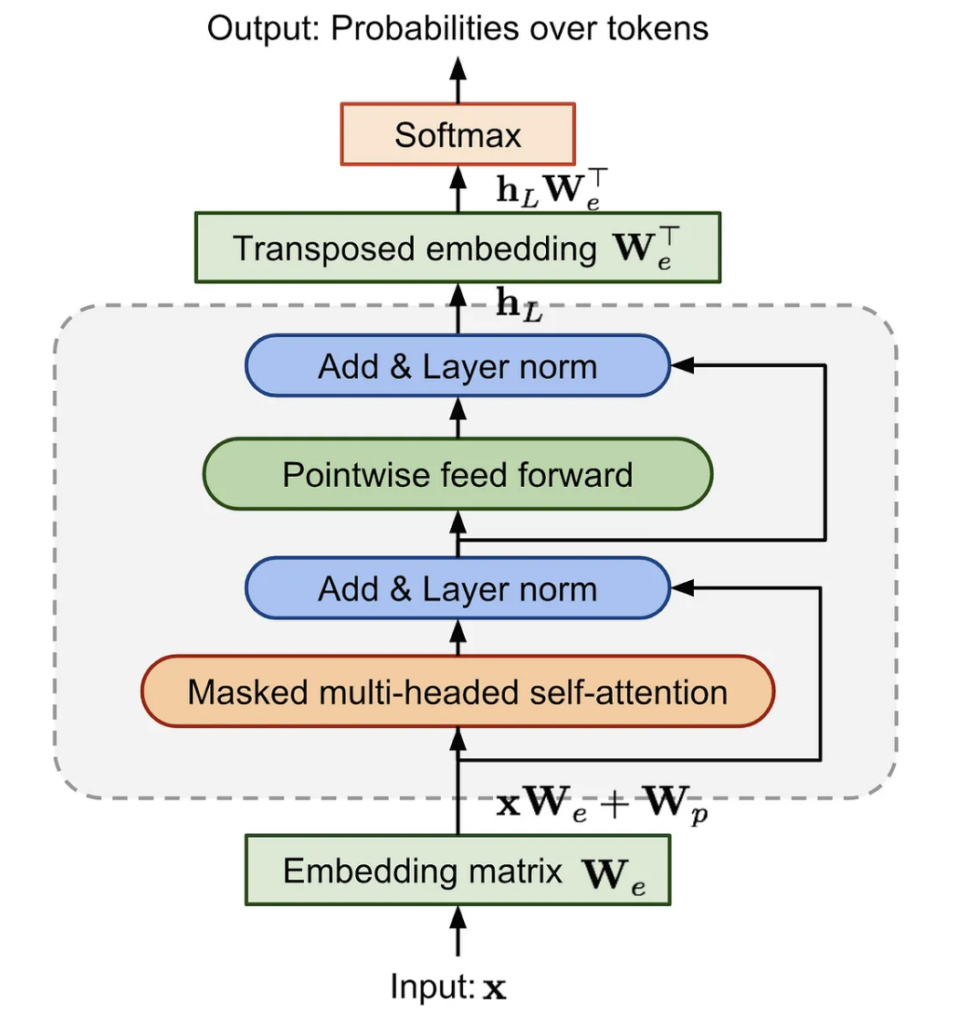
밑에서 더 자세하게 서술하겠지만 GPT는 다음 단어를 예측하는 방법을 사용하여 학습합니다. 이러한 학습방식을 위해서는 Decoder가 적합하기 때문에 GPT는 Decoder만을 사용합니다. 추가로 모델의 구조가 더 간결해지는 동시에 연산량이 줄어드는 장점이 있기에 Decoder만을 활용하여 GPT를 구성했습니다. 위 두가지 이유로 GPT는 Decoder를 여러개 쌓아올린 구조로 구성되었습니다.
