안녕하세요 오늘은 또 다른 moment retrieval 논문입니다.
trimmed video을 다루는 tasks에서는 CLIP과 같은 image-text 사전 학습 모델을 활용하는 연구가 많이 진행되고 있습니다. 하지만, untrimmed video를 다루는 tasks에서는 CLIP을 활용하는 연구가 아직 많이 진행되지 않았습니다. 따라서 저자는 untrimmed video에서 사전 학습된 image-text 모델과 feature pyramid를 활용하여 프레임 단위로 relavancy score와 start/end time displacements를 예측하는 모델 UnLoc을 제안합니다. UnLoc은 Moment Retrieval, Temporal Localization, Action Segmentation 총 3가지 task에서 활용 가능한 모델입니다.
Introduction
Contrastive vision-language 사전학습은 강력한 특징 표현력을 학습하며 다양한 분야에서 활용되고 있습니다. CLIP은 video classification, object detection, segmentation과 같은 task에서 많이 활용되며 강력한 성능을 보이고 있습니다. 이러한 CLIP과 같은 large image-text 모델을 temporal 정보를 다루는 video task에서도 활용하기 위한 연구가 현재 활발히 진행되고 있습니다. 하지만, fine-grained temporal 정보를 다루는 untrimmed video 관련 task에서 CLIP을 활용한 연구는 아직 초기단계입니다. image-text 모델이 foreground actions와 동시에 temporal backgrounds의 특징을 학습하는 것은 어렵기 때문입니다. 하지만 실제 영상에서는 많은 배경 영상이 포함되고 여러 temporal scale을 갖는 actions가 존재하기에 특정 action을 감지하는 것은 localization tasks에서 굉장히 중요합니다. 기존 연구는 이 문제를 해결하기 위해 proposal generator를 활용하는 2-stage 접근방식 혹은 C3D, I3D와 같은 temporal features를 활용하였습니다. 하지만 이 논문에서 저자는 CLIP의 two-tower model를 활용하는 학습 가능한 end-to-end 1-stage 접근 방식을 제안합니다.
저자는 사전 학습된 텍스트 인코더에는 중요한 정보가가 포함되며 similarity computation을 위해 나중에 활용되는 것이 아닌 모델 설계 초기에 이미지 인코더와 함께 활용되어야 한다고 언급합니다. 또한, feature pyramid 구조를 활용하여 multiple temporal scale을 다룰 수 있게 한다고 언급합니다.
Related Work
짧은 trimmed video를 다루는 classification tasks에는 ActionCLIP, X-CLIP, EVL과 같은 연구들은 CLIP에 추가적인 파라미터를 조금 추가하는 것으로 해결하려 했습니다. 하지만, untrimmed video를 활용하는 연구는 아직 C3D, I3D, SlowFast의 features에 의존하고 있습니다.
TAL(Temporal Action Localization)
TAL은 video 안의 events를 탐지하고 그에 해당하는 start, end time stamp를 반환하는 task입니다.
action proposal을 활용하는 기존의 연구와 달리 저자는 video, text features를 fusion하여 활용하여 class label 혹은 query에 해당하는 temporal location을 directly regress하는 proposal-free 프레임워크를 구성했습니다.
MR(Moment Retrievel)
Video Grounding이라고도 불리는 MR은 untrimmed video 안의 language description(query)에 해당하는 특정 video segments를 반환하는 task입니다. TAL과 비슷하지만, 사전에 정의된 closed-vocabulary set(e.g., “baking cookie”)을 쿼리로 사용하는 TAL과 달리 MR의 query는 사전에 정의되지 않은 구체적인 상황(e.g., ”The pans are filled with pastries and loaded into the oven.”)을 쿼리로 주어진다는 점에서 차이점이 있습니다. 이 부분이 MR이 TAL에 비해 더 어려운 task인 이유입니다.
