안녕하세요, 스물여섯 번째 X-Review입니다. 이번 논문은 2019년도 CVPR에게재된 Group-wise Correlation Stereo Network 논문입니다. 그럼 바로 리뷰 시작하겠습니다. ⛹?♀️
1. Introductio
스테레오 매칭이란 두 이미지 쌍간의 pixel을 matching함으로써 depth를 추정하는 task를 의미합니다. 전통적인 스테레오 매칭 방법론들은 다음의 4 단계를 따릅니다. 1) matching cost계산, 2) cost aggregation, 3) disparity prediction, 4) post processing
각 단계를 간단히 설명하자면, matching cost를 계산하는 것은 좌 우 영상의 pixel(혹은 patch)에 대한 유사도를 계산하는 것이라고 보면 됩니다. 이렇게 matching cost를 계산한 것을 쌓아서 cost volume을 생성하게 되고 이를 좀 더 의미있는 정보를 갖도록 가공하는 과정이 cost aggregation 과정입니다. 이렇게 가공된 cost volume에서 disparity를 시차를 예측하게 되고 이후 생성된 disparity map을 통해 더 부드럽게 만든다거나, , , 등등의 후처리 과정을 거치게 됩니다.
학습 기반의 방법론들은 feature representation도 전통적인 방법론과 다르고, matchign된 cost를 aggregation하는 방식도 다릅니다. DispNetC라고 하는 딥러닝 기반의 초기 방법론 같은 경우 CNN을 통해 추출한 좌 우 feature map들 간의 상관관계를 게산하여 correlation volume을 구축하여 이 correlation volume에서 disparity를 예측하는 방식을 사용했으며 이후 GC-Net이나 PSMNet 같은 경우는 단순히 좌 우 feature map을 concat하여 볼륨을 생성하고 이 볼륨을 3D convolution 태움으로써 aggregation하게 되었습니다. 하지만, 방금 언급한 이런 방법론들 같은 경우 몇몇 단점이 존재합니다. DispNetC 같이 full correlation을 사용하는 경우 두 feature간의 유사도를 측정하는 효율적인 방식이라고 볼 수 있겠지만, 각 disparity level에 대해서 상관관계를 계산하다보니 많은 정보를 잃게 됩니다. (같은 channel을 갖는 feature끼리만 상관관계를 계산하기 때문) 또한 concat하여 볼륨을 생성하는 방식은 유사도를 측정하기 위한 cost aggregation 과정에서 3D conv를 사용했어야 했기 때문에 많은 수의 파라미터가 요구되었죠.
그래서 본 논문에서는 앞서 언급한 연구들의 단점을 극복하는 group-wise correlation이라고 하는 단순하지만 효율적인 연산을 제안하게 됩니다. 간단하게 설명하자면, 특징 추출기를 통해 multi-level의 feature map들을 얻게 되고 이들을 concat하여 f_l, f_r를 얻어냅니다. 그 다음이 feature들은 채널 축에 대해 여러 그룹으로 분할되고 i번째 그룹에 대항하는 좌 우 feature map들에 대해 correlation을 계산함으로써 모든 disparity level에 대해 그룹별 correlation map을 얻게 됩니다. 이렇게 얻어낸 correlation map은 gwcNetC에서의 full correlation map과는 다르게 정보 손실을 피할 수 있는 것이죠.
본 논문의 주요 contribution은 다음과 같습니다.
- 더 나은 유사도 측정을 위한 cost volume을 구성하기 위해 group-wise correlation 방식 제안
- 추론 시간을 늘리지 않고 성능을 향상시키기 위해 stacked 3D hourglass refinement 네트워크
- 좋은 성능
- real-time 동작 가능
2. Group-wise Correlation Network
본 논문은 PSMNet의 확장 버전인 group-wise correlation stereo network(이하 GwcNet)을 제안합니다. PSMNet은 특징 추출기를 통해 추출한 feature들을 concat하여 concatenation volume을 생성하고 3D convolution을 통해 aggregation하면서 스크레치 레벨로 학습하게 됩니다. 이 경우 computation cost가 크게 되는데 이에 반해 DispNetC의 경우 channel 별로 correlation 을 계산함으로써 효율적이지만 정보 손실이 큰 볼륨을 구추갛게 되었죠. 본 논문의 저자는 이 PSMNet과 DispNetC의 단점을 극복하면서 장점만을 가져온 GwcNet을 제안합니다.
