이 논문의 주요 키워드
- Weakly Supervised Temporal Sentence Grounding
- Moment Retrieval
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Temporal Grounding에 대한 이해 (Moment-DETR 리뷰)
안녕하세요. 백지오입니다.
서른 번째 X-REVIEW는 Weakly Supervised Temporal Sentence Grounding을 수행한 논문입니다. Temporal Sentence Grounding은 어떤 영상에서 주어진 자연어 형태의 쿼리와 연관된 moment를 찾는 task로 moment retrieval이라고도 하는데요, 여느 video understanding task와 마찬가지로 이러한 task를 fully supervised로 풀기 위해 요구되는 temporal annotation은 상당히 costly 하기에 이러한 라벨 없이 task를 수행하고자 하는 약지도학습 기반의 방법이 연구되었습니다.
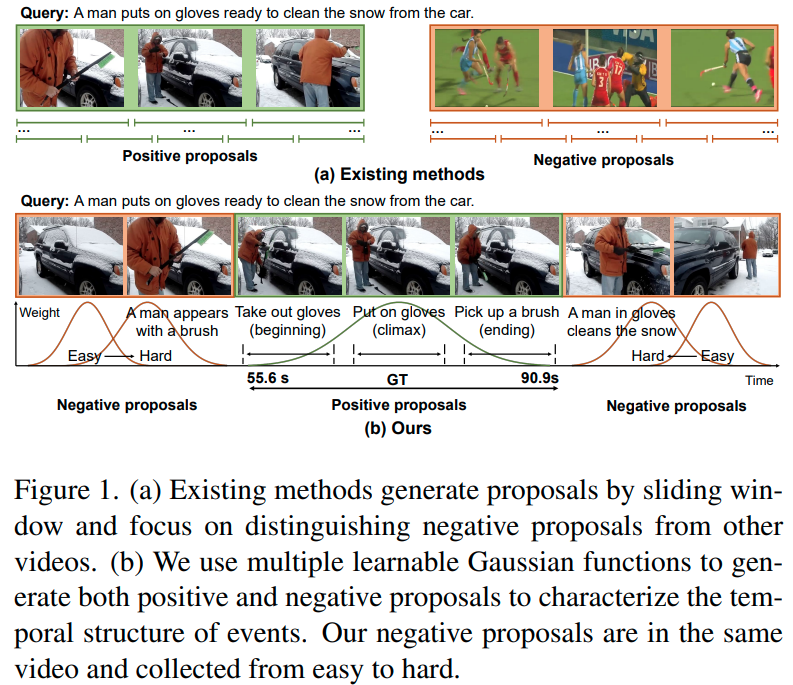
특히 이 논문 이전의 weakly-supervised 연구들은 sliding window 방식으로 proposal을 생성하고 positive visual-language pair와 negative pair를 구분하도록 학습시키는 방식을 많이 사용하였는데, 이 경우 negative pair는 다른 영상에서 랜덤 하게 선정되므로 정작 같은 영상 내에서 찾고자 하는 구간을 잘 찾도록 학습하기에는 적절하지 않았다고 합니다. 본 논문에서는 이러한 단점을 극복한 Contrastive Proposal Learning (CPL)을 제안합니다.
기존의 약지도학습 방법론들은 대체로 Multiple Instance Learning (MIL)이나 Reconstruction 방식을 활용하였습니다. MIL 기반의 방법론들은 주어진 자연어 쿼리와 영상의 구간이 올바르게 매칭된 쌍 혹은 올바르지 않게 매칭된 쌍, 즉 positive와 negative pair를 정의하여 video-level alignment를 수행하였습니다. 한편, Reconstruction 기반 방법론들은 텍스트 쿼리의 일부를 마스킹하고 이를 가장 잘 복원하는 구간이 해당 text와 관련된 구간일 것이라는 가정을 통해 학습을 진행했습니다. 이러한 기존의 방식은 모두 한계가 존재했는데요,
- 기존 방법들은 대부분 sliding window 방식을 통해 proposal을 생성하였는데, 이때 proposal의 생성에 영상이나 쿼리의 내용, 난이도 등은 전혀 고려하지 않기 때문에 proposal의 품질이 낮고 비효율적이었다고 합니다. CNM은 학습가능한 하나의 가우시안 마스크를 통해 positive proposal을 생성하는 방식으로 이를 극복하고자 하였지만, 편집되지 않은 긴 영상 속에는 대부분 하나 이상의 유사한 장면들이 등장하여, sub-optimal solution에 빠질 가능성이 높았습니다.
