안녕하세요, 스물네 번째 X-Review입니다. 이번 논문은 2021년도 3DV에게재된 RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching 논문으로 Optical flow 방법론인 RAFT의 stereo matching 버전입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
Stereo matching은 두 입력 영상 사이의 displacement를 픽셀별로 추정하는 task입니다. 입력 영상은 rectification 된 영상이며, 한 pixel에 대한 matching pixel은 수평선상에 존재하게 되겠죠. 초기 stereo matching같은 경우 1) feature matching 2) regularization 이 두 부분에 초점이 맞춰져 있었습니다. 두 영상이 주어진 상황에서 가장 먼저 feature matching 과정을 수행하게 되는데, 이 feature matching이란 matching cost를 계산하는 과정으로, 간단하게 말하자면 두 영상 간의 유사도를 pixel level로 측정하는 것이라고 생각하면 되겠습니다. 이후 매칭 결과가 노이지한 경우 regularization을 통해 depth map을 개선할 수 있겠죠. 이 regularization같은 경우 smoothness와 planrity에 목적을 두게 됩니다. 부드럽고 평탄한 depth map을 얻는 것이 최종 목적이라는 의미와 동일합니다.
Optical flow와 stereo matching 같은 경우 어떤 시각에서는 유사한 task로 볼 수 있습니다. Optical flow같은 경우 첫 번째 프레임의 모든 픽셀와 두번째 프레임의 모든 픽셀간의 displacement를 예측하게 됩니다. stereo 같은 경우 마찬가지로 두 영상 간의 displacement를 pixel 별로 추정하는데, rectification된 영상이 들어오기 때문에 corresponding point가 수평선에 놓여있다는 점과 x축 displacement가 항상 양수 값을 갖는 다는 추가적인 제약 사항을 제외하면 Optical flow와 같은 셈이죠.
하지만, 이런 stereo와 flow task가 유사함에도 불구하고, 네트워크 구조 자체는 매우 다릅니다. 구체적으로 Stereo의 경우 3D convolution을 사용한 연구가 많았습니다. 앞에서 stereo matching task는 가장 먼저 두 영상간의 matching cost를 계산한다고 했었는데, 이후에 이 계산된 matching cost를 쌓아 cost volume을 형성하게 됩니다. 이 3D 혹은 4D의 cost volume을 filtering하기 위해 3D convolution이 많이 사용되어 왔던 것이지요. 근데 이 3D convolution은 계산량이 많이 들뿐더러 resolution의 제약도 받습니다. 특히 Middlebury 데이터셋에서 제공하는 메가 픽셀 영상 같이 고해상도 영상을 처리하기 위해선느 다른 특수한 접근이 필요하게 됩니다.
반면에, optical flow같은 경우 iterative refinment 방식, 즉 반복적으로 flow map을 개선해나가는 식으로 접근한다고 합니다. Optical Flow 방법론인 RAFT 같은 경우 단순한 구조를 가지는데, 반복적으로 refinement해 나가는 과정에서 고해상도 영상에서도 좋은 성능을 냅니다. 간단히 RAFT의 동작 방식을 살펴보자면, RAFT는 가장 먼저 입력 영상에 대해 feature를 추출한 다음 추출한 feature의 모든 pixel pair마다의 상관관게를 계산하여 4D cost volume을 구축합니다. 이후 GRU 기반의 업데이트 operator를 사용해 반복적으로 flow를 업데이트 해 나가는 식으로 동작합니다.
저자는 이 RAFT의 아이디어를 차용하여 RAFT-Stereo를 제안합니다. 전체적인 모델 구조는 RAFT의 방식을 따르되, 모든 pixel쌍에 대해 correlation을 계산하여 생성한 4D correlation volume을 3D volume으로 대체하였습니다. 왜냠, stereo matching의 경우에는 rectification과정을 거쳤기 때문에 같은 height를 갖는 pixel간의 visual similarity만 계산하면 되기 때문입니다. 추가적으로 저자는 multi-level의 GRU unit을 제안하는데, 이는 다양한 해상도를 갖는 feature들이 GRU를 거치면 multiple 해상도의 hidden state가 나오게 될 것이고 이 hidden state들 간의 cross-연결을 통해 고해상도의 disparity를 생성해내기 위함입니다. 이와 관련하여 보다 자세한 설명은 아래 method에서 하도록 하겠습니다.