2.1. Network architecture
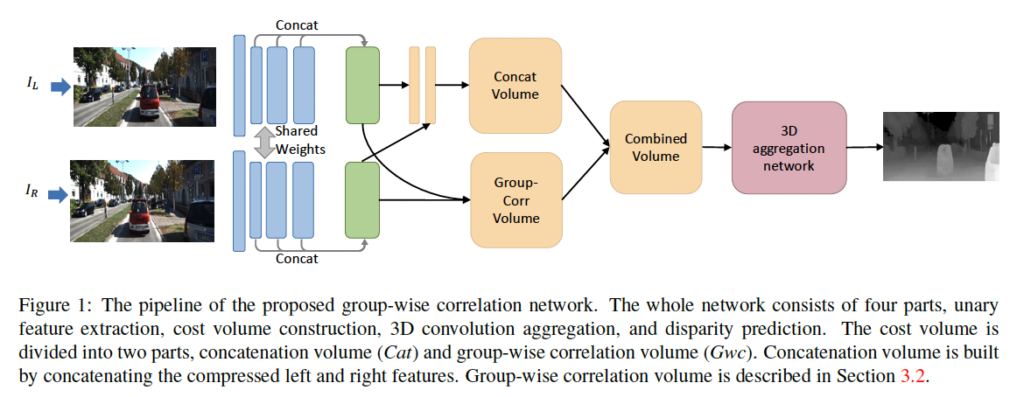
group-wise correlation network의 구조는 Figure1에서 확인할 수 있습니다. 네트워크는 총 4개의 파트로 나눠 볼 수 있습니다. 1) feature extraction, cost volume 구축, 3D aggregation, disparity 예측으로 말이죠.
각 모듈에 대해 간단히 살펴보도록 하겠습니다. 먼저 feature extraction 단계에서는 PSMNet에서 사용한 ResNet-like 네트워크를 그대로 사용하였습니다. 그림 1에서의 파란색 블록에서 확인할 수 있듯이 마지막 feature map들인 conv2, 3, 4는 채널 축으로 concat되어 320 channel을 갖는 feature map(초록색 블록)이 output으로 나오게 됩니다.
cost volume은 두 부분으로 나눠서 구성되는데, concatenation 볼륨과 group-wise correlation 볼륨입니다. 먼저 concatenation 볼륨같은 경우 PSMNet의 볼륨과 동일하지만, 두 convolution을 타고 나와 PSMNet의 feature map보다 더 적은 채널 수인 12채널 feature map이 나오게 됩니다. 또 본 논문에서 제안한 group-wise correlation volume같은 경우는 아래에서 더 자세히 서술하도록 하겠습니다. 그래서 이 두 볼륨들은 concat되어 3D aggregation 네트워크의 입력으로 들어가게 됩니다.
3D aggregation 네트워크는 이웃한 disparity와 pixel들의 feature를 aggregate하면서 cost 볼륨을 개선하게 됩니다. aggregate한다는 표현은 단순히 초기 cost volume을 가공하여 더 좋은 표현력을 갖도록 하는 것이라고 이해하시면 되겠습니다. 이 aggregation 과정은 4개의 3D convolution, batchnorm, ReLU 활성함수로 구성된 hourglass 모듈입니다.
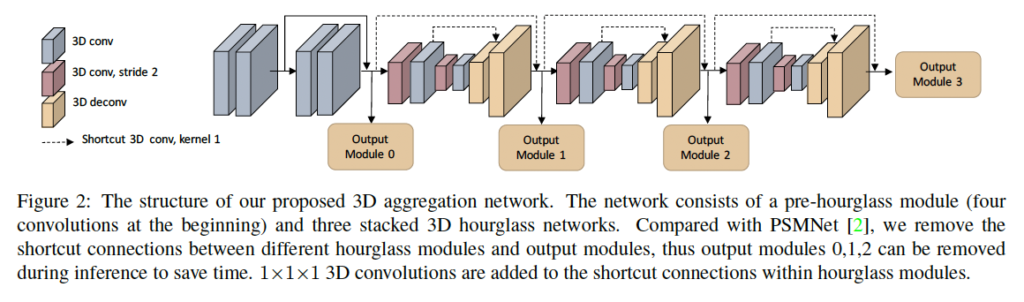
위 그림 2에서도 확인할 수 있듯이 hourglass 모듈을 3번 쌓아서 3D hourglass network를 구성하였습니다. 각 모듈마다 각각의 output이 나오게 되고 각 output은 dispairty map을 예측하게 됩니다.
