
안녕하세요, 허재연입니다. 오랜만에 Model Calibration 논문을 가져왔습니다. Model Calibration 문제를 이전에 한번 다룬 적이 있었는데, Confidence값을 이용한 Active Learning의 정확한 uncertainty를 측정하기 위해서는 calibration에 대한 이해가 필요하다는 것을 느꼈습니다. 이전에 리뷰했던 논문[Guo et al 2017. ICML]의 경우 상당히 예전(2017년) 논문이기에 최근 사용되는 모델들에 대한 분석도 궁금증을 갖고 있어서 이를 다룬 논문을 선택했습니다. 리뷰 시작하겠습니다.
Introduction
근래에 딥러닝 신경망은 급속도로 발전했고, 다양한 컴퓨터 비전 task에 사용되기 시작했습니다. 그럼 우리는 이 성능 좋은 모델을 바로 실제 산업에 사용하면 될까요? 정확도 이외에는 고려할 것이 없을까요? 비전 모델은 의료 진단, 기상 예측, 자율주행 등 오작동에 대한 위험 부담이 큰 사례에 접목되기 시작됐습니다. 모델의 잘못된 예측으로 인해 인명 피해나 큰 경제적 손실 등이 일어날 수 있기 때문에, 우리는 단순이 성능 좋은 모델이 아닌, 믿을 수 있는 예측을 하는 딥러닝 모델이 필요합니다. 만약 딥러닝 모델이 확신할 수 없는 예측을 하고 있다면, 이에 대한 정보를 제공해야 합니다. 모델의 예측 확신도에 대한 정확한 정보를 제공받을 수 있다면 의료 진단 모델이 확신하지 못하는 상황에 전문의에게 판단을 맡길 수 있고, 자율주행 시스템에서 운전자에게 운전을 위임하는 형태로 위험도를 낮출 수 있을 것입니다.
신뢰할 수 있는 좋은 모델은 구체적으로 어떤 특성을 가질까요? 본 논문에서 다루는 이미지 분류를 예로 들면, 모델의 성능(accuracy)과 모델의 prediction confidence가 일치하면 믿을 수 있는 모델이라고 합니다. 모델의 confidence를 통해 얼마나 모델이 예측 결과에 확신하고 있는지 확인할 수 있으니까요. 하지만 [ICML2017] On Calibration of Modern Neural Networks라는 논문에서는 ResNet과 같이 발전된 형태의 CNN이 잘못된 예측 결과를 과신하는(overconfidence) 경향을 지적했습니다. 모델의 성능 향상에만 초점을 맞추어서 발전시켰지만, LeNet과 같은 초기 모델보다 ResNet같은 발전된 모델의 calibration 성능이 훨씬 떨어진 것입니다. Model calibration이라 함은, 모델의 예측 confidence가 실제 모델의 정확도를 반영할 수 있도록 교정(calibration)하는 것을 뜻합니다. 본 논문은 이전 CNN기반 비전 모델들과 그 이후에 등장한 ViT 모델 등에 대해 다양한 분석을 시도합니다. 그리고 다음과 같은 사실을 발견할 수 있었다고 합니다.
- MLP-Mixer, Vision Transformer와 같은 최근의 non-convolutional model들의 경우 이전의 모델들과 비교해 좋은 calibration을 보이며 distribution shift에도 강건하다.
- In-distribution(학습 데이터와 동일한 분포의 데이터셋으로 평가하는 것) calibration 성능의 경우 모델 사이즈가 증가하며 약간 저하되지만, 정확도 향상으로 얻는 이점이 더 크다.
- distribution shift(학습 데이터와 다른 형태의 데이터셋으로 평가하는 것)에서는 in-distribution 상황과 다르게 모델 사이즈가 증가하면 calibration 성능이 좋아진다.
- distribution shift 상황에서는 accuracy와 calibration이 함께 증감하는 경향을 보이니 accuracy를 높이는 방향으로 최적화하는것이 calibration에도 도움이 된다
- 모델 크기, 사전학습 기간, 사전학습 데이터셋 크기는 결정적으로 calibration 성능 차이를 완전히 설명하지 못한다
실험에 대해 설명하기 앞서 평가 지표 등을 짚고 넘어가겠습니다.