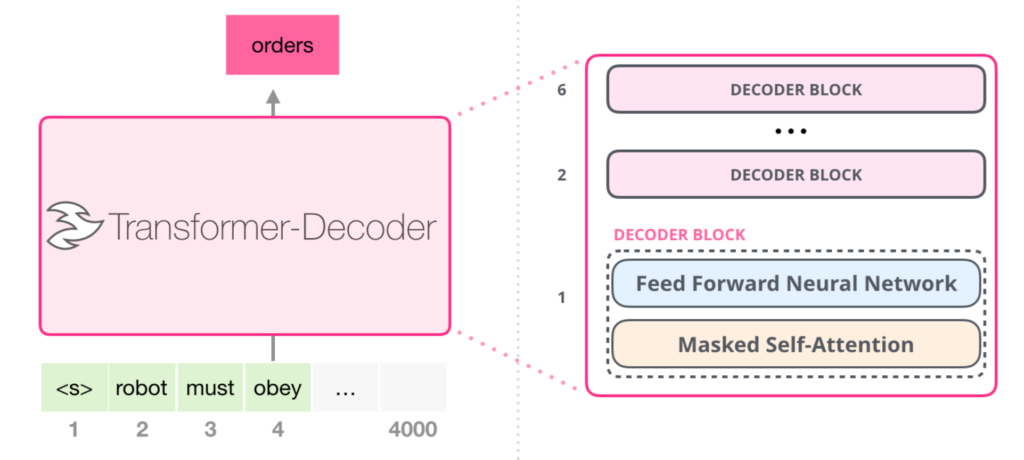
Pre-training
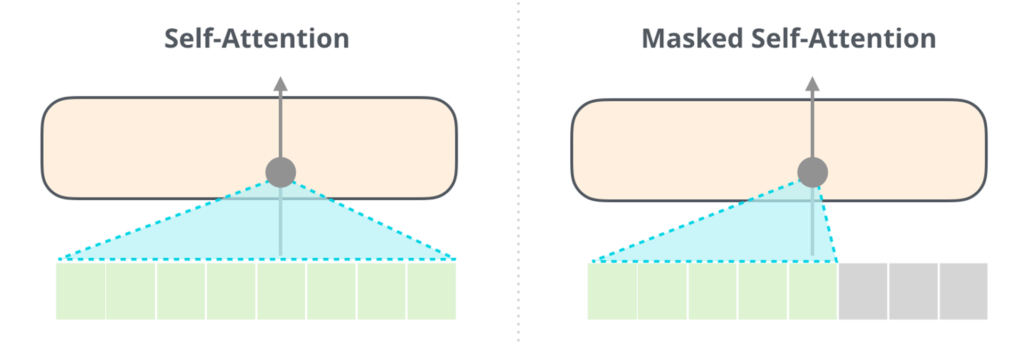
GPT는 기본적으로 앞의 문맥을 고려하여 뒤에 오는 단어를 맞추는 방법으로 학습합니다. 따라서 self-attention에서 앞 뒤 모두의 문맥을 고려하는 것이 아닌 앞의 문맥을 고려하여 뒤의 단어를 맞추는 방법으로 학습합니다. 논문에서 이를 Next Word Prediction으로 칭하여 NWP라고 표현합니다.
$L_1(u)=\sum_i\log P(u_i|u_{i-k},\dots,u_{i-1};\theta)$
손실함수는 위와 같이 표현됩니다. 위 수식에서 k는 window size를 의미하고, P는 네트워크를 거치며 modeling된 조건부 확률입니다. 위의 그림에서의 Masked self-attetion은 문장이 있을때, 문장의 뒷부분은 masking 한 후에 뒤의 단어들을 예측하는 것으로 학습을 합니다. 따라서 문장의 레이블링이 되어 있지 않는 상황에서도 문장이 있다면 그 문장의 뒷 부분을 예측하는 것으로 레이블링이 되어 있지 않은 데이터에 대해서도 학습이 가능하게 됩니다.