- 또한 대부분의 기존 방법들은 랜덤 하게 선정된 negative sample들에게 성능의 영향이 컸다고 합니다. 그림 1. (a)를 보면, 다른 영상에서 랜덤 하게 선택된 negative sample은 positive sample과 너무 쉽게 구분될 확률이 높아 강한 학습 신호를 주기가 어려웠습니다.
이러한 한계를 극복하기 위해, 저자들은 Contrastive Proposal Learning, CPL을 제안합니다.
CPL은 여러 개의 proposal을 content-dependent 한 방식으로 생성하여, 예측의 근간이 되는 proposal의 품질을 올리고, negative sample을 positive sample과 같은 영상에서 easy / hard 각각의 난이도로 mining 하였습니다. 구체적으로 그림 1. (b)와 같이, 영상 전체에서 여러 개의 학습 가능한 가우시안 함수를 통해 proposal들을 만들게 되는데, 이때 positive sample과 가까운 proposal 일수록 positive와 시각적으로 유사할 확률이 높으므로 hard 하다고 보고, 멀수록 easy 한 negative라고 보게 됩니다. 저자들은 이렇게 mining 되는 negative sample들의 난이도를 조정해 가며 커리큘럼 학습을 수행하였습니다.
저자들의 기여는 다음과 같습니다.
- 여러 개의 가우시안 함수를 통해 같은 영상에서 positive / negative proposal을 생성하여 content-dependent 하고 효율적으로 proposal을 생성함
- Controllable easy to hard negative sample mining을 제안하여 학습을 진행
- SOTA 달성
Related Work
Weakly Supervised Temporal Sentence Grounding. 기존의 방법들은 대체로 sliding window 방식으로 proposal을 생성하였습니다. 이 경우, proposal은 영상이나 쿼리의 내용과 무관(content-independent)하게 고정된 간격, 고정된 길이로 생기게 되어 특정 데이터셋의 GT 길이 분포에 의존적이게 되며, 전처리에 요구되는 시간도 길어집니다. CNM이 이를 극복하기 위해 하나의 학습 가능한 가우시안 마스크를 positive proposal로 간주하고, 나머지 영역들을 negative proposal로 간주하는 방식을 사용하였으나, 이러한 방식은 영상 하나 안에 여러 개의 유사한 이벤트가 존재할 수 있는 현실적인 상황에서 적합하지 않습니다. 따라서 저자들이 제안한 CPL은 여러 개의 가우시안 함수를 통해 positive / negative proposal들을 생성합니다.
한편, 기존 방법론들은 Contrastive Learning을 위한 negative sample들을 다른 영상에서 랜덤하게 추출하여 모델이 negative pair를 구분하는 것이 쉬웠지만, 본 방법에서는 하나의 영상에서 positive sample과 negative sample을 모두 추출하였습니다. 한편, 앞서 이러한 방법을 활용했던 RTBPN이나 CNM에서는 positive와 negative proposal들이 겹치는 confront 문제가 생겨 학습에 문제가 생길 수 있었던 반면, 제안한 방법은 negative sample을 positive sample 밖에서 추출하여 이러한 문제가 발생하지 않도록 하였습니다.
Curriculum Learning. 커리큘럼 학습은 인간의 학습 방식을 모방하여, 초반에는 쉬운 데이터로 학습하고 후반으로 갈 수록 어려운 데이터로 학습하는 방식입니다. 저자들은 이러한 방식을 proposal mining에 적용하고 temporal sentence grounding에서 성과를 보인 첫 사례라고 합니다.
