
이번 논문 리뷰로 오랜만에 diffusion model을 들고 왔습니다. 기존 diffusion model들이 관행처럼 사용해오던 U-Net 구조의 backbone을 transformer로 나이브하게 변경한 논문입니다. transformer 기반의 diffusion model도 transformer의 scalable한 성질을 따르는 것을 실험적으로 보여줌과 동시에 class-conditional ImageNet 512×512, 256×256 benchmark에서 기존 방법론들을 제치고 SOTA를 달성했습니다.
Intro
최근 머신 러닝 기법들은 트랜스토머를 통해서 놀라운 발전을 이뤄오고 있습니다. 지난 5년 동안 NLP, vision 등등 기타 다른 도메인에서도 트랜스포머를 기반인 신경망들로 대체되어왔습니다. 그러나 image-level generative models에서는 autoregressive model들을 제외한 다른 generative modeling frameworsk에서는 트랜스포머를 적용한 케이스는 한 없이 적습니다. 특히, generative model을 선도하고 있는 diffusion model은 모두 컨볼루션 기반인 U-Net 기반인 backbone을 기본으로 사용하고 있는 추세입니다.
해당 논문에서는 diffusion model의 구조-backbone에 대한 경험적 기준선을 제공하는 것을 목표로 합니다. 저자는 U-Net의 inductive bias가 diffusion model의 성능에 핵심이 아니며 트랜스포머와 같은 기존 백본 모델들로도 쉽게 대체 가능하다는 것을 보입니다. 이를 통해 기존 백본 모델들을 활용한 사례들을 통해 학습 방법을 활용하고 해당 모델의 확장성, 견고성 및 효율성과 같은 유리한 속성들을 유지하여 활용 가능해집니다. 또한 이를 통해 cross-domain 연구에 대한 가능성을 열어줄 것을 기대한다고 합니다.
저자는 다양한 기존 백본 모델 중 트랜스포머를 기반으로 한 새로운 diffusion model인 Diffusion Transformers (DiT)에 중점을 둡니다. DiT는 ViT를 통해 확보된 config를 따릅니다.
좀 더 구체적으로 이야기 하자면 해당 논문에서는 DiT의 network complexity(measured by Gflops). vs sample quality(measured by FID).에 관련하여 트랜스포머의 scaling behavior를 연구합니다. 또한, Stable diffusion-VAE의 잠재 공간 내에서 diffusion model이 훈련되는 LDM (latent diffusion models) 프레임워크-를 기반으로 DiT를 설계했으며, 이를 벤치마킹하여 U-Net 백본을 성공적으로 대체할 수 있음을 보여줍니다.
+ 좀 더 직관적으로 요약하자면
++일반적으로 사용되는 U-Net 방식의 backbone을 latent pathces를 사용하는 transformer로 대체하여 latent diffusion model을 적용한 Diffusion Transformer (DiTs)를 제안함.
++ 저자는 분석을 통해 DiTs가 Gflops-increased transformer depth/with or increased number of input tokens-이 향상될 수록 FID가 지속적으로 낮아지는 경향을 발견함.
++ DiT-XL/2에서 이전 diffusion model들의 class-conditional ImageNet 512×512, 256×256 benchmark를 압도하는 결과를 보여주며, FID 2.27로 SOTA를 달성
Method
앞서 언급한 바와 같이 기존 diffusion model에서 관행처럼 사용되는 U-Net을 transformer~ViT로 변경한 것이 거의 끝이기에 아주 단순합니다. 단, diffusion model 중 LDM을 기반으로 하며, transfoemr는 ViT를 사용하기 때문에 통찰을 얻기 위해서는 두 방법론에 대한 지식이 요구됩니다. 링크를 걸어두었으니 필요하신 분들은 읽어보시면 좋을 것 같습니다.
+ 좀 더 구체적으로 이야기하자면 LDM을 크게 나누면 conditional image를 잠재 공간의 특징 정보로 사영시키는 encodoer E, 잠재 공간의 특징 정보를 다루는 DDPM과 DDPM으로 반복 연산된 특징 정보를 영상으로 변환시키는 VAE로 구분됩니다.
