안녕하세요. 논문 리비전 이후 몇몇 업무들을 마친 이후, 한숨을 돌리고 3월 석사의 시작과 동시에 관심 분야의 OWOD에 대한 이해를 위한 논문 읽기에 열을 올릴 예정입니다. 최근 리뷰한 논문들을 살펴보면 주로 Few-Shot OD와 관련된 논문을 주로 읽었습니다. PD 이후의 자율 주행 관점에서 앞으로의 연구 트렌드를 예측해보고, 사회와 기업의 니즈를 분석하다보니 “급변하는 사회 속, 지금처럼 OD를 잘해내는 것 외에도 (2D든, 3D든 상관 없이) 클래스 범주 외의 새로운 물체에 대해서도 파악하는 것”이 필요할 것으로 생각을 하였는데, 사실 OWOD라는 태스크가 있음에도 불구하고 해당 태스크들이 멀티 모달로 텍스트를 함께 사용하고 있음에 두려움이 있었습니다. 지금이라면 누구든 아는 CLIP 등의 논문도 자세히 알지 못한 채 텍스트를 사용하는 멀티 모달은 너무 어렵단 생각이 들었습니다. 그렇기에 내가 석사 과정 동안 해낼 수 있는 분야는 Few-Shot이지 않을까 싶었는데, 시대의 흐름에 동승하는 것도 굉장히 중요하죠.
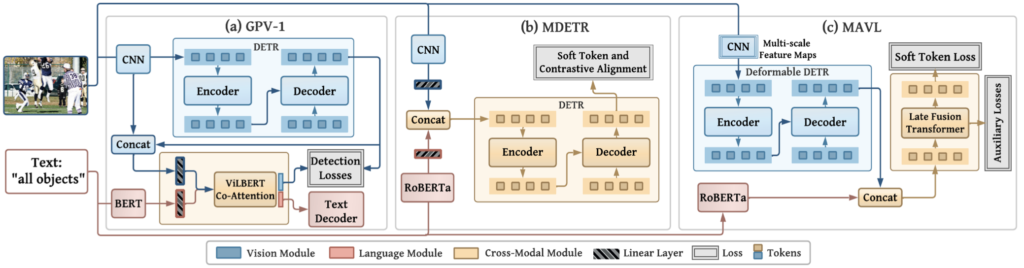
그래서 OWOD의 논문들을 차찬히 훑어보던 중, 물론 김태주 연구원께서 리뷰하신 OWOD의 시초인 Toward Open World Object Detection 논문을 처음 읽는 것이 맞았으나, PapersWithCode 기준 대부분의 OWOD 태스크에서 좋은 성능을 보이는 “Class-agnostic Object Detection with Multi-modal Transformer”가 눈에 들어왔습니다. 아래 그림에 보이는 해당 논문의 모델 구조를 살펴보니, (b) MDETR이라는 글이 보이더군요. 이번 논문은, 그런 연유로 읽게 되었습니다. GPV-1이 뭔지 잘 모르지만, 단순히 MDETR도 무엇인지 살펴보고 싶었습니다. OWOD 태스크의 논문은 아직 몇 십 단위에 머물러 있어 몇 달 노력하면 흐름을 이해하긴 하겠지만, 그런 와중 나오는 개념까지 파생해서 모두 이해하고자 하면.. 뭐 언젠가 하리라 생각합니다. 사담이 길었으니, 바로 시작합니다.
Introduction
아직 Multi-Modal Detection에 대해 충분히 이해하지 못하여 다소 간략히 표현할 수 있습니다. Object Detection (이하 OD)는 최근 SoTA의 Multi-Modal에 관한 시스템의 요소로 사용됩니다. 이는 이미지와 텍스트를 동시에 활용하는 Multi-Modal (이하 MM)의 어떤 태스크에서, OD 방법론이 유용히 쓰인다는 의미죠. 하지만 저자는 MM의 추론 과정이 Visual Feature를 추출하는 OD에 의존하며, 이 때 OD는 Black-Box와 같이 사용되는데 (Faster-RCNN을 예로 들어 단순히 영상을 입력으로 넣으면 그들의 사전 학습 가중치에 따라 RoI를 생성해내는 과정이 결국 사전 학습 가중치에 의존되므로 블랙 박스로 표현됩니다), 이 [1] Black-Box OD로부터는 Visual Feature를 뽑은 이후 추가적인 결합을 거치지 않아 (학습 관점에서 보면, 미분이 끊긴다는 의미입니다) Main Neural Network (Visaul Feature를 Language Feature와 결합한 이후 MM의 추론을 위해 설계한 Neural Network, 주로 Transformer가 사용됨)과 같이 학습되지 않으므로 학습 시 Detection Performance가 개선될 여지가 없으며, [2] 해당 OD는 Bounding Box (이하 BBox) 내의 Visual Feature만을 추출하여 이미지 전역의 Feature에 대해 고려하기 어려우며, [3] 아무리 좋은 Visual Feature를 추출하는 OD라 한들, 사전에 학습한 범주 내에서만 고려할 수 있어 성능에 병목 현상이 발생하며 (이는, 제가 CLIP 논문을 활용한 어떤 연구를 소개하는 연구실 세미나 때마다 몇 번 질문한 점으로, CLIP에 의존한다는 점에서 해당 CLIP 내 없으면 어떻게 되는지에 대한 의문점과 동일하다고 보여집니다. CLIP에만 의존한다면, 진정한 의미의 Zero-Shot, Open-World로 볼 수 있는가에 대해서는 지극히 개인적이지만, 아직 회의적이기 때문입니다), [4] 해당 OD를 사용하는 통상적인 Visual-Linguistic Model들은 Fixed-Form의 텍스트 임베딩 (e.g. CLIP)과 학습하므로 Free-Form의 전체 문장에 대해서는 해당 문장의 Novel한 표현을 제대로 활용하지 못하는 문제가 발생합니다. [4]에 대해 이는 [3]의 문제와 동일하게 이미 학습이 끝난 Visual-Linguistic Model 관점에서는 학습 시 본 적이 없는 표현에 대해서는 해당 표현과 표현에 대한 의미를 제대로 찾아내기 어렵단 점이죠.