RAFT Stereo와 이전 stereo 방법론과의 차이점을 짚어보자면, 기존 3D convolution을 사용해오던 이전 연구들과는 다르게 오직 2D conv만 사용하였으며 한번의 행렬곱을 통해 lightweight한 cost volume을 생성하게 됩니다. (근데,, 본 논문이 2D conv만을 사용해 stereo matching을 수행한 최초의 논문은 아닌걸로 압니다..) 이렇게 3D conv의 많은 계산량과 메모리 cost를 줄이게 됨으로써 RAFT Stereo는 메가 픽셀 영상을 resize나 patch단위로 처리할 필요 없이 곧바로 입력으로 넣어 disparity map을 추출할 수 있습니다. 또 RAFT와 같이 반복적으로 disparity를 개선하는 네트워크 구조를 사용하고 있기에 early stop을 통해 정확도와 효율성을 쉽게 trade할 수 있죠.
본 논문의 주 contrivution을 정리하자면 다음과 같습니다.
- RAFT Stereo는 stereo와 optical flow를 통합한 새로운 스테레오 네트워크이다.
- Generalization 성능이 좋다.
- 좋은 성능.
2. Approach
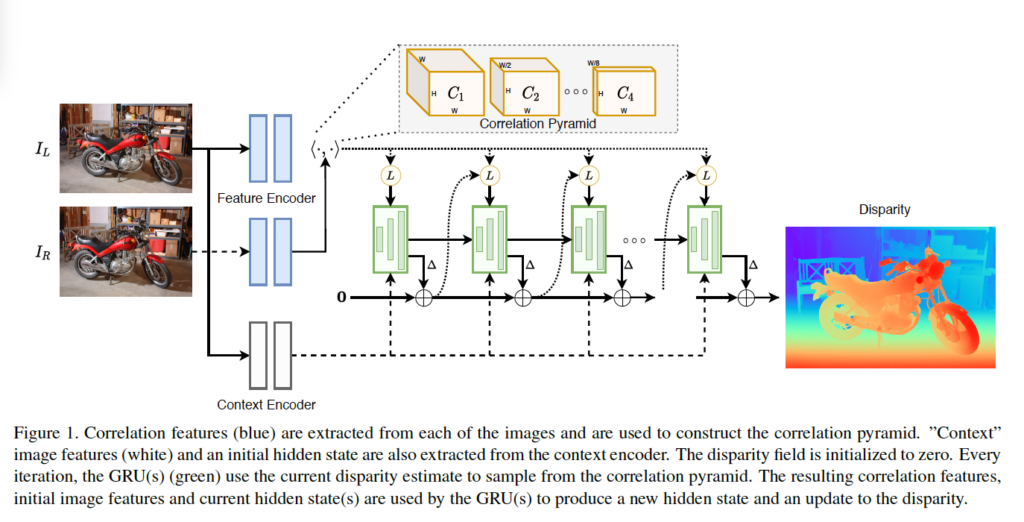
RAFT-Stereo의 전반적인 구조는 Fig 1에서 확인할 수 있습니다. 두 rectified된 영상 (I_L, I_R)가 입력으로 들어오면, 왼쪽 영상 I_L의 모든 픽셀에 대해 x축에 대한 displacement를 추정해 disparity map을 생성하는 식으로 동작합니다. 그림에서 보시다시피 Optical Flow 방법론인 RAFT와 유사하게, feature extractor, correlation pyramid, GRU기반 업데이트 operator로 이루어져 있습니다. 각 모듈에 대해 하나씩 살펴보겠습니다.
2.1. Feature Extraction
feature extractor같은 경우 feature encoder와 context encoder로 구성됩니다. Feature encoder같은 경우 좌우 영상이 입력으로 들어가 각각의 feature map을 추출하고 이 feature map을 correlation volume을 생성하는데 사용됩니다. feature encoder 네트워크는 몇 개의 residual block과 downsampling layer로 구성되어 있으며 하나의 영상에 대해 각 채널 평균과 표준편차로 정규화하는 instance normalization을 사용하였습니다.