Proposed Method
Overall Framework
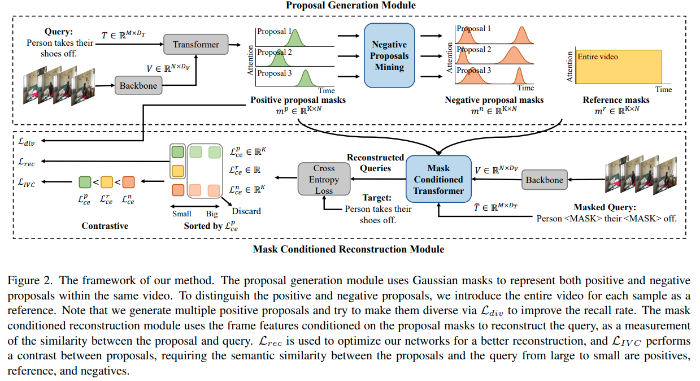
CPL은 proposal generation 모듈과 mask conditioned reconstruction 모듈로 구성됩니다.
Proposal generation 모듈에서는 가우시안 마스크들을 활용하여 영상 속에서 각 positive / negative proposal들을 생성합니다. 각 proposal에 속한 frame feature들은 가우시안 커브에 따라 가중치를 받아 병합되며, 이는 이벤트의 시간적 구조를 내포하게 됩니다. Positive와 negative proposal을 구분하기 위해서 먼저 전체 영상을 reference로 정의하고, negative proposal의 경우 reference와 semantic similarity가 낮고, positive proposal의 경우에는 높다고 가정합니다. 저자들은 positive proposal과 negative proposal들을 같은 영상에서 추출하고, negative의 경우 난이도를 easy와 hard로 나누어 줍니다. Easy에서 hard로 갈수록 positive와 가까워져 구분이 어려워지며, 이때 negative와 positive의 overlap은 없도록 합니다. Proposal 생성 시, positive proposal들도 여러 개 생성되며 diversity loss $\mathcal L_{div}$을 통해 다양한 proposal이 생성되도록 합니다.
Mask conditioned reconstruction 모듈에서는 각 proposal을 이용해 original query를 복원하게 됩니다. 이때, 쿼리와 align이 높은 proposal일수록 쿼리를 더 잘 복원할 수 있으리라는 가정을 통해, 모델이 생성한 positive proposal이 쿼리를 잘 복원하도록 학습을 진행합니다. Reconstruction loss $\mathcal L_{rec}$은 positive proposal과 reference 간의 교차 엔트로피 손실로 구성됩니다. 마지막으로 intra-video contrastive loss $\mathcal L_{IVC}$를 제안하는데요, 이는 positive proposal을 통한 쿼리 복원 결과가 negative proposal에 의한 복원이나 전체 영상에 의한 복원 결과보다 좋아지도록 합니다.
각 모듈의 자세한 구성을 이어서 살펴봅시다.
Multiple Positive Proposals Generation
먼저 비디오와 텍스트의 정보를 활용하여 여러 개의 content-dependent 한 positive proposal들을 생성하고 각 proposal들이 서로 달라지도록 하는 diversity loss를 적용해 줍니다. 편집되지 않은 긴 영상이 일반적으로 여러 개의 이벤트를 담고 있으므로, 이러한 방법을 통해 하나의 positive proposal만 생성하는 CNM보다 더 효율적으로 잠재적 이벤트를 찾고 recall을 올릴 수 있다고 합니다.
Feature Extraction. 텍스트 쿼리는 GloVe를 통해 $T=\{t_1, t_2, \cdots, t_M\}\in \mathbb R^{M\times D_T}$와 같이 임베딩합니다. $M$은 단어의 수, $D_T$는 차원을 나타냅니다. 비디오는 사전학습된 3D 합성곱 신경망을 통해 $V=\{v_1, v_2, \cdots v_N\}\in \mathbb R^{N\timesD_V}$와 같이 나타냅니다. $N$은 추출된 video feature의 수, $D_V$는 차원입니다.