기존의 연구들은 쿼리에 해당하는 구간을 찾는 방식을 크게 3가지 갈래로 나누어 연구되어 왔습니다. segment proposal을 진행한 후에 쿼리와 유사도를 구하는 Sliding windows 방식, proposal generation 대신에 여러 크기의 anchor를 활용하는 Anchor-based 방식 그리고 Regression-based 방식입니다. Sliding window와 Anchor-based 방식은 proposal을 사전에 정해진 크기로 한다는 점에서 fine-grained에는 불리함을 가집니다.
UnLoc은 Regression-based 방식을 사용합니다. Regression-based 방식은 region proposal 없이 쿼리에 해당하는 구간의 시간적 경계를 직접 예측할 수 있는 cross-modal interaction을 학습합니다. 유사성 점수를 계산하기 위해 text tower를 마지막에만 사용하는 기존의 연구들과 달리, UnLoc은 모델 초기에 이미지와 텍스트 토큰을 융합하여 사전 훈련된 CLIP text tower의 language priors를 더 잘 활용합니다.
AS(Action Segmentation)
AS는 사전에 정의된 closed-vocabulary set(”shape cookie”) 라벨을 활용하여 untrimmed video의 각 프레임 단위로 라벨링하는 task입니다. 각 프레임 별 라벨링을 함으로 유의미한 비디오 segments를 구별하는 task입니다.
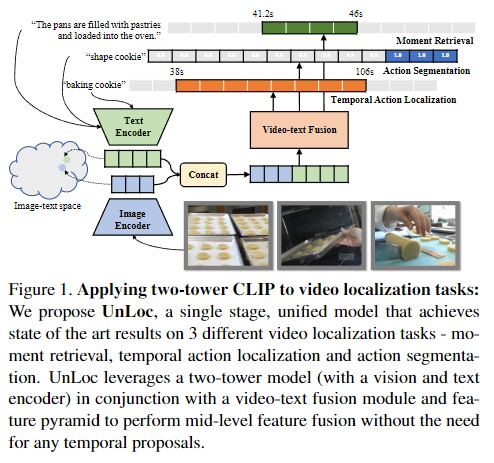
Figure 1은 two-tower CLIP를 사용하여 3가지 task(MR, TAL, AS)를 다루는 것을 보여주고 있습니다.
Architecture
UnLoc은 video, text 쌍을 입력으로 받아 비디오의 각 프레임에 대해 프레임과 입력 텍스트의 관련성 점수(relavancy score)를 구하고 예측 segment의 start/end timestamp와의 시간 차이를 출력합니다. 프레임이 라벨링된 segment에 포함된다면 1, 그렇지 않은 경우에는 0으로 설정됩니다. TAL과 AS는 클래스 라벨을 입력 텍스트로 사용하고 MR의 경우에는 텍스트 쿼리를 입력 텍스트로 사용합니다. 비디오마다 C개의 video, text 쌍을 생성합니다. TAL, AS에서는 C가 클래스의 수가 되고, MR에서 C는 비디오와 관련있는 captions의 수가 됩니다.
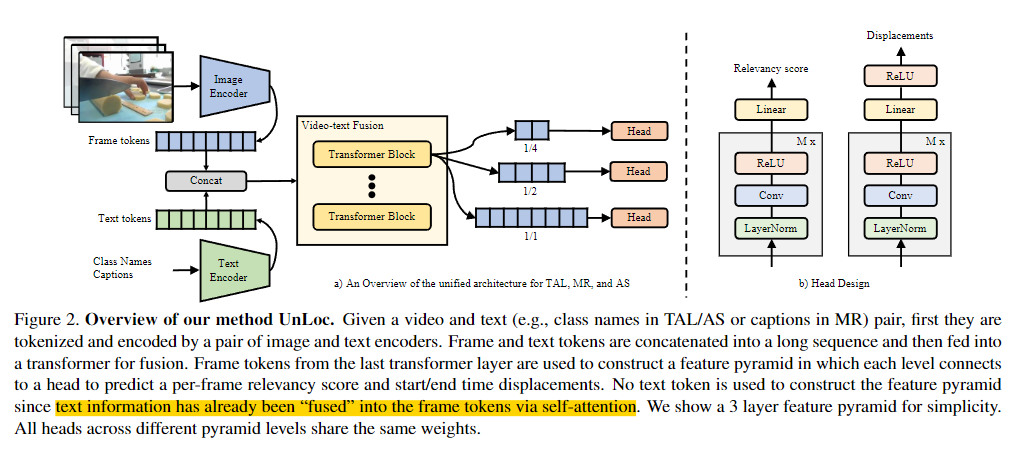
위의 Figure 2는 UnLoc의 architecture를 보여줍니다. 입력쌍은 먼저 토큰화되어 인코딩됩니다. 여기서 사용되는 두개의 인코더는 image-text 쌍에 대해 contrastive loss로 사전학습된 CLIP의 인코더를 사용합니다. 이는 관련성 점수를 구하는 데에 용이하게 사용됩니다. image-text 쌍은 당연히 align 되어 있으면 align되지 않은 경우 성능이 저하됩니다. 이는 ablation study에서 실험을 통해 증명됩니다.