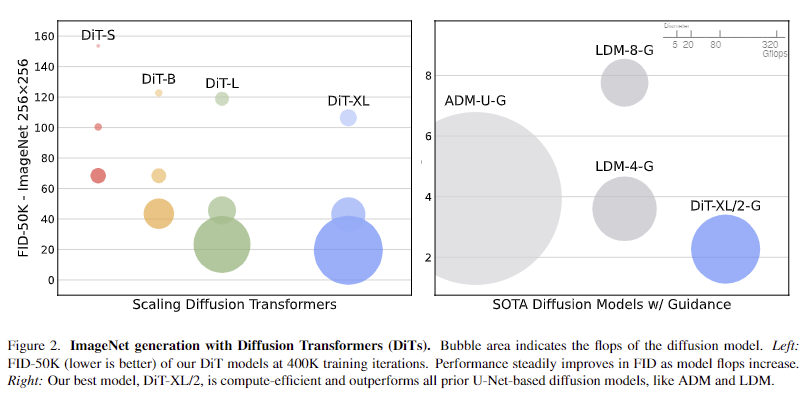
+ 저자는 fig 2에서 LDM이 기존 방법론 대비 성능과 Gflop 측면에서 효율적인 결과를 보이는 것을 토대로 LDM을 기반으로 설계를 진행하였다고 합니다.
Diffusion Transformer Design Space.
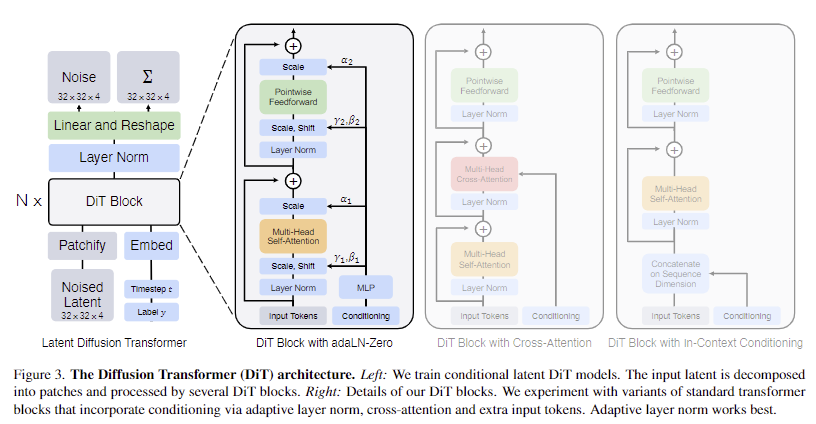
저자는 트랜스포머의 scaling한 속성을 최대한 유지하기 위해서 기존 transformer 구조에 최대한 충실하는 것을 목적으로 합니다. 우선 해당 모델은 DDPM(특히, 영상의 공간적 표현)을 훈련하는 것이 목표이기 때문에 DiT는 일련의 패치에서 작동하는 ViT를 기반으로 합니다. DiT는 ViT의 사례들을 기반으로 설계됩니다. fig 3에서는 DiT의 구조에 대한 전반적인 흐름을 보여줍니다. 해당 섹션에서는 DiT의 forward process와 DiT의 설계 구성 요소에 대해 소개합니다.
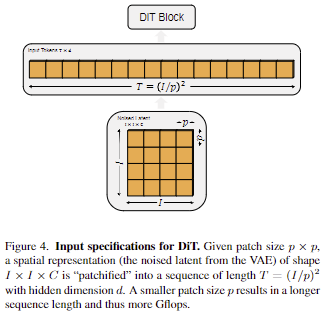
Patchify. DiT에 대한 입력은 spatial representation z = E(x) (e.g. 256 x 256 x 3 image x -> z has shape 32 x 32 x 4.) 입니다. DiT의 첫 번째 레이어는 “patchify”로 각 패치를 입력에 선형적으로 삽입하여 공간 입력을 각각 차원 d의 T 토큰 시퀀스로 변환합니다. 그 다음에, 모든 입력 토큰에 기존 ViT에 따라 sin-cos version의 positional embeddings을 적용합니다. 토큰의 수는 patch size hypermarameter p에 의해 결정됩니다. Fig 4에서 보이는 바와 같이 p를 절반으로 줄이면 T가 4배가 되고, Glfops는 최소 4배가 됩니다. 비록 p를 변경하면 Gflops에 상당한 영향을 주지만 downstream parameter counts에 대해서는 의미 있는 영향이 없다는 점에 유의해주세요. 해당 논문에서는 p=2,4,8을 적용하였습니다.
