제가 이번에 리뷰할 논문은 zero-shot 기반의 6D Pose Estimation 방법론입니다. Unseen object를 대상으로 6D Pose Estimation을 수행하는 방법론을 서베이하다 찾게 된 논문입니다.
< Abstract >
해당 논문은 새로운 객체에 대해 zero-shot 방식으로 pose를 추정하는 연구이며, pose label이 존재하는 데이터 셋이나 카테고리 별 CAD 모델이 필요하지 않다는 장점이 있습니다. 본 논문은 zero-shot 방식을 pose estimation에 정의하고, self-supervised 방식의 transformer를 이용하는 새로운 방식을 제안하였으며, 최근 공개된 CO3D라는 데이터를 현실적인 조건을 고려하여 변형하였습니다. 또한, 해당 논문에서 설정한 베이스라인 방법론과 비교하여 해당 논문에서 제안한 방법론이 높은 정확도를 보임을 실험적으로 보여주었습니다.
< Introduction >
저자들은 사람의 경우 학습한 적 없는 다른 외형의 2가지 객체가 주어졌을 때, 사람은 이전에 학습하지 않았음에도 두 객체 사이의 공간적 관계를 이해하고, 필요할 경우 정렬을 할 수 있다는 점을 들어 문제를 정의합니다. 즉, pose에 대한 annotation이 없어도 동일 카테고리의 두 객체 사이의 pose 차이를 인식할 수 있도록 하는 것 입니다.
기존 6D Pose Estimation 연구들의 경우, intra-category 에 대한 변동이 없는(카테고리별 하나의 대상 객체) instance-level의 방식은 모든 객체의 카테고리에 대해 각각의 labeled pose가 주어진 학습 데이터가 존재하며 대상 객체에 대한 CAD 모델에 접근이 가능하였습니다. 그러나 사람은 이러한 정보가 없어도 pose 정보를 파악할 수 있으며, 이에 대해 저자들은 인간이 관련 객체를 대응시키기 위해 여러 category에 걸쳐 일반화되는 객체의 일부분을 이해하기 때문이며 이 과정을 거쳐 기본 기하학적 요소를 사용하여 객체 간의 공간적 관계를 이해할 수 있다고 주장합니다. 이때 인간이 대략적인 깊이 정보를 추정할 수 있으며, 여러 관점에서 물체를 판단할 수 있다는 점에 착안하여 방법론을 제안합니다.
해당 논문은 test category의 pose label을 본 적 없으면서도 category 별 CAD 모델에 의존하지 않는 ‘zero-shot’ pose estimation을 제안합니다. 먼저 ViT를 이용하여 feature를 추출한 뒤, self-supervised 방식으로 large scale 데이터를 학습하여 동일 카테고리 내의 두 인스턴스 사이의 의미론적 대응(semantic correspondences)을 구합니다. 이후, 의미론적 대응의 가중치를 사용하여 객체 인스턴스 중 하나에 대한 최적의 view를 선택(해당 논문은 test 대상에 대해 multi-view로 설정합니다)하여 대략적인 pose offset을 추정합니다. 의미론적 대응과 최적의 view를 선택한 후, depth map을 이용하여 해당 의미론적 위치에서 각 객체에 대한 sparse point clouds를 생성합니다. 마지막으로 강인한 least squares estimation 방식을 이용하여 point cloud를 변환하여 정렬 최종 pose를 구합니다.
해당 방법론은 동일 category 내의 외관 차이가 있는 다양한 객체에 대한 고해상도 이미지를 제공하는 CO3D 데이터 셋에서 평가를 수행합니다. 이때 해당 방법론과 비교를 위해 다양한 baseline을 설정하였다고 합니다.