토큰화와 인코딩이 끝나면, 입력 비디오와 텍스트는 N개의 frame과 T개의 text token으로 표현됩니다. 그런 다음 전체 텍스트 sequence를 나타내는 단일 토큰(e.g., CLS) 또는 모든 T 텍스트 토큰과 N개의 프레임 토큰을 연결하여 새로운 sequence를 구성합니다.
새로운 sequence video-text fusion 들어갑니다. video-text fusion 모듈은 트랜스포머의 인코더를 사용합니다. 트랜스포머의 인코더는 크게 두가지 역할을 합니다.
- 첫 번째는 이미지만 존재하는 CLIP 모델에서 생략하는 inter-frame 대응, 즉 temporal 정보를 모델링하는 temporal encoder의 역할을 합니다.
- 두 번째는 CLIP 모델의 실수를 수정할 수 있는 refinement network의 역할을 합니다.
fusion 이후에는 프레임 토큰 $X^c$만을 사용하여 stride convolution을 진행해 original sequence를 downsampling하여 여러 level의 feature pyramid를 구성합니다. 여기서 c는 클래스 또는 caption의 인덱스를 나타냅니다. 이 과정은 모든 클래스 라벨/캡션에 반복하여 진행합니다. fusion 모듈을 통해 video와 text의 정보가 fusion되었으므로 이후에 text token은 사용하지 않고 frame token만을 사용합니다.
마지막으로, 모든 pyramid level은 Head module로 연결됩니다. Head 모듈은 프레임별 relevancy score와 start/end time displacements를 예측합니다. 각 예측은 예측된 displacements를 frame timestamp에 적용하여 temporal segment로 확장됩니다. 모든 피라미드의 계층의 모든 segments들은 SoftNMS를 통해 필터링됩니다.
Feature Pyramid
feature pyramid는 다른 scale의 여러 events를 탐지할 수 있도록 도와줍니다. 기존의 FPN은 object detection에서 high level feature map의 더 풍부한 정보를 low level의 feature map에도 담기 위해 자주 사용되었습니다. UnLoc의 feature pyramid는 ViTDet에서 영감을 받아 lateral, top-down connections를 없애는 것으로 더욱 단순한 구조로 구성되었습니다. FPN의 lateral, top-down connections는 서로 다른 resolution을 갖는 feature map에 high level feature map의 semantic 정보를 전달하여 모든 feature map에서 풍부한 semantic 정보를 담기 위해 사용되었지만, 트랜스포머의 last layer는 더 풍부한 semantic 정보를 갖고 있는 동시에 첫 layer와 같은 temporal resolution을 갖기 때문에 lateral, top-down connections를 필요로 하지 않기 때문입니다. 따라서 UnLoc의 feature pyramid는 다른 크기의 stride를 주어 convolution을 진행하는 것으로 사용되었습니다. 이러한 단순한 구조는 인코더의 downsampling 단계를 없애 사전 학습 할 때와 같은 architecture를 공유할 수 있도록 도와줍니다.