Context encoder는 feature encoder와 동일한 구조를 가지고 있는데, instance norm대신 batch norm을 사용하였습니다. 또, 이 context encoder는 오직 왼쪽 영상에 대해서만 적용됩니다. 이 인코더는 GRU기반의 업데이트 operator의 hidden state를 초기화하는데 사용되며, fig1에서 볼 수 있듯이 매 iteration마다 GRU에 입력으로 들어갑니다.
2.2. Correlation Pyramid
Correlation Volume
correlation volume은 앞의 feature encoder를 통해 추출한 feature vector간의 내적을 통해 생성됩니다. RAFT가 픽셀들의 모든 쌍에 대해 visual similarity를 계산함으로써 4D correlation volume을 구성한 것과 유사하게, RAFT-Stereo는 같은 y축 선상에 놓인 pixel 쌍들에 대한 similarity만 계산하여 3D volume을 생성하였습니다. 좌 우 영상 I_L, I_R에서 추출한 각 feature를 f, g ∈ R^{H x W x D}라고 할 때 3D correlation volume은 아래와 같이 동일한 i(y축 index)에 대해서 내적함으로써 계산되는 것입니다.
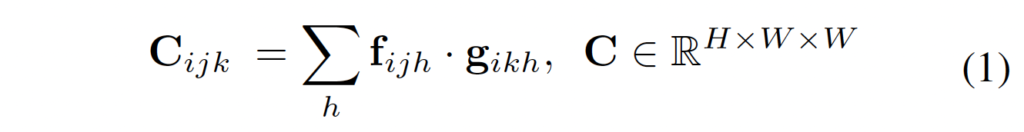
RAFT의 경우 H x W x H x W 크기의 correlation volume이 생성되게 되지만, RAFT-Stereo의 경우 H x W x W 크기의 볼륨이 생성되겠죠 !
Correlation Pyramid
위에서 생성한 Correlation volume을 저자는 4레벨의 피라미드 형식으로 만들어 사용하였습니다. 생성된 Correlation volume은 H x W x W shape을 갖는다고 했었는데 이 마지막 차원인 W 차원에 대해 average pooling을 반복적으로 적용함으로써 피라미드 형식의 multi-level correlation volume을 구성합니다. 구체적으로 k^{th} level의 피라미드는 커널 크기 2, stride 2를 갖는 1D avg pooling을 적용함으로써 H x W x W/2^k 크기의 correlation volume이 생성됩니다. 오직 마지막 차원에 대해 pooling하는 것만으로 수용 영역을 키울 수 있지만, 원본 영상의 고해상도 정보는 유지할 수 있어서 fine한 structure를 recover할 수 있게 된다고 하네요.
Correlation Lookup
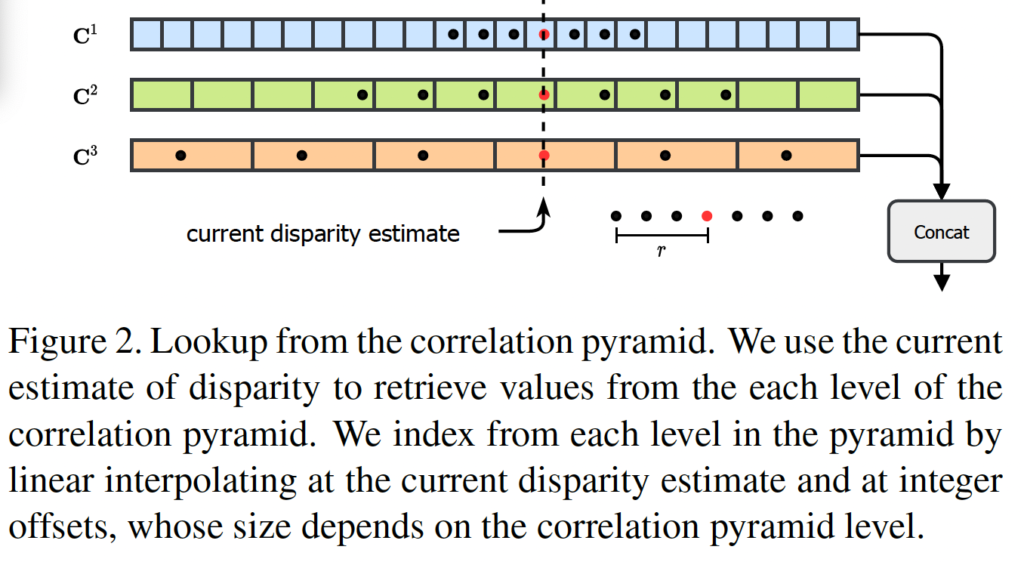
이 correlation lookup같은 경우도 RAFT에서 제안한 lookup과 유사한 것으로, correlation 피라미드를 인덱싱하는데 사용합니다. 추정된 disparity d는 반복적으로 GRU unit을 통과하며 개선되게 되는데 이 때 각 GRU unit을 통과하며 추정된 disparity가 존재할 때 정수의 offset을 갖는 1D grid를 통해 각 레벨의 correlation 피라미드를 인덱싱할 때 lookup이 사용됩니다. 그림 2가 lookup 과정에 대해 모사한 것입니다.
