안녕하세요, 이번에는 6D pose estimation의 방법론에 대한 논문입니다.
Nvidia의 최근 연구 방향을 살펴보고자 알아보던 중에 내용이 흥미로워 읽게 되었습니다. 결국 large-scale의 데이터를 사용하여 novel object에 대한 6D pose estimation을 수행하는 것이 해당 논문의 전체적인 흐름입니다. 아무래도 로봇 task를 최종적으로 수행하는 것이므로 논문의 내용에는 detector에 대한 자세한 설명보다는 pose estimation을 어떻게 수행하는지에 대한 내용으로 좀 더 초점이 맞춰져 있네요. notation이 자주 나와 읽는 데에 불편함이 없도록 작성을 해두었으니, 읽는 데에 도움이 되셨으면 합니다.
리뷰 시작하겠습니다.
Introduction
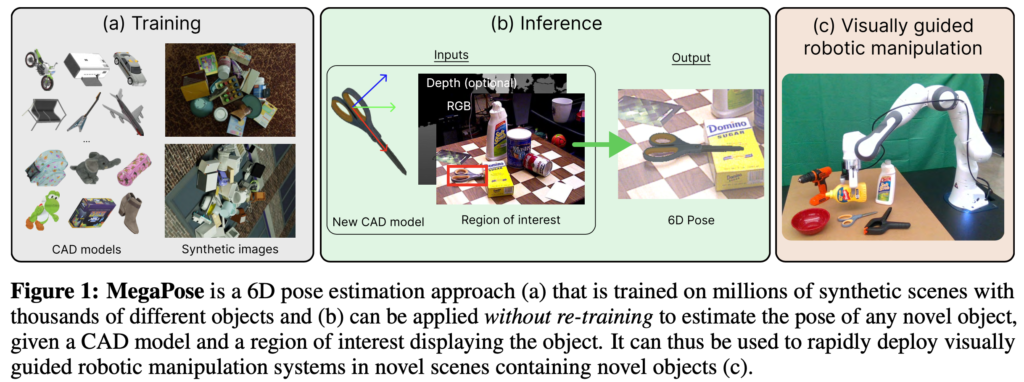
물체에 대한 6D pose estimation을 수행하는 것은 많은 로봇 및 증강 현실 애플리케이션에 필수적입니다. 학습 및 추론을 할 때 모두 물체의 3D 모델이 필요합니다. 이러한 방법은 각 물체에 대한 합성 데이터를 생성하고 pose 추정 모델을 학습하는 데 수 시간에서 수 일이 소요되게 됩니다. 따라서, 추론을 할때 새로운 물체가 등장했을 때, 새로운 scene과 새로운 물체에 빠르게 적용하는 것이 중요한 로봇 애플리케이션에는 사용할 수 없습니다.
이번 논문의 목표는 새로운 물체, 즉 추론 시점에만 사용할 수 있고 학습 중에 미리 알 수 없는 물체에 대한 6D pose를 추정하는 것입니다. 이러한 문제는 실제 애플리케이션에서 접할 수 있는 모양, 질감, 조명 조건, 심한 occlusion 등의 큰 변화에 대해 일반화해야 하는 어려움을 겪고 있습니다.
이번 논문에서의 contribution은 다음과 같습니다
- 새로운 물체에 대한 일반화할 수 있는 rendering 및 compare를 기반으로 6D pose refinement를 위한 새로운 접근법을 제안
- 학습 중에 물체의 대칭에 대한 knowledge가 필요하지 않은 새로운 coarse 모델 제안
- large-scale의 데이터셋을 활용하여 20만개 이상의 3D 모델이 나타나는 2백만장의 PBR 합성데이터를 생성하여 학습으로 사용함
Method
이번 MegaPose에서는 Novel Object에 대한 pose estimation을 수행합니다. 최종 목적은 대상이 되는 물체에 대한 pose를 구하는 것입니다. 입력으로 RGB/RGB-D와 3D 모델이 주어졌을 때, 3가지의 구성 요소를 통해pose를 구하게 되는데요. 구성 요소는 다음과 같습니다.