Head Design
Figure 2의 오른쪽 그림에서 볼 수 있듯이 head module은 2개 존재합니다. 하나는 관련성 점수를 예측하기 위함이고 다른 하나는 dispacement regression을 위한 모듈입니다. 두 모듈은 같은 구조이지만 가중치를 공유하지는 않습니다. M개의 1D convolution blocks로 구성되어있으며 블록은 Layer Normalization, 1D convolution, ReLU 활성화 함수로 구성되어있습니다. 컨볼루션은 주변 프레임들이 동일한 라벨을 공유하도록 권장하기 위해서 사용되었다고 언급하고 있습니다. 추가적인 설명은 없지만 주변 프레임들의 값이 어느정도 비슷한 값을 가지게해 noise를 줄이는 방법인 것으로 생각됩니다. 블록 이후의 linear layer는 각 프레임 별 관련성 점수, start/end time displacements를 예측하기 위한 학습을 진행합니다. displacements의 경우, ReLU 활성화 함수를 거쳐 0 이상의 값만을 가지도록 했다고 합니다.
구간을 반환하는 MR, TAL의 경우 관련성 점수, displacements 를 모든 클래스/캡션마다 계산했고, 가중치는 공유합니다. AS는 displacements가 필요없으므로 관련성 점수만을 구합니다.
Loss Function
AS의 경우에는 프레임과 클래스 라벨 간의 관련성 점수 계산을 위해서 sigmoid cross entropy loss를 사용합니다. TAL과 MR의 경우에는 클래스 불균형은 1-stage detector에서 이미 알려진 문제이므로 관련성 점수에 focal loss를 사용합니다. 저자는 regression에서는 4개의 많이 사용되는 regression loss를 비교해 시험했습니다. L1, IoU, DIoU, L1+IoU입니다.
Focal Loss는 object detection에서 1-stage detector의 단점인 학습중 클래스 불균형 문제를 해결하기 위해 고안된 손실함수입니다. 학습중 클래스 불균형은 배경을 탐지하는 비율이 높아 학습에 방해가 되는 것을 의미합니다. 배경은 easy negative의 케이스로 모델이 비교적 쉽게 구별할 수 있기에 정확도가 높고 실제 객체는 비교적 hard한 문제로 loss가 크지만, 배경의 수가 많기에 실제 객체 추정을 위한 loss의 총합보다 배경에 사용되는 loss의 총합이 커지는 문제가 생기게됩니다. 이를 해결하기 위해 Focal Loss는 확률이 높은 경우(배경)보다 확률이 낮은 경우(실제 객체)보다 loss를 더 크게 낮춥니다.
L1 loss는 예측 start/end time과 정답 start/end time과의 차이의 절대값을 뜻합니다. IoU loss는 다음과 같이 정의되는 집합의 교차점을 직접 최적화합니다
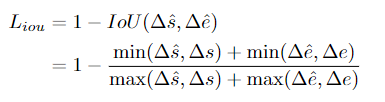
△s_hat, △e_hat 및 △s, △e는 각각 예측 start/end time에 대한 예측 및 GT displacement입니다. 만약 △s_hat, △e_hat가 0이라면, 기울기 또한 0이 됩니다. 이는 안좋은 initialization으로 생길 수 있는 문제입니다. DIoU는 위 문제를 해결하기 위해 제안된 손실함수로 GR box의 중심과 예측 box의 두 중심을 비교합니다. ablation study를 통해 저자는 L1 loss를 사용했다고 밝히며 α를 사용하여 focal loss와 L1 loss의 비율을 맞춘다고 말합니다.
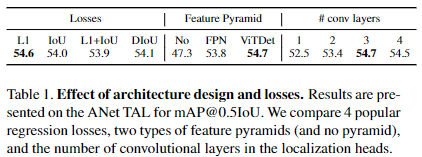
표 1의 왼쪽에서 L1 loss를 사용하는 것이 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
Experiment
Datasets and Evaluation Metrics
Moment Retrieval
Activity Captions 데이터셋은 20k의 비디오와 10k의 사람이 annotate한 segments가 존재합니다. 각 captions는 평균적으로 13.5개의 단어와 2분 정도의 길이로 이루어져 있고, train, val_1, val_2로 구성되어있습니다. 저자는 UnLoc의 학습을 위해 train으로 학습, val_1으로 검증, val_2로 테스트했다고 합니다.
