안녕하세요.
오늘 작성할 리뷰도 Test-Time Adaptation (TTA) 분야의 논문입니다.
저번 리뷰에서 소개드린 TENT 논문이 Online TTA 분야의 baseline격 논문이라면, 이번에 소개드릴 논문은 Online TTA 에다가 continual 한 개념을 섞어서, domain이 계속해서 변화하는 상황에서 adaptation을 수행하는 것이 핵심입니다. 리뷰를 작성하는 지금을 기준으로 벌써 인용수가 230을 넘어갔네요. 그럼 바로 리뷰 시작하겠습니다
1. Introduction
본 논문에서 수행하는 Test-Time Adaptation(이하 TTA) 은 source dataset에 대해 미리 pretrained model을 test 단계에서 adaptation하는 task입니다. 다만 domain분야에서 가장 활발하게 연구되고 있는 Unsupervised Domain Adaptation(UDA) 연구와는 달리 source dataset에 대해 접근이 불가능하다는 제한사항이 존재하죠. 그렇기 때문에 license, 비용측면 등의 문제로 source dataset에 대해 접근할 수 없는 real world 상황에서 adaptation을 수행하고자 할 때 TTA 기법을 적용하기도 합니다.
본 논문 말고도 앞선 여러 연구들이 TTA를 위한 기법들을 제안했습니다. 다만 해당 연구들은 target domain이 고정된, 하나의 target domain에 대한 distribution shift 문제만을 다뤘습니다. 그들은 target domain을 위한 pseudo label을 사용해서 self-training 방식으로 TTA를 수행하기도 하고, target gt가 없는 상황에서 supervision을 부여하기 위해 entropy regularization 방식도 사용했죠.
하지만 본 논문에서는, real-world 속 실제 test 단계에서 마주하는 target domain은 고정된 것이 아니라, 계속해서 변화하는, 일명 continual domain change 라고 말합니다. 해당 언급에 대해 우리도 직관적으로 알 수 있듯이, 실제 자율주행 상황을 가정해 보자면 ‘비->터널 in-> 터널 out’ 처럼 계속해서 domain이 변화하게 되죠.
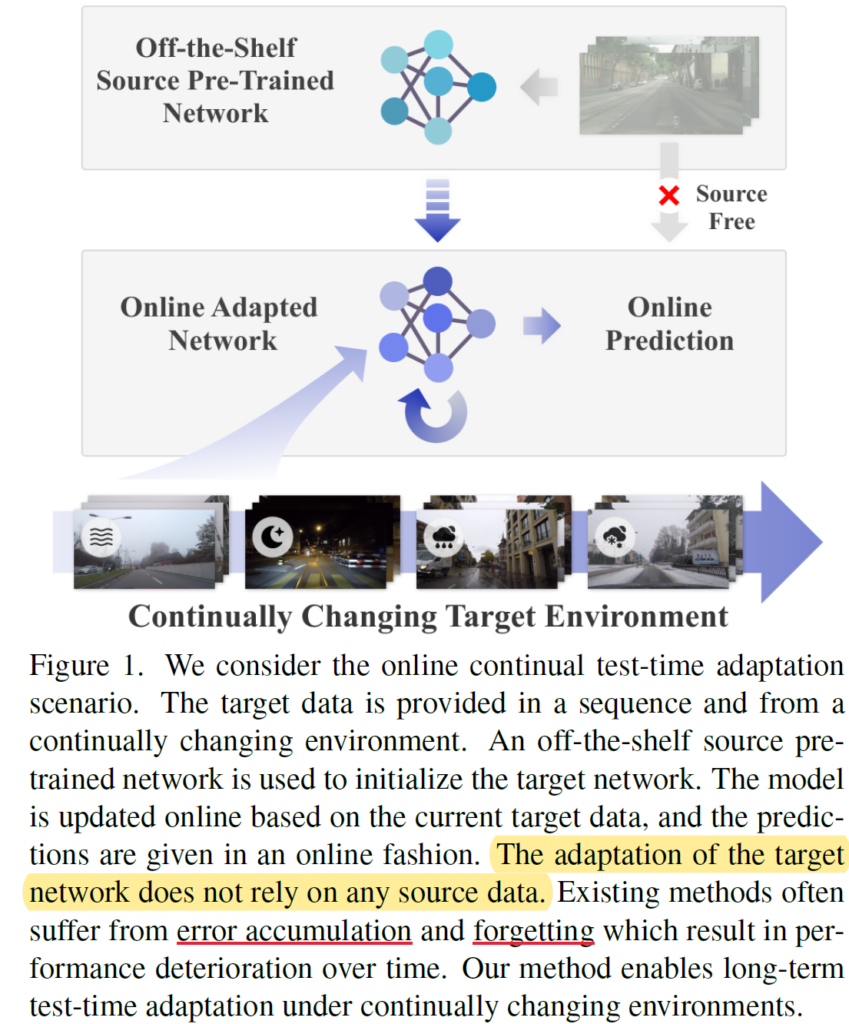
위 사진을 보면 continual domain change를 타겟으로 한 TTA 기법에 대한 이해가 가능합니다.
