안녕하세요. 제가 이번에 리뷰할 논문도 6D Pose Estimation 논문으로, instance-level의 6D를 category-Level로 확장하는 방법론입니다. 제가 주로 리뷰하고 실험하고 있는 방법론들은 주로 instance-level의 방식으로 정확도 측면에 집중하는 연구 방향입니다. 그러나 instance-level은 대상 객체에 대한 3D 모델이 필요하고, 대상 객체에 맞춰 학습한 모델이 필요하므로 실제 활용 측면에서 제한이 많아, 최근 많은 6D 연구들이 category-level로 나아가는 추세입니다. 이런 측면에서, instance-level의 정보를 category-level로 확장할 수 있다면 큰 도움이 될 것 같아 읽고 리뷰하게 되었습니다. 이제 리뷰해보겠습니다!
** instance-level: 대상 객체에 대응되는 3D 모델이 존재하며, 각 대상마다 별도의 학습을 거쳐 객체의 pose를 추정함.
** category-level: 한 카테고리에 대해 여러 외관을 가지는 객체들의 묶어 pose를 추정하기 위한 방식으로, 여러 외관의 객체들 대표할 수 있는 형태를 이용하는 등의 연구가 수행됨.
Abstract
해당 논문은 instance-level의 pose 추정 네트워크를 서로 다른 카테고리에 해당하는 어려 객체의 6D pose 를 추정하는 category-level에 적용하기 위해 i2c-net 프레임워크를 제안한, 단일 RGB 이미지 기반의 방법론입니다. 네트워크는 일부 base CAD모델을 이용하여 생성하며, 도메인 의존성을 낮추기 위해 실제 texture를 이용한 사실적인 합성 데이터를 이용하여 학습됩니다. inference에는 instance-level의 네트워크에 3D mesh 재구성 모듈을 함께 사용하여 category-level의 성능을 달성하였다고 합니다. 이때 Depth 정보는 후처리에 사용되며 YCB-V 데이터와 NOCS-REAL 데이터 셋을 이용하여 정확도를 측정하였습니다.
Introduction
6D Pose Estimation은 제조, 물류 등의 다양한 범위에 적용되기 위해 중요한 연구이지만, 객체의 다양한 형태와 질감, 조명 조건 및 cluttered 장면과 occlusion 등 장면의 다양성 등에 의해 어려운 task입니다. 최근 딥러닝의 발전으로 단일 RGB 기반의 6D Pose Estimation 연구가 발전하였으나, 단일 RGB 이미지에서 3D 정보를 추출하는 것은 물체의 구조를 제대로 반영하기 어려우며, 학습을 위해 라벨링 된 데이터를 수집하기 시간과 비용이 많이 든다는 점에서 어려움이 있습니다. 또한, 사람과 같이 여러 view에서 객체의 자세를 추출하거나 point cloud 정보를 활용하는 방식도 연구되고 있으나, 연산량이 크게 증가한다는 어려움이 있습니다. 이러한 이유로 수동으로 라벨링을 하는 대신, 실제 시나리오에 적용할 수 있도록 합성 데이터를 생성하여 학습을 수행하는 연구가 많이 수행되었습니다.