저자의 기 연구들에 대한 문제 정의는 위의 문단으로 정리할 수 있습니다. 저자는 DETR 프레임워크에 기반을 둔 End-to-End 방식의 변형도니 DETR인 MDETR을 소개합니다. MDETR은 이미지에 대한 이해를 위해 Supervision의 형태로 Text와 Text에 Align된 BBox에 대해 학습하는 형태입니다. 이 때 Align되었다는 의미는 후에 DETR에 대한 개념을 다시 짚어보면 더 잘 이해할 수 있겠지만, 지금은 아래 Figure 1처럼 “A pink elephant”에 맞는 BBOX로 이해하면 됩니다.

말이 조금 어렵지만, 위의 방식은 다시 말해 MDETR은 Black-Box OD가 필요없이, 이미지의 전역적인 Feature를 추출함으로써, 동시에 전체 Text를 모델에 통과시킨 Embedding을 추출함으로써, 그리고 그 둘을 네트워크 초기에 퓨전함으로써 Fixed-Form과 비교하여 Free-Form Text로부터 미묘한 차이를 찾아낼 수 있으며, 객체와 객체의 속성에 대해 본적이 없던 (위 Figure 1의 마지막 문장에 주목해주세요. 해당 모델은 Pink, Blue 코끼리를 학습 시 본 적이 없습니다), Unseen 경우에 대해서도 적절한 (Text-BBox) 묶음을 생성해낼 수 있습니다. MDETR은 Text에 기반한 예측을 수행하여 Visual-Language Resoning 분야인 Phrase Grounding, Expression Comprehension, Expression Segmentation, VQA에 좋은 성능을 보인다고 소개합니다.
Method
Background – DETR
앞서 언급한 바와 같이, MDETR은 DETR을 베이스로 구현되었습니다. 따라서 DETR에 대한 이해가 필요합니다. DETR 논문에 대한 소개는 예전 저의 리뷰와 임근택 연구원의 리뷰 가 있기에 해당 리뷰를 읽는 것이 더 도움이 되므로 지금은 간략히 요약하고 넘어가겠습니다.

DETR은 RseNet과 같은 Backbone과, 뒤 이어 나온 Transformer Encoder-Decoder로 구성되어 있습니다. DETR Encoder는 영상을 Backbone에 통과시켜 얻은 Activation Map을 채널 축에 대해 Projection하여 2D Flatten한 다음 2D Positional Encoding을 더해준 다음 일련의 패치로 만들어 Transformer Encoder의 입력으로 넣어줍니다. 이후, 우선 DETR Decoder는 Object Query로 불리는 학습한 N개의 임베딩 집합을 입력으로 받으며 이는 모델이 객체를 찾아 채워넣어야 하는 Slot으로 볼 수 있습니다. 이제 해당 Slot들은 Transformer-Decoder (Cross-Attention으로 구성됨)에 병렬적으로 입력되고 난 이후, 가중치를 공유하는 FFN을 통과하고 나면 각자의 예측 (Class 및 Bounding Box 위치)을 뱉게 됩니다. 위 DETR의 구조에 보이는 빨간색, 초록색, 노란색, 파란색 박스는 결국 모델이 감지하는 Object의 수와 같으므로, 주어진 이미지에 대해 발견할 수 있을 것으로 기대되는 충분한 큰 사물의 수로 정해야합니다. 이는, DETR의 한계점이죠. 물론 DETR이 100개의 Slot을 사용하는 것으로 알며 이는 보통의 추론 데이터에 대해 충분하다고 여겨지지만, OWOD의 관점에서 보면 더 많은 객체를 탐지하지 못하는 것은 아쉬움으로 남을 수 있습니다. 그렇다한들, 무작정 Slot을 늘리기만 하면 이후의 Bipartite Matching 시 비용도 생각해야죠. 이 때 초록색 Slot의 no object와 같은 경우, 객체가 아닌 배경에 대해 매칭되는 Slot으로 모델은 학습 시 Object로 보지 않는 모든 Query에 해당 클래스를 출력하도록 학습됩니다. 또한 DETR은 Hungarian Matching Loss를 통해 학습되는데, 이 때 예측한 N개의 객체와 GT object 사이의 Bipartite Matching이 계산됩니다. 해당 Loss에 대해서는 제 리뷰 글을 참고하시길 바라며, 최종적으로 Classification Head는 Cross-Entrophy를, BBox Head는 L1 loss와 GIoU의 조합을 사용해 Supervised 방식으로 학습합니다. Loss에 대해 잠시 언급한 이유는, MDETR도 마찬가지입니다. 이 DETR에 대해 추가적인 Loss를 붙여 학습하죠.