이러한 NWP방식의 pre-training 방식은 언어의 구조를 학습하고 문장의 문맥을 이해하려 노력하기 때문에 언어 모델 GPT가 내용을 잘 이해할 수 있도록 하는 데에 도움을 많이 주었습니다. 또한, 레이블 되어 있지 않은 대량의 데이터를 학습하기에 다양한 언어의 패턴을 학습할 수 있습니다. 또한 pre-training을 하며 사전학습을 진행하고 fine-tuning을 진행하는 모델 구조에서 다음 단어를 예측하는 사전 학습 작업은 특정 문제에 치우치지 않으면서도 일반적인 성능을 향상시키는 pre-training 방법을 적합하다고 할 수 있습니다.
Supervised Fine-Tuning
사전 학습을 마친 이후에는 각 task에 적합하게 fine-tuning을 진행합니다. 이 과정에서는 레이블이 되어 있지 않은 pre-training의 과정과는 다르게 레이블이 주어진 데이터셋에서 fine-tuning을 진행합니다. 따라서 fine-tuning을 진행할때의 손실함수는 다음과 같습니다.
$L_2(C)=\sum_{(x,y)}\log P(y|x^1,\dots,x^m)$
Total Loss $L(C)=L_2(C)+\lambda * L_1(C)$
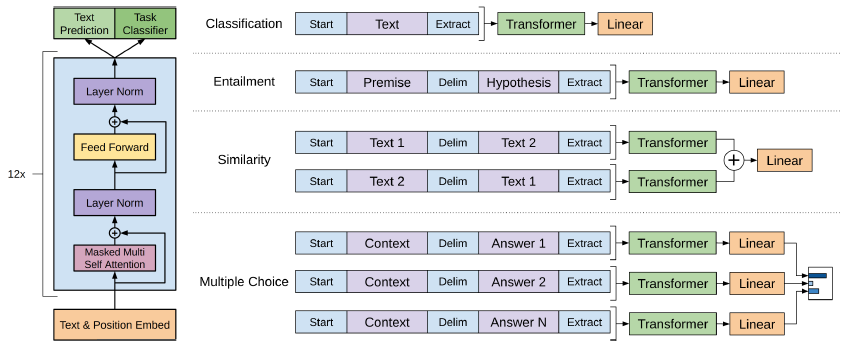
Classification task에 대해서는 입력 받은 text가 어떤 클래스인지 분류하는 문제로 스팸 메일인지 아닌지 분류하는 문제입니다. 문장 전체를 입력하게 됩니다. Entailment task는 문장 2개를 입력 받아 두 문장 사이의 관계를 분류하는 문제입니다. 위 그림에서 첫 문장이 Premise, 두번째 문장이 Hypothesis로 구성됩니다. Similarity task는 두 문장을 입력 받아 두 문장이 얼마나 유사한 지를 0~1 사이의 값으로 표현하는 task입니다. 첫 입력은 text1, text2의 순서로 입력하고 두 번째는 text2, text1의 순서로 두 문장 사이의 순서는 유사도를 측정하는 데에 방해가 될 수 있기에 순서를 바꿔가며 두번 입력하여 학습을 진행합니다. 마지막으로 Multiple Choice 문제는 Context와 Answer로 구성되었습니다. Context는문맥과 질문의 형태로 주어지고 Answer은 Context에서의 질문에 대한 대답입니다.
GPT는 대량의 데이터에 대해 사전 학습을 진행하여 fine-tuning만 진행하는 것에 비해 학습시간, 성능 등의 강점을 가집니다. 또한 언어의 context를 잘 담고 있는 모델로 모델의 구조를 변경하지 않고 여러 task에 fine-tuning을 할 수 있다는 장점도 가지고 있습니다. 하지만 attention 연산의 특성상 많은 연산량을 요구하게되는 단점이 있습니다.
GPT-2는 GPT-1과 비슷한 구조를 가지지만 Decoder의 개수와 context 차원을 늘려 파라미터 수를 늘린 모델입니다. 추가로 기존의 input, output만이 들어가는 것이 아니라 task가 어떠한지 까지 사전 학습에 활용하기에 fine-tuning 과정을 필요로하지 않습니다. 매번 fine-tuning을 해줘야 downstream task에서 활용할 수 있기에 효율적이지 않은 방법이라 제안된 방식으로 이와 같은 방식을 in-context learning이라고 합니다.