크기 정보를고려하여 6D Pose를 추정하기 위해서는 3D 정보가 필요합니다. 6D Pose Estimation에서 많이 사용하는 방식은 대응되는 3D CAD 모델을 이용하며, 이러한 경우 3D CAD 모델에 존재하는 객체에 제한적으로 6D Pose Estimation 적용이 가능하다는 한계가 있습니다. 또 다른 방식은 depth 정보를 활용하는 것으로, 시뮬레이션 데이터를 생성함에 있어 단일 RGB 이미지를 활용하는 것 보다 더 복잡하다는 문제가 있습니다. (배경에 대한 depth를 고려하기 어려우므로)
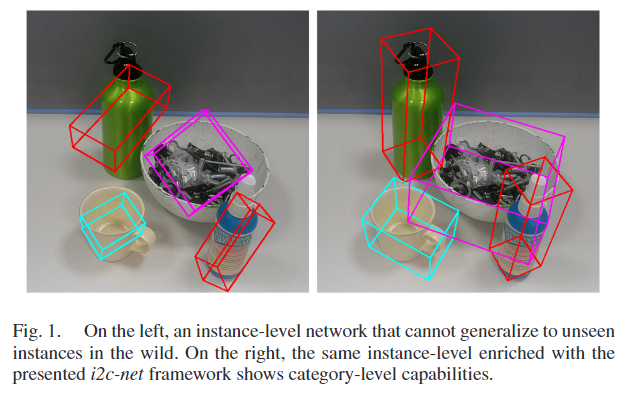
해당 논문은 instance-level의 pose estimation 네트워크에서 시작하여 학습을 위해 합성 데이터를 활용하여 특정 category에 속하는 여러 객체들의 6D Pose를 추정하기 위한 istance-to-category net 또는 i2c-net을 제안합니다. 핵심 아이디어는 RGB 이미지와 활용 가능한 3D CAD 모델을 이용하여 최대한 많은 3D 정보를 추출하고, depth 정보를 후처리 과정에 활용하는 것입니다. 알려진 base CAD 모델에 변형을 주고 실제 texture를 추가한 새로운 3D 모델을 생성합니다. instance-level의 실제와같은 합성 데이터를 생성하여 학습을 수행하며, inference에는 category-level의 성능을 달성하기 위해 3D mesh reconstruction 네트워크와 함께 결합하여 객체의 pose를 추정합니다. 제안한 네트워크 평가를 위해 YCB-V(instance-level)와 NOCS-REAL 275(category-level) 데이터를 이용하여 평가를 수행하였으며, 아래의 [Fig. 1]을 통해 결과를 먼저 확인할 수 있습니다.(instance-level의 방식인 GDR-Net[논문/양희진 연구원님 리뷰:)]과의 비교 결과)
Methodology
제안된 instance-to-category level의 pose estimation 프레임워크는 아래의 [Fig. 2]와 같습니다. 6D Pose Estimation에서 높은 정확도를 달성하였지만, 일반화 성능이 낮은 instance-level의 모델을 category-level의 작업에서도 효과적일 수 있음을 보이는 것을 목표로 합니다. 저자들은 기존의 RGB instance-level의 방법론들이 classification 및 detection 태스크에서도 활용 가능한 범용적인 백본을 이용한다는 점에 집중하여, 동일한 카테고리의 다른 객체에 대한 정보를 추가할 경우 가장 두드러지는 특징을 추출할 수 있을 것이라 보고 연구를 수행하였다고 합니다.
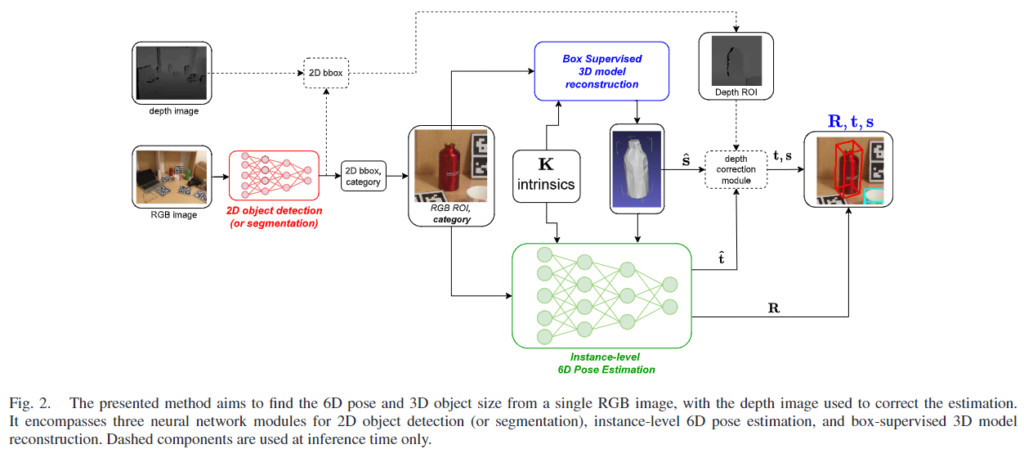
해당 파이프라인은 먼저 RGB 이미지를 입력하여 대상에 대한 2D bounding box를 추출하는 2D detection을 수행합니다. (많은 6D Pose Estimation 방법론도 detection을 기본적으로 활용합니다.) 그 다음, 3D reconstruction 모듈을 통해 crop된 객체 영역의 2D RGB 이미지를 활용하여 좌표축을 따라 절대적인 크기로 객체의 3D mesh를 생성합니다. 마지막으로 instance-level의 6D pose 추정 네트워크를 통해 3D mesh를 얼마나 이동\hat{\mathbf{t}} 및 회전\mathbf{R}시켜야 하는지 변환 정보를 추정합니다. Depth-correction 모듈은 후처리에 사용하여 최종적인 translation \mathbf{t}와 스케일 \mathbf{s}를 구합니다.