완전하게 calibration된 이상적인 분류 모델은 다음과 같이 표기할 수 있습니다. 모델의 prediction confidence(분류모델 softmax의 output)가 accuracy와 일치하는 상황입니다.
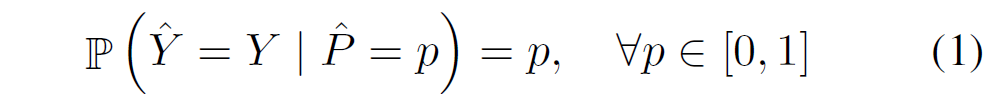
하지만 실제 딥러닝 모델들은 그렇지 못합니다. 분류 모델의 calibration 성능을 나타내는 시각적인 지표로 reliability diagram이 있습니다. Reliability diagram의 경우 0~1까지 confidence값을 N개의 균등한 bin으로 나눈 후 해당 bin의 평균 accuracy와 confidence 차이를 시각적으로 표시한 것입니다.
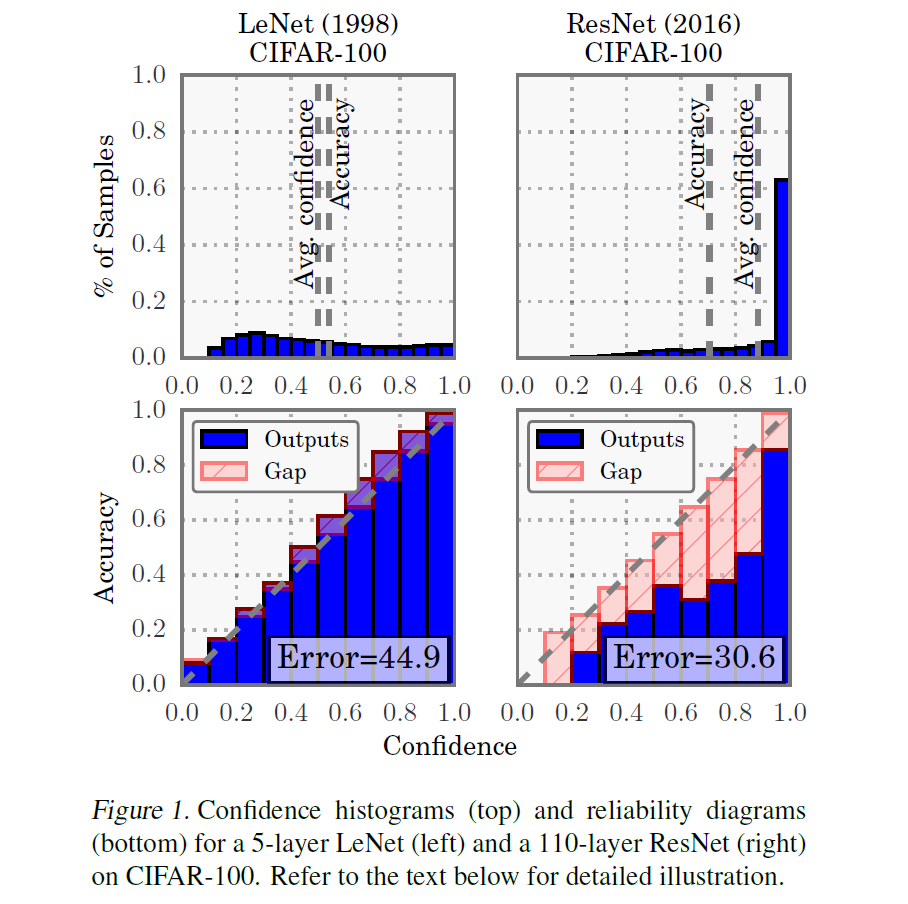
위 그림은 [Guo et al 2017. ICML]논문에 실렸던 Figure중 하나로, LeNet과 ResNet의 reliability diagram(아래 라인)을 나타내고 있습니다. 잘 calibration된 모델의 경우 output인 파란 막대 그래프가 항등함수 y=x라인을 따르는 것이 이상적이지만, 그렇지 않을 때 gap을 분홍색 영역으로 나타낸 것입니다. 분홍색 영역이 큰 ResNet(오른쪽)이 calibration 성능이 좋지 않다는 것을 알 수 있죠.