2.2. Group-wise correlation volume
이제, 저자가 제안한 group-wise correlation 볼륨에 대해 살펴보도록 하겠습니다. 추출된 좌 우 feature들 f_l, f_r은 원본 영상의 1/4 해상도를 갖고 있습니다. 앞에서도 계속 언급하긴 했지만, 한 번 더 하자면 이전 연구들은 좌 우 feature map들을 disparity 축에 대해 (channel 축임) concat하거나 correlation을 계산하는 식으로 볼륨을 생성하였다고 하였죠. 하지만 이 두 볼륨들은 계산량이 많이 든다거나, 정보 손실이 크다는 각각의 단점을 갖고 있었습니다. 이런 이슈를 해결하기 위해 group-wise correlation 방식을 제안하였습니다. 이전의 correlation 볼륨과 concatentation 볼륨의 장점만을 가져온 것이죠.
기본 아이디어는 feature를 몇 개의 그룹으로 나누고 그룹 바이 그룹으로 correlation map을 계산하는 것입니다. feature extractor에서 추출한 feature가 N_c개의 channel을 갖고 있다고 할 때 이 채널을 N_g개의 그룹으로 나눕니다. 그럼 각 feature group은 N_c / N_g 채널을 갖게 되겠습니다. g번째에 그룹에 해당하는 feature group g_l^g, f_r^g는 gN_c/N_g, gN_c/N_g + 1, . . . . , gN_c/N_g + (N_c/N_g-1)번째 채널들로 이루어져 있겠죠. 예를 들어 20채널을 갖는 feature map을 5개의 그룹으로 나눴다고 할 때 2번째 그룹에 해당하는 채널들은 5, 6, 7, 8이라는 의미입니다.
무튼 Group-wise correlation은 아래 식3을 통해 계산됩니다.
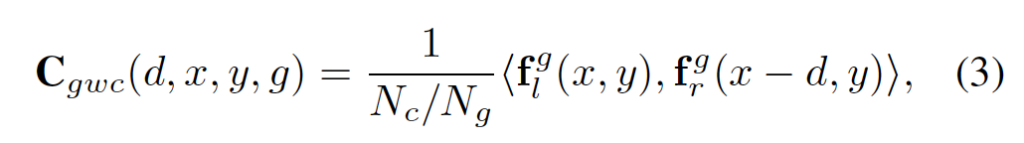
<.,.>은 내적을 의미하며 output으로 나온 cost volume 크기는 (D_{max}, H/4, W/4, N_g입니다. D_{max}는 최대 시차이며 N_g은 feature group 수 입니다. 이후에 이 cost volume은 아래에서 설명드릴 3D aggregation network에서 disparity map을 regression할 때 input으로 들어가게 됩니다.
추가적으로 저자는 더 나은 성능을 위하여 group correlation cost volume과 앞선 concatenation volume을 결합해 사용하였습니다. 이에 대한 ablation study는 실험 단에서 다루도록 하겠습니다.
2.3. Improved 3D aggregation module
PSMNet에서는 더 나은 context feature를 학습하기 위해 stacked hourglass 구조가 제안되었습니다. 이 네트워크게 기반하여 본 논문의 저자는 group-wise correlation에 적합하도록, 추론 속도를 높이도록 몇 중요한 수정을 하였습니다. 이 3D aggregation 구조는 fig2와 아래 table1에서 확인할 수 있습니다.