이때, 2D detection을 위해 해당 논문에서는 YOLOv5를 이용하였으며, 다른 detection method로 대체할 수 있고, clutter한 장면과 occlusion에 대응하기 위해 segmentation을 도입할 경우 객체 영역에 집중할 수 있다고 합니다. 이에 대한 실험적 결과는 실험파트에서 확인하실 수 있습니다.(TABLE 2)
A. Photo-Realistic Dataset
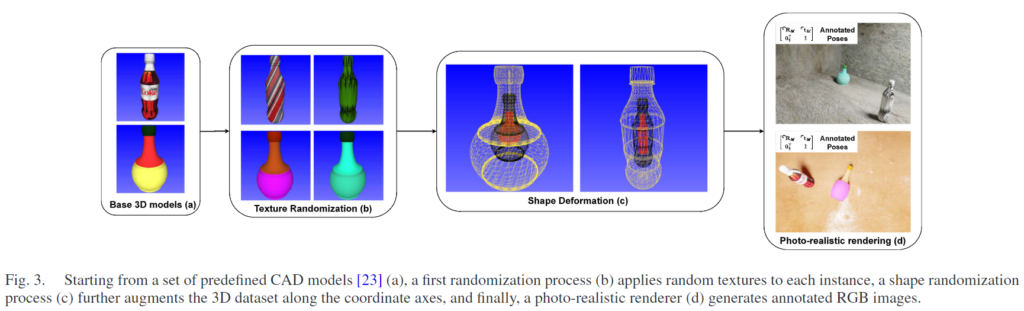
실제와 유사한 합성 데이터를 만들어 학습을 수행하며, 이때 BlenderProc라는 그래픽 엔진을 이용합니다. 데이터셋에는 각 범주에 대한 9900장의 이미지가 포함되며, 다양한 시점과 조명, 배경으로 이루어진 300개의 장면에 대해 각 장면당 33개의 이미지로 구성하였다고 합니다. 동일 카테고리 내에서 CAD 모델을 사용할 수 없는 객체로의 일반화가 가능하도록 하는 것을 목표로 하며, 15개의 base model을 이용하고, 노트북에 대해 300개, 다른 NOCS 카테고리(bottle, bowl, can, mug)에 대해 100개의 객체로 이루어집니다.
기존 연구의 방식을 따라서 base model의 mesh를 좌표축을 따라 무작위로 확대/축소하여 데이터 수를 증가합니다. 이때, deformation은 주어진 범위 내에서 bounding box의 각 측면에 적용되며, 범위가 넓을 경우 일반화 성능을 확보가 가능하나, 과하게 넓은 범위가 주어질 경우, 해당 category에 대한 특성을 잃을 수 있으므로 적절한 범위를 설정해야 합니다.