Proposal Generation. Transformer를 통하여 멀티모달 데이터를 처리합니다. 먼저, video feature에 학습가능한 [CLASS] 토큰을 붙여 $\hat V=\{v_1, v_2, \cdots, v_N, v_{cls}\}$와 같이 만들어주고, 이를 인코더 $E(\cdot)$로 인코딩된 text feature와 함께 트랜스포머 디코더 $D(\cdot)$에 입력하여 hidden feature $H=\{h_1, h_2, \cdots, h_N, h_cls\}$를 얻어줍니다.
$$H = D(\hat V, E(T))\in \mathbb R^{N\times D_H}$$
이렇게 얻어진 $h_{cls}$ 토큰은 모든 프레임과 단어 feature를 조합하여 생성되는데, 이를 sigmoid 출력을 가진 FCN에 입력하여 가우시안 함수의 중심 $c^p\in \mathbb R^K$와 너비 $w^p\in \mathbb R^K$를 얻습니다. 이때 $K$는 생성될 잠재 positive proposal 후보인 가우시안 마스크 $m^p\in\mathbb R^{K\times N}$의 개수입니다.
$$ m^p_{ki} = \frac{1}{\sqrt{2\pi}(w_k^p/\sigma)}\exp(-\frac{(i/N-c^p_k)^2}{2(w^p_k/\sigma)^2}),\\
k=1, \cdots, K; i=1,\cdots , N$$
$c^p_k, w^p_k$는 $w$번째 positive proposal의 중심과 너비로, 학습가능하며 $\sigma$는 가우시안 커브의 너비를 조정하는 하이퍼파라미터입니다. $K$개의 proposal을 서로 다르게 하기 위해, diversity loss $\mathcal L_{div}$를 도입합니다.
$$ \mathcal L_{div} = ||m^pm^{p\top} – \lambda I||^2_F$$
$||\cdot||_F$는 행렬의 Frobenius norm을 나타내며, $\lambda\in [0,1]$은 proposal 간의 overlap을 조절하는 하이퍼파라미터입니다. 위 손실함수는 proposal들이 적은 overlap을 가지게 하여 똑같은 proposal이 되지 않도록 합니다.
Negative Proposal Mining

CNM은 가우시안 마스크를 단순히 1에서 빼어 positive sample과 반대되는 negative sample을 생성하였으나, 저자들은 negative proposal들이 positive proposal과 동일한 구조를 가지고, 쿼리와 의미적으로 무관하면 안 된다고 지적합니다. 따라서 negative proposal을 생성할 때도 가우시안 함수를 활용하는데요. 커리큘럼 학습 방식을 사용하기 위하여 easy / hard negative를 구분하게 됩니다. 일반적으로 positive proposal과 가까운 negative proposal 일수록 배경과 같이 내용과 무관한 시각적 유사성으로 인하여 positive와 헷갈리기 쉬운 난이도가 어려운 negative proposal인 경향이 있었다고 하며, 따라서 학습 초기에는 positive와 먼 easy negative를, 후반부에는 점차 hard negative를 사용하도록 하였습니다.
Negative Proposal Mining. 그림 3에 나타난 것처럼, 저자들은 positive proposal의 전후로 두 개의 negative proposal을 생성하고, 각 negative proposal의 끝이 영상의 맨 처음과 끝에 해당하도록 하였습니다. 이어서, negative proposal과 positive proposal의 거리 $\eta$를 negative proposal의 너비 $w^{n_1}, w^{n_2}$와 positive proposal의 너비 $w^1, w^2$의 비율을 통해 아래와 같이 정의하였습니다.
$$w^1 = c^p-\frac{w^p}{2}, w^2=1-c^p-\frac{w^p}{2}\\
\frac{w^{n_1}}{w^1}=\frac{w^{n_2}}{w^2}=\eta$$
학습이 진행됨에 따라, $\eta$는 점차 증가하여 모든 negative proposal이 positive proposal에 가까워지도록 합니다.
$$\eta = (\frac{e}{e_{\max})^{0.5} \in [0,1]$$
$e$는 현재 epoch, $e_\max$는 총 epoch를 나타냅니다. negative proposal의 한 끝이 이미 정의되어 있기 때문에, 중심 $c^{n_1}, c^{n_2}$는 $c^{n_1} = \frac{w^{n_1}}{2}, c^{n_2}=1-\frac{w^{n_2}}{2}$와 같이 계산할 수 있습니다.