(1) Object detection
(2) coarse pose estimation
(3) pose refinement
이번 논문에서 제안하는 방법론은 새로운 물체(학습하는 동안 보지못한 물체, Novel object)에 대한 일반화를 가능하게 하였으며, 해당 새로운 물체에 대한 과정은 coarse model, refiner, 학습 데이터를 필요로 하게 됩니다. MegaPose는 단일 RGB 또는 RGB-D의 입력이 가능한데요, 이는 네트워크의 입력으로 optional하게 동작하도록 설계를 했다고 합니다. 새로운 물체에 대한 detection을 수행하는 것은 이번 논문의 범위에 벗어나므로 따로 설명을 하지 않는다고 합니다. 그래서 실험을 진행할 때에도 어느 detector를 사용하든 해당 논문의 방법론과는 별개라고 한 번 더 강조를 합니다.
Technical Approach
(Notation 정리)
\mathcal T_{CO} : 카메라 좌표계(C)에 대한 물체 좌표계(O)에 대한 Translation, Rotation 정도를 의미하는 Transform matrix
Coarse pose estimation
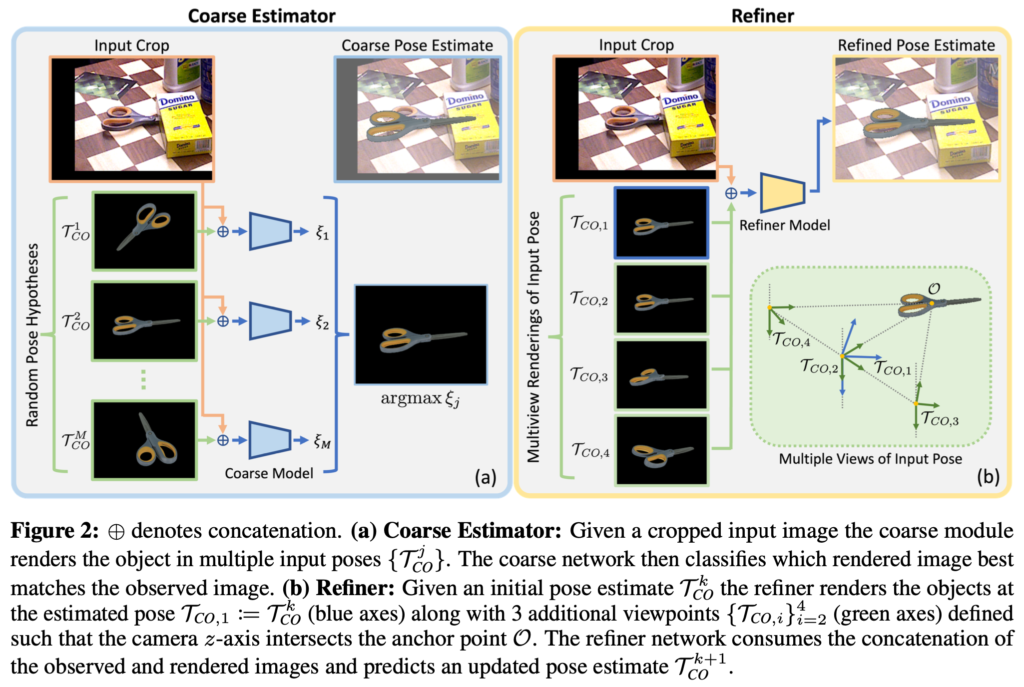
그림(1)의(b)는 Object Detection을 수행하였을 때 coarse pose estimator의 목표는 initial pose estimation입니다. 이는 refiner로 정보를 전달하기 위해 중요한 매개체라고 볼 수 있겠네요. 새로운 물체에 대한 일반화를 위해 저자는 새로운 분류 기반의 접근법을 제안하는데요, 이는 물체의 observed 이미지와 rendered 이미지에 대한 다양한 pose들을 통해 rendered 이미지를 통해 observed 이미지와 서로 비교하였을 때 best pose를 매칭시켜주도록 합니다.
그림(2)의 (a)는 coarse 모델에 전체적인 overview를 나타냅니다. inference를 할 때 네트워크는 Observed Image(I_{o})가 Rendered image(I_{r})은 \{I_{r}(\mathcal T_{CO}^j)\}{j=1}^{M}으로, 다양한 다른 pose들을 의미하는 \{\mathcal T{CO}^j\}{j=1}^{M}만큼 수행하게 됩니다. 모델에서 예측된 각 pose들에 대해서 score를 측정하는 과정은 Random Pose Hypothesis 쪽을 의미하는 (I{o}, I_{r}(\mathcal T_{CO}^j)) \rightarrow \zeta_{j}의 과정입니다. 이렇게 분류를 통해 pose의 예측 결과가 refiner의 attraction 내에 있는지 여부를 판단하게 됩니다. 최종적으로 가장 높은 점수를 가지는 값을 얻기 위해 argmax를 취한 결과가 refinement 과정으로 가기 위한 initial pose로 사용되게 됩니다. 해당 과정은 분류를 수행하기 때문에 여러 pose들이 옳은 pose로 분류를 하도록 하게 될 것 입니다. 그러므로 대칭인 물체에 대해서도 커버가 가능하게 됩니다.