자세히 말하자면, 3 level의 correlation volume이 우선 존재하는데, 이들 각각의 크기는 원본 영상의 1/8, 1/16, 1/32입니다. 뒤에서 설명할 부분이긴 한데, 이 각각의 multi scale을 갖는 correlation volume이 각각의 multilevel의 GRU를 타고 들어가게 되고, 그럼 각각의 output이 나오게 되겠죠. 이때 1/8 크기를 갖는 (가장 큰) correlation volume을 기준으로 삼고 (그림 2에는 C^1에 해당) 그보다 작은 크기의 volume인 C^2, C^3를 선형 보간하여 C^1과 크기를 맞춰준 다음 같은 disparity d에 대해 추정한 값들을 인덱싱하는 것이라고 보면 됩니다. 이렇게 인덱싱하게 된 disparity map같은 경우 concat되어 다음 GRU unit의 입력으로 들어가게 됩니다. 인덱싱 하는 부분은 H x W x W 차원의 correlation volume에서 마지막 차원 W의 값들을 인덱싱 하는 것입니다. 애초에 multi-level volume이 마지막 차원에 W 대해 multi-scale을 갖는 volume이었던 것을 생각해보면, 이해가 될 것 같습니다 . .
정리하자면, 그림2에서 빨간 색 점이 disparity d라고 할 때 C^1의 grid에서는 좌 우 점들이 d-1, d+1에 해당할 것입니다. 하지만, C^2, C^3같은 경우 pooling과정을 거쳤기 때문에, 앞 뒤 채널이 d-1, d+1을 의미하는 것이 아닙니다. 그래서 이 마지막 차원 W에 대한 값들을 인덱싱하기 위해 linear interpolation를 수행하는 것입니다. . . 다른 스케일의 correlation volume을 현재 disparity 추정 결과와 일치하도록 조정하는 과정이라 생각됩니다. .
2.3. Multi-Level Update Operator
이제 GRU 기반의 update operator에 대해 살펴보겠습니다. 한 operator를 통과하면 예측된 disparity map이 나오게 됩니다. 맨 처음 초기값 d_0은 0으로 초기화되어 들어가게 되며, N번 iteration 돈다고 할 때 {d_1, …, d_N}가 나오게 되겠죠.
매 iteration마다, 현재 추정된 disparity를 가지고 correlation volume을 인덱싱하게 되며, correlation feature를 가공하게 됩니다. 이 correlation feature는 2개의 conv layer를 통과하게 된다고 하네요. 비슷하게, 현재 추정된 disparity같은 경우도 2개의 conv layer를 통과합니다. 그 다음 correlation, disparity, context feature가 concat되어 다음 GRU의 입력으로 들어가게 됩니다. GRU는 hidden state를 업데이트 해 나가고, 이 새로운 hidden state가 disparity update를 예측하는데 사용됩니다.