Mask Conditioned Semantic Completion. 전체 영상을 sample reference $m^r$과 같이 나타낼 때, 영상 전체가 쿼리와 관련된 반복적이고 많은 정보를 포함하고 있으므로, 쿼리와 각 영역의 semantic similarity $R(\cdot)$은 아래와 같을 것으로 가정할 수 있습니다.
$$R(m^p, Q) > R(m^r, Q) > R(m^n, Q)$$
즉, 쿼리와 가장 유사한 영역은 positive 영역이며, 그다음으로 영상 전체, 그다음이 negative 영역이라는 것이죠. 저자들은 원본 쿼리의 1/3을 특정 심볼로 마스킹하고, CNM에서 제안된 mask conditioned trnasformer로 하여금 proposal 영역의 visual feature를 참고하여 해당 영역을 복구하도록 합니다. 마지막으로 교차 엔트로피 함수를 통해 복원된 쿼리와 원본 쿼리 사이의 similarity를 측정하게 되는데, 이때 positive proposal, negative proposal, reference (영상 전체)에 의한 결과를 각각 $\mathcal L^p_{ce}, \mathcal L^{n1}_{ce}, \mathcal L^{n2}_{ce}\in\mathbb R^K$, $ \mathcal L^r_{ce}\in\mathbb R$과 같이 나타냅니다.
모델이 $K$개의 positive proposal을 생성하지만, 실제로 쿼리와 유관한 비디오 세그먼트는 하나뿐이므로, $ \mathcal L^p_{ce}$가 가장 작은 $k*$개의 positive proposal만을 남겨두게 됩니다.
$$k*=\arg \min_k (\mathcal L^p_{ce}[k])$$
쿼리와 연관된 세그먼트는 positive proposal과 reference에만 포함되므로, 최적화에는 $\mathcal L^p_{ce}[k*]$와 $ \mathcal L^r_{ce}$만 사용합니다. 최종 reconstruction loss $\mathcal L_{rec}$은 아래와 같습니다.
$$\mathcal L_{rec}= \mathcal L^p_{ce}[k*] + \mathcal L^r_{ce}$$
또한, positive proposal, reference, negative proposal과 쿼리의 유사도가 앞서 정의한 가설과 같은 관계를 가질 수 있도록 Intra-video Contrastive Loss $\mathcal L_{IVC}$를 정의합니다.
$$\mathcal L_{IVC} = \max( \mathcal L^p_{ce} [k*]- \mathcal L^r_{ce}+\beta_1, 0) + \\
\max( \mathcal L^p_{ce} [k*] – \mathcal L^{n_1}_{ce}[k*] + \beta_2, 0 )+\\
\max( \mathcal L^p_{ce} [k*]- \mathcal L^{n_2}_{ce}[k*] + \beta_2, 0) $$
$\beta_1, \beta_2$는 $\beta_1 < \beta_2$를 만족하는 하이퍼파라미터입니다. 이 손실함수는 positive proposal의 $\mathcal L_{ce}$가 reference의 그것보다 적어도 $\beta_1$배 작도록 합니다.
Model Training and Inference
Training. 모델은 앞서 소개한 세 가지 손실함수의 가중합으로 학습됩니다. $\alpha$는 각 손실함수의 가중치 하이퍼파라미터입니다.
$$\mathcal L = \mathcal L_{rec} + \alpha_1\mathcal L_{IVC} + \alpha_2\mathcal L_{div}$$
Inference. 먼저, $K$개의 positive proposal들로부터 중심 $c^p$와 너비 $w^p$를 얻습니다. 이 중 가장 positive 같은 top-1 prediction을 고르기 위한 두 가지 방식이 있는데, loss 기반 방식과 vote 기반 방식입니다.
Loss 기반 방식에서는, 앞서 정의한 교차 엔트로피 손실 $ \mathcal L^p_{ce}$이 각 proposal의 신뢰도를 평가하는데 활용되며, 따라서 가장 낮은 loss를 가진 proposal이 최종적으로 사용되게 됩니다. Vote 기반 방식에서는 앙상블 기법에서 영감을 받은 방식으로, $K$개의 positive proposal로 voting을 수행합니다. 각 positive proposal의 IoU를 계산하여 겹친 proposal이 가장 많은 proposal이 선정되게 됩니다. 이거 좀 신선하네요.