우선 Off-the-Shelf 상황에서 source dataset으로 미리 모델을 학습시킵니다. 그리고 해당 모델은 device에 탑재(?)된 채로 deploy 되겠죠. 이후에는 위 그림에서 표현된 것 처럼 안개, 밤, 비, 눈 등의 여러 변화하는 상황에 대해 online 방식으로 TTA를 수행하게 되는 것입니다.
저자는 위와 같은 continual domain change 상황에서 앞선 TTA 기법들을 그대로 사용하게 되면 크게 2가지 문제점이 발생한다고 언급합니다.
- 기존 self-training 기법을 그대로 사용 시, 연속적인 domain 변화 때문에 pseudo label이 점차적으로 noisy 해지고, mis-calibrated 된다고 합니다. 그렇기 때문에 adaptation이 수행되면서 error가 점차적으로 누적되는 error accumulation 문제도 발생하게 되구요.
- TTA가 연속적으로 수행되면서 새로운 distribution에 대해 긴 시간(long-time)동안 adaptation함에 따라, 기존 source dataset으로 학습했던, 좋은 representation 능력을 점차 잃게 됩니다. 이를 전문 용어로 catastrophic forgetting 이라고 합니다.
그리고 위 2가지 문제점을 해결하기 위해 간단하면서도 효과적인 2가지 contribution을 제시합니다. Method 부분에서 더 자세하게 설명드리긴 하겠지만, 여기서 한번 짚고 넘어가도록 하겠습니다.
- Pseudo label의 error accumulation을 해결하기 위해, pseudo label의 성능을 향상시키는 기법을 설계하게 됩니다. Semi-supervised 연구에서 제안된, mean teacher 방식으로 모델의 parameter를 update해 나가는 방식이 기존 모델에 비해 더 높은 성능을 보이는 것에 motivation을 받아서, weight-averaged teacher model을 설계합니다. 또한 source와 target domain의 큰 domain gap에 의해 adaptation 성능에 지장이 가는것을 완화하고자 augmentation-averaged pseudo labels 라는 것을 제안하게 됩니다.
==> 자세한 설명이 부족해서 이해가 어려우실 수 있는데, continual domain change상황 속 pseudo label의 에러 누적을 해결하기 위해 더 정확한 pseudo label을 생성하고자 했다~ 라고 생각하시면 됩니다. - long-time 동안 TTA가 수행되면서 발생하는 catastrophic forgetting 문제를 해결하기 위해, 기존의 pre-trained source model로 network 내 뉴런의 일부를 확률적으로 restore하는 방식을 제안하게 됩니다. 이는 forgetting을 직관적으로 해결하기 위해 확률적으로 일부 뉴런의 weight값을 초기의 source pretrained model parameter로 회복(restore) 하는 방식입니다.
네, 위에서 설명드린 2가지 방법론에 대해선 아래에서 더 자세하게 설명드리도록 하겠습니다.
다만 들어가기에 앞서, 저자의 의도가 continual한 domain 변화에 대해서도 TTA를 잘 수행하고자 했다라는 것만 잘 이해하시고 넘어가시면 될 듯 합니다.
2. Method
(Continual Test-Time Domain Adaptation)
TTA를 위해서는 우선 source data (X^S, Y^S)에 대해 미리 학습된 모델 f_{\theta_0}(x) 이 필요합니다. 그리고 test 단계서는 source data에 대한 접근 없이 오로지 Unlabeded target data X^T만을 사용해서 continual하게, 연속적으로 변화하는 domain 상황에 대한 adaptation을 수행하게 됩니다.