Multiple Hidden States
기존에 RAFT는 고정된 크기의 flow map을 업데이트 해 나가는 식으로 동작하였습니다. 이런 접근 방식의 문제점은 GRU 수가 증가해 나감에도 receptive field가 굉장히 느리게 커진다는 점인데요. 이는 large textureless 영역이나, local 정보가 부족한 영역에 대해 문제가 될 수 있습니다. 저자는 이런 문제를 해결하기 위해 1/8, 1/16, 1/32 해상도를 갖는 feature map에 대해 연산하는 멀티 크기의 update operator를 제안합니다.
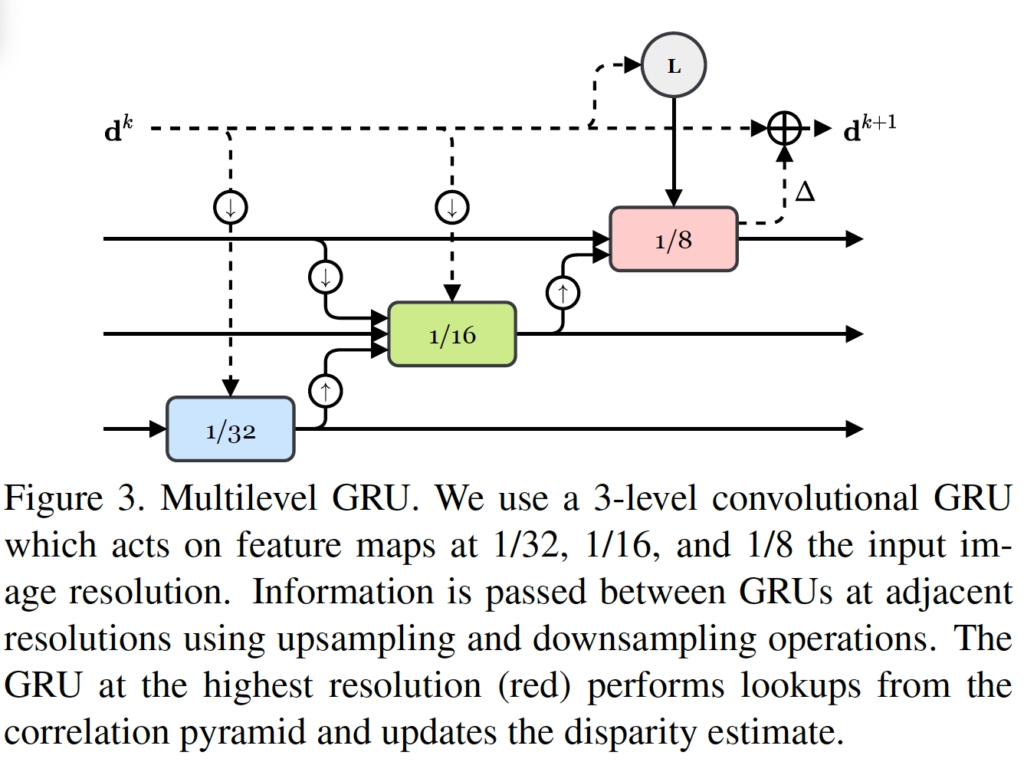
그림 3에서 멀티레벨 GRU를 확인할 수 있습니다. GRU의 hidden state가 다른 레벨의 GRU의 입력으로 들어가는 것을 볼 수 있습니다. (인접한 크기의 feature map의 GRU unit 입력으로 들어감) 이때 correlation lookup같은 경우 가장 큰 해상도를 갖는 feature에 대해 GRU 연산을 마치고 나온 disparity에 대해 수행됩니다. 그림에서는 빨간색 블럭이 가장 큰 feature map에 대한 GRU인데, 이때 윗 부분에 L로 lookup 과정이 수행되는 것을 확인할 수 있습니다.
Upsampling
추론된 disparity map은 입력 해상도의 1/8크기를 갖고 있으므로 최종적으로 입력 해상도와 동일한 크기의 disparity map을 추출하기 위해 upsampling을 해야합니다. 이 때 RAFT와 동일하게 convex upsampling을 사용했습니다.