마침내 선정된 $k*$번째 positive proposal에 대하여, 예측 시작시간 $st$와 끝 시간 $en$은 다음과 같습니다.
$$ st = \max(c^p_{k*} – w^p_{k*}/2, 0)*\text{Duration}\\ en = \max(c^p_{k*} + w^p_{k*}/2, 1)*\text{Duration}$$
Experiments
Datasets
저자들은 Charades-STA와 ActivityNet Captions에서 실험을 진행했습니다.
Charades-STA. 학습과 테스트 각각 5338/1334 개의 영상과 12408/3720개의 영상-쿼리 쌍을 가지고 있습니다.
ActivityNet Captions. 학습/검증/테스트 split이 각각 10009/4917/5044개의 영상과 37417/17505/17031개의 쌍으로 구성되어 있습니다.
Evaluation Metric
Recall@n, IoU=m을 지표로 사용합니다. 특정 IoU에서의 recall을 평가하는 지표입니다.
Implementation Details
Data Preprocessing. 각 영상에서 8 프레임마다 특징을 추출하였고, ANet의 경우 C3D, Charades의 경우 I3D로 feature를 추출했습니다. 텍스트는 pre-trained GloVe word2vec을 사용해 임베딩했고, 최대 길이는 20, vocab size는 8000을 사용했습니다.
Model Settings. 트랜스포머와 mask conditional 트랜스포머는 인코더와 디코더 모두 4개의 어텐션 헤드를 가진 트랜스포머 3 계층을 적용했고, hidden state의 차원은 256을 썼습니다. Positive proposal의 수 $K$는 ANET에서는 5, Charades에서는 8을 썼고, 하이퍼파라미터는 다음과 같습니다. $\sigma=9, \lambda=0.15, \beta_1=0.1, \beta_2=0.15, \alpha_1=1$ 또한, 모델이 $\alpha_2$에 민감하여, Charades에서는 1, ANET에서는 0.1이나 1을 썼다고 합니다. 최적화는 Adam에 learning rate 0.0004를 썼습니다.
근데 막상 코드 돌리려고 보니까 $\lambda$도 민감하다고 저자들은 0.13을 썼으며, 성능 원복이 안되면 0.12~0.135까지 바꿔가며 해보라고 하더군요..ㅋㅋ…
Comparisons to the SOTA
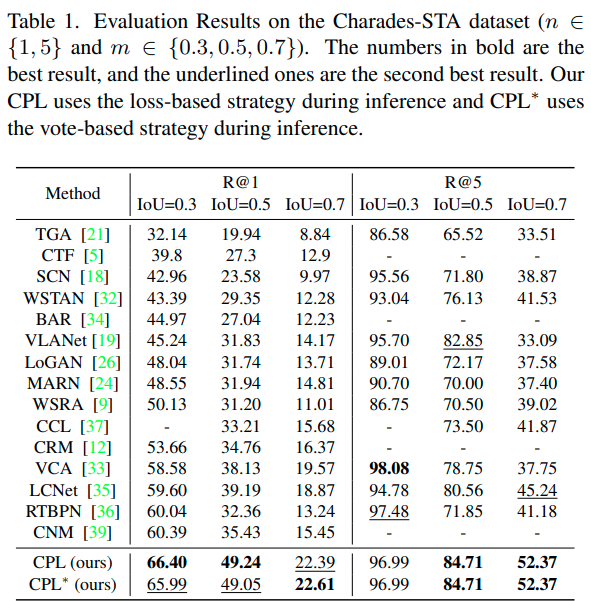

그냥 CPL은 loss 기반 방식, CPL*은 vote기반 방식입니다. Charades에서는 두 방법이 비슷한 성능을 보인 반면, ANET에서는 vote 기반이 확실히 좋은 성능을 보여주었네요. $\alpha_2$는 positive proposal의 다양성을 조절할 수 있는 하이퍼파라미터인데요. 상황에 따라, 쿼리가 여러 이벤트 간의 복잡한 관계를 담고 있으면 오히려 다양성이 낮은 것이 나을 수도 있어, 이에 대한 유연성을 조절할 수 있다고 합니다.