Reliability diagram을 정량적 지표로 나타낸 Expected Calibraion Error(ECE)라는 지표가 있습니다. 이는 정답과 예측값이 같은 경우(예측 모델의 정확도)와 confidence의 차이를 평균낸 것으로, bin으로 구간을 나누었을 때 (bin에 대한 예측 모델 정확도)-(bin에 대한 모델 confidence값들의 평균)을 다시 bin들에 대해 평균낸 것입니다.
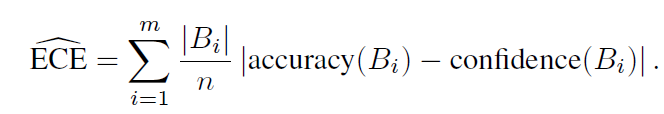
m은 bin의 개수, n은 전체 데이터 개수, Bi는 bin의 sample 수 입니다. 예를 들어, 데이터 1000개에 대해서 200개씩 5개의 집단으로 나눈다고 하면 M=5이고, (200개 m번째 집단 Bm에 대한 평균 accuracy – m번째 집단의 평균적인 예측 confidence)를 계산한 다음 평균을 구한다고 생각하시면 됩니다. acc(Bi)은 집단 Bi에 대한 예측 모델 정확도를, conf(Bi)은 집단 Bi에 대한 모델 확률값들(confidence)의 평균을 의미합니다. ECE 지표는 calibration 성능을 측정할 때 자주 사용되는 지표입니다. 이름이 Error이니 ECE값이 낮을수록 calibration 성능이 높다고 받아들이시면 됩니다.
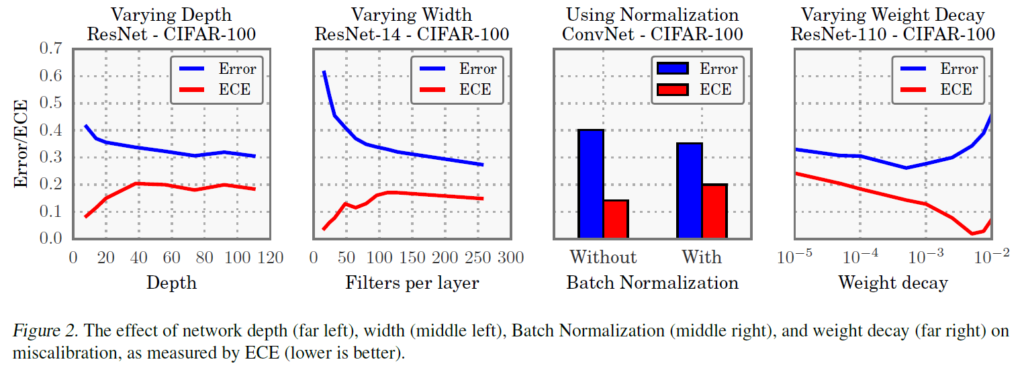
이전 논문[Guo et al 2017. ICML]에서의 경우, ResNet에서 실험한 결과 다음과 같은 경향성을 파악했습니다.
- Depth : 모델의 깊이가 깊어질수록 error? ECE?
- Width : 깊이를 고정하고 파라미터 늘려서 실험. layer 당 filter 늘려보니 error? ECE?
- Batch Norm 적용하면 error? ECE?
이번에 리뷰하는 논문에서는 ResNet뿐만 아니라 다양한 모델들에 대해 폭넓은 실험을 수행합니다. 딥러닝의 다양한 조건들이 calibration에 미치는 영향을 파악하기 위해 convolutional / non-convolutional model, supervised, weakly supervised, unsupervised, zero-shot 모델들까지 폭넓게 실험했습니다. MLP-Mixer, ViT, BiT(대규모 데이터로 사전 학습된ResNet기반 구조), ResNext-WSL(인스타그램 해시태그로 학습된 weakly supervised ResNext model이라고 합니다), SimCLR(ResNet기반으로 SimCLR 방식을 사용해 self-supervised 사전 학습한 모델. 사전 학습의 영향 확인), CLIP(zero-shot을 위해 만들어진 모델이라고 합니다, 백지오 연구원님 리뷰에 자세히 다루어져 있습니다), 이전 연구들과 비교를 위한 AlexNet이 사용되었다고 합니다. CLIP을 제외하고는 모두 ImageNet으로 학습되었다고 합니다.