MDETR – Architecture
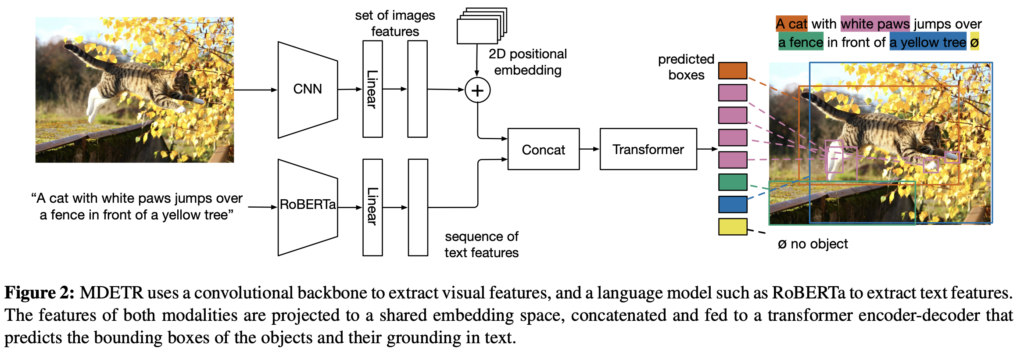
이제 MDETR의 Architecture를 살펴봅니다. 우선 [1] 이미지는 CNN Backbone에 의해 Encoding된 이후 2D Flatten됩니다. 이후 2D Positional Embedding을 더해준다는 점도, DETR과 동일합니다. [2] 텍스트는, RoBERTa라는 (해당 모델에 대해선 정확히 모릅니다만) 사전학습된 트랜스포머 방식의 자연어 처리 모델에 의해 Encoding되며 이미지와 동일하게 Flatten하여 입력 텍스트와 동일한 사이즈의 Hidden Vector (1D)를 생성해냅니다. CLIP이 입력 텍스트를 고정된 크기로 Embedding 한다는 점과 비교했을 때, Free-Form Text로 소개한 점이 바로 이점에서 기인합니다. [3] 이후, Image Feature와 Text Feature에 대해 각각 Linear Projection을 적용하여 둘을 동일한 Embedding Space 내 Projection합니다. [4] 이는 뒤의 Concat 연산을 위함으로써, 이 때 Concat을 통해 두 정보가 일차적으로 퓨전된다고 이해하면 되겠습니다. [5] Concat 되고 나면, 이미지와 텍스트는 단일의 시퀀스 형태로 존재하며 이를 Transformer Encoder에 태웁니다. (저자는 이를 Cross Encoder로 명명합니다). [6] DETR의 구조를 차용한 것이죠, 이제 Cross Encoder의 최종 Hidden State (Object Query)들에 대한 Transformer Decoder를 적용한 이후 FFN을 달아 Text에 나타나는 Object들에 대한 Class와 BBox를 예측하도록 합니다. 자, 저는 “Text에 나타는 Object들에 대한 Class”로 설명했습니다. 이는 어떤 의미일까요? 바로 다음의 Training 과정을 살펴보겠습니다.
Training
저자는 위의 DETR 소개시에 나온 Loss 외 두 Loss를 추가적으로 설계하였습니다. 해당 Loss들은 이미지와 텍스트 간 Align을 맞추기 위함이죠. 이제 맨 처음 언급한 Align에 대한 의의를 살펴볼 수 있는데, 두 정보가 Fusion되었어도 결국 서로 간의 Representation은 차이가 날 것 입니다. 이를 Align 했다는 의의 그리고 각 Object에 대한 예측을 위한 Slot에 Text와 Object가 적절히 매칭되도록 하기 위한 Align으로 생각해도 좋습니다.
