안녕하세요, 허재연입니다. 오늘은 Representation Learning 논문을 들고 왔습니다. 사실 representation learning이라 함은 pretext task나 adversarial learning, contrastive learning 등 사전학습을 거쳐서 모델이 데이터에 대한 일반적인 표현력을 갖추게 한 뒤 downstream task로 fine-tuning하는것이 일반적인데 반해 이 논문 같은 경우는 모델 안에 image classification learning에 도움이 되는 다른 pipeline을 삽입해 loss 항을 추가한 것이므로 엄밀히 Representation Learning으로 분류해도 되는지 확실하지 않습니다만, 굳이 분류를 한다면 Representation Learning에 포함시키는 것이 맞는 것 같네요. 이 논문은 기존 ViT에 단순히 직소 퍼즐을 푸는 flow(Loss항을 추가한 일종의 regularization으로 볼 수도 있습니다)를 추가해 이미지 분류 성능을 높이는 방법을 소개하는데, 재밌어 보이기도 하고 ViT 공부도 할 겸 읽어보았습니다. 리뷰 바로 시작하겠습니다.
Abstract
비전 트랜스포머(ViT)가 다양한 컴퓨터 비전 영역에서 좋은 결과를 보여주고 있고, CNN 기반 모델들의 자리가 점점 ViT로 대체되어가는 추세입니다. 저자들은 ViT가 이미지 패치 단위로 동작한다는 사실에서 ViT를 전통적인 self-supervised task중 하나로 사용되어왔던 jigsaw puzzle solving과 연결시키는 아이디어를 내놓습니다. 본 논문에서 저자들은 jigsaw puzzle solving을 이미지 분류를 위한 ViT에 self-supervised auxiliary loss로 사용하는법을 탐구하고, 이를 Jigsaw-ViT라고 이름 붙였습니다. Jigsaw-ViT는 기본 ViT에서 positional embedding을 없애고 무작위로 패치를 마스킹하는 방향으로 수정되었습니다. 이 방법으로 standard ViT보다 ImageNet classification에서 높은 성능을 달성할 수 있었습니다. 추가적으로, auxiliary loss를 추가한 것이 noisy label에 대해서 robustness를 증가지켜줄 수 있음을 보였습니다.
Introduction
ViT는 CNN과 다르게 이미지를 패치 단위로 분할하여 입력받으며, feature map의 픽셀 간 global interaction이 가능하도록 self-attention을 수행합니다. 따라서 local→global 정보를 점차 배워가는 CNN과 달리 ViT는 학습 시작과 동시에 멀리 떨어진 픽셀 간의 global information을 이용할 수 있습니다. 그리고 현재까지 이러한 convolution-free 구조의 ViT가 image classification, object detection, semantic segmentation, image generation 등 다양한 컴퓨터 비전 task에 성공적으로 적용되었습니다.
ViT가 이미지 패치 단위로 입력을 받고 동작한다는 점에서 ViT가 전통적인 patch-based learning task인 직소 퍼즐 풀기와 연관이 있다고 볼 수 있습니다. 직소 퍼즐 풀기 task는 조각난 이미지 패치를 다시 정렬하는 task로, computer vision에서는 주어진 이미지 데이터에 대해 annotation이 필요하지 않은 self-supervised learning으로 다룰 수 있다는 점에서 주목받았었습니다. 직소 퍼즐 풀기는 해당 task 자체를 목적으로 하기보다는 image representation을 얻는 pretext task중 하나로 주로 연구되었다고 합니다. 본 논문에서도 직소 퍼즐 풀기를 표준 이미지 분류 ViT에 self-supervised auxiliary loss형태로 접목시켜 분류 성능 향상을 노립니다. 기존의 end-to-end image classification flow에 jigsaw solving flow를 추가시켜 본래의 classification loss에 jigsaw solving loss를 더한 total loss = (classification loss) + (jigsaw solving loss) 형태로 학습을 진행하는 것입니다.