Pose refinement model
해당 refinement 과정은 이미지와 initial pose(estimated pose)가 주어지게 되면, refiner가 pose를 업데이트 하는 방식으로 진행하게 됩니다. coarse initial pose \mathcal T_{CO, coarse}부터 시작하여 반복적으로 refiner를 적용하게 되면 pose estimation의 결과를 향상시킬 수 있게 됩니다. MegaPose에서 사용되는 refiner는 observed 이미지 I_{o}와 rendered 이미지 I_{r}(\mathcal T_{CO}^k)를 사용하며 업데이트된 pose \mathcal T_{CO}^{k+1}를 예측하게 됩니다. 이때, k는 refiner 과정을 반복하는 횟수를 의미합니다. 설명한 해당 refinement과정에 대한 overview는 그림(2)의 (b)를 보시면 이해가 직관적으로 되실 것이라고 생각합니다. pose를 업데이트하는 과정에서도 파라미터가 사용될텐데 이는 rotation과 translation에 대해 각각 분리되어 사용된다고 합니다. 이러한 parameterization 과정은 선행연구인 DeepIM과 CosyPose와 동일하게 구성을 했다고 하네요. 또 중요한 점은 이러한 pose 업데이트 과정은 anchor point mathcal O에 의존적이라는 겁니다. 같은 물체에 대해 학습 및 평가를 진행한다면 anchor point \mathcal O가 효과적으로 위치를 학습하겠지만, 새로운 물체에 대한 일반화를 수행하기 위해서는 네트워크가 inference 할 때 anchor point \mathcal O를 예측할 수 있도록 해야 합니다.
그럼 anchor point \mathcal O는 어떻게 예측하도록 할까요?
그림(2)의 (b)에 해당하는 multiple views of input pose를 보시면저자는 해당 정보를 제공하기 위해 모든 rendered 이미지 I_{r}(\mathcal T_{CO}^k)에 anchor point \mathcal O를 이미지의 중점에 projection하였고 이러한 rendered 이미지들을 사용하여 네트워크는 이는 카메라 ray와의 교점을 의미을 의미하는 anchor point \mathcal O에 대한 위치를 예측할 수 있게 됩니다.
물체의 모양이나 기하학적인 추가적인 정보는 redering된 depth와 surface normal channel들을 제공할 수 있습니다. 만약 depth를 추가적인 입력으로 주게 되는 경우 물체에 대한 scale 정보를 좀 더 일반화하는 것에 도움을 주게 될 것이라고 합니다.
Network architecture
앞서 설명한 coarse와 refiner는 ResNet34를 backbone으로 사용합니다.
coarse 모델은 backbone feature를 사용하고 분류에 대한 logit을 결과로 내는 single FC layer로 구성되어 있습니다.
refiner 모델도 동일하게 backbone feature를 사용하고 pose 업데이트에 대한 rotation과 translation을 지정하는 9개의 값을 출력하는 single FC layer가 있습니다.
Training Procedure
Training data
학습을 위해서는 coarse model과 refiner model은 둘 다 물체에 대응하는 3D 모델에 대한 6D pose annotation 정보가 있어야 합니다. 새로운 물체에 대한 일반화를 위해 저자는 다양한 물체를 포함하는 대규모의 데이터셋을 필요로 하게 되었다고 합니다. MegaPose는 결국 BlenderProc으로 만든 합성 데이터를 사용하여 학습을 합니다. 해당 데이터들은 2백만 이미지를 사용하는데, ShapeNe(SN)과 Google-Scanned-Objects(GSO)들을 조합하여 사용하였다고 합니다. BOP challenge에서 사용되는 합성 데이터와 비슷하게 데이터셋에서 무작위로 물체를 샘플링하여 물리 시뮬레이터를 사용하여 평면에 떨어뜨려 사용하였다고 합니다. 소재, 배경에 대한 재질, 조명 정도, 카메라 위치들은 모두 랜덤하다고 합니다. 예시 이미지는 그림(1)의 (a)에 해당하는 synthetic images를 보시면 됩니다.