+ 패치가 증가하면 ViT의 head가 증가하지만 downstream을 수행하기 위한 output은 동일한 차원이 나오도록 설계 가능
+ diffusion model의 특징상, 동일 파라미터를 가진 모델로부터 나온 output을 반복 연산을 통해 값을 구함. 그렇기에 patch가 증가량에 반복 횟수만큼 가해져 Gflops이 증가함
DiT block design. patchify 이후, 입력 토큰은 일련의 트랜스포머 블록에 의해 처리됩니다. diffusion model은 노이즈가 있는 영상 입력 외에도 noise timestamp t, class lables c, natural language 등과 같은 추가 조건부 정보를 처리하기도 합니다. 조건부 입력을 다르게 처리하는 네 가지 변형 트랜스포머 블록을 살펴봅니다. 이 디자인들은 기존 (표준) ViT 블록 디자인에 약간의 변형을 가합니다. 모든 블록의 설계는 fig 3에 나와 있으며, 이는 아래와 같습니다..
- In-context conditioning. 단순히 입력 시퀀스(patches)에 t와 c의 벡터 임베딩을 두 개의 추가 토큰으로 추가하여 이미지 토큰과 동일하게 취급합니다. 이는 ViT의 cls 토큰과 유사하며, 이를 통해 수정 없이 standard ViT 블록을 사용할 수 있습니다. 최종 블록 이후에는 시퀀스에서 conditioning tokens을 제거합니다. 이 접근 방식은 모델 설계 측면에서 가장 나이브한 방식으로 Gflops 측면에서 베이스라인으로 사용됩니다.
- Cross-attention block. 이미지 토큰 시퀀스와는 별도로 t와 c의 임베딩을 길이 2의 시퀀스로 연결합니다. transformer block은 multi-head self-attention block에 이어 추가 multi-head cross-attention layer 포함하도록 수정되었으며, class label에 대한 conditioning을 위해 LDM에서 사용하는 것과도 유사합니다. Cross-attention은 모델에 약 15%의 오버헤드를 추가하여 가장 많은 Gflops를 보입니다.
- Adaptive layer norm (adaLN) block. GAN과 U-Net 백본 기반의 diffusion model에서 adaptive normalization layers가 널리 사용됨에 따라, transformer block의 standard layer norm layers를 adaptive layer norm (adaLN)으로 대체하는 방안을 모색합니다. dimension-wise scale과 shift parameters γ와 β를 직접 학습하는 대신, t와 c의 임베딩 벡터의 합으로부터 회귀합니다. 세 가지 블록 디자인 중 adaLN은 가장 적은 Gflops를 추가하므로 컴퓨팅 효율이 가장 높습니다. 또한 모든 토큰에 동일한 함수를 적용하도록 엄격하게 제한하는 유일한 컨디셔닝 메커니즘이기도 합니다.
- adaLN-Zero block. ResNet에 대한 이전 연구에 따르면 각 residual block을 identity function로 초기화하는 것이 유용하다는 사실이 밝혀졌습니다. 예를 들어 각 블록의 최종 batch norm scale factor γ를 0으로 초기화하면 지도 학습 환경에서 대규모 학습을 가속화할 수 있다는 사실을 발견했습니다. Diffusion U-Net model도 유사한 초기화 전략을 사용하여 residual connections 전에 각 블록의 최종 convolutional layer을 zero-initializing합니다. 저자는 유사한 작업을 수행하는 adaLN DiT block을 수정하여 사용할 것을 제안합니다. 또한 γ와 β를 회귀하는 것 외에도, DiT block 내의 residual connections 직전에 적용되는 dimension-wise scaling parameters α도 회귀합니다. 모든 α에 대해 zero-vector를 출력하도록 MLP를 초기화하면 전체 DiT 블록이 identity function로 초기화됩니다. vanilla adaLN block과 마찬가지로 adaLN-Zero는 베이스라인 대비 무시할 수 있는 Gflops이 발생합니.