저자들은 일반화 성능을 높이고 다양한 표면 패턴에 정용 가능하도록 하기 위해 deformed 3D 모델에 랜덤하게 RGB 변형을 주었다고 합니다. 이를 통해 동일 category 내의 다양한 외관 변화에도 대응 가능하도록 모델을 학습할 수 있다고 합니다. 위의 그림 [Fig. 3]의 (b)를 통해 3D CAD 모델에 임의의 색상과 texture로 변형하여 데이터를 증강하는 과정을 확인할 수 있으며, (c)를 통해 객체의 크기를 랜덤하게 수정하는 과정을 확인할 수 있습니다. 마지막으로 Blenderproc를 이용하여 객체의 배경과 조명을 실제와 유사하게 시뮬레이션 하여 각 view에 대한 6D Pose 정보를 포함한 합성 데이터를 생성합니다.
B. RGB 6D Pose Estimation
instance-level의 네트워크를 활용하여 RGB 입력에서 객체의 6D Pose(\mathbf{R, \hat{t}})를 추출합니다. 기존 네트워크 중 정확성과 속도, flexibility를 고려하여 GDR-Net을 베이스라인으로 선정하였다고 합니다. GDR-Net은 ResNet 백본 encoder와 커스텀된 decoder 구조로 이루어지며,객체의 feature space에 기하학적 특징을 인코딩하는 방법론으로, 저자들은 이런 특징이 category-level의 시나리오로 확장하기에 적절하다고 판단하였다고 합니다.(범용적인 백본과 기하학적 구조 인코딩 등) 따라서, 특정 category의 공통적인 3D 기하학을 학습하도록 네트워크를 학습하여 category-level로 확장합니다. 그러나, 단일 RGB 이미지에서 상대적 또는 절대적 크기를 복구하는 것은 여전히 instance-level의 능력이므로 category-level로 확장을 위해서 3D reconstruction 모듈이 필요합니다.
C. 3D Model Reconstruction
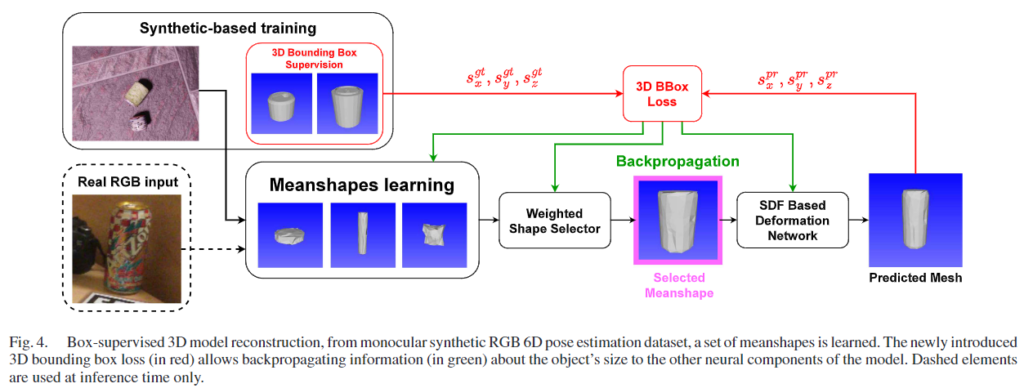
해당 모델은 앞서 생성한 합성 데이터로 학습하여 단일 RGB 이미지에서 객체의 보이지 않는 부분의 3D mesh를 추론하는 방법을 학습합니다. box-supervised 3D model reconstructor는 Multi-Category Mesho Reconstruction(MCMR)**이라는 기존 연구를 활용하며, [Fig. 4]를 통해 과정을 확인하실 수 있습니다. 3D 모델의 적절한 모양과 scale을 구하기 위해 meanshapes라는 3D 모델에 학습 과정에 얻은 사전 정보를 활용합니다. meanshape은 객체의 구조에 한 두드러지는 특징이 응축된 latent feature로 간주할 수 있으며, 여러 meanshapes을 학습하고 classifier가 이미지의 특징과 비교하여 적절한 형태를 선택하여 사용할 수 있도록 loss function을 설계하였습니다.