이외에 별다른 분석은 없는데, 논문에서 자주 비교하는 CNM과 성능 차이가 Charades에서는 큰 반면 ANET에서는 또 비슷하네요. 다만 vote 기반 방식이 성능이 확 올라가서 이 부분은 또 신기합니다.
코드를 먼저 돌려보고 논문을 읽게 되었는데 코드를 돌리면서 보니 ANET 기준으로 성능이 3%씩은 확확 바뀌어서 조금 아쉽다는 생각이 듭니다.
Ablation Study
Charades에서의 loss 기반 방법을 통해 비교 실험을 수행했습니다.
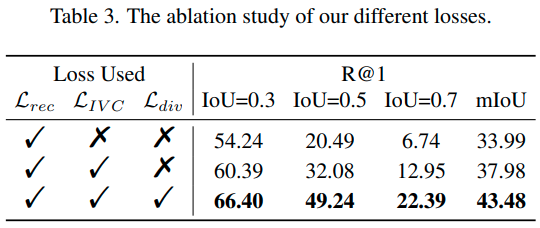
Effectiveness of different losses. 저자들이 제안한 각 loss가 모두 성능을 확연히 올려주고 있습니다.
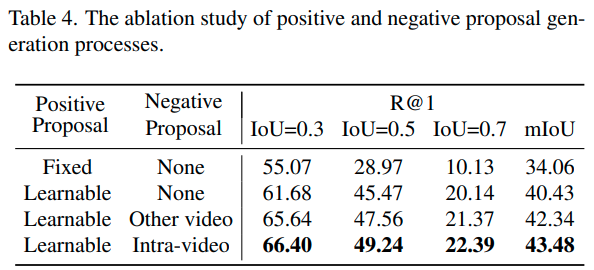
Effectiveness of Proposal Generation. 저자들이 여러 번 강조한 것처럼, positive proposal 생성을 학습 가능한 방식으로 바꾸기만 해도 성능이 크게 올라갔습니다. 이어서 negative proposal도 활용하는 편이 확실히 성능이 올랐는데, 이때 같은 영상에서 생성해 주는 편이 성능을 확실히 올려주는 모습이네요.
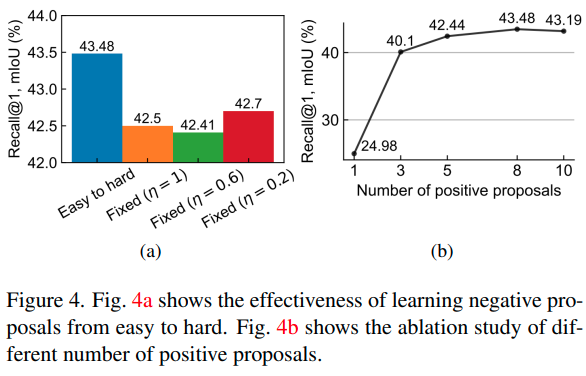
한편, negative proposal의 난이도를 $\eta$를 통해 조절해 주는 방식도 성능 향상을 불러오는 모습을 그림 4에서 볼 수 있습니다. negative proposal이 항상 positive로부터 먼 경우 ($\eta=0.2$)보다 가까운 경우($\eta=1$) 성능이 낮은 것을 볼 수 있는데, 이는 positive proposal의 정확도가 낮은 학습 초반부터 hard negative가 들어간 결과로 보인다고 합니다.
Effect of multiple Positive Proposals. 그림 4의 우측에서 보이는 것처럼, positive proposal의 수는 8에서 최고의 성능을 보였습니다.
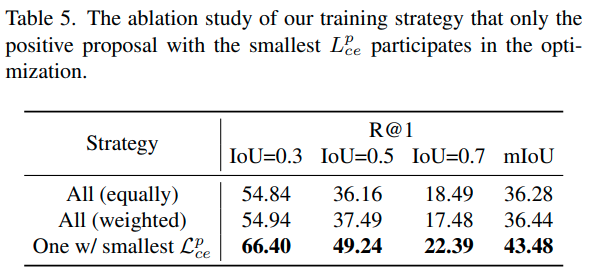
표 5에서 $K$개의 positive proposal 중 일부만 사용하는 학습 전략이 유효함을 확인할 수 있는데요. 모든 psitive pair를 사용하거나, 순위에 따른 가중치를 부여해 사용하는 것보다도, 가장 loss가 작은 것만 사용하는 게 성능이 10 이상 좋았습니다.