GPT-3은 파라미터 수를 1750억개로 늘린 크기의 모델로 attention을 sparse self-attention으로 수정했습니다. 기존의 self-attention은 각 layer당 연산 수가 $n^2$으로 연상량이 굉장히 많다는 단점이 있습니다. 이는 메모리 용량, 연산량 , 속도 측면에서 한계가 있기에 모델의 구조가 커지고 파라미터의 수가 많아짐에 따라 sparse한 attention을 적용합니다.
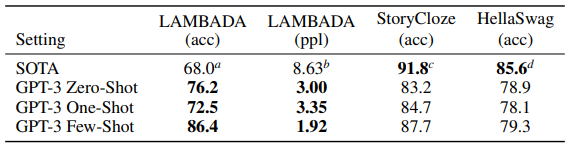
해결해야 하는 task에 대한 예시를 몇 개 확인하고 그 예시들을 이용하여 task 전체에 적용하는 학습 방식을 few shot learning이라고 합니다. 기존의 fine-tuning은 아주 작은 라벨링되어 있는 데이터에 대해 학습을 하기 때문에 훈련 데이터 이외의 분포는 잘 파악하지 않는다는 단점이 있기에 더 일반적인 task에 대해 진행할 수 있도록 하기 위해 여러 방법들이 제안되고 있고 few shot leaning이 그 방법 중에 하나 입니다. GPT-3는 fine-tuning 과정없이 SOTA를 달성했습니다.

감사합니다.
안녕하세요. 리뷰 감사합니다.
GPT-3에 대해서 오랜만에 봐서 반가운 감정이 먼저 드네요. 조금 아쉬운 부분은 GPT-3에서 fine-tuning 없이 SOTA를 달성할 수 있었던 이유는 여러 이유가 있겠지만 가장 큰 것이 in-context learning 때문이라고 생각하는데요. 리뷰에 in-context learning이 무엇이고 이를 통해서 무엇을 해낼 수 있었는지에 대해서 언급이 없는것 같은데, in-context learning은 GPT-3에서 처음으로 제안된 방법론인가요? 이 방법론을 통해서 어떻게 few-shot learning이 가능하게 되었는지 설명해주시면 감사하겠습니다.
감사합니다.
안녕하세요 주연님 좋은 댓글 감사합니다.
in-context learning은 사전 학습 후에 fine-tuning 하는 과정을 prompt를 활용하여 fine-tuning없이도 downstream task에 활용할 수 있도록하는 학습법입니다. task description, example, prompt를 활용하여 학습합니다. 여기서 활용하는 example의 개수에 따라 zero-shot, one-shot, few-shot learning으로 구분할 수 있습니다. 위의 방식으로 prompt를 활용하는 것으로 fine-tuning 없이도 downstream task에서 좋은 성능을 달성했다고 하네요. GPT-3에서 처음 제안된 방법론은 아니지만 GPT-3에서 활용함으로 좋은 성능을 이끌어 냈다고 하네요.
감사합니다.
안녕하세요. 박성준 연구원님.
GPT 한번 공부해봐야지 하고 있었는데, 리뷰 감사합니다.
궁굼한 점이 있는데요.
1. GPT가 Decoder만을 사용한 구조로 연산량이 줄어드는 장점이 있다고 했는데, 한번에 단어 하나를 출력하는 Decoder가 Encoder 대비 연산 횟수가 많을 것 같은데, 왜 decoder만 사용하면 연산량이 줄어드는 효과가 있는 것인가요?
2. GPT-2는 task가 어떠한지를 사전학습에 활용한다고 하는데, 구체적으로 이를 사전학습에 활용한다는 것이 무슨 의미인가요?
감사합니다.
안녕하세요 지오님 좋은 댓글 감사합니다.
1. GPT는 기존 transformer에 포함되는 Encoder를 포함하지 않는 구조이기에 연산량이 줄어드는 장점이 있다고 언급하고 있습니다. 하지만 지오님이 언급해주신대로 decoder자체가 연산량이 많고 decoder를 쌓은 구조이기에 연산량이 적다고하기에는 무리가 있겠네요. 본문에서의 연산량이 줄어드는 효과는 Encoder를 활용하지 않는 구조이기에 Encoder의 연산이 필요없어지고 transformer의 구조보다 GPT의 구조가 간결해진다는 것으로 이해해주시면 될 것 같습니다.