Charades-STA 데이터셋은 6672개의 비디오, 16128개의 segment/caption 쌍이 있으며, 학습으로 12408쌍, 테스트로 3720쌍을 사용합니다. 모든 비디오는 평균 2.4개의 segments와 8.2초의 길이를 갖습니다.
QVHighlights 데이터셋은 10148의 150초로 cropped된 비디오로 구성되어있습니다. 각 비디오는 최소 1개 이상의 쿼리로 annotate되어있으며 24.6초의 평균 시간을 가집니다. 총 10310의 텍스트 쿼리와 18367개의 해당하는 영상으로 구성되어있습니다.
평가지표로는 Recall@K, IoU=[0.5, 0.7]을 사용합니다. 서로 다른 IoU 임계값(0.5,0.7)에서 계산된 k의 평균 리콜이며, GT segment와의 IoU가 임계값보다 더 큰 값을 갖는 상위 k개의 예측 segment 중에 적어도 하나가 있을 확률로 정의됩니다.
Temporal Action Localization
ActivityNet 1.3은 20k의 untrimmed 사람 행동으로 구성된 데이터셋입니다. 대부분의 비디오는 하나의 라벨링된 segment 혹은 하나의 클래스에 대해 여러개의 segments가 존재하는 형식으로 존재합니다.
TAL의 평가지표로는 mAP를 사용합니다. 구체적으로는 mAP@0.5IoU를 사용하며 이는 mAP 계산에 사용하는 IoU의 임계값을 0.5로 설정하여 계산합니다.
Action Segmentation
COIN 데이터셋은 11827의 학습용 비디오와 2797개의 테스트용 비디오로 구성되어 있습니다. 각 비디오는 평균 14.9초의 길이를 갖는 3.9개의 segments로 구성되어 있으며 mAP를 평가지표로 사용합니다.
Implementation Details
Model Architecture
UnLoc-Base, UnLoc-Large 모델 총 두가지 모델에 대해 실험을 진행했으며 video-text fusion module의 경우 6-layer transformer와 base의 경우 hidden state를 512, large의 경우 hidden state를 768로 설정했습니다. UnLoc-B(Base), UnLoc-L(Large) 각각 MLP dimension은 2048, 3072로 설정했습니다. feature pyramid의 경우 4-layer로 구성했습니다. regression range는 pyramid의 레벨별 [0,4], [4,8], [8,16], [16,inf]로 설정되어 bottom-up으로 정렬되었습니다. 서로 다른 레벨의 모든 head들은 같은 가중치를 공유하며 랜덤 init했습니다.
Pretraining
사전학습은 Kinetics(모델은 K700, ablation study를 위해선 K400)을 사용했으며 400/700-way 이진 분류 문제로 sigmoid cross entropy를 사용하여 학습했습니다. 여기서 이진 분류는 클래스 라벨과 영상이 매칭하는지, 아닌지로 이진 분류하였습니다. Kinetics 사전학습 동안에 image 인코더는 finetuned되었고, text 인코더는 freeze하여 catastrophic forgetting을 막았다고 합니다. 여기서 catastrophic forgetting은 Kinetics의 small fixed vocabulary를 finetuning 하기 때문에 생기는 문제라고 하는데 무슨 말인지는 정확하게 모르겠지만, text를 freeze하지 않으면 학습이 제대로 되지 않는 것을 의미하는 것 같습니다.
Training
학습 때 프레임들은 짧은 곳의 256으로 resize된 후에 224×224로 random crop합니다. TAL과 AS의 경우 Kinetics의 prompt인 “a video of a person doing {label}”로 사용됩니다. 특별한 이유가 없는 한 TAL과 MR의 경우 여러 길이의 비디오를 다룰 수 있도록 전체 비디오를 128프레임으로 나누어 학습됩니다. 모든 모델은 synchronous SGD를 사용하여 0.9의 모멘텀, 64의 배치 사이즈로 학습했습니다.