먼저, 저자는 한 개의 output module을 추가하였습니다. 이는 fig2의 output module 0에 해당합니다. 이 0번째 output에 대해 계산된 loss로 학습하면서 네트워크는 앞단의 layer에 대한 더 좋은 feature를 학습하게 됩니다. 두번째로는 서로 다른 output module가느이 residual connection을 제거하였습니다. 이로써 추론 시에 output module 0, 1, 2이 제거되고 3만 사용되게 되면서 계산량을 줄인 것이지요. 세번째로 1x1x1 3D convolution을 통한 shorcut connection을 각 hourglass 모듈에 추가하였습니다. 이는 fig2의 dash line에 해당합니다. 이는 추가적인 computation cost 없이 성능을 향상하기 위함입니다.
2.4. Output module and loss function
앞에서 3D aggregation network에서 각 hourglass모듈마다 output이 나온다고 했었습니다. 이 각각의 output에 대해 2개의 3D conv가 적용되며 output으로는 1채널의 4D 볼륨이 나오게 됩니다. 이 볼륨을 upsampling한 다음 softmax함수를 통해 확률 볼륨으로 바꾸게 됩니다. upsampling하는 이유는 이 output volume을 통해 최종 dispairty를 예측할 것이고 이를 위해 원본 영상 크기로 맞춰주는 것이라고 이해하시면 됩니다. 최종 disparity는 아래 식 4를 통해 추정됩니다.
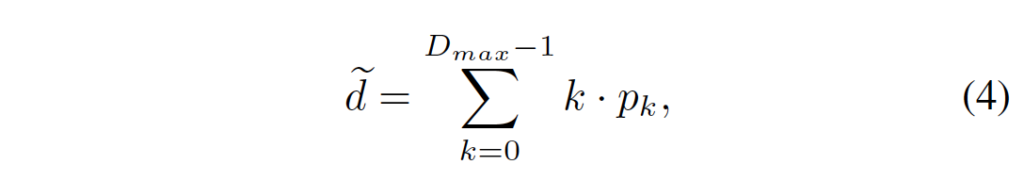
k는 disparity level을 의미하며 P_k는 그 k에 해당하는 disparity에 대한 확률을 의미합니다. 총 4개의 output모듈이 나오게 되니 예측된 disparity map도 \tilde{d}_0, \tilde{d}_1, \tilde{d}_2, \tilde{d}_3으로 4개가 나오게 됩니다. 이에 대해 최종 loss는 아래 식 5와 같이 계산됩니다.
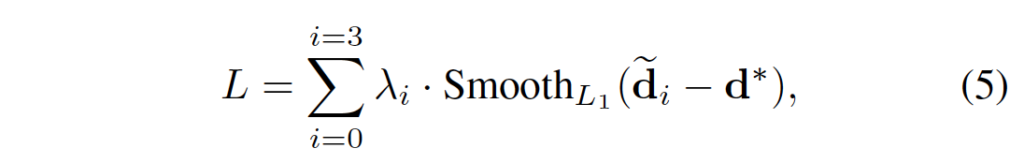
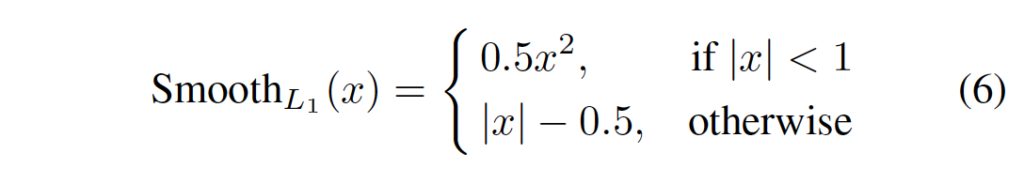
\lambda_i는 i번째 disparity 예측에 대한 계수이며, d*은 gt disparity map을 의미합니다. gt disparity map과 예측한 disparity map간의 smooth l1 loss function을 통해 loss가 계산됩니다.
3. Experiment
실험은 합성 데이터셋인 Scene Flow 데이터셋과 real 데이터셋인 KITTI에서 수행되었습니다. Scene Flow 데이터셋에 대한 평가지표는 end-point-error(EPE)로 gt disparity와 예측한 dispairty간의 평균 픽셀 차이를 의미합니다. KITTI 2012의 평가 지표로는 occluded되지 않은 영역(Noc)과 모든 영역(All)에 대해 잘못 예측한 pixel의 비율과 epe이며, KITTI 2015에서는 gt disparity와 예측한 disparity간의 차이가 3픽셀 이하를 에러로 간주하고 이 outlier의 비율을 배경, 전경, all에 대해 측정하였습니다.