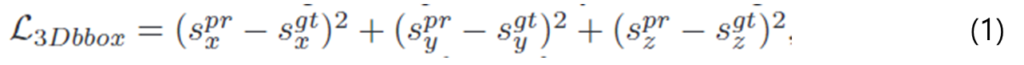
- s_k, k∈\{x,y,z \}: k축에 대한 3D bounding box 한 변의 길이
- ^{pr}, ^{gt}: 각각 예측값과 정답값
이러한 방식으로 정보를 다른 네트워크에 모두 back propagation하여 객체의 적절한 크기와 모양을 regression으로 구하여 좋은 성능을 보였다고 합니다. 이때, GT와 예측 값을 비교하려면 3D 모델의 위치를 정렬하는 것이 편하므로, bounding box의 중심을 [0,0,0]이 되도록 이동시켰으며, 3D bounding box를 비교하므로써, 근사치의 scale값을 예측할 수 있었다고 합니다.
**A. Simoni, S. Pini, R. Vezzani, and R. Cucchiara, “Multi-category mesh reconstruction from image collections,” in Proc. IEEE Int. Conf. 3D Vis., 2021
D. Depth Correction Module
해당 모듈은 후처리 과정으로, inference 과정에 3D reconstruction 모델을 통해 구한 pose 정보의 절대적 scale로 인한 오류를 조정하기 위해 depth 정보를 활용하여 3D translation에 대한 추가적인 조정을 수행합니다. 이를 위해 3D reconstruction 네트워크에서 생성한 3D mesh를 앞서 예측한 rotation 및 translation 이용하여 렌더링하여 얻은 depth map을 이용합니다. 다음은 stereo depth를 활용하여 correction을 수행하는 과정입니다.
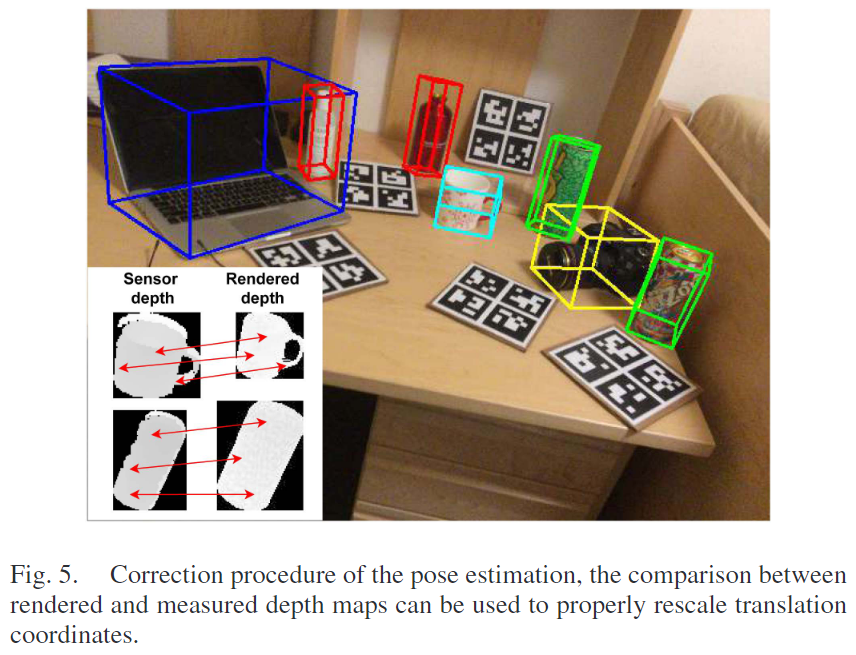
- 렌더링된 depth map과 측정된 depth map 사이의 width \sigma_u와 height \sigma_v 비율을 구함