Inference
Inference시에는 224×224로 centor crop했습니다. COIN 데이터셋에서 AS할 때에는 겹치는 구간 없이 512프레임으로 나누었습니다.
Comparison with SOTA
Moment Retrieval
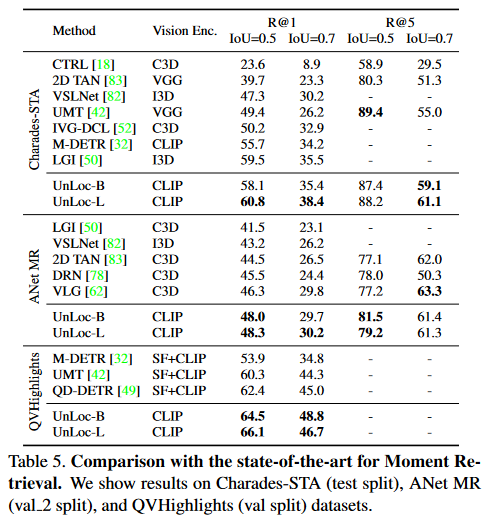
Moment Retreival에서의 UnLoc-B와 UnLoc-L의 성능은 다음과 같습니다.
Temporal Localization
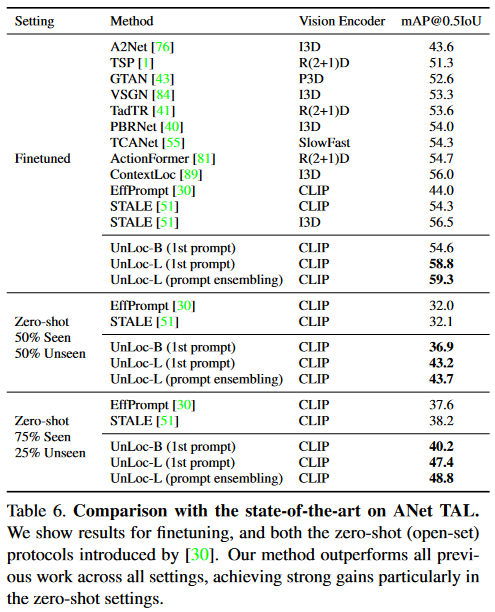
Temporal Action Localization에서는 zero-shot 실험도 진행했으며 성능은 다음과 같습니다. UnLoc-L에 1st prompt는 training에서 설명드린 class label을 “a video of a person doing {label}”의 문장 형태로 프롬프팅하는 것입니다. prompt ensembling은 위의 프롬프트 외에도 여러 프롬프트를 사용해 앙상블을 한 모델이라고 합니다. 구체적으로 어떠한 prompt를 사용했는 지에 대한 언급은 없습니다.
Action Segmentation
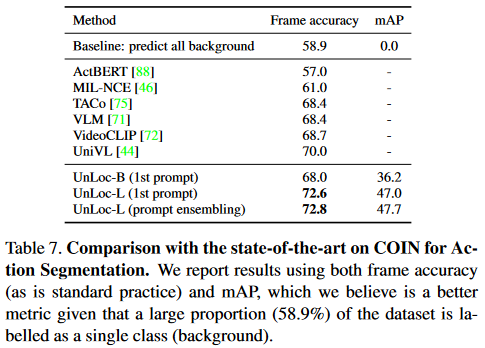
Action Segmentation의 성능은 다음과 같습니다.