Qualitative Results

정성적 결과입니다. 파란색의 P1과 P2 막대가 각각 CPL이 생성한 top1, top2 positive proposal입니다. 전체적으로 top1인 P1이 P2보다 좋은 정확도를 보여주며, 비교 모델인 SCN보다도 정확합니다. (c)를 보면, 여러 이벤트의 복잡한 관계가 담긴 쿼리에 대해서는 CPL의 성능이 안 좋은 모습인데, 이는 reconstruction accuracy가 낮아져 발생하는 문제로 보인다고 합니다. (근데 애초에 어려울 수밖에 없는 상황에서 안 좋은 모습을 보여준 거라, 그다지 모범적인 failure case 분석은 아닌 것 같습니다.)
Conclusion
저자들은 새로운 weakly supervised video moment localization 방법인 Contrastive Proposal Learning (CPL)을 제안하였습니다. 이 모델은 학습가능한 가우시안 함수를 이용해 여러 개의 positive proposal을 생성하여 고품질, 고효율로 positive proposal을 생성하였습니다. 또한, 같은 영상에서 negative sample을 난이도별로 생성하여 커리큘럼 학습을 도입하였고, reconstruction loss를 통해 proposal들의 reliability를 평가하여 가장 좋은 proposal을 선정하였습니다.
약지도학습 기반의 TSGV 논문은 처음 읽었는데, Temporal Action Localization도 그렇고 약지도학습이 대세이면서, 정말 창의력 싸움인 것 같습니다. 동시에 코드도 돌려보면서 느낀 것이, 하이퍼파라미터 조금 바뀌거나 랜덤 시드, 하드웨어에 따라 성능 변화가 너무 크다는 생각도 듭니다. 어찌하기 어려운 문제이지만 참 답답할 때가 많은 것 같습니다.
읽어주셔서 감사합니다.
리뷰 잘 봤습니다.
우선 Grounding 분야에서 text feature를 인코딩할 때 Glove와 같은 워드 임베딩 알고리즘을 사용하는 것이 일반적인가요? CLIP을 굳이 사용하지 않은 이유가 좀 궁금합니다.
그리고 Negative Proposal 만드는 부분이 이해가 좀 안되는데 단순히 positive proposal 전후로 사용하는 이유는 뭔가요? 앞뒤는 비교적 유사성이 높은거 같은데 뭔가 분포간의 통계적 거리를 사용하는 것이 아니라 굉장히 manually 하게 mining 하는 거 같아 의미가 있는지 궁금하네요.
안녕하세요. 임근택 연구원님.
1. Grounding 분야를 저도 최근에야 읽기 시작해서 GloVe를 사용하는 것이 일반적이다 아니다라고 말씀드리기는 어렵지만, 제가 본 논문들에서는 CLIP visual encoder의 임베딩과 유사성을 볼 생각이 아니라면 GloVe를 사용한 경우가 많은 것 같습니다. 마침 이번 주 현우님 리뷰에서 관련한 내용이 있어 찾아보니, CLIP이 specialized language models in NLP task에 비해 부족하다는 연구가 있다고 합니다.
(Chang et al., A Survey on Evaluation of Large Language Models, arxiv 2023)
2. 제 서술에 오해의 여지가 있었던 것 같습니다. negative proposal을 positive proposal의 바로 앞, 뒤로 만드는 것이 아니라, positive proposal의 전, 후 영역 전체 (즉, 영상 시작 ~ positive proposal 시작 / positive proposal 끝 ~ 영상 끝)에서 생성하는데, 이때 학습의 진행도에 따라 처음에는 영상에서 먼 영역에서 negative proposal을 생성하고, 학습이 진행될 수록 가까운 영역에서 생성되도록 하는 것 입니다.
negative가 positive에 가까울수록 positive와 배경과 같은 요소가 유사하여 hard negative가 되는데, 학습 초기에는 positive와 거리가 멀어 쉬운 negative, 후반에는 어려운 negative로 학습하도록 하여 성능을 향상했다고 합니다.
감사합니다.