Soft token prediction
우선, Soft token prediction은 Non-parametric한 Alignement Loss입니다. 제가 MDETR Architecture에 대한 소개의 마지막에서 “Text에 나타는 Object들에 대한 Class를 예측한다”고 설명하였는데, 결국 우리가 MDETR이라는 모델을 사용하여 할 일은 예를 들어 “텍스트를 보고, 영상에 나타나는 객체와 텍스트를 매칭하여 찾아내기”입니다. 저자도 이 점을 언급하죠. “우리는 예측한 객체 가각에 대한 클래스를 예측하는데 관심이 없다”, 이는 곧 전통적인 OD와는 그 의의가 다르다는 점입니다. 텍스트에서 이미 찾아야 할 대상을 기반하고 있죠. 다시 말해 원본 텍스트로부터 나온 토큰들과와 이에 매칭되는 각각의 객체들에 대해 예측하고자 합니다.
구체적으로, 주어진 문장에 대해 표현할 수 있는 토큰의 최대 수를 L=256으로 정합니다. Bipartite Matching을 통해 GT와 매칭된 예측 박스들에 대해 모델은 객체에 상응하는 모든 Token 위치의 Uniform Distribution을 예측하도록 학습됩니다.
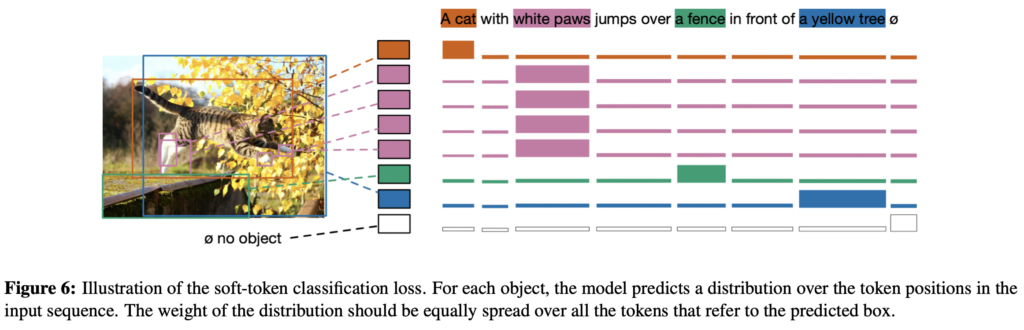
위 MDETR Architecture Figure를 다시 보면, 고양이에 해당하는 주황색 BBox가 A와 Cat이라는 두 단어에 대해 모두 매칭되도록 균일한 분포를 학습했다고 볼 수 있습니다. 위의 Figure 6에서도 이 점이 보이죠. 결국, 각 Slot의 BBox들이 Text의 어떤 토큰 (A도 토큰, Cat도 토큰, With도 토큰, …)에 매칭되도록 학습하고자 그 토큰들에 대한 분포 (분포라 한들, 결국 매칭에 대한 확률과 동일한 의미로 봐도 무방하지 않을까 생각합니다)를 예측한다고 보면 되겠죠. 균일 분포를 예측한다니, 저는 처음 들어봐서 이해에 오래 걸렸네요. 그렇다면 “No Object”에 대응해야하는 Background들은, 공집합 표기에 해당하는 균일 분포를 예측하도록 학습되겠죠. 그런데 Loss에 대한 수식이 논문 상 따로 나와있지는 않은데요, 그래서 다른 글들을 조금 찾아 보다가, 발견한 문장으로 “결국 한 Query(Slot)의 BBox가, Text의 어떤 부분과 관련 있는지 예측하도록 학습하며, 각 Slot마다 관련이 있는 토큰을 표시하는 Logit(위 Figure 6의 분포)과 이 Logit에 log_softmax를 취하면 (Query의 수) x (토큰의 수)에 해당하는 행렬이 나오며, 이를 GT 행렬 (GT도 위와 동일하게 구성할 수 있죠)과 Hadamard Product를 한 이후의 행렬의 총합을 Loss로 취한다고 합니다. 즉, 각 Slot (BBox)와 Text 토큰에 대한 값을 행렬로 구성하여 GT와 곱하면 GT에 대응하는 부분에 대한 Loss가 상당 수 높게 취해지게 되는 개념을 사용합니다. 이 때, 텍스트 내 여러 단어가 이미지의 동일한 Object에 상응할 수 있고 (위의 A, cat과 같은 경우) 역으로 여러 Object들이 하나의 텍스트 토큰 (위의 White, Paws와 같은 경우)에 상응할 수도 있겠죠. 그렇게 함으로써, 모델은 동일한 표현에 대해 공동으로 참조되는 객체에 대해서도 학습할 수 있습니다 (논문의 말이 어려운데 간단히는 White Paws라는 텍스트에 해당하는 객체들을 다양한 이미지의 특징에서 학습할 수 있는 이점이 있다는 점이죠)
Constrative alignment
위의 Soft token Prediction Loss가 객체와 텍스트의 위치를 Align하기 위해 위치 정보를 활용하는 반면, 이번의 Contrastive alignment Loss는 Decoder Output의 Embedding된 Feature Representation과, Cross Encoder의 Output에서의 Text Representation 사이의 Alignment를 위함입니다. 이렇게 말하면 너무 어렵고, 앞서 DETR Architecture에 소개한 바와 같이 Linear Projection을 통해 객체에 대한 Visual Representation과 상응하는 Text Token Representation을 동일한 Feature Space에 두었으니, 상응하는 둘은 더 가깝게, 상응하지 않는 둘은 더 멀게 만드는 Loss입니다. 바로 Loss에 대한 수식을 보죠. InfoNCE Loss를 안다면 이해는 쉽습니다.