contribution을 정리하면,
- 실제 환경을 반영한 설정을 통해 3차원 인지를 위한 새롭고 challenge한 세팅을 공식화
- zero-shot category-level의 새로운 방법론을 제안
- CO3D 데이터 셋에 대한 실험을 통해 베이스라인이 작동하지 않을 때 해당 논문에서 제안한 방식이 용이하게 작동함을 입증
< Zero-shot Category-Level Pose Estimation >
해당 파트는 zero-shot Pose Estimation 설정을 공식화합니다. 먼저 일반적인 6D Pose Estimation은 객체의 이미지만 제공되는 일부 기준 프레임에 대해 객체의 offset(translation and rotation)을 추정하며, reference 프레임은 암묵적(supervised 방식의 경우 프레임에 대해 pose label이 정의됨) 방식이나 명시적(reference 이미지) 방식으로 정의됩니다. 이러한 두 가지 경우 모두 pose estimation은 상대적인 문제이며, zero-shot 관점에서는 reference 프레임이 label로 주어질 수 없습니다. 따라서 pose estimation 문제를 동일 카테고리의 두 인스턴스를 정렬하는 것을 문제로 정의합니다.
Zero-shot 설정
저자들은 N개의 view에서 촬영한 target object에 대한 이미지와 두 객체에 대한 depth 정보를 이용하는 것으로 설정하였으며, 이러한 제약 조건은 open-world에서 학습을 위한 CAD 모델과 pose 정보가 없으며, depth 카메라가 부착되어 있고 객체와 상호작용을 위해 다양한 view에서 이미지를 수집하는 실제 환경을 반영한다고 합니다. (multi-view와 depth 정보를 이용해야 한다는 제약 조건이 있으나 이는 현실의 로봇 조작 관점에서 충분히 합리적이라고 주장합니다.) 표현을 정리하면
- reference 이미지: I_\mathcal{R}
- target 이미지: I_{\mathcal{T}_1:N} = \{ I_{\mathcal{T}_1} ... , I_{\mathcal{T}_N} \}, I_i∈\mathbf{R}^{H⨉W⨉3} (N개의 multi-view)
- 모든 이미지에 대한 depth map: D_i∈\mathbf{R}^{H⨉W}
- 두 객체 사이의 6D Pose offset을 출력할 모델: \mathcal{M}
- 두 객체 사이의 offset:
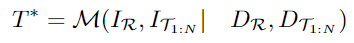
마지막으로, target view 사이의 변환 관계를 쉽게 알 수 있으며(에이전트를 이용할 경우 변환 정도를 설정하여 움직이므로 두 target view 사이의 변환 관계를 구할 수 있음) reference 이미지 I_\mathcal{R}와 target view사이의 정렬이 주어질 경우, reference 인스턴스를 target 인스턴스와 정렬할 수 있습니다.
< Methods >
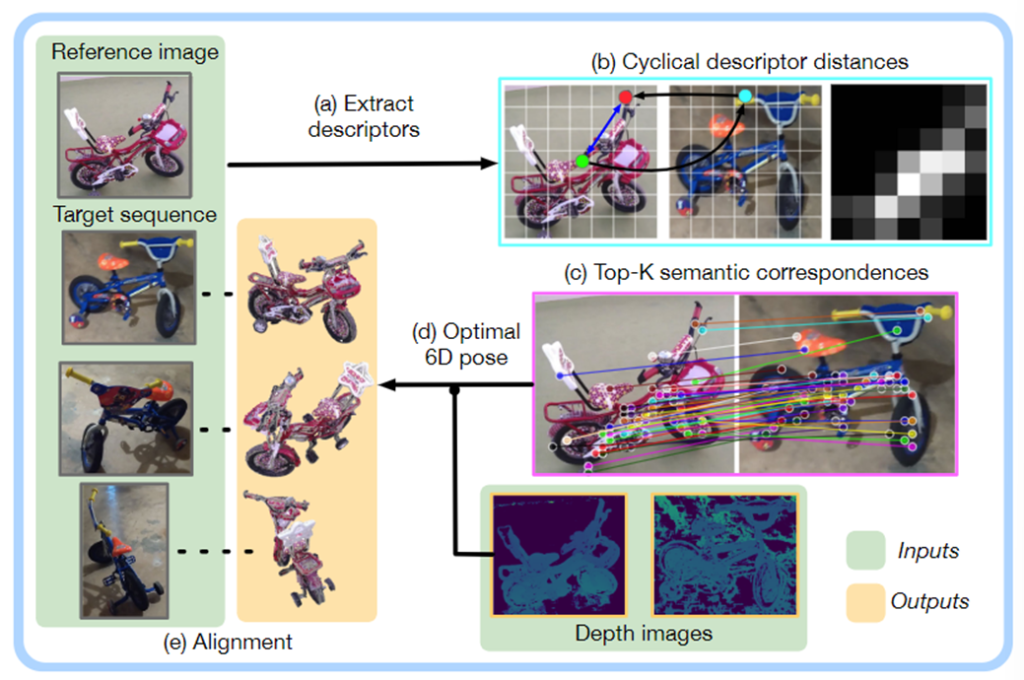
위의 그림은 전체적인 파이브라인으로 정리하면 다음과 같은 과정을 거치게 됩니다.