이런 연속적인 adaptation 상황 속 model parameter의 update 과정은 아래와 같습니다.
time step t에서 target data x^T_t가 모델 f_{\theta_t}(x)의 입력으로 들어와서 예측 f_{\theta_t}(x^T_t)를 수행하게 됩니다. 모델에게 time step t에 부여할 수 있는 supervision은 오로지 prediction f_{\theta_t}(x^T_t) 밖에 없기 때문에, 이를 사용해서 parameter \theta_{t+1}을 추정하게 됩니다. 이러한 방식으로 점차적으로 t+1, t+2 의 parameter를 추정해 나가면서 모델은 continual한 domain shift 속 adaptation을 수행하게 되는 것입니다.
하지만 위 Intro에서 간단하게 언급했다시피 기존 TTA 기법의 self-training pseudo label 기법을 그대로 사용해버리게 되면 error accumulation 문제가 발생하기 때문에, continual changing을 위한 부가적인 pseudo label 세팅 과정이 필요하게 됩니다. 이를 묶어서 weight-and-augmentation-averaged pseudo-labels 라고 저자는 표현하였고, 아래 2.1.절과 2.2.절에서 설명해 드릴 예정입니다.
그리고 long-time동안의 TTA 수행 동안에 기존 source data로 부터 학습된 훌륭한 representation 능력을 forgetting하는 문제를 해결하기 위해 stochastic restoration 기법을 설계하게 되며, 이는 2.3.절에서 설명드릴 예정입니다.
또한 이 모든 사항들이 잘 그려진 전체 구조는 아래와 같습니다.
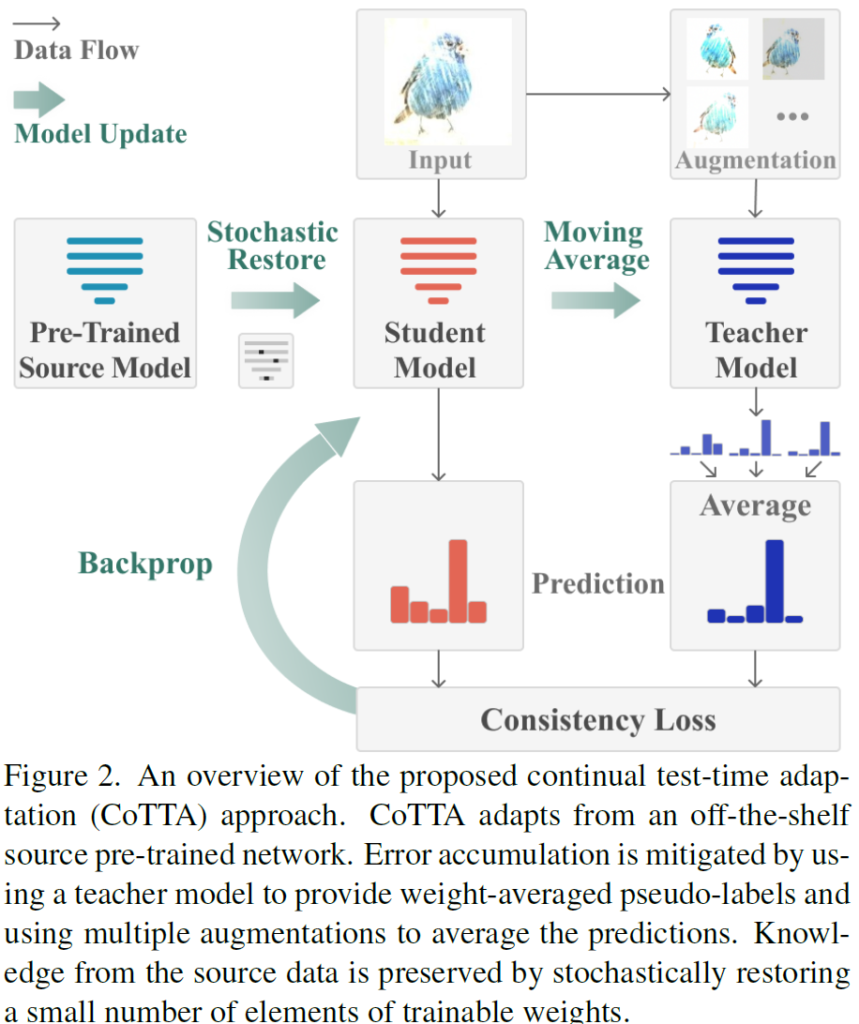
2.1. Weight-Averaged Pseudo-Labels
TTA 수행 시 입력으로 들어오는 target data x^T_t, 그리고 모델 f_{\theta_t}에 대해 일반적인 self-training based TTA 기법들은 모델의 예측인 \hat{y}^T_t = f_{\theta_t}(x^T_t)와 pseudo label 사이의 cross-entropy를 줄여나가는 방식으로 adaptation이 수행되게 됩니다.