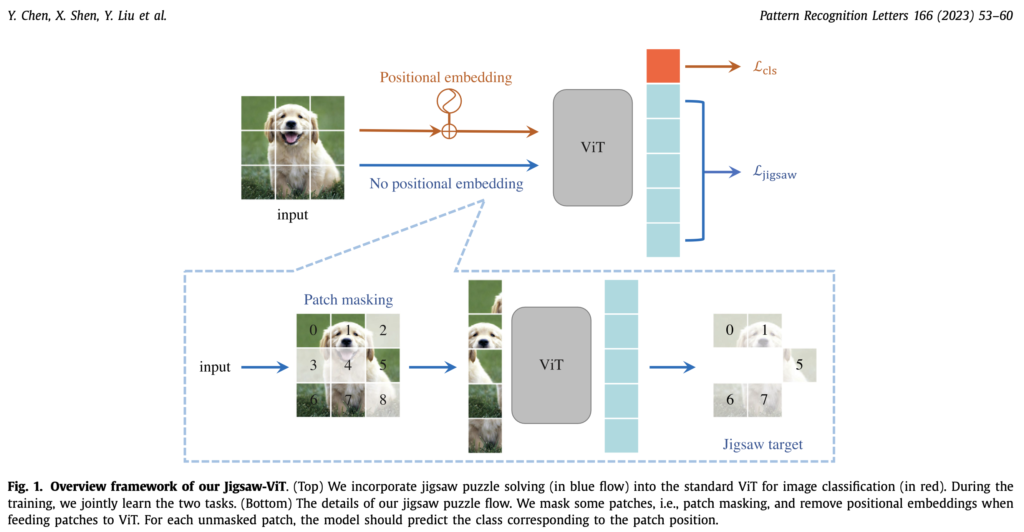
이를 위해서 저자는 기본 ViT구조를 다음과 같이 수정했습니다: (i) 모델이 positional embedding 정보에서 shortcut cue를 얻는 것을 방지하기 위해 positional embedding을 제거하였습니다. 만약 모델이 positional embedding 정보를 shortcut으로 학습하게 된다면 image data의 표현력을 학습하는데 도움이 되지 않을 것이므로 이를 명시적으로 막아준 것입니다. (ii) 이미지 패치 중 일부를 부작위로 마스킹하고, 마스킹되지 않은 패치들의 원래 위치를 예측하도록 합니다. 이는 특정 패치에만 집중하여 예측하는것을 방지하고 모델이 global context에 조금 더 집중할 수 있게 패널티를 가해준 것입니다.
간단한 수정만 가했을 뿐인데도, 저자들은 Jigsat-ViT가 기본적인 ViT와 비교해 보통 trade-off 관계에 있는 generalization과 robustness를 모두 개선할 수 있음을 발견했다고 합니다. generalization 측면에서는, jigsaw flow가 ViT에 ImageNet-1K에서의 이미지 분류 성능 향상을 가져왔다고 합니다. robustness 측면에서는, 3가지 noisy-label 데이터(Animal-10N, Food-101N, Clothing1M)에 대해 일관적인 성능 향상을 보였다고 합니다.
Related work
Solving jigsaw puzzle
Jigsaw puzzle solving은 shuffle된 original image patch를 원래 상태로 되돌리는 것인데, 컴퓨터 비전에서는 퍼즐을 푸는 것을 최종 목표로 연구하기보다는 visual recognition task를 위한 pre-text task로 다루어졌다고 합니다. self-supervised 방식으로 풍부한 feature representation을 얻을 수 있기에 task-specific data를 fine-tuning할 때 사용될 수 있다고 합니다.
Learning with noisy labels
noisy label의 경우 저는 이 논문에서 처음 보는 학습법이었습니다. 해당 task는 annotation에 noise가 껴 있는 데이터로 모델을 학습을 시킨 후 좋은 clean test accuracy를 달성하는것을 목표로 한다고 합니다. 논문에서 소개된 일반적인 접근법은 다음과 같습니다 : (i) 틀렸을 가능성이 있는 label을 수정하는 label correction, (ii) 정확한 일부의 label만 이용하는 semi-supervised learning, (iii) clean데이터일 확률이 높은 sample에 높은 가중치를 부여하는 sample reweighting.
Method
Vision Transformer
해당 부분에서는 먼저 비전 트랜스포머의 동작 방식을 간단히 짚고 넘어갑니다. 먼저 주어진 이미지 데이터 I를 patch resulution이 PxP인 2D 패치로 분할하고(패치 수는 L=HW/P^2), 패당 패치들은 linear projection을 거쳐 D차원 feature인 patch embedding이 됩니다. 여기에 본래 패치의 위치 정보를 보존하기 위한 positional embedding(p)을 sequential patch embedding(z)에 더한 다음(v0 = z0 + p) 트랜스포머 인코더에 입력하게 됩니다. 트랜스포머 인코더는 layer normalization(LN), multi-head self-attention(MSA), multi-layer perceptron blocks(MLP)로 구성됩니다.