이해를 위해 해당 설명 글까지 함께 첨부하였는데요, InfoNCE Loss와 동일한 방식으로 작동하며 L, N 이 각각 토큰의 최대 수와 객체의 최대 수로 두고, |T_i^+|, |O_i^+| 를 각각 Object가 Align되어야 할 Token의 집합, Token이 Align 되어야 할 Object의 집합으로 두고 나면, 나머지는 Negative Sample이니 멀어져야하죠. 최종에는 둘의 평균을 contrastive alignment Loss로 정합니다.
Experiments
Pre-training Modulated Detection Pre-training 시의 목적은 Free-Form으로 주어진 텍스트 내 모든 객체를 검출하는 것입니다. 이를 달성하고자 하는 간단한 방법은 많은 양의 데이터를 학습시키는 것입니다. 저자는 Flickr30k, MS COCO, Visual Genome (VG)의 영상 데이터를 결합한 결합 데이터 셋을 만들었습니다. Referring expression datasets, Flickr entities, 그리고 GQA train balanced set으로 부터 학습을 위한 어노테이션을 가져와 이를 정제하였습니다. 결국 이러한 방법들로부터 이미지 하나는 연관된 텍스트 어노테이션을 여러 개 가질 수 있는데, 저자는 이 점이 데이터 효율성 관점에서 좋으며 또한 단 하나의 문장만 있다면 Trivial solution에 빠져 모델이 이미지에 대한 이해 없이 문장만 볼 수 있으나 데이터 결합 과정을 통해 같은 객체 클래스가 여럿 나오더라도 이들 간의 모호함을 잘 구분하여 각각을 잘 구별해낼 수 있다고 봅니다. 아래 Figure 3을 잘 살펴보시죠!
Model 저자는 RoBERTa-base를 Text Encoder로 사용합니다. 반면, 이미지에 대한 Backbone으로는 ResNet-101과 EfficientNet을 사용하여 성능을 보입니다.
Downstream Tasks
다양한 Downstream Task에 대해 실험을 하였으나, 현재 해당 태스크에 대한 자세한 실험 세팅을 소개하기 보다는 해당 태스크가 어떤 태스크인지 소개하고, 사용한 데이터 셋을 살펴보고, 성능 지표를 간단히 소개하고, 해당 실험 성능 표를 한번 구경하는 것으로 마무리 짓겠습니다.
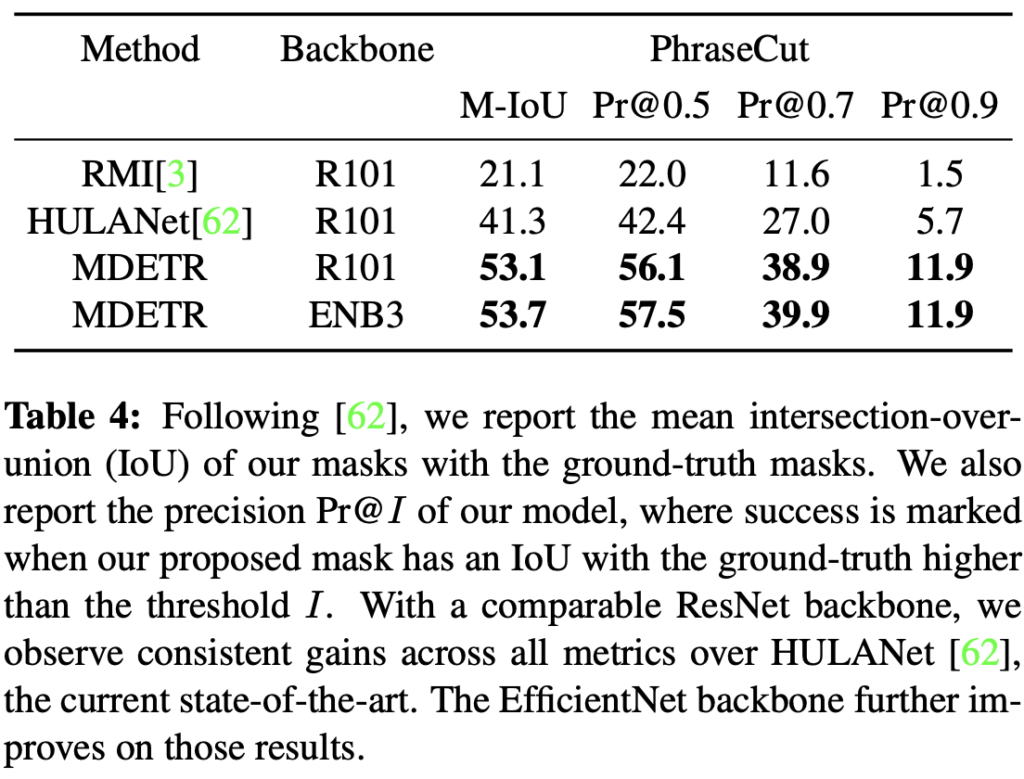
Phrase grounding 위의 MDETR을 설명한 예시와 같이 “문장과 이미지가 주어지고, 해당 문장 내 명사에 해당하는 객체를 찾는 태스크”입니다. 저자는 위에서 언급한 Flickr30k Entities 데이터 셋을 사용하였습니다. 해당 데이터 셋의 예시인 아래 사진이 곧장 Phrase grounding 태스크에 대한 설명이 되겠네요.