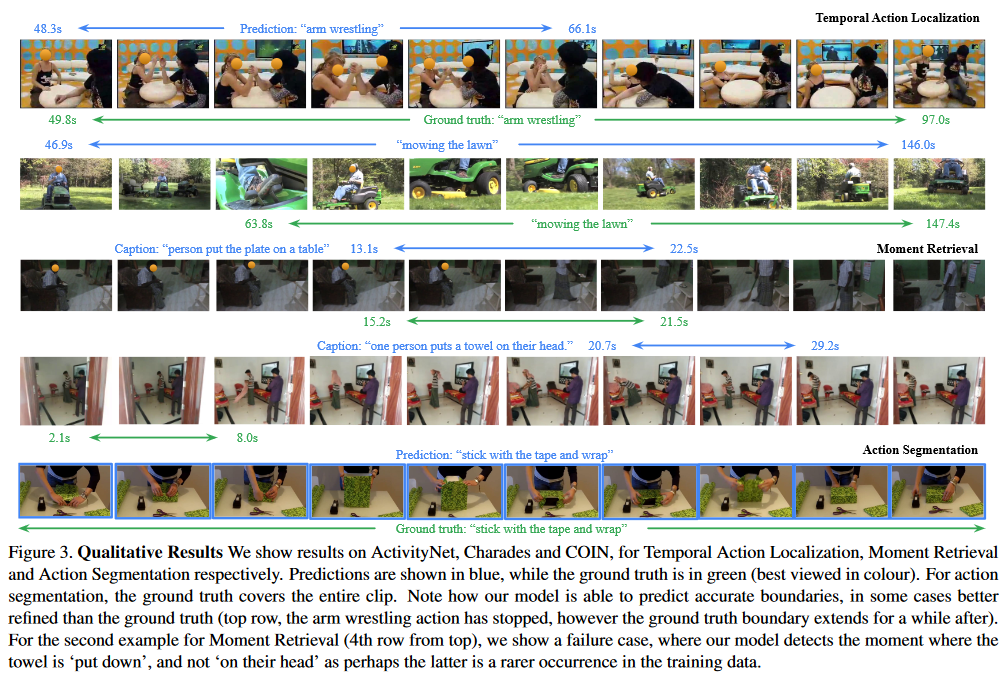
위의 Figure 3.에서 정성적인 UnLoc의 성능을 확인할 수 있습니다.
Conclusion
저자는 비디오의 3가지 task에서 활용할 수 있는 하나의 모델 UnLoc을 제안합니다. two-tower CLIP와 video-text fusion module 그리고 feature pyramid를 사용하였으며 3 task 모두 좋은 성능을 보입니다. 저자는 이후 future work로 많은 weakly labelled 데이터셋에 대한 사전학습을 하는 것과 highlight detection과 같은 다른 task에도 접목시킬 수 있는지, 그리고 audio와 같은 다른 모달리티와의 활용 등을 언급하며 이후 연구의 방향성을 제시하며 논문을 마칩니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다
리뷰를 읽다보니 모델구조에 따로 노벨티가 높은 편이 아니고 이 task에서 CLIP을 사용하여 성능 향상을 이뤘다가 주요 컨트리부션인거 같은데 제가 잘 이해를 못한걸지도 모르지만 CLIP때문에 ICCV 2023에 되었다는 것이 신기하네요
질문이 있는데요. CLIP의 경우 프롬프트를 어떻게 주는지에 따라서 성능차이가 발생하고 이전에 현우님 리뷰를 보면 학습 가능한 프롬프트를 사용하여 성능 항샹을 이룬 논문이 있는걸로 아는데 여기서는 이와 비슷한 실험을 진행하지는 않았나요? 프롬프트 앙상블이라는 실험을 진행한 것으로 보이는데 이는 여러 버전의 프롬프트를 입력으로 주어 뽑은 피쳐를 나이브하게 앙상블 사용한것으로 이해할 수 있을것 같은데 제 이해가 맞을까요?
안녕하세요 주연님 좋은 답변 감사합니다.
논문에서는 TAL task에서 class 라벨을 그대로 사용하는 것이 아닌 프롬프트를 활용하였고 “a video of a person doing {label}”의 프롬프트를 사용한 결과와 28가지의 prompt를 사용한 결과를 비교합니다. 두 실험결과는 약 0.5%정도의 성능 차이가 났다고 밝히고 있으며 28가지의 prompt는 ICML 2021에 개제된 “Learning Transferable Visual Models From Natural Language Supervision” 논문의 방식을 참고했다고 말하는데 해당 논문은 CLIP이 소개된 논문으로 CLIP의 prompt 방식을 그대로 사용한 것으로 생각됩니다.