이러한 방식은 test domain이 하나로 고정된 상황이라면 효과적이지만, distribution shift로 인해 연속적으로 target domain이 변화하는 상황에서는 pseudo label의 성능이 하락하게 됩니다.
저자는 Semi-supervised 방법론에서 제안된 mean teacher에 착안하여 더 정확한 pseudo label을 만들기 위한 weight-averaged teacher model f_{\theta'} 모델을 사용하게 됩니다. 위 모델 전체 그림에서 우측 파랑색 teacher 모델에 해당합니다.
(추가적으로 아래에서 설명 드릴꺼긴 한데 미리 말씀드리자면, 위 모델에서 주황색 student 모델은 back propagation으로 학습이 진행되는 모델이고, teacher model은 학습하는 모델이 아니라 mean teacher 방식으로 parameter만 update 되는 방식입니다. 아래에서 더 설명 드리겠습니다.)
동작 과정은 아래와 같습니다.
우선 TTA 시작 초기, 즉 t=0 시점에 source pre-trained network와 동일한 parameter로 teacher network를 초기화합니다. 그리고 time-step t에서 teacher 모델의 예측인 \hat{y'}^T_t = f_{\theta'_t}(x^T_t)를 pseudo label 삼아서 student 모델의 update가 진행되게 됩니다. 아래 loss를 통해서 학습이 진행되고, \hat{y}^T_t는 main(student) 모델의 예측이며, teacher 모델의 예측은 soft label 값을 그대로 사용하게 됩니다.
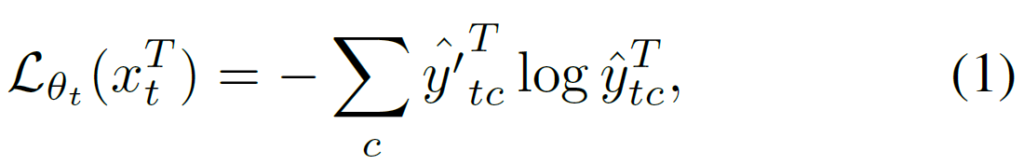
사실 위와 같은, pseudo label과의 cross-entropy loss를 통해 main(student) 모델을 update하는 방식은 기존과 동일합니다. 다만 다른 점은 pseudo label을 생성하는, teacher 모델의 parameter를 어떻게 update해 나가냐는 것이죠. 위에서 설명드렸다시피 기존 mean teacher의 EMA update 방식에 모티브를 얻어서, 아래와 같은 수식을 통해 t+1 시점의 teacher model parameter \theta'_{t+1} 를 update해 나가게 됩니다. 사실 뭐 별다르게 특별한 방식은 아니라고 생각이 듭니다.
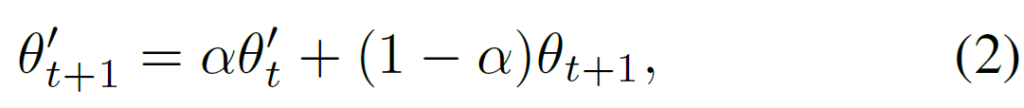
위 식 1의 loss를 통해 back propagation으로 update된 student 모델 paramter \theta_{t+1}를 구한 다음, 위 식 2를 통해 t+1 시점의 teacher model parameter \theta'_{t+1} 를 구하는 방식입니다. student model의 paramter를 특정 가중치 만큼 EMA방식으로 반영시키는 것이며, \alpha는 hyperparameter 입니다.