out-of-distribution(OOD) 상황 등을 확인하고 싶어 다양한 데이터셋으로 accuracy 및 calibration을 평가했다고 합니다. ImageNetV2(기존 이미지넷과 비슷하게 수집), ImageNet-C(인공적으로 영상처리 기법을 가한 이미지넷. distribution shift가 발생), ImageNet-R(그림, 만화, 조각상 등으로 이루어진 데이터셋. 이미지넷에서 실제 새 사진을 가지고 있다면 해당 데이터셋은 새 그림 등을 포함) .. 등의 데이터셋이 사용되었습니다.

성능 지표는 전반적으로 ECE가 사용되었습니다.
In-Distribution Calibration

다양한 모델 구조들에 대한 경향입니다. MLP-Mixer, ViT, BiT 등 최근 모델들은 좋은 성능을 보일 뿐만 아니라 좋은 calibration을 보이고, zero-shot model인 CLIP도 굉장히 좋은 calibration을 보입니다. 그림에서 보면 convolutional 계열인 WSL, SimCLR는 calibration 성능이 조금 떨어지는것을 확인할 수 있습니다. 표에서 표시된 도형의 크기는 모델의 크기라고 생각하시면 됩니다

[Guo et al 2017. ICML]논문에서는 calibration 성능을 개선시키는 방법 중 하나로 temperature scaling을 언급했었습니다. 이는 분류 모델에서 softmax를 거치기 이전 logit vector들을 temperature라는 상수값으로 나눠준 것입니다. softmax를 태우기 전에 prediction값들 간의 차이를 조정하는 것이죠.
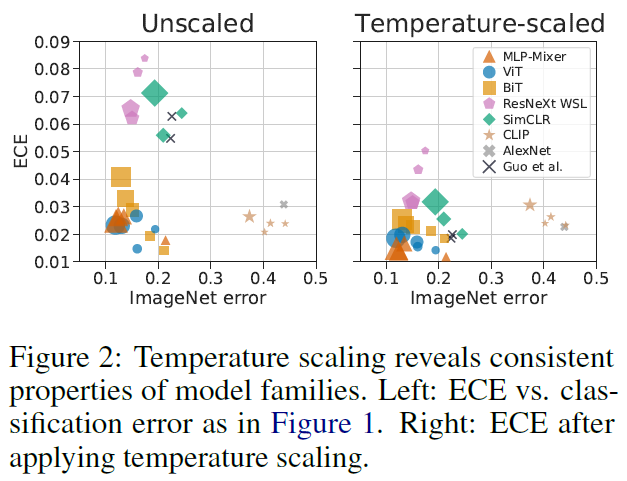
Figure2의 왼쪽을 보시면 MLP-Mixer, ViT, BiT등 최근 모델들이 이전 모델들보다 calibration이 개선된 것을 볼 수 있으며, zero-shot model인 CLIP도 accuracy대비 좋은 calibration을 보여줍니다. temperature scaling을 거친 이후에도 예전 모델들이 최신 모델들의 calibration 성능을 잡을 수 없었다고 합니다.
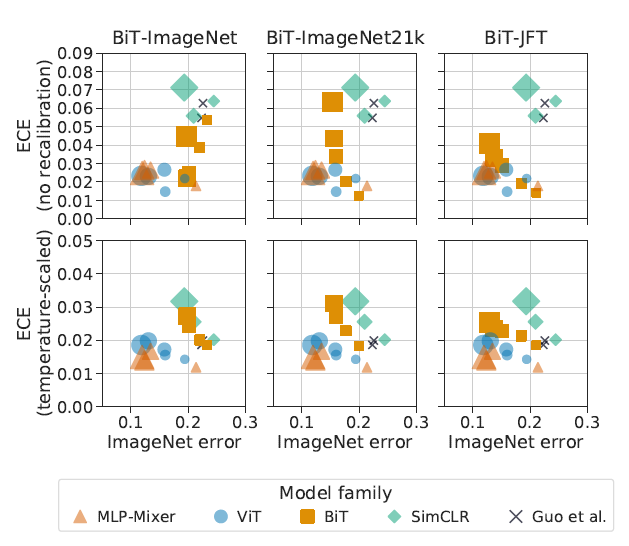
이후에는 사전학습 양에 대한 실험도 수행되었습니다. 데이터셋 size는 ImageNet<ImageNet21k<JFT입니다. 사전학습 데이터셋의 크기가 증가하며 모델의 성능(분류 정확도)는 향상되었지만, calibration 성능에는 큰 영향을 미치지 못했습니다. 결국, 모델 구조(MLP-Mixer, ViT등 inductive bias가 적은 non-convolutional 모델이 convolutional 계열보다 좋은 calibration을 보여줌)를 제외하고 모델 크기, 사전학습 양으로는 calibration 성능 추이를 제대로 설명할 수 없다는 결론을 내립니다.