- 렌더링된 depth map z_r 에서 2D point 8개 \{ (u^r_1,v^r_1), ..., (u^r_p, v^r_p) \}를 샘플링
- 아래의 식 (2)를 이용하여 측정한 depth map z_m에서 대응되는 점 찾기
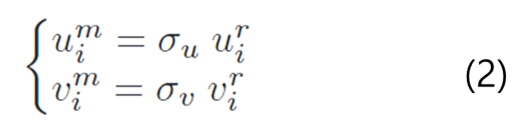
- 다음 식 (3)을 이용하여 최종 depth 비율 구하기
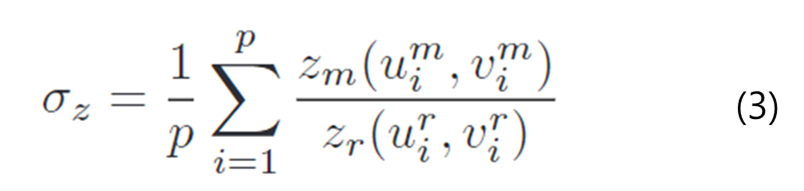
이렇게 구한 \sigma_z를 이용하여 translation과 scale의 크기를 조정합니다. (\mathbf{t} = \sigma_z\mathbf{\hat{t}}, \mathbf{s}=\sigma_z\hat{\mathbf{s}})
Experimental Results
해당 논문의 성능을 평가하기 위해 NOCS-REAL 275 데이터 셋을 밴치마크로 이용하였습니다. 학습에는 NOCS 데이터와 관련 없는 실제같은 합성 데이터를 이용하였으며, NOCS 데이터 셋 외의 category에도 작동함을 확인하기 위해 YCB-V 데이터도 활용하여 평가를 진행하였다고 합니다. 실험에 사용한 평가지표는 3D IoU로, GT와 예측 값에 대한 bounding box간의 IoU를 측정하여 평균 정밀도를 측정합니다.(category-level에서 활용하는 방식) 또한, cm와 °는 rotation과 translation의 오차 threshold에 대한 평균 정밀도를 측정합니다.
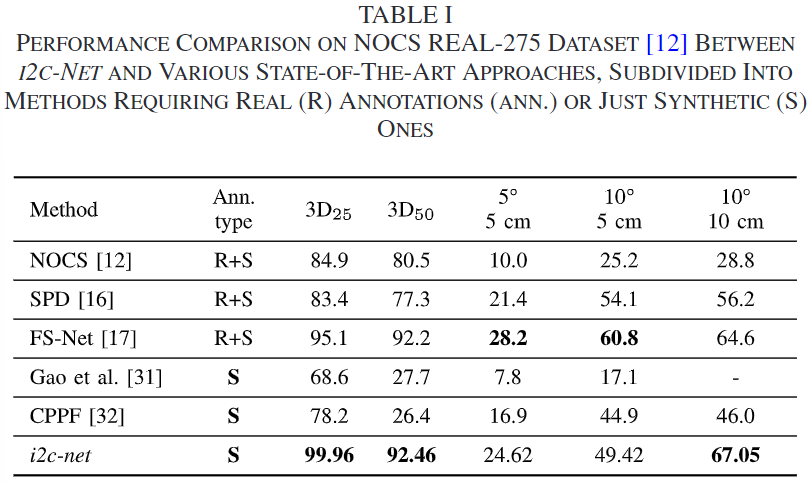
위의 TABLE 1은 i2c-net과 SOTA category-level 6D Pose Estimation 방법론의 성능을 비교한 것으로, i2c-net이 3D IoU에 대해 가장 좋은 정확도를 기록하였으며, 10 ° , 10 cm에서도 가장 좋은 성능을 보였습니다. 특히, 다른 방법론들은 데부분 실제 데이터에 의존하는 데 반해, i2c-net은 합성 데이터만을 활용하여 다른 category로 확장하였다는 점에서 주목할만합니다.