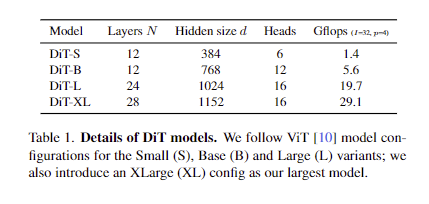
Model size. 해당 논문에서는 hidden dimension size d에서 작동하는 일련의 N개의 DiT 블록을 적용합니다. 보다 구체적으로 설명하면 표준 ViT에 따라 scale N, d 및 attention heads를 공동으로 확장하는 양식을 사용합니다. 즉, ViT의 config에 따라 DiT-S, DiT-B, DiT-L 및 DiT-XL 네가지 구성을 이룹니다 . 이 구성은 0.3~118.6Gflops에 이르는 광범위한 모델 크기와 flops 할당을 보임으로 확장 성능을 측정할 수 있습니다. tab 1은 구성에 대한 세부 정보를 제공합니다.
Transformer decoder. 최종 DiT 블록이 끝나면 이미지 토큰 시퀀스를 output noise prediction과 output diagonal covariance prediction으로 디코딩해야 합니다. 이 두 출력은 모두 original spatial input과 동일한 모양을 갖습니다. 이를 위해 tandard linear decoder를 사용해 최종 layer norm (adaptive if using adaLN)을 적용하고 각 토큰을 p×p×2C tensor (여기서 C는 DiT에 대한 spatial input의 채널 수)로 디코딩합니다. 마지막으로 디코딩된 토큰을 original spatial layout으로 재배열하여 predicted noise와 covariance을 얻습니다.
Experiment
Experimental Setup
+ DiT-XL/2: XLarge config and p=2
- Training.
- AdamW, LR=1 × 10−4, Batch size = 256, warmup 미적용
- Augmenation: only horizontal flips
- Diffusion. Stable Diffusion의 사전 훈련된 variational autoencoder (VAE) model을 사용합니다. VAE 인코더의 downsample factor는 8이며, RGB 이미지 x가 256 × 256 × 3 모양이고 z = E(x)는 32 × 32 × 4 모양입니다. 모든 실험에서 diffusion models은 이 Z 공간에서 작동합니다. diffusion model에서 new latent을 샘플링한 후, VAE decoder D는 x = D(z)를 사용하여 픽셀로 디코딩합니다. 추가로 diffusion의 convariance와 하이퍼-파라미터는 이전 연구인 ACM을 따릅니다.
- Compute. 모든 모델을 JAX로 구현하고 TPU-v3 pods를 사용하여 훈련합니다. DiT-XL/2는 global batch size가 256인 TPU v3-256 pods에서 초당 약 5.7번의 반복으로 훈련합니다.
+ JAX는 ViT의 특화된 라이브러리로 numpy로 구현된 딥러닝 라이브러리입니다.
+ TPU라서 얼마나 많은 코스트가 드는건지 감이 안오네요 ㅠ… 일단 TPU v3-256 pods가 128G라고 합니다.
Experiments
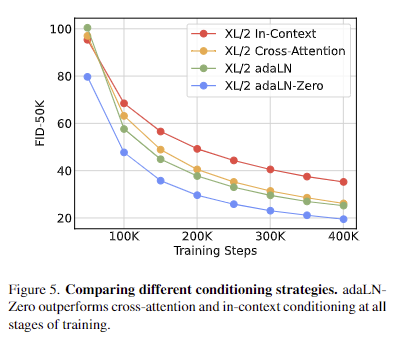
- DiT block design. 해당 실험에서는 앞서 언급한 4종의 블록 구조에 대한 Gflop과 성능을 분석합니다. 모델은 DiT-XL/2을 기반으로 하며 in-context (119.4Gflops), cross-attention (137.6Gflops), adaptive layer norm (adaLN, 118.6Gflops) 또는 adaLN-zero(118.6Gflops)를 훈련합니다. fig 5에서는 훈련이 진행되는 동안 FID를 측정 결과를 보여줍니다. 결과적으로 adaLN-Zero 블록이 가장 효율적인 컴퓨팅 파워와 가장 좋은 FID를 보입니다. 이를 기반으로 이후 모든 모델에 adaLN-Zero DiT 블록을 사용합니다.