Under Distribution Shift
safety-critical한 실세계 적용을 고려할 때, 실제 만나게 되는 상황이 학습 데이터와 다를 수 있습니다. 따라서 distribution shift가 발생한 상황에 대해서도 적절한 예측을 할 수 있어야 합니다. 일반적으로 학습 및 검증에 분포가 다른 데이터셋을 사용하여 distribution shift를 가하면 calibration 성능과 분류 정확도가 감소합니다. 여기서는 ImageNet으로 학습하고 ImageNet-C로 평가를 진행합니다. in-distribution 상황에서는 (모델 구조보다 직접적인 영향을 미치지는 않지만)모델이 클수록 calibration 성능이 저하되는 경향이 있었는데, OOD(out of distribution)상황에서는 반대로 모델이 커질수록 정확도와 calibration이 좋아지는 경향을 확인했다고 합니다. 그리고 큰 모델일수록 distribution shift에 강건함을 확인했습니다.
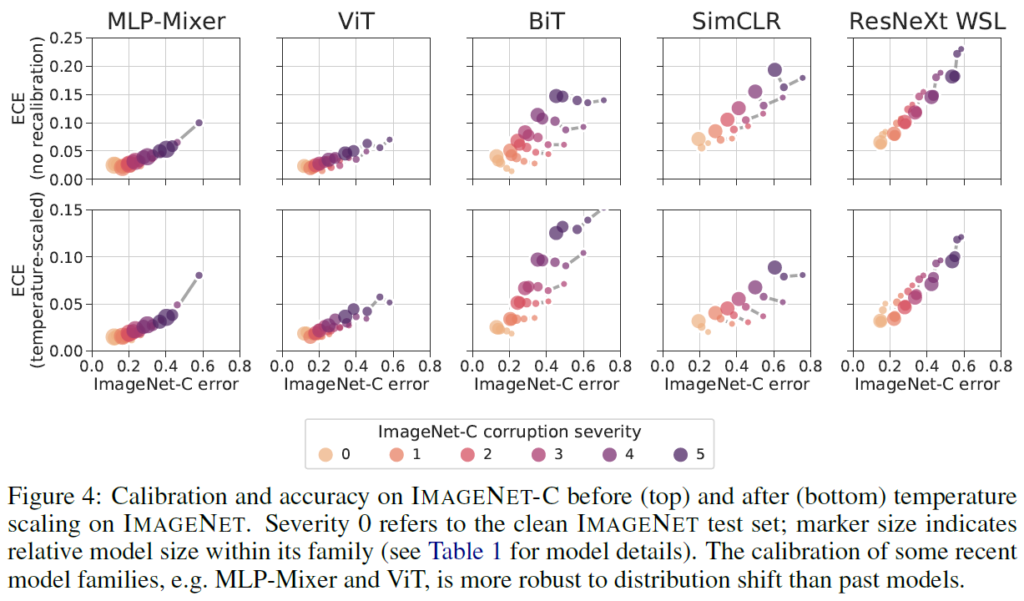
ImageNet-C corruption severity가 커질수록 shift의 강도가 강해집니다. 모델이 예측하기 더욱 어려워집니다(0의 경우 그냥 imagenet test set이라고 생각하면 됩니다).
표에서 MLP-Mixer나 ViT의 경우 모델의 크기에 따라서도, severity(distribution shift)에 대해서도 calibration error에 큰 차이가 없었습니다(오히려 분류 정확도에 영향이 있었습니다). 하지만 BiT, SimCLR, ResNeXt WSL와 같은 convolutional model의 경우 distribution shift에 크게 영향을 받았으며, model size에도 크게 영향을 받았습니다.