i2c-net에 대한 분석
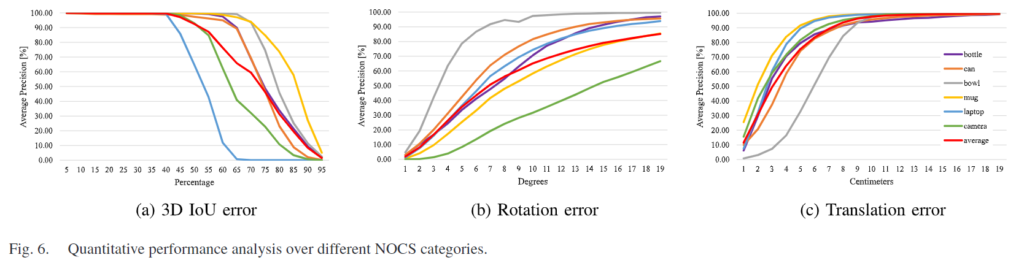

위의 [Fig. 6]은 정량적 성능 분석을 위한 그래프로, 3D IoU와 rotation 및 translation 오류에 대한 평균 정밀도를 나타냅니다. 100%에 가까울수로 좋은 결과이며, [Fig. 7]에서 정성적 결과를 확인할 수 있습니다. translation error는 3D reconstruction 과정에서 구멍으로 인해 RGB 이미지만으로 depth를 감지하기 어려운 bowl을 제외한 모든 클래스에서 대체로 좋은 성능을 보입니다. camere의 경우, 다른 객체에 비해 외관의 다양성이 크기 때문에 rotation error에서 낮은 성능을 보이는 경향이 있으며, laptop은 cm와 °에 대한 성능에 비해 3D IoU의 성능이 낮은 편이며 이는 laptop이 관절구조로 인해 IoU 영역이 적기 때문이라고 저자들은 분석하였습니다.
Ablation study
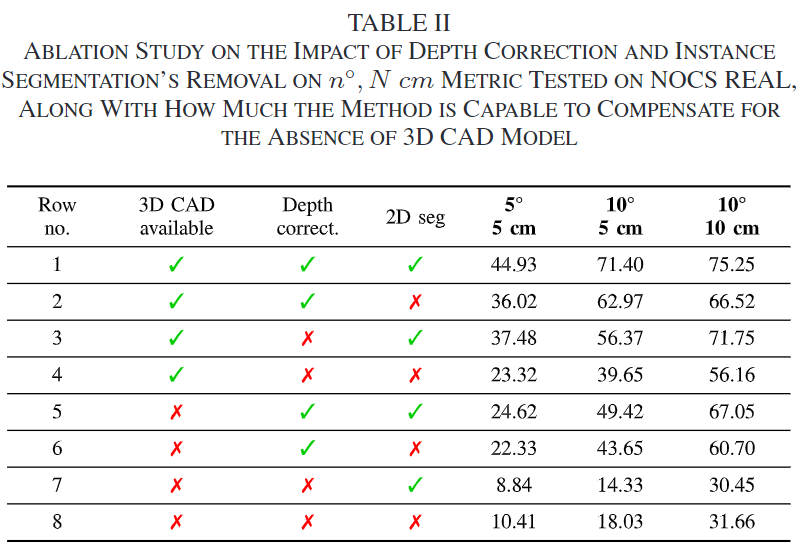
TABLE 2는 cm와 °평가지표를 이용하며 각 모듈의 유효성을 평가한 결과로 instance segmentation을 활용할 경우 성능 변화도 함께 평가하였습니다.
- 1~4행은 실측 3D model을 이용할 수 있는 경우에 대한 실험 결과이며, 5~8행의 실험 결과를 통해 inference 과정에 3D 모델을 reconstruction 함으로써 성능을 얼마나 보완할 수 있는 지를 나타내었습니다.
- 6행과 8행, 5행과 7행을 비교함으로써, depth correction 모듈을 사용하지 않을 경우 11.92%, 36.6%의 성능 저하가 발생함을 확인할 수 있습니다.
- 1-3-5행과 2-4-6행을 비교함으로써, instance-segmentation을 이용할 경우 더 높은 정확도를 가짐을 확인할 수 있습니다.