Real dataset인 KITTI 2012, 2015 데이터셋에 대해서는 Scene Flow 데이터셋에서 먼저 사전학습 한 다음 finetuning하였습니다.
3.1. The effectiveness of Group-wise correlation
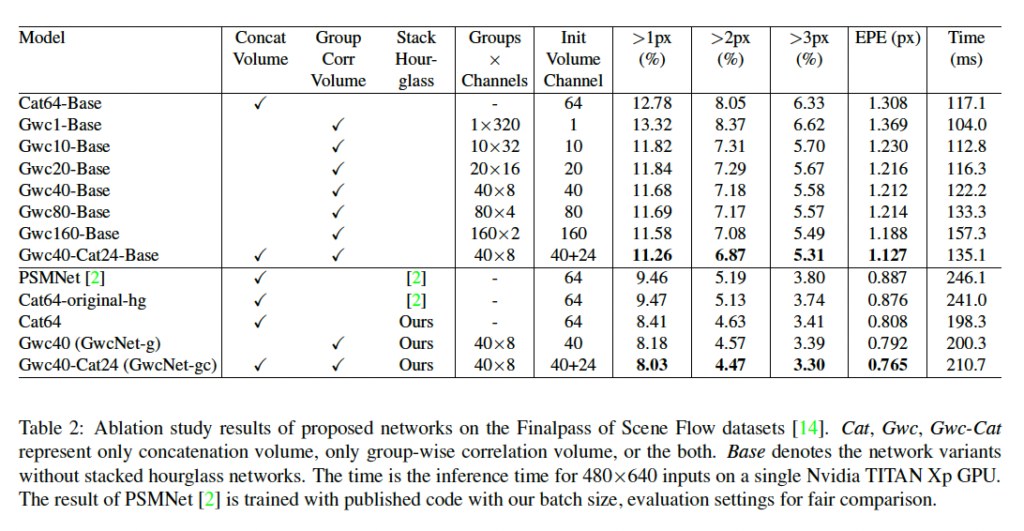
먼저, 저자가 제안한 group-wise correlation의 효과에 대한 실험을 살펴보도록 하겠습니다. 실험 결과는 표 2에서 살펴볼 수 있는데, Cat-base와 Gwc-Base, Gwc-Cat-Base는 각각 베이스 모델에 오직 concatenation 볼륨만을 사용한 것, 오직 group-wise correlation volume만 사용한 것 마지막으로 둘 다 사용한 것에 해당합니다.
여기서 베이스 모델이란 stacked hourglass network를 제거하였고 오직 output module 0만을 출력하는 모델입니다. 우선 각 볼륨을 어떻게 구성하느냐에 따른 성능 결과를 비교하기에는 초기 채널 수가 cat과 gwc간의 약간의 차이가 존재하기 때문에 공정한 비교가 어렵겠지만 초기 볼륨 채널이 1인 Gwc1-base를 제외하고는 나머지 Gwc 볼륨을 사용한 모델이 성능이 더 좋은 결과를 보입니다. 또 Gwc-Base 네트워크의 성능은 그룹 수가 증가함에 따라 증가하는 것을 확인할 수 있지만 그룹 수가 40보다 커지게 되면 성능 향상이 미미해집니다. 이때 저자는 메모리 사용량과 성능 사이의 trade-off 를 고려하여 각 그룹이 8개의 channel을 갖는 40개의 그룹을 최종 네트워크 구조로 가져갔습니다.
추가적으로 correlation volume과 concatenation volume을 결합해 사용했을 때가 성능이 더 향상되는 결과를 보입니다.