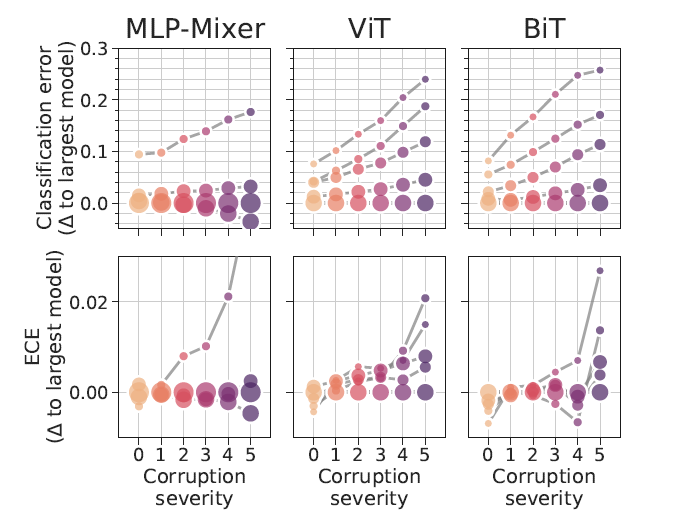
위 표에서도 모델 크기의 영향을 확인할 수 있습니다. 모델 사이즈가 클수록 ECE 및 분류 정확도에 영향이 적으며, 특히 MLP-Mixer가 calibration error의 편차가 적습니다.
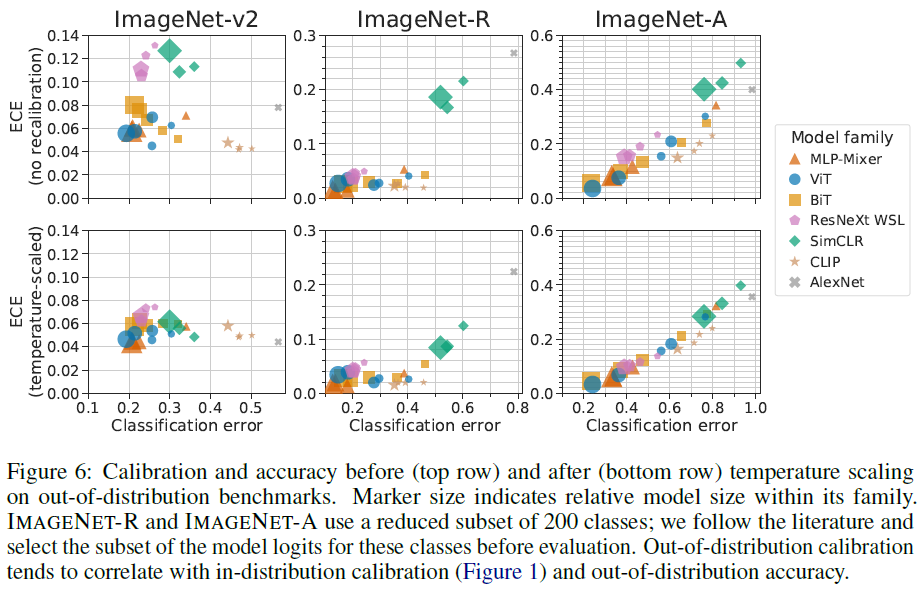
다른 distribution shift를 가한 경우에 대해서도 실험이 수행되었습니다. 윗줄은 calibration을 가하지 않은 것이고 아랫줄은 temperature scaling으로 보정을 한 결과입니다. 마찬가지로, accuracy와 calibration이 상관관계를 보이는 것을 확인할 수 있습니다.
Pitfalls and limitations
calibration을 측정하는 과정에서 bias가 발생할 수 있기 때문에, calibration을 정확히 측정하는것은 challenging한 과정이라고 합니다.