2. GPT-1에서는 사전학습을 진행한 후에 fine-tuning 과정을 거치며 downstream task에서 활용했지만, GPT-2부터는 in-context learning을 활용합니다. in-context learning이란 사전학습을 진행할 때에 task description과 prompt를 활용하여 학습을 진행하게 되는데 사전학습에도 task에 대한 설명이 포함되기에 충분한 데이터를 활용하여 학습을 하게 된다면 특정 task에 fine-tuning을 하지 않더라도 특정 task에서 모델을 활용할 수 있도록하는 학습 방법입니다. task가 어떠한지를 사전학습에 활용하는 것은 이와 같은 in-context learning을 활용하기 위함으로 사전학습만으로 여러 task에서 좋은 성능을 낼 수 있다는 것을 설명하기 위함입니다.
감사합니다.
그림이 너무 크게 보이는 것은 저만 그런가요;
안녕하세요 교수님 좋은 피드백 감사합니다.
확실히 그림 크기가 너무 커서 가독성이 떨어지는 것 같습니다. 보기 좋은 크기로 수정해서 업데이트했습니다.
안녕하세요. 리뷰에 질문 및 피드백 남깁니다.
Transformer의 Encoder만을 활용하는 BERT와 비교했을 때 Transformer의 Decoder만을 활용하는 GPT의 장점은 무엇이라고 생각하시나요? 그리고 반대로 단점은 또 무엇이라고 생각하시나요?
그리고 전반적으로 원인과 결과 형식으로 리뷰를 작성해주셨는데, (e.g., downstream task마다 fine-tuning하는 것은 비효율적이라 incontext learning을 수행해야 함 등으로 서술하는 방식) 정작 해당 기술들의 과정에 대한 설명이 구체적으로 작성되지 않아서 아쉽네요. 예를 들어서 GPT3에서는 연산량을 줄이기 위해 Sparse Attention을 사용한다고 해주셨는데, 이 Sparse Attention이 정확히 어떻게 동작하는 방법론인가요? 모든 토큰들을 다 attention에 활용하지 않는다는 것으로 보여지는데 그럼 어떤 부분만 활용해서 attention을 수행한다는 것인지 등 보다 구체적으로 방법론들의 동작 과정을 설명해주면 좋겠습니다.
그리고 GPT라는 모델 자체가 워낙 유명하다보니 다들 좋다고 생각하겠지만.. 개인적으로 저자들이 주장하는 바가 맞는지 (가령 디코더만을 활용하면 더 메모리/연산 효율적이다 등등)를 검증하기 위해서는 실험 결과를 철저히 분석해야한다고 생각합니다. 그런 측면에서 마지막 실험 테이블 하나 말고는 GPT가 자신들이 설계한 의도대로 잘 동작해서 좋은 성과를 얻었는지 그리고 GPT1과 2와 3으로 버전 업그레이드 됐을 때마다 어떻게 수치적으로 좋아졌는지 등 GPT의 활약 면모를 확인할 수 없어 아쉽습니다.
마지막으로 리뷰 맨 마지막에 GPT3와 그 분야에 SOTA 방법론과의 비교 테이블이 하나 있긴 한데.. 두 모델이 얼마나 크기 차이가 나는지부터 LAMBADA와 Stroy Close, HellaSwag가 어떤 데이터셋 및 task이며 어떻게 평가하는지 등을 설명해주어야 리뷰를 읽는 사람에게 도움이 될 것 같습니다. 리뷰에 작성해주신대로 GPT는 다양한 downstream task를 수행할 수 있기 때문에 단순히 저 표만으로는 어떻게 해석해야할지도 잘 모르겠으며 공평한 평가를 진행했는지도 잘 모르겠습니다.
안녕하세요, 좋은 리뷰 감사합니다.