- self-supervised ViT를 이용하여 descriptors 추출 [Fig.1]-(a)
- reference 이미지와 모든 target 이미지 시퀀스를 비교하여 cyclical distance map 구축 [Fig.1]-(b)
- cyclical distance map을 이용하여 두 이미지 사이의 K semantic correspondences을 설정하고 대상 시퀀스에서 적절한 view를 선택 [Fig.1]-(c)
- semantic correspondences와 적절한 target view를 구한 뒤 depth 정보를 활용하여 reference 객체와 target 객체 사이의 rigid transformation을 계산 [Fig.1]-(d)
- 상대적 pose 변환 관계가 주어졌을 때, reference 이미지의 point cloud를 전체 target 시퀀스와 정렬 [Fig.1]-(e)
1. Self-supervised semantic correspondence with cyclical distances
저자들은 의미론적 correspondences가 동일 카테고리 내의 서로 다른 인스턴스 사이에서 잘 일반화되고, 각 객체에 대해 유사한 방식으로 분포하는 경향이 있다는 통찰을 기반으로 방법론을 설계하였습니다. 객체에 대해 parts-based understanding은 인스턴스 간의 일반화 뿐만 아니라 카테고리간의 일반화도 가능합니다.(e.g. 눈-코-귀와 같은 부분은 사람뿐만 아니라 많은 동물에도 확대 가능) 최근 딥러닝 연구에 따르면 ViT의 feature는 parts-based understanding가 가능하며(연산이 패치 단위로 이루어지 때문인 것으로 이해하였습니다) 저자들은 large scale 데이터(ImageNet-1K)로 pre-training된 네트워크를 활용하였다고 합니다.
앞서 Zero-shot 문제 정의 파트에서 언급한 것과 같이, 저자들은 해당 문제를 reference(단일 이미지I_1 )와 target(multi-view) 사이의 상대적 pose를 구하는 문제로 정의하고, I_1 의 모든 픽셀에 대한 cyclical distance map을 구축하여 두 이미지(I_1, I_2 )를 비교합니다. ViT를 통해 추출한 이미지의 feature는 \Phi(I_i)∈\mathbb{R}^{H'⨉W'⨉D} 이고, u∈\{1...H' \}⨉\{1...W'\}는 \Phi(I_i)의 인덱스 일 때, cyclical point u'는 아래의 식(2)를 이용하여 찾습니다.
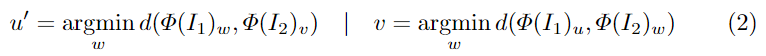
- d( · , · ): L2 distance
- I_1의 u 위치와 distance가 가장 가까운 I_2의 유사한 위치 v를 찾고, 다시 I_1에서 v와 유사한 u’를 구함([Fig.1]-(b)의 빨간점: u, 파란점: v, 초록점: u’ 가 됨)
cyclical distance map은 C_u = -d(u, u') , C_u∈\mathbb{R}^{H'⨉W'} 로 구성되며, C의 top-K를 이용하여 \Phi(I_1)에 가장 가까운 \Phi(I_2) 대응 관계를 구합니다.