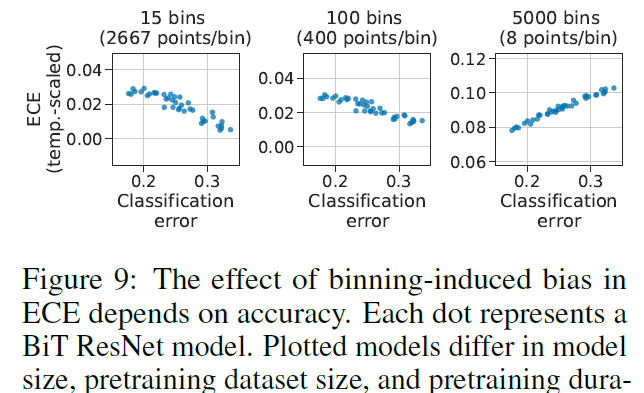
ECE 계산을 위해서는 confidence에 대해 0~1사이 bin으로 나눈 다음 bin 범위에 해당하는 샘플들을 할당시켜 계산하는데, bin을 나누는 과정에서 bias가 생길 수 있으며, 나누워진 bin sample 수에 대해서도 bias가 생길 수 있습니다. bin을 많이 나누다 보면 각 bin 안의 sample 수가 적어질수도 있는데, 위 Fig9에서 확인하듯이 bin을 너무 잘게 쪼개면 bin당 평균 샘플 수가 너무 적어져 올바른 통계적 특성을 잃을 수 있습니다. 따라서 ECE-classification 경향성이 아예 뒤집혀버릴 수도 있습니다. 이러한 trade-off를 잘 고려해야 한다고 합니다.
Conclusion
저자들은 SOTA 이미지 분류 모델들의 calibration에 대해 광범위한 분석을 수행했습니다. 결론적으로 최근 모델들은 accuracy 향상 측면에 집중하여 발전했음에도 불구하고 distribution shift 상황에 대해서도 비교적 잘 calibration된다는 것을 확인했습니다. ViT나 MLP-Mixer와 같은 최신 모델들은 ICML2017에서 지적되었던 ’발전된 형태의 딥러닝 모델들이 점점 calibration이 안 좋아지고 있다’는 경향을 따르지 않음을 알 수 있었습니다.
실험 결과에 따르면 모델 크기나 사전학습량과 같은 단순한 요소들만으로는 모델 간 calibration 차이 경향을 완전히 설명할 수 없으며, 모델 구조가 calibration에 있어 주요한 영향을 미침을 확인했습니다. 특히 non-convolutional 모델인 MLP-Mixer와 Vision Transformers는 in-distribution 및 OOD 상황에서 calibration이 매우 잘 됨을 확인할 수 있었습니다(이전 연구들에 의하면, self-attention을 활용한 ViT가 out-of-distribution 상황에 대해 강건성이 있다고 합니다). 모델 구조의 inductive bias가 calibration 및 OOD 강건성 및 generalization에 미치는 영향에 대한 연구가 향후 수행될 필요가 있다며 논문이 마무리됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
평가지표로 ece와 error가 사용되는 것 같은데, 이 둘에 대한 차이가 무엇인지 궁금합니다. 또, fig2 아래에 depth, width,batchnorm에서의 error와 ece 경향성에 대한 설명에서 네모 박스로 보이는 건 화살표로 생각하면 되는 걸까요 ? !?
마지막으로 사전학습 양에 대한 실험에서 모델 크기로는 calibration 성능 추이로 설명할 수 없다는 결론을 내렸다고 하셨는데, 바로 아래에 in-distribution 상황에서는 모델이 클수록 성능이 저하되는 경향이 있다고 적혀있어 무엇이 맞는 결론인지 의문이 듭니다.
감사합니다.
안녕하세요, 정윤서 연구원님. 질문에 대해 하나씩 답변 드리겠습니다.
1. error는 말 그대로 모델의 성능을 뜻합니다. 분류 모델의 경우 error는 잘못 분류한 비율을 뜻합니다. error=5%는 분류 정확도(accuracy)=95%라고 생각하시면 될 것 같습니다.
ECE는 모델의 분류(본래 모델의 task) 성능이 아닌, 딥러닝 모델의 calibration 성능입니다. error값이 낮더라도(분류기 성능이 좋더라도) calibration 성능이 좋지 못하다면(잘못된 예측에 대해 overconfident하다면 )리뷰 초반에 언급한 바와 같이 해당 모델의 confidence 확률값을 있는 그대로 사용하기에 위험합니다.