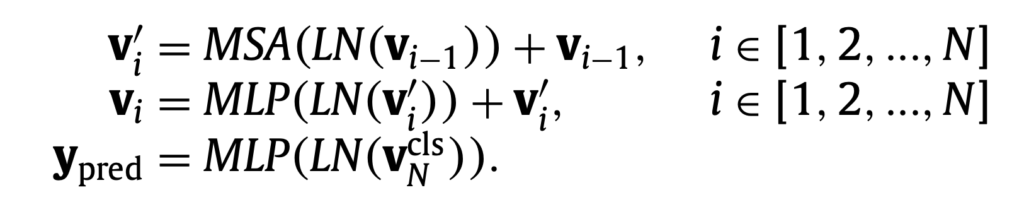
Jigsaw-ViT
직소 퍼즐 풀기는 shuffled sequential patch들을 원래 포맷으로 재정렬하는것을 목표로 합니다. 이전 CNN 기반 방법론들은 직소 퍼즐 풀기가 다양한 컴퓨터비전 task에 (representation learning 측면으로)도움이 됨을 보였습니다. 저자가 제안한 전반적인 overview는 Fig.1에서 확인할 수 있습니다. 저자들은 ViT model이 전통적인 분류와 직소 퍼즐 풀기를 optimization objective로 묶어서 함께 학습하도록 했습니다. 2개의 cross-entropy를 이용했으며, class prediction을 위한 loss와 패치 토큰에 대해 position prediction을 위한 loss를 다음과 같이 가중치를 두어 묶었습니다:
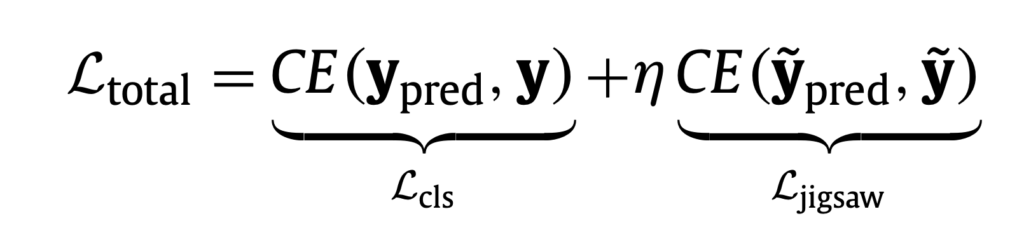
직소 퍼줄 풀기를 위한 cross-entropy는 예측 위치(prediction와 실제 위치(label) 정보를 비교하는 cross-entropy입니다.
Fig1의 아래에 쓰여진것처럼 저자들이 제안하는 flow는 일반적인 jigsaw solving flow와 몇가지 다른 점이 있습니다. (i) 일단 jigsaw solving flow에 positional embedding을 없앴습니다. 이는 모델이 positional embedding 정보를 shortcut cue로 사용해 퍼즐을 맞추는것을 방지하고 보다 image representation에 집중시키기 위함입니다. (ii) 두 번째로 mask ratio(하이퍼파라미터) 비율에 따라 input patch에 무작위로 마스킹을 가했습니다. 이는 모델이 특정 패치에만 의존하는 것이 아니라 global context를 고려하게 하기 위함이라고 합니다. 마스킹 된 패치는 고려하지 않고 마스킹되지 않은 패치만 model input으로 들어가며, 모델은 unmasked patch의 위치만 예측합니다. mask ratio는 데이터셋에 따라 다르지만 0.2~0.5정도로 설정되어 있습니다. 저자들은 제안하는 jigsaw puzzle solving이 self-supervised task이기에 본래 모델 구조에 큰 수정을 가하지 않고 기존 ViT에 적용시킬 수 있었다고 합니다.
Experiment
여기서는 저자들이 제안한 모델을 (i) ImageNet dataset을 이용해서 large-scale classification에 대해 실험하고, (ii) Animal-10N, Food-101N, Clothing1M이라는 noisy-label dataset을 이용해 robustness측면에서 실험을 진행했습니다.