cyclical distance map은 soft mutual nearest neighbours 할당으로 볼 수 있으며, I_1 과 I_2 사이의 mutual nearest neighbours[1]는 cyclical distance 0을 반환하지만, 거리가 가까운 I_1의 point는 I_2에 거의 mutual nearest neighbours가 존재하는 것으로 볼 수 있습니다. 이러한 cyclical distance metric은 (1) 예측할 수 없는 수의 대응을 만드는 mutual nearest neighbours와 다르게, soft measure를 통해 모든 이미지 쌍에 대해 K개의 의미론적 대응을 구할 수 있도록 하며, (2) soft constraint를 통해 대응 관계를 구하기 전에 공간적 정보를 추가합니다. (동일한 객체 부분에 속하는 특징은 픽셀 공간에서 서로 근접할 가능성이 높음)
[1] Amir, Shir, et al. “Deep vit features as dense visual descriptors.” arXiv preprint arXiv:2112.05814 2.3 (2021): 4.
[1]의 방식을 따라 초기의 매칭 집합을 cyclical distance 방식으로 식별한 뒤, reference 이미지에서 선택한 feature에 대해 K-means clustering을 사용하여 객체에 공간적으로 잘 분포된 point를 복구합니다. 이때, 실제로는 top-2K의 correspondence를 선택하고 K-means를 이용하여 K개의 correspondence로 필터링하였다고 합니다.
2. Finding a suitable view for alignment
다른 방향에서 사물을 바라보는 두 이미지 사이의 의미론적 대응을 찾는 것은 공통된 의미론적 부분이 없을 수 있으므로 굉장히 어려운 작업입니다. 이를 해결하기 위해 의미론적 대응 관계를 설정할 수 있는 적절한 view를 선택해야하며, N개의 target 이미지 중 가장 적절한 view를 선택하는 과정을 수행합니다. 이를 위해 reference 이미지인 I_\mathcal{R}과 target 시퀀스 I_{\mathcal{T}_1:N} 사이의 K개의 의미론적 대응 사이의 feature 유사도의 합을 이용하여 대응 점수를 구하며 아래의 식 (3)으로 정의됩니다.
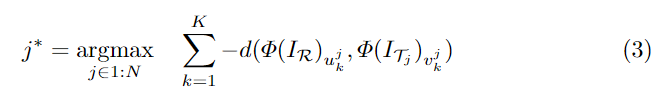
- \{ (u^j_k, v^j_k ) \}^{K}_{k=1} : j^{th}번째 target 이미지와 reference 이미지 사이의 K개의 대응 집합
3. Pose estimation from semantic correspondences and depth
앞서 파트1에서 설명한 과정은 2차원 픽셀의 좌표에서 대응 점 집합 \{ (u_k, v_k ) \}^{K}_{k=1} 를 생성하며, 대응 점들은 depth 정보와 카메라의 intrinsic 파라미터를 이용하여 3차원 좌표 \{ (\mathbf{u}_k, \mathbf{v}_k ) \}^{K}_{k=1}로 투영됩니다. pose 추정은 reference 객체에 의해 정의된 프레임을 기준으로 target 객체의 방향과 이동 변환 관계를 구하는 것으로, 3차원 point 집합이 주어질 경우 RANSAC을 이용한 least-squares 방식을 적용하여 target 객체에 대한 7-D transform(rotation \mathbf{R}, translation \mathbf{t}, scale 파라미터 \lambda)을 구합니다. least-squares 방식은 residual을 최소화하고, 예측된 6D Pose offset T^*는 아래의 식(4)를 이용하여 구합니다.
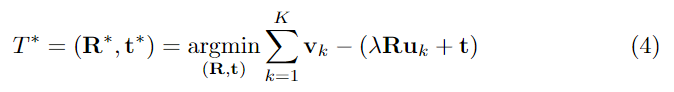
< Experiments >
Evaluation Setup
Dataset: CO3D
zero-shot 및 category=level의 pose estimation 연구를 위해, 카테고리 내의 인스턴스 변형이 많고 다양한 view를 가진 여러 카테고리의 이미지를 제공하는 데이터 셋이 필요합니다. CO3D(Common Objects in 3D)는 이러한 조건을 만족하며, 50개의 카테고리의 객체를 약 19,000장의 장면에서 촬영한 150만 프레임으로 구성됩니다. CO3D는 각 객체 인스턴스에 대해 360° 시점이 변하며 촬영한 100장의 프레임을 제공하며 카메라 pose offset이 라벨링 되어있고, 각 이미지에 대해 object의 point cloud와 대략적인 depth map을 제공합니다. 이러한 이유로 저자들은 해당 데이터 셋을 선정하여 실험을 진행하였다고 합니다.