Fig2의 경향성을 작성할 때 위아래 화살표로 경향성을 정리했는데, 네모 박스로 보인다면 텍스트가 깨진 듯 싶습니다. 다음과 같이 생각하시면 됩니다:
– Depth : 모델의 깊이가 깊어질수록 error? ECE? -> error는 감소(분류성능 개선), ECE는 증가(calibration 성능은 하락)
– Width : 깊이를 고정하고 파라미터 늘려서 실험. layer 당 filter 늘려보니 error? ECE? -> error는 감소(분류성능 개선), ECE는 증가(calibration 성능은 하락)
– Batch Norm 적용하면 error? ECE? -> error는 감소(분류성능 개선), ECE는 증가(calibration 성능은 하락)
2. [Guo et al 2017. ICML] 논문의 실험에 의하면, 다른 변인들을 모두 고정시켰을 때 모델 크기를 증가시키면(filter 수나 모델 깊이 증가) 분류기의 분류 성능은 좋아지지만 calibration 성능은 나빠지는 것을(ECE증가) 확인했습니다. 해당 실험은 이번 논문의 분류에 따르면 In-distribution 상황이었습니다.
하지만 Under Distribution Shift부분에서 설명했듯이, in-distribution 상황에서는 (모델 구조보다 직접적인 영향을 미치지는 않지만)모델이 클수록 calibration 성능이 저하되는 경향이 있었는데, OOD(out of distribution)상황에서는 반대로 모델이 커질수록 정확도와 calibration이 좋아지는 경향을 확인했다고 합니다. 그리고 큰 모델일수록 distribution shift에 강건함을 확인했습니다.
data distribution의 변화에 따라 모델 크기와 calibration 성능의 관계가 바뀌기 때문에, 모델 용량이 calibration을 결정짓는다고 보기는 힘듭니다. 그리고 모델 크기에 따라 calibration 성능에 약간의 변화가 있는 것은 맞지만, 이보다는 모델 구조(convolutional / non-convolutional)가 훨씬 결정적인 영향을 미치게 됩니다.
정리하자면 모델 크기가 calibration 성능에 어느정도 영향이 있는것은 맞지만 이 영향이 모든 상황에서 일관적이지 않고, 모델 구조 등 다른 변인보다 영향력이 적다고 이해하시면 될 것 같습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
본문의 In-Distribution Calibration 부분에서 질문이 있습니다. 실험 결과를 통해서 모델 크기, 사전 학습 양으로는 calibration 성능 추이를 제대로 설명할 수 없고 모델 구조로는 어느 정도 분류가 가능하다고 해주셨습니다. 특히 non-convolutional 모델이 convolutional 계열보다 좋은 calibration 성능을 보여준다 하셨고 이에 대한 이유로 inductive bias을 언급해 주셨는데 논문에서는 inductive bias에 대해서만 언급을 하나요?? Non-convolutional 모델이 convolutional 모델보다 데이터 분포에 대한 편향이 적어서 새로운 데이터 분포에 대한 일반화 성능이 높아지고 calibration 성능에도 좋은 영향을 끼칠 것 같다고 생각은 하지만 다른 기타 요인도 있을 것 같은데 이와 같은 언급은 없는지 혹은 재연님만의 의견이 있는지가 궁금합니다.
감사합니다.
안녕하세요, 정의철 연구원님. 답변 드리도록 하겠습니다.
저자들은 다양한 변인에 대한 calibration 성능에 대해 분석 결과는 제시하지만 이에 대한 해석에 대해서는 소극적인 모습을 보입니다. ‘인과관계를 명확히 추론할수는 없지만 ~~한 경향을 보인다’라는 문장이 반복됩니다. inductive bias에 대한 언급도 non-convolutional model이 확연히 개선된 calibration을 보이는 현상을 어떻게든 설명하려는 시도로 보이고, 그 이외의 언급은 딱히 없습니다. 저도 [Guo et al 2017. ICML]논문을 읽을 때까지만 해도 학습 과정에서 GT label값의 one-hot vector에 overfitting되기 때문에 모델 성능이 좋아질수록(모델 구조 증가, 배치 정규화 적용 등) overconfidence 경향이 두드러진다고 개인적으로 생각하고 있었는데, MLP-Mixer와 ViT계열이 모델 성능 및 calibration 성능에서도 우수한 결과를 보이는 이유에 대해서는 딱히 짐작가는 부분이 없습니다. 다만, 이후 model confidence값을 이용한 Active Learning 방법을 설계할 때 uncertainty의 과소평가를 피하기 위해 convolutional 계열은 피해야 할 것 같습니다.
감사합니다.