해당 태스크는 Recall@k를 사용하며 해당 수치는 문장 내 연관되는 (찾아야하는) 전체 객체 중, Top K의 예측 중 정확히 찾은 객체의 수에 해당합니다. 참고로 제가 따로 모델의 자세한 세팅들에 대해 언급하지 않는 이유는 태스크마다 Pre-train한 데이터와 Backbone이 상이하기 때문입니다.
ANY-BOX-PROTOCOL이라 함은 어떤 BBox든 GT와의 IoU가 0.5 이상이라면 True로 판명하며, MERGED-BOXES-PROTOCOL은 텍스트에 대해 하나의 BBox로 병합되며 이는 Group, a Woman과 같은 구문이 한 영상 내 동시에 참조될 수 있기 때문으로 보입니다. 뭐, 결과적으로 SotA의 성능을 보이네요.
Referring expression comprehension 해당 태스크는 Referring expression으로부터 참조 대상이 되는 하나의 객체의 BBox를 찾아내는 태스크입니다. 위의 Phrase grounding이 객체의 클래스가 문장 내 명확히 나타난다면, 해당 태스크는 추론 과정이 필요합니다. 아래의 데이터 예시를 살펴보죠 해당 태스크에 대한 선행 연구들은 보통 사전학습된 Detection 모델로부터 검출한 경계 박스에 대한 순위를 매기는 정도였습니다. 순위를 매긴다는 의미는 아마 방법에 따라 상이하겠죠. 저자는 이와 달리 텍스트와 이미지를 입력으로 넣기에 직접적으로 예측하도록 설계하여 학습하였습니다. 이렇게 보니 RoBERT-a의 Text Encoder는 얼마나 좋길래.. 싶네요

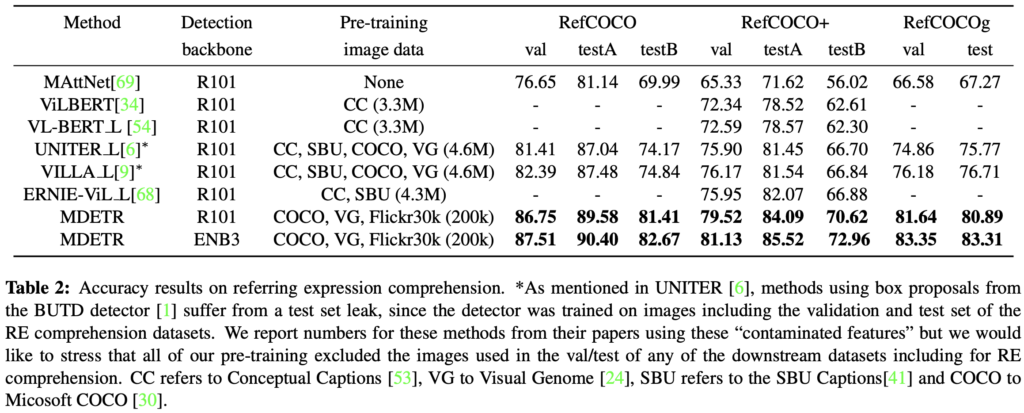
역시나 SoTA의 성능을 보입니다. 신기하게도 많은 데이터 셋을 사용하면서도 모두 SoTA를 달성하니, 이는 해당 MDETR이 정말 좋구나 싶네요.
Referring expression segmentation 바로 위의 BBox를 예측하는 Comprehension과 달리 Segmentation을 수행합니다.