Refiner model
입력으로 물체 \mathcal M에 대한 GT pose \mathcal T_{co}^\prime observed 이미지 I_{o}가 주어질 때, random한 rotation과translation을 \mathcal T_{co}^\prime에 적용하여 perturbed pose \mathcal T_{co}^\prime을 생성하게 됩니다. 이때, perturbed pose는 random으로 GT pose에 대한 변화된 pose라고 이해하시면 됩니다. translation은 표준 편차가 (0.02, 0.02, 0.05) cm인 정규 분포에서 샘플링되고 rotation은 각 축에서 표준 편차가 15도인 임의의 Euler angle으로 샘플링됩니다. 네트워크는 initial pose와 target pose 사이에서 상대적인 변화정도를 예측하도록 학습이 진행되게 됩니다. loss는 depth, x-y translation, rotation에 대한 disentangle한 loss를 사용합니다.
Coarse model
입력으로 물체 \mathcal M에 대한 observed 이미지 I_{o}와 이에 해당하는 앞서 언급된 perturbed pose \mathcal T_{co}^\prime가 주어졌을 때, coarse 모델은 \mathcal T_{co}^\prime가 refiner의 attraction한지 아닌지 분류하도록 학습을 진행합니다. refiner가 initial pose 추정치인 \mathcal T_{co}^\prime로 시작한다면 반복적인 refiner과정을 통해 GT를 추정할 수 있을까요? GT pose인 \mathcal T_{co}^*가 주어지면 random한 rotation과 rotation을 적용하여 \mathcal T_{co}^\prime를 샘플링합니다. 이때, positive pose는 refiner가 학습한 perturbed pose를 생성하는 데 사용되는 것과 동일한 분포에서 샘플링됩니다. 해당 pose와 충분히 구별이 되는 경우는 negative pose로 분류가 되겠죠. 이로써 해당 모델은 최종적인 출력을 위해 cross entropy로 학습을 진행하게 됩니다.
Experiments
Dataset and metrics
실험은 BOP challenge에서 사용되는 7개의 코어 데이터셋(LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB, YCB-V)에서 진행됩니다. 해당 데이터셋들은 132개의 다양한 물체들과 clutter, occlustion이 있는 scene들로 구성되어 있습니다. 해당 물체들은 다양하게 구성되어 있는데요. 예를들면, 텍스처의 유무, 대칭/비대칭, 가정용/산업용 등으로 구성되어 있습니다. 이러한 구성들은 로봇이 동작하는 것에 대한 여러 시나리오로 구성되어 있다고도 볼 수 있겠네요. 또한 저도 처음보는 데이터셋인 ModelNet이라는 데이터셋은 indivisual한 instance들 7개의 요소(bathtub, bookshelf, guitar, range hood, sofa, tv stand, wardrobe)들로 제공하고 있습니다. 저자는 선행 연구들과 유사하게 GT에 noise를 추가하여 얻은 pose를 initial pose로 사용한다고 합니다. 이러한 initial pose를 개선하는 것에 초점을 두었으며, BOP challenge에 대한 데이터셋들은 해당 challenge에서 사용되는 평가 지표들을 사용하고 ModelNet의 경우는 DeepIM의 평가 지표를 사용하였다고 합니다.
6D pose estimation of novel objects
Performance of coarse+refiner
coarse모델과 refiner를 동시에 비교하는 것에 초점을 맞춘 섹션입니다.
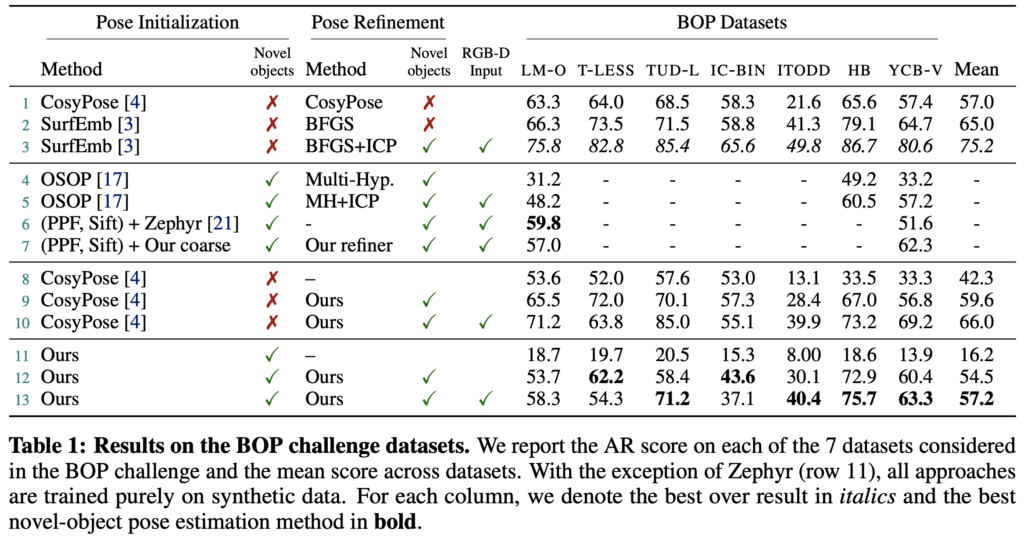
표(1)은 BOP 데이터셋에 대한 각각에 대한 물체의 pose estimation 방법론의 결과를 나타내고 있습니다.