저자는 weight-averaged 방식으로 teacher 모델의 parameter를 update해 나가는 것에 크게 2가지 이점이 있다고 말합니다.
- 일반적인 모델에 비해 보통 더 높은 성능을 보이는 weight-averaged 예측을 pseudo label로 사용함으로써 pseudo label의 error accumulation 완화.
- mean teacher의 예측 \hat{y'}^T_t은 EMA방식으로 update된 teacher 모델의 특성 상 과거 batch들의 정보들이 encoding되어 있다. 따라서 long-term continual adaptation의 관점에서 과거 지식이 encoding되어 있기 때문에 catastrophic forgetting에 덜 취약하고, 새롭게 등장하는 unseen domain에 대해 더 높은 일반화 성능을 보인다.
2.2. Augmentation-Averaged Pseudo-Labels
일반적으로 모델의 학습 시 모델의 성능을 끌어올리고자 data augmentation 기법을 적용하곤 합니다.
앞선 TTA 연구들에서도 augmentation을 통한 모델의 robustness향상을 입증했는데, TTA 수행 시 마주하는 여러 domain distribution shift와 무관하게 강인한 예측을 수행하도록 하기 위해 augmentation을 적용하였습니다.
예를 들어, 현재 들어온 data가 기존 source data와 domain gap이 작다면 굳이 augmentation을 적용하지 않고, 만약 domain gap이 크다면 더 강인한 예측을 수행하기 위해 augmentation을 적용하는 것이죠.
어떤 방식으로 적용되는지에 대한 수식은 아래와 같습니다.
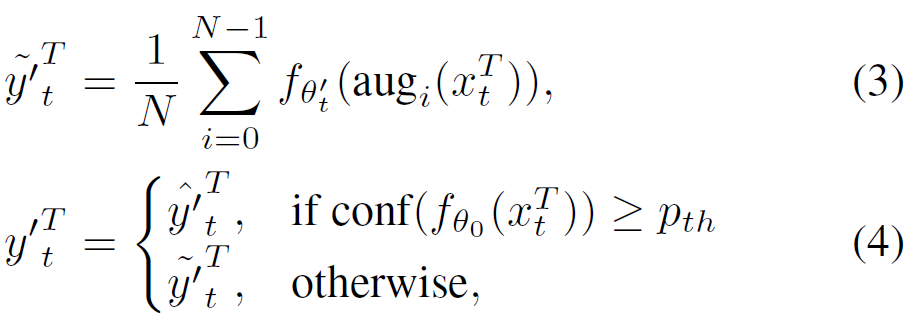
우선 위 식에서 y의 종류가 많아 헷갈리실수 있을 거 같아서 조금 풀어서 이야기해보자면,
결국 위 식(4)를 통해 student 모델을 위한 pseudo label y'^T_t 를 생성하는 것이 목표입니다. 그런데 여기서 source data와의 domain gap(=distance)를 confidence를 기준으로 판단하게 됩니다.
특정 confidence threshold p_{th}를 기준으로 해당 threshold보다 confidence가 작으면, 즉 source data와의 domain gap이 큰 경우에는 조금 더 robust한 예측을 수행하기 위해 augmentation을 수행한 결과 \tilde{y'}^T_t를 사용하게 됩니다.
반대로 confidence가 크다면, 즉 source data와 별다른 domain gap이 존재하지 않는다면 굳이 augmentation을 적용할 필요가 없기 때문에 mean teacher의 예측 \hat{y'}^T_t를 그대로 사용하게 되는 것입니다.
본 논문에서 domain distribution 차이가 큰 경우에 대한 robustness 확보를 위해 설계한 augmentation-average pseudo labels 방식은 위에서 첨부해드린 모델 전체 그림을 보시면 직관적으로 이해하실 수 있습니다.
결국 어떠한 augmentation을 적용한다 한들 동일한 예측을 수행해야 하기 때문에 결과값들의 average를 pseudo soft label로 채택해서 사용하게 되는 것입니다.
2.3. Stochastic Restoration
2.1절과 2.2절을 통해 보다 정확한 pseudo label을 사용하게 되면 error accumulation 문제를 해결할 수는 있습니다. 하지만 long-time 동안 continual TTA를 수행하게 되면 이전 source data로부터 학습했던 좋은 respresentation 능력을 forgetting 할 수 있다는 문제가 있습니다.