3.2. Improved stacked hourglass
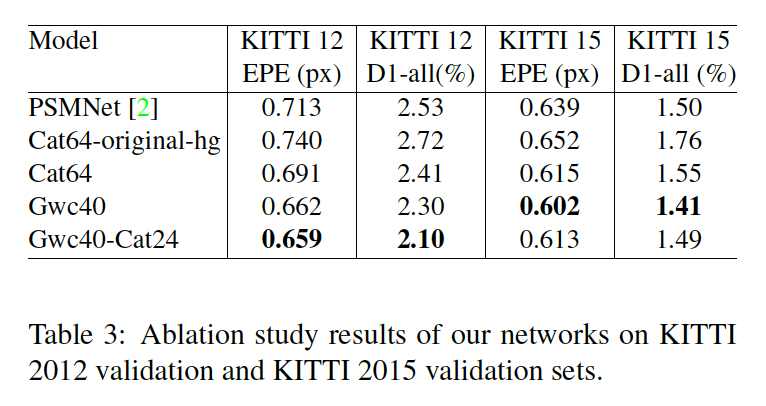
추가적으로 PSMNet에서 제안한 stacked hourglass network에서 몇 변경사항을 추가한 것에 대한 ablation study입니다. 표2의 구분선 아래 실험이 scene flow 데이터셋에서 ablation study이며, table3이 KITTI 데이터셋에서의 ablation study 결과입니다. 기존 PSMNet에서의 stacked hourglass에서 수정을 한 결과는 2, 3행에서 보시면 되는데 약간의 성능 향상을 보이네요.
3.3. KITTI 2012 and KITTI 2015
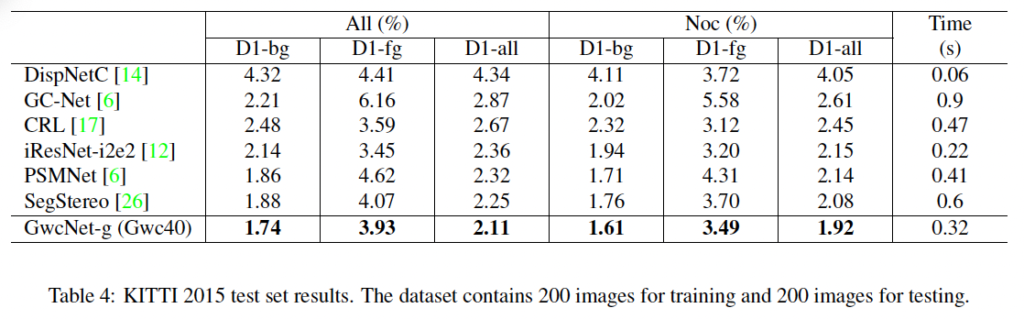
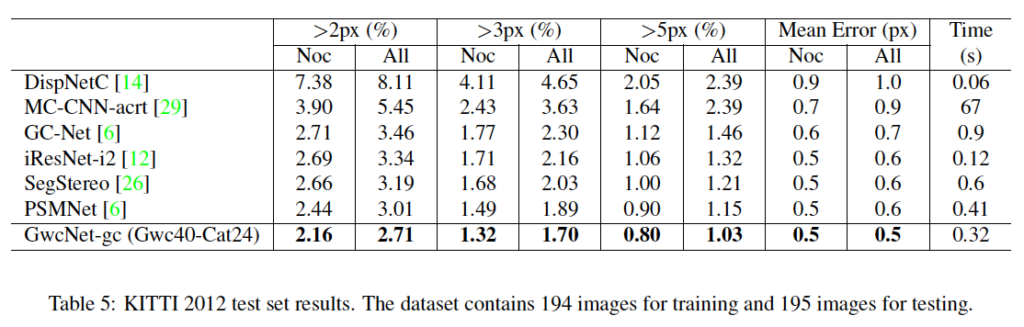
KITTI 2012, 2015에 대한 실험 결과입니다. 아무래도 stereo matching에서 딥러닝을 적용한 초창기 모델이다보니 비교군이 적고, 최근 방법론에 비해 성능도 많이 떨어지긴 합니다.
표3의 ablation study에서 concatenation volume을 함께 사용했을 경우가 KITTI 데이터셋에서는 사용하지 않았을 때보다 성능이 하락한 점으로 보아 KITTI 2012에서는 최종 모델로 group-wise correlation volume만 사용하였습니다. 결과적으로 2012, 2015에서 둘 다 그 당시 sota를 달성하였네요.