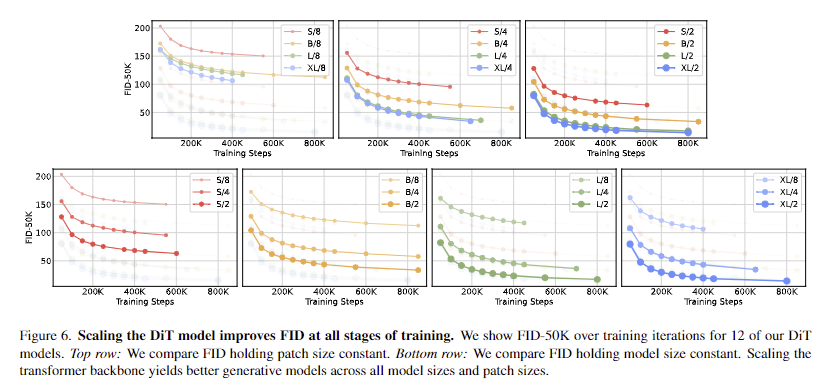
- Scaling model size and patch size. 모델 구성(S, B, L, XL)과 패치 크기(8, 4, 2)에 따라 12개의 DiT에 대한 분석을 진행합니다. DiT-L과 DiT-XL은 다른 구성보다 상대적인 Gflops 측면에서 훨씬 더 가깝다는 점에 유의하세요. fig 2(왼쪽)는 400K 훈련 반복에서 각 모델의 Gflops와 해당 FID에 대한 개요를 보여줍니다. 모든 경우에서 모델 크기를 늘리고 패치 크기를 줄이면 diffusion model이 상당히 개선된다는 것을 알 수 있습니다. fig 6(위)은 모델 크기를 늘리고 패치 크기를 일정하게 유지했을 때 FID가 어떻게 변화하는지 보여줍니다. 네 가지 구성 모두에서 트랜스포머를 더 깊고 넓게 만들면 모든 훈련 단계에서 FID가 크게 개선됩니다. 마찬가지로 fig 6(하단)은 패치 크기를 줄이고 모델 크기를 일정하게 유지했을 때의 FID를 보여줍니다. 파라미터를 거의 고정된 상태로 유지한 채로 DiT가 처리하는 토큰의 수를 단순히 확장하는 것만으로도 훈련 전반에 걸쳐 상당한 FID 개선을 관찰할 수 있습니다.
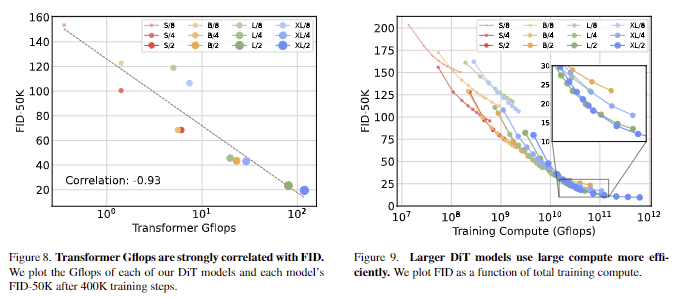
- DiT Gflops are critical to improving performance. fig 6의 결과는 파라미터 수가 DiT 모델의 품질을 유일하게 결정하는 요소가 아님을 시사합니다. 모델 크기가 일정하게 유지되고 패치 크기가 감소하면 트랜스포머의 총 파라미터는 사실상 변경되지 않고(실제로는 총 파라미터가 약간 감소), Gflops만 증가합니다. 이러한 결과는 Gflops에 대한 모델 스케일링이 실제로 성능 향상의 핵심임을 나타냅니다. 이를 더 자세히 알아보기 위해 fig 8 (왼쪽)에서 400K 훈련 단계의 FID-50K를 모델 Gflops와 비교하여 플롯합니다. 결과는 총 Gflops가 비슷한 경우(e.g. DiT-S/2 and DiT-B/4) 서로 다른 DiT 구성이 비슷한 FID 값을 얻는다는 것을 보여줍니다. 또한 fig 8 (왼쪽)에서 보이는 바와 같이 FID-50K~Transformer Gflops 간의 강한 음의 상관관계가 있음을 알 수 있으며, DiT 모델에 대한 성능 향상의 핵심 요소임을 시사합니다.