VQA VQA 태스크는 다들 알고 있을테니, 성능만 살펴보죠. 다시 한번 강조하지만 저자가 사소한 학습 스킬들을 소개하기는 하지만, 지금 리뷰에서 그 내용을 하나하나 적는 것보다 논문 한 번 읽으면 될 것이라 생각이 들어 넘어가고 있습니다. 아, 그리고 처음 들어보는 태스크들이 많을텐데, 해당 태스크들을 알아보고자 한다면 음.. ChatGPT나 구글링이 답이긴 하지만 그보다 PapersWithCode에 해당 태스크를 치면, 한 두 줄의 아주 간결한 설명으로 해당 태스크를 요약-설명해주고 대표적인 데이터 셋 예시를 오른쪽에 보여주어 바로 이해하는데 도움이 됩니다.
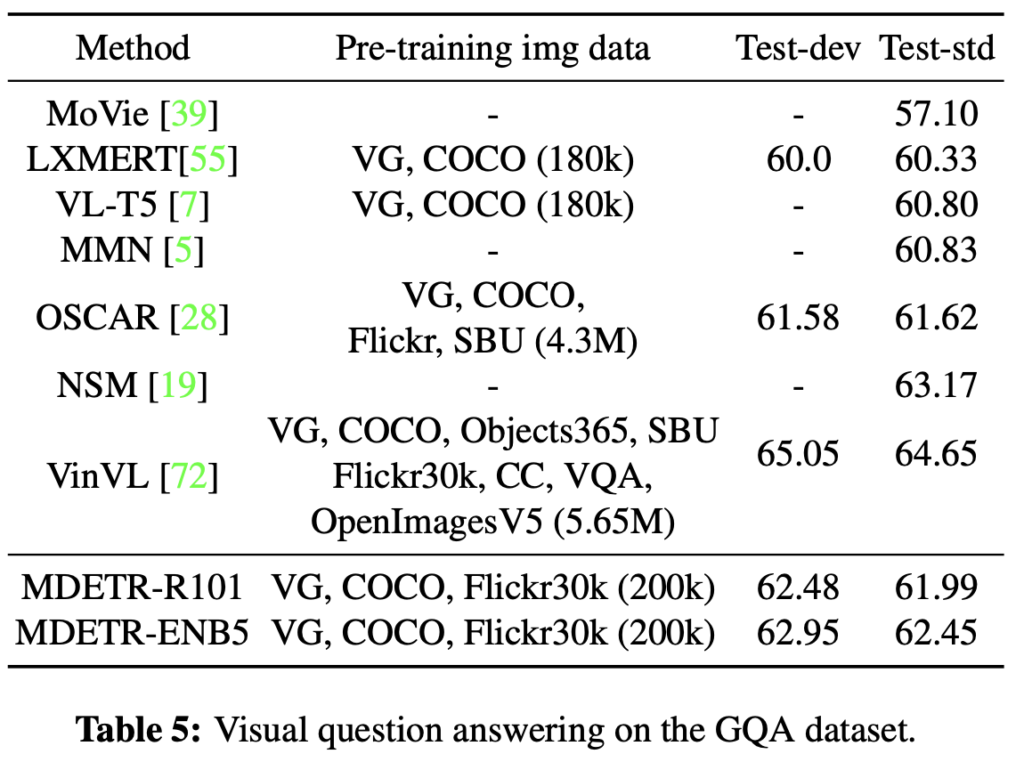
VQS로 설명은 하였지만 Video는 아니고, 아래의 GQA라는 데이터 셋을 활용하였습니다. Component 간의 연결성을 알아내야 하는 태스크로 보입니다.