2.4. Supervision
학습은 모델이 예측한 disparity {d_1, …, d_N}와 gt disparity간의 l_1 distance를 가지고 지도학습합니다.
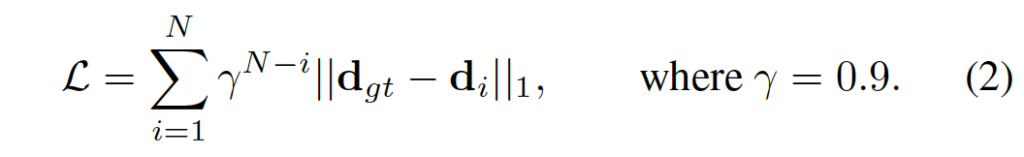
뒤 iteration에서 예측한 disparity일수록 높은 가중치를 부여했습니다.
3. Experiments
실험은 ETH3D, Middlebury, KITTI-2015 데이터셋에 대해 수행되었습니다. 이전 연구들과 동일하게 합성 데이터셋인 Sceneflow 데이터셋으로 사전학습 했다고 하며, zero-shot generalization 성능도 뛰어나다고 합니다.
3.1. Zero-Shot Generalization
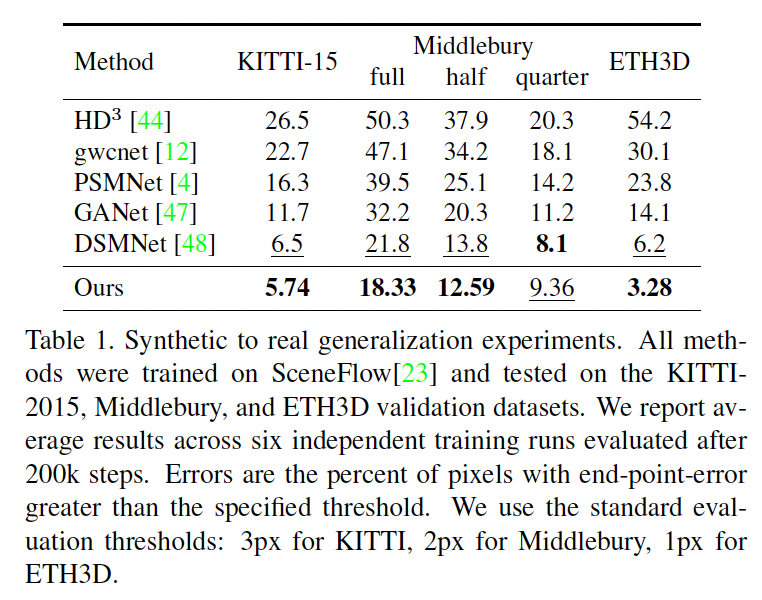
본 논문의 contribution 중 하나가 generalization 성능이 뛰어나다는 것이었습니다. 위 table 1은 합성 데이터셋인 Sceneflow 데이터셋에서 학습한 후 바로 real dataset인 KITTI15, ETH3D, Middlebury validation set에 대해 평가한 성능입니다. 이 세 데이터셋에 대해 SOTA의 성능을 보였지만, 비교하는 방법론 자체가 다 초창기 방법론이긴 합니다. 아래에서 보여드릴 표와는 달리 최신 방법론의 제로샷 성능은 왜 넣지 않은 것인지 의문이네요 ?