특시 연속적으로 변화하는 상황 속 강한 domain shift를 마주하게 될 경우 잘못된 pseudo label로 인해 모델이 그 쪽으로 bias 됨으로써 원래대로 회복(recover)되지 못한다는 문제점이 발생하게 됩니다.
이를 해결하고자 저자는 stochatic restoration, 확률론적 복원 방법을 설계하게 됩니다.
forgetting문제를 해결하기 위해 직관적으로, time-step t가 진행됨에 따라 student(main) 모델 layer의 일부를 초기 source-pretrained weight으로 다시 회복(restore)시키는 그런 방식입니다.
아래 식이 전부입니다.
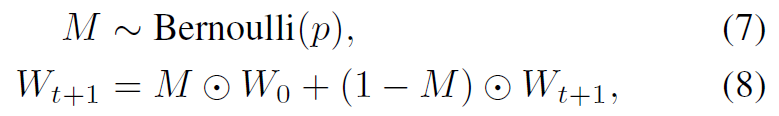
우선 식 7을 통해 베르누이 분포를 가지는 Mask M을 생성하게 됩니다. 논문에서는 p=0.01을 사용하기 때문에, 생성되는 mask M은 100개 중 1개꼴로 1의 값을, 나머지 99개는 0의 값을 가지게 되는 mask 입니다.
그리고 해당 mask M을 식 8에 적용하게 됩니다. 여기서 W는 그냥 weight라고 생각하시면 됩니다.
적용하게 되면 t+1 시간대의 weight W_{t+1}은 mask M 만큼의 weight을 초기 상태로 초기화해서 update 하게 됩니다. M과 W 사이의 연산자는 element-wise multiplication 입니다.
위 처럼 초기 source-pretrained weight을 M만큼 restore하는 방식을 통해, 기존 source의 지식을 보존하면서 forgetting 문제도 해결할 수 있다고 합니다.
제안하는 전체 알고리즘은 아래와 같습니다.
리뷰 Method 상단부의 전체 pipeline 구조와 매치해서 보시면 이해하기 수월하실겁니다.

3. Experiment
본 논문에서는 continual TTA의 효과를 classification, 그리고 segmentation에서 입증합니다.
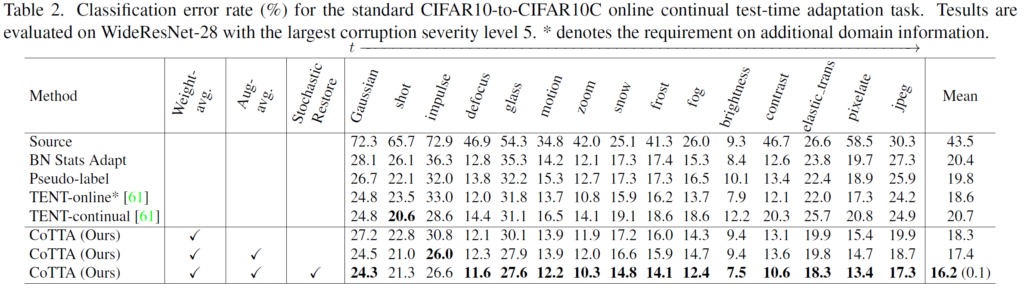
위 실험은 CIFAR10 에서 CIFAR10C 로의 TTA 성능을 classification error로 리포팅 한 결과입니다. 그리고 CIFAR10C 데이터셋은 CIFAR10 데이터에 임의의 corruption을 부여한 것인데, corruption의 종류로는 위 tabel에 나열된 Gaussian, shot,, 등이 있습니다.
첫번째 열의 Source는 말 그대로 source-pretrained 모델을 별다른 후처리 없이 target domain에 태우는, 바로 TTA를 수행했을때의 성능입니다. 본 task의 lower bound라고 생각하시면 됩니다.
BN Stats Adapt는 test 단계에서 각 입력 batch로 들어오는 Batch Normalization 통계값을 활용해서 TTA를 online으로 수행한 결과입니다. 각 test batch에 대한 데이터 distribution의 평균, 표준편차 값이 사용되었기 때문에 첫번째 열의 source에 비해 classification error가 많이 낮아진것을 볼 수 있습니다. 23%나 낮아졌네요.