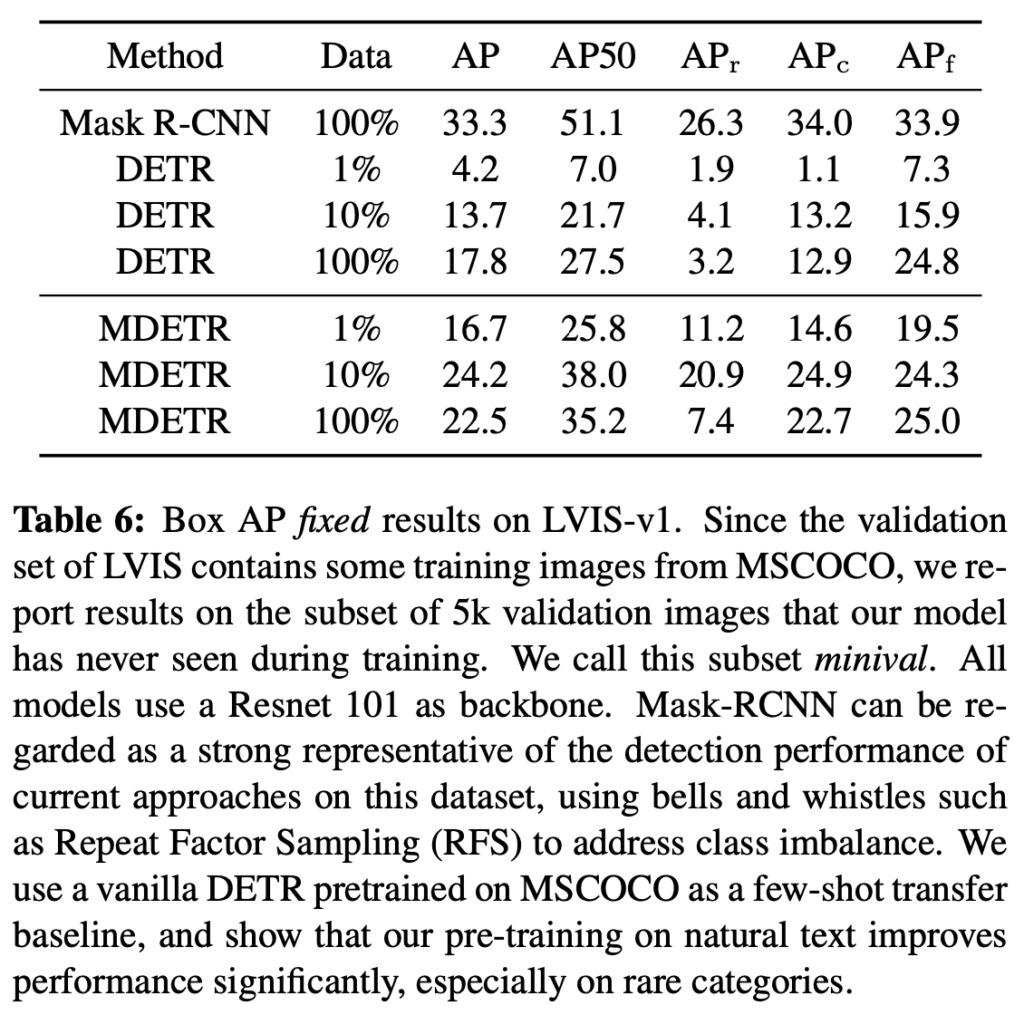
Few-Shot Object Detection Few-Shot OD에서도 사용이 되었네요! LVIS-v1 데이터와 MS-COCO 데이터 중 겹치지 않는 클래스에 대해 선별하여 학습 및 평가를 하였으며 성능만 간략히 살펴보겠습니다. DETR과 비교하는데, 뭐 사실 텍스트를 동시에 사용하기 때문에 조금 더 다양하게 그 의의를 분석하면 좋지 않았을까 싶습니다.
Conclusion
저자는 MDETR을 소개하고, 해당 모델이 이미지와 텍스트를 결합하여 미분 가능성을 보장하며 학습시키므로 이전과 차별성이 있다고 주장합니다. 또한 많은 태스크들에 대해서도 좋은 성능을 보이구요. 그런데 사실 해당 논문을 보다보며 느낀건데, 한 논문을 작성하기 위해 저자가 정말 많은 실험을 진행하네요. 실험만 약 4-5페이지 분량인데, 물론 실험 자체에서 SoTA임을, 그리고 각각에 대한 실험 세팅만을 소개하여 읽을 점은 많지 않았지만.. 제가 저 정도의 실험 세팅을 할 수 있을지 조차 경이롭습니다. 논문 리뷰 마치겠습니다.
안녕하세요! 좋은 리뷰 감사합니다.
실험 상 Phrase Grounding과 Referring expression comprehension 태스크의 차이가 궁금합니다.
또한, DETR에서 Slot은 객체 탐지를 위한 Slot 이외의 역할은 따로 없는 건지요 ?!?!?
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
중간에 설명된 soft-token prediction 부분을 이해하는데 굉장히 오래걸렸네요..
결국 제가 예전에 살피던 Temporal Action Localization에서는 text가 action을 설명하는 한 “단어”만을 활용할 수 있지만, 참고할만한 task들인 Video-Text Retrieval이나 Video Captioning 등은 문장 단위의 구체적인 text를 활용할 수 있기에 명시적인 도움을 얻기 어렵다는 문제점이 있었습니다.
결국 OWOD도 물체를 설명하는 단 하나의 “단어”만을 text 입력으로 받는 것으로 알고 있습니다.(문장 내 token이 1개?)
그럼 원래 읽어보고자 하신 논문인 “Class-agnostic Object Detection with Multi-modal Transformer”에서 MDETR을 가져다 쓰고 있는데, soft-token prediction이나 contrastive learning 부분이 잘 동작할지 궁금하며 이에 대해 어떻게 생각하시는지 궁금합니다. 제가 무언가 잘못 이해한 부분이 있다면 알려주시기 바랍니다.