3.2. KITTI
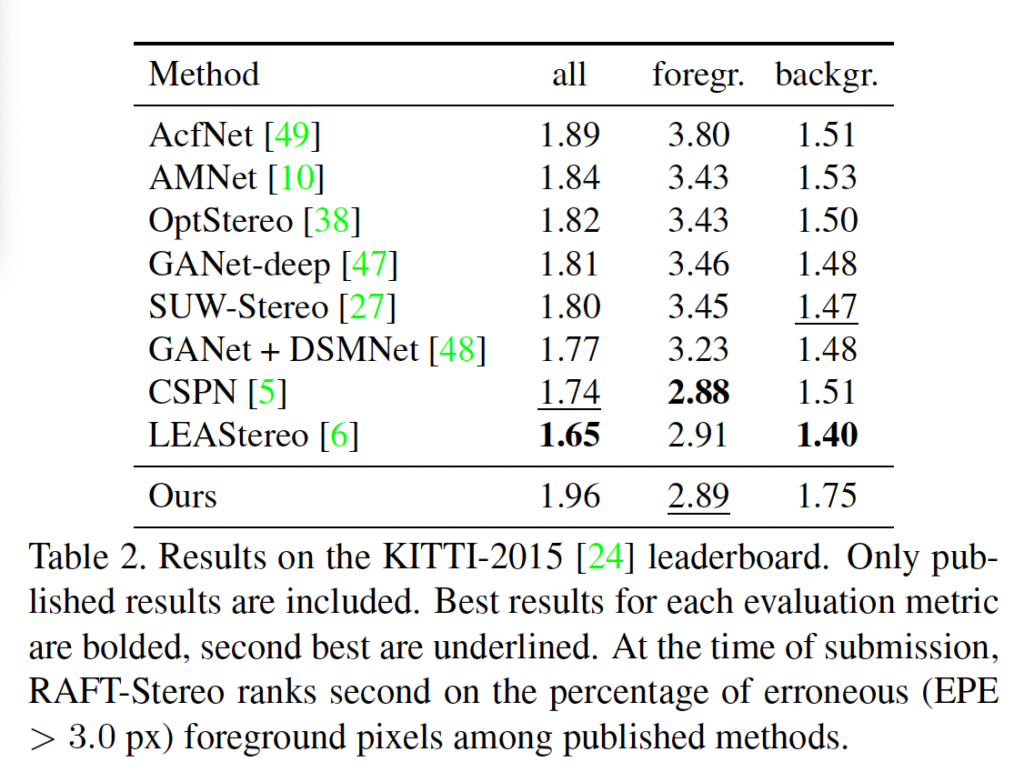
표 2는 KITTI-2015 데이터셋에 대한 결과입니다. 숫자가 낮을 수록 좋은 성능인 것을 생각해보면, all(foreground + background)에 대한 성능은 사실상 벤치마크표에 있는 모든 방법론 중 가장 안좋은 성능을 보입니다. . 이는 전경과 배경 중 배경의 성능이 특히 좋지 않은 것으로 보이며 전경에 대한 성능은 2번째로 좋긴 합니다. 배경 영역에 대한 성능이 타 방법론에 비해 많이 차이나는 이유에 대해서는 언급이 되어 있지 않습니다 . .
3.3. Middlebury
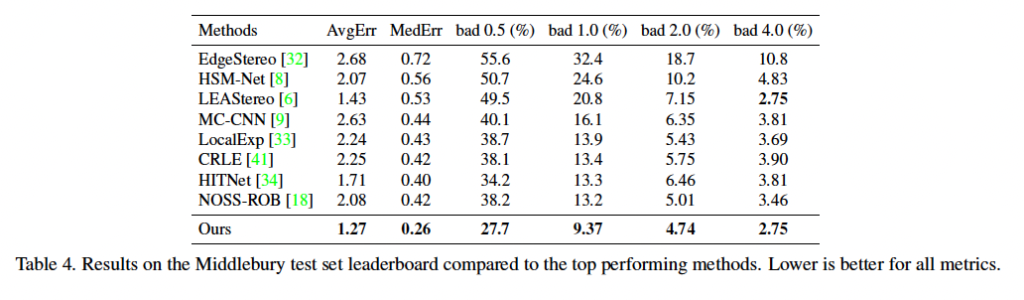
다음으로 biddlebury 데이터셋에 대한 성능입니다. Middlebury 데이터셋 같은 경우 (1900×3000) 크기의 고해상도 영상을 output으로 요구합니다. RAFT-Stereo 같은 경우 고해상도 영상을 처리하기 위해 pyramid correlation을 사용하였고, 그로 인해 메가픽셀 크기의 고해상도 영상을 곧바로 출력해낼 수 있다고 합니다. 반면, 이 middlebury 리더보드에 있는 best 34개의 방법 중 33개가 그의 절반 해상도에서 upsampling을 했다고 하며 이 RAFT-Stereo의 메모리 효율성을 강조하고 있습니다.