PPF(point cloud를 이용하는 matching 알고리즘)와 SIFT의 조합으로 제공되는 detection과 pose estimation을 사용하는 6행을 베이스라인으로 하여, coarse 모델에서 사용하는 score를 사용해 최적의 hypothesis를 찾은 다음 5번의 refinement 반복합니다. 이에 대한 결과는 7행에 리포팅 되어 있는 것을 확인할 수 있습니다.
coarse estimation strategy의 결과는 11행에 리포팅 되어있습니다. 단일 RGB에 대한 refiner를 수행 한 결과는 12행, RGB-D를 통한 refiner의 결과는 13행에 있는데요. MegaPose는 첫 번째로 refine 네트워크가 coarse estimation 결과에 대한 정확도를 크게 향상시키고, 두 번째로 두 모델의 성능이 테스트에 해당 하는 물체에 대한 학습이 필요하지 않으면서도 기존의 CosyPose(1행)의 학습 기반 refiner보다는 떨어지지만 경쟁력을 보여주는 것을 보여줍니다.
SurfEmb(2행)는 MegaPose 보다 더 나은 성능을 보이지만, 학습을 위해 물체에 대한 정보에 크게 의존하며 새로운 물체에 일반화할 수 없으므로 적절하지 않다고 합니다.
Performance of the refiner
이번에는 임의의 initial pose를 개선하는 데 사용하는 refiner를 평가를 진행합니다.
MegaPose에서 사용하는 refiner는 새로운 물체에 대해 적용할 수 있는 유일한 학습 기반의 접근 방식입니다. 9행과 10행에서는 CosyPose의 대략적인 추정치에 대한 결과를 refiner를 적용함에 따른 결과를 리포팅한 것을 볼 수 있는데요. 해당 refiner를 통해 전체적으로 정확도를 크게 향상한 것을 볼 수 있습니다. 특히 단일 RGB만을 사용하여 학습 중에 BOP에서 사용하는 물체들을 학습하지 않은 상태에서 평균적으로 더 좋은 성능을 보여주고 있습니다. 이는 수천개의 다양한 물체에 대한 large-scale의 학습을 진행한 반면에, CosyPose는 각 데이터셋에 대한 수십 개의 물체만을 학습한 것으로 보입니다.
Limitations
MegaPose에 대한 한계의 첫 번째는 coarse 모델의 부정확한 initial pose 추정으로 인한 것이라고 합니다. refiner 모델은 제한된 범위 내에 있는 pose를 개선하도록 학습되지만 initial pose에 대한 error가 크면 작동하지 않을 수 있다고 합니다. 이러한 문제를 해결하기 위해서는 inference 시간이 늘어나는 대신에 pose hypothesis 수 M을 늘려 coarse 모델의 attraction을 늘리는 방법이 있습니다.
두 번째 한계는 coarse 모델의 런타임입니다. coarse 모델에서 rendering을 거치게 됩니다. 이때, 객체 당 M=520으로 설정하여 평가하는 경우 약 2.5초가 걸리게 된다고 하네요.