Generalization on large-scale image classification

저자들은 우선 ImageNet Classification에 대해 ViT모델(Table의 DeiT)과 저자들의 Jigsaw-ViT모델을 비교했습니다. 해당 실험에서는 Loss의 balance parameter η= 0.1로 설정하고 mask ratio=0.5로 설정했다고 합니다. 기본 백본(ViT)는 모델 크기에 따라 tiny부터 base까지 리포팅하였습니다. 모델 크기는 embedding dimension 크기, head 수 등에서 차이가 난다고 생각하시면 됩니다. ViT-Base의 경우 768 embedding dimention, 12heads, 12layers를 가진 반면 ViT-tiny는 192 embedding dimention, 3 heads, 12layers를 가집니다. 같은 모델 크기에서의 비교는 기반이 되는 ViT모델에 저자들의 jigsaw solving flow를 추가시켜 ViT와 비교했다고 이해하시면 될 것 같습니다. ImageNetv1과 v2에서 모두 일관적으로 Jigsaw-ViT가 baseline보다 좋은 성능을 보이는 것을 확인할 수 있습니다. 저자들은 이를 통해 Jigsaw-ViT가 on large-scale image classification에서의 generalization performances가 뛰어나다고 주장합니다.

저자들은 jigsaw flow를 추가한 것에 대한 영향을 알기 위해 추가적인 조사를 합니다. Fig2는 baseline인 ViT모델과 Jigsaw-ViT의 self-attention map을 시각화 한 것입니다. Fig2에서 확인할 수 있듯이, Jigsaw-ViT에서 모델이 좀 더 객체의 형상을 잘 attention하고 있음을 알 수 있습니다. 저자들은 jigsaw solving task가 서로 다른 순서의 패치 관계를 파악하기 위해 다양한 공간 관계를 고려하기 때문에 attention에 도움이 될 수 있다고 해석합니다.
Robustness to label noise
여기서는 학습 데이터셋의 라벨에 노이즈가 포함된, 모델에게 보다 도전적인 실험을 진행합니다. Animal-10N, Food-101N, Clothing1M라는 데이터셋을 사용하는데, 이는 noise label에 자주 사용되는 real world dataset이라고 합니다(저는 이 논문에서 noise label과 해당 데이터셋들을 처음 보았습니다). animal-10N, Food-101N은 비교적 낮은 noise ratio가 포함되어 있고(각각 8%, 20%), Clothing1M 데이터셋에는 비교적 높은(38%) noise label이 포함되어있다고 합니다. 실험에서는 imagenet에 사전학습된 가중치를 전이학습하지 않고 scratch부터 학습하였다고 합니다.
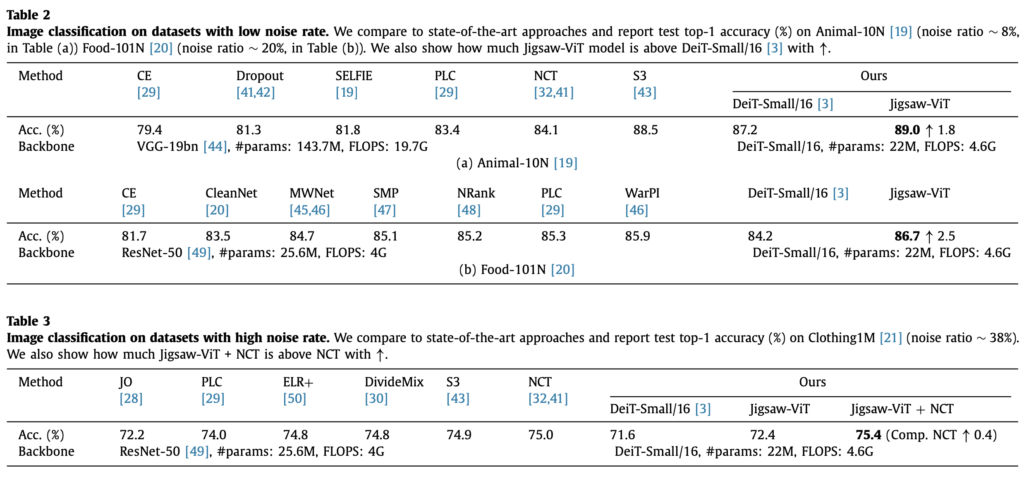
여기서도 Baseline인 ViT모델(Table의 DeiT-Small)모다 Jigsaw-ViT모델이 개선된 성능을 보임을 확인할 수 있습니다. 저자들은 Jigsaw-ViT에 추가해준 auxiliary loss가 내부적으로 noisy label을 학습하는데 regularization 효과를 주기 때문이라고 해석합니다. Table 3의 NCT같은 경우 sota 방법론이라고 하는데, Jigaw-ViT에 NCT라는 방법론을 추가했더니 sota보다 개선된 결과를 얻을 수 있었다고 강조합니다.