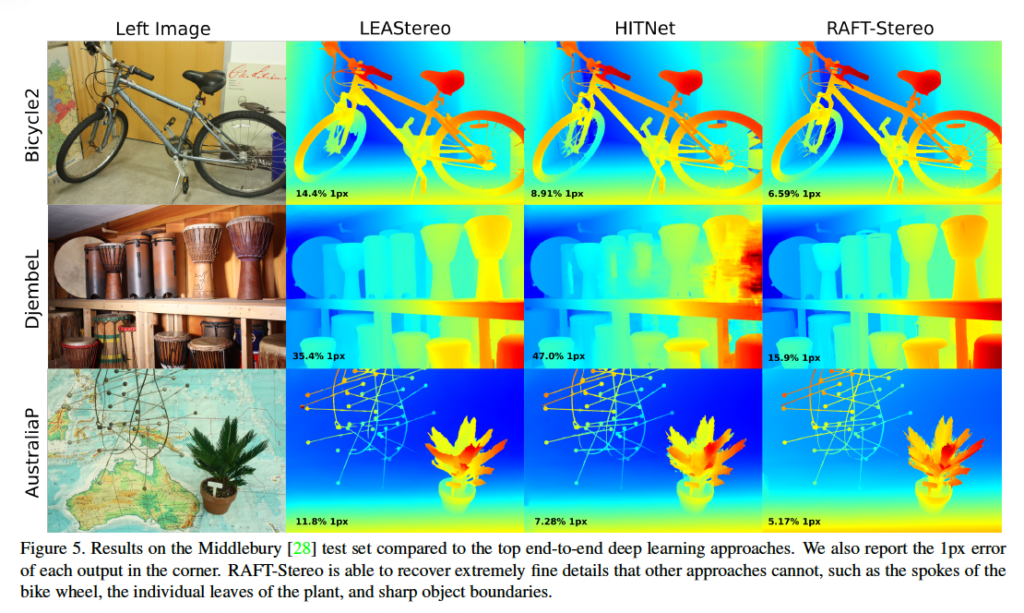
Middlebury 데이터셋에서의 정성적 결과 보여드리며, 리뷰 마치도록 하겠습니다.
좋은 논문 리뷰 감사합니다.
몇 가지 질문 남기고 갈게요!
1. 2.1. Feature Extraction에서 context encoder로 초기화를 진행하는 이유는 뭘까요?
2. Correlation Pyramid에서 3D Correlation Volume을 커널 크기 2, stride 2를 갖는 1D avg pooling로 어떻게 연산하는 건가요?
3. 초기 GRU에 입력되는 값은 1/32 스케일을 가진 feature map을 0으로 채워 들어가는 건가요?
4. Correlation Lookup에서 GRU에 업데이트 되는 정보는 각 피라미드의 C_ijk 하나의 값만 들어가는 걸까요? 그럼 GRU는 HxWxW 만큼 반복하는 건데… 제가 뭔가 크게 잘못 이해한 것 같은데…
안녕하세요. 질문이 하나 있는데,
optical flow는 두 영상 간에 대응점을 찾는 것이고 stereo matching도 두 영상 간에 대응점을 찾는다는 점에서 두 task는 사실상 동일하며 optical flow는 다양한 방향까지 고려한다는 점을 두고 봤을 때 stereo matching은 optical flow 분야 내 포함되는 부분집합 task로 볼 수 있습니다.
이러한 관점에서 stereo matching task는 matching cost와 cost volume 등의 개념이 나오며 3D convolution을 활용하는 반면에 optical flow에서는 이러한 cost volume이 아닌 iterative refinement를 채택한 이유가 무엇이라고 생각하시나요?
즉, 두 테스크가 풀고자하는 목표는 상당히 비슷한데(두 영상 간에 대응점을 찾겠다는 것) 왜 한쪽은 cost volume을 통한 3D convolution을, 다른 한쪽은 iterative refinement를 채택하는지, optical flow에서는 3D conv를 사용안하는 이유가 무엇인지 등에 대해서 설명해주시면 좋을 것 같습니다.