마지막으로 세 데이터셋에서의 정성적 결과를 확인하고 마무리하도록 하겠습니다. 맨 위쪽 순으로 scene flow, 2012, 2015데이터셋 순서며, 맨 왼쪽 순으로 원본 영상, 예측한 disparity map, error map에 해당합니다. 타 방법론의 정성적 결과는 보이지 않고 있어 비교는 어렵습니다.
안녕하세요, 좋은 리뷰 감사합니다.
stereo matching을 위한 유사도를 측정하는 방법을 개선하는 방법도 새로운 것 같습니다. 이쪽 task를 잘 몰라서 생소하네요.
1. 제가 해당 task에 대한 팔로우업이 안 돼서 질문을 드리자면, 2D conv 연산으로도 커버가 가능한 task라고 생각했습니다. 근데 3D conv 연산을 사용하는 것을 사용하는데 이는 기하학적 요소를 고려하기 위한 것인가요?
2. 실험 결과 섹션 중 KITTI2012 & KITTI2015에서 사용되는 평가지표들은 어떤 오차를 의미하나요? foreground, background를 의미하는 것 같은데 간단하게망 설명해주시면 감사하겠습니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 3D conv연산을 사용하는 이유는 spatial 차원뿐만 아니라 disparity 차원에 따른 feature 정보를 aggregate하기 위해 사용한다고 보면 되겠습니다. .. .. 이게 좀 초창기 논문이라 3D conv를 쓰고 있는데 요즘은 잘 안쓰려고 하는 편입니ㅏㄷ.
2. KITTI 2012의 평가 지표로는 occluded되지 않은 영역(Noc)과 모든 영역(All)에 대해 잘못 예측한 pixel의 비율과 epe입니다. epe는 end-point-error(EPE)로 gt disparity와 예측한 dispairty간의 평균 픽셀 차이를 의미합니다.
KITTI 2015에서는 gt disparity와 예측한 disparity간의 차이가 3픽셀 이하를 에러로 간주하고 이 outlier의 비율을 배경, 전경, all에 대해 측정하였습니다.
안녕하세요. 좋은 리뷰 감사합니다.
group-wise correlation이라는 방법에 대해 새롭게 알게 되어 흥미롭네요. 리뷰 내용에 대해서도 궁금한 부분이 있는데 output module는 residual connection을 제거하여서 추론 시에 output module 1, 2, 3이 제거되고 4만 사용되게 되면서 계산량을 줄인 것이라고 하셨는데, 여기서 output module 4는 어디에 나와있는 걸까요? figure를 봤을 때 보이지 않아 질문 드립니다.
댓글 감사합니다.
오타입니다 . . 0, 1, 2가 제거되고 3이 사용된다고 썼어야 했는데 하나씩 밀려쓴 것 같네용
수정해두겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
PSMNet과 같은 이전 방법론의 문제가 cost aggregation 과정에서 3D conv를 사용해야했기 때문에 많은 계산 비용이 발생한다는 점이라고 말씀해주셨습니다. 그런데 본문에서도 마찬가지로 역시 두 볼륨을 합칠 때 3D conv를 사용하고 있는데 이는 기존 PSMNet에 비해 더 적은 수의 채널을 가진 feature map을 출력을 가지기 때문에 계산 비용 측면에서 크게 문제가 되지 않는 것인가요 ??
그리고 제안하는 main 모듈이 group wise correlation volume과 PSMNet 대비 개선된 3D aggregation 모듈이라고 생각이 드는데, 이 두 모듈이 성능에 미치는 영향에 대해 비교한 ablation study는 없었을까요?
감사합니다.
안녕하세요. 댓글 감사합니다.
더 적은 수의 채널을 가진 feature map을 출력하기 때문이 아닌, 기존 PSMNet보다 3D conv를 덜 사용함으로써 계산 비용을 줄였습니다.
또, 언급해주신 ablation study 같은 경우 group-wise correlation에 대한 실험이 3.1파트에, PSMNet 대비 개선한 aggregation 모듈에 대한 실험이 3.2에 적혀져 있습니다 . . .. .