GPT3는 모델의 규모(파라미터 수)를 키워 few shot과 같은 meta learning이 잘 동작하게 하도록 한 것으로 이해를 하였습니다. 하지만, 이렇게 단순히 파라미터 수를 키워 잘 동작하게 하는 것은 어떠한 효과를 불러일으켜서 생기는 결과인가요?
그리고, 마지막 실험 결과에서는 무엇을 의미하나요? GPT는 생성 모델인데 어떻게 정확도를 측정하는지 알려주시면 감사하겠습니다.
감사합니다.
안녕하세요 희진님 좋은 댓글 감사합니다.
파라미터 수를 키우는 것은 더 많은 패턴을 학습할 수 있고 모다 많은 데이터로 훈련을 진행하며 일반화 성능이 올라가게됩니다. fine-tuning의 경우 파라미터가 많으면 과적합의 위험이 있지만 GPT3는 fine-tuning을 하지않는 것으로 일반화 기능을 올렸습니다.
마지막 실험결과는 몇몇 데이터셋에 대해서 성능을 확인한 결과입니다. LAMBADA 데이터셋의 경우, 각 구절의 마지막 문장의 단어를 누락시킨 후에 그 누락시킨 위치에 들어가는 단어를 예측할 수 있도록하는 데이터셋으로 자연어 모델의 추론 능력을 평가하는 데이터셋입니다.
StoryCloze 데이터셋은 4문장으로 이루어진 이야기의 올바른 결말을 추론하는 데이터셋입니다. 이 데이터셋은 문장의 context를 자연어 모델이 얼마나 잘 이해하고있는지를 평가하는 데이터셋입니다.
HellaSwag 데이터셋은 NLI(Natural Language Ingerence), 즉 자연어 추론을 하는 데이터셋으로 문장이 두개가 주어져 두 문장의 관계를 추론하는 데이터셋입니다.
위 3가지 데이터셋 모두 자연어 모델의 추론능력을 확인하기 위한 데이터셋으로 GPT3가 기존의 SOTA 모델에 비해 추론을 잘한다는 것을 저자가 보여주기 위해 실험한 결과입니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문의 마지막 그림에서 Zero-shot, one-shot, Few-shot이 나와있는 부분에서 질문이 있는데 내용 설명을 보면 3가지 종류의 shot leaning에 대해서는 그래디언트 업데이트가 일어나지 않는다고 나와있습니다. 그럼 GPT 모델은 shot leaning을 통해 어느 부분에서 변화가 일어났길래 성능을 높일 수 있었던건지 궁금합니다.
감사합니다.
안녕하세요 의철님 좋은 댓글 감사합니다.
downstream task를 위해 fine-tuning을 하기 위해서는 라벨링도 필요하고 파라미터의 수가 증가하여 과적합되어 일반화가 되지 않을 위험이 있습니다. k-shot-learning은 파라미터의 변경 없이 task와 instruction을 제공하는 것으로 downstream task를 수행할 수 있습니다. k개의 예시를 통해 자연어 모델이 downstream task에 대한 이해를 할 수 있도록 돕는 것으로 fine-tuning과정 없이도 성능을 낼 수 있습니다.
감사합니다.
안녕하세요, 박성준 연구원님. 좋은 리뷰 감사합니다. 리뷰를 읽다보니 몇가지 궁금증이 생겨 질문 남기고자 합니다.
1. 본문에서 다음 단어를 예측하는 방법에는 decoder가 적합하기 때문에 decodcer만 사용한다고 했는데, seq2seq나 transformer도 next token prediction을 하는 모델로 encoder-decoder 구조를 활용합니다. decoder에서 next token generation을 하는 것은 맞지만 굳이 encoder를 없애야 하는 이유가 납득이 가지 않는데, encoder를 없애야만 하는 이유가 있나요? 그리고 decoder만 사용함으로써 생기는 부작용은 무엇이 있나요?
2. Decoder 부분의 figure에서 MSA와 layer norm 다음에 pointwise feed forward 부분이 있는데, pointwise feed-forward가 무엇인지 설명해주실 수 있나요?
감사합니다.