Conclusion
저자들은 기존 ViT에 positional embedding을 없애고 patch에 random masking을 가한 다음 새로운 jigsaw solving flow와 loss 항을 도입해 Jigsaw-ViT라는 신박한 모델을 제안했습니다. 기존의 Representation Learning의 pretext task로 사용되던 jigsaw puzzle solving을 이미지 패치를 활용하는 ViT에 적절히 잘 결합시킨 것 같습니다. 결과적으로는 본래 task인 classification 성능뿐만 아니라, noisy label이라는 특수한 상황에서도 해당 모델이 잘 작동함을 확인할 수 있었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
방법론이 그리 복잡하지 않은데 생각보다 간단한 방법으로 성능 향상을 이룬 좋은 논문이 아닌가 싶습니다. 궁금한 점은 representation learning 방법론이면 사전학습 모델로 많이들 사용하게 될 것 같은데 이 논문에서는 따로 학습 cost에 대해서 다루지는 않았는지 궁금합니다. (gpu를 어떤거를 사용했는지, 데이터셋은 얼마나 큰지, 며칠동안 학습했는지 등등)
또한, label noise가 강인하다에 대해서는 뭔가 뜬금없이 등장하는 느낌이 들기도 하는데요. 본 논문의 저자들이 Jigsaw-ViT에 추가해준 auxiliary loss가 내부적으로 noisy label을 학습하는데 regularization 효과를 주기 때문에 노이즈에 강인하다고 하는것 같은데 기존에 auxilliary loss가 noisy label을 학습하는데 효과적이다는 논문이 있나요?
auxillary loss가 헷갈리는데 L_jigsaw라고 생각하면 되는 걸까요?
감사합니다.
안녕하세요, 김주연 연구원님. 논문에 하이퍼파라미터 이외에 다른 학습 정보(gpu, training time)등에 대한 별다른 언급은 없습니다. 데이터셋의 경우, Animal-10N 데이터셋은 50,000장의 학습 이미지로, Food-101N의 경우 310,009장의 학습 이미지로, Clothing1M의 경우 백만 장의 이미지로 학습합니다.
label noise의 경우 저도 이 논문을 보며 처음 접했습니다. 다양한 실험을 해보며 contribution을 찾게 됐거나, 논문을 작성할 때 참고했던 다른 논문들에서 아이디어를 얻지 않았나 합니다. reference를 보면 noisy label을 다룬 논문이 다수 있습니다. regularization을 가하면 noisy label에 대해 어느 정도 성능을 확보할 수 있는 것으로 보입니다.
auxiliary loss는 분류 loss 이외에 추가적으로 더해준 jigsaw soling loss로 생각하시면 됩니다.
감사합니다
안녕하세요 재연님 좋은 리뷰 감사합니다. 왜 이전에 직소 퍼즐을 푸는 태스크가 챌린지 문제로 제시되었는지 이해가 되었네요.
본문의 Method 부분에서 질문이 있습니다. 수식 옆에 i = 1~N의 표현이 있는데 여기서 N은 무엇을 의미하는건가요?
또한 ypred = MLP(LN(vclsN))의 수식에서 vclsN은 어떻게 만들어지는가 궁금한데 vi와 vi’ 연관지어 설명해 주실 수 있나요??
감사합니다.
두 질문 모두 ViT의 모델 구조를 이해하면 해결됩니다. transformer 계열 모델들은 encoder 내부에 반복적으로 N개의 layer를 가집니다. 본문에서 N은 transformer encoder의 layer의 수입니다. encoder 내부에서 v0부터 N번 layer를 거친다고 생각하시면 됩니다. VclsN은 class token을 의미합니다. ViT, BERT 등의 모델에서는 입력 image patch(NLP에서는 단어 token)에 class token을 추가해 encoder에 넣어주게 되며, 결과 예측에 최종 feature를 모두 사용하지 않고 class token만을 사용해서 예측합니다. MLP에 vN 전체를 넣어주는게 아닌 일부만 사용한다고 생각하시면 됩니다.
이해되지 않는 부분이 있다면 ViT 모델의 동작 과정에 대해 살펴보는것을 추천드립니다.
감사합니다.