- Larger DiT models are more compute-efficient. fig 9에서는 모든 DiT 모델에 대한 총 training compute의 함수와 이에 대한 FID를 표시합니다. training compute은 모델 Gflops * batch size * trainig step * 3으로 추정되며, 여기서 3의 계수는 대략적으로 backwards pass가 forward pass보다 컴퓨팅 부하가 두 배 더 많다는 것을 의미합니다. DiT/S 모델은 더 오래 훈련하더라도 결국 더 적은 단계로 훈련된 큰 DiT 모델에 비해 compute-inefficient이라는 것을 알 수 있습니다. 마찬가지로, patch size를 제외하고 동일한 모델이라도 Gflop을 제어할 때 성능 양이 서로 다른 결과를 보입니다. 예를 들어, XL/4는 약 1010 Gflops 이후에는 XL/2보다 성능이 더 뛰어난 결과를 보이죠.
- Visualizing scaling. fig 7에서는 스케일링이 샘플 품질에 미치는 영향에 대한 시각화 결과 보입니다. 400K training steps에서 12개의 DiT 모델에서 각각 이미지를 샘플링. 모델 크기와 토큰 수를 모두 조정하면 시각적 품질이 눈에 띄게 향상

SOTA
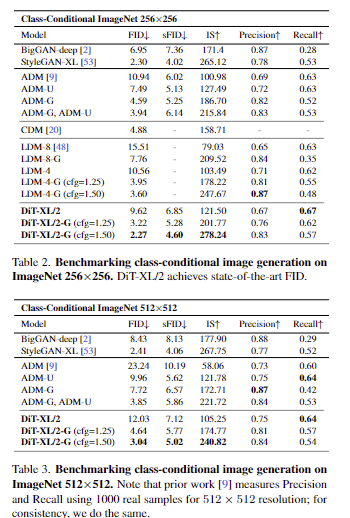
tab 2-3에서 class-conditional image generation in 256×256 ImageNet and 512×512 ImageNet에서 SOTA를 달성한 결과를 보여
Scaling Model vs. Sampling Compute.
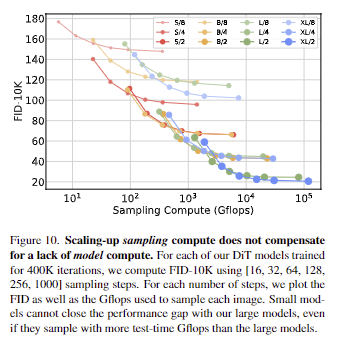
Diffusion models은 이미지를 생성할 때 sampling steps의 수를 늘려 훈련 후 추가 컴퓨팅을 사용할 수 있다는 점에서 독특합니다. 모델에 Gflops이 샘플 품질에 미치는 영향을 고려할 때, 더 많은 샘플링 컴퓨팅을 사용하여 더 작은 모델의 DiT가 더 큰 모델의 성능을 능가할 수 있는지에 대해 보입니다. 이미지당 [16, 32, 64, 128, 256, 1000] sampling steps를 사용하여 400K training steps를 거친 후 12개 DiT 모델 모두에 대해 FID를 계산합니다. 주요 결과는 fig 10에 나와 있습니다. 1000개의 sampling steps을 사용하는 DiT-L/2와 128개의 sampling steps을 사용하는 DiT-XL/2를 비교해보면 L/2는 각 이미지를 샘플링하는 데 80.7T플롭을 사용하고, XL/2는 5배 적은 연산(15.2T플롭)을 사용하여 각 이미지를 샘플링합니다. 그럼에도 불구하고 XL/2의 FID-10K가 더 우수한 결과를 보입니다.(23.7 vs 25.9). 저자는 이에 대해 일반적으로 sampling에 대한 scaling-up은 model compute를 보완할 수 없다고 합니다.