Conclusion
새로운 물체에 대한 6D pose estimation을 수행하는 MegaPose를 제안합니다. 해당 모델은 inference에만 사용할 수 있는 물체의 3D 모델이 주어지면 새로운 물체의 6D pose를 추정하게 됩니다. 저자는 clutter한 scene에서 등장하는 수백 개의 다양한 물체에 대해 MegaPose를 정량적으로 평가하고, 네트워크에 대한 설계를 함으로써 각각에 대한 선택을 검증하였습니다. 새로운 물체가 있는 새로운 scene에 대해서 빠르게 적용하는 것이 중요한 로봇의 조작에 대한 시나리오를 생각해보았을 때, 실용적인 새로운 방법입니다. 이를 개발하고 촉진하기 위해 large-scale의 합성 데이터셋과 모델을 공개하였습니다. 이번 논문에서는 물체의 pose를 coarse하게 추정하고 refiner를 통해 좀 더 개선하는 것에 중점을 두었습니다. 새로운 물체가 등장했을 때, 3D 모델만 주어진 경우 물체를 detection하고 pose estimation을 수행하는 것은 어려운 문제입니다. 향후 연구는 large-scale의 합성데이터를 사용하여 zero-shot object detection을 다룰 예정이라고 합니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
새로운 물체에 대한 detection을 수행하는 것이 논문의 범위에 벗어나는 파트이기는 하나, 결국 본 논문이 제안하는 coarse pose estimation과 같은 네트워크가 작동하기 위한 조건은 novel object detection 네트워크에서 새로운 물체가 검출이 된 경우가 맞는 것이죠 ??
그리고 Coarse pose estimation에서 pose의 예측 결과가 refiner의 attraction 내에 있는지 여부를 판단하게 된다고 말씀하셨는데, refiner의 attraction이 정확하게 무엇을 의미하는지 궁금합니다 . . .
그리고 해당 과정이 분류로 수행되기 때문에 대칭적인 물체에 대해서 커버가 가능하다고 설명해주셨는데, 이는 다양한 pose들 중에서 score가 가장 높은 pose로 선정되기 때문에 비교적 정확하게 대칭적인 물체에 대해서도 커버를 할 수 있다는 의미인가요 아니면 특별히 분류로 수행되기 때문에 대칭적인 물체까지 다룰 수 있는 이유가 있는 것인가요 ??
감사합니다.
안녕하세요 희진님 좋은 리뷰 감사합니다~~
1. fig2에서 input crop 이미지가 rendered images 들과 concat 되어 coarse Model의 입력으로 들어가던데 두 개의 이미지를 concat 시키는 이유는 무엇이고 coarse Model의 출력값 ξj는 무엇을 의미하는지 궁금합니다.
2. anchor point O가 무엇을 의미하는건가요? 또한 surface normal channel을 추가적으로 제공하면 물체에 대한 scale 정보를 좀 더 일반화하는 것에 도움을 줄 수 있다고 하셨는데 어떤 식으로 도움이 되는지가 궁금하네요. 예를 들면 빛의 반사 정보나 그림자 등을 정보로 이용하는 건가요?
그리고 마지막 질문은 조금 개인적인 거지만 Nvidia의 연구 방향에 대해 알아보시는 이유가 뭔지도 궁금하네요…ㅎㅎ
감사합니다!
좋은 리뷰 감사합니다.
Coarse pose estimation에 대한 설명 중 crop된 input 이미지와 렌더링 된 이미지 사이의 score를 구하는 과정에서 pose의 예측 결과가 attraction 내에 있다는 것은 어떻게 판단하는 지 궁금합니다. 또한, 해당 과정이 대칭인 물체에 대해 커버 가능하다고 하셨는데, 조금 더 설명해주실 수 있나요?
그리고 실험파트의 Table 1을 보면, 방법론마다 Novel object 가능 여부를 나타낸 것으로 보이는데, 리포팅된 실험결과도 novel obejct 유무와 관련이 있는 지 궁금합니다. 관련이 없다면, 해당 논문이 Novel object에 대응 가능하도록 제안된 방법론이다보니, 이를 실험적으로 검증하지는 않았는 지 궁금합니다.
좋은 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
1. T_{CO}에 대한 노테이션에 대한 정의를 정리가 필요한 것 같아요. “카메라 좌표계(C)에 대한 물체 좌표계(O)에 대한”이라고 하셔서 정확하게 어느 방향을 가르키는 건지 모르겠습니다.
2. Coarse pose estimation에서 1^M의 의미를 모르겠습니다. 그래서 그런지 이해가 안갑니다. 다시 설명 부탁드립니다.
3. anchor point가 물체의 중심?으로 설명되어져 있습니다. object detection으로부터 얻음 RoI의 중심이 물체의 중심이라는 가정으로 시작되는 걸까요?
4. “loss는 depth, x-y translation, rotation에 대한 disentangle한 loss를 사용합니다.”이 뭘까요?
4.