Main Results
저자들은 zero-shot을 위해 설정한 제약 조건을 만족하도록 기존 6D Pose estimation 연구를 변경하기 어려워 다음 가지를 베이스라인으로 선정하였습니다.
- PoseContrast: 학습 과정에 보지 않은 category에 대한 3D Pose(방향만)를 추정. 각 이미지의 pose를 독립적으로 추정하여 test 대상 카테고리에 대한 canonical 프레임을 암시적으로 추론한 뒤, 참조 이미지와 대상 이미지 사이의 pose offset을 계산하여 상대적 pose를 추정.
- ICP(Iterative Closest Point): 두 point cloud를 정렬하는 방법론으로, 두 인스턴스의 depth 값을 이용하여 대상 객체에 대한 point cloud를 만든 뒤, ICP를 적용하여 pose를 추정하는 방식이며, 이때 ‘ + BV’는 ICP 성능에 큰 영향을 주는 초기화 방식 중 가장 좋은 방식을 적용한 결과를 의미.
- Image Matching: standard SIFT feature와 ResNet-50으로 구한 deep feature(SWaV)를 모두 실험하며 reference와 target 사이의 매칭의 강도를 활용하여 최적의 view를 선택하는 방식으로 실험.
실험 결과
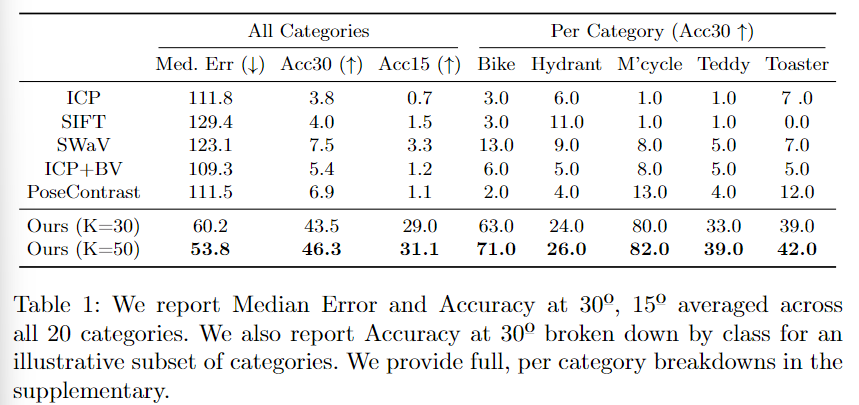
앞서 설정한 baseline 방법론들은 모두 20개의 카테고리에 대해 모두 낮은 성능을 보이는 것을 Table 1의 All Categories 결과를 통해 확인할 수 있습니다. 특히 ICP와 SIFT의 성능이 저조하였으며, 이는 해당 방법론들이 인스턴스 내의 매칭을 위한 방식이기 때문이라고 저자들은 주장합니다. 해당 방법론은 베이스라인 방법론과 비교하였을 때, 오차가 절반 정도 감소하였으며, Acc30에서 정확도가 6배 증가하였음을 실험적으로 보였습니다.