안녕하세요 좋은 리뷰 감사합니다.
읽다보니 궁금한 점이 생겼는데, UnLoc은 3가지 task를 동시에 학습하는 것인가요?
예를 들어 moment retrieval 벤치마크 성능을 뽑기 위해 모델에 3가지 task의 데이터와 라벨을 모두 사용하여 학습 후 추론을 하는 것인지, K700으로 사전학습 후 Moment retrieval에 대한 학습 및 추론을 진행하는 것인지 궁금합니다. 만약 전자라면 multi-task learning 관점에서 task들이 서로의 학습에 어떠한 영향을 미치는지에 대한 분석도 있는지 궁금합니다.
그리고 이번에 리뷰해주신 UnLoc이나 UniVTG의 경우 Grounding만 수행하는 방법론들과 성능 경향이 어떻게 되던가요? 물론 TAL이나 AS task에서의 성능 경향성도 있겠지만, Grounding 관점에서 Grounding만 수행하는 최신 논문들에 비해 성능이 어떠한지, 또한 그 연장선에서 여러 task를 하나의 모델로 수행할 수 있는 방법론이 왜 좋은지에 대해 어떻게 생각하시는지 궁금합니다.
안녕하세요 현우님 좋은 답변 감사합니다.
먼저 UnLoc은 3가지 task를 다룰 수 있는 end-to-end 구조로 구성되었지만, 3가지 task를 동시에 학습하지 않습니다. TAL과 MR의 경우에는 TAL의 쿼리를 ‘a video of a person doing {label}’의 prompt를 활용하여 MR과 같은 쿼리의 형태로 만든 후에 같은 방식으로 학습을 진행하고 학습하는 방식이 같지만, AS의 경우에는 학습하는 방식이 다르기 때문에 동시에 학습은 불가능합니다. 따라서 MR, TAL, AS 각각 task에 맞게 fine-tuning 과정을 거쳐 활용하게 됩니다.
하지만, 사전 학습의 경우에는 비디오와 자연어의 representation을 학습하는 과정으로 Image Encoder, Text Encoder, Video-text Fusion Module을 학습합니다. 쿼리와 비디오의 프레임이 연관이 있는지 없는 지에 대한 이진 분류로 학습하기에 3가지 task모두 같은 사전 학습 모델을 활용합니다.
현우님이 예시를 들어주신 대로 K700에 대해 사전 학습을 진행한 후에 사전 학습 모델을 바탕으로 서로 다른 task에 대한 학습 및 추론을 진행합니다.
UnLoc과 UniVTG와 같은 Unified 모델의 경우, Grounding만 수행하는 방법론들에 비해 성능이 크게 차이가 나지는 않지만 조금 더 낮은 것으로 확인됩니다. 최근 Grounding만 수행하는 최신 논문들은 C3D, I3D, SlowFast와 같은 CNN기반의 feature들을 video encoder로 활용합니다. 아직 최신 논문들을 많이 읽어본 것은 아니라 정확한 분석은 아닐 수 있지만, 여러 task를 수행하기 위해 CLIP을 활용하는 논문들의 큰 단점을 바로 CLIP은 temporal 정보를 담고 있지 않다는 점입니다. 물론 이를 해결하기 위해 attention을 활용하는 등 문제를 해결하려는 시도들이 많지만, 아무래도 C3D, I3D, SlowFast와 같은 모델의 temporal 정보에는 못 미치는 것으로 생각됩니다.
그럼에도 불구하고 여러 task를 하나의 모델로 수행하는 방법론들의 연구들의 성능이 크게 차이 나지 않는 것은 CLIP과 같은 방대한 크기의 image-text 사전 학습 모델이 image와 text의 feature를 잘 담고 있고 두 모달리티의 유사성을 잘 표현하기에 좋은 성능을 보이는 것이라 생각합니다.
감사합니다.