트랜스포머가 결국 diffusion model까지 넘어왔네요 ㅋㅋㅋ 근데 생각보다 나이브하게 접근해도 잘 작동하는 것으로 보아 확장 가능성이 크게 보입니다. 또한 트랜스포머의 스케일 업만 해도 성능이 향상되는 결과를 보아… 한동안은 diffusion model도 transformer 기반으로 흘러갈 것 같네요. 관련 연구 하시는 분들은 참고하시길…
안녕하세요.
질문이 조금 있는데요, 먼저 해당 논문에서는 GFLOP과 FID 사이에 대한 실험을 이것저것 한 것으로 보입니다. 제가 제대로 이해한 것인지는 모르겠지만, 모델의 파라미터 크기 보다는 token 수에 따른 연산량이 더 커짐에 따라 GFLOP이 커지면 FID가 더 낮게(좋게) 된다는 결과인 것 같은데 맞나요?
그거랑 별개로 원래 diffusion이 resnet기반으로 동작하던 시절에도 추론 시간이 오래 걸리던 것 같은데 혹시 transformer로 변경되는 경우에는 추론 시간이 얼마나 더 커지나요? GFLOPs로 표현되다보니까 직관적이지 않은데 resNet 기반 Unet diffusion 모델과 비교해서는 얼마나 더 큰 GFLOPs 혹은 추론 시간을 가지는지 궁금하네요.
마지막으로 adaptive layer norm이라던지 등등 transformer block 안에 구성 자체에도 많은 디테일을 신경써서 transformer diffusion을 구성한 것 같은데, 이와 관련해서는 따로 ablation study가 없나요? 가령 그냥 순수한 ViT 블록과 다르게 본인들이 세부적으로 구성을 바꾼 transformer block이 diffusion 모델에 더 적합한다던가 말이에요.
감사합니다.
Q. 질문이 조금 있는데요, 먼저 해당 논문에서는 GFLOP과 FID 사이에 대한 실험을 이것저것 한 것으로 보입니다. 제가 제대로 이해한 것인지는 모르겠지만, 모델의 파라미터 크기 보다는 token 수에 따른 연산량이 더 커짐에 따라 GFLOP이 커지면 FID가 더 낮게(좋게) 된다는 결과인 것 같은데 맞나요?
A. 질문을 보니 fig 10에 대해서 질문하신 걸로 이해됩니다. Diffusion의 특성상 반복 연산; sampling steps을 수행해야합니다. 이때 소요되는 반복 연산 횟수와 이에 다른 연산량을 Sampling Compute (Gflop)으로 표시한 겁니다. 그리고 token이 들어남에 따라 성능이 개선되는 결과이냐는 말씀도 맞습니다. 각 성능을 보이는 그림의 범례에서 {S, B, L, XL}/{2, 4, 8} 중 숫자가 patch size = num of token이기에 맞는 말입니다.
Q. 그거랑 별개로 원래 diffusion이 resnet기반으로 동작하던 시절에도 추론 시간이 오래 걸리던 것 같은데 혹시 transformer로 변경되는 경우에는 추론 시간이 얼마나 더 커지나요? GFLOPs로 표현되다보니까 직관적이지 않은데 resNet 기반 Unet diffusion 모델과 비교해서는 얼마나 더 큰 GFLOPs 혹은 추론 시간을 가지는지 궁금하네요.
A. resNet 기반과 비교 성능이 궁금하시다는 질문이네요. 이전 기법들은 모두 resnet 기반이라고 보시면 됩니다. fig 2를 보시면 될 것 같고, 저자는 LDM(=Stable diffusion)과 비교했을 때, transforemr인데도 불구하고 비슷하다는 어필을 하고 싶었던 것 같네요.
Q. 마지막으로 adaptive layer norm이라던지 등등 transformer block 안에 구성 자체에도 많은 디테일을 신경써서 transformer diffusion을 구성한 것 같은데, 이와 관련해서는 따로 ablation study가 없나요? 가령 그냥 순수한 ViT 블록과 다르게 본인들이 세부적으로 구성을 바꾼 transformer block이 diffusion 모델에 더 적합한다던가 말이에요.
A. fig 5 쪽 내용 보시면 됩니다.