Per Category의 결과를 통해 카테고리의 기하학적 특성에 따라 성능이 크게 달라진다는 것을 발견하였으며, texture 정보가 풍부한 카테고리(Bike, M’cycle)의 경우 texture-less 카테고리(Toaster)에 비해 더 좋은 성능을 보이는 것을 확인하실 수 있습니다. 특히, Hydrant(소화전)의 경우 아래의 [Fig. 3]에서 확인할 수 있듯 4개의 면 중 3개의 면에서만 수도꼭지를 명확히 볼 수 있으나 모델이 수도꼭지와 같이 방향 정보 파악에 중요한 부분을 keypoint로 인식하지 못하여 rotation에 대한 추정이 어려웠다고 분석합니다. 반면 SIFT의 경우 외관에 집중하므로 texture-less 영역이 아닌 texture가 풍부한 영역에 집중하므로 타 베이스라인 방법론들보다 높은 성능을 보였다고 합니다. 저자들이 제안한 방식은 의미론적 대응 관계를 고려하므로 SIFT보다 훨씬 좋은 성능을 보입니다.

Mutli-view 관련 실험
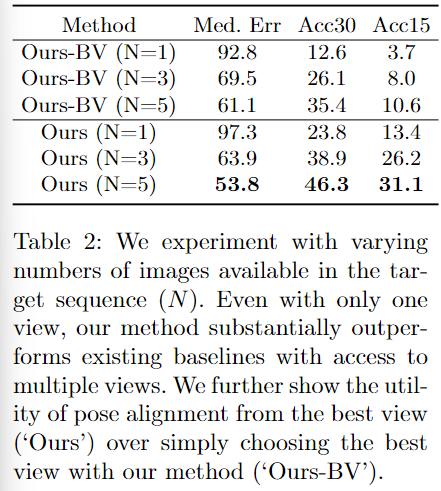
- Table 2는 multi-view 설정과 관련한 실험입니다. target view의 수를 1, 3, 5로 바꿔가며 실험을 수행하였으며, 아래의 3개 행 비교를 통해 확인할 수 있습니다.
- Ours-BV에 대한 실험 결과는 reference 이미지와 최적의 view를 선택하여 pose offset을 구한 과정의 성능입니다.(파트 2. Finding a suitable view for alignment까지 수행)
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
CO3D라는 데이터셋을 사용했다는 것이 핵심인거 같은데요,
기존 데이터셋과의 어떤 차별점이 있는지 궁금합니다
안녕하세요. 질문 해주셔서 감사합니다.
CO3D 데이터 셋은 Zero-shot category-level Pose Estimation의 세팅에 맞는 데이터라 할 수 있습니다.
해당 데이터 셋은 기존 Cateogy-level 방식에서 활용하는 데이터 셋은 CAMERA25와 REAL275가 있으며, CAMERA25는 합성데이터이고, REAL275는 real 데이터이지만 18개의 카테고리로 이루어져 있습니다.
이에 비해 CO3D는 real 데이터이며, 더 다양한 카테고리로 이루어져 있다는 점에서 장점이 있습니다.
(하지만CO3D는 해당 논문에서 제안된 데이터 셋은 아닙니다.)
안녕하세요 ! 좋은 리뷰 감사합니다.
6D pose estimation에서는 pose label 뿐만 아니라 CAD 모델까지 존재하지 않아야 unseen object로 정의할 수 있는건가요 ? 그리고 상대적인 pose, pose offset이라는 표현을 계속 하셨는데 zero shot을 통한 pose estimation은 앞선 scene에서의 pose 대비 변화한 상대적인 pose만을 추정할 수 있는걸까요 ? 해당 scene에서의 카메라에 대한 절대적인 pose를 추정할 수는 없는건지 의문이 들어 질문 드립니다.
감사합니다.
안녕하세요. 질문 해주셔서 감사합니다.
우선, 이해하신 바가 맞습니다.
추가적인 설명을 드리자면,
6D Pose Estimation 분야에서의 unseen object 에 대하여 서베이하여 본 결과 unseen에 대해서는 논문마다 약간씩 정의하는 바가 다르며, CAD 모델을 이용한 unseen과 CAD 모델을 이용하지 않는 unseen이 있습니다.
우선 절대적 pose라는 표현보다는 기준이 CAD 모델인지, 아니면 reference 이미지인지 달라진다고 보는 게 적절할 것 같습니다.
(CAD 모델이 존재할 경우 CAD 모델을 기준으로 pose를 구하게 되며, CAD모델이 없을 경우 reference를 기준으로 pose를 구하게 되는 것이기 때문입니다.)