세번째 열의 Pseudo-label은 Batch Norm의 학습 파라미터를 학습할 때 hard pseudo-label을 사용하는 방식입니다.
그리고 4번째 열은 TENT-online 성능입니다.
TENT는 continual한 domain 변화를 타겟으로 설계한 방법론이 아니라 하나의 domain 변화만을 타겟으로 설계한 방식입니다. 따라서 TENT-online 는 domain 상황이 변할때 마다 모델의 parameter를 초기 상태로 초기화한 다음 새로이 adaptation을 수행했을때의 성능을 나타낸 것입니다.
물론 error가 18.6%이긴 합니다만, 새로운 domain 상황이 등장했을 때 모델을 다시 초기 상태로 돌리는 세팅 자체가 real-world 상황에서는 말이 안되기 때문에 한계점이 많습니다.
5번째 열의 TENT-continual 성능은 TENT 방법론을 continual한 domain 상황에 적용시켰을때의 성능입니다. 위 TENT-online보다 못한 20.7%의 성능을 보이고 있네요. 저자들이 주장한 error accumulation, catastrophic forgetting 문제 때문에 성능 하락이 생긴 듯 합니다.
그리고 아래 3개의 열은 Ours 방법론에 대한 ablation 결과를 함께 담은 결과입니다.
3가지 요소 중 특히 3번째 Stochastic Restore 방식 추가에 따른 성능 향상이 재밌습니다. 사실 해당 방법론의 동작 방식은 매우 단순합니다. weight 의 일부를 초기 t=0 상황으로 되돌리는 것이죠. 하지만 이에 따른 성능향상, 특히 time t가 뒤쪽으로 진행이 될 수록 향상폭은 커집니다. 이말은 즉슨 forgetting 문제를 아주 효과적으로 잘 완화했다는 것이죠.
저자는 이에 대해 weight의 일부를 초기 상황으로 되돌리는 행위가, 마치 모델에 dropout layer를 추가하는 것과 유사한 효과를 낸다고 합니다.
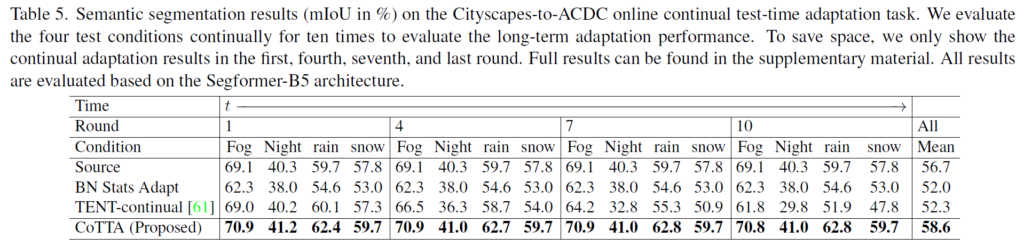
또한 위는 segmentation task에서의 continual TTA 실험 결과입니다.
time t가 뒤쪽으로 진행 되면서, 특히 뒤쪽에서의 성능 향상이 효과적인것을 알 수 있습니다.
네 오늘은 online TTA, 그것도 continual 상황을 고려한 online TTA 방법론 중 하나인 CoTTA 리뷰를 진행해 보았습니다.
online TTA 계의 baseline이라고 불리는 이전 work인 TENT 방법론이 continual한 상황에서의 고려가 없었다는 아주 직관적이면서도 치명적인 문제정의 하였고, 이에 대한 아주 직관적이고 효과적인 해결책을 통해 continual 한 상황에서의 TTA 성능 향상을 이뤄냈습니다.
논문도 꽤나 깔끔하게 구성되어 있어서 스무스하게 잘 읽혔던 거 같습니다.
그럼 다음에는 또 다른 TTA 논문을 가지고 오도록 하겠습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
TENT를 읽고 TTA의 필요성과 효용성에 대해 느꼈는데, 이 리뷰까지 같이 읽으니 Continual한 domain shift 문제에도 대응해줘야 한다는 점을 알게되었습니다.
표 2에서 TENT-online의 성능도 인상깊어보이는데, domain이 변할 때마다 모델을 초기로 돌린다는 설명 중 domain이 변했다는 것은 어떻게 판단하나요? 그리고 모델을 초기로 돌리는 것이 real-world에서는 왜 말이 안된다고 하신건지 궁금합니다.
본 논문에서 설계한 CoTTA와는 달리, TENT는 continual한 상황에 대한 고려가 모델 설계에 반영되어 있지 않습니다.
위 실험 table에서 TENT-online은 test 단계에서 test&adaptation 수행 시 domain이 변할 때 마다 사람이 임의로 개입해서 새로이 parameter를 초기로 돌리는 작업을 수행하게 됩니다. 이와 같은 이유 때문에 real world에서는 말이 안된다고 표현한것이구요.
(어느 시점에 domain이 바뀔 지 모르는 real 상황에서 사람이 매번 개입하는건 불가능하지요)
안녕하세요. 리뷰 읽다가 질문이 몇개 있어서 남깁니다.
해당 방법론은 student와 teacher의 모델이 완전히 동일해야만 적용할 수 있는 방법인가요? EMA 방식으로 teacher를 업데이트한다길래, teacher를 더 무거운 모델, student를 더 가벼운 모델로 적용하고 싶을 때는 사용하지 못하나 해서요.
두번쨰로는 그림2에서 볼 수 있는 augmentation 및 mean average pseudo label 방식은 classification task를 위한 방법인 것 같은데, segmentation에서는 어떻게 활용해야하나요? 그림2 입력 예시에서는 기하학적 변환들이 여럿 적용되어 있는데, flip은 원본으로 되돌리는게 쉬우니 예외로 치고 만약 Crop 연산이 포함된 기하학적 변환 같은 경우에는 해당 추론 값을 기하학적 변환이 적용되지 않은 원본 영상의 추론 값과 완벽하게 align 시키기 어려울 것 같은데.. 어떻게 추론값의 평균으로 pseudo label을 만들 수 있을까요?
셋째로 해당 방법론은 student 모델의 전체 레이어를 다 학습시키는 방법인가요? TTA는 추론 단계에서 학습을 해야하다보니 적은 레이어만을 학습시킨다고 예전에 들었던 것 같은데, 퀄컴이랑 동일하게 전체 모델을 학습시키는 방향으로 이해하면 되는건가요?
마지막으로 실제 자율주행 상황에서 해당 방법론을 적용할 때 Student 모델과 Teacher 모델이 있는데, 이때도 teacher model의 입력으로 다양한 augmentation 처리를 수행해주고 multi-image들을 입력으로 넣어주어야하나요? 만약 그렇다면 하나의 frame을 처리하는데 마치 비디오 처리하듯이 여러장의 영상을 forward 하는 것으로 이해하면 되는지 궁금하네요.
감사합니다.
댓글 감사합니다.
1. 음 정확히 본 논문에서 설계한 EMA based mean teacher 방식을 사용하기 위해선 student와 teacher의 구조가 동일해야 하는 것으로 알고 있습니다. 본 논문에서는 time step t에 대해 domain이 계속해서 변화하는 상황 속 learnable한 teacher network의 예측을 그대로 pseudo label로 사용하기에는 error accumulation의 문제가 발생한다고 하였습니다. 따라서 이를 해결하고자 기존 mean teacher 연구에서 모티브를 받아서, mean teacher 방식을 활용하여 더욱 안정성 있는 weight averaged pseudo label 생성 기법을 설계하였습니다.
2. Segmentation을 위한 augmentation으로는 flip만을 사용하였다고 합니다.
3. 네. 본 논문에서는 기존 연구인 TENT와는 달리 모델 전체의 parameter를 update하는 방식을 채택하고 있습니다.
4. 맞습니다. mean teacher의 augmentation-Averaged Pseudo-Labels 생성을 위해 여러 augmentation을 적용한 이미지들을 함께 forward하는 과정을 거치게 됩니다. 이에 더해 위 3번 응답에서 말씀드린 거 처럼 모델의 전체 parameter를 update하는 방식을 사용하고 있다 보니, 성능적으로는 우수할지 몰라도 비효율적인 TTA가 수행됩니다.
이를 문제삼아 KAIST RCV에서 CVPR 2023에 ECoTTA(Efficient CoTTA)라는 방법론을 제안하였습니다.